Comments 121
А для линукса будут плюшки?
Да. Новый алгоритм синхронизации используется в ПО для linux версии 0.1.5.870.
UFO just landed and posted this here
Вопрос немного в другом направлении есть. Можно ли пользоваться Яндекс.Диском на разных учетных данных? То есть если есть несколько учеток.
Когда история файлов на Яндекс.Диск появится? Ждем уже который год.
у меня яндекс диск умудрялся выедать по 8-9гб озу, что считаю овер жестоко))) Ну и цпу выедался.
Плюс вопрос к яндексу. Данные изменения снизят появление файлов с идексом (2)? Просто в своё время на дропбоксе у меня таких проблем не возникало, на гугл диксе крайне редко а с яндекс диском такое случается ооочень часто, и это напрягает, учитывая что у меня там хранятся гит репозитории частенько, и вычищать иногда просто вымораживает. А за апдейт спасибо!
Плюс вопрос к яндексу. Данные изменения снизят появление файлов с идексом (2)? Просто в своё время на дропбоксе у меня таких проблем не возникало, на гугл диксе крайне редко а с яндекс диском такое случается ооочень часто, и это напрягает, учитывая что у меня там хранятся гит репозитории частенько, и вычищать иногда просто вымораживает. А за апдейт спасибо!
А есть ли возможность запустить клиентский Яндекс.Диск на сервере как службу?
В настоящее время такая возможность есть только в linux версии.
Подскажите пожалуйста а как вы определяете изменения на уровне файловой системы? Используете ли вы стандартный windows-ский FO watcher. Если нет, то подскажите какое у вас решение, если же да, то как вы справляетесь с косолапостью данного чуда природы?
Я не работаю да дропбокс, честно. Я знаком с этой темой не по наслышке и в прошлом много пострадал от FO watcher-а в задачах синхронизации.
Заранее благодарю.
Я не работаю да дропбокс, честно. Я знаком с этой темой не по наслышке и в прошлом много пострадал от FO watcher-а в задачах синхронизации.
Заранее благодарю.
Да, используем, если вы про ReadDirectoryChanges и т.п. Доверять этому способу, действительно, нельзя, хотя бы потому, что программа получает эти сообщения, только когда она работает. Поэтому используйте дополнительно листинг папки, в которой произошли изменения, и тогда вы ничего не пропустите.
Спасибо, я немного опечатался выше, я имел ввиду FS watcher. Который как раз реализован на Win32 api функционале, если мне не изменяет память. Я помню что при использовании из .NET там были проблемы с утечкой памяти при большем объеме папок и файлов.
Попробуем. Старая версия нестабильно работала когда на диске было всего несколько сотен файлов всего, а действия были уровня «обновить версию файла». Если же открывать проект из VS, лежащий на диске и засинхронизированный у нескольких пользователей, то файлы проекты у всех остальных пользователей минут через 20 переставали обновляться.
Но я верю в вас:) По крайней мере бэкапер под WD-харды где-то с год назад таки научился корректно все такие ситуации обрабатывать)
Но я верю в вас:) По крайней мере бэкапер под WD-харды где-то с год назад таки научился корректно все такие ситуации обрабатывать)
Если же открывать проект из VS, лежащий на диске и засинхронизированный у нескольких пользователей, то файлы проекты у всех остальных пользователей минут через 20 переставали обновляться.
вы определённо не то делаете.
Ломаю Яндекс Диск?:)
* Дропбокс с этим справляется, кстати.
* Дропбокс с этим справляется, кстати.
Используйте, пожалуйста, систему контроля версий для таких задач, например Git
Я не работаю с проектом одновременно с разных машин. Но хочу его открывать с нескольких своих компов. То, что ЯД с таким не справлялся — выглядело смешно. Все конкуренты это давно умеют.
Git я тоже использую. Но не для всех проектов подходит открытый GitHub, а поднимать под какие-то мелкие проекты на побаловаться отдельную свою систему и настраивать её на всех компах на которых могу работать — влом.
Git я тоже использую. Но не для всех проектов подходит открытый GitHub, а поднимать под какие-то мелкие проекты на побаловаться отдельную свою систему и настраивать её на всех компах на которых могу работать — влом.
Если не хотите платить за GitHub — есть бесплатный Bitbucket
Господи. Я вам про Фому, вы мне про Ерёму. Я вам указываю на конкетный баг программы. Баг не в высоконагруженных проектах. Баг ни при каких-то запредельных режимах эксплуатации. Баг в повседневном потреблении одного человека. Баг, которого нет ни у одного из конкурентов.
Да, я знаю как решать такие проблемы. И да, я пользовался битбакетом. И, да, там тоже есть куча ограничений, например размер репозитория и размер файлов + более сложная настройка + Git, который требует некоторых дополнительных сил на использование.
