
Несколько месяцев назад наши коллеги из Google провели на Kaggle конкурс по созданию классификатора изображений, полученных в нашумевшей игре «Quick, Draw!». Команда, в которой участвовал разработчик Яндекса Роман Власов, заняла в конкурсе четвертое место. На январской тренировке по машинному обучению Роман поделился идеями своей команды, финальной реализацией классификатора и интересными практиками соперников.
— Всем привет! Меня зовут Рома Власов, сегодня я вам расскажу про Quick, Draw! Doodle Recognition Challenge.

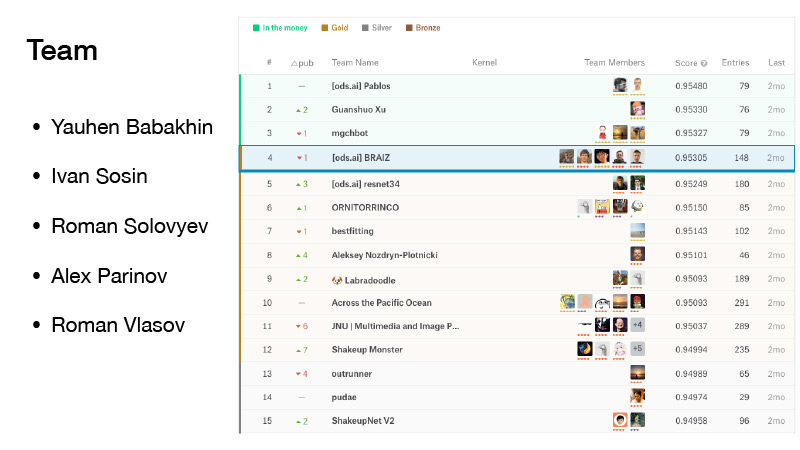
В нашей команде было пять человек. Я присоединился к ней прям перед мерж-дедлайном. Нам не повезло, нас немного шейкапнуло, но нас шейкапнуло из money, а их с позиции gold. И мы заняли почетное четвертое место.
(Во время соревнования команды наблюдали себя в рейтинге, который формировался по результатам, показанным на одной части предложенного набора данных. Финальный рейтинг, в свою очередь, формировался по другой части датасета. Так делают, чтобы участники соревнования не подстраивали свои алгоритмы под конкретные данные. Поэтому в финале, при переключении между рейтингами, позиции немного «шейкапятся» (от англ. shake up — перемешаться): на других данных и результат может оказаться другим. Команда Романа сначала была в тройке лидеров. В данном случае тройка — это money, денежная зона рейтинга, поскольку только за первые три места полагался денежный приз. После «шейк апа» команда оказалась уже на четвертом месте. Точно так же другая команда потеряла победу, позицию gold. — Прим. ред.)

Также соревнование было знаменательно тем, что Евгений Бабахнин получил за него грандмастера, Иван Сосин — мастера, Роман Соловьев так и остался грандмастером, Алекс Паринов получил мастера, я стал экспертом, а сейчас я уже мастер.

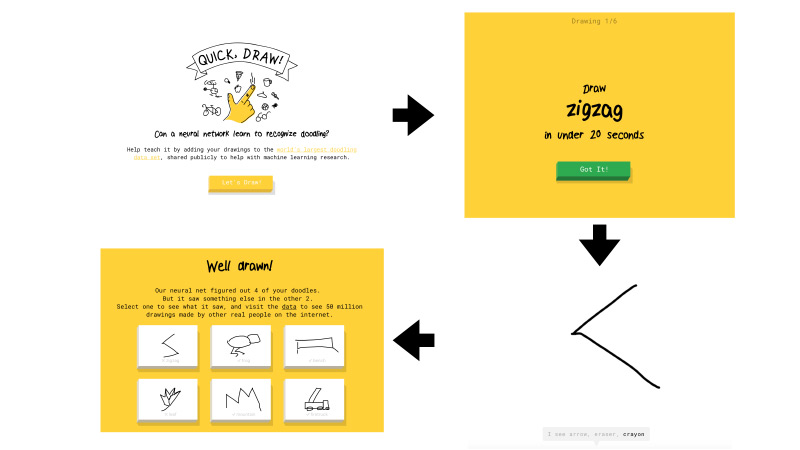
Что это за Quick, Draw? Это сервис от Google. Google преследовал цель популяризировать ИИ и этим сервисом хотел показать, как нейронные сети работают. Вы туда заходите, нажимаете Let’s draw, и вам вылезает новая страничка, где вам говорят: нарисуйте зигзаг, у вас на это есть 20 секунд. Вы пытаетесь нарисовать за 20 секунд зигзаг, как здесь, например. Если у вас все получается, сеть говорит, что это зигзаг, и вы идете дальше. Таких картинок всего шесть.
Если сети от Google не удалось распознать, что вы нарисовали, на задании ставился крестик. Позже я расскажу, что в дальнейшем будет значить, распознан рисунок сетью или нет.
Этот сервис собрал довольно большое количество пользователей, и все картинки, которые пользователи рисовали, логировались.

