
Хочу рассказать вам о том, как мы в Яндекс.Браузере попытались сделать кэш не таким бесполезным для пользователей, как обычно. В недавно вышедшей новой бете Яндекс.Браузера для Android (планируем и для других ОС) можно получить доступ к недавно посещенным сайтам даже при отсутствии соединения с интернетом. Причём работать это должно гораздо надёжнее и удобнее, чем всё, что вы видели до этого.
Чтобы это стало возможным, мы придумали собственное кластерное кэширование, алгоритм работы которого следит за тем, чтобы сохранять страницы максимально целостно. Подробности об устройстве всего — под катом.
Постоянный и бесперебойный доступ в интернет в любой точке мира или хотя бы города по-прежнему остается мечтой. Поэтому в реальности мы так или иначе сталкиваемся с офлайном и неприятностями, которые он порождает. Например, вы не сможете продолжить чтение ранее открытого поста в браузере, если обновите вкладку при отсутствии WiFi/3G/LTE. Или она сама решит обновиться, потому что была выгружена из оперативной памяти. Или вы решите вернуться на предыдущую страницу с помощью кнопки «Назад». Ситуации бывают разные, но каждая из них закончится ошибкой, потому что браузер не сможет загрузить материал из сети. Стоп! Но ведь он уже был загружен на ваше устройство. Все, что вы ищите, уже лежит в браузерном кэше. Так почему нельзя это использовать? Звучит достаточно просто, не правда ли?
Именно это наша команда и взялась реализовать в Яндекс.Браузере. Мы поставили перед собой задачу добиться предсказуемой и качественной работы в офлайне с использованием браузерного кэша.
Кэширование обычное
Если обратиться к опыту десктопных браузеров, то можно вспомнить автономный режим в Internet Explorer или Firefox, который заключался в попытках браузера загрузить запрошенную страницу из сохраненной копии или кэша. Десять или даже двадцать лет назад это было особенно актуально из-за широкого распространения dialup и оплаты за время, проведенное в сети. Было дешевле вначале загрузить все нужные сайты, уйти в офлайн и уже там продолжить их чтение совершенно бесплатно. Со временем потребность в подобных решениях стала падать, и работа над кэшированием в тех или иных продуктах если не приостановилась, то уж точно продолжалась не в направлении офлайна.
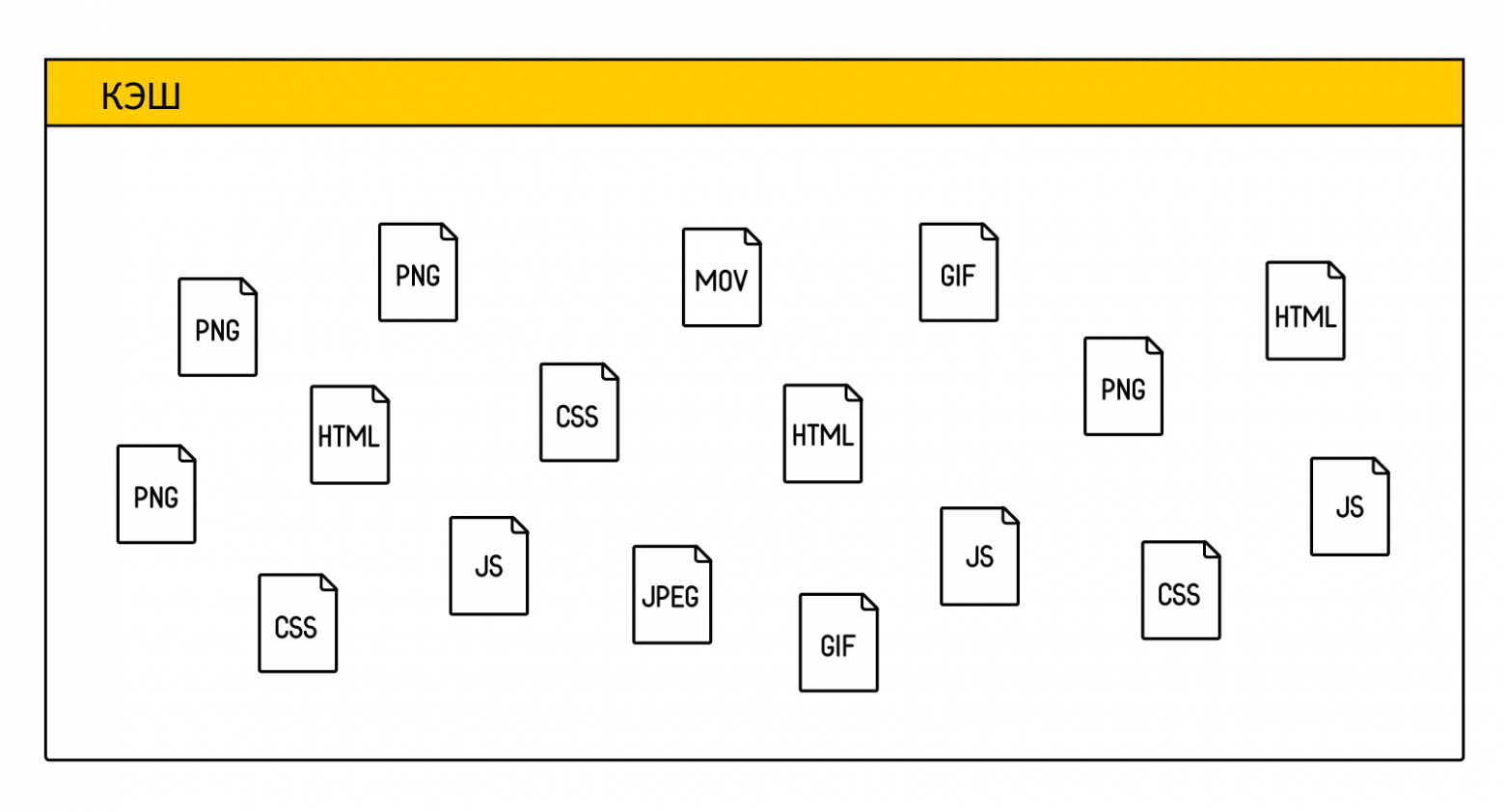
Современные мобильные браузеры напротив столкнулись с проблемой офлайна в полной мере. Нет, за время, проведенное в интернете платить теперь не нужно, но пользователи сети сами стали мобильны и в любой момент могут выйти из зоны покрытия. Каких-то радикальных решений этой проблемы в популярных продуктах нами замечено не было. При этом в мобильных сборках Chromium под Android (напомним, Яндекс.Браузер использует его в своей основе) процесс кэширования представляет из себя сильно упрощенную версию с десктопа. Никакой сложной логики. Все закэшированные ресурсы живут в одной очереди и удаляются в соответствии с алгоритмом LRU (удаляются те элементы, которые не использовались дольше всех). Сам кэш представляет из себя «свалку» из отдельных ресурсов (html, css, png, js, ...) с емкостью порядка 300 МБ. С точки зрения кэширующего алгоритма эти ресурсы никак не связаны между собой и удаляются независимо друг от друга при нехватке памяти для новых страниц.
