
Современные протоколы прикладного уровня используют для ускорения передачи данных мультиплексирование, которое повышает требования к надёжности канала. На конференции YaTalks Александр Грянко phasma рассказал, как мы ускоряем загрузку страниц на каналах с большими потерями пакетов на примере протоколов HTTP/2 и TCP BBR.
— Привет. Я Саша, работаю в Яндексе, в последние три года занимаюсь разработкой L7-балансировщика нагрузки. Расскажу о быстром и простом способе ускорения сети. Мы начнем с седьмого уровня, HTTP, и опустимся к четвертому уровню, TCP. Сегодня мы поговорим только об этих двух уровнях и остановимся на них довольно подробно.
В последние восемь лет я занимаюсь больше бэкенд-разработкой, и, скорее всего, мои знания остались на уровне AngularJS первых версий. Вы, скорее всего, лучше меня знаете, как это все работает. Вы всё уже оптимизировали, всё сжали, и здесь я вам ничего посоветовать не смогу.
Но я могу вам посоветовать, как ускорить вашу сеть с помощью оптимизации самого сервера, самой операционной системы.

Чтобы что-то ускорить, нужны метрики. В данном случае мы использовали следующие: среднее время до первого байта показывает нам, как быстро работает уровень TCP, а вторая метрика — время получения HTML от первого байта. Мы произвели эксперименты, замерили наши метрики, и после включения BBR наше ускорение составило приблизительно десять процентов.
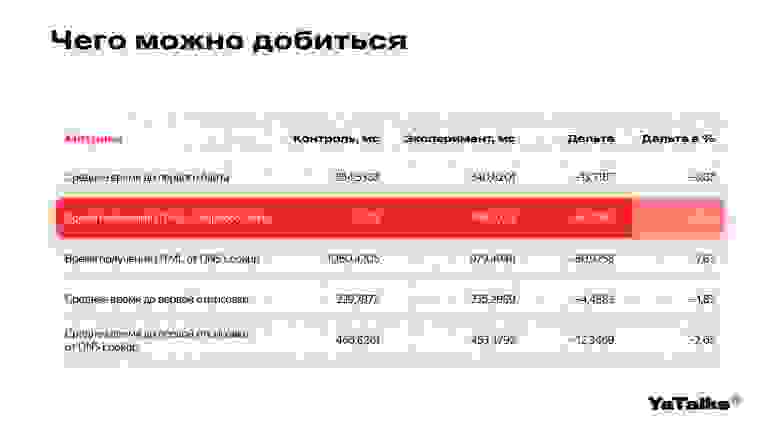
Чтобы понимать, что такое десять процентов, мы обратимся к абсолютному значению, которое составляет 66 миллисекунд. Если вы зайдете в свою любимую многопользовательскую онлайн-игру, то Ping до западноевропейских серверов будет составлять приблизительно 60-70 миллисекунд.
Все наши сервера управляются с помощью протоколов удаленного управления, в данном случае SSH. Если вы еще не сталкивались с протоколом SSH, то можете попросить вашего системного администратора настроить ваш сервер. Я расскажу, как его убедить это сделать.

Что же такое BBR? Это один из алгоритмов, который позволяет нам управлять тем, как пакеты уходят в сеть. И конфигурируется он следующими двумя параметрами. Первое — выставление планировщика пакетов в FQ, далее я расскажу, почему стоит использовать FQ. Второе — включение самого congestion control, то есть самого BBR.
Кажется, что на этом мы могли бы закончить. Но на самом деле существует много подводных камней, и, скорее всего, ваш системный администратор просто так не включит BBR на сервере. Поэтому мы пойдем дальше.
Мы начнем с седьмого уровня, то есть с HTTP, и потихоньку пойдем вниз, рассматривая наши протоколы.

Начнем мы с наших браузеров, с которыми мы каждый день взаимодействуем. Мы видим консоль веб-разработчика. В консоли есть интересное для нас поле — protocol.
В нашем случае указаны протоколы HTTP/1 и HTTP/2. Также существует протокол HTTP/3, который основан на протоколе QUIC от компании Google. Но сегодня мы к нему не будем возвращаться, так как он находится в стадии разработки, еще не утвержден до конца. Вернемся к HTTP/1.

На слайде мы видим утилиту Wireshark, которая позволяет анализировать наши пакеты, то, как мы взаимодействуем с сетью. Видим, что одно поле подсвечено зеленым цветом. Это как раз наш HTTP-запрос. Внизу мы можем видеть байтики, как они будут представлены в сети.

Как же выглядит HTTP/1 в жизни? Это достаточно простой протокол. Он полностью текстовый, то есть мы просто пишем текст и отправляем его в сеть. Наши символы кодируются специальными шестнадцатеричными значениями. Справа таблица ASCII, небольшой кусочек, чтобы можно было ориентироваться.
Мы имеем первую часть в виде заголовков, которая отделена символами “\r\n\r\n” от нашего тела. Мы здесь просто запрашиваем обычный ресурс методом GET, поэтому тела у этого запроса не будет. И мы видим, что байтики приблизительно похожи на то, что есть в ASCII-таблице. Мы запрашиваем какую-то JS-ку, какой-то ресурс. Также есть заголовок Host, указывающий домен, с которым мы сейчас работаем. И — какой-то дополнительный набор заголовков. Они могут быть кастомными, можно использовать любые.

HTTP/2 — более сложный протокол. Он является бинарным, и наименьшей единицей обмена информации являются фреймы. Существует большое количество специальных случаев, специальных типов этих фреймов. На слайде вы видите, что они подсвечены.

Также мы можем наблюдать в первой строчке, что в один пакет могут поместиться сразу два фрейма. Мы не будем подробно останавливаться на том, какие фреймы существуют, их достаточно много. В данном случае нам будет интересен фрейм headers, потому как раз позволяет запрашивать ресурсы. Я немного участвовал в разработке Wireshark, помогал его улучшать в этом поле.
Мы видим, что есть get-запрос. Видим, что в середине есть текстовое представление этого get-запроса. Но в правой колонке видим только один выделенный байт, и он как раз будет являться этим методом get. Далее я расскажу, почему так происходит.
Дальше у нас есть заголовок path, который указывает путь до ресурса, до нашей JS-ки, которую мы будем запрашивать. И есть набор каких-то дополнительных заголовков, которые также будут присутствовать в нашем запросе.
Так почему же наши байты в сети не совпадают с тем, как это все рисуется на нашей картинке? Дело в том, что Wireshark показывает нам конечный результат, как он это все расшифровал. А в сети эти байты, эти заголовки, будут сжаты специальным форматом HPACK. Более подробно лучше ознакомиться в интернете. Поищите информацию, она хорошо документирована.
Вернемся к нашим байтикам. Есть специальное поле — идентификатор контента. Оно указывает, с каким ресурсом данные фреймы работают в текущий момент. В данном случае первый фрейм мы отправили, получили данные. Когда сервер будет нам отдавать сами байтики содержимого, уже будет использоваться фрейм data.