Удалось собрать почти 50 млн картинок. Из этого формировался трейн и тест дата для нашего соревнования. Кстати, количество данных в тесте и количество классов не зря выделено жирным шрифтом. Я о них расскажу чуть позже.
Формат данных был следующий. Это не просто RGB-картинки, а, грубо говоря, лог всего, что делал пользователь. Word — это наш таргет, countrycode — это то, откуда родом автор дудла, timestamp — время. Лейбл recognized как раз показывает то, распознала сеть от Google картинку или нет. И сам drawing — последовательность, аппроксимация кривой, которую пользователь рисует точками. И тайминги. Это время от начала рисования картинки.
Данные были представлены в двух форматах. Это первый формат, а второй — упрощенный. Они оттуда выпилили тайминги и аппроксимировали этот набор точек меньшим набором точек. Для этого они использовали алгоритм Дугласа-Пекера. У вас большой набор точек, который просто аппроксимирует какую-то прямую линию, а вы на самом деле можете эту линию аппроксимировать всего двумя точками. В этом и состоит идея алгоритма.
Данные были распределены следующим образом. Все равномерно, но есть некоторые выбросы. Когда мы решали задачу, то на это не смотрели. Главное, что не было тех классов, которых реально мало, нам не приходилось делать weighted samplers и data oversampling.

Как выглядели картинки? Это класс «самолет» и примеры из него с метками recognized и unrecognized. Соотношение их было где-то 1 к 9. Как видно, данные достаточно шумные. Я бы предположил, что это самолет. Если же посмотреть на not recognized, это в большинстве случаев просто шум. Кто-то даже пытался написать «самолет», но видимо, по-французски.
Большинство участников просто брали сетки, отрисовывали данные из этой последовательности линий как RGB-картинки и закидывали в сеть. Примерно так же отрисовывал и я: брал палитру цветов, первую строку отрисовывал одним цветом, который был в начале этой палитры, последнюю — другим, который в конце палитры, а между ними везде делал интерполяцию по этой палитре. Кстати, это давало лучший результат, чем если вы будете рисовать как на самом первом слайде — просто черным цветом.
Другие участники команды, например Иван Сосин, пробовали немного другие подходы к рисованию. Одним каналом он просто рисовал серую картинку, другим каналом — рисовал каждый штрих градиентом от начала до конца, с 32 до 255, а третим каналом рисовал градиент по всем штрихам от 32 до 255.
Еще из интересного — Алекс Паринов закидывал информацию в сеть по countrycode.

Метрика, которая использовалась в соревновании, это Mean Average Precision. В чем суть этой метрики для соревнования? Вы можете отдать три предикшина, и если в этих трех предикшинах нет правильного, то вы получаете 0. Если есть правильный, то учитывается его порядок. И результат по таргету будет считаться как 1, деленное на порядок вашего предсказания. Например, вы сделали три предикшина, и правильный из них первый, то вы 1 делите на 1 и получаете 1. Если предикшин верный и его порядок 2, то 1 делите на 2, получаете 0,5. Ну и т. д.

С предобработкой данных — как рисовать картинки и так далее — мы немного определились. Какие архитектуры мы использовали? Мы пытались использовать жирные архитектуры, такие как PNASNet, SENet, и такие уже классические архитектуры как SE-Res-NeXt, они все больше заходят в новых соревнованиях. Также были ResNet и DenseNet.



