Когда встает вопрос о том, как вычислить арифметическое выражение, то, наверное, многие думают от обратной польской нотации. Поэтому в данном топике хотелось бы рассказать о том, как можно составить грамматику арифметического выражения и построить по ней лексический и синтаксический анализатор при помощи ANTLR.
Для начала рассмотрим необходимый инструментарий. Нам понадобятся:
Все, что имеет отношение к ANTLR, то есть первые три пункта, можно скачать с официального сайта http://www.antlr.org/download.html безвозмездно, то есть даром.
Теперь пару слов, собственно, об ANTLR (обратимся к Википедии). ANTLR (Another Tool For Language Recognition — «Еще один инструмент для распознания языков») — генератор парсеров, позволяющий автоматически создавать программу-парсер (как и лексический анализатор) на одном из целевых языков программирования (C++, Java, C#, Python, Ruby) по описанию LL(*)-грамматики на языке, близком к РБНФ. Автором данного проекта является профессор Теренс Парр (Terence Parr) из Университета Сан-Франциско. Надо сказать, что проект имеет открытый исходный код и распространяется по лицензии BSD.
В рамках данного топика мы напишем программу на языке C#, которая с консоли будет считывать арифметические выражения, разделенные переводом строки, а затем выдавать результат вычислений. В качестве арифметических операций будут поддерживаться: сложение, вычитание, умножение, деление. Для простоты все операции будут производиться над целыми числами. В качестве бонуса наш калькулятор (давайте так и назовем проект) будет поддерживать работу с переменными, а соответственно, и операцию присваивания.
Настало время запустить ANTLRWorks и создать проект с нашей грамматикой. При запуске ANTLRWorks спросит какой тип документа мы хотим создать. Выбираем «ANTLR 3 Grammar (*.g)». В появившемся окошке вводим имя грамматики (назовем ее «Calc»), тип оставляем по умолчанию («Combined Grammar»). Это означает, что в одном файле у нас будут находится как правила грамматики лексического, так и синтаксического анализатора. Чтобы в дальнейшем не было разногласий, давайте лексический анализатор будем называть лексер (Lexer), а синтаксический — парсер (Parser). Если в выпадающем списке вы посмотрите на другие варианты, то поймете введенные обозначения. Напомню, что лексер из потока символов выделяет лексемы(токены): целые числа, идентификаторы, строки и т.д., а парсер проверяет в правильном ли порядке идут лексемы в потоке лексем. Также рекоммендую поставить галочки Identifier и Integer, чтобы в нашей грамматике уже присутствовали правила для идентификаторов и целых чисел. В итоге должно получится следующее:

Нажимаеи кнопку «Ok» и получаем грамматику с двумя автоматически добавленными правилами лексера. Давайте разберем, как записываются правила для лексера на примере правила «INT». Правило начинается с имени (в данном случае INT). Имена для правил лексера обязаны начинаться с заглавной буквы. После имени идет символ ":", за которым следуют так называемые альтернативы. Альтернативы разделяются сиволом "|" и должны заканчиваться символом ";".
Посмотрим теперь на единственную альтернативу для правила INT. Запись '0'..'9'+ в ANTLR означает, что INT — это последовательность цифр, в которой есть хотя бы одна цифра. Если бы вместо символа '+' стоял, например, сивол '*', то это значило бы, что последовательность цифр может быть и пустой. Правило ID несколько сложнее и означает, что ID — это последовательность символов, состоящая из строчных и заглавных латинских букв, цифр, символов подчеркивания и начинающаяся с буквы или символа подчеркивания.
Ну что ж, напишем теперь самостоятельно первое правило для парсера или по-научному аксиому, то есть правило, с которого парсер начнет проверять поток лексем. И так:
Как видите, правила для парсера по структуре ничуть не отличаются от правил для лексера, разве что имя должно начинаться со строчной буквы. В данном случае мы говорим парсеру, что входной поток лексем представляет из себя непустую последовательность statement'ов. Поскольку парсер не ясновидящий, ему надо знать, что из себя представляет statement. Расскажем ему:
Те, кто забыл, что такое альтернативы, на данном правиле могутузнать вспомнить что это за зверь. Альтернатива — это просто один из возможных вариантов порядка следования лексем. То есть, statement — это ЛИБО выражение(expr), заканчивающееся переводм строки (NEWLINE), ЛИБО операция присваивания, оканчивающаяся переводом строки, ЛИБО просто перевод строки. Да, кстати, не забудте добавить правило NEWLINE в правила лексера, которые рекоммендую расположить в конце файла с грамматикой:
Знак "?" означает, что символ '\r' должен присутствовать в предложении либо 1 раз, либо не присутствовать вообще.