Наши протоколы HTTP/1 и HTTP/2 сильно отличаются. Мы уже поговорили о том, что HTTP/1 является текстовым протоколом, а HTTP/2 — бинарным, то есть работает с помощью фреймов.
HTTP/1 в случае запроса в виде одного соединения вернет неизвестно какой результат, в зависимости от реализации того, как это написали разработчики веб-сервера. То есть если мы сделаем два запроса в одно соединение, скорее всего, вернется либо ответ на первый, либо на второй запрос. Для этого, чтобы загружать ресурсы параллельно, браузер устанавливает несколько соединений, обычно их около шести, и параллельно загружает ресурсы.
HTTP/2, в свою очередь, использует одно соединение. То есть он задает соединение, и внутри него через фреймы подгружает все нужные данные. Эта техника упаковки нескольких ресурсов в одно соединение называется мультиплексированием.
Из того, как работают наши соединения, понятно: в случае потери пакета в одном из соединений HTTP/1 отработает лучше. Скорее всего, мы не затронем другие соединения, они продолжат грузиться с той же скоростью. А в случае HTTP/2, если наш пакет теряется, загрузка всех ресурсов начинает замедляться.
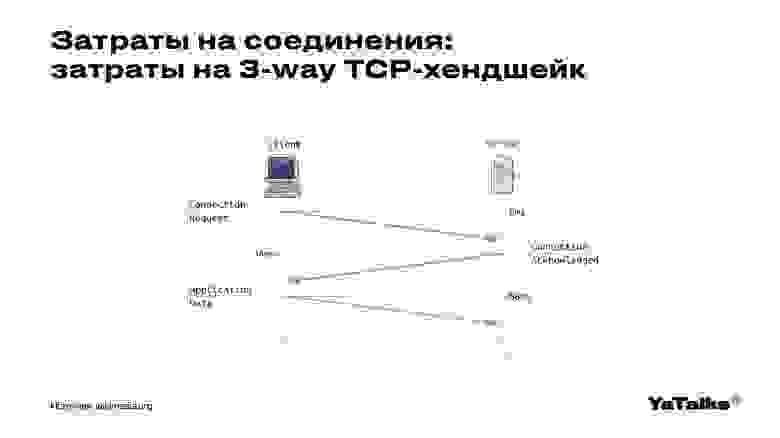
Кажется, что HTTP/2 хуже, он же чувствителен к потере пакетов. На самом деле, когда мы создаем каждое из этих шести соединений, мы производим следующую операцию.
Клиент и сервер как бы устанавливают надежное соединение, TCP-соединение. Мы отправляем от клиента два пакета серверу, и один пакет отправляется со стороны сервера клиенту. Тем самым мы как бы говорим, что готовы передавать данные. Это, конечно, создает накладные ресурсы, мы это можем делать достаточно долго.

Также существует шифрование. Если вы сейчас посмотрите на ваш браузер, скорее всего, увидите иконочку с замочком. Многие ее называют SSL, но на самом деле это не SSL. Это TLS. SSL уже давно устарел, уже практически не поддерживается, и стоит от него отказаться.
У TLS тоже есть обмен пакетов. То есть мы так же, как и в случае TCP-хендшейка, устанавливаем определенное состояние, после которого можем продолжать работать. В этом месте мы тоже можем заниматься оптимизацией, но браузеры пока не поддерживают те вещи, которые мы уже включили со стороны сервера. Будем ожидать, когда все это включат.

Когда-то давно в HTTP/1 пытались решить проблему параллельной загрузки ресурсов. В RFC это есть. И когда-то давно все-таки реализовали pipelining. Из-за сложности в реализации Internet Explorer его не поддерживает, а Firefox и Chrome поддерживают, но поддержка была со временем отключена.

Каждое наше соединение из шести, которые мы уже создали, на самом деле, не будет закрываться. То есть они продолжат работать так же, как и раньше. Для этого используется техника типа Keep-Alive. То есть мы создаем надежное соединение до конкретного сервера и продолжаем работать.
На уровне HTTP это контролируется заголовком. В данном случае это connection. А на уровне TCP мы уже будем использовать саму операционную систему, она за нас решит, как ей поступить.
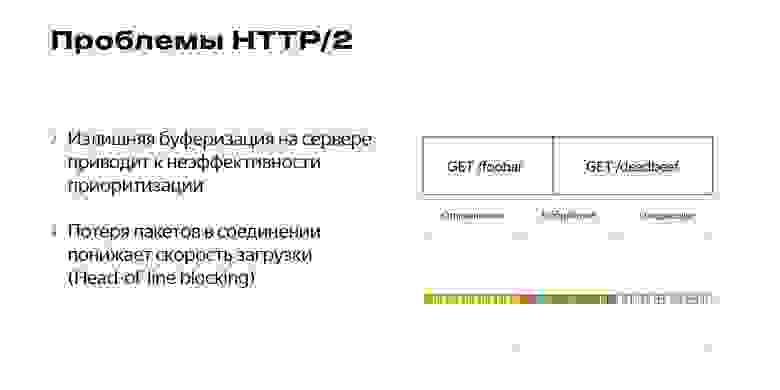
Существуют и другие проблемы с HTTP/2. В HTTP/2 мы можем приоритизировать пакеты и отправлять более нужные данные быстрее. В данном случае, когда мы пытаемся отправить очень много данных за один раз, буфер на сервере может переполниться. Тогда более приоритетные пакеты просто затормозятся, встанут в конец очереди.
Наблюдается потеря пакетов. Они тормозят нашу загрузку, и такая блокировка называется Head-of-line blocking.
Теперь мы поговорим о TCP, то есть о нашем четвертом уровне. За следующие десять минут я расскажу, как работает TCP.
Когда мы в гостях, то просим кого-то передать соль. Когда человек нам передает соль, мы подтверждаем, что соль до нас дошла. В данном случае мы также берем какой-то сегмент, передаем его, ждем подтверждения. Опять передаем. И если произошла потеря, то мы пересылаем этот сегмент и в итоге он у нас доставляется. Такая техника отправки одного сегмента называется Stop and wait.
Но наши сети за последние 30 лет очень сильно ускорились. Возможно, кто-то из вас помнит диалап, интернет по мегабайтам. Сейчас вы, возможно, уже можете подключить домой гигабитный интернет.
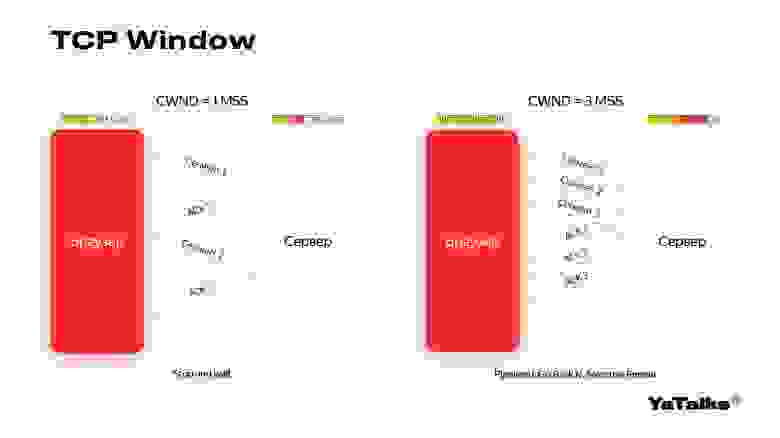
Также мы можем в этом случае начать отправлять сразу по несколько пакетов. В нашем примере их три. Мы отправляем окно в виде трех пакетов и ждем, когда они все подтвердятся.
В случае потери пакета мы можем начать переотправлять все пакеты, начиная с первой нашей потери. Эта техника называется Go-Back N. А в другой ситуации мы можем начать отслеживать все пакеты и пересылать только те, которые были потеряны. Такая техника называется Selective Repeat. Она более дорогая со стороны сервера. Когда мы готовили слайды, ушло много времени на то, чтобы понять, как ее представить. Я сам в ней запутался, и поэтому придумал такую аналогию.
Есть всем нам известные трубы, через которые идет вода. Трубы имеют разный диаметр, где-то они могут быть тоньше, и в данном случае самое узкое место будет как раз с нашей максимальной пропускной способностью. Мы не сможем налить больше воды, чем позволяет это узкое место.

