Comments 57
Молодцы!
Задержались с бета-тестом.
1. В гугле можно тянуть картинку на форму ввода запроса и при этом автоматически открывается поле для переноса картинки. У вас для этого нужно нажимать лишнюю кнопочку с иконкой фотоаппарата.
2. Тащим например вот эту фотку portswigger.net/css/portswigger-logo.gif
с главной этого сайта portswigger.net/index.html, гугл правильно грузит фотку и находит что это, у вас же если делать по яндекс-логике, то ответ «По указанному адресу не смогли найти картинку, попробуйте ввести другой адрес.» А если сделать интуитивно — перетащить картинку на пиктограмму фотоаппарата в строке поиска — то мы переходим по ссылке < a href=«index.html» > т.е нас редиректит на главную сайта.
1. В гугле можно тянуть картинку на форму ввода запроса и при этом автоматически открывается поле для переноса картинки. У вас для этого нужно нажимать лишнюю кнопочку с иконкой фотоаппарата.
2. Тащим например вот эту фотку portswigger.net/css/portswigger-logo.gif
{kind=link}
с главной этого сайта portswigger.net/index.html, гугл правильно грузит фотку и находит что это, у вас же если делать по яндекс-логике, то ответ «По указанному адресу не смогли найти картинку, попробуйте ввести другой адрес.» А если сделать интуитивно — перетащить картинку на пиктограмму фотоаппарата в строке поиска — то мы переходим по ссылке < a href=«index.html» > т.е нас редиректит на главную сайта.
Спасибо за замечания. Сейчас дорожки протопчут, а потом мы их заасфальтируем. Посмотрим, как чаще используют, куда кликают, куда переходят — и дошлифуем интерфейс.
Бегло ознакомился cо статьей, я правильно понимаю, что идея алгоритма у вас вертится вокруг построения диаграммы Вороного по Дескрипторам ключевых точек? А как данный подход масштабируется при увеличении данных? Не смотрели при разработке в сторону моделей нейронного газа, или(буквально сегодня мной описанных на хабре) растущих нейронных сетей? Или глубокие сети(они вроде бы применяются в аналогичном сервисе от Google)?
Строго говоря наш алгоритм кластеризации не эквивалентен алгоритму построения диаграммы Вороного.
Масштабируется наше решение очень хорошо. Это как раз было одним из важнейших условий.
Для этой задачи мы нейронные сети не рассматривали. Нейронные сети — это эффективное средство для определения категорий изображений, а не для поиска копий.
Google, насколько, нам известно, тоже нейронные сети использует не для поиска копий, а для распознавания категорий (наиболее частых меток) на фотографиях в Google+. Но тут, конечно, лучше у них спрашивать.
Масштабируется наше решение очень хорошо. Это как раз было одним из важнейших условий.
Для этой задачи мы нейронные сети не рассматривали. Нейронные сети — это эффективное средство для определения категорий изображений, а не для поиска копий.
Google, насколько, нам известно, тоже нейронные сети использует не для поиска копий, а для распознавания категорий (наиболее частых меток) на фотографиях в Google+. Но тут, конечно, лучше у них спрашивать.
Вы же решаете задачу кластеризации при поиске копий? Модели нейронного газа и растущих нейронных сетей как раз для этого и разработаны.
А про способы масштабирования можно поподробней? Это ведь самая интересная часть вашей системы.
А про способы масштабирования можно поподробней? Это ведь самая интересная часть вашей системы.
Вы же решаете задачу кластеризации при поиске копий? Модели нейронного газа и растущих нейронных сетей как раз для этого и разработаны.
Решаем, да. Но так сложилось, что сейчас мы это делаем без использования сетей.
А про способы масштабирования можно поподробней? Это ведь самая интересная часть вашей системы.
В основном масштабирования мы добиваемся не столько алгоритмами, сколько архитектурой. Посмотрите на схему: довольно очевидно, что компенсировать рост объемов индекса можно большим дроблением и увеличением количества базовых поисков (CBIR search на схеме).
Но если решать задачу в жестких рамках — скажем, если есть условие, что количество картинок в индексе растет, а количество «железа» нет — то можно «играть» размерами индекса, убирая наиболее частотные визуальные слова. И, кроме того, можно строже отбирать кандидатов для валидации, что несколько уменьшит полноту, но заметно увеличит скорость.
Очень хотелось бы расширение для Хрома, позволяющее запускать Яндексовский поиск по картинке прямо из контекстного меню по правому клику мыши. То есть как аналогичный функционал у расширения «Гугл — поиск по картинкам». Это чертовски удобно.
