
Перед вами доклад Марии Зеленовой zelma — разработчика в Едадиле. За час Маша рассказала, в чём состоит тестирование программ, какие тесты бывают, зачем их писать. На простых примерах можно узнать про библиотеки для тестирования Python-кода (unittest, pytest, mock), принципы их работы и отличия между ними.
— Добрый вечер, меня зовут Маша, я работаю в отделе подготовки анализа данных Едадила, и сегодня у нас с вами лекция про тестирование.

Вначале мы с вами обсудим, какие вообще бывают виды тестирования, и я постараюсь вас убедить, зачем нужно писать тесты. Потом мы поговорим про то, что у нас есть в Python для работы непосредственно с тестами, с их написанием и вспомогательными модулями. В конце я немного расскажу про CI — неизбежную составляющую жизни в большой компании.
Мне хотелось бы начать с примера. Я попробую на очень страшных примерах объяснить, почему стоит писать тесты.
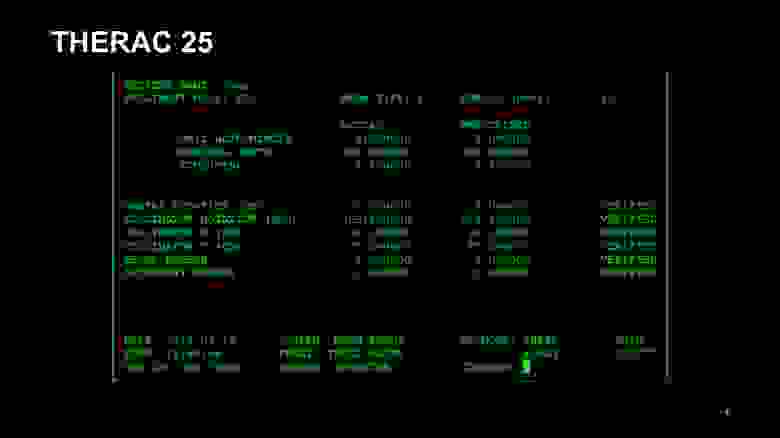
Перед вами интерфейс программы THERAC 25. Так назывался аппарат для лучевой терапии онкобольных, и с ним все пошло крайне неудачно. В первую очередь у него был неудачный интерфейс. Глядя на него, уже можно понять, что он не очень хороший: врачам было неудобно вбивать все эти циферки. В результате они копировали данные из карты предыдущего пациента и пытались править только то, что нужно было править.
Понятно, что они половину поправить забывали и ошибались. В результате пациентов лечили неправильно. UI тоже стоит тестировать, тестов много не бывает.
Но помимо неудачного интерфейса было ещё множество проблем в бэкенде. Я выделила две, которые показались мне самыми вопиющими:
Стоило бы написать тесты. Потому что это закончилось пятью зафиксированными смертельными случаями, и непонятно, сколько еще людей пострадало от того, что им дали слишком большие дозы препаратов.

Есть еще один пример того, что в некоторых ситуациях написание тестов позволяет сэкономить большие деньги. Это Mars Climate Orbiter — аппарат, который должен был в атмосфере Марса произвести замеры атмосферы, посмотреть, что там с климатом.
Но модуль, который был на земле, отдавал команды в системе СИ, в метрической системе. А модуль на орбите Марса думал, что это британская система мер, неправильно это интерпретировал.
В результате модуль вошел в атмосферу под неправильным углом и разрушился. 125 млн долларов просто ушло в мусорку, хотя казалось бы, можно промоделировать ситуацию на тестах и избежать этого. Но не вышло.
Теперь я поговорю про более прозаичные причины, зачем стоит писать тесты. Давайте поговорю про каждый пункт в отдельности:
Теперь мне хотелось бы немного поговорить про то, какие бывают классификации разновидностей тестирования. Их очень много. Я расскажу лишь о нескольких.
Процесс тестирования делится на тестирование черного ящика, белого и серого.
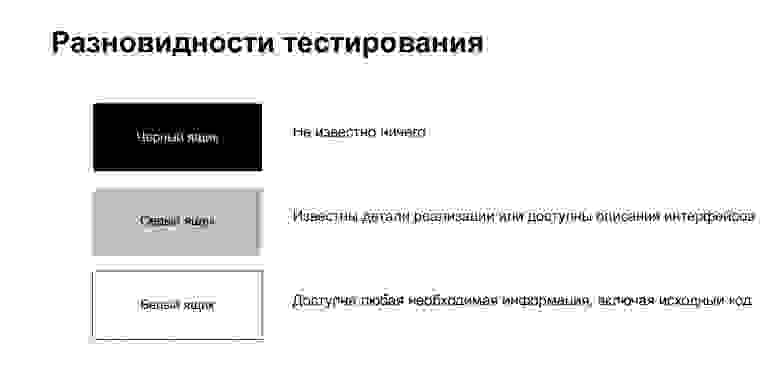
Тестирование черного ящика — процесс, когда тестировщику ничего не известно про то, что внутри. Он, как обычный пользователь, что-то делает, не зная никаких особенностей реализации.
Тестирование белого ящика означает, что тестировщику доступна любая необходимая информация, включая исходный код. Мы находимся в такой ситуации, когда пишем тест на собственный код.
Тестирование серого ящика — нечто промежуточное. Это когда вам известны какие-то детали реализации, но не вся целиком.
Также процесс тестирования можно поделить на ручной, полуавтоматический и автоматический. Ручное тестирование делает человек. Допустим, кнопочки в браузере нажимает, куда-то кликает, смотрит, что у него сломалось или не сломалось. Полуавтоматическое тестирование — это когда тестировщик запускает тестовые сценарии. Можно сказать, что мы с вами находимся в такой ситуации, когда локально свои тесты запускаем и прогоняем. Автоматическое тестирование не предполагает участия человека: тесты должны запускаться автоматически, а не руками.
Также тесты можно поделить по уровню детализации. Здесь их принято делить на юнит- и интеграционные тесты. Тут могут быть разночтения. Есть люди, которые любые автотесты называют юнит-тестами. Но более классическое деление примерно такое.
Юнит-тесты проверяют работу отдельных компонент системы, а интеграционные проверяют связку некоторых модулей. Иногда тут еще выделяют системные тесты, которые проверяют работу всей системы целиком. Но кажется, что это скорее большой вариант интеграционных тестов.
Тесты на наш код — это юнит- и интеграционные тесты. Есть люди, которые считают, что надо писать только интеграционные тесты. Я к таким не отношусь, считаю, что все должно быть в меру, и полезны как юнит-тесты, когда вы тестируете одну компоненту, так и интеграционные тесты, когда вы тестируете что-то большое.
Почему я так считаю? Потому что юнит-тесты обычно быстрее. Когда надо что-то подебажить, вас будет очень раздражать, что вы нажали на кнопку «запустить тест», а дальше три минуты ждете, пока стартанет база данных, сделаются миграции, произойдет что-то еще. Для таких случаев полезны юнит-тесты. Их можно запускать быстро и удобно, запускать по одному. Но когда вы юнит-тесты починили, прекрасно, давайте чинить интеграционные тесты.
Интеграционные тесты — вещь тоже очень нужная, большой плюс в том, что они больше про систему. Еще один большой плюс: они более устойчивы к рефакторингу кода. Если вы с большей вероятностью перепишете какую-то маленькую функцию, то общий пайплайн вы вряд ли будете менять с такой же частотой.

Бывает еще много разных классификаций. Я быстро пробегусь по тому, что здесь написала, но подробно останавливаться не буду, это слова, которые вы можете услышать где-то еще.
Smoke-тесты — тесты на критическую функциональность, самые первые и самые простые тесты. Если они сломались, то больше не надо тестировать, а надо идти их чинить. Допустим, приложение запустилось, не упало, — отлично, smoke-тест прошел.
Бывают regression-тесты — тесты на старую функциональность. Допустим, вы катите новый релиз и должны проверить, что в старом ничего не сломали. Это задача регрессионных тестов.
Бывают тесты совместимости, тесты установки. Они проверяют, что у вас все корректно работает в разных ОС и разных версиях ОС, в разных браузера и разных версиях браузера.
Acceptance-тесты — приемочные тесты. Про них я уже говорила, они говорят о том, можно ваше изменение катить в прод или нет.
Есть еще альфа- и бета-тестирование. Оба этих понятия больше относятся к продукту. Обычно, когда у вас есть более-менее готовая версия релиза, но там еще не все пофикшено, ее можно отдать либо на условно внешних, либо на внешних людей, добровольцев, чтобы они нашли вам баги, отрепортили и вы могли зарелизить совсем хорошую версию. Менее готовая — альфа-версия, более готовая — бета. В бета-тестировании почти все уже должно быть хорошо.
Дальше бывают performance- и стресс-тесты, нагрузочное тестирование. Они проверяют, допустим, как ваше приложение держит нагрузку. Есть какой-то код. Вы посчитали, сколько у него будет пользователей, запросов, какой РПС, сколько будет приходить запросов в секунду. Проэмулировали эту ситуацию, запустили, посмотрели — держит, не держит. Если не держит — думайте, что делать дальше. Возможно, оптимизировать код или увеличить количество железа, есть разные решения.
Стресс-тесты — примерно то же самое, только нагрузка выше ожидаемой. Если performance-тесты дают тот уровень нагрузки, который вы ожидаете, то в стресс-тестах вы можете увеличивать нагрузку, пока не сломается.
Немного отдельно тут стоят линтеры. Про линтеры я еще чуть позже немного скажу, это тесты оформления кода, стайл-гайд. В Python нам повезло, есть PEP8 — понятный стайлгайд, которому все должны следовать. И когда вы что-то пишете, вам обычно сложно следить за кодом. Предположим, вы забыли поставить пустую строку или сделали лишнюю, или оставили слишком длинную строчку. Это мешает, потому что вы привыкаете, что у вас код написан в едином стиле. Линтеры позволяют такие вещи автоматически отловить.
С теорией все, дальше я буду рассказывать про то, что есть в Python.

Вот список некоторых библиотек. Я не буду рассказывать подробно про все из них, но про большую часть буду. Про unittest и pytest мы, конечно, поговорим. Это библиотеки, которые используются непосредственно для написания тестов. Mock — вспомогательная библиотека по созданию mock-объектов. Про нее мы тоже поговорим. doctest — модуль для тестирования документации, flake8 — линтер, на них тоже посмотрим. Про pylama и tox я рассказывать не буду. Если вам будет интересно, можете посмотреть сами. Pylama — тоже линтер, даже, металинтер, он объединяет в себе несколько пакетов, очень удобный и хороший. А библиотека tox нужна, если вам необходимо тестировать ваш код в разном окружении — допустим, с разными версиями Python или с разными версиями библиотек. Tox в этом смысле очень помогает.
Но прежде чем рассказывать про разные библиотеки, я начну с банальности. Не стесняйтесь использовать в коде assert. Это не стыдно. Часто это помогает понять, что происходит.

Предположим, есть функция, которая считает порядковую статистику, к ней написано два assert. Assert стоит писать в функции в тех случаях, когда это совсем крайняя ерунда, которой не должно быть в коде. Это совсем крайние случаи, они, скорее всего, вам даже в продакшене не встретятся. То есть если вы накосячите в коде, оно у вас, скорее всего, должно упасть на тестах.
Assert помогают, когда вы занимаетесь прототипированием, у вас еще не продакшен-код, вы можете assert вообще везде воткнуть — в вызываемую функцию, куда угодно. Это не очень хорошо для серьезных проектов, но на этапе прототипирования вполне неплохо.
Предположим, вы по какой-то причине вы хотите отключить assert — например, хотите, чтобы это никогда не стреляло в продакшене. Для этого в Python есть специальная опция.

