
Пару недель назад Даня Тарарухин рассказал на Хабре, как появился наш сервис, Яндекс.Маршрутизация, и как он помогает компаниям с логистикой. Создавая платформу, мы решили несколько интересных проблем, одной из которых и посвящён сегодняшний пост. Я хочу поговорить о самом планировании маршрутов и необходимых для этого ресурсах.
Поиск оптимального маршрута между множеством точек — классическая задача дискретной оптимизации. Для её решения нужно знать расстояния и времена в пути между всеми точками. То есть — знать матрицу расстояний и времён. Ещё два года назад долгое вычисление матрицы было для нас очень критичной проблемой и блокировало развитие. Сам поиск оптимального решения при известной матрице занимал 10 минут, а вот вычисление всех ячеек матрицы для больших задач (на несколько тысяч заказов) занимало часы.
Чтобы решить задачу с пятью тысячами заказов, нужно знать расстояния и времена в пути между всеми точками. Это две матрицы чисел размерностью 5000х5000. Мы планируем маршруты курьеров на весь день, и утром курьер доедет от точки до точки за одно время, а вечером — за другое. Значит, нужно вычислять матрицы времён и расстояний для каждого часа дня. Не все часы дня уникальны, но пробочное время (утро и вечер) нужно покрыть хорошо. Поэтому мы пришли к конфигурации с тринадцатью часовыми срезами. Итого нам нужно два куба (времён и расстояний) размерностью 13х5000х5000 каждый. Это 325 млн маршрутов, посчитанных по реальному графу дорог, в котором 165 млн ребёр. Расчёт одного маршрута в хорошо оптимизированном алгоритме команды Яндекс.Карт занимает порядка 10 мс, суммарно получаем 900 часов вычислений. Даже при распараллеливании на 900 CPU нужно ждать 1 час. Такой сервис мы не могли запустить, нужен был более подходящий алгоритм.
Для дальнейшего чтения полезно знать алгоритм Дейкстры для поиска кратчайшего пути в графе. Его можно представить как «волну», исходящую из точки старта маршрута и идущую кругом по всему графу до тех пор, пока не встретится точка финиша. Время работы алгоритма при этом пропорционально пройденным рёбрам графа, то есть площади, которую покрыла волна:

Почти каждый кандидат в разработчики на собеседовании догадывается до первого шага оптимизации такой задачи: можно запускать волну с двух сторон и заканчивать поиск, когда волны встретятся. Суммарная площадь двух волн половинного радиуса меньше одной большой.

Реальный граф дорог достаточно сильно структурирован, и это можно использовать. Когда вы ищете кратчайшее расстояние между Москвой и Питером, в классической Дейкстре вы будете вынуждены распространять волну по кругу и перебирать все улицы и переулки Москвы, подмосковных городов и деревень, улицы Твери и Новгорода. Это огромный объём вычислений, но можно заранее подготовиться и запомнить оптимальные маршруты между городами (aka шорткаты) и не повторять их в рантайме. Тогда для поиска маршрута между двумя точками в иерархической Дейкстре вам останется посчитать кратчайшие расстояния до нужного шортката. Так как уровней иерархии может быть не два, а 5-6, то они драматически снижают время поиска.
Команда роутера Карт уже достаточно давно реализовала такие оптимизации. Именно они позволили достичь 10 мс для поиска маршрута между двумя точками. :) Так что пока мы не приблизились к решению нашей проблемы.
Раз режим поиска точка-точка уже предельно оптимизирован, мы можем оптимизировать расчёт ряда в матрице. Ряд — это расстояния от одной точки до всех остальных. Пока мы ищем расстояние до самой дальней точки, мы попутно вычисляем расстояния до более близких. Значит, вычисление ряда эквивалентно вычислению расстояния до самой дальней точки.

Смотрим на время вычисления ряда по такому алгоритму и вспоминаем, что последовательное вычисление 5000 маршрутов заняло бы порядка 5000 * 10 мс = 50 с:

На графике показано время вычисления строки в матрице расстояний размером 1*N для разных N (по реальным данным). Видно, что вычисление строки интересующего нас размера 1*5000 укладывается в 1,3 секунды. На график добавлена линия тренда, которая показывает, что время вычислений растет чуть медленнее, чем линейно по N, порядок N**0.74
Уже неплохо! С таким алгоритмом мы можем посчитать наш куб за 13 * 5000 * 1,3 с = 84 500 с = почти 24 часа. Он легко параллелится по рядам, и при использовании 50 CPU расстояния вычисляются за полчаса. Порядок сложности алгоритма вычисления куба — O(N**1.74):
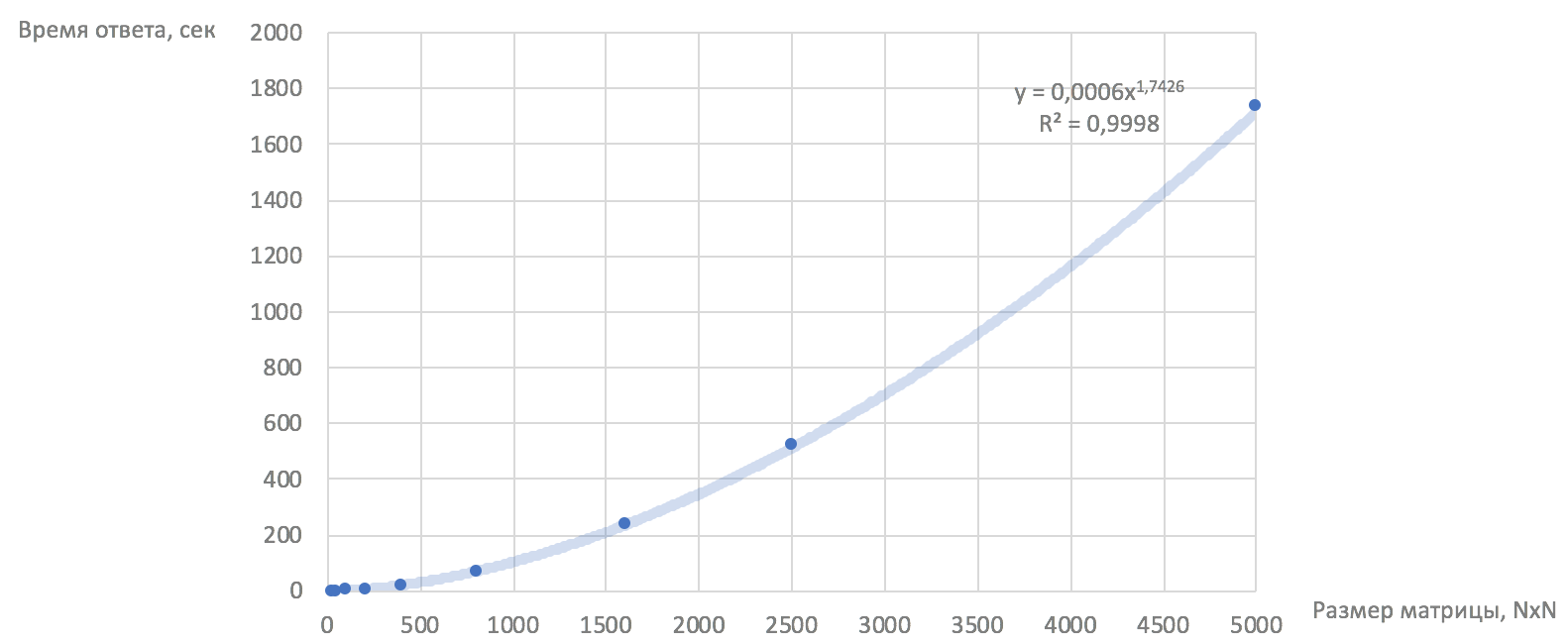
График оценочного времени вычисления 13 матриц размером N*N по рядам на 50 CPU (домножили предыдущий график на 13*N/50). По этому графику мы принимали решение, что если к нам придет клиент с 5000 заказов, то мы должны уложиться в полчаса со всеми тринадцатью часовыми срезами. А вот если заказов станет 10 000, то всё плохо: придётся добавлять железо или увеличивать время.
В таком виде два с половиной года назад мы запустили первую версию нашего API, решающего логистическую задачу. Клиенты достаточно часто жаловались на долгое время решения, и их легко понять: ты запустил задачу решаться, ждёшь 1 час, получаешь решение и понимаешь, что забыл поправить время смены у водителя, исправляешь и всё начинается сначала. Водители начинают нервничать, так как рискуют попасть в утренний час пик, а то и вовсе не успеют доставить заказ в срок. Нужно было что-то делать. «Закидывать» проблему железом не хотелось: мы готовились к большим нагрузкам, потребовалось бы много железа, да и закупка серверов происходит не одномоментно.
Изучение академических статей показало, что, оказывается, для этой задачи есть алгоритмы с линейной сложностью*! (В статье по ссылке есть большой обзор всевозможных современных способов ускорения Дейкстры, в том числе и для матричного случая.) Вычислять матрицу за линейное время — это не укладывалось в голове. Один из наших разработчиков вызвался написать прототип, и вот что получилось:

Время вычисления одной матрицы размера N*N на одном CPU с помощью алгоритма «быстрых матриц». Сложность получается порядка O(N**1,1). Высокие N выбиваются из линии тренда, поскольку на время уже больше влияет генерация ответа и его скачивание по сети.
115 секунд на матрицу 5000х5000 при использовании одного ядра и почти линейная зависимость от N. Фантастика стала реальностью! Идея алгоритма комбинирует две описанные выше идеи: Дейкстру для рядов и иерархический поиск. Очевидно, что, начав вычислять второй ряд, мы в какой-то момент вновь будем обходить ту же область графа, которую мы только что проходили, вычисляя предыдущий ряд. Поэтому давайте запоминать в узлах иерархического графа кратчайшие расстояния до всех destinations. Когда мы начнём вычислять следующий ряд, то, дойдя до такого узла, мы разом получим почти все расстояния до других точек.

Полтора года назад это позволило нам сэкономить полчаса времени седения волос логиста и существенно уменьшить потребление железа. Если раньше на один большой запрос нам требовалось 50 ядер на полчаса, то теперь — 13 ядер на 2 минуты. Это примерно 200 000 маршрутов в секунду на ядро. Тот редкий случай, когда новый алгоритм не просто закрывает класс проблем, а расширяет наши представления о возможном.
* Статья «Route Planning in Transportation Networks», см. параграф 2.7.2 «Batched Shortest Paths»