Уже кто-то постарался
Яндекс впереди планеты всей…
Могу подкинуть ещё пару идей. Как насчет поиска изображения из камеры смартфона? Голосовой поиск?
а идей и желания у нас для этого хватает
Могу подкинуть ещё пару идей. Как насчет поиска изображения из камеры смартфона? Голосовой поиск?
В принципе для поиска по загруженному изображению можно приспособить и более простой алгоритм:
habrahabr.ru/post/122372
habrahabr.ru/post/122372
Как описываемый вами алгоритм решает дилемму стабильности-пластичности? Даже если брать в качестве хэша изображения 64*64, а интенсивность в диапазоне [0...255], то всего таких хэшей будет чуть больше миллиона. И при очень больших размерах базы(а у поисковой системы база именно такой должна быть) коллизий будет значительно больше, чем при feature matching'е на той-же базе.
Ну так индексирование в моем алгоритме — это просто способ уменьшить количество сравнений. В моем случае оказалось достаточно трехмерного индекса, но ничего в принципе не мешает использовать индексы большей размерности, например, пятимерные индексы.
Трехмерные индексы — это индексы i[1], i[2], i[3](в терминологии той статьи)? Это ведь по сути некоторые частные случаи для градиентов(кстати, похожи на часть Хааровских фич для детектирования лиц). Для тех-же SIFT дескрипторов вычисляется значительно больше градиентов, и совокупность дескрипторов для изображения будет более репрезентативной «подписью» для изображения.
Вообще, если интересно, по одному из методов оценки совокупностей особых точек можно почитать в моей статье.
Вообще, если интересно, по одному из методов оценки совокупностей особых точек можно почитать в моей статье.
Такой подход не решает проблем с сильными модификациями. Самый частый случай модификации — это кроп. Но бывает разное: и элементы двигают, и текст меняют, и добавляют всякое…
Возьмем для примера логотип хабра — чего тут только не встретишь.
Возьмем для примера логотип хабра — чего тут только не встретишь.
Яндекс изобрел SURF (habrahabr.ru/post/103107/) и как водится написал об этом намного путанее и загадочнее чем оно есть на самом деле ))
Протестировал. Почему-то через раз выдает ошибку «не удалось загрузить картинку». То, что удалось загрузить, показало, что картинки почему-то находятся только в доменной.ру зоне, нет картинок из соц.сетей, нет картинок из фотобанков, кроме русского pressfoto. Надеюсь, в скором будущем все это тоже будет работать.
Заранее извиняюсь за дилетантскую постановку вопросов, но очень интересно узнать:
— кэшируются ли свойства изображений (имя файла, exif и так далее);
— сохраняется ли история поиска для зарегистрированных пользователей;
— есть ли планы по интеграции с Яндекс.диском (например кнопка «отправить в Яндекс.диск»);
— планируется ли распознавание изображений (за отдельную плату скорее всего, так как слишком затратно для вас будет).
— кэшируются ли свойства изображений (имя файла, exif и так далее);
— сохраняется ли история поиска для зарегистрированных пользователей;
— есть ли планы по интеграции с Яндекс.диском (например кнопка «отправить в Яндекс.диск»);
— планируется ли распознавание изображений (за отдельную плату скорее всего, так как слишком затратно для вас будет).
кэшируются ли свойства изображений (имя файла, exif и так далее)
Свойства изображений мы не используем, поэтому и не храним. Храним мы только небольшую копию картинки. Она нужны только для того, чтоб показать ее на странице результатов. Но и она храниться временно.
сохраняется ли история поиска для зарегистрированных пользователей
Нет, мы это не предусматривали. Когда мы исследовали задачу поиска по картинке, мы не увидели такой потребности
есть ли планы по интеграции с Яндекс.диском (например кнопка «отправить в Яндекс.диск»)
Мы не планировали такую функциональность, а что вы хотите отправлять в Яндекс.Диск?
планируется ли распознавание изображений (за отдельную плату скорее всего, так как слишком затратно для вас будет)
Распознавать изображения мы, конечно, хотим. Это довольно очевидное развитие продукта. Но я не представляю, что станем брать за это деньги.
Про свойства спросил потому, что подумал как было бы хорошо если по найденному фотошопленному обрезку нашелся оригинал с исходным exif-ом. А если бы еще под это дело и API, то…… я себя остановил, больше мечтать не буду.
История полезна если вдруг навернулся жесткий диск, забыл взять флэшку где все ранее найденные оригиналы прекрасных примеров для прототипа интерфейса (случайный пример привел) в высоком разрешении.