Теперь рассмотрим правило, в котором две альтернативы объединены в одну:
На языке ANTLR это означает, что expr есть произвольная последовательность слагаемых с произвольными знаками. Например, multExpression-multExpression+multExpression-multExpression-multExpression+multExpression.
Я не буду рассматривать оставшиеся правила (к тому же их осталось всего две штуки), а просто приведу их как есть:
Если Вы записываете правила в файл с грамматикой по ходу чтения, то наверняка уже заметили, что для каждого правила ANTLRWorks рисует граф. Заметили? Отлично! Теперь мне не надо комментирвоать каждое правило:
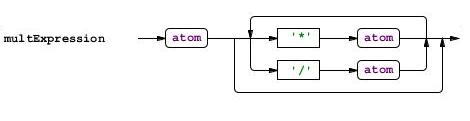
На этом с грамматикой можно закончить. Правда все просто?
Что ж, грамматику мы разработали. Настало время сгенерировать парсер и лексер на языке C#. Поскольку ANTLRWorks больше ориентирован на Java, поэтому генерировать код будет проще вручную (лично для меня), чем при помощи визуальной среды. Но об этом чуть позже. Для начала допишем пару строк в файл с грамматикой. Сразу после первой строчки с именнем грамматики необходимо добавить следующее:
Приведенные строки расскажут ANTLR, что мы хотим получить код на C#, а также хотим чтобы классы парсера и лексера находились в пространтсве имен Generated. Все, можно генерироват код. Для этого создадим .bat-файл, в который внесем следующее содержимое:
Обратите внимание, что в моем случае .bat-файл лежит в одной директории с файлами antlr-3.2.jar и Calc.g.
Ключ "-o" задает путь к папке, в которой будут лежить сгенерированные файлы. Пауза сделана исключительно для удобства — чтобы в случае наличия ошибок мы могли об этом узнать.
Запускаем .bat-файл и скорее смотрим в папку Generated. Там мы видим три файла:
Для запуска парсера я создал консольное приложение в Visual Studio и добавил в него два полученный .cs-файла. Для удобства пространство имен назвал Generated, чтобы не писать никакие using'и. Важно не забыть добавить в проект reference на C# runtime distribution (Файл Antlr3.Runtime.dll в архиве DOT-NET-runtime-3.1.1.zip, скачанного с сайта проекта ANTLR). В функцию Main() добавим следующий код:
Готово!!! Компилируем и запускаем.
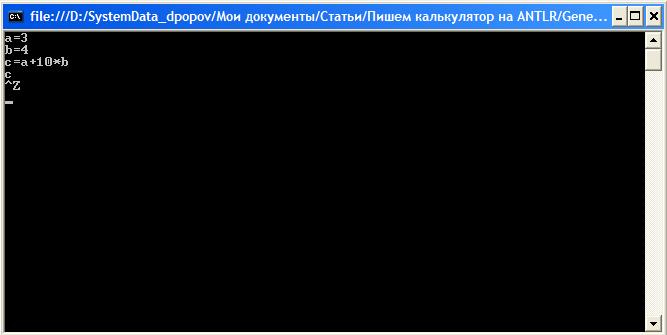
Обратите внимание, что ввод заканчивается, когда встречается символ конца файла (EOF). Чтобы этот символ поставить в Windows, следует нажать CTRL+Z.
Все почти здорово. Вы наверняка заметили, что никакого результат на экран не выводится. Непорядок! Чтобы исправить досадную недоделку надо снова поколдовать с грамматикой. Еще не закрыли ANTLRWorks?
Пришло время самого интересного. Для начала еще немного отконфигурируем ANTLR, добавив следующий фрагмент в начало файла с
грамматикой:
Поясню. @members говорит ANTLR, что необходимо добавить в класс парсера закрытый член memory (для хранения значений переменных) и, соответственно, header говорит какие пространтсва имен необходимо подключить, чтобы использовать Hashtable. Теперь можно добавлять C# код в нашу грамматику. Начнем с правила statement:
Код пишется в фигурных скобках {}. Если statement это первая альтернатива, то мы печатаем на экран значение арифметического выражения, если вторая — то сохраняем в memory имя перемменной и ее значение, чтобы потом можно было его получить. Тут все предельно просто, однако возникает вопрос, откуда берется значение выражения $expr.value? А берется оно отсюда:
Здесь тоже ничего сложного. Мы говорим ANTLR, что правило expr возвращает значение с именем value, имеющее тип int. Обратите внимание, что в обеих записях "$expr.value" и «returns[int value]» value фигурирует не случайно. Если мы напишем:
а потом обратимся к $expr.value, то ANTLR выдаст ошибку.