Подобная упрощенная логика стала для нас проблемой, поскольку не позволяла добиться предсказуемого результата при работе в офлайне. Проще говоря, браузер не знает, что именно есть у него в кэше и насколько этого достаточно для полноценного отображения страницы. Мы могли воспользоваться механизмом, реализованным в рамках эксперимента chrome://flags/#show-saved-copy. Если вы не знаете, о чем идет речь, то вот краткая суть. В случае отсутствия сети пользователю предлагается попробовать загрузить сайт из кэша. Это ведь ровно то, что нам и нужно, думали бы вы!
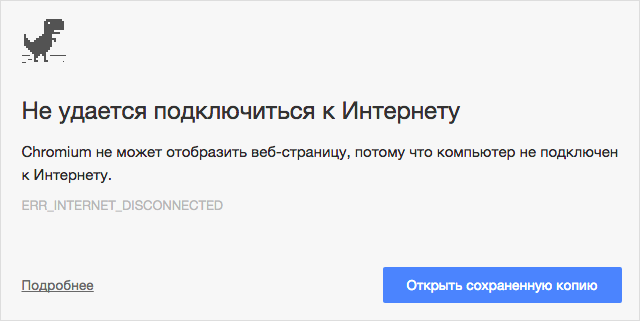
К сожалению, если включить этот эксперимент, браузер проверяет доступность локальной копии лишь главного HTML-документа без учета всех остальных ресурсов и скриптов. Для простых текстовых страниц этого обычно хватает. Но для всего остального результат порой слишком печальный. А вскоре мы узнали, что для многих популярных сайтов эксперимент не сработает даже при наличии кэша, но об этом чуть ниже, а пока нам нужно было научиться прогнозировать результат.
Кэширование прогнозируемое
Мы хотели добиться более качественной и ненавязчивой работы в офлайне. Чтобы пользователь мог получить доступ к уже и так загруженной на его устройство информации без лишних кнопок. Причем браузер должен его предупредить, если некоторые ресурсы уже были удалены из кэша. Для этого Яндекс.Браузер должен был знать, по-прежнему ли доступны в кэше все ресурсы, что присутствуют на запрошенной странице.
Теоретически мы могли проверять доступность HTML-документа в кэше, а дальше уже пробежаться по всем зависимостям из него и оценить доступность каждого ресурса. К сожалению, такой простой способ оценки «в лоб» не может похвастаться скоростью. Да и на потреблении ресурсов это сказывается особенно сильно. Настолько сильно, что холодными зимними вечерами ваш смартфон мог бы вас согревать. Вот только за окном уже лето.
Подобные неудачные идеи постепенно привели нас к мысли, что без структурных изменений в кэше результат не достичь. Поэтому мы зашли с другой стороны. Научили браузер уже на этапе загрузки сайта запоминать зависимости между страницей и ее ресурсами. Все ресурсы, которые необходимы для отображения конкретной страницы, теперь логически объединяются браузером в набор данных. Такой набор мы назвали «кластером». Причем если ресурс присутствует на двух разных страницах (например, логотип сайта обычно дублируется), то он будет ассоциирован с двумя разными кластерами. При этом браузер может очищать кэш только за счет тех ресурсов, которые принадлежат самому неиспользуемому кластеру (тот же LRU, но на уровне кластеров, а не отдельных ресурсов).
