Comments 73
Отличный пример ситуации «быстрее снова скачать, чем найти куда сохранил».
Я вижу, что вы тестируете в старой Opera 12. Не думаете отказаться от поддержки устаревающего браузера? У вас есть статистика о том, сколько людей всё ещё им пользуются?
Интересно, почему google diff patch match на IE 9 так медленно работает?
Кстати о мобильной версии Яндекс.Почта: после последнего обновления Яндекс.Почты на Андройд (4.4.3) телефон HTC One телефон постоянно находится в режиме «синхронизации», аккумулятор разряжается в ноль за 2-3 часа. Спасает только удаление приложения из телефона. Это я к тому, что перед выпуском обновлений надо их сперва тщательно тестировать.
Интересно, как выглядит diff для однострочного css файла? Или вы не минифицируете их?
Очень радует что вы проводите подобные эксперименты.
Для этой задачи пока не пробовали. Но у нас уже появляются идеи для второго подхода к снаряду )
В порядке бреда… Вроде бы последние версии браузеров умеют криптографию. И, получается, умеют её нативно, а значит очень быстро. Вы чек-суммы вычисляли js-способом?
Это совсем недавно появилось и почти нигде еще не поддерживается. Нужно тестить, но да, это бы нам сильно помогло.
сrypto.subtle, где есть метод digest появился недавно, кажется этим летом. В Fx он до сих «This is an experimental API that should not be used in production code.»
Ну и главная проблема с чексуммами была в старых браузерах, а не в новых. Поэтому и реализовали это на JS быстрым Флетчером.
Ну и главная проблема с чексуммами была в старых браузерах, а не в новых. Поэтому и реализовали это на JS быстрым Флетчером.
Зачем вы сменили адреса для почты для домена?
Было mail.yandex.ru/for/мой домен/neo2/ теперь mail.yandex.ua/neo2/
У меня есть почта для двух адресов, и теперь при переключении между ними надо каждый раз логиниться…
Было mail.yandex.ru/for/мой домен/neo2/ теперь mail.yandex.ua/neo2/
У меня есть почта для двух адресов, и теперь при переключении между ними надо каждый раз логиниться…
UFO just landed and posted this here
Хмм… неплохо
кстати, не в курсе,
это
нормально, или ко мне adware прокралось? :)
Нормально, вы попали в эксперимент.
Ну вот тогда вам сразу фидбек, показывайте как-то что это ваше, а не от вируса рекламного или еще откуда-то, ну переход какой-то визуальный сделайте, например. В текущем виде немного нервирует :) (был разок adware, выглядел один-в-один так же(внезапно появляющийся с какой-то стороны рекламный блок))
Уже давно: blog.yandex.ru/post/83889/
UFO just landed and posted this here
Как часто (и по каким причинам) были ошибки чексуммы? Ведь версия файла известна, патч получен (если он пришёл битый, то всё очень плохо и даже чексумма не поможет), процесс наложения патча не такой сложный (ну то есть если работает, то работает)… Или проблема в не отловленных багах?
Да, проблема именно в багах. Кто-то ошибся, под видом одной версии загрузили другую, например, и все такое. В итоге, это становится сильной головной болью тестировщиков.
А что если перед заливкой автоматически проводить эту проверку один раз, вместо того, чтобы на каждом клиенте её проводить? От такого рода ошибок должно помочь.
Нет, от такого рода ошибок как раз не поможет.
Я говорю про такие случаи:
по ошибке разработчика под видом version=1 записалась статика от version=2. Выходит version=3 и мы накладываем патч 2 -> 3, он, естественно, накладывается неправильно
Я говорю про такие случаи:
по ошибке разработчика под видом version=1 записалась статика от version=2. Выходит version=3 и мы накладываем патч 2 -> 3, он, естественно, накладывается неправильно
То есть клиенту под видом версии 1 попала версия 2 и он накатывает патч 2->3?
То есть как если бы кто-то залил новую версию, не обновив номер версии? Этого можно избежать, используя автоматическое назначение версии вместо задания вручную.
То есть как если бы кто-то залил новую версию, не обновив номер версии? Этого можно избежать, используя автоматическое назначение версии вместо задания вручную.
