Comments 60
Крайне сомнительный совет.
Текст-картинка не проиндексируется должным образом поисковиками и статью не будут находить по ключевым словам из этой таблицы. И в поиске самого хабра по словам из таблицы статья тоже не будет попадать в выборку.
А подготовка такой картинки (сделать таблицу в другом редакторе, потом скриншотить её, затем в фотошопе уменьшать/увеличивать эту картинку по ширине с потерей качества изображения, вставлять картинку в текст с правильным обтеканием если таблица небольшая и т.п.) запросто может оказаться более геморройным делом, чем оформить таблицу в тексте с помощью html-тегов.
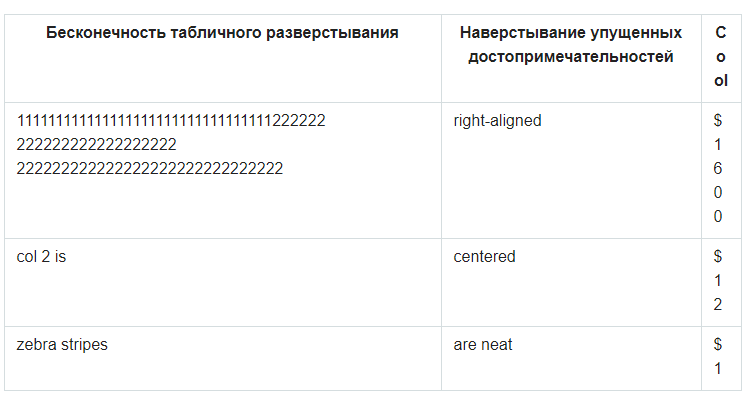
Я говорил скорее о том, что в некоторых таблицах столбцы превращаются в кашу, которую довольно сложно контролировать (а есть же еще мобильная версия сайта). Таким болеют и HTML, и markdown. Всё зависит от типа таблицы, и надо пробовать, прежде чем понять, выбрать для таблицы текст или картинку.

в некоторых таблицах столбцы превращаются в кашу, которую довольно сложно контролироватьЛегко:
<th width="100">Cool</th>.
В итоге приходится использовать обычный html.

Такое бывает, если случайно прилепить абзац текста к концу списка или неаккуратно вставить разметку кода.