Расскажу, что такое doctest. Это модуль, стандартная библиотека Python, предназначенная для тестирования документации. Почему это хорошо? Документация, которая написана в коде, имеет свойство очень часто ломаться. Здесь очень маленькая игрушечная функция, все видно. Но когда у вас большой код, много параметров и вы в конце что-то дописали, то с очень большой вероятностью вы забудете поправить docstrings. Doctest позволяет таких вещей избежать. Вы что-то поправите, здесь не обновите, запустите doctest, и он у вас упадет. Так вы вспомните, что именно вы не поправили, пойдете и поправите.
Как это выглядит? Doctest ищет в docstrings эти елочки, дальше исполняет их и сравнивает то, что получается.

Вот пример запуска doctest. Запустили, видим, что у нас два теста и один из них упал — совершенно по делу. Отлично, мы увидели хорошую понятную информацию об ошибке.

Ссылка со слайда
У doctest есть полезные директивы, которые могут пригодиться. Про все из них я рассказывать не буду, но некоторые, которые мне показались наиболее употребительными, я вынесла на слайд. Директива SKIP позволяет не запускать тест на помеченном примере. Директива IGNORE_EXCEPTION_DETAIL игнорирует тест EXCEPTION. ELLIPSIS позволяет написать троеточие вместо любого места в выводе. FAIL_FAST останавливается после первого упавшего теста. Все остальное можно прочесть в документации, там очень много. Лучше покажу на примере.

В этом примере есть директива ELLIPSIS и директива IGNORE_EXCEPTION_DETAIL. Вы видите в директиве ELLIPSIS К-ю порядковую статистику, и мы ожидаем, что придет что-то, начинающееся с девятки и заканчивающееся на девятку. В середине может быть что угодно. Такой тест не упадет.
Ниже есть директива IGNORE_EXCEPTION_DETAIL, она будет проверять только то, что пришло в AssertionError. Видите, мы там написали бла-бла-бла. Тест пройдет, он не будет сравнивать бла-бла-бла с expected iterable as first argument. Он будет сравнивать только AssertionError с AssertionError. Это полезные вещи, которыми можно пользоваться.

Дальше план такой: я буду рассказывать вам про unittest, потом про pytest. Сразу скажу, что я, наверное, не знаю плюсов unittest, кроме того, что это часть стандартной библиотеки. Я не вижу ситуации, которая бы меня заставила сейчас пользоваться unittest. Но есть проекты, которые его используют, в любом случае полезно знать, как выглядит синтаксис и что оно из себя представляет.
Другой момент: тесты, написанные на unittest, умеют запускать pytest прямо из коробки. Ему все равно. (…)
Unittest выглядит так. Есть класс, начинающийся со слова test. Внутри функция, начинающаяся со слова test. Тестовый класс наследован от unittest.TestCase. Сразу скажу, что один тест тут написан правильно, а другой тест неправильно.
Верхний тест, где написан обычный assert, упадет, но это будет выглядеть странно. Давайте посмотрим.

Команда запуска. Вы можете написать в сам код unittest main, можете вызвать его из Python.

Мы запустили этот тест и видим, что он написал AssertionError, но он не написал, в каком месте он упал — в отличие от следующего теста, где использовался self.assertEqual. Тут явным образом написано: три не равно двум.

Надо чинить, конечно. Но тогда был не виден этот волшебный вывод на экране.
Давайте посмотрим еще раз. В первом случае мы написали assert, во втором self.assertEqual. К сожалению, в unittest только так. Есть специальные функции — self.assertEqual, self.assertnotEqual и еще 100500 функций, которые нужно использовать, если вы хотите увидеть адекватное сообщение об ошибке.
Почему так происходит? Потому что assert — оператор, которому приходит bool и, возможно, строка, но в данном случае bool. И он видит, что у него true или false, а левую и правую часть ему уже неоткуда взять. Поэтому в unittest есть специальные функции, которые будут корректно выводить сообщения об ошибке.
Это не очень удобно, на мой взгляд. Точнее, совсем не удобно, потому что это какие-то специальные методы, которые есть только в этой библиотеке. Они отличны от того, к чему мы привыкли в обычном языке.

Это необязательно запоминать — позже мы поговорим про pytest и, я надеюсь, вы в основном будете писать на нем. В unittest целый зоопарк функций, которые нужно использовать, если вы хотите что-то проверить и получить при этом хорошие сообщения об ошибках.
Дальше поговорим про то, как в unittest написать фикстуры. Но для этого мне сначала нужно сказать, что такое фикстуры. Это функции, которые вызываются до или после выполнения теста. Они нужны, если тесту нужно выполнить специальную настройку — создать временный файл после теста, удалить временный файл; создать базу данных, удалить базу данных; создать базу данных, написать в нее что-то. В общем, что угодно. Давайте посмотрим, как это выглядит в unittest.

Для написания фикстуры в unittest есть специальные методы setUp и tearDown. Почему они до сих пор написаны не по PEP8 — для меня большая загадка. (…)
SetUp — это то, что выполняется до теста, tearDown — то, что выполняется после теста. Мне кажется, это крайне неудобная конструкция. Почему? Потому что, во-первых, у меня рука не поднимается эти имена писать: я уже живу в мире, где все-таки есть PEP8. Во-вторых, у вас появился temp-файл, про который у вас в аргументах самого теста ничего нет. Откуда он взялся? Не очень понятно, почему он есть и что это вообще такое.
Когда у нас маленький класс, который влазит на экран, — это классно, его можно охватить взглядом. А когда у вас эта огромная простыня, вы замучаетесь искать, что это вообще было и почему он такой, почему так себя ведет.
С фикстурами в unittest есть еще одна не очень удобная особенность. Предположим, у нас есть один класс тестов, которым нужен временный файл, и другой класс тестов, которым нужна база данных. Отлично. Вы написали один класс, сделали setUp, tearDown, сделали создание/удаление временного файла. Написали другой класс, в нем тоже написали setUp, tearDown, сделали в нем создание/удаление базы данных.
Вопрос. Есть третья группа тестов, которым нужно и то и то. Что с этим всем делать? Мне видится два варианта. Либо взять и скопипастить код, но это не очень удобно. Либо создать новый класс, наследовать его от двух предыдущих, вызвать super. В целом это тоже будет работать, но выглядит как дикий overkill для тестов.

Поэтому мне хочется, чтобы ваше знакомство с unittest осталось вот таким, на теоретическом уровне. Дальше мы поговорим про более удобный способ писать тесты, более удобную библиотеку, это pytest.
Вначале я вам попробую рассказать, почему pytest — это удобно.

Ссылка со слайда
Первый момент: в pytest обычно работают assert, те, к которым вы привыкли, и они выдают нормальную информацию об ошибке. Второе: к pytest есть хорошая документация, где разобрана куча примеров, и все что угодно, все, что вы не понимаете, можно посмотреть.
Третье: тесты — это просто функции, которые начинаются на test_. То есть вам не нужного лишнего класса, вы просто пишете обычную функцию, называете ее на test_ и она будет запускаться через pytest. Это удобно, потому что чем проще писать тесты, тем больше вероятность, что вы тест напишете, а не забьете.
В pytest есть куча удобных фич. Можно писать параметризованные тесты, удобно писать фикстуры разных уровней, есть и просто красивости, которыми можно пользоваться: xfail, raises, skip, еще какие-то. В pytest есть много плагинов, плюс можно писать свои.

Давайте посмотрим на примере. Так выглядят тесты, которые написаны на pytest. По смыслу это то же самое, что и на unittest, только выглядит гораздо лаконичнее. Первый тест — вообще две строчки.

Запускаем командой python -m pytest. Отлично. Два теста прошли, все хорошо, мы видим, что они прошли и за какое время.

Теперь давайте сломаем один тест и сделаем так, чтобы у нас вывелась информация об ошибке. Вывелось assert 3 == 2 и ошибка. То есть мы видим: несмотря на то, что мы написали обычный assert, у нас корректно вывелась информация об ошибке, хотя до этого в unittest мы говорили, что assert принимает bool в строку или bool, так что информацию об ошибке вывести проблематично.
Можно задаться вопросом, почему это все работает? Потому что в pytest постарались и прибрали некрасивую часть за интерфейс. Pytest сначала делает синтаксический разбор вашего кода, и он представляется в виде некой древовидной структуры, абстрактного синтаксического дерева. В этой структуре у вас в вершинах стоят операторы, в листьях — операнды. Assert — это оператор. Он стоит в вершине дерева, и в этот момент, прежде чем отдать всё интерпретатору, можно этот assert подменить на внутреннюю функцию, которая делает интроспекцию и понимает, что у вас в левой и правой части. На самом деле интерпретатору скармливается уже вот это, с подмененным assert.
Подробно рассказывать не буду, есть ссылка, по ней можно прочитать, как они это сделали. Но мне нравится, что это все работает под капотом. пользователь этого не видит. Он пишет assert, как привык, все остальное делает сама библиотека. Можно об этом даже не задумываться.
Дальше в pytest для стандартных типов у вас и так выведется хорошая информация об ошибке. Потому что pytest знает, как эту информацию об ошибке выводить. Но вы можете у себя в тесте сравнивать кастомные типы данных, например деревья или что-то сложное, и pytest может не знать, как для них информацию об ошибке выводить. Для таких случаев можно добавить специальный хук — вот раздел в документации — и в этом хуке написать, как должна выглядеть информация об ошибке. Все очень гибко и удобно.

Посмотрим, как в pytest выглядят фикстуры. Если в unittest это необходимость писать setUp и tearDown, то здесь называйте обычную функцию как угодно. Написали сверху декоратор pytest.fixture — отлично, это фикстура.
Причем здесь еще не самый простой пример. Фикстура может просто делать return, что-то возвращать, это будет аналог setUp. В данном случае она сделает еще как бы tearDown, то есть именно здесь, после окончания теста, она вызовет close, и временный файлик удалится.
Кажется, это удобно. У вас есть произвольная функция, которую вы можете как угодно назвать. Вы ее явно в тест передаете. Передали filled_file, знаете, что это она. От вас не требуется ничего специального. В общем, пользуйтесь. Это намного удобнее, чем в unittest.

Еще немного про фикстуры. В pytest очень легко создать фикстуры разных scope. По дефолту фикстура создается с уровнем function. Это значит, что она будет вызываться на каждый тест, куда вы ее передали. То есть если есть yield или что-то еще а-ля tearDown, это тоже будет происходить после каждого теста.
Вы можете объявить scope='module', и тогда фикстура будет выполняться один раз на модуль. Допустим, вы хотите один раз создать базу данных и не хотите после каждого теста удалять и накатывать все миграции.
Еще в фикстурах есть возможность указать аргумент autouse=True, и тогда фикстура будет вызываться независимо от того, попросили вы ее или нет. Кажется, что этой опцией не нужно пользоваться никогда, или нужно, но очень осторожно, потому что это неявная вещь. Неявного лучше избегать.

