Привет, меня зовут Максим, я системный администратор. Три года назад мы с коллегами начали переводить продукты на микросервисы, а в качестве платформы решили использовать Openstack, и столкнулись с некоторым количеством неочевидных граблей при автоматизации тестовых схем. Этот пост про нюансы настройки OpenStack, которые с трудом находятся на пятой странице выдачи поисковика (а лучше, чтобы легко находились на первой).
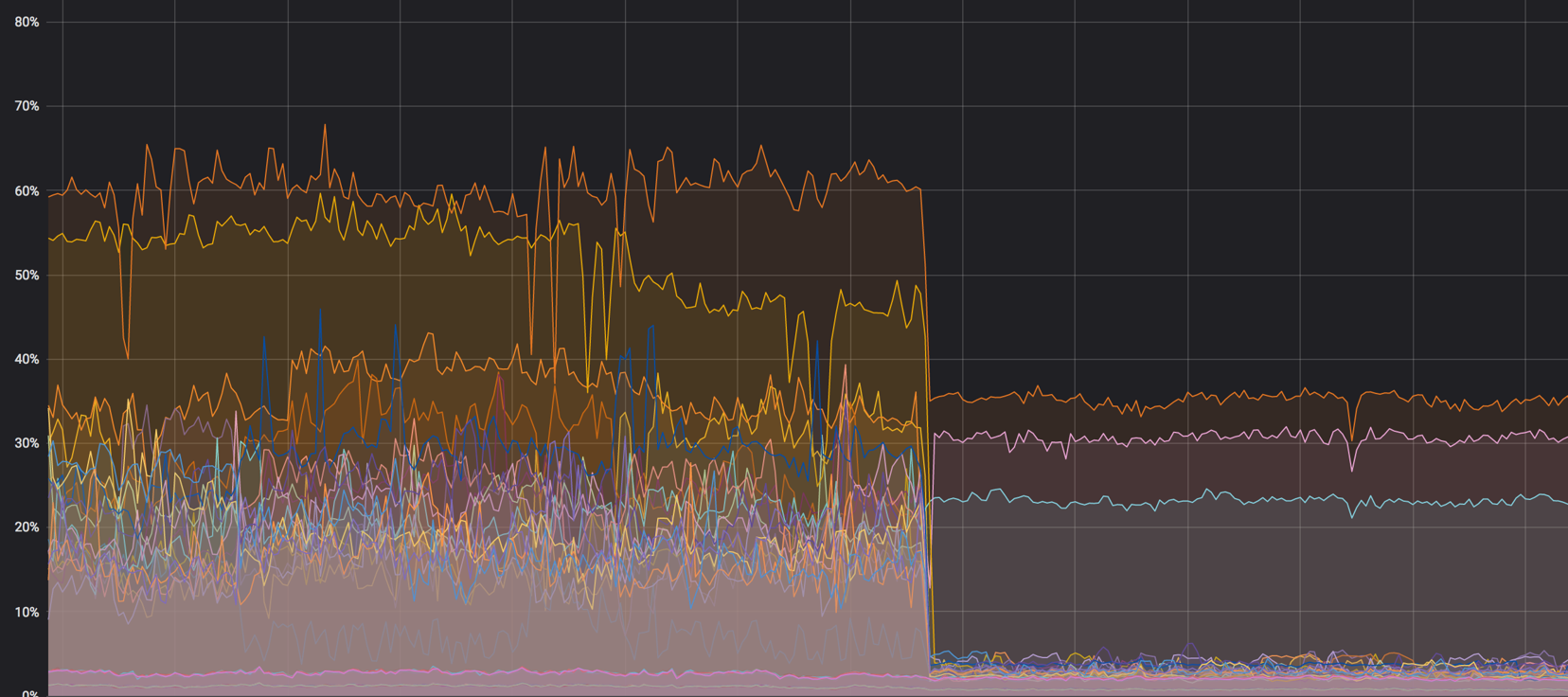
Нагрузка на ядра: было — стало
NAT
В некоторых инстансах мы используем dualstack. Это когда виртуальная машина получает сразу два адреса — IPv4 и IPv6. Сначала мы сделали так, что «плавающий» v4-адрес назначался во внутренней сети через NAT, а v6 машина получала через BGP, но с этим есть пара проблем.
NAT — дополнительный узел в сети, где и без него нужно следить за нормальным распределением нагрузки. Появление NAT в сети почти всегда ведёт к сложностям с отладкой — на хосте один IP, в базе другой, и отследить запрос становится сложно. Начинаются массовые поиски, а разгадка всё равно будет внутри OpenStack.
Ещё NAT не позволяет сделать нормальную сегментацию доступов между проектами. У всех проектов свои подсети, плавающие IP постоянно мигрируют, и с NAT управлять этим становится решительно невозможно. В некоторых инсталляциях говорят об использовании NAT 1 в 1 (внутренний адрес не отличается от внешнего), но это всё равно оставляет лишние звенья в цепочке взаимодействия с внешними сервисами. Мы пришли к мнению, что для нас лучший вариант — это BGP сеть.
Чем проще, тем лучше
Мы пробовали разные средства автоматизации, но остановились на Ansible. Это хороший инструмент, но его стандартной функциональности (даже с учетом дополнительных модулей) может не хватать в некоторых сложных ситуациях.