Все ошибки, конечно, можно избежать. :)
Главный вопрос ведь в другом — «стоит ли игра свечь». У нас оказалось, что не стоит. Держать сложную логику ради небольшой оптимизации просто неэффективно.
Главный вопрос ведь в другом — «стоит ли игра свечь». У нас оказалось, что не стоит. Держать сложную логику ради небольшой оптимизации просто неэффективно.
Почему, всё-таки, не SDCH? Есть нативная поддержка в Хроме и форках, включая Яндекс.Браузер, скоро будет поддержка в Safari, активно поддерживается гуглом в своих сервисах; т.е. вам не придётся сражаться с производительностью cliend-side, целостностью, хешами и прочим — всё это уже встроено и тщательно протестировано, и от вас нужно просто сделать словарь и разложить по http сервисам. И, да, кодирование/декодирование в 400мкс — заметно меньше метрик vcdiff.
Мы, на самом деле, собираемся поэкспериментировать с SDCH. Но пока веры в его успех немного. Ведь у нас выдача очень персонализированная, т.е. у разных пользователей ответы сервера будут разными. Не очень понятно, как формировать словари. Но подробно мы этот вопрос еще не изучали.
SDCH хорошо работает на стабильных словарях. А у нас сервис с персональной выдачей. Еще есть проблема, что словарь генерируется очень долго в тех реализациях, что мы смотрели. Это нельзя делать на лету.
Технические куски html (шаблоны итп) и статики меняются не очень сильно, т.ч. словарь можно делать редко, например раз в месяц.
Мы делали прототип, у нас было все плохо
Расскажите, это интересно. У LinkedIn, например, со статикой всё получилось.
Все как я описал выше, словари долго генерились и диффы были большими. Но я не отрицаю, что мы просто могли его неправильно готовить :)
А можете про LinkedIn ссылку дать почитать?
А можете про LinkedIn ссылку дать почитать?
Словарь генерируется действительно долго (10 часов на 1200 файлов LinkedIn), но если его менять раз в месяц, это не проблема.
Исходно это доклад на Highload 2014, видео и презентация когда-нибудь будут.
Исходно это доклад на Highload 2014, видео и презентация когда-нибудь будут.
UFO just landed and posted this here
Все просто, если нет localstorage, то работает обычная загрузка
Ведь в LocalStorage теперь хранятся js-файлы. И если их кто-то подменит, будет фигово.
LocalStorage заявляется как domain-based, то есть подменить может только тот, кто с того же домена. Но тогда с таким же успехом могут подменить и без LocalStorage, или есть какая-то магия для cross-domain доступа к LocalStorage?
1. почему не кэшировать хэши?
2. почему не использовать для расчетов вебворкеры?
3. почему бы не использовать канвас? Сунули строку как imageData, сделали какую-то трансформацию, проверили. Я бы вообще на шейдерах попробовал это сделать для ie10+, если честно.
4. почему бы просто не использовать ленивую помодульную загрузку+async/defer? Условно, если открываем какое-то письмо — загружаем сначала код, связанный с письмом, остальное потом. Открываем общий интерфейс — загружаем сначала код, связанный с отображением общего списка писем
2. почему не использовать для расчетов вебворкеры?
3. почему бы не использовать канвас? Сунули строку как imageData, сделали какую-то трансформацию, проверили. Я бы вообще на шейдерах попробовал это сделать для ie10+, если честно.
4. почему бы просто не использовать ленивую помодульную загрузку+async/defer? Условно, если открываем какое-то письмо — загружаем сначала код, связанный с письмом, остальное потом. Открываем общий интерфейс — загружаем сначала код, связанный с отображением общего списка писем
На 1 и 2 я ответил выше
3. А какую проблему решит canvas?
4. У нас есть модули и ленивая загрузка
3. А какую проблему решит canvas?
4. У нас есть модули и ленивая загрузка
Еще пять копеек: судя по размеру диффов, вы вполне можете их докидывать в конец HTML для клиента (зная, например, последнее время захода).