Мы попробуем стрелять шариками слева направо. С правой стороны нам будут подтверждать, что шарики долетели. Мы начинаем слать поток шариков. Посмотрим на его срез. Вот шарики летят в одну сторону, подтверждаются, и количество наших шариков экспоненциально растет. В какой-то момент объем шариков становится настолько большим, что они замедляются и начинаются потери. После потери мы немножко замедляемся, уменьшаем наше окно в два раза. Затем мы пытаемся понять, что с нами произошло. Первая стадия называется TCP Slow Start.
Когда мы схлопнули окно в два раза, мы можем восстановить соединение и попросить ребят переслать нам наши шарики заново. Они кричат нам, что надо переслать шарики, мы им отвечаем — вот ваши шарики. Такая фаза называется Fast Recovery и Fast Retransmit.
Когда мы поняли, что у нас все хорошо, мы начинаем постепенно наращивать количество отправляемых шариков, начиная с того схлопнутого окна. Такая фаза называется Congestion Avoidance. То есть мы пытаемся избежать потерь наших пакетов.
Фаза схлопывания нашего окна в два раза называется Multiplicative decrease. А медленная фаза наращивания количества шариков называется Additive Increase.
Когда наш Congestion Avoidance опять потеряет пакеты, мы можем произвести следующую стадию. Но в данный момент нас больше интересует само изображение этого графика. Мы видим такую пилу, и эта пила нам еще несколько раз пригодится. Запомните, как она выглядит.
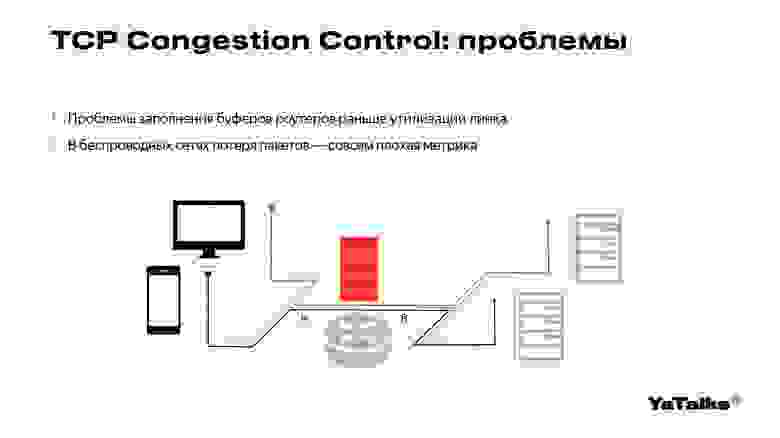
Мы вернемся к проблемам обычных TCP-протоколов. По аналогии с трубой мы наливаем пакеты. Так как в интернете кроме нас существуют еще другие пользователи, они тоже начинают наливать пакеты в трубу. В какой-то момент буферы наших роутеров могут переполниться и создать нам проблемы отправки пакетов.
Также существует проблема с потерей пакетов в беспроводных сетях. Скорее всего, в вашем ноутбуке нет Ethernet-порта и вы смотрите доклад через Wi-Fi. Потери пакетов в Wi-Fi и в мобильных сетях возникают не по причине самого маршрутизирующего устройства, а по причине радиопомех. Такая метрика будет нам не очень полезна.
Тут мы подошли к BBR. Он расшифровывается как Bottleneck Bandwidth and Round Trip Time, это метрики ширины канала, когда мы не забиваем наш канал полностью, и времени путешествия пакета от нас к серверу и обратно.
Когда мы отправляем данные, то идеальное состояние, при котором пакеты находятся в стабильном состоянии, летят и еще не были подтверждены, называется Bandwidth-delay product. BDP мы можем увеличивать за счет использования буферов сетевых устройств. Когда этот буфер превышается, начинаются потери.
И обычные TCP-алгоритмы как раз работают с правой стороны графика, то есть там, где происходят потери — мы наливаем так много пакетов, что потери неизбужны. Пакеты замедляются, и мы начинаем схлопывать окно.
BBR, в свою очередь, работает по другому принципу, близкому к нашей трубе. Мы просто наливаем то количество пакетов, которое можем пропустить. В фазе старта, то есть в самом начале, мы наливаем пакеты до тех пор, пока не начнутся заторы.
И иногда возможны потери пакетов. Но BBR пытается избежать этого момента. Когда мы заполнили нашу трубу, мы начинаем откатываться. Эта фаза называется drain.
Мы возвращаемся к нашему стабильному соединению, где будет полностью заполнена, но при этом мы не будем использовать дополнительные буферы, дополнительные резервуары. Из этого положения BBR продолжает работать.
Периодически мы будем смотреть на то, что происходит с нашей сетью. Мы отслеживаем практически каждый пакет, который к нам возвращается. Когда к нам вернулись пакеты, мы начинаем пробовать немножко ускорять количество пакетов, ускорять сами пакеты, отправляя их в сеть.
И если у нас не происходит никаких проблем, мы можем остаться на этом значении. То есть продолжить работать с тем темпом, который нам комфортен. Если же все-таки произошли потери, мы можем откатиться назад.
Когда мы получили подтверждение, увидели, что скорость улучшилась, мы можем немножко подождать, посмотреть на промежуток десять секунд. И если на этом промежутке мы увидим, что скорость отправки пакетов возрастает и пакеты быстрее подтверждаются, то мы можем войти в фазу probe RTT и проверить, не стало ли все еще лучше.
Такие фазы чередуются, то есть мы будем постоянно проверять, что у нас с сетью.
Алгоритм BBR основан уже не на потере пакетов, а как раз на ширине канала и времени путешествия пакета.
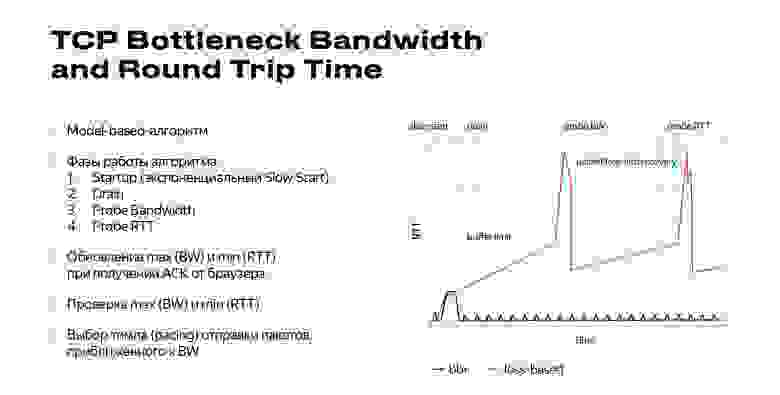
Фактически он неуязвим для потери пакетов. Он на них практически не реагирует, и из-за этого у нас возникают некоторые проблемы. Google обещал, что эти проблемы будут исправлены в BBR v2.
Мы рассмотрели наши фазы, и перед нами опять гребенка, которую я уже показывал. Красным выделены обычные TCP -протоколы. Вот он набирает, набирает, замедляется, и опять теряет пакеты. А BBR выставляет такой темп, который ему нужен, с которым он будет работать все время, и постоянно проверяет нашу сеть, не стала ли она чуть лучше. И, возможно, ускоряется.
Наши метрики постоянно обновляются, мы отслеживаем каждое подтверждение со стороны клиента и проверяем, ускорилась наша сеть или нет.
Чем же управляется этот темп отправки пакетов? Мы управляем темпом отправки с помощью техники pacing. Она реализована в планировщике, о котором я уже говорил. Это планировщик FQ. Также она реализована в самом ядре, но об этом я расскажу позже.
Мы стараемся, как в трубе, налить больше данных, и при этом не замедляться, не терять наши пакеты. Но BBR не так прост. Скорее всего, вы живете в контейнерах либо используете несколько серверов для баз данных — возможно, для картинок.