* и да, я надеюсь, что в текущей версии этот баг таки вычистили
Да, я знаю как решать такие проблемы. И да, я пользовался битбакетом. И, да, там тоже есть куча ограничений, например размер репозитория и размер файлов + более сложная настройка + Git, который требует некоторых дополнительных сил на использование.
* и да, я надеюсь, что в текущей версии этот баг таки вычистили
Кстати, ЯД при синхронизации (т.е. банальном бэкапе в облако, а не как выше :) ) ломает у меня Git репозитории. Что старая версия, что новая.
Ребята, сделайте возможность загружать большие файлы, цены вам не будет.
4Гб это маловато, бэкапы хранить неудобно.
4Гб это маловато, бэкапы хранить неудобно.
Всем проголосовавшим за статью будет автоматически установлен Яндекс.Браузер
Хорошая новость, долго мучался от чрезмерного аппетита к цпу у яндекс диска. Часто приходилось отключать синхронизацию и только на ночь включать.
Давно хотел спросить: можно ли ограничить нагрузку Я.Диском на процессор при загрузке файлов? К примеру, если загружаешь папку с большим количеством файлов, то ближайший час пока она синхронизируется работать с компьютером не комфортно, а при параллельном запуске тяжелых приложений так и вообще проблематично.
Диск это программа фоновая, она не должна занимать большую часть процессорного времени, разве не так?
Диск это программа фоновая, она не должна занимать большую часть процессорного времени, разве не так?
Пониженный приоритет процессу Я.Диска задавать не пробовали в диспетчере задач? Хотя конечно по-хорошему он сам себе его мог бы таким выставлять, хотя бы в ситуациях, когда видит нагрузку на процессор и/или диск со стороны других приложений.
Да, все так. Спасибо. Мы стараемся, чтобы приложение работало в фоне и не мешало. Настройки такой нет, стараемся, чтобы так работало «из коробки». Подумаем об этом.
Может немного не в тему, но можно как-то настроить одну(!) папку, чтоб в ней были лишь ссылки/ярлыки на файлы? Вроде bitcasa так делала или я ошибаюсь.
Т.е. хочется:
— создать папку
— указать для папки размер кэша (укажу -1, то всегда скачиваю с интернета; укажу 0, то ничего не удаляет, как сейчас работает; укажу 1Гб, тут понятно)
— все что закину в эту папку будет отправлено в облако
— живые файлы, в этой папке, будут заменены на ярлыки/ссылки в облако
— когда открываю какой-то файл, то он скачивает этот файл и заменяет ярлык/ссылку на реальный файл
— в фоновом режиме смотрим размер кэша, если превышаем, то удаляем, что давно не открывали или редко совсем открываем, и заменяем живой файл обратно ярлыком/ссылкой
SSD диски на всех машинах и быстро место кончается, кучу файлов, которые не так страшно потерять, но и удалить рука не поднимается, а так закинул в эту папку и автоматом почистил места на ноуте. Если надо будет то скачал назад. Что-то вроде корзины.
Может что напридумывал, возможно уже так и работает, просто хотелось уточнить как сделать.
Т.е. хочется:
— создать папку
— указать для папки размер кэша (укажу -1, то всегда скачиваю с интернета; укажу 0, то ничего не удаляет, как сейчас работает; укажу 1Гб, тут понятно)
— все что закину в эту папку будет отправлено в облако
— живые файлы, в этой папке, будут заменены на ярлыки/ссылки в облако
— когда открываю какой-то файл, то он скачивает этот файл и заменяет ярлык/ссылку на реальный файл
— в фоновом режиме смотрим размер кэша, если превышаем, то удаляем, что давно не открывали или редко совсем открываем, и заменяем живой файл обратно ярлыком/ссылкой
SSD диски на всех машинах и быстро место кончается, кучу файлов, которые не так страшно потерять, но и удалить рука не поднимается, а так закинул в эту папку и автоматом почистил места на ноуте. Если надо будет то скачал назад. Что-то вроде корзины.
Может что напридумывал, возможно уже так и работает, просто хотелось уточнить как сделать.
Яндекс.Диск умеет webdav, дальше всё зависит от используемой ОС и от того, есть ли под нее софт, который позволяет смонтировать webdav, как нечто, с которым можно работать локальным ПО. Ну а для контента, который нужен локально и в скачанном виде поставить нормальный Яндекс.Диск, выборочная синхронизация там вроде есть.
Действительно, посмотрите на настройки выборочной синхронизации программе и на WebDAV. В десктопном ПО у нас задача сделать так, чтобы файлы, которые вы положили в папку Диска были у вас и локально и в облаке.
А тот сценарий работы, который вы описываете у нас реализуют мобильные клиенты.
А тот сценарий работы, который вы описываете у нас реализуют мобильные клиенты.
