Здравствуйте, уважаемые читатели. Хочу представить вашему вниманию описание алгоритма компрессии данных SwingingDoor и рассказать о том, как мы его применяем.
По роду деятельности я занимаюсь разработкой решений в области промышленной автоматизации, а более конкретно — разработкой информационных систем производства. Их назначение — предоставлять информацию для людей и других систем. Они предоставляют оперативные, самые последние данные, а также данные за прошлое. Данные поступают из многочисленных систем контроля (СК), количество параметров измеряется десятками тысяч.
Зачем использовать компрессию, почему бы не хранить все данные?
Причины достаточно очевидны:
Конечно, сейчас доступны жесткие диски с большим объемом памяти и каналы связи становятся все лучше и лучше, но, будем реалистами, эти вопросы нельзя не рассматривать. К тому же, как будет сказано ниже, хранение всего объема данных не всегда имеет смысл.
Кстати, вместо компрессии можно использовать прореженные данные (среднее значение параметра за период), но эти значения уже будут отличаться от «сырых» данных, полученных из систем контроля. Усредненные данные будут сглаживать мгновенные максимальные и минимальные значения параметров. Для части задач это допустимо, а для части нет.
Одной из задач нашей системы является консолидация данных из различных СК предприятия в единую базу данных.
Некоторые СК, например телемеханика, предоставляют данные каждую секунду, при этом сами данные могут изменяться не значительно.
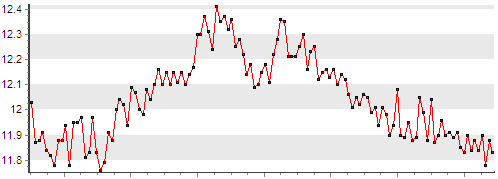
Например, если взглянуть на график, приведенный ниже, то мы увидим, что значения параметра «Суммарная генерация по ТЭЦ» изменяются в пределах от 11,5 до 12,5 МВт, при этом в большинстве случаев соседние значения отличаются друг от друга менее чем на 0.1, а общая динамика изменений имеет некоторую закономерность.
Для того чтобы не хранить «лишние» данные, часть отсчетов мы можем пропускать. Компрессия как раз и заключается в выборке «нужных» данных из входного потока.
Общие требования к компрессии:
• прореженные данные не должны изменять общее представление о течении процесса;
• все локальные экстремумы графика с определенной точностью должны присутствовать в прореженных данных — другими словами, если произошел резкий скачек значения параметра, то алгоритм должен это зафиксировать.
Эти критерии можно сформулировать более строго. Например (и этот критерий будет использоваться в следующем алгоритме), метод прореживания должен гарантировать, что если мы сохранили две точки и пропустили несколько точек между ними, то прямая, соединяющая сохраненные точки будет отстоять от этих точек не более, чем на заданную погрешность.
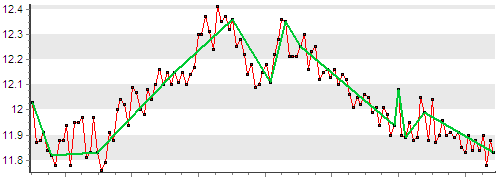
Ниже на графике зеленой линей показаны точки, которые останутся после применения компрессии.
Также есть еще одно требование к алгоритмам компрессии. Поскольку они обрабатывают большое количество данных, то они должны работать быстро. В идеале (и это реализовано в следующем алгоритме), они должны работать с потоком данных и, не возвращаясь к ранее полученным точкам, принимать решение по архивации последней рассмотренной точки.
Для компрессии данных мы используем алгоритм SwingingDoor. Алгоритм был запатентован в США в мае 1987 года. Основная область применения алгоритма — системы АСУТП и информационные системы производства.
