
Яндекс.Диск — один из немногих сервисов Яндекса, частью которого является программное обеспечение для десктопа. И одна из самых важных его составляющих — алгоритм синхронизации локальных файлов с их копией в облаке. Недавно нам пришлось его полностью поменять. Если старая версия с трудом переваривала даже несколько десятков тысяч файлов и к тому же не достаточно быстро реагировала на некоторые «сложные» действия пользователя, то новая, используя те же ресурсы, справляется с сотнями тысяч файлов.
В этом посте я расскажу, почему так получилось: чего мы не смогли предвидеть, когда придумывали первую версию ПО Яндекс.Диска, и как создавали новую.

Прежде всего, о самой задаче синхронизации. Технически говоря, она состоит в том, чтобы в папке Яндекс.Диска на компьютере пользователя и в облаке был один и тот же набор файлов. То есть такие действия пользователя, как переименование, удаление, копирование, добавление и изменение файлов, должны синхронизироваться с облаком автоматически.
Теоретически задача может показаться достаточно простой, но в реальности мы сталкиваемся с разными сложными ситуациями. Например, человек переименовал папку на своем компьютере, мы это детектировали и послали команду на бекенд. Однако никто из пользователей не ждет, пока бекенд подтвердит успешность переименования. Человек сразу открывает свою локально переименованную папку, создает в ней подпапку, и, к примеру, переносит в нее часть файлов. Мы попали в ситуацию, в которой невозможно сразу выполнить все необходимые операции синхронизации в облаке. Сначала надо дождаться завершения первой операции и только потом можно продолжать.
Ситуация может стать еще сложнее, если с одним аккаунтом одновременно работают несколько пользователей или у них есть общая папка. А это случается достаточно часто в организациях, использующих Яндекс.Диск. Представьте себе, что в предыдущем примере в тот момент, когда мы получили от бекенда подтверждение первого переименования, другой пользователь берет и переименовывает эту папку еще раз. В этом случае опять нельзя сразу выполнить действия, которые уже совершил первый пользователь у себя на компьютере. Папка, в которой он работал локально, на бекенде в это время уже называется по-другому.
Бывают случаи, когда файл на компьютере пользователя нельзя назвать так же, как он называется в облаке. Это может произойти, если в имени есть символ, который не может использоваться локальной файловой системой, или в том случае, когда пользователя приглашают в общую папку, а у него есть своя папка с таким именем. В таких случаях нам приходится использовать локальные псевдонимы и отслеживать их связь с объектами в облаке.
В прошлой версии десктопного ПО Яндекс.Диска для поиска изменений использовался алгоритм сравнения деревьев. Любое другое решение на тот момент не позволяло реализовать поиск перемещений и переименований, так как бэкэнд не имел уникальных идентификаторов объектов.
В этой версии алгоритма мы использовали три основных дерева: локальное (Local Index), облачное (Remote Index) и последнее синхронизированное (Stable Index). Кроме этого, чтобы предотвратить повторную генерацию уже поставленных в очередь операций синхронизации, использовались ещё два вспомогательных дерева: локальное ожидаемое и облачное ожидаемое (Expected Remote Index и Expected Local Index). В этих вспомогательных деревьях хранилось ожидаемое состояние локальной файловой системы и облака, после выполнения всех операций синхронизации, которые уже поставлены в очередь.