Как мы это обучали? Все модели, которые мы брали, мы брали сами предобученными на imagenet. Хотя данных много, 50 млн картинок, но все равно, если вы берете сеть, предобученную на imagenet, она показывала лучший результат, чем если вы будете просто обучать ее from scratch.
Какие техники для обучения мы использовали? Это Cosing Annealing with Warm Restarts, о ней я поговорю чуть позже. Это техника, которую я использую практически во всех моих последних соревнованиях, и с ними получается довольно хорошо обучить сетки, достичь хорошего минимума.

Дальше Reduce Learning Rate on Plateau. Вы начинаете обучать сеть, задаете какой-то определенный learning rate, дальше ее учите, у вас постепенно loss сходится к какому-то определенному значению. Вы это чекаете, например, на протяжении десяти эпох loss никак не поменялся. Вы уменьшаете ваш learning rate на какое-то значение и продолжаете учить. Он у вас опять немного падает, сходится в каком-то минимуме и вы опять понижаете learning rate и так далее, пока у ваша сеть окончательно не сойдется.
Дальше интересная техника Don’t decay the learning rate, increase the batch size. Есть статья с одноименным названием. Когда вы обучаете сеть, вам необязательно уменьшать learning rate, вы можете просто увеличивать batch size.
Эту технику, кстати, использовал Алекс Паринов. Он начинал с батча, равного 408, и когда сеть у него приходила на какое-то плато, он просто увеличивал batch size в два раза, и т. д.
На самом деле, я не помню, до какого значения у него batch size доходил, но что интересно, были команды на Kaggle, которые использовали эту же технику, у них batch size был порядка 10000. Кстати, современные фреймворки для deep learning, такие как PyTorch, например, позволяют вам это очень просто делать. Вы генерируете свой батч и подаете его в сеть не как он есть, целиком, а делите его на чанки, чтобы у вас это влезало в вашу видеокарту, считаете градиенты, и после того, как для всего батча посчитали градиент делаете обновление весов.
Кстати, в этом соревновании еще заходили большие batch sizes, потому что данные были довольно шумными, и большой batch size помогал вам более точно аппроксимировать градиент.
Также использовался псевдолейблинг, его по большей части использовал Роман Соловьев. Он в батч семплил где-то половину данных из теста, и на таких батчах обучал сетку.
Размер картинок играл значение, но факт в том, что у вас данных много, нужно долго обучать, и если у вас размер картинки будет довольно большим, то вы будете обучать очень долго. Но это приносило в качество вашего финального классификатора не так много, так что стоило использовать некий trade-off. И пробовали только картинки не очень большого размера.
Как это все обучалось? Сначала брались картинки маленького размера, на них прогонялось несколько эпох, это довольно быстро занимало по времени. Потом давались картинки большого размера, сеть обучалась, потом еще больше, еще больше, чтобы не обучать это с нуля и не тратить очень много времени.
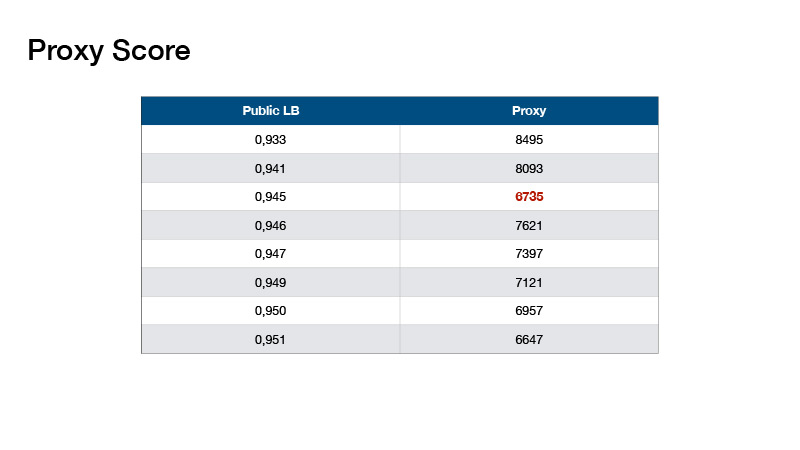
Про оптимайзеры. Мы использовали SGD и Adam. Таким способом можно было получить single модель, которая давала скор 0,941-0,946 на паблик лидерборде, что довольно неплохо.
Если вы заансамблируете модели неким образом, то вы получите где-то 0,951. Если применить еще одну технику, то финальный скор вы получите на паблик борде 0,954, как получили мы. Но об этом чуть позже. Дальше я расскажу, как мы асамблировали модели, и как такого финального скора удалось добиться.
Дальше хотел бы рассказать про Cosing Annealing with Warm Restarts или Stochastic Gradient Descent with Warm Restarts. Грубо говоря, в принципе, оптимайзер вы можете засунуть любой, но суть в следующем: если вы просто будете обучать одну сеть и постепенно она будет сходиться к какому-то минимуму, то все окей, у вас получится одна сеть, она делает определенные ошибки, но вы можете ее обучать немного по-другому. Вы будете задавать какой-то начальный learning rate, и постепенно его понижать по данной формуле. Вы его занижаете, у вас сеть приходит к какому-то минимуму, дальше вы сохраняете веса, и снова ставите learning rate, который был в начале обучения, тем самым из этого минимума выходите куда-то наверх, и опять занижаете ваш learning rate.
Тем самым вы можете посетить сразу несколько минимумов, в которых loss у вас будет плюс-минус одинаковым. Но факт в том, что сети с данными весами будут давать разные ошибки на вашей дате. Усреднив их, вы получите некую аппроксимацию, и ваш скор будет выше.

