Comments 113
Ребят, уважаю вас за такие статьи. Спасибо!
Я не могу не оставить это здесь www.yaplakal.com/pics/pics_original/2/6/5/38562.jpg
Правильно я понял, что можно отрывок не только с микрофона предлагать, но и из своего файла?
Нет, такой возможности не предусматривали — на первый взгляд кажется, что это совсем не массовая потребность.
Не согласен. Например, друг перекинул рингтон, но мне интересно, откуда он. Или была запись ещё до установки вашей программы. Или человек хочет сделать данную конкретную запись, и потом только узнать, что же он записал.
В дополнение к предыдущему комментатору: или нет доступа в интернет на данный момент, поэтому записал на диктофон смартфона.
Насчёт Я.Музыки не знаю, а конкуренты позволяют отложить распознавание до того времени, когда интернет появится. Именно поэтому не стал включать этот пункт.
в тех же шазамах, трейайди, саундхаундах клиент может записать в оффлайне и при появлении интернета надо нажать что то типа «отправить сохраненный трек»
Воспроизвести запись через другое устройство и поднести телефон с Яндекс.Музыкой?
Интересно насколько востребована эта фича? кто-нибудь оценивал?
Количество инсталляций Shazam, TrackId, SoundHound и иже.
tunatic, audiotag
Music Brainz Pickard ( musicbrainz.org/doc/Fingerprinting )
Пока мы не очень её продвигали, ей попробовали воспользоваться порядка 20% пользователей мобильного приложения Яндекс.Музыка.
Со временем планируем сделать её более заметной — это тоже должно повлиять на популярность этой функции.
Со временем планируем сделать её более заметной — это тоже должно повлиять на популярность этой функции.
Большое спасибо за описание метода, пытался решать подобную проблему через сравнение спектограмм, успеха не достиг.
Отдельное спасибо за список литратуры!
Отдельное спасибо за список литратуры!
Мы рады что вам понравилось :-)
Небольшая просьба немного не по теме — было бы здорово, если бы в Яндекс.Музыку вернулись те треки, соглашение на использование которых у вас истекло. У меня уже год половина плейлиста недоступна :(
Конечно, можно скачать их с торрентиков и залить в яндекс.диск, но это как-то не совсем хорошо :)
Желаю вам дорасти и перерасти iTunes! :)
Конечно, можно скачать их с торрентиков и залить в яндекс.диск, но это как-то не совсем хорошо :)
Желаю вам дорасти и перерасти iTunes! :)
UFO just landed and posted this here
Просьба действительно совсем не по теме статьи — но в порядке исключения отвечу, цитирую коллегу:
Мы делаем все возможное, чтобы наша база пополнялась новым и актуальным контентом. К сожалению, не все правообладатели готовы сотрудничать с нами, и на некоторые песни нам не удается получить лицензию. В других случаях, правообладателя бывает трудно отыскать, чтобы заключить с ним договор. Чаще всего контент появляется и пропадает на сервисе в том случае, если у рекорд компании, которая лицензировала нам песни, заканчивается срок действия договора с артистом, а новый договор между ними не подписывается. В этом случае контент может появиться в каталоге другой рекорд компании, и тогда контент остается на сервисе или очень быстро снова становится доступен. Или же артист может решить оставить все права у себя, и для получения контента нам потребуется идти договариваться к артисту напрямую, что не всегда удается сделать.
Очень интересно. Спасибо, что поделились.
У меня только один вопрос есть: нет ли у вас статистики релевантности по стилям музыки? Ведь многие жанры (ambient, noize, shoegazing и др.) практически полностью состоят из различного рода шумов. Интересно бы было посмотреть, процент релевантных запросов по таким жанрам.
У меня только один вопрос есть: нет ли у вас статистики релевантности по стилям музыки? Ведь многие жанры (ambient, noize, shoegazing и др.) практически полностью состоят из различного рода шумов. Интересно бы было посмотреть, процент релевантных запросов по таким жанрам.
Во-вторых, мы собрали подборку музыкальных треков, выложенных в интернете.
Вот именно этот ход делает ваше решение лучше конкурентов, которые получают образцы только от звукозаписывающих компаний, так как, теоретически, можно найти не только то, что было выпущено в продажу, но и то, что люди делали на некоммерческой основе и выкладывали в сеть.
Если же к базе треков вы присоедините, например, вконтакте или soundcloud-подобные вещи, то будет вообще здорово!