Попробуйте Microsoft OneDrive. В нём под Windows 8.1 любой файл можно пометить как "доступный только в облаке". Он тогда как бы остаётся на месте (виден в папке, любая программа его может совершенно прозрачно открыть, если потребуется), но места физически на диске не занимает.
Простите, но я не смог понять несколько моментов, не могли бы вы их прояснить?
* Как производилась (и производится) миграция со старой версии на новую? Что, если пользователь все еще сидит на старой версии Яндекс.Диска?
* Как ведет себя алгоритм в описанных вами граничных случаев вроде «один пользователь изменил содержимое каталога, а второй пользователь этот каталог переименовал»?
* Как производилась (и производится) миграция со старой версии на новую? Что, если пользователь все еще сидит на старой версии Яндекс.Диска?
* Как ведет себя алгоритм в описанных вами граничных случаев вроде «один пользователь изменил содержимое каталога, а второй пользователь этот каталог переименовал»?
Мы автоматически обновляем версию ПО у пользователей. Однако, обновление не всегда устанавливается сразу, так как мы стараемся не мешать, откладываем обновление, если компьютер активно используется. Проверить наличие обновлений можно в окне «О программе».
Про конфликтную ситуацию – все зависит от порядка применения изменений на бекенде.
В первом случае сначала у первого пользователя будет применено изменение из облака. Папка получит новое имя. После этого изменения в этой папке будут синхронизированы с облаком.
Если же переименование, сделанное вторым пользователем, не успело попасть в облако, то сначала завершится синхронизация изменений сделанных первым пользователем, потом в облаке выполнится переименование папки, которое сделал второй, и в заключение это переименование применится локально у первого пользователя.
Результат в любом случае будет один и тот же.
Сложность тут, скорее, в том, что из-за асинхронности всех действий нужно уметь подхватывать изменения налету.
Про конфликтную ситуацию – все зависит от порядка применения изменений на бекенде.
В первом случае сначала у первого пользователя будет применено изменение из облака. Папка получит новое имя. После этого изменения в этой папке будут синхронизированы с облаком.
Если же переименование, сделанное вторым пользователем, не успело попасть в облако, то сначала завершится синхронизация изменений сделанных первым пользователем, потом в облаке выполнится переименование папки, которое сделал второй, и в заключение это переименование применится локально у первого пользователя.
Результат в любом случае будет один и тот же.
Сложность тут, скорее, в том, что из-за асинхронности всех действий нужно уметь подхватывать изменения налету.
Миграция проводится автоматически, если она не запрещена Вами в Настройках. На сегодня уже 98% пользователей Диска живут на новой версии. Версию на своем компьютере можно проверить, посмотрев Справка/О программе. Номер новой версии — 1.3.3 и выше.
Вы знаете, вопрос использования Я-диска в доолнение к SSD в ноутбуке/компе весьма и весьма важен. За это как раз можно платить за подписку (как ни странно, сейчас все онлайн-сервисы сделались облаками для синхронизации, а не для хранения, так что на этом фоне выделиться — милое дело).
Вопрос в чем: если я на ноутбуке и на телефоне настроил Я.диск, то не факт, а и там, и там у меня места — кот наплакал (128 Гб на ноуте, и 1 или 32 Гб в телефоне; не вопрос, что этот объем можно расширить, а исходим из предположения, что «места никогда много не бывает»), и что я хочу иметь на компе и на телефоне только те данные, которые мне нужны в данный момент, а остальные держать в облаке. Идеально задать, что вот эту и эту папку убрать в облако, а вот эту и эту — скачать на устройство. И при этом четко показать, какие файлы на устройстве можно локально удалять так, чтобы в облаке их копии (если включено — то и со всеми версиями) сохранялись.
Потому что сейчас, сколько я ваш Диск не ставил, меня не покидает странное ощущение: я то получаю (т.е. клиент Диска мне их весело скачивает, забивая канал и процессор) из облака документы, которые мне в данный момент не нужны, то, наоборот, боюсь стереть файл на локальном диске из-за того, что не уверен, как поведет себя его копия в облаке — удалится «за компанию», или останется в целости. Это двойственной ощущение прямо отличается от того, что хочется получать от некого места хранения, от чего я я.Диск и другие облачные сервисы (уверен — хорошие) если и исползую, то опасливо. Один пока выход: не ставить клиента на комп, а грузить/загружать файлы через веб. Но это уже не удобство получаем, а мазохизм.
Серьезно, сделайте это, я уверен (да и читаю выше) — я не один такой, страждущий!
P.S. И, да, хотел спросить: вы пользуетесь фичами файловых систем при работе с файлами? Скажем, shadow copy у ntfs, или снапшотами у тех ФС, что их умеют и если юзер не запретил? Хочется иметь атомарно целостные версии файлов, особенно когда ОС это позволяет и ФС может помочь.