Я допустил некоторую вольность речи, сказав, что «правило возвращает значение», однако коротко сказать по-другому, не потеряв смысла, достаточно трудно на мой взгляд.
Еще одна тонкость. Рассмотрим правило statement, например, первую альтернативу. В коде, соответствующем данной альтернативе, мы обращаемся к правилу expr напрямую ($expr.value). Но в правиле statement так не получится, потому что в нем присутствуют сразу два правила multExpression, то есть, чтобы их различать нужно дать им имена. В данном случае это me1 и me2. Вроде бы все тонкости
обсудили, теперь ближе к сути.
В правиле expr две альтернативы записаны в одну через символ '|'. Это наглядно видно в части 2 данного топика. Напомню, что expr это предложения вида multExpression-multExpression+multExpression-multExpression-multExpression+multExpression. Теперь посмотрим на код в фигурных скобках и увидим, что сначала возвращаемому значению value присваивается значение первого слагаемого, а затем в зависимости от операции прибавляются или вычитаются значения последующих слагаемых. Аналогично выглядит правило
multExpression:
Осталось последнее правило парсера atom. С ним проблем возникнуть не должно:
Если atom это идентификатор (ID), то возвращаем его значение, взятое из memory. Если atom — целое число, то просто возвращаем число, полученное из его строкового представления. Ну и наконец, если atom это выражение в скобках, то просто возвращаем значение выражения.
Осталось сгенерировать парсер и лексер с помощью .bat-файла. Даже код функции Main() не придется менять. Запускаем наш калькулятор и играемся.

Интересно то, что сгенерированный парсер умеет сообщать о синтаксических ошибках и более того восстанавливаться после них. Чтобы это увидеть попробуйте набрать какое-нибудь выражение, например, с пробелами (мы ведь не сделали обработку пробелов, табуляций и прочего):
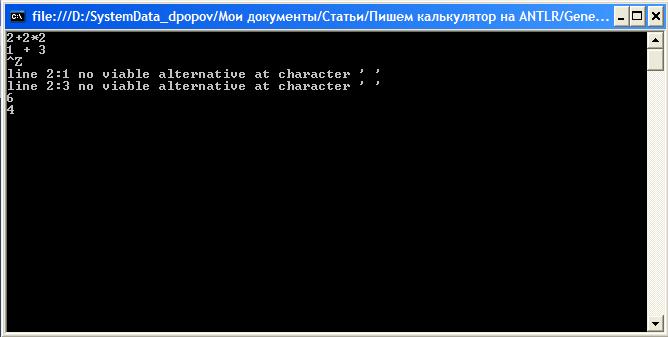
Парсер, обнаружил ошибки, но тем не менее правильно вычислил результат. Можно даже написать что-то типа «2++3» и получить 5.
Пришло время подвести небольшой итог. То решение, которое у нас получилось, как мне кажется, полностью соответствует поставленной задаче. Программа выражения считывает? Да. Результат вычисляет? Да. На этом, пожалуй, можно и закончить. Я очень надеюсь, уважаемый хаброчеловек, что этот топик пришелся тебе по душе и ты хочешь узнать, как с помощью ANTLR по грамматике строить деревья разбора и с помощью того же ANTLR их обходить. Если у тебя есть мечта написать свой собственный язык программирования, то с ANTLR она стала намного ближе к осуществлению!
Для начала рассмотрим необходимый инструментарий. Нам понадобятся:
- ANTLRWorks — среда для разработки и отладки грамматик
- ANTLR v3 — собтсвенно сам ANTLR (на момент написания статьи последнияя версия — 3.2)
- C# runtime distribution (Antlr3.Runtime.dll) — .NET библиотека для работы с сгенирированными анализаторами
- Visual Studio — любой другой инструмент для компиляции и отладки C# кода
- Среда исполнения Java — так как ANTLR и ANTLRWorks написаны на Java
Все, что имеет отношение к ANTLR, то есть первые три пункта, можно скачать с официального сайта http://www.antlr.org/download.html безвозмездно, то есть даром.