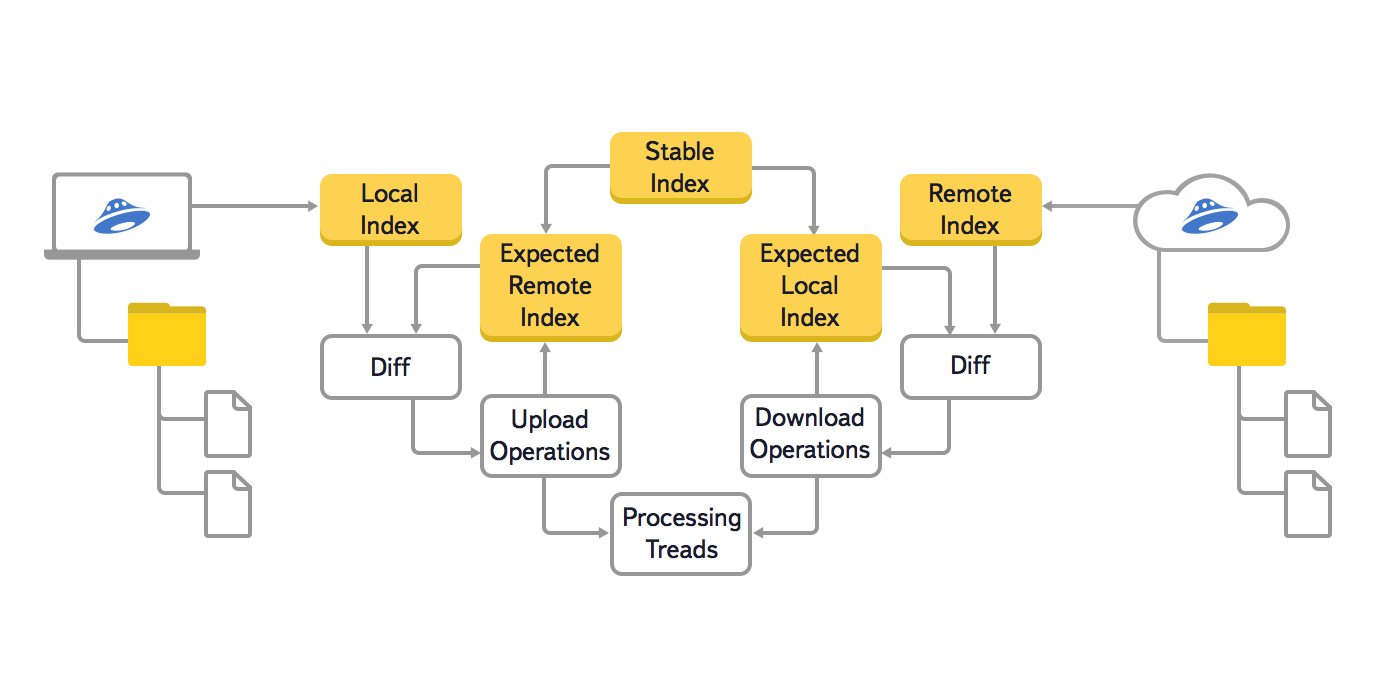
Процедура сравнения деревьев в старом алгоритме выглядела следующим образом:
Главными проблемами алгоритма сравнения деревьев стали большое потребление памяти и необходимость сравнения деревьев целиком даже при небольших изменениях, что приводило к большой нагрузке на процессор. Во время обработки изменений даже одного файла использование оперативной памяти возрастало примерно на 35%. Допустим, у пользователя было 20 000 файлов. Тогда при простом переименовании одного файла размером 10Кб потребление памяти вырастало скачкообразно — со 116Мб до 167МБ.
Также мы хотели увеличить максимальное количество файлов, с которым без проблем может работать пользователь. Несколько десятков и даже сотен тысяч файлов может оказаться, к примеру, у фотографа, который хранит в Яндекс.Диске результаты фотосессий. Эта задача стала особенно актуальной, когда у людей появилась возможность купить дополнительное место на Яндекс.Диске.
В разработке тоже хотелось кое-что поменять. Отладка старой версии вызывала трудности, так как данные о состояниях одного элемента находились в разных деревьях.
К этому времени на бекенде появились id объектов, с помощью которых можно было более эффективно решить задачу обнаружения перемещений — ранее мы использовали пути.
Мы решили изменить структуру хранения данных и заменить три дерева (Local Index, Remote Index, Stable Index) на одно, что должно было привести к снижению избыточности в главной структуре данных. Из-за того что ключом в дереве является путь к элементу файловой системы, в результате объединения значительно сократился объем используемой оперативной памяти.