*мечтательно вздыхаю* а было бы такое у Last.fm…
а когда вы перестанете игнорировать windows phone?
Кому он нужен?
Приложение под платформу Windows Phone уже находится в разработке, следите за анонсами.
Сегодня, кстати, появился Диск для WP. Не игнорируем :)
www.windowsphone.com/ru-ru/store/app/%D0%B4%D0%B8%D1%81%D0%BA/dde791fc-a577-49b0-8e64-6d7d653592f5
www.windowsphone.com/ru-ru/store/app/%D0%B4%D0%B8%D1%81%D0%BA/dde791fc-a577-49b0-8e64-6d7d653592f5
Всегда было интересно узнать, как работает! :)
А разве это не запатентовано?
Один программист написал нечто похожее на Java и опубликовал:
www.redcode.nl/blog/2010/06/creating-shazam-in-java/
На что получил гневное письмо из Shazam с требованием удалить всё, т.к. оно нарушает их патент.
Один программист написал нечто похожее на Java и опубликовал:
www.redcode.nl/blog/2010/06/creating-shazam-in-java/
На что получил гневное письмо из Shazam с требованием удалить всё, т.к. оно нарушает их патент.
A Яндексу есть дело до американских патентов?
Хотя и купить могут конечно…
Хотя и купить могут конечно…
На их зарубежные патенты в эрэфии можно класть болт с таёжным прибором.
Спасибо, мы отдельно исследовали этот вопрос. На наши рынки патент Shazam не распространяется.
Странно, здесь — musicbrainz.org/doc/Fingerprinting — перечислены опенсорсные реализации муз. фингерпринтинга.
Спасибо, очень интересно, давно думал, как же реализованы подобные сервисы.
Остался вопрос — как решается проблема с несколькими похожими треками (например, живая версия, исполненная очень близко к студийной) — ведь в изначальной постановке задачи требуется вернуть только один ответ.
Остался вопрос — как решается проблема с несколькими похожими треками (например, живая версия, исполненная очень близко к студийной) — ведь в изначальной постановке задачи требуется вернуть только один ответ.
По нашему опыту, с точки зрения алгоритмов распознавания живое исполнение всегда отличается от студийного.
А если речь идёт о нескольких студийных записях, которые совсем неотличимы — то какая разница, какой из нескольких идентичных треков мы отдадим пользователю? :-)
А если речь идёт о нескольких студийных записях, которые совсем неотличимы — то какая разница, какой из нескольких идентичных треков мы отдадим пользователю? :-)
вот бы открытый и бесплатный API для этого :)
Я могу ошибаться, но вроде в первых версиях Яндекс.Музыки (для iOS) вы использовали SoundHound? В последней версии уже никакого упоминания об этом нет. Чем вас не устроил этот сервис и вы решили сделать всё своё?
Да, действительно раньше использовали технологии SoundHound — и совсем недавно перешли на собственное решение в мобильном приложении Яндекс.Музыка (и на iOS, и на Android). Причин перехода несколько:
1) нам удобнее самим контролировать качество продукта и развивать его в тех направлениях, которые важны для наших пользователей
2) так появляется больше возможности применять наши наработки к смежным областям (классификация жанров, склейка дублей и т.п.)
1) нам удобнее самим контролировать качество продукта и развивать его в тех направлениях, которые важны для наших пользователей
2) так появляется больше возможности применять наши наработки к смежным областям (классификация жанров, склейка дублей и т.п.)
А планируете ли добавить возможность распознавать музыку с микрофона в music.yandex.ru/? Что бы с компьютера можно было распознавать с микрофона, без приложений для телефона. Очень нужно)
только мы с друзьями сделали прототип и отправили его в startfellows на грант, как тут и яндекс музыка подоспела =)
Просто здорово, потихоньку начинаю переезжать с гугла на яндекс. Только не теряйте темпа :-)
А классические произведения типа Гайдн, Моцарт оно не знает? Тестировал на sky.fm, канал Israeli Hits конечно наивно было надеяться, канал Mostly Classical не распознало ни разу, рэп и рок узнает с первого раза, кантри через раз.
Кроме того через раз очень долго крутится «анализ» потом сообщает об ошибке загрузки, хотя соединение wi-fi.
Платформа iphone 4s.
Кроме того через раз очень долго крутится «анализ» потом сообщает об ошибке загрузки, хотя соединение wi-fi.
Платформа iphone 4s.