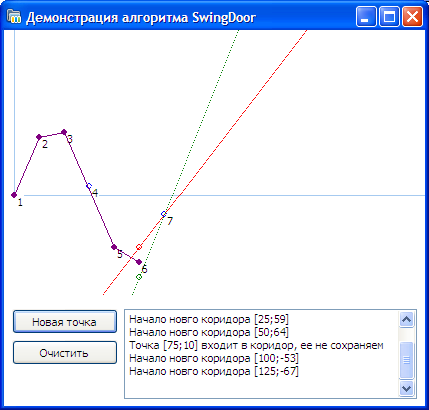
Алгоритм носит название «Вращающаяся дверь». В названии алгоритма отражен принцип работы.
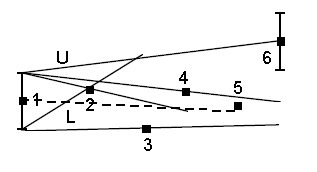
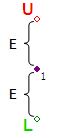
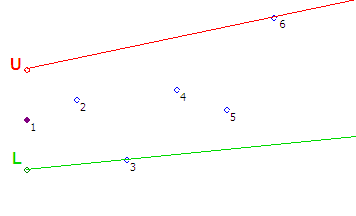
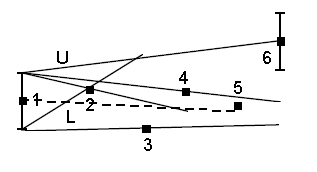
Шаг #1 — Получаем первую точку. На расстоянии равном погрешности E откладываем по вертикали две опорные точки L и U.
Шаг #2 — Получаем вторую точку. Через опорные точки L, U и полученную точку проводим лучи. Лучи образуют двери коридора.
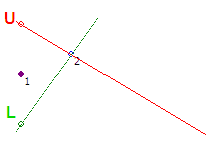
Шаг #3 — Точка 3 не входит в коридор, построенный на втором шаге. Вращаем луч L по часовой стрелке до точки 3
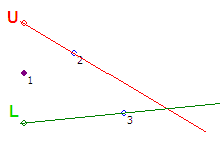
Шаг #4 — Точка 4 не входит в коридор, построенный на предыдущем шаге. Вращаем луч U против часовой стрелке до точки 4
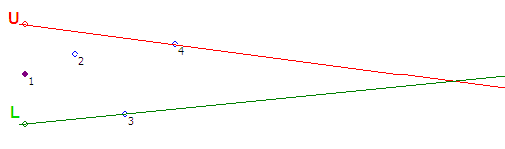
Шаг #5 — Точка 5 входит в коридор, ничего не делаем
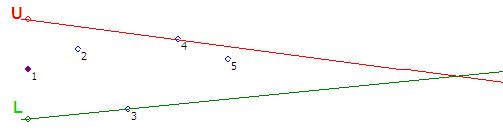
Шаг #6 — Точка 6 не входит в коридор. Начинаем вращать луч U против часовой стрелки до пересечения с точкой 6 и обнаруживаем, что двери коридора открылись
Шаг #7 — Открываем новый коридор, начиная с точки 5. Точки 1 и 5 сохраняем
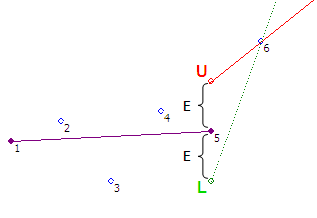
Итого из 5 первых точек сохранены будут только две. В примере 3 точки для нас оказались «лишними», что позволило нам отсечь 60% входных данных.
В спецификации алгоритма предлагается начинать новый коридор с точки расположенной между точками 5 и 6 и отстоящей от луча U на E / 2. Но в нашем проекте мы поступаем иначе — новый коридор начинаем строить с последней точки, которая входит в коридор, т.е. с точки 5, поскольку при таком поведении мы гарантируем, что все прореженные данные будут иметь временную метку и значение, полученное из системы контроля.