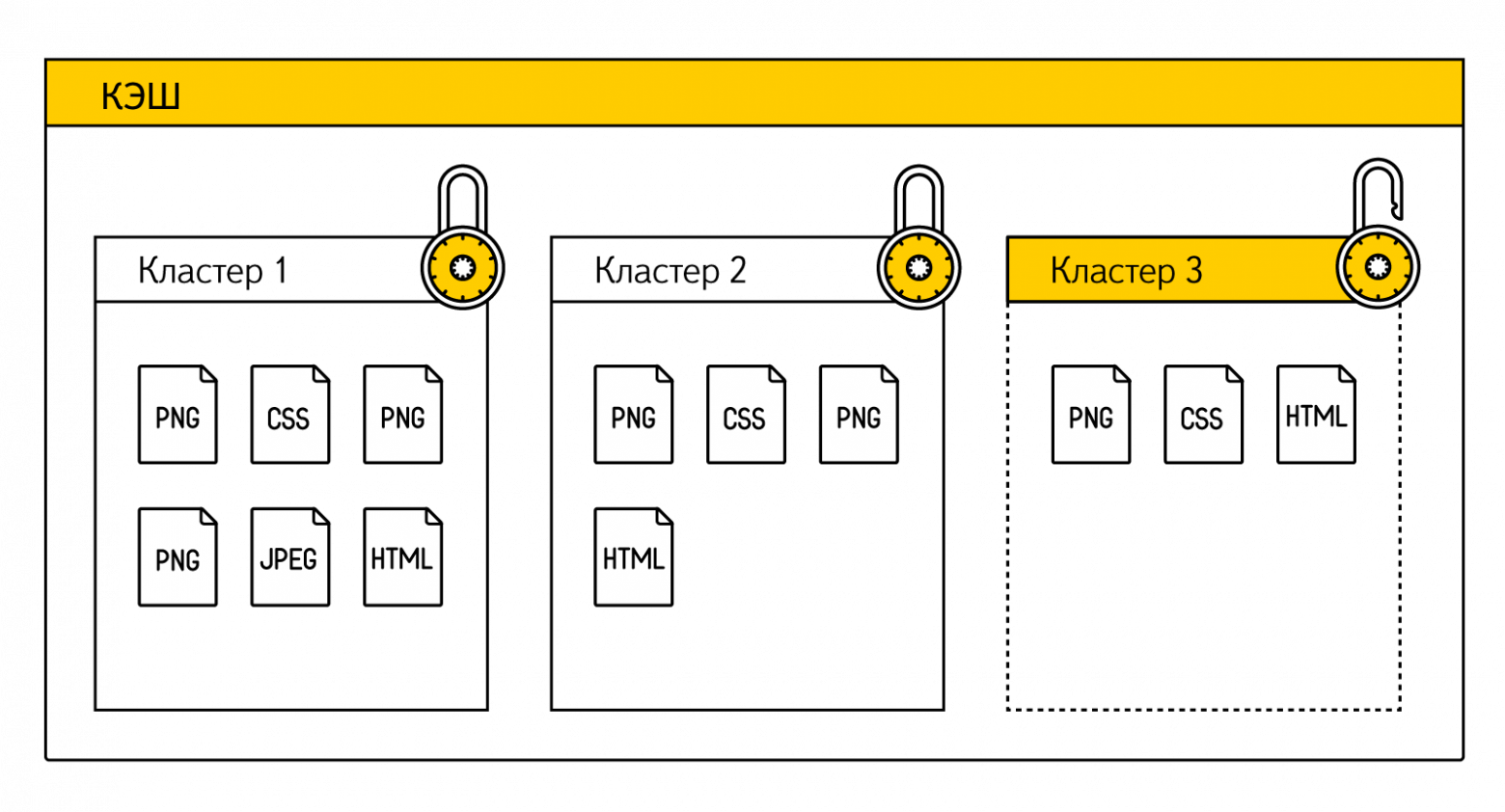
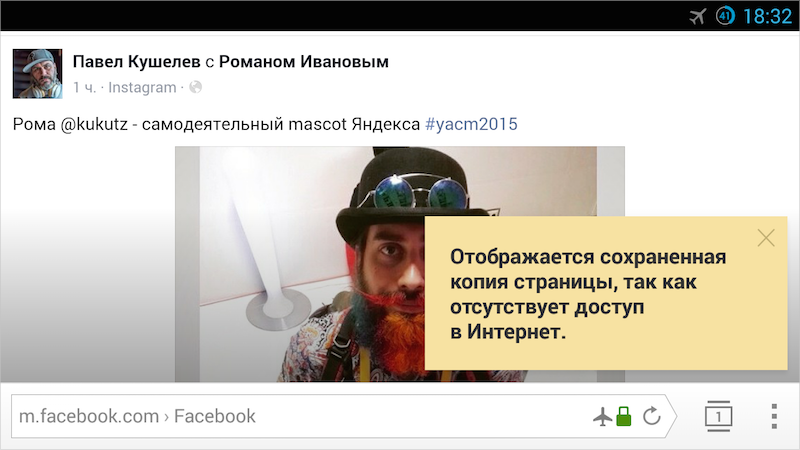
В тот момент, когда пользователь запрашивает страницу, Яндекс.Браузер уже знает какому кластеру соответствует запрашиваемый адрес, и какие ресурсы для нее необходимы. А дальше он просто проверяет доступность каждого элемента из кластера. Если кластер (т.е. фактически все ресурсы нужной страницы) доступен полностью, то можно не пугать пользователя ошибкой, а сразу показать сайт, предупредив, что он работает в офлайне. Если часть ресурсов уже удалена, то в текущей сборке мы также восстанавливаем страницу, но предупреждаем о том, что копия сохранена частично.