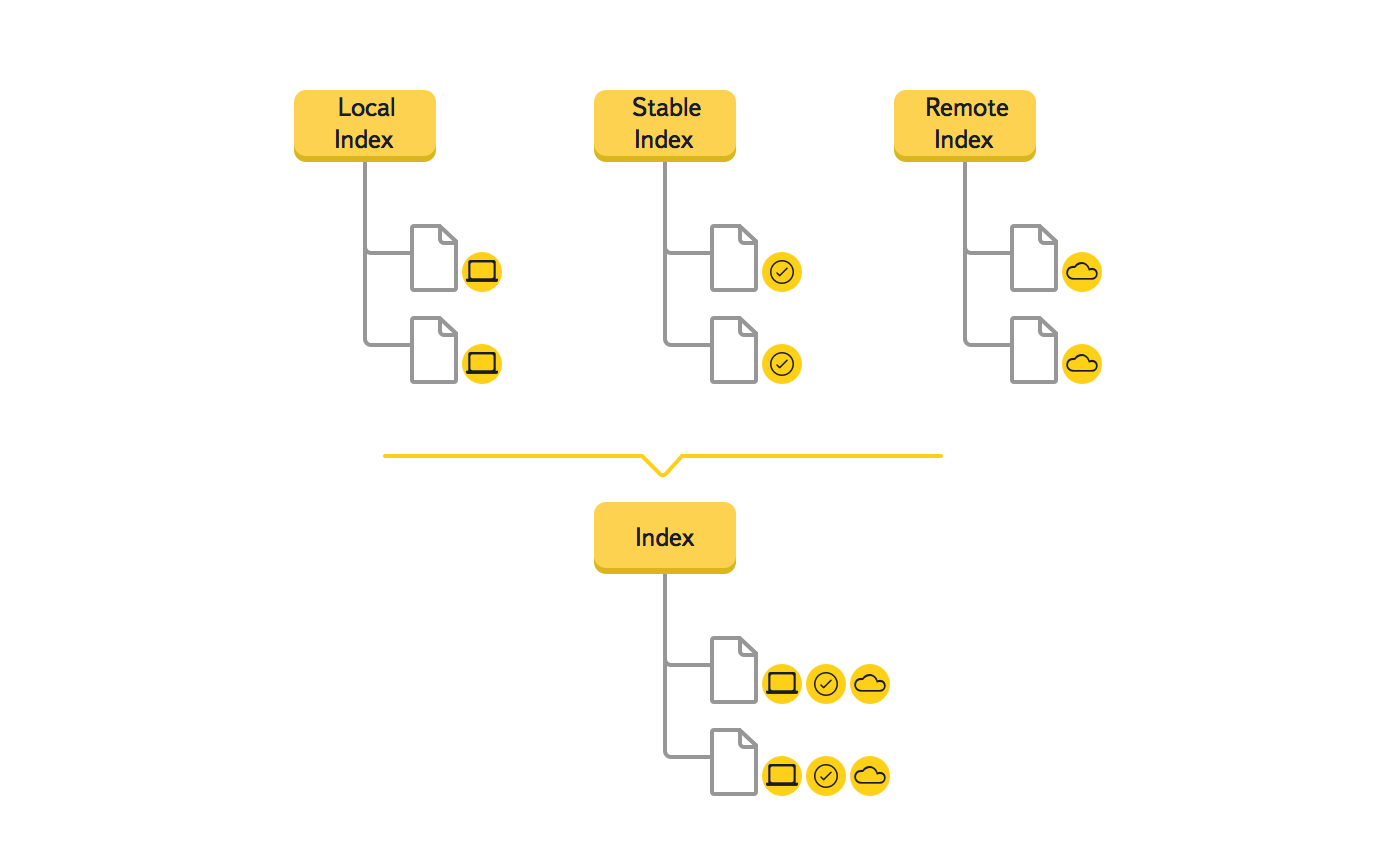
Еще мы отказались от использования вспомогательных деревьев во время синхронизации, потому что каждый элемент дерева в новой версии хранит все нужные данные. Это изменение структуры сильно упростило отладку кода.
Так как мы понимали, что это серьезное изменение, то создали прототип, подтвердивший эффективность нового решения. Рассмотрим на примере, как меняются данные в дереве во время синхронизации нового файла.

На этом примере видно, что в новом алгоритме синхронизации обрабатываются только те элементы и события, данные об изменениях в которых были получены от файловой системы или облака, а не всё дерево целиком, как это было ранее. При необходимости будут обработаны родительские или дочерние узлы (например, в случае перемещения папки).
В новой версии мы поработали и над другими улучшениями, повлиявшими на производительность. Сохранение дерева сделали инкрементальным, что позволяет записывать в файл только последние изменения.
Яндекс.Диск использует дайджесты sha256 и MD5 для проверки целостности файлов, обнаружения изменившихся фрагментов и дедупликации файлов на бекенде. Так как эта задача сильно нагружает CPU, в новой версии реализация расчетов дайджеста была существенно оптимизирована. Скорость получения дайджеста файла увеличена примерно в два раза.