Мы запустили этот код — посмотрим, что получилось. Есть test one, который зависит от фикстуры call me once use when needed, call me every time. При этом call me once use when needed — фикстура уровня модуля. Видим, что первый раз у нас вызвались фикстуры call me once use when needed, call me every time, которые это выводят, но еще вызвалась фикстура с autouse, потому что ей все равно, она всегда вызывается.
Второй тест зависит от тех же самых фикстур. Видим, что у нас второй раз call me once use when needed не напечаталась, потому что она уровня модуля, она один раз уже вызвалась и она больше вызываться не будет.
Кроме того, из этого примера видно, что в pytest нет таких проблем, о которых мы с вами говорили в unittest, когда в одном тесте вам может быть нужна база данных, в другом — временный файл. Как их нормально сагрегировать, непонятно. Вот ответ на этот вопрос в pytest. Если передали две фикстуры, то внутри и будет две фикстуры.
Прекрасно, очень удобно, никаких проблем. Фикстуры очень гибкие, они могут зависеть от других фикстур. В этом нет никакого противоречия, и pytest сам вызовет их в нужном порядке.

На самом деле внутри можно отнаследовать фикстуры от других фикстур, сделать их разного scope, и autouse без autouse. Он сам их расставит в правильном порядке и вызовет.
Здесь у нас есть первый тест, test one, который зависит от rare_dependency_for_test_one, где эта фикстура зависит от другой фикстуры — и еще от одной. Давайте посмотрим, что будет на выхлопе.

Мы видели, что они вызываются, причем в порядке наследования. Тут все фикстуры уровня функции, поэтому все они вызываются на каждый тест. Второй тест зависит от rare_dependency, а rare_dependency зависит от some_common_dependency. Смотрим на выхлоп и видим, что перед тестом вызвались две фикстуры.
В pytest есть специальный конфигурационный файл conftest.py, куда вы можете положить все фикстуры, и хорошо, если положите: обычно, когда человек смотрит на чужой код, он обычно пойдет смотреть фикстуры в conftest.
Это не обязательно. Если есть фикстура, которая вам нужна только в этом файле, и вы точно знаете, что она специфичная, узкоприменимая, и в другом файле не понадобится, то можете объявить ее в файле. Либо создавать много conftest, и они все будут работать на разных уровнях.

Поговорим про фичи, которые бывают в pytest. Как я уже говорила, очень легко делать параметризацию тестов. Здесь мы видим тест, у которого три набора параметров: два входных и тот, что ожидается. Мы их передаем в аргументы функции и смотрим, совпадает ли то, что мы передали на вход, с тем, что ожидается.

Посмотрим, как это выглядит. Видим, что здесь три теста. То есть pytest считает, что это три теста. Два прошло, один упал. Что здесь хорошо? Для того теста, который упал, мы видим аргументы, видим, на каком наборе параметров он упал.
Опять же, когда у вас маленькая функция и в parametrize написано — три штуки, возможно, вы и глазами увидите, что именно упало. Но когда наборов в параметрах много, вы это глазами не увидите. Вернее, увидите, но вам будет очень сложно. И очень удобно, что pytest так все выводит — вы сразу можете посмотреть, в каком именно случае тест упал.

Parametrize — хорошая штука. И когда вы написали тест один раз, а дальше делаете много-много наборов параметров — это хорошая практика. Не делать много вариантов кода на похожие тесты, а один раз написать тест, дальше сделать большой набор параметров, и оно будет работать.
В pytest есть еще много всяких удобных штук. Если о них рассказывать, лекции явно не хватит, поэтому я покажу, опять же, только несколько. В первом тесте используется pytest.raises(), чтобы показать, что вы ожидаете исключения. То есть в данном случае, если вызовется AssertionError, тест пройдет. У вас должно броситься исключение.
Вторая удобная штука — xfail. Это декоратор, который разрешает тесту падать. Допустим, у вас есть много тестов, много кода. Вы что-то порефакторили, тест начал падать. При этом вы понимаете, что либо он не критичный, либо чинить его придется очень дорого. И вы такие: ладно, навешу на него декоратор, он станет зелененьким, починю его потом. Или предположим, тест начал флакать. Понятно, что это договоренность с собственной совестью, но иногда это бывает нужно. Причем xfail в таком виде будет зелененьким независимо от того, упал тест или нет. Ему еще можно передать в параметр Strict = True, тогда это будет немножко другая ситуация, pytest будет ждать, что тест упадет. Если тест пройдет, то вернется сообщение об ошибке, и, наоборот.
Еще одна полезная штука — skipif. Есть просто skip, который не будет запускать тесты. И есть skipif. Если вы навесите этот декоратор, тест не будет запускаться при определенных условиях.
В данном случае написано, что если у меня платформа Mac, то не запускайся, потому что тест почему-то падает. Бывает. Но в целом бывают платформозависимые тесты, которые всегда будут падать на определенной платформе. Тогда это полезно.

Давайте запустим. Увидели буковку X, увидели S. X у нас относится к xfail, S — к skipif. То есть pytest показывает, какой тест мы совсем пропустили, а какой запустили, но не смотрим на результат.

В самом pytest есть много разных полезных опций. Я, конечно, не смогу вывести их сюда, можно посмотреть в документации. Но про несколько я расскажу.
Вот полезная опция --collect-only. Она выводит список найденных тестов. Есть опция -k — фильтрация по имени теста. Это одна из моих самых любимых опций: если у вас один тест свалился, особенно если он сложный и вы пока не знаете, как его чинить, — пофильтруйте и запускайте его.
Вам хочется сэкономить время и, наверное, неинтересно запускать 15 других тестов — вы знаете, что они проходят или падают, но пока до них не дошли. Запускайте тест, который падает, чините его и идите дальше.
Еще есть очень хорошая опция -s, она включает вывод из stdout и stderr в тестах. По дефолту pytest будет выводить stdout и stderr только для упавших тестов. Но есть моменты, обычно на этапе отладки, когда вы хотите что-то в тесте вывести и не знаете, упадет ли тест. Может, и не упадет, но вы хотите в самом тесте увидеть, что туда приходит, и вывести. Тогда запускайте с -s — и вы увидите то, что хотели.
-v — стандартная опция verbose, повысить детализацию.
--lf, --last-failed — опция, которая позволяет перезапустить только те тесты, которые упали в последнем запуске. --sw, --stepwise — тоже полезная функция, как и -k. Если вы чините тесты последовательно, то запускаете со --stepwise, она проходит по зелененьким, а как только видит упавший тест, останавливается. И когда вы еще раз запустите --sw, она запустится с этого теста, который падал. Если опять упадет, она опять остановится, если не упадет — пойдет дальше до следующего падения.

Ссылка со слайда
В pytest есть основной конфигурационный файл pytest.ini. В нем можно изменить поведение pytest по умолчанию. Я здесь привела опции, которые очень часто встречаются в конфигурационном файле.
Testpaths — пути, в которых pytest будет искать тесты. addopts — то, что добавляется в командную строку при запуске. Здесь у меня в addopts добавлены плагины flake8 и coverage. Мы чуть позже на них посмотрим.

Ссылка со слайда
В pytest есть очень много разных плагинов. Я написала те, которые, опять же, используются повсеместно. flake8 — это линтер, coverage — покрытие кода тестами. Дальше есть целый набор плагинов, которые облегчают работу с теми или иными фреймворками: pytest-flask, pytest-django, pytest-twisted, pytest-tornado. Наверное, еще что-нибудь есть.
Плагин xdist используется, если вы хотите запускать тесты параллельно. Плагин timeout позволяет ограничить время работы теста: это пригождается. Вы вешаете на тест декоратор timeout, и если тест работает дольше, он сваливается.

Давайте посмотрим. Я в pytest.ini добавила coverage и flake8. Сoverage мне выдал отчет, у меня там файл с тестами, что-то из него не вызвалось, но это ничего :)
Вот файл k_stat.py, в нем нашлось целых пять стейтментов. Это примерно то же самое, что пять строчек кода. И покрытие 100%, но это потому, что у меня файлик очень маленький.
На самом деле покрытие обычно не бывает стопроцентным, и более того, не стоит его добиваться всеми способами. Субъективно кажется, что покрытие тестами 60-70% — это вполне достаточно и нормально для работы.
Сoverage — такая метрика, которая даже будучи стопроцетной не говорит, что вы молодец. То, что вы вызвали этот код, не значит, что вы что-то проверили. Вы можете еще assert True в конце написать. К coverage нужно подходить разумно, для стопроцентного покрытия тестами есть файзинг и роботы, а людям так делать не надо.
В pytest.ini я подключила еще один плагин. Здесь видно --flake8, это линтер, который показывает мои стилевые ошибки, и некоторые другие, уже не из PEP8, а из pyflakes.

Тут в выхлопе написан номер ошибки в PEP8 или в pyflakes. В целом все понятно. Строчка слишком длинная, для redefinition нужно две пустые строки, нужна пустая строка в конце файла. В конце написано, что у меня CitizenImport не используется. В общем, линтеры позволяют ловить грубые ошибки и ошибки в оформлении кода.

Мы с вами уже говорили про плагин timeout, он позволяет ограничить время работы теста. Для некоторых перфтестов важно время работы. И вы можете ограничить его внутри тестов с помощью time.time и timeit. Либо с помощью плагина timeout, что тоже очень удобно. Если тест работает слишком много, его можно попрофилировать разными способами, например cProfile, но про это будет рассказывать Юра в своей лекции.

Если вы пользуетесь IDE, а пользоваться вспомогательными средствами стоит, у меня тут, в частности, PyCharm, то тесты очень легко запустить прямо из него.
Осталось поговорить про mock. Представим, у нас есть модуль A, мы хотим его протестировать и есть другие модули, которые мы тестировать не хотим. Один из них ходит в сеть, другой в базу данных, а третий — простой модуль, который нам ничем не мешает. В таких случаях нам поможет mock. Опять же, если мы пишем интеграционный тест, то, скорее всего, поднимем тестовую базу данных, напишем тестового клиента, и это тоже прекрасно. Это просто интеграционный тест.
Бывают случаи, когда мы хотим сделать unittest, когда мы хотим протестировать только один кусочек. Тогда нам нужен mock.

Mock — это набор объектов, которыми можно подменить настоящий объект. На любое обращение к методам, к атрибутам он возвращает тоже mock.
В этом примере у нас есть простой модуль. Мы его оставим, а какие-то более сложные заменим на mock. Сейчас мы посмотрим, как это работает.

Тут показано наглядно. Мы его проимпортировали, говорим, что m — это mock. Вызвали, вернулся mock. Сказали, что у m есть метод f. Вызвали, вернулся mock. Сказали, что m есть атрибут is_alive. Отлично, вернулся еще один mock. И мы видим, что m и f вызвались по одному разу. То есть это такой хитрый объект, внутри у которого переписан метод getattr.

Давайте посмотрим на более понятном примере. Допустим, есть AliveChecker. Он использует какую-то http_session, ему нужен таргет, и у него есть функция do_check, которая возвращает True или false в зависимости от того, что ему пришло: 200 или не 200. Это немножко искусственный пример. Но предположим, что внутри do_check можно накрутить сложную логику.
Допустим, мы не хотим ничего тестировать про сессию, не хотим ничего знать про метод get. Мы хотим протестировать только do_check. Отлично, давайте протестируем.

Можно это сделать так. Мокаем http_session, здесь она называется pseudo_client. Мокаем у нее метод get, говорим, что get — это такой mock, который возвращает 200. Запускаем, создаем от этого всего AliveChecker, запускаем. Этот тест будет работать.
В дополнение давайте проверим, что get вызвался один раз и ровно с такими аргументами, как там написано. То есть мы вызвали do_check, ничего не зная ни про то, что это за сессия, ни про то, что у него за методы. Мы их просто замокали. Единственное, что мы знаем, — что он вернул 200.