Про первую часть: а можете назвать конкретные треки, которые не удалось распознать? (в идеале — сразу ссылками на треки на Яндекс.Музыке, так будет чуть проще разбираться)
Конечно тех треков уж не припомню, попробовал на sky.fm снова, из классики ничего не распознает, вот примеры треков:
Francesco Geminiani — Concerto Grosso in D Major, Op. 3, No. 1, mvmt. IV. Allegro (Jaroslav Krecek, Capella Istropolitana)
Vivaldi — Concerto for Flute, Strings and Basso Continuo in F Major No. 5, Op. 10, RV 434, mvmt. III. Allegro
Bach — Keyboard Concerto No. 7 in G Minor, BWV 1058, mvmt. I. (Without Indication) (Trevor Pinnock, English Concert)
На Я.Музыке довольно много вариантов BWV 1058, но конкретно при поиске данного исполнения яндекс отсылает на youtube www.youtube.com/watch?v=OibctIudG2k
Из Israeli Hits вот пример:
Yoram Gaon — nigun atik
На Я. Музыке точно такого трека не находит, но при поиске поиске по названию Я.Музыка выдает ссылки на youtube www.youtube.com/watch?v=H7FraPrWlyM
Конечно если включить любой трек непосредственно с яндекс музыки он распознается без проблем.
Francesco Geminiani — Concerto Grosso in D Major, Op. 3, No. 1, mvmt. IV. Allegro (Jaroslav Krecek, Capella Istropolitana)
Vivaldi — Concerto for Flute, Strings and Basso Continuo in F Major No. 5, Op. 10, RV 434, mvmt. III. Allegro
Bach — Keyboard Concerto No. 7 in G Minor, BWV 1058, mvmt. I. (Without Indication) (Trevor Pinnock, English Concert)
На Я.Музыке довольно много вариантов BWV 1058, но конкретно при поиске данного исполнения яндекс отсылает на youtube www.youtube.com/watch?v=OibctIudG2k
Из Israeli Hits вот пример:
Yoram Gaon — nigun atik
На Я. Музыке точно такого трека не находит, но при поиске поиске по названию Я.Музыка выдает ссылки на youtube www.youtube.com/watch?v=H7FraPrWlyM
Конечно если включить любой трек непосредственно с яндекс музыки он распознается без проблем.
Спасибо за примеры.
С классикой — похоже, ключевая причина в том, что даже несколько записей одного и того же произведения, исполненные одним и тем же коллективом — это разные записи. Даже небольшие изменения темпа, тембра — оказываются критичными. Такая проблема гораздо реже случается для популярной музыки, там исполнитель гораздо реже варьируется, да и для одного исполнителя гораздо реже случаются повторные записи одного произведения.
С классикой — похоже, ключевая причина в том, что даже несколько записей одного и того же произведения, исполненные одним и тем же коллективом — это разные записи. Даже небольшие изменения темпа, тембра — оказываются критичными. Такая проблема гораздо реже случается для популярной музыки, там исполнитель гораздо реже варьируется, да и для одного исполнителя гораздо реже случаются повторные записи одного произведения.
По второй проблеме — скиньте мне пожалуйста ваш email-адрес в личку. Я передал вашу проблему коллегам в поддержку полоьзователей, они свяжутся с уточнениями.
Я раньше думал, что это как раз делается с помощью взаимно корреляционной функции. Правда затраты были бы сумасшедшие
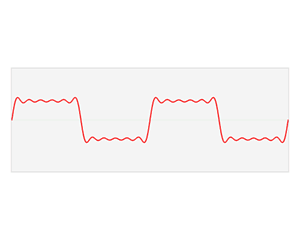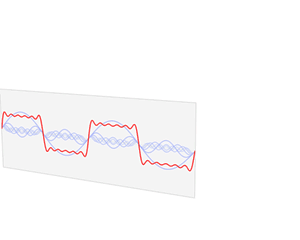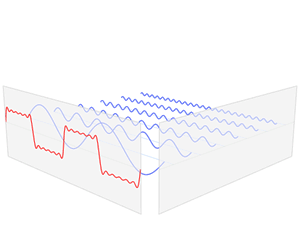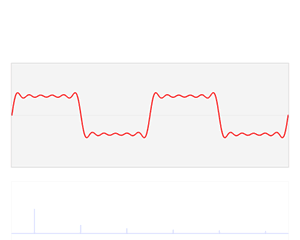
«И мы подобрали такую их [пиков] комбинацию, при которой остаётся минимальное число пиков, но почти все они устойчивы к искажениям.»