Вопрос в чем: если я на ноутбуке и на телефоне настроил Я.диск, то не факт, а и там, и там у меня места — кот наплакал (128 Гб на ноуте, и 1 или 32 Гб в телефоне; не вопрос, что этот объем можно расширить, а исходим из предположения, что «места никогда много не бывает»), и что я хочу иметь на компе и на телефоне только те данные, которые мне нужны в данный момент, а остальные держать в облаке. Идеально задать, что вот эту и эту папку убрать в облако, а вот эту и эту — скачать на устройство. И при этом четко показать, какие файлы на устройстве можно локально удалять так, чтобы в облаке их копии (если включено — то и со всеми версиями) сохранялись.
Потому что сейчас, сколько я ваш Диск не ставил, меня не покидает странное ощущение: я то получаю (т.е. клиент Диска мне их весело скачивает, забивая канал и процессор) из облака документы, которые мне в данный момент не нужны, то, наоборот, боюсь стереть файл на локальном диске из-за того, что не уверен, как поведет себя его копия в облаке — удалится «за компанию», или останется в целости. Это двойственной ощущение прямо отличается от того, что хочется получать от некого места хранения, от чего я я.Диск и другие облачные сервисы (уверен — хорошие) если и исползую, то опасливо. Один пока выход: не ставить клиента на комп, а грузить/загружать файлы через веб. Но это уже не удобство получаем, а мазохизм.
Серьезно, сделайте это, я уверен (да и читаю выше) — я не один такой, страждущий!
P.S. И, да, хотел спросить: вы пользуетесь фичами файловых систем при работе с файлами? Скажем, shadow copy у ntfs, или снапшотами у тех ФС, что их умеют и если юзер не запретил? Хочется иметь атомарно целостные версии файлов, особенно когда ОС это позволяет и ФС может помочь.
Как я понял, вы имеете в виду вот эту страничку настроек?:
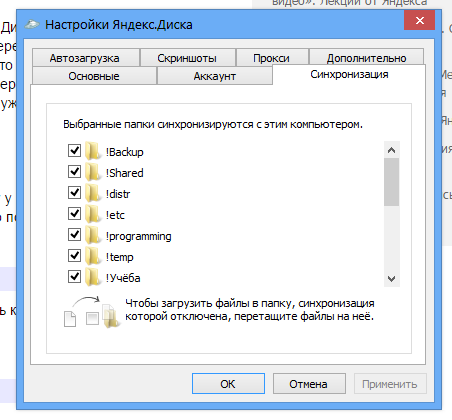

Нет, не совсем. Эту вкладку я знаю, но из нее никак не понять, что будет, если я, имея «для папки» галочку включенной, удалю один из файлов в это папке. Полагаю, что файл удалится и в облаке, а это вовсе не то, что я пытаюсь получить. Хочется, наоборот, иметь возможность держать файлы в облаке, а на рабочем ПК иметь копии лишь нужных из этих файлов.
Более того, т.к. Облако — это механизм синхронизации между разными устройствами, и на разных устойствах мне интересны разные файлы (на работе закидываю на Я.Диск копии проекта рабочего, дома — какие-то домашние файлы).
Смысл в том, чтобы с небольшим размером локального диска можно было работать с многими файлами, отправляя не самое нужное в облако, и стирая локально те или иные части наборов файлов по мере необходимости в диковом пространстве.
Более того, т.к. Облако — это механизм синхронизации между разными устройствами, и на разных устойствах мне интересны разные файлы (на работе закидываю на Я.Диск копии проекта рабочего, дома — какие-то домашние файлы).
Смысл в том, чтобы с небольшим размером локального диска можно было работать с многими файлами, отправляя не самое нужное в облако, и стирая локально те или иные части наборов файлов по мере необходимости в диковом пространстве.
У Яндекс.диска пока наверное самая удобная для меня штука — скриншоты. Очень клево можно на лету заскринить кусок, добавить текст, показать стрелкой что-то. Только вот функционала маловато конечно. Будет ли совершенствоваться редактор скриншотов?
Да, скриншотилку будем развивать. Что бы вам хотелось добавить?
Как пример — панельку со скажем последними 10 или другим количеством скриншотов, чтобы можно было реализовать такой сценарий — сделать подряд, допустим, 3 разных скриншота, и объединить их в одной картинке. Еще очень хорошим сценарием было бы расширение до функционала Screen Recorder.
Пожалуюсь. На Маке скриншотилка Я.Диска искажает цвета, и это довольно критично для дизайнеров. Если при первом скриншоте разницу заметит не каждый (хотя она есть), то если заскриншотить саму же скриншотилку 5 раз подряд, получим следующее:

Я нашел выход из этой ситуации: приходится делать скриншот не области, а окна (в этом режиме с цветами все ок), и делать нужный мне кроп. Если не придется прибегать к такому хаку, буду очень вам благодарен.