Теперь пару слов, собственно, об ANTLR (обратимся к Википедии). ANTLR (Another Tool For Language Recognition — «Еще один инструмент для распознания языков») — генератор парсеров, позволяющий автоматически создавать программу-парсер (как и лексический анализатор) на одном из целевых языков программирования (C++, Java, C#, Python, Ruby) по описанию LL(*)-грамматики на языке, близком к РБНФ. Автором данного проекта является профессор Теренс Парр (Terence Parr) из Университета Сан-Франциско. Надо сказать, что проект имеет открытый исходный код и распространяется по лицензии BSD.
1. Постановка задачи
В рамках данного топика мы напишем программу на языке C#, которая с консоли будет считывать арифметические выражения, разделенные переводом строки, а затем выдавать результат вычислений. В качестве арифметических операций будут поддерживаться: сложение, вычитание, умножение, деление. Для простоты все операции будут производиться над целыми числами. В качестве бонуса наш калькулятор (давайте так и назовем проект) будет поддерживать работу с переменными, а соответственно, и операцию присваивания.
2. Разработка грамматики
Настало время запустить ANTLRWorks и создать проект с нашей грамматикой. При запуске ANTLRWorks спросит какой тип документа мы хотим создать. Выбираем «ANTLR 3 Grammar (*.g)». В появившемся окошке вводим имя грамматики (назовем ее «Calc»), тип оставляем по умолчанию («Combined Grammar»). Это означает, что в одном файле у нас будут находится как правила грамматики лексического, так и синтаксического анализатора. Чтобы в дальнейшем не было разногласий, давайте лексический анализатор будем называть лексер (Lexer), а синтаксический — парсер (Parser). Если в выпадающем списке вы посмотрите на другие варианты, то поймете введенные обозначения. Напомню, что лексер из потока символов выделяет лексемы(токены): целые числа, идентификаторы, строки и т.д., а парсер проверяет в правильном ли порядке идут лексемы в потоке лексем. Также рекоммендую поставить галочки Identifier и Integer, чтобы в нашей грамматике уже присутствовали правила для идентификаторов и целых чисел. В итоге должно получится следующее:

Нажимаеи кнопку «Ok» и получаем грамматику с двумя автоматически добавленными правилами лексера. Давайте разберем, как записываются правила для лексера на примере правила «INT». Правило начинается с имени (в данном случае INT). Имена для правил лексера обязаны начинаться с заглавной буквы. После имени идет символ ":", за которым следуют так называемые альтернативы. Альтернативы разделяются сиволом "|" и должны заканчиваться символом ";".
Посмотрим теперь на единственную альтернативу для правила INT. Запись '0'..'9'+ в ANTLR означает, что INT — это последовательность цифр, в которой есть хотя бы одна цифра. Если бы вместо символа '+' стоял, например, сивол '*', то это значило бы, что последовательность цифр может быть и пустой. Правило ID несколько сложнее и означает, что ID — это последовательность символов, состоящая из строчных и заглавных латинских букв, цифр, символов подчеркивания и начинающаяся с буквы или символа подчеркивания.
Ну что ж, напишем теперь самостоятельно первое правило для парсера или по-научному аксиому, то есть правило, с которого парсер начнет проверять поток лексем. И так:
calc : statement+ ;
Как видите, правила для парсера по структуре ничуть не отличаются от правил для лексера, разве что имя должно начинаться со строчной буквы. В данном случае мы говорим парсеру, что входной поток лексем представляет из себя непустую последовательность statement'ов. Поскольку парсер не ясновидящий, ему надо знать, что из себя представляет statement. Расскажем ему:
statement : expr NEWLINE | ID '=' expr NEWLINE | NEWLINE ;
Те, кто забыл, что такое альтернативы, на данном правиле могут
NEWLINE : '\r'? '\n' ;
Знак "?" означает, что символ '\r' должен присутствовать в предложении либо 1 раз, либо не присутствовать вообще.
Теперь рассмотрим правило, в котором две альтернативы объединены в одну:
expr
: multExpression ('+' multExpression |'-' multExpression)*
;
На языке ANTLR это означает, что expr есть произвольная последовательность слагаемых с произвольными знаками. Например, multExpression-multExpression+multExpression-multExpression-multExpression+multExpression.
