 Последнее время, в области баз данных, внимание сконцентрировано на интенсивно развивающихся NoSQL решениях. Складывается обманчивое впечатление, что в секторе реляционных СУБД затишье: основные продукты давно известны, все ниши заняты. Казалось бы, новому игроку сюда так просто не попасть. Только если речь идёт не о проекте с пятнадцатилетней историей, не о развитой объектно-реляционной СУБД с открытым кодом, оптимизированной для использования в веб-приложениях, не о системе, которая имеет поддержку хранимых процедур, партиционирование, опции высокой доступности, репликацию и распределённые транзакции. Имя этой «тёмной лошадки» — CUBRID. И, судя по заявлениям создателей, она претендует на лавры MySQL.
Последнее время, в области баз данных, внимание сконцентрировано на интенсивно развивающихся NoSQL решениях. Складывается обманчивое впечатление, что в секторе реляционных СУБД затишье: основные продукты давно известны, все ниши заняты. Казалось бы, новому игроку сюда так просто не попасть. Только если речь идёт не о проекте с пятнадцатилетней историей, не о развитой объектно-реляционной СУБД с открытым кодом, оптимизированной для использования в веб-приложениях, не о системе, которая имеет поддержку хранимых процедур, партиционирование, опции высокой доступности, репликацию и распределённые транзакции. Имя этой «тёмной лошадки» — CUBRID. И, судя по заявлениям создателей, она претендует на лавры MySQL.Лошадку «прятали» в Южной Корее, где она обрела популярность и начала использоваться в проектах госструктур и таких гигантов, как корпорации NHN. В конце 2008 года были открыты исходные коды, но международное лицо проект обрёл (с запуском официального сайта и публикацией на sourceforge) лишь в конце 2009.
С MySQL эту СУБД роднит только сфера применения, они не имеют общей кодовой базы и различаются использованными подходами начиная с идей и заканчивая API. Высокая производительность для веб-приложений заложена в трёхзвенной архитектуре CUBRID.
- Серверная подсистема представлена как набор процессов, каждый из которых решает узкий набор задач:
- распределение свободного пространства
- логгирование
- управление блокировками
- управление транзакциями
- обработка объектов и запросов
- Клиентская подсистема включает API для C, PHP, Python и Ruby, а также поддержку JDBC, ODBC и OLEDB и берёт на себя
- парсинг и оптимизацию запросов
- кэширование объектов и блокировок
- управление объектами, транзакциями и триггерами
- Промежуточная подсистема (Broker) реализует
- очередь задач
- пул соединений
- мониторинг
- логгирование
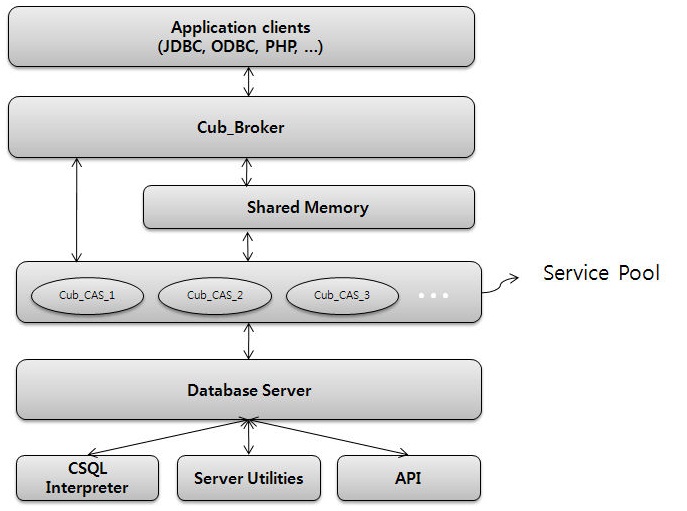
Архитектура CUBRID ориентирована на масштабирование звеньев-брокеров, которые берут на себя задачи оптимизации запросов и пулинга соединений, разгружая сервер БД, а также повышают безопасность системы за счёт изолирования обработки запросов. Кроме того, 7 июня 2010 стартовал проект по кластеризации самой БД (к концу года запланирован выпуск стабильной версии).
Также, данная СУБД обладает рядом уникальных возможностей, актуальных именно для веб-приложений. Приведу пример. Представьте что ваша БД используется для хранения большого количества статей. Есть пользователи, которые их просматривают. Рассмотрим общепринятую последовательностью действий при запросе статьи на просмотр:
SELECT header, text FROM articles WHERE article_id = :requested_id;
UPDATE articles SET read_count = read_count + 1 WHERE article_id = :requested_id;А теперь вспомните что случается под высокой нагрузкой. Верно, блокировки из-за апдейтов будут значительно снижать производительность. В CUBRID эта проблема решается так:
SELECT header, text, INCR(read_count) FROM articles WHERE article_id = :requested_id;Блокировка при этом не создаётся. Ещё одно оригинальное расширение — директива DO, которая указывает БД не возвращать никаких результатов запроса, будь то вывод функции, выборка или сообщение об ошибке. В качестве подтверждения эффективности этих решений на сайте приведены результаты тестирования производительности. Не смотря на то, что имена конкурентов скрыты, можно легко догадаться кто есть кто.
СУБД написана на C и C++, интерфейс администрирования — на Java, поддерживаются ОС Linux и Windows. Уже реализована поддержка SQL-92, JDBC, ODBC и OLEDB.
CUBRID использует объектно-реляционный подход к хранению данных. Поэтому, в ней нет столбцов — есть атрибуты, нет таблиц — есть классы, нет строк — есть экземпляры классов, нет типов данных — есть домены, нет процедур — есть методы. Это позволяет вместо генерации DDL под имеющуюся структуру классов, просто взять скомпилированный jar-файл, загрузить его в БД:
loadjava db_name MyClass.classcsql> create function Sample() return string as language java name 'MyClass.Sample() return java.lang.String';
csql> ;xrunА вот так, при использовании объектного подхода, изменяются атрибуты:
CUBRIDResultSet rs = (CUBRIDResultSet) stmt.executeQuery("select object_name from object_name");
rs.next();
CUBRIDOID oid = rs.getOID(1);
oid.addToSet("set_name", new Integer(10));
oid.addToSequence("list_name", 1, new Integer(30));
oid.putIntoSequence("list_name", 99, new Integer(99));
oid.removeFromSet("set_name", new Integer(1));
oid.removeFromSequence("list_name", 1);
con.commit();
rs.close();Для Java-разработчиков есть поддержка Eclipse через QuantumDB и драйвер для Hibernate, хотя, после примеров выше, он вряд ли пригодится.
Кроме всех перечисленных отличий, CUBRID обладает неплохим инструментарием для администрирования, хорошей реализацией высокой доступности (failover, обновление СУБД и ОС без простоя), резервного копирования (горячие бэкапы, компрессия). Готовы и инструменты для миграции: Scriptella и Apache DdlUtils. В качестве хранилища CUBRID уже могут использовать MediaWiki, phpBB, Wordpress и несколько проектов поменьше.
К минусам относятся: пока что, небольшое сообщество разработчиков и пользователей, отсутствие поддержки Solaris, Mac OS X и FreeBSD, а также некоторые особенности диалекта SQL, хотя документация и видео-уроки снимают почти все вопросы.
Удивляет, что информация по этой теме в рунете практически отсутствует, кроме пары упоминаний в сообществе Ruby и перевода англоязычной статьи в википедии, где ошибочно (пруф) указано, что БД разрабатывается с 2006 года. Думаю, что этот обзор даст читателям пищу для размышлений.