Я нашел выход из этой ситуации: приходится делать скриншот не области, а окна (в этом режиме с цветами все ок), и делать нужный мне кроп. Если не придется прибегать к такому хаку, буду очень вам благодарен.
1. В Ticket#14042122590267937 почти год назад просил чтобы добавили кнопку в граф-редакторе диска — «скопировать в буфер обмена»
сейчас внизу есть только кнопки «сохранить» и «поделиться» и куча свободного места.
Буфер обмена мне удобен когда я вставляю картинку в почтовик или word… понимаю, что это не приоритетная задача,
но с другой стороны ее ведь сделать очень просто и надеюсь что эта хотелка просто затерялась и кнопка когда-то появится.
2. Сейчас все картинки лежат в одном каталоге в формате YandexDisk\Скриншоты\2015-03-14 12-46-02 Скриншот экрана.png"
можете добавить галку по которой картинки будут группироваться в подкаталоги (например по месяцам)
сейчас внизу есть только кнопки «сохранить» и «поделиться» и куча свободного места.
Буфер обмена мне удобен когда я вставляю картинку в почтовик или word… понимаю, что это не приоритетная задача,
но с другой стороны ее ведь сделать очень просто и надеюсь что эта хотелка просто затерялась и кнопка когда-то появится.
2. Сейчас все картинки лежат в одном каталоге в формате YandexDisk\Скриншоты\2015-03-14 12-46-02 Скриншот экрана.png"
можете добавить галку по которой картинки будут группироваться в подкаталоги (например по месяцам)
1. Копирование в редакторе скриншотов работает — нажмите [Ctrl]+[C]. Если нет выделенного объекта, то копируется все изображение. Если есть, то только выделенный объект. Скопированную картинку можно вставить, например, в Word.
2. Спасибо за предложение, подумаем.
Есть еще несколько полезных хоткеев в редакторе скриншотов:
[Ctrl]+[Z] — Undo
[Ctrl]+[Y] — Redo
[Ctrl]+[0] — Zoom 100%
[Ctrl]+[+] — Zoom in
[Ctrl]+[-] — Zoom out
Если хочется на скриншоте выделить окно, то можно удерживать [Shift] при добавлении фигуры. Так же можно быстро обрезать картинку по размерам одного из окон на скриншоте.
2. Спасибо за предложение, подумаем.
Есть еще несколько полезных хоткеев в редакторе скриншотов:
[Ctrl]+[Z] — Undo
[Ctrl]+[Y] — Redo
[Ctrl]+[0] — Zoom 100%
[Ctrl]+[+] — Zoom in
[Ctrl]+[-] — Zoom out
Если хочется на скриншоте выделить окно, то можно удерживать [Shift] при добавлении фигуры. Так же можно быстро обрезать картинку по размерам одного из окон на скриншоте.
Не сочтите за рекламу: cloudshot.codeplex.com/
Делаю в качестве хобби проекта с экс-коллегами, недавно выпустили версию с редактором. На текущий момент есть интеграция с Dropbox
Делаю в качестве хобби проекта с экс-коллегами, недавно выпустили версию с редактором. На текущий момент есть интеграция с Dropbox
Для скриншотов удобная штука — Jing. Вот пример: http://screencast.com/t/I6nS3zEBrQ.
Я понимаю, что этому не бывать (надо же как-то деньги зарабатывать), но выпустили бы вы это как библиотеку — можно было бы шикарный локальный бэкап запилить. А то бэкап на винде — ужасный гимор…
В чем проблемы бэкапов на винде?
В том, чт оони не работают. Родной бэкап виснет в процессе, просто ничего не говоря. Купил винт с какой-то утилитой бэкапирования — ьэкапит чего-то часов шесть, потом вылетает, бэкап не возобновляется. Учитывая количество времени, требующееся на одну попытку, настройка бэкапа на машине превращается в неподъемный проект.
Бэкаплю терабайт фото, видео и документов.
Бэкаплю терабайт фото, видео и документов.
А что именно вам хочется получить от такой библиотеки? У нас есть несколько открытых API, с помощью которых можно работать с нашим облаком — WebDAV, например. И обязательно посмотрите на новый REST API.
У вас после введения двухфакторной аутентификации WebDAV «поломался». Не хочет авторизовывать (Win/Lin). В техподдержку написал. Пока починить не смогли, посоветовали использовать web-клиент. :(
Мне хочется получить софт, который сможет бэкапить мой фото-видео архив на винт (1-2 терабайт). Наверное, это не очень правильный путь, да? Потому что я в идеале хочу версионность и инкрементальность…
Использую Яндекс.Диск в основном для фотографий, видео и скриншотов. Пожалуйста сделайте так чтобы фотографии и их миниатюры в вебе «отдавались» быстрее. Сейчас чтобы показать друзьям фотографии прямо из облака приходится набираться терпения.