Я не буду рассматривать оставшиеся правила (к тому же их осталось всего две штуки), а просто приведу их как есть:
multExpression
: a1=atom ('*' a2=atom | '/' a2=atom)*
;
atom
: ID
| INT
| '(' expr ')'
;
Если Вы записываете правила в файл с грамматикой по ходу чтения, то наверняка уже заметили, что для каждого правила ANTLRWorks рисует граф. Заметили? Отлично! Теперь мне не надо комментирвоать каждое правило:
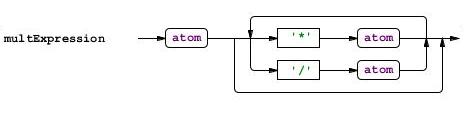
На этом с грамматикой можно закончить. Правда все просто?
3. Генерация и запуск парсера и лексера
Что ж, грамматику мы разработали. Настало время сгенерировать парсер и лексер на языке C#. Поскольку ANTLRWorks больше ориентирован на Java, поэтому генерировать код будет проще вручную (лично для меня), чем при помощи визуальной среды. Но об этом чуть позже. Для начала допишем пару строк в файл с грамматикой. Сразу после первой строчки с именнем грамматики необходимо добавить следующее:
options
{
language = CSharp2;
}
@parser::namespace { Generated }
@lexer::namespace { Generated }
Приведенные строки расскажут ANTLR, что мы хотим получить код на C#, а также хотим чтобы классы парсера и лексера находились в пространтсве имен Generated. Все, можно генерироват код. Для этого создадим .bat-файл, в который внесем следующее содержимое:
java -jar antlr-3.2.jar -o Generated Calc.g pause
Обратите внимание, что в моем случае .bat-файл лежит в одной директории с файлами antlr-3.2.jar и Calc.g.
Ключ "-o" задает путь к папке, в которой будут лежить сгенерированные файлы. Пауза сделана исключительно для удобства — чтобы в случае наличия ошибок мы могли об этом узнать.
Запускаем .bat-файл и скорее смотрим в папку Generated. Там мы видим три файла:
- CalcLexer.cs — код лексера
- CalcParser.cs — код парсера
- Calc.tokens — служебный файл со списком токенов
Для запуска парсера я создал консольное приложение в Visual Studio и добавил в него два полученный .cs-файла. Для удобства пространство имен назвал Generated, чтобы не писать никакие using'и. Важно не забыть добавить в проект reference на C# runtime distribution (Файл Antlr3.Runtime.dll в архиве DOT-NET-runtime-3.1.1.zip, скачанного с сайта проекта ANTLR). В функцию Main() добавим следующий код:
try
{
// В качестве входного потока символов устанавливаем консольный ввод
ANTLRReaderStream input = new ANTLRReaderStream(Console.In);
// Настраиваем лексер на этот поток
CalcLexer lexer = new CalcLexer(input);
// Создаем поток токенов на основе лексера
CommonTokenStream tokens = new CommonTokenStream(lexer);
// Создаем парсер
CalcParser parser = new CalcParser(tokens);
// И запускаем первое правило грамматики!!!
parser.calc();
}
catch(Exception e)
{
Console.WriteLine(e.Message);
}
Console.ReadKey();
Готово!!! Компилируем и запускаем.

Обратите внимание, что ввод заканчивается, когда встречается символ конца файла (EOF). Чтобы этот символ поставить в Windows, следует нажать CTRL+Z.
Все почти здорово. Вы наверняка заметили, что никакого результат на экран не выводится. Непорядок! Чтобы исправить досадную недоделку надо снова поколдовать с грамматикой. Еще не закрыли ANTLRWorks?
4. Добавление функционала калькулятора в грамматику
Пришло время самого интересного. Для начала еще немного отконфигурируем ANTLR, добавив следующий фрагмент в начало файла с
грамматикой:
@header{
using System;
using System.Collections;
}
@members{
Hashtable memory = new Hashtable();
}
Поясню. @members говорит ANTLR, что необходимо добавить в класс парсера закрытый член memory (для хранения значений переменных) и, соответственно, header говорит какие пространтсва имен необходимо подключить, чтобы использовать Hashtable. Теперь можно добавлять C# код в нашу грамматику. Начнем с правила statement:
statement
: expr NEWLINE { Console.WriteLine($expr.value); }
| ID '=' expr NEWLINE { memory.Add($ID.text, $expr.value); }
| NEWLINE
;
Код пишется в фигурных скобках {}. Если statement это первая альтернатива, то мы печатаем на экран значение арифметического выражения, если вторая — то сохраняем в memory имя перемменной и ее значение, чтобы потом можно было его получить. Тут все предельно просто, однако возникает вопрос, откуда берется значение выражения $expr.value? А берется оно отсюда:
expr returns[int value]
: me1=multExpression {$value = me1;}
('+' me2=multExpression {$value += $me2.value;}
|'-' me2=multExpression {$value -= $me2.value;})*
;
Здесь тоже ничего сложного. Мы говорим ANTLR, что правило expr возвращает значение с именем value, имеющее тип int. Обратите внимание, что в обеих записях "$expr.value" и «returns[int value]» value фигурирует не случайно. Если мы напишем:
expr returns[int tratata] ... ;
а потом обратимся к $expr.value, то ANTLR выдаст ошибку.