Синхронизация уникальных 20000 файлов по 10Кб
Вычисление дайджестов уникальных 20000 файлов по 10кб (индексация)
Запуск с 20000 синхронизированных файлов по 10Кб
Upload 1Gb. Соединение Wi-Fi 10 МБит
Из примеров видно, что новая версия ПО Яндекс.Диска использует примерно в 3 раза меньше оперативной памяти и примерно в 2 раза меньше нагружает CPU. Обработка мелких изменений не приводит к увеличению объема используемой памяти.
В результате проделанных изменений существенно увеличилось количество файлов, с которым без проблем справляется программа. В версии для Windows – 300 000, а на Mac OS X — 900 000 файлов.
В этом посте я расскажу, почему так получилось: чего мы не смогли предвидеть, когда придумывали первую версию ПО Яндекс.Диска, и как создавали новую.

Прежде всего, о самой задаче синхронизации. Технически говоря, она состоит в том, чтобы в папке Яндекс.Диска на компьютере пользователя и в облаке был один и тот же набор файлов. То есть такие действия пользователя, как переименование, удаление, копирование, добавление и изменение файлов, должны синхронизироваться с облаком автоматически.
Почему это не так просто, как кажется на первый взгляд?
Теоретически задача может показаться достаточно простой, но в реальности мы сталкиваемся с разными сложными ситуациями. Например, человек переименовал папку на своем компьютере, мы это детектировали и послали команду на бекенд. Однако никто из пользователей не ждет, пока бекенд подтвердит успешность переименования. Человек сразу открывает свою локально переименованную папку, создает в ней подпапку, и, к примеру, переносит в нее часть файлов. Мы попали в ситуацию, в которой невозможно сразу выполнить все необходимые операции синхронизации в облаке. Сначала надо дождаться завершения первой операции и только потом можно продолжать.
Ситуация может стать еще сложнее, если с одним аккаунтом одновременно работают несколько пользователей или у них есть общая папка. А это случается достаточно часто в организациях, использующих Яндекс.Диск. Представьте себе, что в предыдущем примере в тот момент, когда мы получили от бекенда подтверждение первого переименования, другой пользователь берет и переименовывает эту папку еще раз. В этом случае опять нельзя сразу выполнить действия, которые уже совершил первый пользователь у себя на компьютере. Папка, в которой он работал локально, на бекенде в это время уже называется по-другому.
Бывают случаи, когда файл на компьютере пользователя нельзя назвать так же, как он называется в облаке. Это может произойти, если в имени есть символ, который не может использоваться локальной файловой системой, или в том случае, когда пользователя приглашают в общую папку, а у него есть своя папка с таким именем. В таких случаях нам приходится использовать локальные псевдонимы и отслеживать их связь с объектами в облаке.
Прошлая версия алгоритма
В прошлой версии десктопного ПО Яндекс.Диска для поиска изменений использовался алгоритм сравнения деревьев. Любое другое решение на тот момент не позволяло реализовать поиск перемещений и переименований, так как бэкэнд не имел уникальных идентификаторов объектов.
В этой версии алгоритма мы использовали три основных дерева: локальное (Local Index), облачное (Remote Index) и последнее синхронизированное (Stable Index). Кроме этого, чтобы предотвратить повторную генерацию уже поставленных в очередь операций синхронизации, использовались ещё два вспомогательных дерева: локальное ожидаемое и облачное ожидаемое (Expected Remote Index и Expected Local Index). В этих вспомогательных деревьях хранилось ожидаемое состояние локальной файловой системы и облака, после выполнения всех операций синхронизации, которые уже поставлены в очередь.