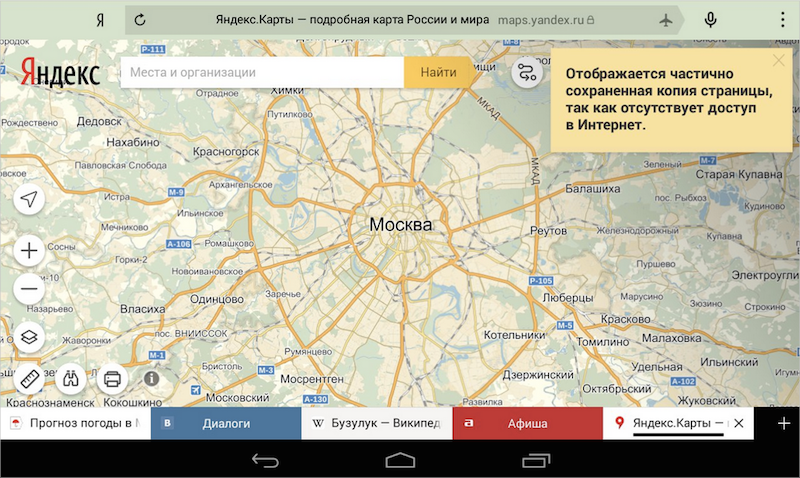
Кстати, на скриншоте один из пяти экспериментальных дизайнов для планшета, которые также тестируются в текущей бете.
Кэширование качественное
Когда мы говорим про работу в офлайне, то подразумеваем не только банальное восстановление вкладки при запуске браузера. В нашем случае кэш используется для любого способа открытия страниц. Вы можете нажать «Обновить» или перемещаться по истории через «Вперед»/«Назад». Можете тапнуть по ссылке. Можете ввести адрес вручную. Во всех этих ситуациях Яндекс.Браузер оценит доступность ресурсов и загрузит локальную страницу, если это возможно.
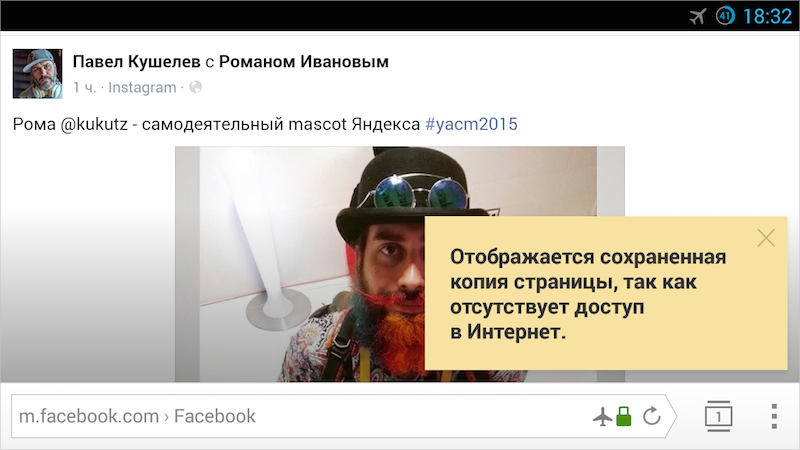
Мы и раньше подозревали, что далеко не каждый сайт может быть восстановлен из кэша. Но только после того, как научились прогнозировать результат, стало ясно, что о полноценной и качественной работе в офлайне без дальнейших доработок можно забыть. Многие сайты никогда не откроются в офлайне. Например, Яндекс, Хабрахабр, Facebook или ВКонтакте (если вы авторизованы на них).