Про то, как мы ассемблировали наши модели. В начале презентации я говорил обратить внимание на количество данных в тесте и количество классов. Если к количеству таргетов в test set вы прибавите 1 и поделите на количество классов, вы получите число 330, и об этом писалось на форуме — что классы в тесте сбалансированы. Этим можно было воспользоваться.
Роман Соловьев на основе этого придумал метрику, мы ее называли Proxy Score, которая довольно хорошо коррелировала с лидербордом. Суть в чем: вы делаете предикшен, берете топ-1 ваших предиктов и считаете количество объектов для каждого класса. Дальше из каждого значения вычитаете 330 и складываете полученные абсолютные значения.
Получились такие значения. Это нам помогало не делать пробинг-лидерборда, а валидироваться локально и подбирать коэффициенты для наших ансамблей.
С ансамблем вы могли получить такой скор. Что бы еще сделать? Предположим, вы воспользовались информацией, что классы в тесте у вас сбалансированы.
Балансировки были разные. Пример одной из них — балансировка от ребят, которые заняли первое место.
Что делали мы? У нас балансировка была довольно простая, ее предложил Евгений Бабахнин. Мы сначала сортировали наши предсказания по топ-1 и из них выбирали кандидатов — таким образом, чтобы количество классов не превышало 330. Но для некоторых классов у вас получается так, что предиктов меньше, чем 330. Окей, давайте еще отсортируем по топ-2 и топ-3, и так же выберем кандидатов.
Чем наша балансировка отличалась от балансировки первого места? Они использовали итеративный подход, брали самый популярный класс и уменьшали вероятности для этого класса на какое-то маленькое число — до тех пор, пока этот класс не становился не самым популярным. Брали следующий самый популярный класс. Так дальше и понижали, пока количество всех классов не становилось равным.
Все использовали плюс-минус один подход для обучения сетей, но не все использовали балансировку. Используя балансировку, вы могли зайти в голд, а если бы повезло, то и в мани.
Как предпроцессить дату? Все предпроцессили дату плюс-минус одинаково — делалая handcrafted-фичи, пытались закодировать тайминги разным цветом штрихов и т. д. Как раз про это говорил Алексей Ноздрин-Плотницкий, который занял 8 место.
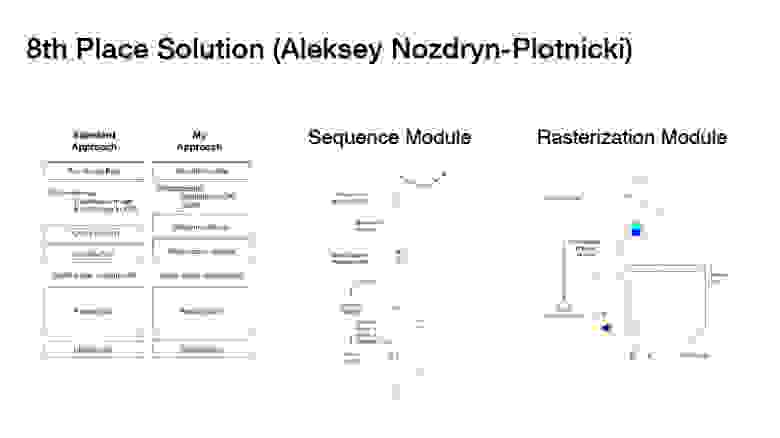
Он делал по-другому. Он говорил, что все эти ваши handcrafted-фичи не работают, так делать не надо, у вас сеть должна сама все это выучивать. И вместо этого он придумал обучаемые модули, которые делали предобработку ваших данных. Он в них закидывал исходные данные без предобработки — координаты точек и тайминги.
Дальше по координатам он брал разность, а по таймингам это все усреднял. И у него получалась довольна длинная матрица. К ней он несколько раз применял 1D-свертку, чтобы получить матрицу размером 64хn, где n — общее количество точек, а 64 сделано для того, чтобы подать полученную матрицу уже на слой какой-либо сверточной сети, которая принимает количество каналов — 64. У него получалась матрица 64хn, дальше из этого нужно было составить тензор какого-то размера, чтобы количество каналов было равно 64. Он нормировал все точки Х, Y в диапазоне от 0 до 32, чтобы составить тензор размером 32х32. Не знаю, почему он захотел 32х32, так получилось. И в эту координату он клал фрагмент этой матрицы размером 64хn. Таким образом, он просто получал тензор 32х32х64, который можно было положить дальше в вашу сверточную нейронную сеть. У меня все.
— Всем привет! Меня зовут Рома Власов, сегодня я вам расскажу про Quick, Draw! Doodle Recognition Challenge.