И все эти сервера взаимодействуют между собой. Там включен обычный TCP, не BBR. И когда у вас появится пила, которую мы уже видели, когда начнет схлопываться окно, то, возможно, BBR начнет нащупывать, что окно схлопывается, и увеличивать темп отправки пакетов. Тем самым он будет вытеснять обычные TCP из нашей сети, доминировать.
Если сеть будет совсем плохой, возможны другие проблемы. Обычные TCP вообще не будут работать, а так как BBR практически не чувствителен к потере пакетов, он с определенным темпом все же продолжит работать.
Эту проблему с data-центрами мы можем решить опцией TCP_CONGESTION. Она выставляется на каждый сокет, на каждое соединение. Сейчас, насколько я знаю, эта опция не реализована практически ни в одном веб-сервере. А наш L7-балансировщик ее поддерживает. Но вернемся к нашему pacing. Если вы работаете со старыми ядрами, то в ядрах до версии 4.20 была ошибка в реализации pacing. В этом случае стоит использовать планировщик FQ.

Теперь вы знаете, как работает TCP, можете прийти к своему системному администратору и рассказать ему, почему стоит включить BBR.
Вернемся к нашим десяти процентам. Откуда они могут появиться? Сети со стороны операторов сейчас очень большие. Все упирается в основном в деньги. Вы можете построить каналы на 100, 200 терабит и пропускать огромное количество 4K-видео, например. Но ваш клиент все равно будет находиться в конечной точке.
И скорее всего, эта последняя миля до клиента будет источником проблем. Все наши Wi-Fi и LTE будут терять пакеты. В случае использования обычного TCP мы будем видеть замедления. BBR решает эту проблему. Вы можете его включить всего лишь за счет двух команд, которые я указал. Всем спасибо.
— Привет. Я Саша, работаю в Яндексе, в последние три года занимаюсь разработкой L7-балансировщика нагрузки. Расскажу о быстром и простом способе ускорения сети. Мы начнем с седьмого уровня, HTTP, и опустимся к четвертому уровню, TCP. Сегодня мы поговорим только об этих двух уровнях и остановимся на них довольно подробно.
В последние восемь лет я занимаюсь больше бэкенд-разработкой, и, скорее всего, мои знания остались на уровне AngularJS первых версий. Вы, скорее всего, лучше меня знаете, как это все работает. Вы всё уже оптимизировали, всё сжали, и здесь я вам ничего посоветовать не смогу.
Но я могу вам посоветовать, как ускорить вашу сеть с помощью оптимизации самого сервера, самой операционной системы.

Чтобы что-то ускорить, нужны метрики. В данном случае мы использовали следующие: среднее время до первого байта показывает нам, как быстро работает уровень TCP, а вторая метрика — время получения HTML от первого байта. Мы произвели эксперименты, замерили наши метрики, и после включения BBR наше ускорение составило приблизительно десять процентов.

Чтобы понимать, что такое десять процентов, мы обратимся к абсолютному значению, которое составляет 66 миллисекунд. Если вы зайдете в свою любимую многопользовательскую онлайн-игру, то Ping до западноевропейских серверов будет составлять приблизительно 60-70 миллисекунд.
Как сделать быстро
Все наши сервера управляются с помощью протоколов удаленного управления, в данном случае SSH. Если вы еще не сталкивались с протоколом SSH, то можете попросить вашего системного администратора настроить ваш сервер. Я расскажу, как его убедить это сделать.

Что же такое BBR? Это один из алгоритмов, который позволяет нам управлять тем, как пакеты уходят в сеть. И конфигурируется он следующими двумя параметрами. Первое — выставление планировщика пакетов в FQ, далее я расскажу, почему стоит использовать FQ. Второе — включение самого congestion control, то есть самого BBR.
Кажется, что на этом мы могли бы закончить. Но на самом деле существует много подводных камней, и, скорее всего, ваш системный администратор просто так не включит BBR на сервере. Поэтому мы пойдем дальше.
HTTP/2 и мультиплексирование
Мы начнем с седьмого уровня, то есть с HTTP, и потихоньку пойдем вниз, рассматривая наши протоколы.

Начнем мы с наших браузеров, с которыми мы каждый день взаимодействуем. Мы видим консоль веб-разработчика. В консоли есть интересное для нас поле — protocol.
В нашем случае указаны протоколы HTTP/1 и HTTP/2. Также существует протокол HTTP/3, который основан на протоколе QUIC от компании Google. Но сегодня мы к нему не будем возвращаться, так как он находится в стадии разработки, еще не утвержден до конца. Вернемся к HTTP/1.

На слайде мы видим утилиту Wireshark, которая позволяет анализировать наши пакеты, то, как мы взаимодействуем с сетью. Видим, что одно поле подсвечено зеленым цветом. Это как раз наш HTTP-запрос. Внизу мы можем видеть байтики, как они будут представлены в сети.

Как же выглядит HTTP/1 в жизни? Это достаточно простой протокол. Он полностью текстовый, то есть мы просто пишем текст и отправляем его в сеть. Наши символы кодируются специальными шестнадцатеричными значениями. Справа таблица ASCII, небольшой кусочек, чтобы можно было ориентироваться.
Мы имеем первую часть в виде заголовков, которая отделена символами “\r\n\r\n” от нашего тела. Мы здесь просто запрашиваем обычный ресурс методом GET, поэтому тела у этого запроса не будет. И мы видим, что байтики приблизительно похожи на то, что есть в ASCII-таблице. Мы запрашиваем какую-то JS-ку, какой-то ресурс. Также есть заголовок Host, указывающий домен, с которым мы сейчас работаем. И — какой-то дополнительный набор заголовков. Они могут быть кастомными, можно использовать любые.

HTTP/2 — более сложный протокол. Он является бинарным, и наименьшей единицей обмена информации являются фреймы. Существует большое количество специальных случаев, специальных типов этих фреймов. На слайде вы видите, что они подсвечены.