В Яндекс.диск удобно отправлять найденный результат для дальнейшего расшаривания. Например если сейчас срочный поиск не с домашнего/личного компьютера, а нужен результат как раз сейчас и еще дома (чтобы не повторять поиск снова). Поверьте, это было бы очень удобно.
С распознаванием было бы шикарно, более лестного эпитета даже не подберу.
История полезна если вдруг навернулся жесткий диск, забыл взять флэшку где все ранее найденные оригиналы прекрасных примеров для прототипа интерфейса (случайный пример привел) в высоком разрешении.
В Яндекс.диск удобно отправлять найденный результат для дальнейшего расшаривания. Например если сейчас срочный поиск не с домашнего/личного компьютера, а нужен результат как раз сейчас и еще дома (чтобы не повторять поиск снова). Поверьте, это было бы очень удобно.
С распознаванием было бы шикарно, более лестного эпитета даже не подберу.
почему выдается
картинка не загрузилась, попробуйте загрузить другую.?
картинка не загрузилась, попробуйте загрузить другую.?
Давно ждал подобного рода фичу. Спасибо!
А чем вас не устраивали аналоги, начиная от tineye.com и заканчивая, как ни «странно», гуглом images.google.ru/?
www.tineye.com в 2008 году решил похожую задачу ( мы на тот момент не успели за ними)
Есть три сценария, при которых нужен поиск по загруженной картинке и которые нам и нужно было научиться обрабатывать.
Поиск соуса ещё.
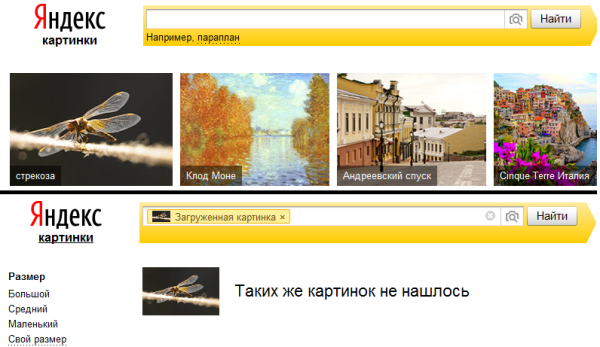
Сегодня день тестировщика, а самый первый тест — всегда банальный. Берем первую картинку со стрекозой из яндекса и ищем ее. Правильно — ничего не находит.

По сути я один из ваших конкурентов. Представляю узко тематический, семантический поиск. В последнее время приходится всё больше конкурировать с гуглом и вами, но всё же мы всё ещё на плаву.
В данный момент я про семантические имиджборды или ещё данбуру подобные имиджборды (если что мой anime-pictures.net).
Так вот, меня удивляет почему Яндекс не пытается использовать все те теги, что люди старательно прописывают к картинкам? За счёт того, что мы вручную проставляем связи (теги), мы можем гарантировать очень релевантный поиск для конкретной темы изображений, яндекс мог бы этим пользоваться ну и стараться отправлять по больше нам пользователей. Но в итоге из-за того, что на наших страницах только картинки и теги, все поисковики (не только Яндекс) нас крайне не любят, хотя мне кажется лучше было бы сотрудничать.
Кроме того такие сайты часто гораздо лучше первоисточников, так как на них авторы редко любят описывать свои творения.
К слову на наших объёмах для поиска по картинке хватает поиска по среднему цвету или по хеш функции (вот этот проект iqdb.org).
В данный момент я про семантические имиджборды или ещё данбуру подобные имиджборды (если что мой anime-pictures.net).
Так вот, меня удивляет почему Яндекс не пытается использовать все те теги, что люди старательно прописывают к картинкам? За счёт того, что мы вручную проставляем связи (теги), мы можем гарантировать очень релевантный поиск для конкретной темы изображений, яндекс мог бы этим пользоваться ну и стараться отправлять по больше нам пользователей. Но в итоге из-за того, что на наших страницах только картинки и теги, все поисковики (не только Яндекс) нас крайне не любят, хотя мне кажется лучше было бы сотрудничать.
Кроме того такие сайты часто гораздо лучше первоисточников, так как на них авторы редко любят описывать свои творения.
К слову на наших объёмах для поиска по картинке хватает поиска по среднему цвету или по хеш функции (вот этот проект iqdb.org).
Внедрите в своих тегах хотя бы простую семантическую разметку microformats.org/wiki/rel-tag-ru. Это значительно повысит шансы для машиночитаемого разбора тегов.