Еще хотелось бы импорт фотографий с устройств с сортировкой по дате/месту.
В Диске уже есть автозагрузка фотографий, как с мобильных, так и с фотоаппаратов, при подключении их к компьютеру, на котором установлен Диск.
Автоматически загруженные фото в вебе и в мобильном хранятся в папке Фотокамера, в которой в вебе и на мобильном фото организованы по дате съемки и разбиты на месяца.
В перспективе мы планируем улучшать удобство работы с фотографиями.
Автоматически загруженные фото в вебе и в мобильном хранятся в папке Фотокамера, в которой в вебе и на мобильном фото организованы по дате съемки и разбиты на месяца.
В перспективе мы планируем улучшать удобство работы с фотографиями.
Добрый день!
Скорость отдачи и показа изображений зависит от клиентского окружения, сети передачи данных и от серверного ПО. Мы работаем над оптимизацией наиболее «тяжелых» мест во всей этой цепочке: от запроса картинки до ее показа, чтобы картинки показывались как можно быстрее.
Скорость отдачи и показа изображений зависит от клиентского окружения, сети передачи данных и от серверного ПО. Мы работаем над оптимизацией наиболее «тяжелых» мест во всей этой цепочке: от запроса картинки до ее показа, чтобы картинки показывались как можно быстрее.
У нас бывают проблемы со скоростью отдачи превью. Оптимизируем.
Подскажите, Яндекс-диск научился не перекачивать целиком файл, если изменилось в нем совсем немножко? А то раньше помнится, мой архив outlook размером в 5гб перекачивался целиком после добавления туда 10-20 мб.
Скорость получения дайджеста файла увеличена примерно в два раза.
Воспользуйтесь каким-нибудь современным и быстрым алгоритмом хеширования (вроде xxhash) вместо медленных sha256 и md5, и у вас будет повод написать о том, что скорость выросла не в 2, а в 20-30 раз.
Поясню. Криптографические хеши sha256 и MD5 (как и древний некриптографический CRC32), которые вы используете для решения этих задач, имеют потолок производительности 300-500 Мбайт/с на одном ядре. То есть если читать и хешировать данные с SSD, то потребление CPU будет где-то в районе 100%.
При этом у вас описаны следующие цели:
Эти задачи применения криптографических хеш-функций не требуют. Для их решения логичнее использовать быстрые некриптографические хеши (например вышеназванный xxhash, по ссылке есть небольшое сравнение).
При этом у вас описаны следующие цели:
Яндекс.Диск использует дайджесты sha256 и MD5 для проверки целостности файлов, обнаружения изменившихся фрагментов и дедупликации файлов на бекенде.
Эти задачи применения криптографических хеш-функций не требуют. Для их решения логичнее использовать быстрые некриптографические хеши (например вышеназванный xxhash, по ссылке есть небольшое сравнение).
для дедупликации скорее всего можно использовать только криптографические хеши.
Это заблуждение. Основное требование к криптографическим функциям — сложность поиска коллизий к хешу, к дедупликации это требование никакого отношения не имеет. Хотя zfs использует sha256, да. Вот тут хороший ответ о выборе хеш-функции.
Спасибо за совет! Все не так просто, так как решение о смене алгоритма хэширования выходит за рамки десктопного приложения — оно должно быть поддержано на бекенде и другими приложениями.
Кстати, вы ведь не используете gzip компрессию?
Используем во время передачи, если компрессия эффективна для конкретного файла.
Zlib жмет 20 Мбайт в секунду при 100% утилизации ядра.
Более современные LZ4 и Snappy (этот последний — от Google) при чуть более низком коэффициенте компрессии жмут 300-400 Мбайт на одном ядре, то бишь работают в 15-20 раз быстрее. Так что если стоит цель сэкономить CPU — на мой взгляд логичнее вместо zlib использовать их (при условии что и сервер, и клиент — ваша кодовая база, а в вашем случае это так).
Более современные LZ4 и Snappy (этот последний — от Google) при чуть более низком коэффициенте компрессии жмут 300-400 Мбайт на одном ядре, то бишь работают в 15-20 раз быстрее. Так что если стоит цель сэкономить CPU — на мой взгляд логичнее вместо zlib использовать их (при условии что и сервер, и клиент — ваша кодовая база, а в вашем случае это так).
Это очень хорошая новость. Я даже убрал фотографии с Диска, чтобы не потерять их. После нескольких быстрых действий с папками и файлами они, бывало, просто исчезали с Диска. Теперь попробую осторожно вернуть их.