Также мы можем наблюдать в первой строчке, что в один пакет могут поместиться сразу два фрейма. Мы не будем подробно останавливаться на том, какие фреймы существуют, их достаточно много. В данном случае нам будет интересен фрейм headers, потому как раз позволяет запрашивать ресурсы. Я немного участвовал в разработке Wireshark, помогал его улучшать в этом поле.
Мы видим, что есть get-запрос. Видим, что в середине есть текстовое представление этого get-запроса. Но в правой колонке видим только один выделенный байт, и он как раз будет являться этим методом get. Далее я расскажу, почему так происходит.
Дальше у нас есть заголовок path, который указывает путь до ресурса, до нашей JS-ки, которую мы будем запрашивать. И есть набор каких-то дополнительных заголовков, которые также будут присутствовать в нашем запросе.
Так почему же наши байты в сети не совпадают с тем, как это все рисуется на нашей картинке? Дело в том, что Wireshark показывает нам конечный результат, как он это все расшифровал. А в сети эти байты, эти заголовки, будут сжаты специальным форматом HPACK. Более подробно лучше ознакомиться в интернете. Поищите информацию, она хорошо документирована.
Вернемся к нашим байтикам. Есть специальное поле — идентификатор контента. Оно указывает, с каким ресурсом данные фреймы работают в текущий момент. В данном случае первый фрейм мы отправили, получили данные. Когда сервер будет нам отдавать сами байтики содержимого, уже будет использоваться фрейм data.

Наши протоколы HTTP/1 и HTTP/2 сильно отличаются. Мы уже поговорили о том, что HTTP/1 является текстовым протоколом, а HTTP/2 — бинарным, то есть работает с помощью фреймов.
HTTP/1 в случае запроса в виде одного соединения вернет неизвестно какой результат, в зависимости от реализации того, как это написали разработчики веб-сервера. То есть если мы сделаем два запроса в одно соединение, скорее всего, вернется либо ответ на первый, либо на второй запрос. Для этого, чтобы загружать ресурсы параллельно, браузер устанавливает несколько соединений, обычно их около шести, и параллельно загружает ресурсы.
HTTP/2, в свою очередь, использует одно соединение. То есть он задает соединение, и внутри него через фреймы подгружает все нужные данные. Эта техника упаковки нескольких ресурсов в одно соединение называется мультиплексированием.
Из того, как работают наши соединения, понятно: в случае потери пакета в одном из соединений HTTP/1 отработает лучше. Скорее всего, мы не затронем другие соединения, они продолжат грузиться с той же скоростью. А в случае HTTP/2, если наш пакет теряется, загрузка всех ресурсов начинает замедляться.

Кажется, что HTTP/2 хуже, он же чувствителен к потере пакетов. На самом деле, когда мы создаем каждое из этих шести соединений, мы производим следующую операцию.
Клиент и сервер как бы устанавливают надежное соединение, TCP-соединение. Мы отправляем от клиента два пакета серверу, и один пакет отправляется со стороны сервера клиенту. Тем самым мы как бы говорим, что готовы передавать данные. Это, конечно, создает накладные ресурсы, мы это можем делать достаточно долго.

Также существует шифрование. Если вы сейчас посмотрите на ваш браузер, скорее всего, увидите иконочку с замочком. Многие ее называют SSL, но на самом деле это не SSL. Это TLS. SSL уже давно устарел, уже практически не поддерживается, и стоит от него отказаться.
У TLS тоже есть обмен пакетов. То есть мы так же, как и в случае TCP-хендшейка, устанавливаем определенное состояние, после которого можем продолжать работать. В этом месте мы тоже можем заниматься оптимизацией, но браузеры пока не поддерживают те вещи, которые мы уже включили со стороны сервера. Будем ожидать, когда все это включат.

Когда-то давно в HTTP/1 пытались решить проблему параллельной загрузки ресурсов. В RFC это есть. И когда-то давно все-таки реализовали pipelining. Из-за сложности в реализации Internet Explorer его не поддерживает, а Firefox и Chrome поддерживают, но поддержка была со временем отключена.

Каждое наше соединение из шести, которые мы уже создали, на самом деле, не будет закрываться. То есть они продолжат работать так же, как и раньше. Для этого используется техника типа Keep-Alive. То есть мы создаем надежное соединение до конкретного сервера и продолжаем работать.
На уровне HTTP это контролируется заголовком. В данном случае это connection. А на уровне TCP мы уже будем использовать саму операционную систему, она за нас решит, как ей поступить.

Существуют и другие проблемы с HTTP/2. В HTTP/2 мы можем приоритизировать пакеты и отправлять более нужные данные быстрее. В данном случае, когда мы пытаемся отправить очень много данных за один раз, буфер на сервере может переполниться. Тогда более приоритетные пакеты просто затормозятся, встанут в конец очереди.
Наблюдается потеря пакетов. Они тормозят нашу загрузку, и такая блокировка называется Head-of-line blocking.
Как TCP решает проблемы потери пакетов
Теперь мы поговорим о TCP, то есть о нашем четвертом уровне. За следующие десять минут я расскажу, как работает TCP.

Когда мы в гостях, то просим кого-то передать соль. Когда человек нам передает соль, мы подтверждаем, что соль до нас дошла. В данном случае мы также берем какой-то сегмент, передаем его, ждем подтверждения. Опять передаем. И если произошла потеря, то мы пересылаем этот сегмент и в итоге он у нас доставляется. Такая техника отправки одного сегмента называется Stop and wait.
Но наши сети за последние 30 лет очень сильно ускорились. Возможно, кто-то из вас помнит диалап, интернет по мегабайтам. Сейчас вы, возможно, уже можете подключить домой гигабитный интернет.
Также мы можем в этом случае начать отправлять сразу по несколько пакетов. В нашем примере их три. Мы отправляем окно в виде трех пакетов и ждем, когда они все подтвердятся.
В случае потери пакета мы можем начать переотправлять все пакеты, начиная с первой нашей потери. Эта техника называется Go-Back N. А в другой ситуации мы можем начать отслеживать все пакеты и пересылать только те, которые были потеряны. Такая техника называется Selective Repeat. Она более дорогая со стороны сервера. Когда мы готовили слайды, ушло много времени на то, чтобы понять, как ее представить. Я сам в ней запутался, и поэтому придумал такую аналогию.
Есть всем нам известные трубы, через которые идет вода. Трубы имеют разный диаметр, где-то они могут быть тоньше, и в данном случае самое узкое место будет как раз с нашей максимальной пропускной способностью. Мы не сможем налить больше воды, чем позволяет это узкое место.
Мы попробуем стрелять шариками слева направо. С правой стороны нам будут подтверждать, что шарики долетели. Мы начинаем слать поток шариков. Посмотрим на его срез. Вот шарики летят в одну сторону, подтверждаются, и количество наших шариков экспоненциально растет. В какой-то момент объем шариков становится настолько большим, что они замедляются и начинаются потери. После потери мы немножко замедляемся, уменьшаем наше окно в два раза. Затем мы пытаемся понять, что с нами произошло. Первая стадия называется TCP Slow Start.
Смотреть анимацию