Использование компрессии данных позволило нам:
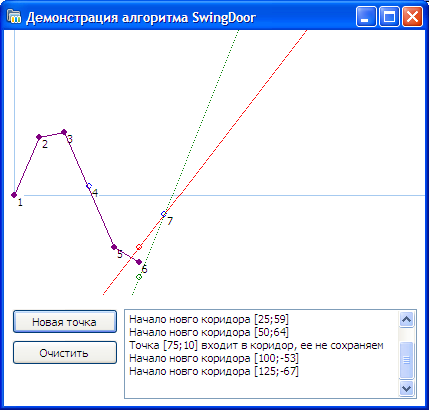
Перед тем как реализовать алгоритм мы написали приложение, моделирующее работу алгоритма. Здесь вы можете скачать исходный код(Delphi) демо-приложения.
US-Patent-4669097 — Data compression for display and storage
По роду деятельности я занимаюсь разработкой решений в области промышленной автоматизации, а более конкретно — разработкой информационных систем производства. Их назначение — предоставлять информацию для людей и других систем. Они предоставляют оперативные, самые последние данные, а также данные за прошлое. Данные поступают из многочисленных систем контроля (СК), количество параметров измеряется десятками тысяч.
Зачем использовать компрессию, почему бы не хранить все данные?
Компрессия данных
Причины достаточно очевидны:
- для сокращения дискового пространства для хранения данных;
- для сокращения нагрузки каналов передачи данных.
Конечно, сейчас доступны жесткие диски с большим объемом памяти и каналы связи становятся все лучше и лучше, но, будем реалистами, эти вопросы нельзя не рассматривать. К тому же, как будет сказано ниже, хранение всего объема данных не всегда имеет смысл.
Кстати, вместо компрессии можно использовать прореженные данные (среднее значение параметра за период), но эти значения уже будут отличаться от «сырых» данных, полученных из систем контроля. Усредненные данные будут сглаживать мгновенные максимальные и минимальные значения параметров. Для части задач это допустимо, а для части нет.
Как мы используем компрессию данных
Одной из задач нашей системы является консолидация данных из различных СК предприятия в единую базу данных.
Некоторые СК, например телемеханика, предоставляют данные каждую секунду, при этом сами данные могут изменяться не значительно.
Например, если взглянуть на график, приведенный ниже, то мы увидим, что значения параметра «Суммарная генерация по ТЭЦ» изменяются в пределах от 11,5 до 12,5 МВт, при этом в большинстве случаев соседние значения отличаются друг от друга менее чем на 0.1, а общая динамика изменений имеет некоторую закономерность.
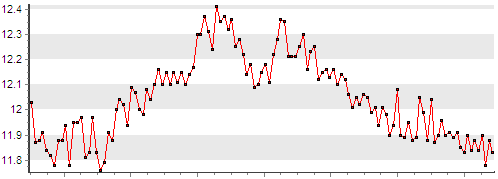
Для того чтобы не хранить «лишние» данные, часть отсчетов мы можем пропускать. Компрессия как раз и заключается в выборке «нужных» данных из входного потока.
Общие требования к компрессии:
• прореженные данные не должны изменять общее представление о течении процесса;
• все локальные экстремумы графика с определенной точностью должны присутствовать в прореженных данных — другими словами, если произошел резкий скачек значения параметра, то алгоритм должен это зафиксировать.
Эти критерии можно сформулировать более строго. Например (и этот критерий будет использоваться в следующем алгоритме), метод прореживания должен гарантировать, что если мы сохранили две точки и пропустили несколько точек между ними, то прямая, соединяющая сохраненные точки будет отстоять от этих точек не более, чем на заданную погрешность.
Ниже на графике зеленой линей показаны точки, которые останутся после применения компрессии.
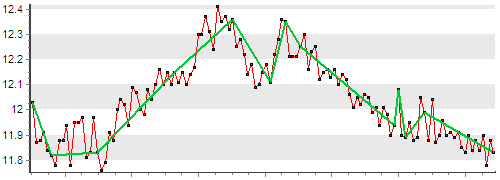
Также есть еще одно требование к алгоритмам компрессии. Поскольку они обрабатывают большое количество данных, то они должны работать быстро. В идеале (и это реализовано в следующем алгоритме), они должны работать с потоком данных и, не возвращаясь к ранее полученным точкам, принимать решение по архивации последней рассмотренной точки.