В нашей команде было пять человек. Я присоединился к ней прям перед мерж-дедлайном. Нам не повезло, нас немного шейкапнуло, но нас шейкапнуло из money, а их с позиции gold. И мы заняли почетное четвертое место.
(Во время соревнования команды наблюдали себя в рейтинге, который формировался по результатам, показанным на одной части предложенного набора данных. Финальный рейтинг, в свою очередь, формировался по другой части датасета. Так делают, чтобы участники соревнования не подстраивали свои алгоритмы под конкретные данные. Поэтому в финале, при переключении между рейтингами, позиции немного «шейкапятся» (от англ. shake up — перемешаться): на других данных и результат может оказаться другим. Команда Романа сначала была в тройке лидеров. В данном случае тройка — это money, денежная зона рейтинга, поскольку только за первые три места полагался денежный приз. После «шейк апа» команда оказалась уже на четвертом месте. Точно так же другая команда потеряла победу, позицию gold. — Прим. ред.)
Также соревнование было знаменательно тем, что Евгений Бабахнин получил за него грандмастера, Иван Сосин — мастера, Роман Соловьев так и остался грандмастером, Алекс Паринов получил мастера, я стал экспертом, а сейчас я уже мастер.
Что это за Quick, Draw? Это сервис от Google. Google преследовал цель популяризировать ИИ и этим сервисом хотел показать, как нейронные сети работают. Вы туда заходите, нажимаете Let’s draw, и вам вылезает новая страничка, где вам говорят: нарисуйте зигзаг, у вас на это есть 20 секунд. Вы пытаетесь нарисовать за 20 секунд зигзаг, как здесь, например. Если у вас все получается, сеть говорит, что это зигзаг, и вы идете дальше. Таких картинок всего шесть.
Если сети от Google не удалось распознать, что вы нарисовали, на задании ставился крестик. Позже я расскажу, что в дальнейшем будет значить, распознан рисунок сетью или нет.
Этот сервис собрал довольно большое количество пользователей, и все картинки, которые пользователи рисовали, логировались.