Когда мы схлопнули окно в два раза, мы можем восстановить соединение и попросить ребят переслать нам наши шарики заново. Они кричат нам, что надо переслать шарики, мы им отвечаем — вот ваши шарики. Такая фаза называется Fast Recovery и Fast Retransmit.
Смотреть анимацию
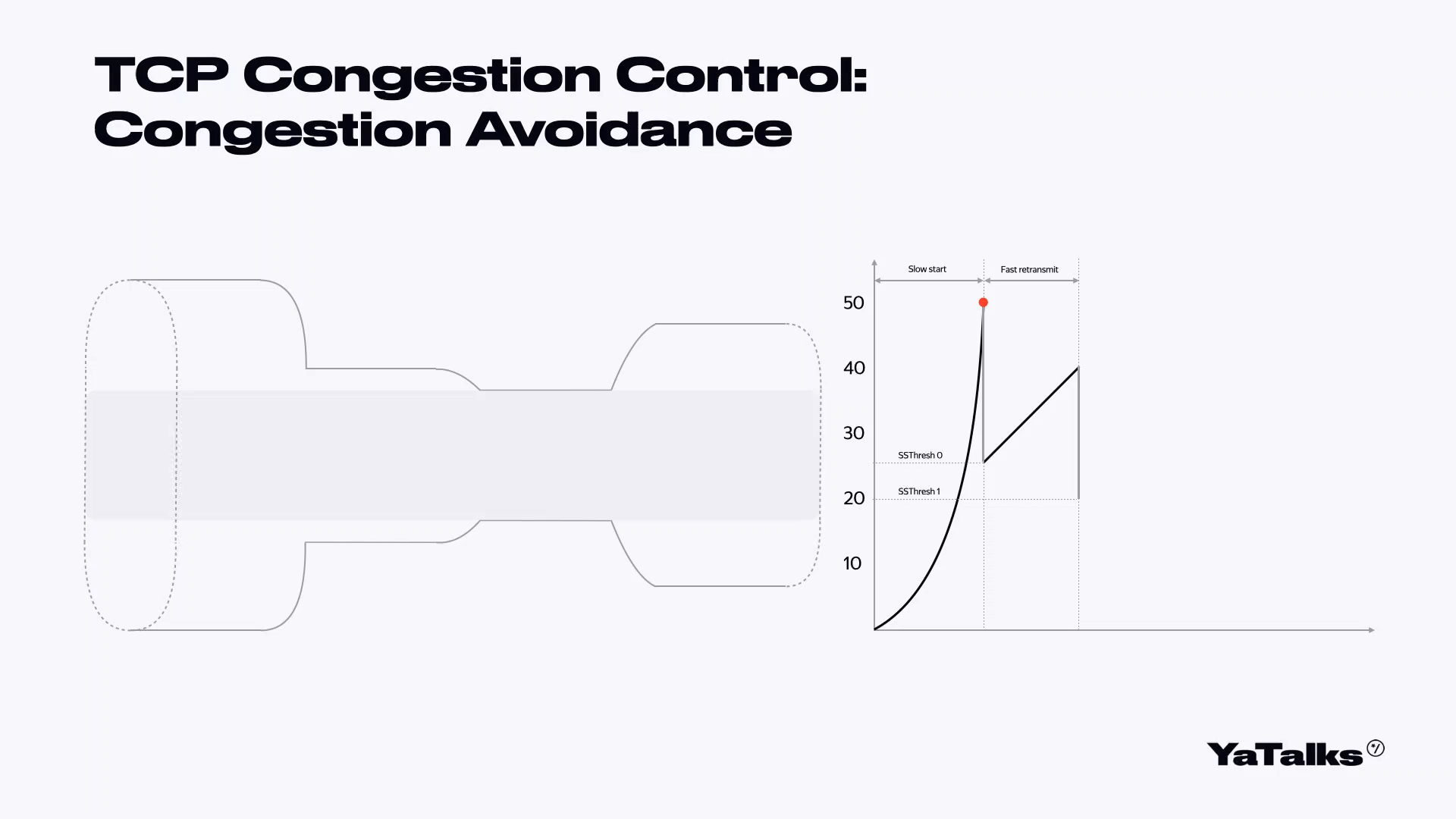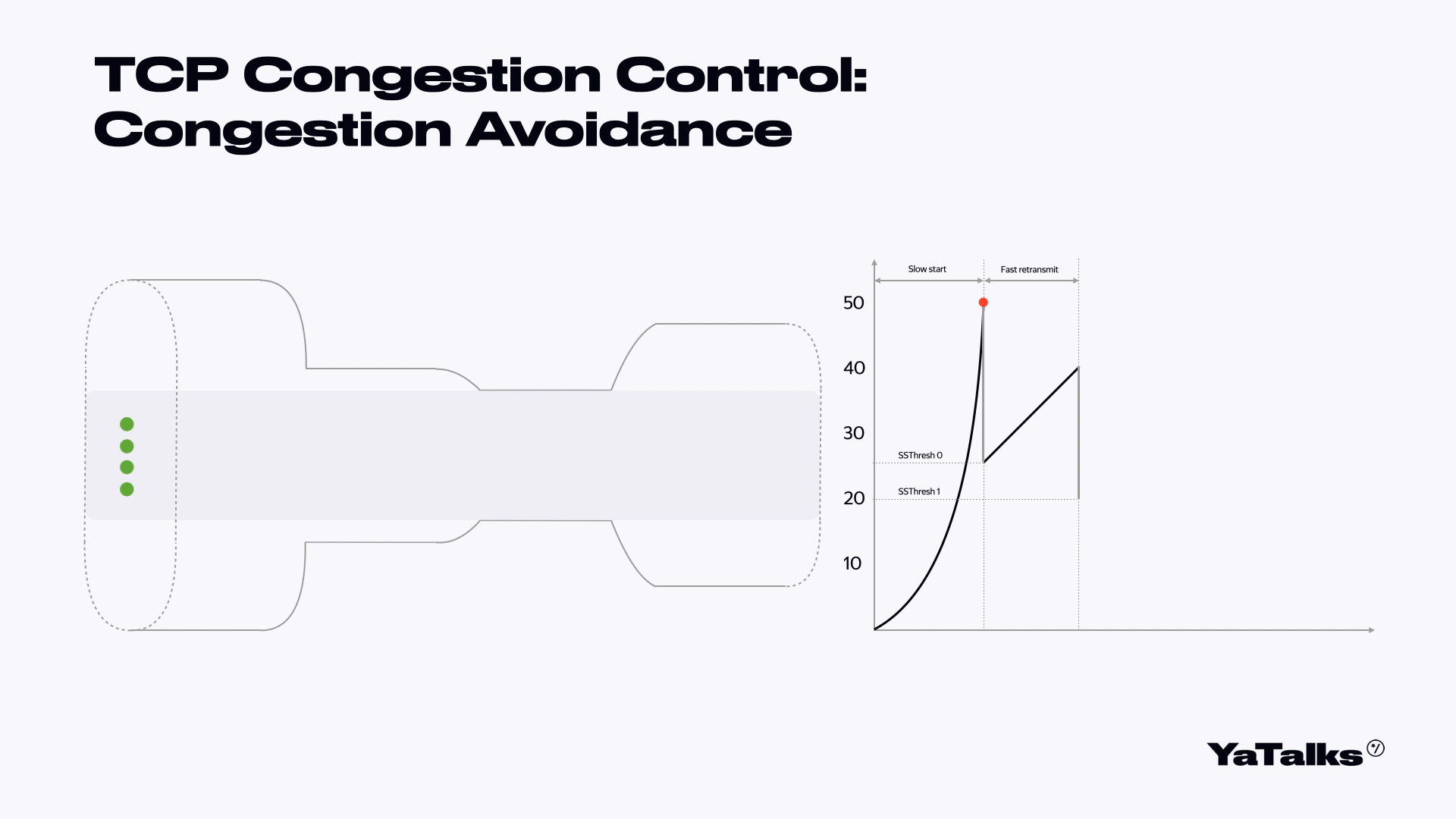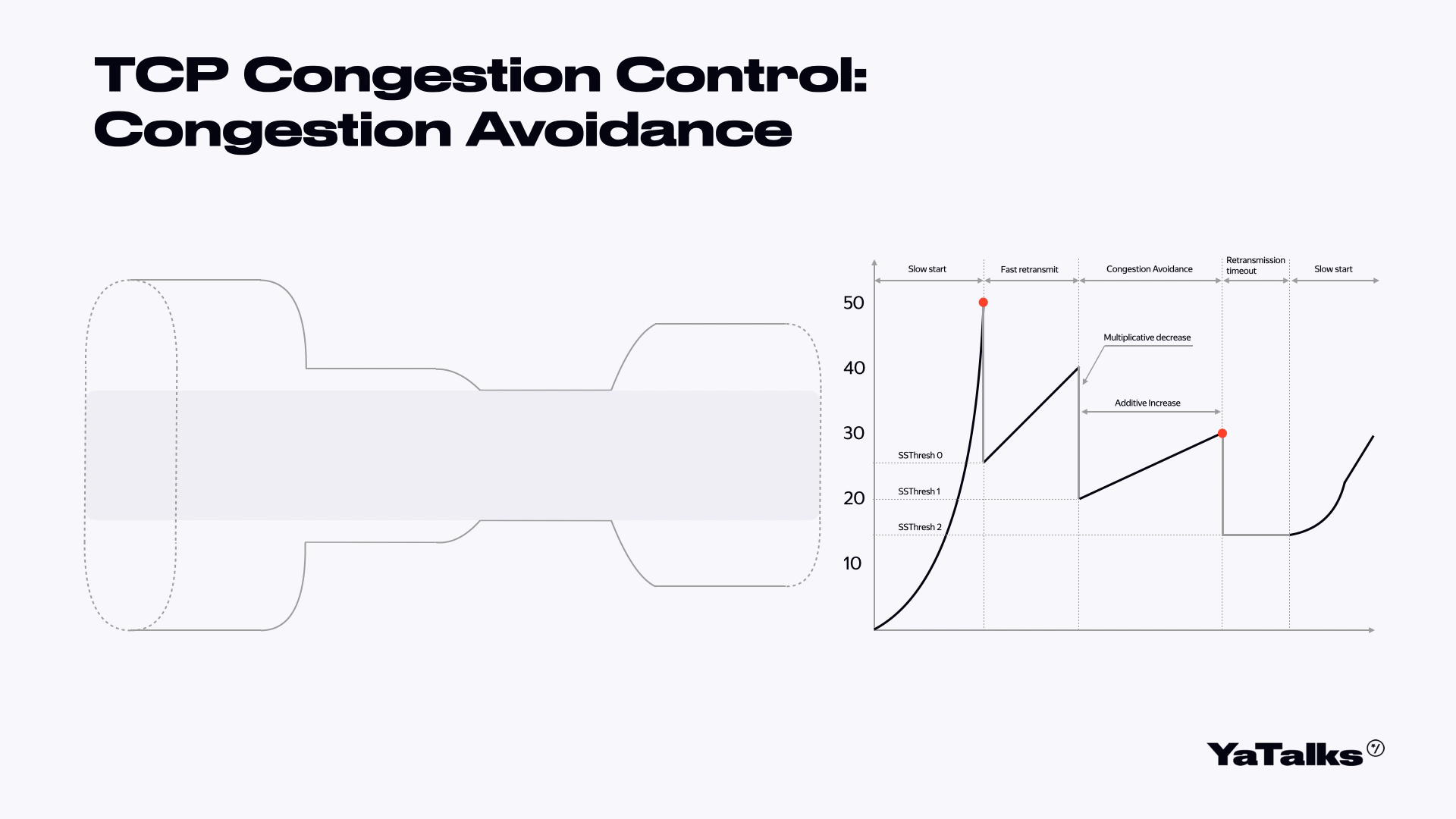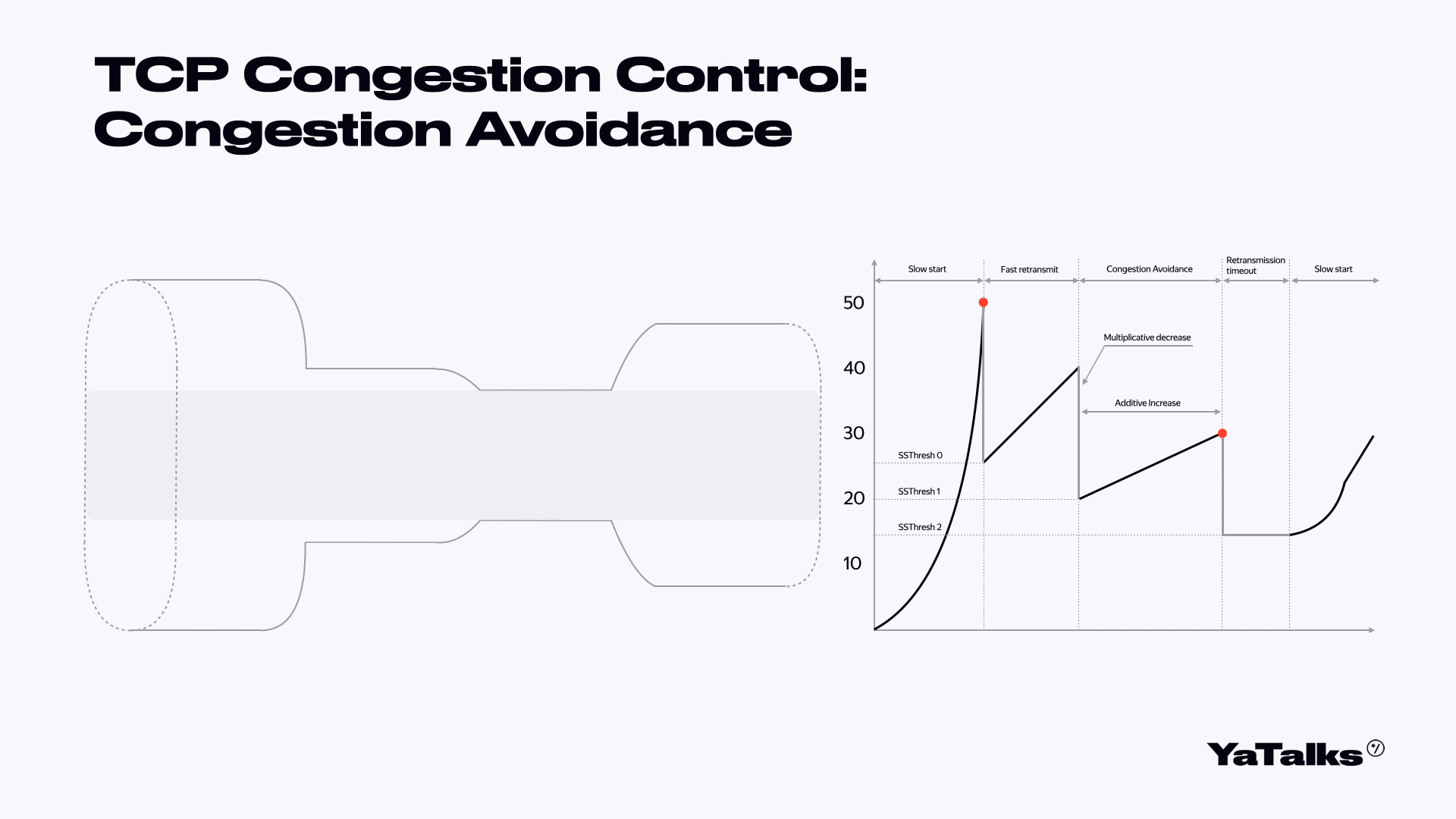
Когда мы поняли, что у нас все хорошо, мы начинаем постепенно наращивать количество отправляемых шариков, начиная с того схлопнутого окна. Такая фаза называется Congestion Avoidance. То есть мы пытаемся избежать потерь наших пакетов.
Фаза схлопывания нашего окна в два раза называется Multiplicative decrease. А медленная фаза наращивания количества шариков называется Additive Increase.
Когда наш Congestion Avoidance опять потеряет пакеты, мы можем произвести следующую стадию. Но в данный момент нас больше интересует само изображение этого графика. Мы видим такую пилу, и эта пила нам еще несколько раз пригодится. Запомните, как она выглядит.