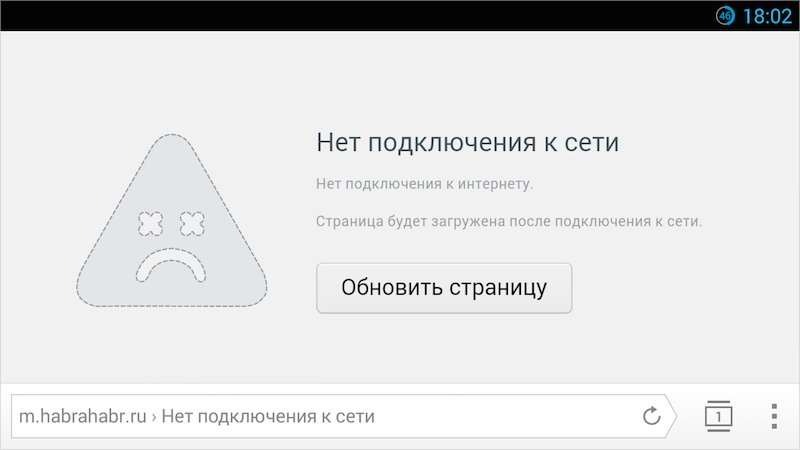
Причина кроется в HTTP-заголовке «cache-control:no-cache, no-store», который запрещает браузеру сохранять ресурсы в кэше. Мы понимаем, что вебмастеры используют его в том числе для того, чтобы регулярно обновляемые ресурсы не брались из кэша, а всегда загружались самой свежей версии. К сожалению, широко распространена практика добавлять этот заголовок не для отдельных ресурсов, а для всего HTML-документа, что ставит крест на открытии сайта в офлайне.
Отказываться от офлайна мы точно не собирались. Но и простым игнорированием указанных HTTP-заголовков проблему решать было нельзя. Это могло привести к использованию в онлайне неактуальных ресурсов из кэша. Нам нужно было соблюсти смысл HTTP-заголовка, но при этом обеспечить доступ к информации без соединения с сетью. К счастью, нашим разработчикам удалось найти такое компромиссное решение. Согласно этому решению, Яндекс.Браузер сохраняет в кэше все ресурсы, включая те, для которых прописан запрет через «cache-control». Но при этом мы также сохраняем информацию о наличии запрета и не используем такие ресурсы при обычной работе в онлайне. Браузер обращается к ним только в офлайне. Более того, мы сейчас исследуем возможность шифровать эту часть кэша.
Кстати, результаты POST-запросов или исполнения AJAX мы также сохраняем в кэш. Без этого многие динамические сайты выглядели бы в офлайне неполноценно.
Перспективы кластерного кэширования
Возвращаемся к нашим кластерам. При обычном кэшировании все хранимые ресурсы никак не связаны между собой и удаляются в соответствии с LRU. При этом никак не учитывается, открыта ли вкладка со страницей до сих пор где-нибудь в фоне, или пользователь уже давно ее закрыл. Чтобы лучше понять проблему, взглянем на простой пример. Вы открываете в браузере на своем смартфоне пост на Хабре и оставляете его открытым, чтобы прочитать на борту самолета. Но до того момента, как начнется посадка на рейс, вам может потребоваться взглянуть на прогноз погоды, проверить новые сообщения в социальной сети или поработать с веб-версией почты. Да, вкладка с постом на Хабре у вас все еще открыта в фоне. Но ее ресурсы уже успели переместиться в конец очереди и были удалены из кэша. Да и сама вкладка уже были выброшена из оперативной памяти. И вот вы летите в 10 тыс. метрах над землей, достаете свой телефон и кликаете по нужной вкладке, предвкушая захватывающее чтиво. Но браузер выдает ошибку, потому что беспощадному LRU нет дела до открытых вкладок и ваших проблем.
К счастью, у нас уже изобретены кластеры, которые могут решить эту проблему. Введение кластеров позволило нам объединять ресурсы в логические группы, каждая из которых явно ассоциируется с определенной страницей. Чтобы решить описанную выше проблему, достаточно запрещать браузеру удалять ресурсы тех кластеров, которые соответствуют открытым вкладкам. А можно пойти еще дальше и предусмотреть возможность вручную сохранять страницу. Как раз над этими идеями мы сейчас и продолжаем работать.
К сожалению, даже кластерное кэширование на данный момент не может гарантировать доступ к странице в офлайне. Если вы вдруг загружаете тяжелый сайт, то его ресурсы могут очень быстро выбить из кэша все остальные. Но в большинстве случаев наша технология позволяет избежать неловких моментов и предоставить пользователю доступ к загруженной информации. И как бы мы ни старались, сайты в офлайне далеко не всегда работают именно так, как в онлайне, поэтому мы в обязательно порядке информируем пользователя об отсутствии сети специальной иконкой.
Попробовать офлайн-режим вы можете в бета-версии Яндекс.Браузера 15.6 для Android. Уже в этой сборке браузер умеет открывать страницы в офлайне, если необходимые ресурсы доступны в кэше. Приглашаем всех желающих помочь нам с поиском проблем и новых идей.
P.S. Версия для iOS была практически готова, но недавно мы приступили к миграции на новый компонент WKWebView, который, к сожалению, лишился многих возможностей в сравнении с устаревшим UIWebView. И новое кэширование там пока не реализовать по ряду причин. Но это уже совсем другая история.
P.P.S. Кстати, если вы хотите помочь нашей мобильной команде с изобретением других интересных технологий, то вакансии ждут. Мы ищем разработчиков (C, C++, Java), дизайнеров, руководителей проектов, специалистов по продуктам и тестировщиков в офисы Яндекса в Москве, Санкт-Петербурге и Новосибирске.