Удалось собрать почти 50 млн картинок. Из этого формировался трейн и тест дата для нашего соревнования. Кстати, количество данных в тесте и количество классов не зря выделено жирным шрифтом. Я о них расскажу чуть позже.
Формат данных был следующий. Это не просто RGB-картинки, а, грубо говоря, лог всего, что делал пользователь. Word — это наш таргет, countrycode — это то, откуда родом автор дудла, timestamp — время. Лейбл recognized как раз показывает то, распознала сеть от Google картинку или нет. И сам drawing — последовательность, аппроксимация кривой, которую пользователь рисует точками. И тайминги. Это время от начала рисования картинки.
Данные были представлены в двух форматах. Это первый формат, а второй — упрощенный. Они оттуда выпилили тайминги и аппроксимировали этот набор точек меньшим набором точек. Для этого они использовали алгоритм Дугласа-Пекера. У вас большой набор точек, который просто аппроксимирует какую-то прямую линию, а вы на самом деле можете эту линию аппроксимировать всего двумя точками. В этом и состоит идея алгоритма.
Данные были распределены следующим образом. Все равномерно, но есть некоторые выбросы. Когда мы решали задачу, то на это не смотрели. Главное, что не было тех классов, которых реально мало, нам не приходилось делать weighted samplers и data oversampling.

Как выглядели картинки? Это класс «самолет» и примеры из него с метками recognized и unrecognized. Соотношение их было где-то 1 к 9. Как видно, данные достаточно шумные. Я бы предположил, что это самолет. Если же посмотреть на not recognized, это в большинстве случаев просто шум. Кто-то даже пытался написать «самолет», но видимо, по-французски.
Большинство участников просто брали сетки, отрисовывали данные из этой последовательности линий как RGB-картинки и закидывали в сеть. Примерно так же отрисовывал и я: брал палитру цветов, первую строку отрисовывал одним цветом, который был в начале этой палитры, последнюю — другим, который в конце палитры, а между ними везде делал интерполяцию по этой палитре. Кстати, это давало лучший результат, чем если вы будете рисовать как на самом первом слайде — просто черным цветом.
Другие участники команды, например Иван Сосин, пробовали немного другие подходы к рисованию. Одним каналом он просто рисовал серую картинку, другим каналом — рисовал каждый штрих градиентом от начала до конца, с 32 до 255, а третим каналом рисовал градиент по всем штрихам от 32 до 255.
Еще из интересного — Алекс Паринов закидывал информацию в сеть по countrycode.
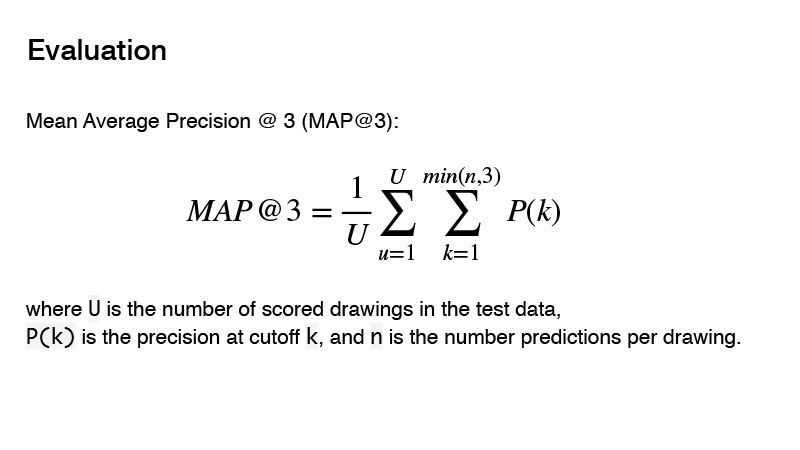
Метрика, которая использовалась в соревновании, это Mean Average Precision. В чем суть этой метрики для соревнования? Вы можете отдать три предикшина, и если в этих трех предикшинах нет правильного, то вы получаете 0. Если есть правильный, то учитывается его порядок. И результат по таргету будет считаться как 1, деленное на порядок вашего предсказания. Например, вы сделали три предикшина, и правильный из них первый, то вы 1 делите на 1 и получаете 1. Если предикшин верный и его порядок 2, то 1 делите на 2, получаете 0,5. Ну и т. д.