Другой пример. Он очень похож на предыдущий. Единственное, здесь вместо return_value написан side_effect. Но это что-то, что mock выполняет. В данном случае он бросает исключение. Строчка с assert поменяна на assert not AliveChecker.do_check(). То есть мы видим, что проверка не пройдет.
Это два примера, как протестировать функцию do_check, не зная ничего про то, что в нее сверху пришло, что пришло в этот класс.
Пример, конечно, выглядит искусственным: не совсем понятно, зачем проверять, 200 или не 200, здесь просто минимум логики. Но давайте представим, что в зависимости от кода возврата делается нечто хитрое. И тогда такой тест начинает казаться гораздо более осмысленным. Мы увидели, что приходит 200, а дальше проверяем обрабатывающую логику. Если не 200 — то же самое.

Еще с помощью mock можно патчить библиотеки. Допустим, у вас уже есть библиотека, и в ней надо что-то поменять. Тут пример, мы запатчили синус. Теперь он у нас всегда возвращает двойку. Отлично.
Еще мы видим, что m вызвалась два раза. Mock ничего, конечно, не знает про внутренние API методов, которые вы мокаете и вообще, не обязан с ними совпадать. Но mock позволяет проверить, что вы вызвали, сколько раз и с какими аргументами. В этом смысле он помогает тестировать код.

Я хочу предостеречь вас от случая, когда остается один модуль и огромный mock. Подходите, пожалуйста, ко всему разумно. Если у вас есть простые штуки, не надо их мокать. Чем больше mock у вас в тесте, тем больше вы уходите от реальности: у вас может не совпадать API, и вообще это не совсем то, что вы тестируете. Без необходимости не надо мокать все подряд. Подходите к процессу разумно.

У нас осталась последняя маленькая часть про Continuous Integration. Когда вы одни разрабатываете пет-проджект, вы можете запускать тесты локально, и ничего страшного, они будет работать.
Как только проект вырастает и разработчиков в нем становится больше одно, это перестает работать. Во-первых, половина не будет запускать тесты локально. Во-вторых, они будут запускать их на своих версиях. Где-то будут конфликты, все будет постоянно ломаться.
Для этого есть Continuous Integration, практика разработки, которая заключается в быстром вливании кандидатов в основную ветку. Но при этом они должны пройти некую автосборку или автотесты в специальной системе. У вас есть код в репозитории, коммиты, которые вы хотите влить в вашу ветку основную проекта. На этих коммитах в специальной системе проходят тесты. Если тесты зелененькие, то либо коммит вливается сам, либо у вас появляется возможность его влить.
У такой схемы, конечно, есть свои недостатки, как и у всего. Как минимум вам нужно дополнительное железо — не факт, что CI будет бесплатным. Но в любой более-менее крупной компании, да и не крупной тоже, без CI никуда не уйти.

Как пример — скриншот из TeamCity, одной из CI. Есть сборка, она завершилась успешно. В ней было много изменений, она запустилась на таком-то агенте во столько-то. Это пример того, когда все хорошо и можно вливать.
Существуют много разных CI-систем. Я написала список, если интересно, посмотрите: AppVeyor, Jenkins, Travis, CircleCI, GoCD, Buildbot. Спасибо.
Другие лекции видеокурса по Python — в посте на Хабре.
— Добрый вечер, меня зовут Маша, я работаю в отделе подготовки анализа данных Едадила, и сегодня у нас с вами лекция про тестирование.

Вначале мы с вами обсудим, какие вообще бывают виды тестирования, и я постараюсь вас убедить, зачем нужно писать тесты. Потом мы поговорим про то, что у нас есть в Python для работы непосредственно с тестами, с их написанием и вспомогательными модулями. В конце я немного расскажу про CI — неизбежную составляющую жизни в большой компании.
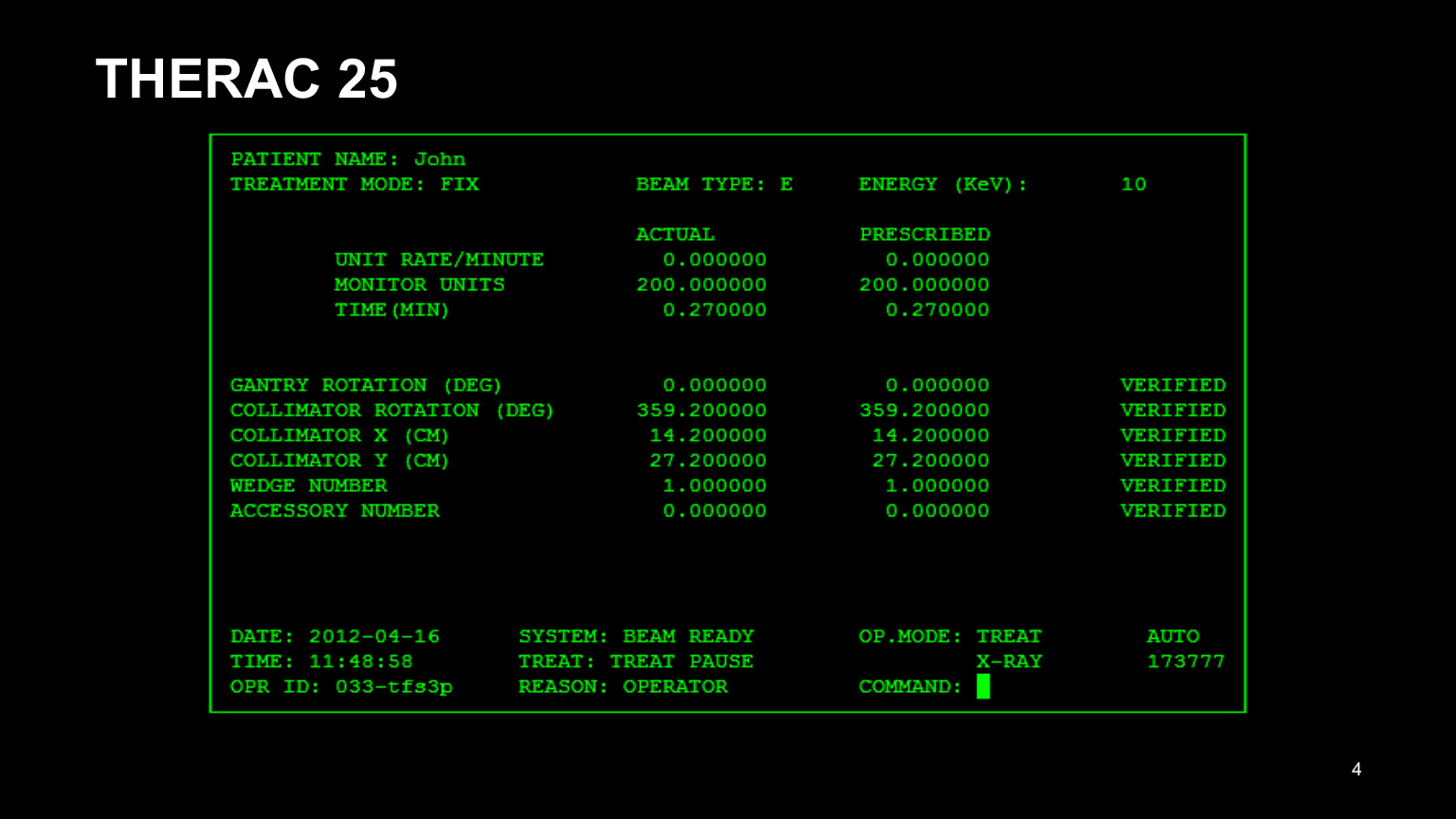
Мне хотелось бы начать с примера. Я попробую на очень страшных примерах объяснить, почему стоит писать тесты.
Перед вами интерфейс программы THERAC 25. Так назывался аппарат для лучевой терапии онкобольных, и с ним все пошло крайне неудачно. В первую очередь у него был неудачный интерфейс. Глядя на него, уже можно понять, что он не очень хороший: врачам было неудобно вбивать все эти циферки. В результате они копировали данные из карты предыдущего пациента и пытались править только то, что нужно было править.
Понятно, что они половину поправить забывали и ошибались. В результате пациентов лечили неправильно. UI тоже стоит тестировать, тестов много не бывает.
Но помимо неудачного интерфейса было ещё множество проблем в бэкенде. Я выделила две, которые показались мне самыми вопиющими:
- Деление на ноль. Существовало состояние переменной, которое можно было покрутить до очень маленькой величины. Происходило деление на ноль, и после этого величина облучения устанавливалась максимальной. Понятно, что для человека это ничем хорошим не заканчивалось.
- Cостояние гонки. В THERAC была переменная, которая отвечала за некоторую физическую величину — если я правильно помню, за поворот головки устройства. Эта же переменная использовалась для построения аналитических данных. Предположим, происходит поворот, до конца еще ничего не доехало, но из переменной взялись какие-то неправильные данные, что-то на этих данных посчиталось — и пациент получил неправильное лечение.
Стоило бы написать тесты. Потому что это закончилось пятью зафиксированными смертельными случаями, и непонятно, сколько еще людей пострадало от того, что им дали слишком большие дозы препаратов.