А вы не пробовали «воспроизводить» (делать обратное преобразование) эти самые найденные пики, очистив их от остальных данных на диаграмме «частота-время»? Интересно, что будет слышно.
Расскажите пожалуйста по-подробнее, как вы конвертируете амплитуду\время в амплитуду\частоту.
В этой статье читал www.redcode.nl/blog/2010/06/creating-shazam-in-java/?, что используется быстрое преобразование Фурье, но въехать, как этот алгоритм работает пока не получилось. Если-бы Вы смогли объяснить человекопонятным языком, было-бы совсем супер
В этой статье читал www.redcode.nl/blog/2010/06/creating-shazam-in-java/?, что используется быстрое преобразование Фурье, но въехать, как этот алгоритм работает пока не получилось. Если-бы Вы смогли объяснить человекопонятным языком, было-бы совсем супер
Если совсем на пальцах:
= любую периодическую функцию можно приблизить рядом Фурье
= музыкальную запись можно разрезать на множество временных интервалов, и на каждом интервале приближать её своим рядом Фурье — тогда длину этого интервала можно считать периодом (и тогда слово «периодической» в предыдущем пункте уже не важно)
= быстрое преобразование Фурье — просто вычислительно недорогой алгоритм получения первых N коэффициентов для такого разложения
Вы об этом спрашивали?
= любую периодическую функцию можно приблизить рядом Фурье
= музыкальную запись можно разрезать на множество временных интервалов, и на каждом интервале приближать её своим рядом Фурье — тогда длину этого интервала можно считать периодом (и тогда слово «периодической» в предыдущем пункте уже не важно)
= быстрое преобразование Фурье — просто вычислительно недорогой алгоритм получения первых N коэффициентов для такого разложения
Вы об этом спрашивали?
{kind=link}
Гений программист, создатель известной программы goldwave в 2008 году на форуме мне ответил ссылкой на этот алгоритм.
en.wikipedia.org/wiki/Autocorrelation
en.wikipedia.org/wiki/Autocorrelation
Новая забава — покричать/пропеть что-нибудь в смартфон и посмотреть что выдаст яндекс.
Всегда было любопытно — а нельзя ли эту задачу решать комбинацией двух алгоритмов. Сначала применить набор из N вейвлет для каждого фрагмента трека, где N это достаточно большое число. Под вейвлетами я подразумеваю не совсем классическое определение, а просто коротенькие фрагменты звука. Они могут быть от нескольких миллисекунд до секунд, могут представлять собой нарезку инструментов, могут быть нарезкой постоянной частоты, а могут классические, такие как Хаар, Шляпа, Гаусс. Эта операция спозиционирует фрагмент в N-мерное пространство. При этом устойчивость к шумам и инвариантность должна быть значительно выше классического Фурье-спектра: спектральный шум не сильно влияет на вейвлет, а за счёт большой базы сэмплов даже пара полностью выпадших вейвлетов не будет критична.
Ну а потом произвести поиск ближайшего вектора в N-мерном пространстве. Там есть много хороших и быстрых алгоритмов. Тот же SVM наверняка можно приспособить.
Просто аналогичные способы периодически использую в распознавании объектов на изображениях. Возможно есть какая-то их применимость и к аудиопотоку.
Ну а потом произвести поиск ближайшего вектора в N-мерном пространстве. Там есть много хороших и быстрых алгоритмов. Тот же SVM наверняка можно приспособить.
Просто аналогичные способы периодически использую в распознавании объектов на изображениях. Возможно есть какая-то их применимость и к аудиопотоку.
Мы недаром привели в списке литературы статью, подробно разбирающую применение вейвлетов для этого класса задач :-)
Shumeet Baluja, Michele Covell: «Audio Fingerprinting: Combining Computer Vision & Data Stream Processing»
Наверняка вам будет любопытно прочесть, если ещё не успели.
Shumeet Baluja, Michele Covell: «Audio Fingerprinting: Combining Computer Vision & Data Stream Processing»
Наверняка вам будет любопытно прочесть, если ещё не успели.
Проморгал, спасибо:)
Статья интересная, хотя, конечно, подход не тот что я выше описал, а с другой стороны. Всё же я предлагал использовать больше вайвлетов и применять их вместо построения спектрограммы, напрямую к сигналу. Любопытно, что одни и те же методы машинного зрения приводят к разной версии алгоритма.