Самое же страшное стряслось, когда я на одну из папок на Диске натравил Bittorrent Sync. Вот тут оба взбесились и потерли очень серьезно все, что там было. Bittorrent Sync, похоже, быстро создавал временные файлы — и Яндекс.Диск не успевал их понять. И решал стереть от греха подальше :) В общем, спасибо, потестирую.
Самое же страшное стряслось, когда я на одну из папок на Диске натравил Bittorrent Sync. Вот тут оба взбесились и потерли очень серьезно все, что там было. Bittorrent Sync, похоже, быстро создавал временные файлы — и Яндекс.Диск не успевал их понять. И решал стереть от греха подальше :) В общем, спасибо, потестирую.
Действительно, стало лучше.
Спасибо.
Спасибо.
Вы индексируете Диск?
А картинки распознаете?
А картинки распознаете?
Если у вас есть картинки с текстом, то Диск их распознает. Можно делать поиск на вебном Диске по словам с картинок.
А что Вы имеете в виду под индексацией?
А что Вы имеете в виду под индексацией?
Что насчет delta sync?
Есть вопрос к разработчикам.
Яндекс Диск в одной из организаций используется как средство хранения бэкапов. Так вот есть один неприятный момент…
Бэкапы делаются программно и старые версии автоматически удаляются (а Яндекс Диск помещает их в свою корзину), а новые соответственно создаются и сохраняются в папке с бэкапами.
Яндекс Диск, помещает старый бэкап в корзину и там их начинает складировать, при этом так как бэкапы большие, то корзина очень быстро доходит до предельного размера, после чего синхронизация перестает работать, так как 80% объема диска в корзине и они учитываются при определении размеров Яндекс Диска. При этом автоматическая очистка, когда доходим до предельных размеров не работает(!)
Приходится заходить через веб-интерфейс в Яндекс Диск и в корзине нажимать на кнопку «Очистить корзину» и только потом синхронизация начинает нормально работать.
Хотелось бы услышать от разработчиков, это баг или фича? :)
Яндекс Диск в одной из организаций используется как средство хранения бэкапов. Так вот есть один неприятный момент…
Бэкапы делаются программно и старые версии автоматически удаляются (а Яндекс Диск помещает их в свою корзину), а новые соответственно создаются и сохраняются в папке с бэкапами.
Яндекс Диск, помещает старый бэкап в корзину и там их начинает складировать, при этом так как бэкапы большие, то корзина очень быстро доходит до предельного размера, после чего синхронизация перестает работать, так как 80% объема диска в корзине и они учитываются при определении размеров Яндекс Диска. При этом автоматическая очистка, когда доходим до предельных размеров не работает(!)
Приходится заходить через веб-интерфейс в Яндекс Диск и в корзине нажимать на кнопку «Очистить корзину» и только потом синхронизация начинает нормально работать.
Хотелось бы услышать от разработчиков, это баг или фича? :)
UFO just landed and posted this here
А почему на Mac программа справляется с втрое большим количеством файлов?
Опасный вопрос. Mac или Windows?
При работе с большим количеством файлов, естественно, требуется больше оперативной памяти. И тут OS X оказывается эффективнее по нескольким причинам:
При работе с большим количеством файлов, естественно, требуется больше оперативной памяти. И тут OS X оказывается эффективнее по нескольким причинам:
- Apple давно отказался от 32 битных ОС, а Microsoft продолжает их выпускать. На 32 битной системе у любого приложения, которое пытается использовать больше 1.7 Гб, начинаются проблемы.
- У Apple есть Compressed Memory.
- OS X работает с путями (path) в UTF-8, а Windows в UCS-2. То есть в большинстве случаев Windows использует в два раза больше памяти для представления той же строки. Даже если мы храним UTF-8, нам приходится часто выполнять преобразование в формат, который понимает Win API
- Работа с файлами в Windows требует более сложного кода из-за блокировок — всем знакомы ошибки «файл занят другим процессом» и т.п.
Читал новость с телефона. Подумал: о, как круто, надо прицениться и купить (сейчас плачу $99 в год за терабайт Дропбокса). Зашел на мобильный сайт — а там ни тарифов, ничего, только ссылки в аппстор. Ну ладно, request desktop site — и облом, в браузере (мобильный хром) видна только левая часть и очень мешает попап «Войти» по центру. В общем, так и не купил.
С тарифами в итоге ознакомился. Недешево. Буду пока на Дропбоксе, особенно с учетом истории файлов.
С тарифами в итоге ознакомился. Недешево. Буду пока на Дропбоксе, особенно с учетом истории файлов.
Спасибо за комментарии. Окончательно перестал пользоваться ЯД.
Скорость получения дайджеста файла увеличена примерно в два раза.
Скажите, а как получилось ускорить вычисление с sha256?
Алгоритм может и хороший, но теперь у меня каждый день часами крутиться синхронизация, при этом получить ссылку на файл просто нереально. Раньше было лучше.