Есть еще один пример того, что в некоторых ситуациях написание тестов позволяет сэкономить большие деньги. Это Mars Climate Orbiter — аппарат, который должен был в атмосфере Марса произвести замеры атмосферы, посмотреть, что там с климатом.
Но модуль, который был на земле, отдавал команды в системе СИ, в метрической системе. А модуль на орбите Марса думал, что это британская система мер, неправильно это интерпретировал.
В результате модуль вошел в атмосферу под неправильным углом и разрушился. 125 млн долларов просто ушло в мусорку, хотя казалось бы, можно промоделировать ситуацию на тестах и избежать этого. Но не вышло.
Теперь я поговорю про более прозаичные причины, зачем стоит писать тесты. Давайте поговорю про каждый пункт в отдельности:
- Тесты проверяют работоспособность кода и немного вас успокаивают. В тех случаях, для которых вы тесты написали, можно быть уверенным, что код работает — если, конечно, вы его нормально написали. Сон крепче. Это очень важно.
- Тесты проверяют исполнение контрактов поведения кода. Поясню. У вас есть код, который в краевых или редких условиях, в непонятных кейсах, должен вести себя определенным образом. Вы это обговорили с заказчиком, или это написано в ТЗ. В любом случае вы договорились, что код должен вести себя именно так.
Дальше может прийти человек, который захочет написать другой код рядом или что-то порефакторить, вынести в отдельную функцию — в общем, что-то сделать с вашим кодом. Не зная об этих договоренностях, он их может легко сломать. Но тесты, если они написаны, у вашего коллеги сломаются перед отправкой в продакшен. Тогда, скорее всего, коллега подумает головой, посмотрит git blame, спросит, что это было, или просто восстановит правильное поведение, что тоже неплохо. - Тесты позволяют проверять взаимодействие старого и нового кода. Представим ситуацию, как в предыдущем пункте. У вас есть код, он работает. Пришел человек, написал новый код, захотел использовать кусочек старого. Что-то куда-то вынес, что-то где-то поправил. На случай, если он сломал существующую функциональность, хорошо бы иметь тесты, которые тоже сломаются. Иначе вы можете обнаружить это в продакшене в какой-нибудь очень неприятный момент.
- Тесты поощряют написание кода слабого зацепления, когда ваш код распадается на отдельные обособленные кусочки. Почему это связано с тестированием? Если у вас есть одна функция с кучей параметров, которая написана простыней на четыре экрана, то вы на нее посмотрите и, скорее всего, подумаете: писать тест на эту функцию неудобно, придется кучу всего передать. Возникает 500 тест-кейсов, у вас голова разрывается. Разбейте огромную функцию на много маленьких и протестируйте каждую в отдельности. Это намного проще и заодно сделает код более читаемым.
- Небольшой лайфхак: часто тесты — единственная понятная документация к коду. Предположим, вы читаете опенсорсный код внешней библиотеки, про которую ничего не знаете. Сидите, смотрите на нее как баран на новые ворота и вообще не понимаете, что она делает и с какой стороны в нее зайти.
В этот момент иногда полезно посмотреть в тесты и почитать, что там написано, потому что в тестах понятно, что приходит на входе и на выходе функции. Если вы не понимаете, что происходит в коде, то можете со стороны тестов потихонечку это поведение раскопать. - Тесты позволяют справиться с перфекционизмом и перестать улучшать код. Время — это ресурс, давайте тратить его разумно. Некоторые вещи можно улучшать до бесконечности, но не стоит, потому что от вас уже ждут новых задач. Самому порой сложно понять, в какой момент правильно остановиться.
Бывают приемочные тесты: метрики качества или какие-нибудь еще. Если они прошли, это повод пойти дальше, код готов к отправке в продакшен. При этом, возможно, стоит завести себе тикет, чтобы что-нибудь улучшить, когда появится свободное время.
Теперь мне хотелось бы немного поговорить про то, какие бывают классификации разновидностей тестирования. Их очень много. Я расскажу лишь о нескольких.
Процесс тестирования делится на тестирование черного ящика, белого и серого.
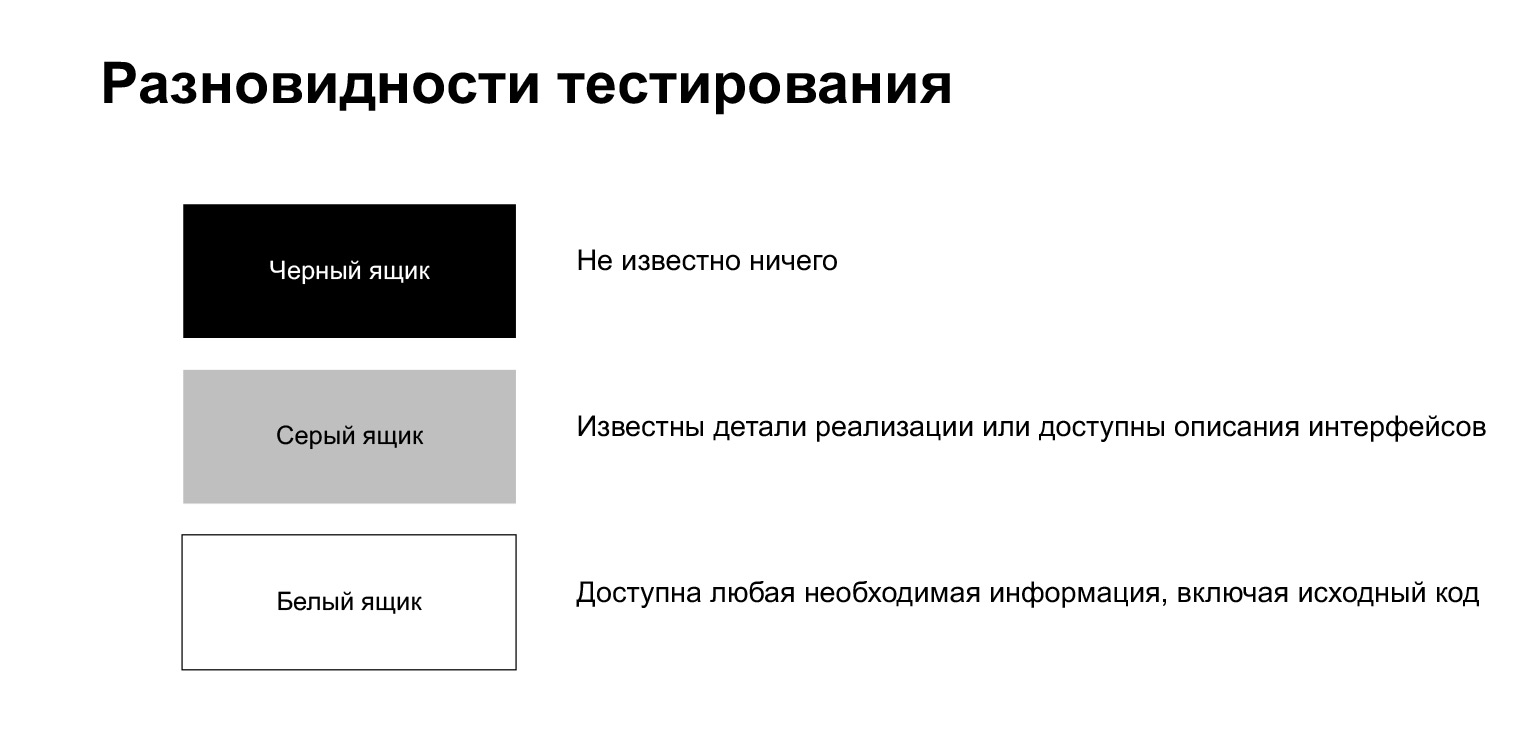
Тестирование черного ящика — процесс, когда тестировщику ничего не известно про то, что внутри. Он, как обычный пользователь, что-то делает, не зная никаких особенностей реализации.
Тестирование белого ящика означает, что тестировщику доступна любая необходимая информация, включая исходный код. Мы находимся в такой ситуации, когда пишем тест на собственный код.
Тестирование серого ящика — нечто промежуточное. Это когда вам известны какие-то детали реализации, но не вся целиком.
Также процесс тестирования можно поделить на ручной, полуавтоматический и автоматический. Ручное тестирование делает человек. Допустим, кнопочки в браузере нажимает, куда-то кликает, смотрит, что у него сломалось или не сломалось. Полуавтоматическое тестирование — это когда тестировщик запускает тестовые сценарии. Можно сказать, что мы с вами находимся в такой ситуации, когда локально свои тесты запускаем и прогоняем. Автоматическое тестирование не предполагает участия человека: тесты должны запускаться автоматически, а не руками.
Также тесты можно поделить по уровню детализации. Здесь их принято делить на юнит- и интеграционные тесты. Тут могут быть разночтения. Есть люди, которые любые автотесты называют юнит-тестами. Но более классическое деление примерно такое.
Юнит-тесты проверяют работу отдельных компонент системы, а интеграционные проверяют связку некоторых модулей. Иногда тут еще выделяют системные тесты, которые проверяют работу всей системы целиком. Но кажется, что это скорее большой вариант интеграционных тестов.
Тесты на наш код — это юнит- и интеграционные тесты. Есть люди, которые считают, что надо писать только интеграционные тесты. Я к таким не отношусь, считаю, что все должно быть в меру, и полезны как юнит-тесты, когда вы тестируете одну компоненту, так и интеграционные тесты, когда вы тестируете что-то большое.
Почему я так считаю? Потому что юнит-тесты обычно быстрее. Когда надо что-то подебажить, вас будет очень раздражать, что вы нажали на кнопку «запустить тест», а дальше три минуты ждете, пока стартанет база данных, сделаются миграции, произойдет что-то еще. Для таких случаев полезны юнит-тесты. Их можно запускать быстро и удобно, запускать по одному. Но когда вы юнит-тесты починили, прекрасно, давайте чинить интеграционные тесты.
Интеграционные тесты — вещь тоже очень нужная, большой плюс в том, что они больше про систему. Еще один большой плюс: они более устойчивы к рефакторингу кода. Если вы с большей вероятностью перепишете какую-то маленькую функцию, то общий пайплайн вы вряд ли будете менять с такой же частотой.

Бывает еще много разных классификаций. Я быстро пробегусь по тому, что здесь написала, но подробно останавливаться не буду, это слова, которые вы можете услышать где-то еще.
Smoke-тесты — тесты на критическую функциональность, самые первые и самые простые тесты. Если они сломались, то больше не надо тестировать, а надо идти их чинить. Допустим, приложение запустилось, не упало, — отлично, smoke-тест прошел.
Бывают regression-тесты — тесты на старую функциональность. Допустим, вы катите новый релиз и должны проверить, что в старом ничего не сломали. Это задача регрессионных тестов.
Бывают тесты совместимости, тесты установки. Они проверяют, что у вас все корректно работает в разных ОС и разных версиях ОС, в разных браузера и разных версиях браузера.
Acceptance-тесты — приемочные тесты. Про них я уже говорила, они говорят о том, можно ваше изменение катить в прод или нет.
Есть еще альфа- и бета-тестирование. Оба этих понятия больше относятся к продукту. Обычно, когда у вас есть более-менее готовая версия релиза, но там еще не все пофикшено, ее можно отдать либо на условно внешних, либо на внешних людей, добровольцев, чтобы они нашли вам баги, отрепортили и вы могли зарелизить совсем хорошую версию. Менее готовая — альфа-версия, более готовая — бета. В бета-тестировании почти все уже должно быть хорошо.
Дальше бывают performance- и стресс-тесты, нагрузочное тестирование. Они проверяют, допустим, как ваше приложение держит нагрузку. Есть какой-то код. Вы посчитали, сколько у него будет пользователей, запросов, какой РПС, сколько будет приходить запросов в секунду. Проэмулировали эту ситуацию, запустили, посмотрели — держит, не держит. Если не держит — думайте, что делать дальше. Возможно, оптимизировать код или увеличить количество железа, есть разные решения.
Стресс-тесты — примерно то же самое, только нагрузка выше ожидаемой. Если performance-тесты дают тот уровень нагрузки, который вы ожидаете, то в стресс-тестах вы можете увеличивать нагрузку, пока не сломается.
Немного отдельно тут стоят линтеры. Про линтеры я еще чуть позже немного скажу, это тесты оформления кода, стайл-гайд. В Python нам повезло, есть PEP8 — понятный стайлгайд, которому все должны следовать. И когда вы что-то пишете, вам обычно сложно следить за кодом. Предположим, вы забыли поставить пустую строку или сделали лишнюю, или оставили слишком длинную строчку. Это мешает, потому что вы привыкаете, что у вас код написан в едином стиле. Линтеры позволяют такие вещи автоматически отловить.
С теорией все, дальше я буду рассказывать про то, что есть в Python.

Вот список некоторых библиотек. Я не буду рассказывать подробно про все из них, но про большую часть буду. Про unittest и pytest мы, конечно, поговорим. Это библиотеки, которые используются непосредственно для написания тестов. Mock — вспомогательная библиотека по созданию mock-объектов. Про нее мы тоже поговорим. doctest — модуль для тестирования документации, flake8 — линтер, на них тоже посмотрим. Про pylama и tox я рассказывать не буду. Если вам будет интересно, можете посмотреть сами. Pylama — тоже линтер, даже, металинтер, он объединяет в себе несколько пакетов, очень удобный и хороший. А библиотека tox нужна, если вам необходимо тестировать ваш код в разном окружении — допустим, с разными версиями Python или с разными версиями библиотек. Tox в этом смысле очень помогает.
Но прежде чем рассказывать про разные библиотеки, я начну с банальности. Не стесняйтесь использовать в коде assert. Это не стыдно. Часто это помогает понять, что происходит.