Да, ещё сегодня вспомнилось, возможно вам будет любопытно. Когда вы ищите похожую на сэмпл картину пиков в базе то это очень похоже на две классические задачи для которых придумано огромное количество методов. Первая — привязка снимка к звёздному небу. Вторая — сравнение отпечатков пальцев. Может быть пригодится.
Статья интересная, хотя, конечно, подход не тот что я выше описал, а с другой стороны. Всё же я предлагал использовать больше вайвлетов и применять их вместо построения спектрограммы, напрямую к сигналу. Любопытно, что одни и те же методы машинного зрения приводят к разной версии алгоритма.
Да, ещё сегодня вспомнилось, возможно вам будет любопытно. Когда вы ищите похожую на сэмпл картину пиков в базе то это очень похоже на две классические задачи для которых придумано огромное количество методов. Первая — привязка снимка к звёздному небу. Вторая — сравнение отпечатков пальцев. Может быть пригодится.
Хмм, выглядит прикольно, сидя в клубе или ресторане, нажать кнопку и узнать что играет, НО…
Ребята, вы в реальной жизни это проверяли?
ИМХО хорошо работать это будет лишь при условии отсутствия какой-либо динамической обработки, транспозиции, реверберации, что уже совсем не так интересно.
Кроме того специфические, особенности «прогрессивной» электронной музыки, говнорока и попсы наложат таки свой отпечаток :-)
Да-да, три простых и правильных аккорда, Yamaha PSR — мама российской (и не только) эстрады, да и современные библиотечные грувы, и синтаки кочующие из аранжировки в аранжировку…
Ребята, вы в реальной жизни это проверяли?
ИМХО хорошо работать это будет лишь при условии отсутствия какой-либо динамической обработки, транспозиции, реверберации, что уже совсем не так интересно.
Кроме того специфические, особенности «прогрессивной» электронной музыки, говнорока и попсы наложат таки свой отпечаток :-)
Да-да, три простых и правильных аккорда, Yamaha PSR — мама российской (и не только) эстрады, да и современные библиотечные грувы, и синтаки кочующие из аранжировки в аранжировку…
Если это вопрос, можете его переформулировать? Пока мы не очень поняли, о чём в точности вы спрашиваете.
Ребята, вы в реальной жизни это проверяли?
За крайне редким исключением пользуюсь распознаванием музыки в шумных местах (кафе, бары, улица). Не Яндексом, но soundhound. Распознавание работает в 90% случаев.
Пока Гугл чистится от продуктов, размывающих фокус и яростно разрабатывает самоуправляемые машины и google glass, Яндекс запускает конкурента Шазаму и Саундханду.
Ребята, без обид, но может быть примените свои без сомнения талантливые ресурсы на что-то более инновационное, а не на копирование (как бы это ни было увлекательно)? :)
Ребята, без обид, но может быть примените свои без сомнения талантливые ресурсы на что-то более инновационное, а не на копирование (как бы это ни было увлекательно)? :)
Мне кажется Яндекс никогда не был про инновации, он про продукты для пользователей (уже существующих). Это заявлялось неоднократно на многих конференциях и в том числе подкрепляется тем фактом, что Яндекс несравнимо мало покупает продукты/компании в отличии от зарубежных коллег. Хотя мне как гику ближе ваша позиция :)
Скорее так: при том что у Яндекса алгоритмическая, технологическая, математическая часть продуктов на самом приличном уровне («инновационном», как бы я не ненавидел этот термин:), тем не менее (1) мы почти никогда не попадаем в фокус западной технопрессы из-за культурного и языкового барьера и (2) собственно «продуктовая инновация» (когда из кусков хорошо известного «технологического старого» лепится и четко подается «продуктовое новое») — не самая сильная сторона отечественной разработческой культуры.
Но мы учимся (1) «говорить по английски» и (2) активнее лепить «продуктовое новое». Совсем-совсем новое.
(Кстати, вы почти буквально процитировали товарища Роберта Скобла: он как-то, пару лет назад, высказался, что, мол, такие компании («треш-холдинги» :) как Яндекс и Baidu не способны на инновацию в принципе :)
Но мы учимся (1) «говорить по английски» и (2) активнее лепить «продуктовое новое». Совсем-совсем новое.