Чтобы это стало возможным, мы придумали собственное кластерное кэширование, алгоритм работы которого следит за тем, чтобы сохранять страницы максимально целостно. Подробности об устройстве всего — под катом.
Постоянный и бесперебойный доступ в интернет в любой точке мира или хотя бы города по-прежнему остается мечтой. Поэтому в реальности мы так или иначе сталкиваемся с офлайном и неприятностями, которые он порождает. Например, вы не сможете продолжить чтение ранее открытого поста в браузере, если обновите вкладку при отсутствии WiFi/3G/LTE. Или она сама решит обновиться, потому что была выгружена из оперативной памяти. Или вы решите вернуться на предыдущую страницу с помощью кнопки «Назад». Ситуации бывают разные, но каждая из них закончится ошибкой, потому что браузер не сможет загрузить материал из сети. Стоп! Но ведь он уже был загружен на ваше устройство. Все, что вы ищите, уже лежит в браузерном кэше. Так почему нельзя это использовать? Звучит достаточно просто, не правда ли?
Именно это наша команда и взялась реализовать в Яндекс.Браузере. Мы поставили перед собой задачу добиться предсказуемой и качественной работы в офлайне с использованием браузерного кэша.
Кэширование обычное
Если обратиться к опыту десктопных браузеров, то можно вспомнить автономный режим в Internet Explorer или Firefox, который заключался в попытках браузера загрузить запрошенную страницу из сохраненной копии или кэша. Десять или даже двадцать лет назад это было особенно актуально из-за широкого распространения dialup и оплаты за время, проведенное в сети. Было дешевле вначале загрузить все нужные сайты, уйти в офлайн и уже там продолжить их чтение совершенно бесплатно. Со временем потребность в подобных решениях стала падать, и работа над кэшированием в тех или иных продуктах если не приостановилась, то уж точно продолжалась не в направлении офлайна.
Современные мобильные браузеры напротив столкнулись с проблемой офлайна в полной мере. Нет, за время, проведенное в интернете платить теперь не нужно, но пользователи сети сами стали мобильны и в любой момент могут выйти из зоны покрытия. Каких-то радикальных решений этой проблемы в популярных продуктах нами замечено не было. При этом в мобильных сборках Chromium под Android (напомним, Яндекс.Браузер использует его в своей основе) процесс кэширования представляет из себя сильно упрощенную версию с десктопа. Никакой сложной логики. Все закэшированные ресурсы живут в одной очереди и удаляются в соответствии с алгоритмом LRU (удаляются те элементы, которые не использовались дольше всех). Сам кэш представляет из себя «свалку» из отдельных ресурсов (html, css, png, js, ...) с емкостью порядка 300 МБ. С точки зрения кэширующего алгоритма эти ресурсы никак не связаны между собой и удаляются независимо друг от друга при нехватке памяти для новых страниц.

Подобная упрощенная логика стала для нас проблемой, поскольку не позволяла добиться предсказуемого результата при работе в офлайне. Проще говоря, браузер не знает, что именно есть у него в кэше и насколько этого достаточно для полноценного отображения страницы. Мы могли воспользоваться механизмом, реализованным в рамках эксперимента chrome://flags/#show-saved-copy. Если вы не знаете, о чем идет речь, то вот краткая суть. В случае отсутствия сети пользователю предлагается попробовать загрузить сайт из кэша. Это ведь ровно то, что нам и нужно, думали бы вы!

К сожалению, если включить этот эксперимент, браузер проверяет доступность локальной копии лишь главного HTML-документа без учета всех остальных ресурсов и скриптов. Для простых текстовых страниц этого обычно хватает. Но для всего остального результат порой слишком печальный. А вскоре мы узнали, что для многих популярных сайтов эксперимент не сработает даже при наличии кэша, но об этом чуть ниже, а пока нам нужно было научиться прогнозировать результат.
Кэширование прогнозируемое
Мы хотели добиться более качественной и ненавязчивой работы в офлайне. Чтобы пользователь мог получить доступ к уже и так загруженной на его устройство информации без лишних кнопок. Причем браузер должен его предупредить, если некоторые ресурсы уже были удалены из кэша. Для этого Яндекс.Браузер должен был знать, по-прежнему ли доступны в кэше все ресурсы, что присутствуют на запрошенной странице.
Теоретически мы могли проверять доступность HTML-документа в кэше, а дальше уже пробежаться по всем зависимостям из него и оценить доступность каждого ресурса. К сожалению, такой простой способ оценки «в лоб» не может похвастаться скоростью. Да и на потреблении ресурсов это сказывается особенно сильно. Настолько сильно, что холодными зимними вечерами ваш смартфон мог бы вас согревать. Вот только за окном уже лето.
Подобные неудачные идеи постепенно привели нас к мысли, что без структурных изменений в кэше результат не достичь. Поэтому мы зашли с другой стороны. Научили браузер уже на этапе загрузки сайта запоминать зависимости между страницей и ее ресурсами. Все ресурсы, которые необходимы для отображения конкретной страницы, теперь логически объединяются браузером в набор данных. Такой набор мы назвали «кластером». Причем если ресурс присутствует на двух разных страницах (например, логотип сайта обычно дублируется), то он будет ассоциирован с двумя разными кластерами. При этом браузер может очищать кэш только за счет тех ресурсов, которые принадлежат самому неиспользуемому кластеру (тот же LRU, но на уровне кластеров, а не отдельных ресурсов).