Значительные проблемы при выявлении целостности применения изменений, тут вы молодцы, что отказались. CSS селектор может посередине «порваться», а вы этого не узнаете…
Я бы делал так: накидывал бы патчи для клиентов по времени последнего захода (подразумевая, если в localStorage что-то лежит). И быструю проверку можно просто по длине делать (или по значению какого-то селектора или JS-переменной). А потом бы по onload потихоньку сверял бы checksum от всего файла с заданным. Чтобы наверняка. Или даже прогрузить полную версию в localStorage, чтобы бы без патча.
Задача очень похожа на оптимизацию изображений: «на лету» файлик в 100 Кб png оптимизировать очень тяжело. Будет проигрыш по времени: быстрее загрузить обычно неоптимизированный файл, чем его оптимизировать «на лету» и только потом отдавать.
Но в отложенном режиме в несколько потоков все отлично оптимизируется. Для последующих использований.
Соответственно, вопрос: что мешает полностью обновленную версию файлов загружать по onload (если там минорные изменения)? Канал у всех достаточно быстрый, экономия получится на спичках, а целостность данных — на порядок выше.
Значительные проблемы при выявлении целостности применения изменений, тут вы молодцы, что отказались. CSS селектор может посередине «порваться», а вы этого не узнаете…
Я бы делал так: накидывал бы патчи для клиентов по времени последнего захода (подразумевая, если в localStorage что-то лежит). И быструю проверку можно просто по длине делать (или по значению какого-то селектора или JS-переменной). А потом бы по onload потихоньку сверял бы checksum от всего файла с заданным. Чтобы наверняка. Или даже прогрузить полную версию в localStorage, чтобы бы без патча.
Задача очень похожа на оптимизацию изображений: «на лету» файлик в 100 Кб png оптимизировать очень тяжело. Будет проигрыш по времени: быстрее загрузить обычно неоптимизированный файл, чем его оптимизировать «на лету» и только потом отдавать.
Но в отложенном режиме в несколько потоков все отлично оптимизируется. Для последующих использований.
Соответственно, вопрос: что мешает полностью обновленную версию файлов загружать по onload (если там минорные изменения)? Канал у всех достаточно быстрый, экономия получится на спичках, а целостность данных — на порядок выше.
А вы выбрали бы библиотеку от Гугла если бы она оказалась быстрее? =)
Linux 3.17.2-1-ARCH
Chromium 38.0.2125.111
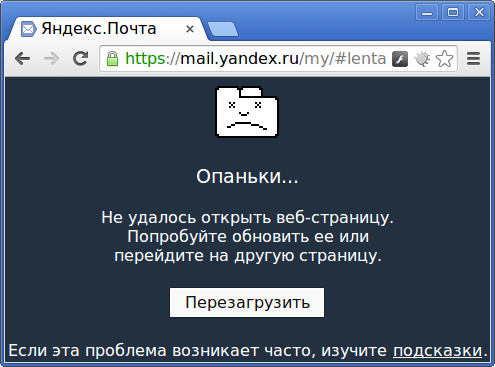
С месяц наблюдаю картину. Куда писать, чтоб поправилось?
Недавно поставил Я.Браузер. Там лучше ситуация, но иногда просто виснет на этапе загрузки ленты :(
Chromium 38.0.2125.111

С месяц наблюдаю картину. Куда писать, чтоб поправилось?
Недавно поставил Я.Браузер. Там лучше ситуация, но иногда просто виснет на этапе загрузки ленты :(
А «классические» инструменты и форматы, вроде unified diff, тут никак заюзать нельзя?
Этакий маленький git у пользователя в docstorage, который делает fetch и merge при загрузке? Или даже не, комплект патчей gilt.
Ведь тот же патч можно накатить локально, чтобы стопудово удостовериться, что получается правильный файл в итоге. А если не так — что-нибудь подшаманить (например, увеличить контекст на единичку), и попробовать снова. И уже «правильный» патч слать клиентам.
Этакий маленький git у пользователя в docstorage, который делает fetch и merge при загрузке? Или даже не, комплект патчей gilt.
Ведь тот же патч можно накатить локально, чтобы стопудово удостовериться, что получается правильный файл в итоге. А если не так — что-нибудь подшаманить (например, увеличить контекст на единичку), и попробовать снова. И уже «правильный» патч слать клиентам.
Sign up to leave a comment.
Как инкрементальные обновления влияют на скорость загрузки. Опыт Яндекс.Почты