Заголовок смещается правее, а остаток текста пропадает вовсе, пока не разведешь их пустой строкой.
Мне кажется, это допустимый компромисс и дело привычки — как, например, запомнить, где в маркдауне картинка ![](), а где просто ссылка [](). Ну или как перекрасить заголовок в HTML-разметке — надо только чуть наловчиться.
Когда расскажете о продуктивной совместной работе? Или за это сойдет упоминание Гуглодокс и «беру текст из второго конвертера, а картинки перезаливаю»?
Ну и вообще, редакторов — десятки, если не сотни, под все платформы и на любой вкус.
На правах личного мнения, есть неплохой редактор MarkDown — Typora.
В принципе, функционал только и состоит из редактора и более ничего, умеет импотировать (конвертировать) из различных форматов в MarkDown но делает это через PanDoc и соответственно не всё там очень хорошо :)
Ещё один лайфхак. В gitlab есть встроенная web-IDE. Она умеет работать с md. Там же можно делать ревью, там же просматривать, там же редактировать, там же история правки в понятном любому разработчику виде. При этом ещё и редактировать можно в любимом редакторе. Там же можно временно хранить картинки. Ветки git, наверное, никому в такой задаче не приводятся, но они есть.
С маркдауном у Хабра проблема в том, что он не склеивает строки. Поэтому приходится проходиться по статье, написанной в маркдаун ещё одним конвертером, который конвертит маркдаун в хабровский маркдаун.
Это каким? Специально для этой цели разработал MarkConv. Помимо склеивания, он конвертит спойлеры, адреса картинок с локальных на habrastorage, относительные ссылки (удобно для содержания) и делает другие полезные вещи.
Когда-то давно я сделал свой форк pandoc и добавил туда хабросовместимый html. Потом на хабре появился маркдаун и я стал склеивать строки вместо хабра каким-то ключиком в pandoc. Последние статьи у меня написаны в org-mode.
Но есть один нюанс — если ты работаешь над статьёй не один, а есть какой-то редактор или кто-то в этом духе, то никакого маркдауна и тем более оргмода нельзя. Надо выкладывать у гуглдоки, чтобы там все делали правки.
Но есть один нюанс — если ты работаешь над статьёй не один, а есть какой-то редактор или кто-то в этом духе, то никакого маркдауна и тем более оргмода нельзя.
Можно конечно, для чего Git с GitHub существуют? Я бы даже сказал нужно. Одно из достоинств Markdown — простые дифы. К тому же разрывы строк как раз и существуют, чтобы вместо одной огромной измененной строки размером в абзац отображалась строка размером 80-120 символов.
Всё вы правильно говорите, только редакторы не знают что такое Git и работать с ним, конечно, не умеют. Редакторы исправляют косноязычность, ошибки всякие и так дале, с их точки зрения инструмент для совместной работы над текстом это именно гуглдок. Да и, к сожалению, не только с их точки зрения, а с точки зрения вообще всех, кто не программист в широком смысле этого слова.
Достаточно было бы WISIWIG, который отображает именно так, как отобразит хабр.
Бывали периоды, когда выпускал по одной хабростатье в день. А может и по нескольку, если считать помощь в вычитке другим авторам. Когда дрожащими руками делаешь перевод статьи на тридцать страниц, пытаясь успеть к концу дня, параллельно координируясь с автором, дизайнером, корректором и остальными — возникают совершенно специфические требования к удобству. Или например, если тебе нужно сделать статью по докладу, в котором 200 слайдов, которых у нас в блоге JUG.ru Group предостаточно. Это как хороший автомобиль, один раз в день в булочную можно съездить и на Оке, а вот целыми днями жить в Оке крайне не рекомендуется :-) В общем, это сложно объяснить словами, и это надо показывать пачку скриптов, написанных за последний год. Возможно, однажды я соберу их во что-то, что смогут использовать другие люди.
Как дела с вашей IDE? :)
Предполагаю, что быстрее всего переразметить готовый HTML руками, но был бы рад ошибаться.
Я юзаю эти кривые реверсеры, и потом допиливаю руками. Не видел ещё ни одного реверсера, который работал бы хоть сколько-то осмысленно хорошо. В последний раз юзал Reverse Markdown, в принципе жить можно.
Pandoc тоже не смог?
Я пишу статью на гитхабе в собственном репозитории Articles причем в GitHub формате Markdown (да, да, он существенно отличается от хабровского). С помощью своей утилиты MarkConv перегоняю их в формат хабра. Как уже писал ранее, он склеивает строки, конвертит спойлеры, меняет адреса картинок с локальных на habrastorage, преобразует относительные ссылки (удобно для содержания) и делает другие полезные вещи.
В связи с тем, что не так давно приватные репозитории стали бесплатными, можно создать приватный репозиторий для черновиков и паблик — для финальных опубликованных топиков. Пушить и туда и туда очень просто, т.к. это Git. Как следствие, получаем механизмы Issues, Pull Request, историю изменений, возможность бекапа локально или на другие сервисы.
Кстати, тоже планирую написать статью о том как писать статьи, но используя Git и GitHub (GitLab) и внешние IDE. Правда надо доделать до конца что запланировал.
А использовать Google Docs для Markdown… Ну, если честно, не очень.
Древние подсказывают, что это делается через ABBR.
abbr title="тэг Abbr">ABBR</abbr
О величайший и мудрейший, а в какой священной книге это написано сам-то как узнал? :)
Ссылка на это чудо чудное была прямо в статье :)
https://habr.com/ru/info/topics/madskillz/
Что-то на мобиле оно никак не смотрится… Или я просто не умею интуитивный интерфейс?
Примерно — так.
На iPhone, iPad и MacBook использую Bear. Поддерживает и MD и HTML. Экспортирует так же в MD, HTML, TXT, DOCX, PDF и прочее. Моментально синхронизируется, что очень удобно, так как часто переключаюсь между девайсами.
Для предосмотра просто копирую в хабраэдитор.
Во-первых, ребята из Мейлру прокачали конвертер (пост об этом) — попробуйте его, работает отлично. Он заточен под GoogleDocs — оттуда уносятся почти все стили: заголовки h1-h3, bui, ссылки, моноширинный шрифт превращается в code или source в зависимости от условий, линии, списки, таблицы и так далее. Если кто-то из авторов прислал статью в вордовском файле, то просто импортируете в GD и при необходимости применяете стили (к заголовкам и тексту).
Во-вторых, картинки можно вставлять прямо в документ — конвертер вставит в пост на Хабре картинки со ссылками на картинки из документа, но Хабр сам их автоматически перезальёт на habrastorage. Причём на странице редактирования поста всё ещё будут google-ссылки, но в самом посте они будут с habrastorage (в чём можно убедиться через инспектор).
После такого удобного комплекта сложно пользоваться любыми другими редакторами, т.к. все они упрутся в необходимость отдельно заливать картинки на HS.
Но вообще жду, когда мои коллеги уже сделают WYSIWYG )
Пост-пост, мета-мета. Учимся писать на Хабр