И сделайте наконец-то возможность выбора начальной папки.
И сделайте наконец-то возможность выбора начальной папки.
То, что не заканчивается синхронизация, баг. Напишите, пожалуйста, в поддержку. Разберёмся. А возможность выбрать папку перед запуском синхронизации уже сделали в версии 1.3.4.
Аналогично, идет бесконечная синхронизация.
Файлы закачивает, но узнать это я могу только открыв wed-версию диска, дождаться заливки, так как в статусе не показывает, что идет upload и какая скорость, а просто всегда висит «Идет синхронизация» и потом из веб забирать ссылку на файл.
И пропали галочки, что файл успешно залит, их просто нет.
Файлы закачивает, но узнать это я могу только открыв wed-версию диска, дождаться заливки, так как в статусе не показывает, что идет upload и какая скорость, а просто всегда висит «Идет синхронизация» и потом из веб забирать ссылку на файл.
И пропали галочки, что файл успешно залит, их просто нет.
Скажите, а возможно как-нибудь запретить синхронизировать файлы с определенным расширением? (мак)
Некоторые программы создают временные файлы при работе с документом, тот же индизайн, например, и они очень не маленькие.
Некоторые программы создают временные файлы при работе с документом, тот же индизайн, например, и они очень не маленькие.
Понекропостю: алгоритм синхронизации просто мега-крутой, позволил мне снести половину архива фотографий одним легким движение мышки безвозвратно и на компе, и в облаке :) И заметил, естественно, только спустя несколько месяцев. Я расстроен, жена расстроена жутко, ТП мажется — радоваться что весь C: как в прошлый раз не форматнули…
Проверяйте свои архивы
Проверяйте свои архивы
А вы сами удалили? Или диск не заметил какие-то ваши действия и грохнул?
Решил переставить систему, предварительно забекапив на я.диск архив фоток. Действовал по следующему алгоритму:
1. Поставил Я.Диск на комп;
2. Через синхронизацию Я.Диска слил папку с фото в облако;
3. С компа снес папку с фото (ессно не отключив её от синхронизации);
4. Я.Диск успешно «синхронизировал» это моё удаление, положив все фото в облаке в свою же облачную корзину;
5. Я переставил систему и не стал заливать всё обратно («пущщай там полежит, авось сохраннее будет!»);
6. Через месяц лежания в корзине в облаке — содержимое дропается безвозвратно;
…
х. Profit!
Через несколько месяцев ищу фото в облаке — нетю ;(
1. Поставил Я.Диск на комп;
2. Через синхронизацию Я.Диска слил папку с фото в облако;
3. С компа снес папку с фото (ессно не отключив её от синхронизации);
4. Я.Диск успешно «синхронизировал» это моё удаление, положив все фото в облаке в свою же облачную корзину;
5. Я переставил систему и не стал заливать всё обратно («пущщай там полежит, авось сохраннее будет!»);
6. Через месяц лежания в корзине в облаке — содержимое дропается безвозвратно;
…
х. Profit!
Через несколько месяцев ищу фото в облаке — нетю ;(
Вы меня, конечно, простите за некрокоммент и вообще, но я обескуражен. Оказывается, Яндекс.Диск при синхронизации файлов с локального компьютера в облако меняет дату и время изменения файлов на дату синхронизации с этим самым облаком. И на другой компьютер они прилетают уже с одинаковыми неверными датами. Написал в поддержку — получил ответ о том, что такое поведение ожидаемо, и, возможно, когда-нибудь исправят, но поток предложений огромен, а ресурсы не безграничны. Но ведь это же базовая вещь! Так было год назад, так есть и сейчас. В итоге тысяча с чем-то руб. за терабайт вылетела в трубу, так как я со своим ворохом документов не могу нормально перенести их в облако, ибо все это после синхронизации по мановению волшебной палочки превращается в кашу с одинаковыми датами :-) В результате не могу пользоваться сервисом, который мне очень нравится во всем остальном. Обидно.
Обнаружил несколько проблем у текущей версии приложения Яндекс.Диск.
Версия 3.2.22 Сборка 4746
Приложение установленное на разных пк в одной сети с одним пользователем иногда пытается дублировать закачки папок, выбранные для загрузки только на одном пк.
Например, выбираем на пк 1 скачать папку A. Через какое-то время пк 2 тоже начинает скачивать папку A. При этом ноутбук с аналогичным приложением и пользователем этого не делает, что правильно.При синхронизации на пк папки Загрузка в какой-то момент приложение начинает что-то считывать и записывать на диск в беконечном цикле при 100% загрузке диска. Даже если вся папка уже синхронизирована. То есть делает бессмысленные фоновые действия.
Sign up to leave a comment.
Новый алгоритм синхронизации Яндекс.Диска: как не подавиться 900 000 файлов