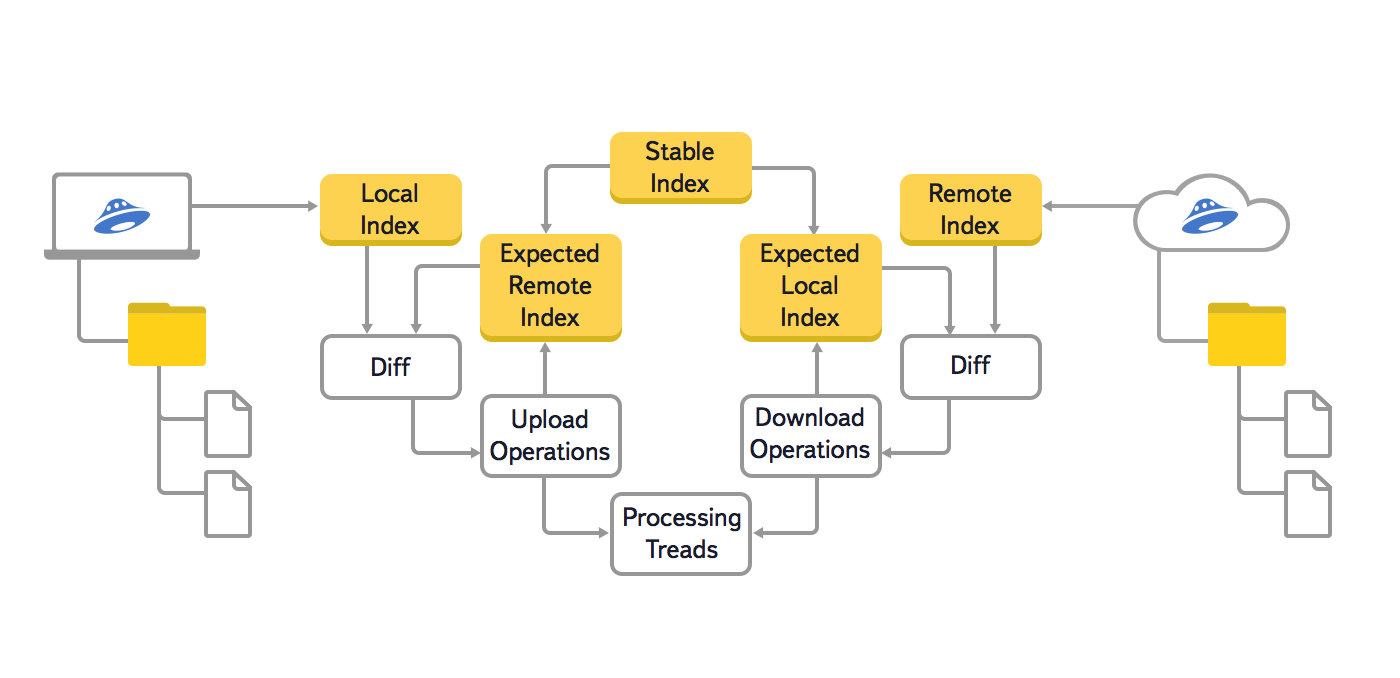
Процедура сравнения деревьев в старом алгоритме выглядела следующим образом:
- Если локальное ожидаемое дерево и облачное ожидаемое дерево пусты, инициализируем их, копируя последнее синхронизированное дерево;
- Сравниваем локальное дерево с облачным ожидаемым и по результатам сравнения отдельных узлов добавляем в очередь операции синхронизации в облаке (создание коллекций, передача файлов в облако, перемещение и удаление в облаке);
- Для всех операций, которые поставлены в очередь на предыдущем шаге, фиксируем их будущий эффект в ожидаемом облачном дереве;
- Сравниваем облачное дерево с локальным ожидаемым и по результатам сравнения отдельных узлов добавляем в очередь операции синхронизации с локальной файловой системой (создание директорий, скачивание файлов из облака, перемещение и удаление локальных файлов и директорий);
- Для всех операций, которые поставлены в очередь на предыдущем шаге, фиксируем их будущий эффект в ожидаемом локальном дереве;
- Если в очередь попадают одновременные операции с одним и тем же файлом или директорией (например, передача файла в облако и скачивание этого же файла из облака), то фиксируем конфликт — файл изменился в двух местах;
- После того, как операция синхронизации выполнена в облаке или с локальной файловой системой, заносим её результат в последнее синхронизированное дерево;
- Когда очередь операций синхронизации становится пустой, удаляем локальное ожидаемое и облачное ожидаемое дерево. Синхронизация закончена, и они нам больше не понадобятся.
Почему нам пришлось придумывать новый алгоритм
Главными проблемами алгоритма сравнения деревьев стали большое потребление памяти и необходимость сравнения деревьев целиком даже при небольших изменениях, что приводило к большой нагрузке на процессор. Во время обработки изменений даже одного файла использование оперативной памяти возрастало примерно на 35%. Допустим, у пользователя было 20 000 файлов. Тогда при простом переименовании одного файла размером 10Кб потребление памяти вырастало скачкообразно — со 116Мб до 167МБ.