Алгоритм SwingingDoor
Для компрессии данных мы используем алгоритм SwingingDoor. Алгоритм был запатентован в США в мае 1987 года. Основная область применения алгоритма — системы АСУТП и информационные системы производства.
Принцип работы
Алгоритм носит название «Вращающаяся дверь». В названии алгоритма отражен принцип работы.
Шаг #1 — Получаем первую точку. На расстоянии равном погрешности E откладываем по вертикали две опорные точки L и U.
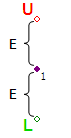
Шаг #2 — Получаем вторую точку. Через опорные точки L, U и полученную точку проводим лучи. Лучи образуют двери коридора.

Шаг #3 — Точка 3 не входит в коридор, построенный на втором шаге. Вращаем луч L по часовой стрелке до точки 3

Шаг #4 — Точка 4 не входит в коридор, построенный на предыдущем шаге. Вращаем луч U против часовой стрелке до точки 4

Шаг #5 — Точка 5 входит в коридор, ничего не делаем
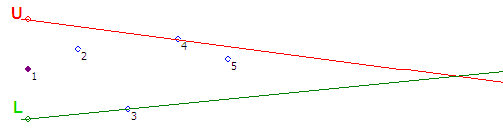
Шаг #6 — Точка 6 не входит в коридор. Начинаем вращать луч U против часовой стрелки до пересечения с точкой 6 и обнаруживаем, что двери коридора открылись

Шаг #7 — Открываем новый коридор, начиная с точки 5. Точки 1 и 5 сохраняем

Итого из 5 первых точек сохранены будут только две. В примере 3 точки для нас оказались «лишними», что позволило нам отсечь 60% входных данных.
В спецификации алгоритма предлагается начинать новый коридор с точки расположенной между точками 5 и 6 и отстоящей от луча U на E / 2. Но в нашем проекте мы поступаем иначе — новый коридор начинаем строить с последней точки, которая входит в коридор, т.е. с точки 5, поскольку при таком поведении мы гарантируем, что все прореженные данные будут иметь временную метку и значение, полученное из системы контроля.
Настройка алгоритма
- Погрешность E — задает максимально возможное отклонение точек коридора от результирующей линии (по оси Y). На картинке выше эта линия между точками 1 и 5. Погрешность необходимо задавать для каждого параметра отдельно, исходя из его смысла. Например, скачки генерации на с 10 на 10,2 МВт является допустимым, но скачек частоты на с 50 на 50,2 Гц является серьезным нарушением. Поэтому для генерации погрешность можно задать, например, равной 0,1, а для частоты — 0,01.
- Время жизни коридора — время, в течение которого должна быть сохранена хотя бы одна точка. Возможны варианты течения процесса, когда данные могут изменяться не значительно (температура воздуха в морозную зимнюю ночь). В таком случае они будут попадать в текущий коридор допустимых значений и алгоритм не будет принимать решение об их сохранении. Чтобы избежать таких случаев вводится соответствующий параметр, который отвечает за то, как долго данные в рамках одного коридора могут не сохраняться. Например, для данных с частотой обновления 1 секунда можно указать этот параметр равный 30 секундам, тем самым обеспечив хотя бы одно значение в прореженном графике за 30 секунд.
Заключение
Использование компрессии данных позволило нам:
- предоставлять сотрудникам предприятия «сырые» тренды параметров, которые были получены из СК месяцы назад;
- снизить объем дискового пространства хранения данных;
- снизить нагрузку каналов передачи данных;
- оптимизировать службы сбора данных из СК предприятия, тем самым снизив загрузку CPU серверов, на которых установлены службы сбора данных.
Демонстрационное приложение
Перед тем как реализовать алгоритм мы написали приложение, моделирующее работу алгоритма. Здесь вы можете скачать исходный код(Delphi) демо-приложения.
Материалы
US-Patent-4669097 — Data compression for display and storage