Это не поможет. rel-tag говорит какой тег прописать для конкретной ссылки, а у меня теги на конкретной странице с картинкой и туда можно попасть как правило через поиск по коллекции (а там где картинки списком у меня не хватит производительности, что бы генерировать теги). Да и слово «тег» у нас имеет немного другой смысл.
Кроме того у нас теги имеют тип (автор, персонаж, произведение, характеристики) и это так же не учитывается. Да и каждый тег у нас на 3 языках… :)
Кроме того у нас теги имеют тип (автор, персонаж, произведение, характеристики) и это так же не учитывается. Да и каждый тег у нас на 3 языках… :)
Естьтричетыре сценария, при которых нужен поиск по загруженной картинке и которые нам и нужно было научиться обрабатывать.
fixed
Обнаружение сайтов, нарушающих авторские права. Само собой незаконных копий картинок, но и для книг, музыки и фильмов можно искать, загрузив обложки.
Интересно узнать, планируете ли вы подключить OCR и уточнять поиск по картинке текстовым поиском по словам на картинке, а также по совпадениям имён загруженного и исходного файлов, или по совпадению имени с текстом на картинке.
Использование OCR довольно обойдется дорого с точки зрения ресурсов. OCR отрабатывает на картинке на порядок медленнее, чем получение визуальных слов. И даже если с этим смириться, то встает вопрос о целесообразности. У нас, конечно, пока статистики нет — мы только запустились. Но предположу, что среди загружаемых картинок текст будет в лучшем случае у 5%. А скорее всего еще реже.
Странно, что не находятся картинки с Викисклада (жму на сайте Wikimedia Commons «случайная страница» и делаю поиск по этому изображению). Казалось бы — общедоступный архив изображений, используемых в Википедии, должен покрывать многие «классические» объекты поиска (достопримечательности, картины, животных, растения), заодно можно было бы брать геоинформацию для достопримечательностей и подсовывать в выдачу Яндекс.Карты.
Странно. Википедию мы хорошо индексируем. А какая именно картинка не нашлась?
10 раз зашёл на страницу commons.wikimedia.org/wiki/Special:Random/File и запускаю поиск по картинке: найдено 4 из 10
Вот, например, одна из ненайденных: commons.wikimedia.org/wiki/File:Fuente_La_Noble_Habana.JPG
давно пользовался tineye, потом пришел в эту нишу гугл, сейчас и яндекс подтянулся
яндекс молодцы!
яндекс молодцы!
Возможно просьба покажется странной, но нет ли у Вас статьи «The Inverted Multi-Index» на русском языке?
Добрый день. Как при вашем методе поиска влияет водяной знак, накладываемый на изображения? Например, интернет-магазины используют оригинальное изображение от производителя и накладывают на него свой водяной знак. Насколько вероятно найти все одинаковые фотографии с разными водяными знаками на разных веб-сайтах?
Водяные знаки вообще никак не влияют. Мы находим картинки с гораздо более сильными модификациями: кропы, фотожабы, коллажи… Иногда даже удается найти совсем другое изображение того же самого объекта.
Использую похожий метод. Вычисляются дескрипторы (SURF) и сопоставляются по базе. Водяной знак нисколько не влияет на результат, больше того при поиске объекта (немного другая задача) даже непрозрачное перекрытие части объекта позволит найти объект. Процент перекрытия зависит от количества оставшихся ключевых точек на видимой области. Удавалось найти даже объект на 80% площади закрытый другим
Простите, а как вы сопоставляете дескрипторы по базе? Простым перебором?
Да, перебор. До такого крутого поиска, как у ребят из Яндекса, пока далеко.
А тестировали на больших базах? По идее на достаточно больших базах должно много коллизий выплывать начать, не говоря уж о низкой скорости работы.
Да, тестировал. Коллизии на больших базах будут всегда, но их количество можно минимизировать (добавив проверки, естественно, увеличив время выполнения). Т.к. мне нужно также получить координаты найденного объекта на изображении, ищется гомография, если дескрипторы заматчились, по гомографии получаем ограничивающий 4х-угольник найденного объекта на исходном изображении, легко проверяем углы на допустимые значения (60-120 градусов для моей задачи). В стандартных примерах opencv все это есть (углы придется только самому посчитать). Проблема с временем выполнения решается подходом в статье.
Надо думать поиск по картинкам требует немалых вычислительных ресурсов. Не рассматриваете ли вы варианты аппаратного ускорения каких-либо ваших алгоритмов?
Sign up to leave a comment.
Яндекс, роботы и Сибирь — как мы сделали систему поиска по загруженному изображению