Предположим, есть функция, которая считает порядковую статистику, к ней написано два assert. Assert стоит писать в функции в тех случаях, когда это совсем крайняя ерунда, которой не должно быть в коде. Это совсем крайние случаи, они, скорее всего, вам даже в продакшене не встретятся. То есть если вы накосячите в коде, оно у вас, скорее всего, должно упасть на тестах.
Assert помогают, когда вы занимаетесь прототипированием, у вас еще не продакшен-код, вы можете assert вообще везде воткнуть — в вызываемую функцию, куда угодно. Это не очень хорошо для серьезных проектов, но на этапе прототипирования вполне неплохо.
Предположим, вы по какой-то причине вы хотите отключить assert — например, хотите, чтобы это никогда не стреляло в продакшене. Для этого в Python есть специальная опция.

Расскажу, что такое doctest. Это модуль, стандартная библиотека Python, предназначенная для тестирования документации. Почему это хорошо? Документация, которая написана в коде, имеет свойство очень часто ломаться. Здесь очень маленькая игрушечная функция, все видно. Но когда у вас большой код, много параметров и вы в конце что-то дописали, то с очень большой вероятностью вы забудете поправить docstrings. Doctest позволяет таких вещей избежать. Вы что-то поправите, здесь не обновите, запустите doctest, и он у вас упадет. Так вы вспомните, что именно вы не поправили, пойдете и поправите.
Как это выглядит? Doctest ищет в docstrings эти елочки, дальше исполняет их и сравнивает то, что получается.

Вот пример запуска doctest. Запустили, видим, что у нас два теста и один из них упал — совершенно по делу. Отлично, мы увидели хорошую понятную информацию об ошибке.

Ссылка со слайда
У doctest есть полезные директивы, которые могут пригодиться. Про все из них я рассказывать не буду, но некоторые, которые мне показались наиболее употребительными, я вынесла на слайд. Директива SKIP позволяет не запускать тест на помеченном примере. Директива IGNORE_EXCEPTION_DETAIL игнорирует тест EXCEPTION. ELLIPSIS позволяет написать троеточие вместо любого места в выводе. FAIL_FAST останавливается после первого упавшего теста. Все остальное можно прочесть в документации, там очень много. Лучше покажу на примере.

В этом примере есть директива ELLIPSIS и директива IGNORE_EXCEPTION_DETAIL. Вы видите в директиве ELLIPSIS К-ю порядковую статистику, и мы ожидаем, что придет что-то, начинающееся с девятки и заканчивающееся на девятку. В середине может быть что угодно. Такой тест не упадет.
Ниже есть директива IGNORE_EXCEPTION_DETAIL, она будет проверять только то, что пришло в AssertionError. Видите, мы там написали бла-бла-бла. Тест пройдет, он не будет сравнивать бла-бла-бла с expected iterable as first argument. Он будет сравнивать только AssertionError с AssertionError. Это полезные вещи, которыми можно пользоваться.

Дальше план такой: я буду рассказывать вам про unittest, потом про pytest. Сразу скажу, что я, наверное, не знаю плюсов unittest, кроме того, что это часть стандартной библиотеки. Я не вижу ситуации, которая бы меня заставила сейчас пользоваться unittest. Но есть проекты, которые его используют, в любом случае полезно знать, как выглядит синтаксис и что оно из себя представляет.
Другой момент: тесты, написанные на unittest, умеют запускать pytest прямо из коробки. Ему все равно. (…)
Unittest выглядит так. Есть класс, начинающийся со слова test. Внутри функция, начинающаяся со слова test. Тестовый класс наследован от unittest.TestCase. Сразу скажу, что один тест тут написан правильно, а другой тест неправильно.
Верхний тест, где написан обычный assert, упадет, но это будет выглядеть странно. Давайте посмотрим.

Команда запуска. Вы можете написать в сам код unittest main, можете вызвать его из Python.

Мы запустили этот тест и видим, что он написал AssertionError, но он не написал, в каком месте он упал — в отличие от следующего теста, где использовался self.assertEqual. Тут явным образом написано: три не равно двум.

Надо чинить, конечно. Но тогда был не виден этот волшебный вывод на экране.
Давайте посмотрим еще раз. В первом случае мы написали assert, во втором self.assertEqual. К сожалению, в unittest только так. Есть специальные функции — self.assertEqual, self.assertnotEqual и еще 100500 функций, которые нужно использовать, если вы хотите увидеть адекватное сообщение об ошибке.
Почему так происходит? Потому что assert — оператор, которому приходит bool и, возможно, строка, но в данном случае bool. И он видит, что у него true или false, а левую и правую часть ему уже неоткуда взять. Поэтому в unittest есть специальные функции, которые будут корректно выводить сообщения об ошибке.
Это не очень удобно, на мой взгляд. Точнее, совсем не удобно, потому что это какие-то специальные методы, которые есть только в этой библиотеке. Они отличны от того, к чему мы привыкли в обычном языке.

Это необязательно запоминать — позже мы поговорим про pytest и, я надеюсь, вы в основном будете писать на нем. В unittest целый зоопарк функций, которые нужно использовать, если вы хотите что-то проверить и получить при этом хорошие сообщения об ошибках.
Дальше поговорим про то, как в unittest написать фикстуры. Но для этого мне сначала нужно сказать, что такое фикстуры. Это функции, которые вызываются до или после выполнения теста. Они нужны, если тесту нужно выполнить специальную настройку — создать временный файл после теста, удалить временный файл; создать базу данных, удалить базу данных; создать базу данных, написать в нее что-то. В общем, что угодно. Давайте посмотрим, как это выглядит в unittest.

Для написания фикстуры в unittest есть специальные методы setUp и tearDown. Почему они до сих пор написаны не по PEP8 — для меня большая загадка. (…)
SetUp — это то, что выполняется до теста, tearDown — то, что выполняется после теста. Мне кажется, это крайне неудобная конструкция. Почему? Потому что, во-первых, у меня рука не поднимается эти имена писать: я уже живу в мире, где все-таки есть PEP8. Во-вторых, у вас появился temp-файл, про который у вас в аргументах самого теста ничего нет. Откуда он взялся? Не очень понятно, почему он есть и что это вообще такое.
Когда у нас маленький класс, который влазит на экран, — это классно, его можно охватить взглядом. А когда у вас эта огромная простыня, вы замучаетесь искать, что это вообще было и почему он такой, почему так себя ведет.
С фикстурами в unittest есть еще одна не очень удобная особенность. Предположим, у нас есть один класс тестов, которым нужен временный файл, и другой класс тестов, которым нужна база данных. Отлично. Вы написали один класс, сделали setUp, tearDown, сделали создание/удаление временного файла. Написали другой класс, в нем тоже написали setUp, tearDown, сделали в нем создание/удаление базы данных.
Вопрос. Есть третья группа тестов, которым нужно и то и то. Что с этим всем делать? Мне видится два варианта. Либо взять и скопипастить код, но это не очень удобно. Либо создать новый класс, наследовать его от двух предыдущих, вызвать super. В целом это тоже будет работать, но выглядит как дикий overkill для тестов.

Поэтому мне хочется, чтобы ваше знакомство с unittest осталось вот таким, на теоретическом уровне. Дальше мы поговорим про более удобный способ писать тесты, более удобную библиотеку, это pytest.
Вначале я вам попробую рассказать, почему pytest — это удобно.

Ссылка со слайда
Первый момент: в pytest обычно работают assert, те, к которым вы привыкли, и они выдают нормальную информацию об ошибке. Второе: к pytest есть хорошая документация, где разобрана куча примеров, и все что угодно, все, что вы не понимаете, можно посмотреть.
Третье: тесты — это просто функции, которые начинаются на test_. То есть вам не нужного лишнего класса, вы просто пишете обычную функцию, называете ее на test_ и она будет запускаться через pytest. Это удобно, потому что чем проще писать тесты, тем больше вероятность, что вы тест напишете, а не забьете.
В pytest есть куча удобных фич. Можно писать параметризованные тесты, удобно писать фикстуры разных уровней, есть и просто красивости, которыми можно пользоваться: xfail, raises, skip, еще какие-то. В pytest есть много плагинов, плюс можно писать свои.

Давайте посмотрим на примере. Так выглядят тесты, которые написаны на pytest. По смыслу это то же самое, что и на unittest, только выглядит гораздо лаконичнее. Первый тест — вообще две строчки.

Запускаем командой python -m pytest. Отлично. Два теста прошли, все хорошо, мы видим, что они прошли и за какое время.

Теперь давайте сломаем один тест и сделаем так, чтобы у нас вывелась информация об ошибке. Вывелось assert 3 == 2 и ошибка. То есть мы видим: несмотря на то, что мы написали обычный assert, у нас корректно вывелась информация об ошибке, хотя до этого в unittest мы говорили, что assert принимает bool в строку или bool, так что информацию об ошибке вывести проблематично.
Можно задаться вопросом, почему это все работает? Потому что в pytest постарались и прибрали некрасивую часть за интерфейс. Pytest сначала делает синтаксический разбор вашего кода, и он представляется в виде некой древовидной структуры, абстрактного синтаксического дерева. В этой структуре у вас в вершинах стоят операторы, в листьях — операнды. Assert — это оператор. Он стоит в вершине дерева, и в этот момент, прежде чем отдать всё интерпретатору, можно этот assert подменить на внутреннюю функцию, которая делает интроспекцию и понимает, что у вас в левой и правой части. На самом деле интерпретатору скармливается уже вот это, с подмененным assert.
Подробно рассказывать не буду, есть ссылка, по ней можно прочитать, как они это сделали. Но мне нравится, что это все работает под капотом. пользователь этого не видит. Он пишет assert, как привык, все остальное делает сама библиотека. Можно об этом даже не задумываться.
Дальше в pytest для стандартных типов у вас и так выведется хорошая информация об ошибке. Потому что pytest знает, как эту информацию об ошибке выводить. Но вы можете у себя в тесте сравнивать кастомные типы данных, например деревья или что-то сложное, и pytest может не знать, как для них информацию об ошибке выводить. Для таких случаев можно добавить специальный хук — вот раздел в документации — и в этом хуке написать, как должна выглядеть информация об ошибке. Все очень гибко и удобно.

Посмотрим, как в pytest выглядят фикстуры. Если в unittest это необходимость писать setUp и tearDown, то здесь называйте обычную функцию как угодно. Написали сверху декоратор pytest.fixture — отлично, это фикстура.
Причем здесь еще не самый простой пример. Фикстура может просто делать return, что-то возвращать, это будет аналог setUp. В данном случае она сделает еще как бы tearDown, то есть именно здесь, после окончания теста, она вызовет close, и временный файлик удалится.
Кажется, это удобно. У вас есть произвольная функция, которую вы можете как угодно назвать. Вы ее явно в тест передаете. Передали filled_file, знаете, что это она. От вас не требуется ничего специального. В общем, пользуйтесь. Это намного удобнее, чем в unittest.