Мы вернемся к проблемам обычных TCP-протоколов. По аналогии с трубой мы наливаем пакеты. Так как в интернете кроме нас существуют еще другие пользователи, они тоже начинают наливать пакеты в трубу. В какой-то момент буферы наших роутеров могут переполниться и создать нам проблемы отправки пакетов.
Также существует проблема с потерей пакетов в беспроводных сетях. Скорее всего, в вашем ноутбуке нет Ethernet-порта и вы смотрите доклад через Wi-Fi. Потери пакетов в Wi-Fi и в мобильных сетях возникают не по причине самого маршрутизирующего устройства, а по причине радиопомех. Такая метрика будет нам не очень полезна.
Отличие TCP BBR от других алгоритмов
Смотреть анимацию

Тут мы подошли к BBR. Он расшифровывается как Bottleneck Bandwidth and Round Trip Time, это метрики ширины канала, когда мы не забиваем наш канал полностью, и времени путешествия пакета от нас к серверу и обратно.
Когда мы отправляем данные, то идеальное состояние, при котором пакеты находятся в стабильном состоянии, летят и еще не были подтверждены, называется Bandwidth-delay product. BDP мы можем увеличивать за счет использования буферов сетевых устройств. Когда этот буфер превышается, начинаются потери.
И обычные TCP-алгоритмы как раз работают с правой стороны графика, то есть там, где происходят потери — мы наливаем так много пакетов, что потери неизбужны. Пакеты замедляются, и мы начинаем схлопывать окно.
BBR, в свою очередь, работает по другому принципу, близкому к нашей трубе. Мы просто наливаем то количество пакетов, которое можем пропустить. В фазе старта, то есть в самом начале, мы наливаем пакеты до тех пор, пока не начнутся заторы.
И иногда возможны потери пакетов. Но BBR пытается избежать этого момента. Когда мы заполнили нашу трубу, мы начинаем откатываться. Эта фаза называется drain.
Смотреть анимацию

Мы возвращаемся к нашему стабильному соединению, где будет полностью заполнена, но при этом мы не будем использовать дополнительные буферы, дополнительные резервуары. Из этого положения BBR продолжает работать.
Периодически мы будем смотреть на то, что происходит с нашей сетью. Мы отслеживаем практически каждый пакет, который к нам возвращается. Когда к нам вернулись пакеты, мы начинаем пробовать немножко ускорять количество пакетов, ускорять сами пакеты, отправляя их в сеть.
Смотреть анимацию

И если у нас не происходит никаких проблем, мы можем остаться на этом значении. То есть продолжить работать с тем темпом, который нам комфортен. Если же все-таки произошли потери, мы можем откатиться назад.
Когда мы получили подтверждение, увидели, что скорость улучшилась, мы можем немножко подождать, посмотреть на промежуток десять секунд. И если на этом промежутке мы увидим, что скорость отправки пакетов возрастает и пакеты быстрее подтверждаются, то мы можем войти в фазу probe RTT и проверить, не стало ли все еще лучше.
Смотреть анимацию

Такие фазы чередуются, то есть мы будем постоянно проверять, что у нас с сетью.
Алгоритм BBR основан уже не на потере пакетов, а как раз на ширине канала и времени путешествия пакета.

Фактически он неуязвим для потери пакетов. Он на них практически не реагирует, и из-за этого у нас возникают некоторые проблемы. Google обещал, что эти проблемы будут исправлены в BBR v2.
Мы рассмотрели наши фазы, и перед нами опять гребенка, которую я уже показывал. Красным выделены обычные TCP -протоколы. Вот он набирает, набирает, замедляется, и опять теряет пакеты. А BBR выставляет такой темп, который ему нужен, с которым он будет работать все время, и постоянно проверяет нашу сеть, не стала ли она чуть лучше. И, возможно, ускоряется.
Наши метрики постоянно обновляются, мы отслеживаем каждое подтверждение со стороны клиента и проверяем, ускорилась наша сеть или нет.
Чем же управляется этот темп отправки пакетов? Мы управляем темпом отправки с помощью техники pacing. Она реализована в планировщике, о котором я уже говорил. Это планировщик FQ. Также она реализована в самом ядре, но об этом я расскажу позже.
Мы стараемся, как в трубе, налить больше данных, и при этом не замедляться, не терять наши пакеты. Но BBR не так прост. Скорее всего, вы живете в контейнерах либо используете несколько серверов для баз данных — возможно, для картинок.

И все эти сервера взаимодействуют между собой. Там включен обычный TCP, не BBR. И когда у вас появится пила, которую мы уже видели, когда начнет схлопываться окно, то, возможно, BBR начнет нащупывать, что окно схлопывается, и увеличивать темп отправки пакетов. Тем самым он будет вытеснять обычные TCP из нашей сети, доминировать.
Если сеть будет совсем плохой, возможны другие проблемы. Обычные TCP вообще не будут работать, а так как BBR практически не чувствителен к потере пакетов, он с определенным темпом все же продолжит работать.
Эту проблему с data-центрами мы можем решить опцией TCP_CONGESTION. Она выставляется на каждый сокет, на каждое соединение. Сейчас, насколько я знаю, эта опция не реализована практически ни в одном веб-сервере. А наш L7-балансировщик ее поддерживает. Но вернемся к нашему pacing. Если вы работаете со старыми ядрами, то в ядрах до версии 4.20 была ошибка в реализации pacing. В этом случае стоит использовать планировщик FQ.

Теперь вы знаете, как работает TCP, можете прийти к своему системному администратору и рассказать ему, почему стоит включить BBR.
Вернемся к нашим десяти процентам. Откуда они могут появиться? Сети со стороны операторов сейчас очень большие. Все упирается в основном в деньги. Вы можете построить каналы на 100, 200 терабит и пропускать огромное количество 4K-видео, например. Но ваш клиент все равно будет находиться в конечной точке.
И скорее всего, эта последняя миля до клиента будет источником проблем. Все наши Wi-Fi и LTE будут терять пакеты. В случае использования обычного TCP мы будем видеть замедления. BBR решает эту проблему. Вы можете его включить всего лишь за счет двух команд, которые я указал. Всем спасибо.