С предобработкой данных — как рисовать картинки и так далее — мы немного определились. Какие архитектуры мы использовали? Мы пытались использовать жирные архитектуры, такие как PNASNet, SENet, и такие уже классические архитектуры как SE-Res-NeXt, они все больше заходят в новых соревнованиях. Также были ResNet и DenseNet.



Как мы это обучали? Все модели, которые мы брали, мы брали сами предобученными на imagenet. Хотя данных много, 50 млн картинок, но все равно, если вы берете сеть, предобученную на imagenet, она показывала лучший результат, чем если вы будете просто обучать ее from scratch.
Какие техники для обучения мы использовали? Это Cosing Annealing with Warm Restarts, о ней я поговорю чуть позже. Это техника, которую я использую практически во всех моих последних соревнованиях, и с ними получается довольно хорошо обучить сетки, достичь хорошего минимума.

Дальше Reduce Learning Rate on Plateau. Вы начинаете обучать сеть, задаете какой-то определенный learning rate, дальше ее учите, у вас постепенно loss сходится к какому-то определенному значению. Вы это чекаете, например, на протяжении десяти эпох loss никак не поменялся. Вы уменьшаете ваш learning rate на какое-то значение и продолжаете учить. Он у вас опять немного падает, сходится в каком-то минимуме и вы опять понижаете learning rate и так далее, пока у ваша сеть окончательно не сойдется.
Дальше интересная техника Don’t decay the learning rate, increase the batch size. Есть статья с одноименным названием. Когда вы обучаете сеть, вам необязательно уменьшать learning rate, вы можете просто увеличивать batch size.
Эту технику, кстати, использовал Алекс Паринов. Он начинал с батча, равного 408, и когда сеть у него приходила на какое-то плато, он просто увеличивал batch size в два раза, и т. д.
На самом деле, я не помню, до какого значения у него batch size доходил, но что интересно, были команды на Kaggle, которые использовали эту же технику, у них batch size был порядка 10000. Кстати, современные фреймворки для deep learning, такие как PyTorch, например, позволяют вам это очень просто делать. Вы генерируете свой батч и подаете его в сеть не как он есть, целиком, а делите его на чанки, чтобы у вас это влезало в вашу видеокарту, считаете градиенты, и после того, как для всего батча посчитали градиент делаете обновление весов.
Кстати, в этом соревновании еще заходили большие batch sizes, потому что данные были довольно шумными, и большой batch size помогал вам более точно аппроксимировать градиент.
Также использовался псевдолейблинг, его по большей части использовал Роман Соловьев. Он в батч семплил где-то половину данных из теста, и на таких батчах обучал сетку.
Размер картинок играл значение, но факт в том, что у вас данных много, нужно долго обучать, и если у вас размер картинки будет довольно большим, то вы будете обучать очень долго. Но это приносило в качество вашего финального классификатора не так много, так что стоило использовать некий trade-off. И пробовали только картинки не очень большого размера.
Как это все обучалось? Сначала брались картинки маленького размера, на них прогонялось несколько эпох, это довольно быстро занимало по времени. Потом давались картинки большого размера, сеть обучалась, потом еще больше, еще больше, чтобы не обучать это с нуля и не тратить очень много времени.
Про оптимайзеры. Мы использовали SGD и Adam. Таким способом можно было получить single модель, которая давала скор 0,941-0,946 на паблик лидерборде, что довольно неплохо.
Если вы заансамблируете модели неким образом, то вы получите где-то 0,951. Если применить еще одну технику, то финальный скор вы получите на паблик борде 0,954, как получили мы. Но об этом чуть позже. Дальше я расскажу, как мы асамблировали модели, и как такого финального скора удалось добиться.