(Кстати, вы почти буквально процитировали товарища Роберта Скобла: он как-то, пару лет назад, высказался, что, мол, такие компании («треш-холдинги» :) как Яндекс и Baidu не способны на инновацию в принципе :)
Илья, приятно видеть ваш комментарий, спасибо. В данном случае я имел в виду сознательно выбранную стратегию Яндекса, которая, как мне кажется, заключается в создание уже проверенных и очевидно необходимых продуктов для конкретных людей (не в вакууме, как часто делают стартапы). Это не исключает высокий уровень реализации. Просто меньше риски = прогнозируемый результат. Так конечно труднее попасть в «западный фокус», но экономическую эффективность такого подхода Яндекс уже доказал.
Что касается способностей Яндекса на инновации, то кажется даже изначально критически настроенный комментатор выше в них не сомневается.
Что касается способностей Яндекса на инновации, то кажется даже изначально критически настроенный комментатор выше в них не сомневается.
Мы как раз наоборот уверены, что фокусирование на поиске — это хорошо и правильно. Ведь поиск музыки по фрагменту — это тоже вид поиска. И нам важно, чтобы его качество росло с такой скоростью, которая бы нас устраивала — поэтому планируем развивать его сами. И инновации стараемся создавать, прежде всего, на ниве поиска же. Вот недавно Острова анонсировали, например — немаленькая штука.
Спасибо, интересно. API планируется или есть какие-то проблемы с этим (коммерческие, юридические)?
Недавно ответили в соседнем треде: habrahabr.ru/company/yandex/blog/181219/#comment_6301868
Как разработчик аналогичного решения для несколько иной задачи (контроль музыкального контента радиостанций) задам пару технических вопросов:
1. Сколько вы в среднем генерируете ключей (хэшей) в секунду?
2. Правильно ли я понял, что Вы используете 2-звездные созвездия (в терминологии Шазама)?
3. Если я правильно понял и хэш у Вас 20-битный (т.е. довольно короткий), то в скольких в среднем записях из базы (вернее в какой доле записей) находится этот хэш? Также интересует максимальное значение этого параметра.
Как-то очень настораживает, что у Вас получается 80% успешного распознавания, тогда как даже бесхитростная реализация алгоритма Шазама с (с 32-битным хэшем и 2-звездными созвездиями) сразу дает более 95% успешных распознаваний. Дальше идет борьба за приближение к 99.9% и за то, чтобы сделать хэш максимально уникальным и тем самым уменьшить нагрузку на базу.
В нашем случае дополнительной проблемой было требование обрабатывать кучу каналов, распознавать композицию в реальном времени с задержкой не более 5 секунд от момента начала проигрывания и определять моменты начала и конца композиции в аудиопотоке, но у нас сейчас база на порядок меньше вашей.
1. Сколько вы в среднем генерируете ключей (хэшей) в секунду?
2. Правильно ли я понял, что Вы используете 2-звездные созвездия (в терминологии Шазама)?
3. Если я правильно понял и хэш у Вас 20-битный (т.е. довольно короткий), то в скольких в среднем записях из базы (вернее в какой доле записей) находится этот хэш? Также интересует максимальное значение этого параметра.
Как-то очень настораживает, что у Вас получается 80% успешного распознавания, тогда как даже бесхитростная реализация алгоритма Шазама с (с 32-битным хэшем и 2-звездными созвездиями) сразу дает более 95% успешных распознаваний. Дальше идет борьба за приближение к 99.9% и за то, чтобы сделать хэш максимально уникальным и тем самым уменьшить нагрузку на базу.
В нашем случае дополнительной проблемой было требование обрабатывать кучу каналов, распознавать композицию в реальном времени с задержкой не более 5 секунд от момента начала проигрывания и определять моменты начала и конца композиции в аудиопотоке, но у нас сейчас база на порядок меньше вашей.
Попробую ответить:
1. Сейчас под рукой нет точной цифры по большому числу треков; по нескольким трекам (первым попавшимся) цифра порядка 60 хешей в секунду.
2. Мы используем пары пиков. Если это и есть двузвёздные созвездия в терминологии Шазама, то ответ «да».
3. В статье есть все исходные для этой цифры: 6 млн / 2^20 ≈ 6 документов на пару. Максимального значения под рукой сейчас нет, а как оно может помочь с вашими вопросами?
Как нам кажется, разница в точности с вашим решением вызвана тремя причинами:
а) вы имеете дело с сильно более чистым сигналом — у вас нет ни посторонних шумов бара/кафе, ни акустики помещения, ни искажений АЧХ микрофона.