Также мы хотели увеличить максимальное количество файлов, с которым без проблем может работать пользователь. Несколько десятков и даже сотен тысяч файлов может оказаться, к примеру, у фотографа, который хранит в Яндекс.Диске результаты фотосессий. Эта задача стала особенно актуальной, когда у людей появилась возможность купить дополнительное место на Яндекс.Диске.
В разработке тоже хотелось кое-что поменять. Отладка старой версии вызывала трудности, так как данные о состояниях одного элемента находились в разных деревьях.
К этому времени на бекенде появились id объектов, с помощью которых можно было более эффективно решить задачу обнаружения перемещений — ранее мы использовали пути.
Новый алгоритм
Мы решили изменить структуру хранения данных и заменить три дерева (Local Index, Remote Index, Stable Index) на одно, что должно было привести к снижению избыточности в главной структуре данных. Из-за того что ключом в дереве является путь к элементу файловой системы, в результате объединения значительно сократился объем используемой оперативной памяти.
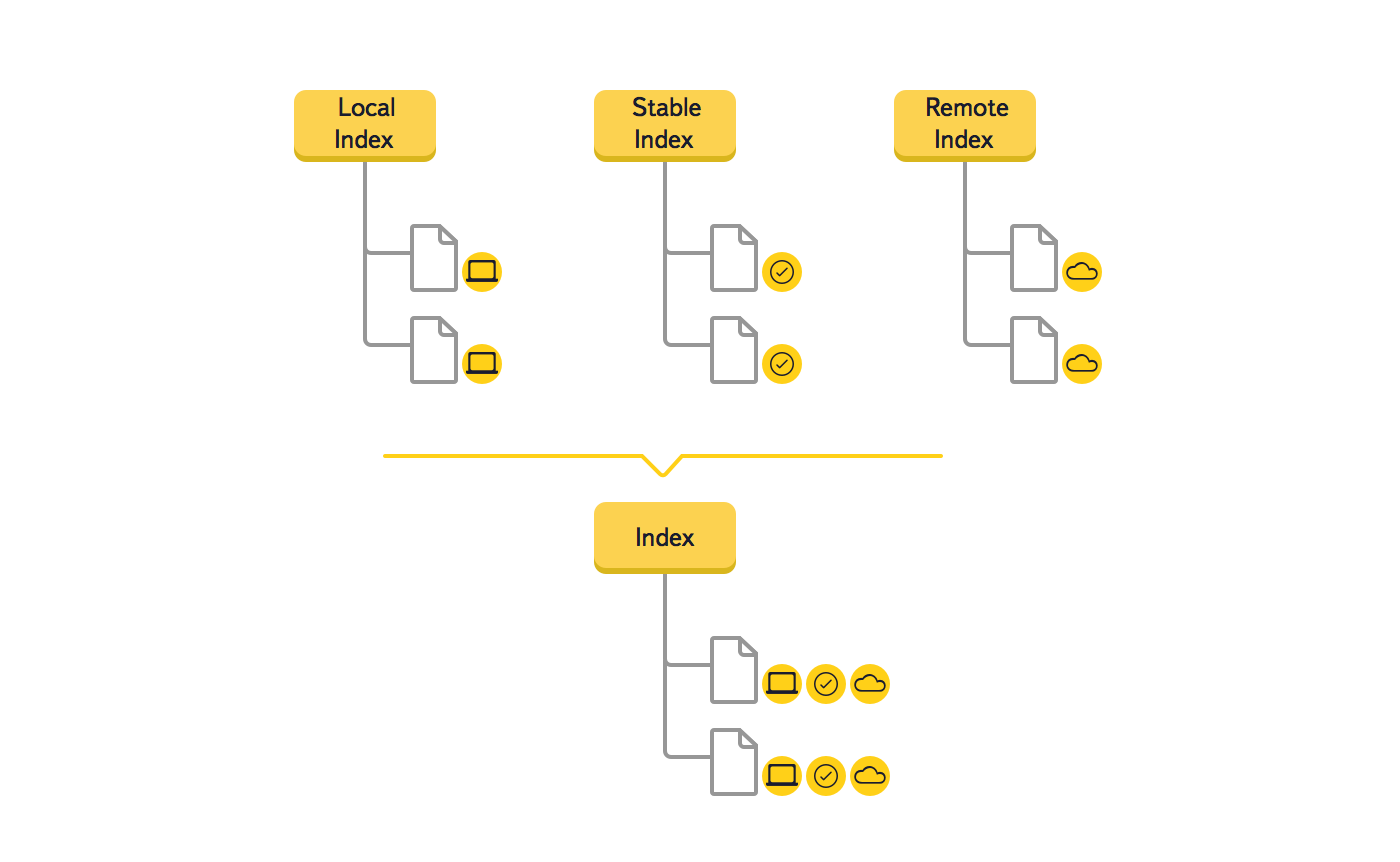
Еще мы отказались от использования вспомогательных деревьев во время синхронизации, потому что каждый элемент дерева в новой версии хранит все нужные данные. Это изменение структуры сильно упростило отладку кода.