Я допустил некоторую вольность речи, сказав, что «правило возвращает значение», однако коротко сказать по-другому, не потеряв смысла, достаточно трудно на мой взгляд.
Еще одна тонкость. Рассмотрим правило statement, например, первую альтернативу. В коде, соответствующем данной альтернативе, мы обращаемся к правилу expr напрямую ($expr.value). Но в правиле statement так не получится, потому что в нем присутствуют сразу два правила multExpression, то есть, чтобы их различать нужно дать им имена. В данном случае это me1 и me2. Вроде бы все тонкости
обсудили, теперь ближе к сути.
В правиле expr две альтернативы записаны в одну через символ '|'. Это наглядно видно в части 2 данного топика. Напомню, что expr это предложения вида multExpression-multExpression+multExpression-multExpression-multExpression+multExpression. Теперь посмотрим на код в фигурных скобках и увидим, что сначала возвращаемому значению value присваивается значение первого слагаемого, а затем в зависимости от операции прибавляются или вычитаются значения последующих слагаемых. Аналогично выглядит правило
multExpression:
multExpression returns[int value]
: a1=atom {$value = $a1.value;}
('*' a2=atom {$value *= $a2.value;}
|'/' a2=atom {$value /= $a2.value;})*
;
Осталось последнее правило парсера atom. С ним проблем возникнуть не должно:
atom returns[int value]
: ID {$value = (int)memory[$ID.text];}
| INT {$value = int.Parse($INT.text);}
| '(' expr ')' {$value = $expr.value;}
;
Если atom это идентификатор (ID), то возвращаем его значение, взятое из memory. Если atom — целое число, то просто возвращаем число, полученное из его строкового представления. Ну и наконец, если atom это выражение в скобках, то просто возвращаем значение выражения.
Осталось сгенерировать парсер и лексер с помощью .bat-файла. Даже код функции Main() не придется менять. Запускаем наш калькулятор и играемся.
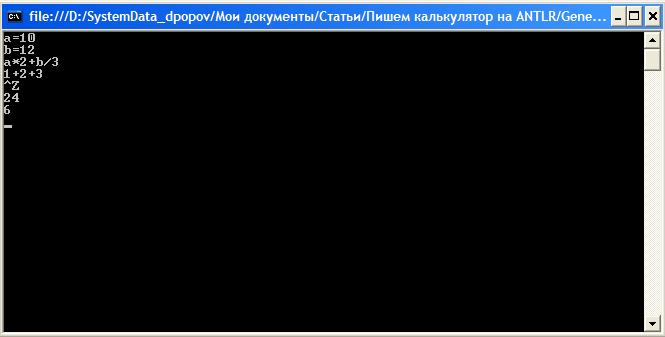
Интересно то, что сгенерированный парсер умеет сообщать о синтаксических ошибках и более того восстанавливаться после них. Чтобы это увидеть попробуйте набрать какое-нибудь выражение, например, с пробелами (мы ведь не сделали обработку пробелов, табуляций и прочего):

Парсер, обнаружил ошибки, но тем не менее правильно вычислил результат. Можно даже написать что-то типа «2++3» и получить 5.
5. Заключение
Пришло время подвести небольшой итог. То решение, которое у нас получилось, как мне кажется, полностью соответствует поставленной задаче. Программа выражения считывает? Да. Результат вычисляет? Да. На этом, пожалуй, можно и закончить. Я очень надеюсь, уважаемый хаброчеловек, что этот топик пришелся тебе по душе и ты хочешь узнать, как с помощью ANTLR по грамматике строить деревья разбора и с помощью того же ANTLR их обходить. Если у тебя есть мечта написать свой собственный язык программирования, то с ANTLR она стала намного ближе к осуществлению!
6. Рекоммендуется к прочтению
- Definite ANTLR Reference, Terence Parr, 2007.
ISBN-10: 0-9787392-5-6, ISBN-13: 978-09787392-4-9 - Language Implementation Patterns, Terence Parr, 2010.
ISBN-10: 1-934356-45-X, ISBN-13: 978-1-934356-45-6