б) я правильно понимаю, что у вас база заведомо содержит все треки, которые играются на радио — и отсутствие трека в базе не считается результатом «не найдено»? В нашем случае считается — а наши пользователи спрашивают, вообще говоря, не только треки из нашей базы. Т.е. в наши 20% нераспознанного входят оба случая — и «треки, которых мы не знаем», и «алгоритм не смог найти» (например, из-за шумов).
в) вы сами написали, что ваша база на порядок меньше нашей. В общем случае с ростом базы точность падает (растёт вероятность «зацепить» что-то похожее, но другое)
1. Сейчас под рукой нет точной цифры по большому числу треков; по нескольким трекам (первым попавшимся) цифра порядка 60 хешей в секунду.
2. Мы используем пары пиков. Если это и есть двузвёздные созвездия в терминологии Шазама, то ответ «да».
3. В статье есть все исходные для этой цифры: 6 млн / 2^20 ≈ 6 документов на пару. Максимального значения под рукой сейчас нет, а как оно может помочь с вашими вопросами?
Как нам кажется, разница в точности с вашим решением вызвана тремя причинами:
а) вы имеете дело с сильно более чистым сигналом — у вас нет ни посторонних шумов бара/кафе, ни акустики помещения, ни искажений АЧХ микрофона.
б) я правильно понимаю, что у вас база заведомо содержит все треки, которые играются на радио — и отсутствие трека в базе не считается результатом «не найдено»? В нашем случае считается — а наши пользователи спрашивают, вообще говоря, не только треки из нашей базы. Т.е. в наши 20% нераспознанного входят оба случая — и «треки, которых мы не знаем», и «алгоритм не смог найти» (например, из-за шумов).
в) вы сами написали, что ваша база на порядок меньше нашей. В общем случае с ростом базы точность падает (растёт вероятность «зацепить» что-то похожее, но другое)
порядка 60 хешей в секунду
Это значительно меньше, чем у нас. Мы начинали с примерно 200 хэшей в секунду, потом увеличили ограничение до 600 (иначе у нас были проблемы с «нехарактерными» кусками композиций, особенно во вступлениях). Причем это именно искусственное ограничение, хэши сортируются по некоему условному «качеству» и отбирается не более заданного количества лучших. А у Вас количество хэшей ограничено жестко, или их получается так мало за счет фокуса с «подвижным ножом»? Я не вполне понял его смысл, но мне показалось, что использование такой схемы не подходит для обработки в реальном времени.
6 млн / 2^20 ≈ 6 документов на пару. Максимального значения под рукой сейчас нет, а как оно может помочь с вашими вопросами?
Ну, простое деление предполагает равномерность распределения, а по моему опыту распределение тут получается чрезвычайно неравномерным. Именно поэтому спрашивал про среднее и максимум.
я правильно понимаю, что у вас база заведомо содержит все треки, которые играются на радио — и отсутствие трека в базе не считается результатом «не найдено»?
Конечно же нет. «Начало нераспознанного участка» и «Конец нераспознанного участка» — обычные события для нашей системы. Для типичной радиостанции в среднем 30% времени вещания распознать не удается либо из-за немузыкального контента, либо из-за отсутствия композиций в базе.
Количество хешей — функция от нескольких параметров прореживания (они приведены в статье).
Опускающееся лезвие (и все остальные приёмы для выбора пиков), на первый взгляд, вполне может работать и для real-time определения — почему нет?
Про среднее число вхождения ключей — давайте тогда уточним, что называть средним. А максимальное — это же просто выброс, как он поможет? Допустим есть один (или даже несколько) ключей, которые встречаются почти во всех треках — но разве это может помочь сделать какой-либо вывод? Кажется, нет.
Опускающееся лезвие (и все остальные приёмы для выбора пиков), на первый взгляд, вполне может работать и для real-time определения — почему нет?
Про среднее число вхождения ключей — давайте тогда уточним, что называть средним. А максимальное — это же просто выброс, как он поможет? Допустим есть один (или даже несколько) ключей, которые встречаются почти во всех треках — но разве это может помочь сделать какой-либо вывод? Кажется, нет.
30% времени вещания распознать не удаетсяТогда непонятно, как это соотносится с цифрами 95..99.9% в вашем первоначальном комментарии.