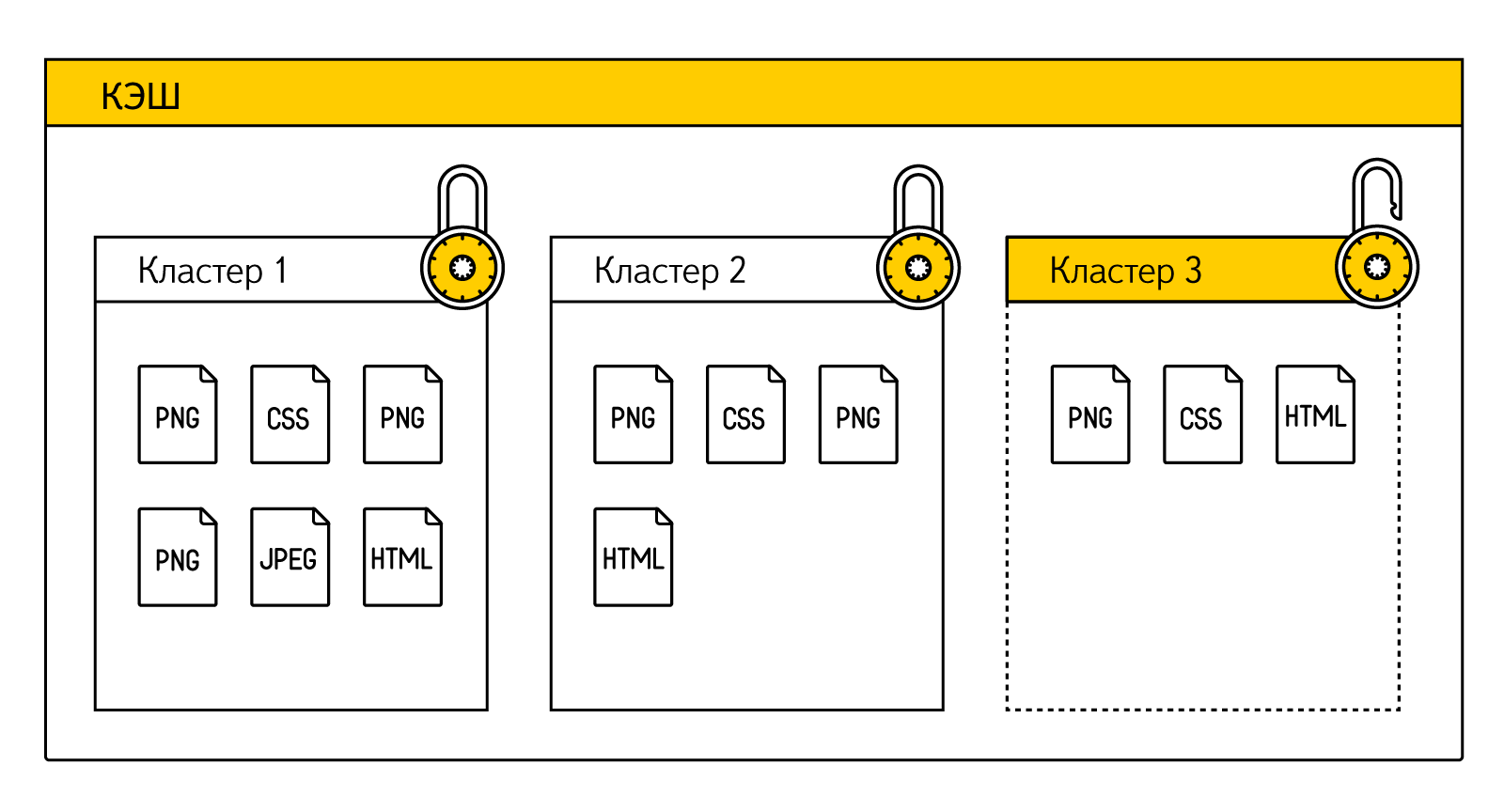
В тот момент, когда пользователь запрашивает страницу, Яндекс.Браузер уже знает какому кластеру соответствует запрашиваемый адрес, и какие ресурсы для нее необходимы. А дальше он просто проверяет доступность каждого элемента из кластера. Если кластер (т.е. фактически все ресурсы нужной страницы) доступен полностью, то можно не пугать пользователя ошибкой, а сразу показать сайт, предупредив, что он работает в офлайне. Если часть ресурсов уже удалена, то в текущей сборке мы также восстанавливаем страницу, но предупреждаем о том, что копия сохранена частично.

Кстати, на скриншоте один из пяти экспериментальных дизайнов для планшета, которые также тестируются в текущей бете.