Дальше хотел бы рассказать про Cosing Annealing with Warm Restarts или Stochastic Gradient Descent with Warm Restarts. Грубо говоря, в принципе, оптимайзер вы можете засунуть любой, но суть в следующем: если вы просто будете обучать одну сеть и постепенно она будет сходиться к какому-то минимуму, то все окей, у вас получится одна сеть, она делает определенные ошибки, но вы можете ее обучать немного по-другому. Вы будете задавать какой-то начальный learning rate, и постепенно его понижать по данной формуле. Вы его занижаете, у вас сеть приходит к какому-то минимуму, дальше вы сохраняете веса, и снова ставите learning rate, который был в начале обучения, тем самым из этого минимума выходите куда-то наверх, и опять занижаете ваш learning rate.
Тем самым вы можете посетить сразу несколько минимумов, в которых loss у вас будет плюс-минус одинаковым. Но факт в том, что сети с данными весами будут давать разные ошибки на вашей дате. Усреднив их, вы получите некую аппроксимацию, и ваш скор будет выше.
Про то, как мы ассемблировали наши модели. В начале презентации я говорил обратить внимание на количество данных в тесте и количество классов. Если к количеству таргетов в test set вы прибавите 1 и поделите на количество классов, вы получите число 330, и об этом писалось на форуме — что классы в тесте сбалансированы. Этим можно было воспользоваться.
Роман Соловьев на основе этого придумал метрику, мы ее называли Proxy Score, которая довольно хорошо коррелировала с лидербордом. Суть в чем: вы делаете предикшен, берете топ-1 ваших предиктов и считаете количество объектов для каждого класса. Дальше из каждого значения вычитаете 330 и складываете полученные абсолютные значения.
Получились такие значения. Это нам помогало не делать пробинг-лидерборда, а валидироваться локально и подбирать коэффициенты для наших ансамблей.
С ансамблем вы могли получить такой скор. Что бы еще сделать? Предположим, вы воспользовались информацией, что классы в тесте у вас сбалансированы.
Балансировки были разные. Пример одной из них — балансировка от ребят, которые заняли первое место.
Что делали мы? У нас балансировка была довольно простая, ее предложил Евгений Бабахнин. Мы сначала сортировали наши предсказания по топ-1 и из них выбирали кандидатов — таким образом, чтобы количество классов не превышало 330. Но для некоторых классов у вас получается так, что предиктов меньше, чем 330. Окей, давайте еще отсортируем по топ-2 и топ-3, и так же выберем кандидатов.
Чем наша балансировка отличалась от балансировки первого места? Они использовали итеративный подход, брали самый популярный класс и уменьшали вероятности для этого класса на какое-то маленькое число — до тех пор, пока этот класс не становился не самым популярным. Брали следующий самый популярный класс. Так дальше и понижали, пока количество всех классов не становилось равным.
Все использовали плюс-минус один подход для обучения сетей, но не все использовали балансировку. Используя балансировку, вы могли зайти в голд, а если бы повезло, то и в мани.
Как предпроцессить дату? Все предпроцессили дату плюс-минус одинаково — делалая handcrafted-фичи, пытались закодировать тайминги разным цветом штрихов и т. д. Как раз про это говорил Алексей Ноздрин-Плотницкий, который занял 8 место.

Он делал по-другому. Он говорил, что все эти ваши handcrafted-фичи не работают, так делать не надо, у вас сеть должна сама все это выучивать. И вместо этого он придумал обучаемые модули, которые делали предобработку ваших данных. Он в них закидывал исходные данные без предобработки — координаты точек и тайминги.
Дальше по координатам он брал разность, а по таймингам это все усреднял. И у него получалась довольна длинная матрица. К ней он несколько раз применял 1D-свертку, чтобы получить матрицу размером 64хn, где n — общее количество точек, а 64 сделано для того, чтобы подать полученную матрицу уже на слой какой-либо сверточной сети, которая принимает количество каналов — 64. У него получалась матрица 64хn, дальше из этого нужно было составить тензор какого-то размера, чтобы количество каналов было равно 64. Он нормировал все точки Х, Y в диапазоне от 0 до 32, чтобы составить тензор размером 32х32. Не знаю, почему он захотел 32х32, так получилось. И в эту координату он клал фрагмент этой матрицы размером 64хn. Таким образом, он просто получал тензор 32х32х64, который можно было положить дальше в вашу сверточную нейронную сеть. У меня все.