Еще немного про фикстуры. В pytest очень легко создать фикстуры разных scope. По дефолту фикстура создается с уровнем function. Это значит, что она будет вызываться на каждый тест, куда вы ее передали. То есть если есть yield или что-то еще а-ля tearDown, это тоже будет происходить после каждого теста.
Вы можете объявить scope='module', и тогда фикстура будет выполняться один раз на модуль. Допустим, вы хотите один раз создать базу данных и не хотите после каждого теста удалять и накатывать все миграции.
Еще в фикстурах есть возможность указать аргумент autouse=True, и тогда фикстура будет вызываться независимо от того, попросили вы ее или нет. Кажется, что этой опцией не нужно пользоваться никогда, или нужно, но очень осторожно, потому что это неявная вещь. Неявного лучше избегать.

Мы запустили этот код — посмотрим, что получилось. Есть test one, который зависит от фикстуры call me once use when needed, call me every time. При этом call me once use when needed — фикстура уровня модуля. Видим, что первый раз у нас вызвались фикстуры call me once use when needed, call me every time, которые это выводят, но еще вызвалась фикстура с autouse, потому что ей все равно, она всегда вызывается.
Второй тест зависит от тех же самых фикстур. Видим, что у нас второй раз call me once use when needed не напечаталась, потому что она уровня модуля, она один раз уже вызвалась и она больше вызываться не будет.
Кроме того, из этого примера видно, что в pytest нет таких проблем, о которых мы с вами говорили в unittest, когда в одном тесте вам может быть нужна база данных, в другом — временный файл. Как их нормально сагрегировать, непонятно. Вот ответ на этот вопрос в pytest. Если передали две фикстуры, то внутри и будет две фикстуры.
Прекрасно, очень удобно, никаких проблем. Фикстуры очень гибкие, они могут зависеть от других фикстур. В этом нет никакого противоречия, и pytest сам вызовет их в нужном порядке.

На самом деле внутри можно отнаследовать фикстуры от других фикстур, сделать их разного scope, и autouse без autouse. Он сам их расставит в правильном порядке и вызовет.
Здесь у нас есть первый тест, test one, который зависит от rare_dependency_for_test_one, где эта фикстура зависит от другой фикстуры — и еще от одной. Давайте посмотрим, что будет на выхлопе.
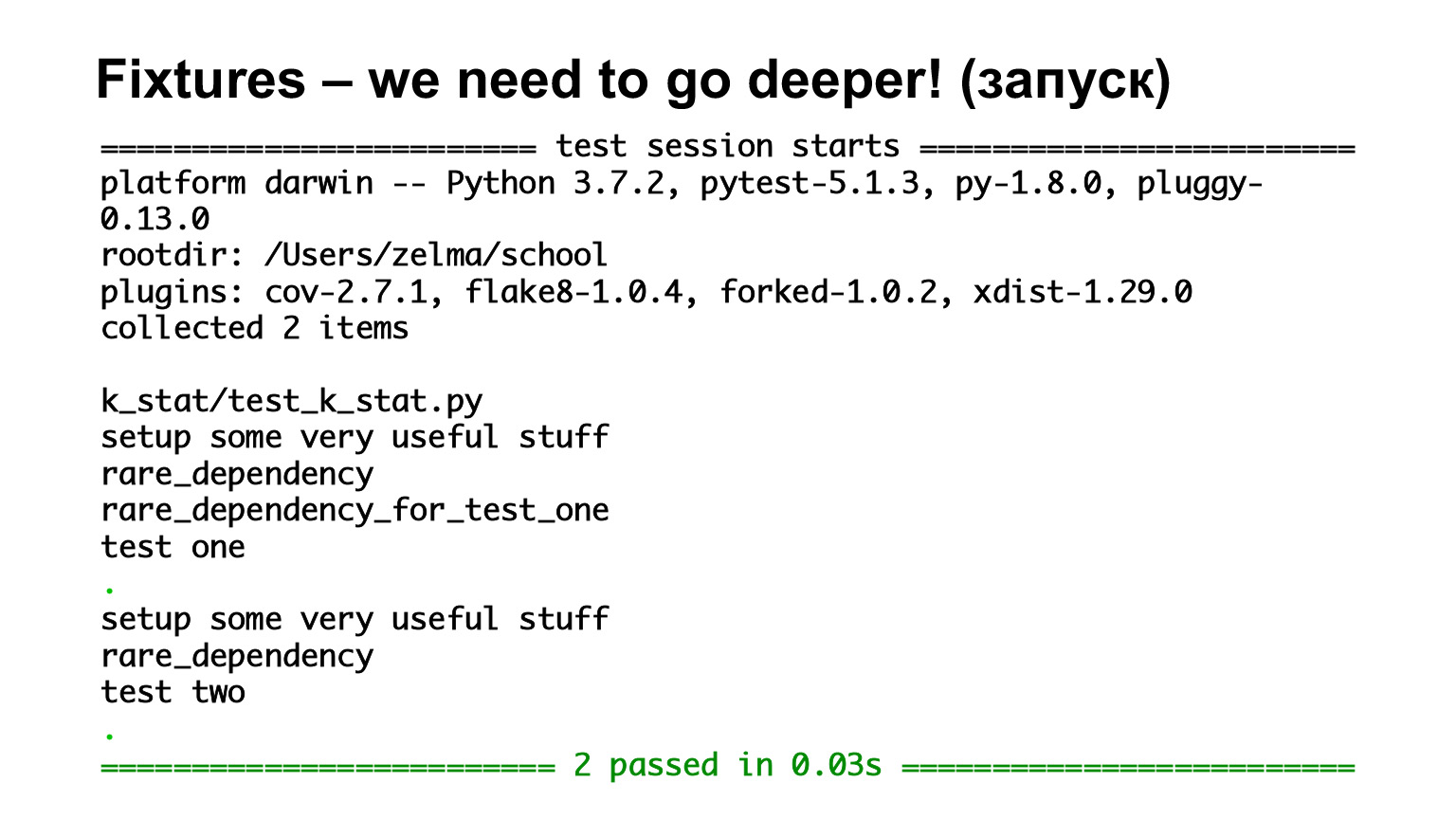
Мы видели, что они вызываются, причем в порядке наследования. Тут все фикстуры уровня функции, поэтому все они вызываются на каждый тест. Второй тест зависит от rare_dependency, а rare_dependency зависит от some_common_dependency. Смотрим на выхлоп и видим, что перед тестом вызвались две фикстуры.
В pytest есть специальный конфигурационный файл conftest.py, куда вы можете положить все фикстуры, и хорошо, если положите: обычно, когда человек смотрит на чужой код, он обычно пойдет смотреть фикстуры в conftest.
Это не обязательно. Если есть фикстура, которая вам нужна только в этом файле, и вы точно знаете, что она специфичная, узкоприменимая, и в другом файле не понадобится, то можете объявить ее в файле. Либо создавать много conftest, и они все будут работать на разных уровнях.

Поговорим про фичи, которые бывают в pytest. Как я уже говорила, очень легко делать параметризацию тестов. Здесь мы видим тест, у которого три набора параметров: два входных и тот, что ожидается. Мы их передаем в аргументы функции и смотрим, совпадает ли то, что мы передали на вход, с тем, что ожидается.

Посмотрим, как это выглядит. Видим, что здесь три теста. То есть pytest считает, что это три теста. Два прошло, один упал. Что здесь хорошо? Для того теста, который упал, мы видим аргументы, видим, на каком наборе параметров он упал.
Опять же, когда у вас маленькая функция и в parametrize написано — три штуки, возможно, вы и глазами увидите, что именно упало. Но когда наборов в параметрах много, вы это глазами не увидите. Вернее, увидите, но вам будет очень сложно. И очень удобно, что pytest так все выводит — вы сразу можете посмотреть, в каком именно случае тест упал.

Parametrize — хорошая штука. И когда вы написали тест один раз, а дальше делаете много-много наборов параметров — это хорошая практика. Не делать много вариантов кода на похожие тесты, а один раз написать тест, дальше сделать большой набор параметров, и оно будет работать.
В pytest есть еще много всяких удобных штук. Если о них рассказывать, лекции явно не хватит, поэтому я покажу, опять же, только несколько. В первом тесте используется pytest.raises(), чтобы показать, что вы ожидаете исключения. То есть в данном случае, если вызовется AssertionError, тест пройдет. У вас должно броситься исключение.
Вторая удобная штука — xfail. Это декоратор, который разрешает тесту падать. Допустим, у вас есть много тестов, много кода. Вы что-то порефакторили, тест начал падать. При этом вы понимаете, что либо он не критичный, либо чинить его придется очень дорого. И вы такие: ладно, навешу на него декоратор, он станет зелененьким, починю его потом. Или предположим, тест начал флакать. Понятно, что это договоренность с собственной совестью, но иногда это бывает нужно. Причем xfail в таком виде будет зелененьким независимо от того, упал тест или нет. Ему еще можно передать в параметр Strict = True, тогда это будет немножко другая ситуация, pytest будет ждать, что тест упадет. Если тест пройдет, то вернется сообщение об ошибке, и, наоборот.
Еще одна полезная штука — skipif. Есть просто skip, который не будет запускать тесты. И есть skipif. Если вы навесите этот декоратор, тест не будет запускаться при определенных условиях.
В данном случае написано, что если у меня платформа Mac, то не запускайся, потому что тест почему-то падает. Бывает. Но в целом бывают платформозависимые тесты, которые всегда будут падать на определенной платформе. Тогда это полезно.

Давайте запустим. Увидели буковку X, увидели S. X у нас относится к xfail, S — к skipif. То есть pytest показывает, какой тест мы совсем пропустили, а какой запустили, но не смотрим на результат.

В самом pytest есть много разных полезных опций. Я, конечно, не смогу вывести их сюда, можно посмотреть в документации. Но про несколько я расскажу.
Вот полезная опция --collect-only. Она выводит список найденных тестов. Есть опция -k — фильтрация по имени теста. Это одна из моих самых любимых опций: если у вас один тест свалился, особенно если он сложный и вы пока не знаете, как его чинить, — пофильтруйте и запускайте его.
Вам хочется сэкономить время и, наверное, неинтересно запускать 15 других тестов — вы знаете, что они проходят или падают, но пока до них не дошли. Запускайте тест, который падает, чините его и идите дальше.
Еще есть очень хорошая опция -s, она включает вывод из stdout и stderr в тестах. По дефолту pytest будет выводить stdout и stderr только для упавших тестов. Но есть моменты, обычно на этапе отладки, когда вы хотите что-то в тесте вывести и не знаете, упадет ли тест. Может, и не упадет, но вы хотите в самом тесте увидеть, что туда приходит, и вывести. Тогда запускайте с -s — и вы увидите то, что хотели.
-v — стандартная опция verbose, повысить детализацию.
--lf, --last-failed — опция, которая позволяет перезапустить только те тесты, которые упали в последнем запуске. --sw, --stepwise — тоже полезная функция, как и -k. Если вы чините тесты последовательно, то запускаете со --stepwise, она проходит по зелененьким, а как только видит упавший тест, останавливается. И когда вы еще раз запустите --sw, она запустится с этого теста, который падал. Если опять упадет, она опять остановится, если не упадет — пойдет дальше до следующего падения.

Ссылка со слайда
В pytest есть основной конфигурационный файл pytest.ini. В нем можно изменить поведение pytest по умолчанию. Я здесь привела опции, которые очень часто встречаются в конфигурационном файле.
Testpaths — пути, в которых pytest будет искать тесты. addopts — то, что добавляется в командную строку при запуске. Здесь у меня в addopts добавлены плагины flake8 и coverage. Мы чуть позже на них посмотрим.