Кэширование качественное
Когда мы говорим про работу в офлайне, то подразумеваем не только банальное восстановление вкладки при запуске браузера. В нашем случае кэш используется для любого способа открытия страниц. Вы можете нажать «Обновить» или перемещаться по истории через «Вперед»/«Назад». Можете тапнуть по ссылке. Можете ввести адрес вручную. Во всех этих ситуациях Яндекс.Браузер оценит доступность ресурсов и загрузит локальную страницу, если это возможно.
Мы и раньше подозревали, что далеко не каждый сайт может быть восстановлен из кэша. Но только после того, как научились прогнозировать результат, стало ясно, что о полноценной и качественной работе в офлайне без дальнейших доработок можно забыть. Многие сайты никогда не откроются в офлайне. Например, Яндекс, Хабрахабр, Facebook или ВКонтакте (если вы авторизованы на них).

Причина кроется в HTTP-заголовке «cache-control:no-cache, no-store», который запрещает браузеру сохранять ресурсы в кэше. Мы понимаем, что вебмастеры используют его в том числе для того, чтобы регулярно обновляемые ресурсы не брались из кэша, а всегда загружались самой свежей версии. К сожалению, широко распространена практика добавлять этот заголовок не для отдельных ресурсов, а для всего HTML-документа, что ставит крест на открытии сайта в офлайне.
Отказываться от офлайна мы точно не собирались. Но и простым игнорированием указанных HTTP-заголовков проблему решать было нельзя. Это могло привести к использованию в онлайне неактуальных ресурсов из кэша. Нам нужно было соблюсти смысл HTTP-заголовка, но при этом обеспечить доступ к информации без соединения с сетью. К счастью, нашим разработчикам удалось найти такое компромиссное решение. Согласно этому решению, Яндекс.Браузер сохраняет в кэше все ресурсы, включая те, для которых прописан запрет через «cache-control». Но при этом мы также сохраняем информацию о наличии запрета и не используем такие ресурсы при обычной работе в онлайне. Браузер обращается к ним только в офлайне. Более того, мы сейчас исследуем возможность шифровать эту часть кэша.
Кстати, результаты POST-запросов или исполнения AJAX мы также сохраняем в кэш. Без этого многие динамические сайты выглядели бы в офлайне неполноценно.
Перспективы кластерного кэширования
Возвращаемся к нашим кластерам. При обычном кэшировании все хранимые ресурсы никак не связаны между собой и удаляются в соответствии с LRU. При этом никак не учитывается, открыта ли вкладка со страницей до сих пор где-нибудь в фоне, или пользователь уже давно ее закрыл. Чтобы лучше понять проблему, взглянем на простой пример. Вы открываете в браузере на своем смартфоне пост на Хабре и оставляете его открытым, чтобы прочитать на борту самолета. Но до того момента, как начнется посадка на рейс, вам может потребоваться взглянуть на прогноз погоды, проверить новые сообщения в социальной сети или поработать с веб-версией почты. Да, вкладка с постом на Хабре у вас все еще открыта в фоне. Но ее ресурсы уже успели переместиться в конец очереди и были удалены из кэша. Да и сама вкладка уже были выброшена из оперативной памяти. И вот вы летите в 10 тыс. метрах над землей, достаете свой телефон и кликаете по нужной вкладке, предвкушая захватывающее чтиво. Но браузер выдает ошибку, потому что беспощадному LRU нет дела до открытых вкладок и ваших проблем.
К счастью, у нас уже изобретены кластеры, которые могут решить эту проблему. Введение кластеров позволило нам объединять ресурсы в логические группы, каждая из которых явно ассоциируется с определенной страницей. Чтобы решить описанную выше проблему, достаточно запрещать браузеру удалять ресурсы тех кластеров, которые соответствуют открытым вкладкам. А можно пойти еще дальше и предусмотреть возможность вручную сохранять страницу. Как раз над этими идеями мы сейчас и продолжаем работать.
К сожалению, даже кластерное кэширование на данный момент не может гарантировать доступ к странице в офлайне. Если вы вдруг загружаете тяжелый сайт, то его ресурсы могут очень быстро выбить из кэша все остальные. Но в большинстве случаев наша технология позволяет избежать неловких моментов и предоставить пользователю доступ к загруженной информации. И как бы мы ни старались, сайты в офлайне далеко не всегда работают именно так, как в онлайне, поэтому мы в обязательно порядке информируем пользователя об отсутствии сети специальной иконкой.
Попробовать офлайн-режим вы можете в бета-версии Яндекс.Браузера 15.6 для Android. Уже в этой сборке браузер умеет открывать страницы в офлайне, если необходимые ресурсы доступны в кэше. Приглашаем всех желающих помочь нам с поиском проблем и новых идей.
P.S. Версия для iOS была практически готова, но недавно мы приступили к миграции на новый компонент WKWebView, который, к сожалению, лишился многих возможностей в сравнении с устаревшим UIWebView. И новое кэширование там пока не реализовать по ряду причин. Но это уже совсем другая история.
P.P.S. Кстати, если вы хотите помочь нашей мобильной команде с изобретением других интересных технологий, то вакансии ждут. Мы ищем разработчиков (C, C++, Java), дизайнеров, руководителей проектов, специалистов по продуктам и тестировщиков в офисы Яндекса в Москве, Санкт-Петербурге и Новосибирске.