Так как мы понимали, что это серьезное изменение, то создали прототип, подтвердивший эффективность нового решения. Рассмотрим на примере, как меняются данные в дереве во время синхронизации нового файла.
- После того как пользователь добавил в папку Диска новый файл, программа обнаружила его и добавила в дерево новый элемент. У этого элемента известно только одно состояние – local. Так как stable и remote состояния отсутствуют, память под них не выделяется;
- Программа выполняет upload файла. Из облака приходит push, подтверждающий появление нового файла, и в дерево добавляется remote состояние;
- Состояния local и remote сравниваются. Так как они совпадают, добавляется stable состояние;
- Состояния local и remote удаляются. Они больше не нужны, так как вся информация есть в stable.

На этом примере видно, что в новом алгоритме синхронизации обрабатываются только те элементы и события, данные об изменениях в которых были получены от файловой системы или облака, а не всё дерево целиком, как это было ранее. При необходимости будут обработаны родительские или дочерние узлы (например, в случае перемещения папки).
Другие улучшения
В новой версии мы поработали и над другими улучшениями, повлиявшими на производительность. Сохранение дерева сделали инкрементальным, что позволяет записывать в файл только последние изменения.
Яндекс.Диск использует дайджесты sha256 и MD5 для проверки целостности файлов, обнаружения изменившихся фрагментов и дедупликации файлов на бекенде. Так как эта задача сильно нагружает CPU, в новой версии реализация расчетов дайджеста была существенно оптимизирована. Скорость получения дайджеста файла увеличена примерно в два раза.
Цифры
Синхронизация уникальных 20000 файлов по 10Кб
| Версия ПО | Загрузка на CPU. Расчет дайджестов |
Нагрузка на CPU upload |
Использование оперативной памяти, Мб |
|---|---|---|---|
| Яндекс.Диск 1.3.3 | 28% (1 ядро 100%) | Примерно 1% | 102 |
| Яндекс.Диск 1.2.7 | 48% (2 ядра 100%) | Примерно 10% | 368 |
Вычисление дайджестов уникальных 20000 файлов по 10кб (индексация)
| Версия ПО | Нагрузка на CPU | Время, сек | Использование оперативной памяти, Мб |
|---|---|---|---|
| Яндекс.Диск 1.3.3 | 25% (1 ядро 100%) | 190 | 82 |
| Яндекс.Диск 1.2.7 | 50% (2 ядра 100%) | 200 | 245 |
Запуск с 20000 синхронизированных файлов по 10Кб
| Версия ПО | Нагрузка на CPU | Время, сек | Использование оперативной памяти, Мб |
|---|---|---|---|
| Яндекс.Диск 1.3.3 | 25% (1 ядро 100%) | 10 | 55 |
| Яндекс.Диск 1.2.7 | 50% (2 ядра 100%) | 22 | 125 |
Upload 1Gb. Соединение Wi-Fi 10 МБит
| Версия ПО | Нагрузка на CPU | Время, сек |
|---|---|---|
| Яндекс.Диск 1.3.3 | 5% | 1106 |
| Яндекс.Диск 1.2.7 | 5% | 2530 |
Что получилось
Из примеров видно, что новая версия ПО Яндекс.Диска использует примерно в 3 раза меньше оперативной памяти и примерно в 2 раза меньше нагружает CPU. Обработка мелких изменений не приводит к увеличению объема используемой памяти.
В результате проделанных изменений существенно увеличилось количество файлов, с которым без проблем справляется программа. В версии для Windows – 300 000, а на Mac OS X — 900 000 файлов.