Ссылка со слайда
В pytest есть очень много разных плагинов. Я написала те, которые, опять же, используются повсеместно. flake8 — это линтер, coverage — покрытие кода тестами. Дальше есть целый набор плагинов, которые облегчают работу с теми или иными фреймворками: pytest-flask, pytest-django, pytest-twisted, pytest-tornado. Наверное, еще что-нибудь есть.
Плагин xdist используется, если вы хотите запускать тесты параллельно. Плагин timeout позволяет ограничить время работы теста: это пригождается. Вы вешаете на тест декоратор timeout, и если тест работает дольше, он сваливается.

Давайте посмотрим. Я в pytest.ini добавила coverage и flake8. Сoverage мне выдал отчет, у меня там файл с тестами, что-то из него не вызвалось, но это ничего :)
Вот файл k_stat.py, в нем нашлось целых пять стейтментов. Это примерно то же самое, что пять строчек кода. И покрытие 100%, но это потому, что у меня файлик очень маленький.
На самом деле покрытие обычно не бывает стопроцентным, и более того, не стоит его добиваться всеми способами. Субъективно кажется, что покрытие тестами 60-70% — это вполне достаточно и нормально для работы.
Сoverage — такая метрика, которая даже будучи стопроцетной не говорит, что вы молодец. То, что вы вызвали этот код, не значит, что вы что-то проверили. Вы можете еще assert True в конце написать. К coverage нужно подходить разумно, для стопроцентного покрытия тестами есть файзинг и роботы, а людям так делать не надо.
В pytest.ini я подключила еще один плагин. Здесь видно --flake8, это линтер, который показывает мои стилевые ошибки, и некоторые другие, уже не из PEP8, а из pyflakes.

Тут в выхлопе написан номер ошибки в PEP8 или в pyflakes. В целом все понятно. Строчка слишком длинная, для redefinition нужно две пустые строки, нужна пустая строка в конце файла. В конце написано, что у меня CitizenImport не используется. В общем, линтеры позволяют ловить грубые ошибки и ошибки в оформлении кода.

Мы с вами уже говорили про плагин timeout, он позволяет ограничить время работы теста. Для некоторых перфтестов важно время работы. И вы можете ограничить его внутри тестов с помощью time.time и timeit. Либо с помощью плагина timeout, что тоже очень удобно. Если тест работает слишком много, его можно попрофилировать разными способами, например cProfile, но про это будет рассказывать Юра в своей лекции.
Если вы пользуетесь IDE, а пользоваться вспомогательными средствами стоит, у меня тут, в частности, PyCharm, то тесты очень легко запустить прямо из него.

Осталось поговорить про mock. Представим, у нас есть модуль A, мы хотим его протестировать и есть другие модули, которые мы тестировать не хотим. Один из них ходит в сеть, другой в базу данных, а третий — простой модуль, который нам ничем не мешает. В таких случаях нам поможет mock. Опять же, если мы пишем интеграционный тест, то, скорее всего, поднимем тестовую базу данных, напишем тестового клиента, и это тоже прекрасно. Это просто интеграционный тест.
Бывают случаи, когда мы хотим сделать unittest, когда мы хотим протестировать только один кусочек. Тогда нам нужен mock.

Mock — это набор объектов, которыми можно подменить настоящий объект. На любое обращение к методам, к атрибутам он возвращает тоже mock.

В этом примере у нас есть простой модуль. Мы его оставим, а какие-то более сложные заменим на mock. Сейчас мы посмотрим, как это работает.

Тут показано наглядно. Мы его проимпортировали, говорим, что m — это mock. Вызвали, вернулся mock. Сказали, что у m есть метод f. Вызвали, вернулся mock. Сказали, что m есть атрибут is_alive. Отлично, вернулся еще один mock. И мы видим, что m и f вызвались по одному разу. То есть это такой хитрый объект, внутри у которого переписан метод getattr.

Давайте посмотрим на более понятном примере. Допустим, есть AliveChecker. Он использует какую-то http_session, ему нужен таргет, и у него есть функция do_check, которая возвращает True или false в зависимости от того, что ему пришло: 200 или не 200. Это немножко искусственный пример. Но предположим, что внутри do_check можно накрутить сложную логику.
Допустим, мы не хотим ничего тестировать про сессию, не хотим ничего знать про метод get. Мы хотим протестировать только do_check. Отлично, давайте протестируем.

Можно это сделать так. Мокаем http_session, здесь она называется pseudo_client. Мокаем у нее метод get, говорим, что get — это такой mock, который возвращает 200. Запускаем, создаем от этого всего AliveChecker, запускаем. Этот тест будет работать.
В дополнение давайте проверим, что get вызвался один раз и ровно с такими аргументами, как там написано. То есть мы вызвали do_check, ничего не зная ни про то, что это за сессия, ни про то, что у него за методы. Мы их просто замокали. Единственное, что мы знаем, — что он вернул 200.

Другой пример. Он очень похож на предыдущий. Единственное, здесь вместо return_value написан side_effect. Но это что-то, что mock выполняет. В данном случае он бросает исключение. Строчка с assert поменяна на assert not AliveChecker.do_check(). То есть мы видим, что проверка не пройдет.
Это два примера, как протестировать функцию do_check, не зная ничего про то, что в нее сверху пришло, что пришло в этот класс.
Пример, конечно, выглядит искусственным: не совсем понятно, зачем проверять, 200 или не 200, здесь просто минимум логики. Но давайте представим, что в зависимости от кода возврата делается нечто хитрое. И тогда такой тест начинает казаться гораздо более осмысленным. Мы увидели, что приходит 200, а дальше проверяем обрабатывающую логику. Если не 200 — то же самое.

Еще с помощью mock можно патчить библиотеки. Допустим, у вас уже есть библиотека, и в ней надо что-то поменять. Тут пример, мы запатчили синус. Теперь он у нас всегда возвращает двойку. Отлично.
Еще мы видим, что m вызвалась два раза. Mock ничего, конечно, не знает про внутренние API методов, которые вы мокаете и вообще, не обязан с ними совпадать. Но mock позволяет проверить, что вы вызвали, сколько раз и с какими аргументами. В этом смысле он помогает тестировать код.

Я хочу предостеречь вас от случая, когда остается один модуль и огромный mock. Подходите, пожалуйста, ко всему разумно. Если у вас есть простые штуки, не надо их мокать. Чем больше mock у вас в тесте, тем больше вы уходите от реальности: у вас может не совпадать API, и вообще это не совсем то, что вы тестируете. Без необходимости не надо мокать все подряд. Подходите к процессу разумно.

У нас осталась последняя маленькая часть про Continuous Integration. Когда вы одни разрабатываете пет-проджект, вы можете запускать тесты локально, и ничего страшного, они будет работать.
Как только проект вырастает и разработчиков в нем становится больше одно, это перестает работать. Во-первых, половина не будет запускать тесты локально. Во-вторых, они будут запускать их на своих версиях. Где-то будут конфликты, все будет постоянно ломаться.
Для этого есть Continuous Integration, практика разработки, которая заключается в быстром вливании кандидатов в основную ветку. Но при этом они должны пройти некую автосборку или автотесты в специальной системе. У вас есть код в репозитории, коммиты, которые вы хотите влить в вашу ветку основную проекта. На этих коммитах в специальной системе проходят тесты. Если тесты зелененькие, то либо коммит вливается сам, либо у вас появляется возможность его влить.
У такой схемы, конечно, есть свои недостатки, как и у всего. Как минимум вам нужно дополнительное железо — не факт, что CI будет бесплатным. Но в любой более-менее крупной компании, да и не крупной тоже, без CI никуда не уйти.
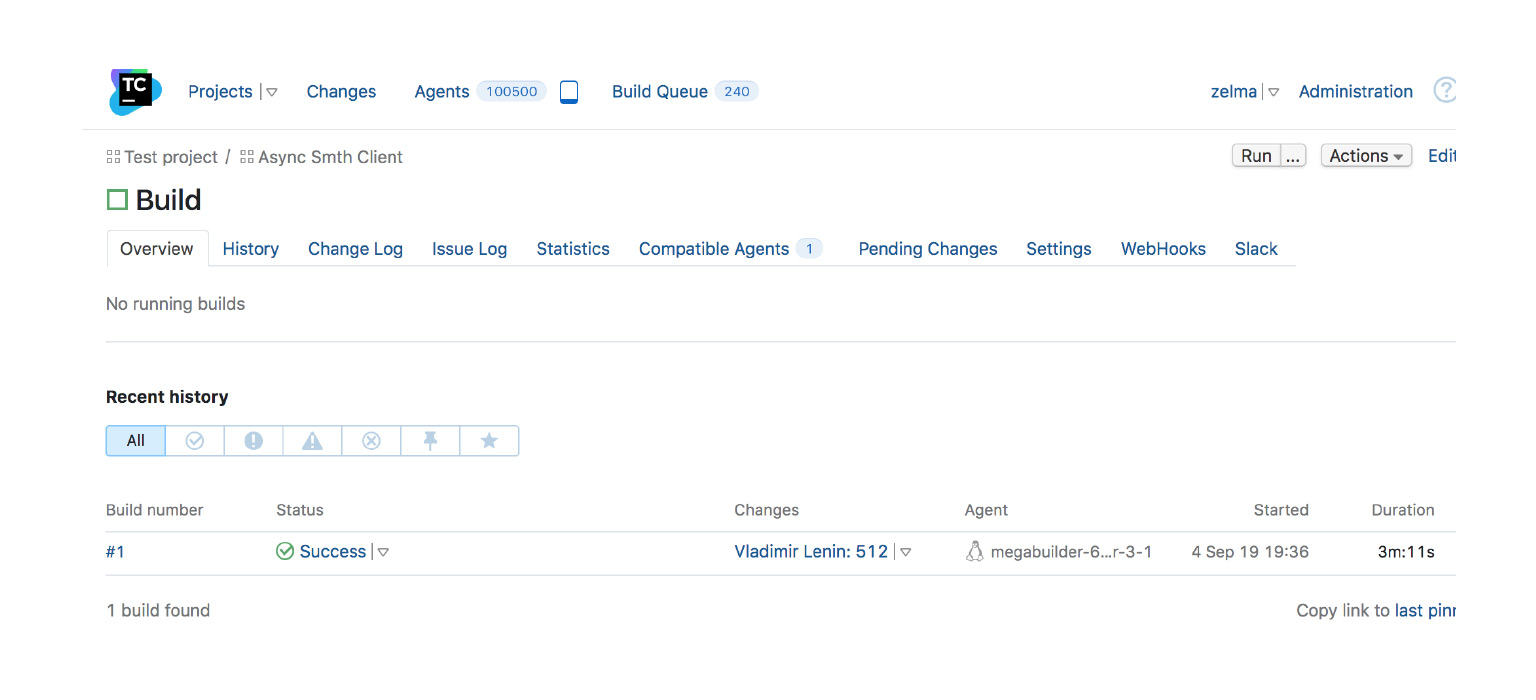
Как пример — скриншот из TeamCity, одной из CI. Есть сборка, она завершилась успешно. В ней было много изменений, она запустилась на таком-то агенте во столько-то. Это пример того, когда все хорошо и можно вливать.
Существуют много разных CI-систем. Я написала список, если интересно, посмотрите: AppVeyor, Jenkins, Travis, CircleCI, GoCD, Buildbot. Спасибо.
Другие лекции видеокурса по Python — в посте на Хабре.