давайте тогда уточним, что называть средним. А максимальное — это же просто выброс, как он поможет? Допустим есть один (или даже несколько) ключей, которые встречаются почти во всех треках
Да, правильно, сам я следил за тем, сколько процентов хэшей встречаются в заданном проценте песен и выводил эти данные в виде гистограммы — так было бы конечно информативнее. Проблема в том, что эти «выбросы» как раз очень сильно нагружают базу. Дело в том, что если некий хэш часто встречается среди композиций, то и для распознаваемых записей велика вероятность его получить. В результате относительно часто активируется значителньая часть композиций из базы.
как это соотносится с цифрами 95..99.9% в вашем первоначальном комментарии
Нашей задачей было не максимально полно распознавать то, что играется на радиостанции, а с близкой к единице вероятностью опознавать ситуацию, когда играется композиция из базы. Соответственно, при оценке качества не учитывался случай, когда не опознается композиция, отсутствующая в базе.
при оценке качества не учитывался случай, когда не опознается композиция, отсутствующая в базеНу вот и разобрались с причиной (б) в расхождении наших показателей качества — мы такие случаи учитываем как нераспознанное.
Ну т.е. Ваша оценка является оценкой качества сервиса для конечного пользователя и вообще ничего не говорит о качестве используемого алгоритма.
Да, именно совокупного качества сервиса — и считаем это правильным для наших задач. Потому что алгоритм распознавания — лишь одна его часть; вторая, полнота базы, ведь тоже практически полностью в наших руках.
Но статья все же именно про алгоритм, так что и оценивать следовало бы качество алгоритма, а не сервиса. Тем более, что он от классического Шазама (подробно описанного в первой же статье из списка) отличается только несколькими минорными модификациями.
Наша статья — гораздо больше про подход «как вообще решаются такие задачи», чем про конкретный алгоритм. И цифры в ней — прежде всего чтобы дать представление о том, какими они в такой задаче бывают, на примере нашего сервиса.
Про методику оценки качества. Согласитесь, что не совсем корректно измерять точность такого алгоритма в отрыве от конкретной базы треков и конкретного потока запросов на распознавание. Условно, если алгоритм показывает прекрасное качество на потоке совершенно незашумлённых запросов и на базе в 10 тыс треков — это ведь не значит, что качество будет таким же на 10 млн треков и на потоке очень шумных запросов?
Да, нам важно «совокупное счастье пользователя» — и для этого, согласитесь, наша метрика подходит лучше, чем изолированное качество алгоритма. Тем более, что и полнота базы в наших руках, и экстенсивное увеличение объёма базы вовсе не линейно конвертируется в рост процента успешных распознаваний — вы ведь понимаете почему.
Про методику оценки качества. Согласитесь, что не совсем корректно измерять точность такого алгоритма в отрыве от конкретной базы треков и конкретного потока запросов на распознавание. Условно, если алгоритм показывает прекрасное качество на потоке совершенно незашумлённых запросов и на базе в 10 тыс треков — это ведь не значит, что качество будет таким же на 10 млн треков и на потоке очень шумных запросов?
Да, нам важно «совокупное счастье пользователя» — и для этого, согласитесь, наша метрика подходит лучше, чем изолированное качество алгоритма. Тем более, что и полнота базы в наших руках, и экстенсивное увеличение объёма базы вовсе не линейно конвертируется в рост процента успешных распознаваний — вы ведь понимаете почему.
rm
А нет случайно такого он-лайн сервиса? Вот есть у меня аудиозапись в mp3(записанная с эфира радио много лет назад на кассету, и позднее перегнанная в mp3) — как её в интернете поискать?
Интересен вопрос, рассматривали ли вы использование аудио-дескрипторов, аналогичным тем, что имеются в стандарте MPEG-7, в качестве дополнения к распознаванию по пикам? Если да, то почему отказались?
P.S. Как я только мог прослоупочить такую интересную статью :)
P.S. Как я только мог прослоупочить такую интересную статью :)
Вопрос скорее из параллельной плоскости, однако также про поиск музыки по звуку.
Всегда интересовало, как яндекс находит песни по словесному описания?
Например запрос «у а а у песня» отсылает к clck.ru/9UQaU ( music.yandex.ru/#!/track/17213160/album/2042296 ) и угадывает.
Всегда интересовало, как яндекс находит песни по словесному описания?
Например запрос «у а а у песня» отсылает к clck.ru/9UQaU ( music.yandex.ru/#!/track/17213160/album/2042296 ) и угадывает.
Sign up to leave a comment.
Как Яндекс распознаёт музыку с микрофона