Например, через Ansible-модуль нельзя указать, из какой подсети нужно выделять адреса. То есть можно указать сеть, но вот конкретный пул адресов задать не получится. Здесь поможет shell-команда, которая создаёт плавающий IP:
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NETДругой пример недостающей функциональности: из-за dualstack мы не можем штатно создать роутер с двумя портами для v4 и v6. Здесь пригодится такой bash-скрипт:
#! /bin/bash
# $1 - router_name
# $2 - router_project
# $3 - router_network
# echo "${@:4}" - private subnet lists
FIXED4_SUBNET="subnet-bgp-nexthop-v4"
FIXED6_SUBNET="subnet-bgp-nexthop-v6"
openstack --os-project-name $2 router show $1
if [ $? -eq 0 ]
then
echo "router is exist"
exit 0
fi
openstack --os-project-name $2 router create --project $2 $1
for subnet in "${@:4}"; do
openstack --os-project-name $2 router add subnet $1 $subnet
done
openstack --os-project-name $2 router set $1 --external-gateway $3 --fixed-ip subnet=$FIXED4_SUBNET --fixed-ip subnet=$FIXED6_SUBNETСкрипт создает роутер, добавляет в него подсети v4 и v6 и назначает внешний шлюз.
Retry
В любой непонятной ситуации — перезапускай. Попробовать заново, создать instance, роутер или DNS-запись, потому что не всегда понимаешь быстро, в чем у тебя проблема. Retry может отсрочить деградацию сервиса, а в это время можно спокойно и без нервов решить проблему.
Все советы выше, на самом деле, прекрасно работают с Terraform, Puppet и чем угодно ещё.
Всему своё место
Любой большой сервис (OpenStack — не исключение) объединяет много сервисов поменьше, которые могут мешать работе друг друга. Вот пример.
Сетевой агент Neutron-L2-agent отвечает за сетевую связность в OpenStack. Если все остальные агенты находятся частично на контроллерах, то L2, в силу специфики, присутствует вообще везде.
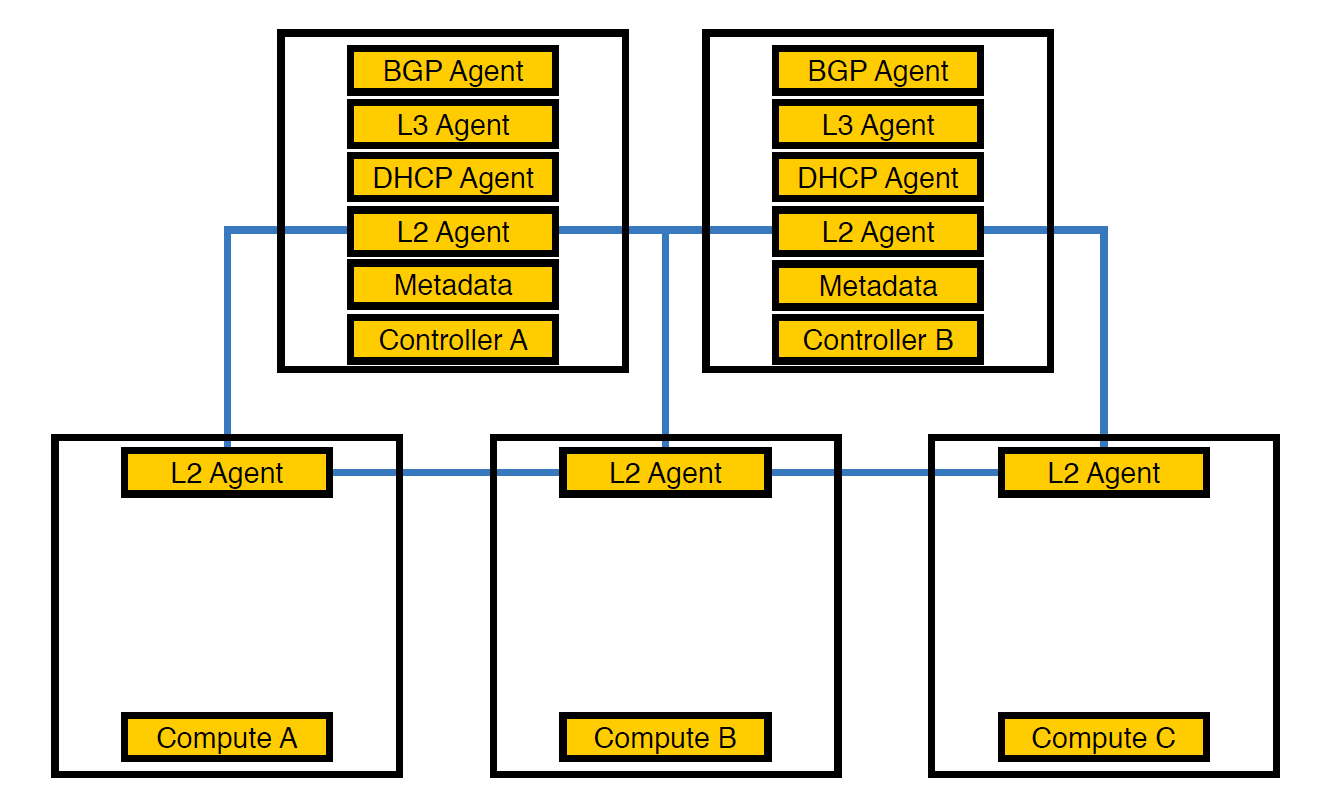
Так выглядела наша инфраструктура в самом начале, пока число схем не перевалило за 50
В этот момент мы поняли, что из-за такого расположения агентов контроллеры не справляются с нагрузкой, и перенесли агентов на compute-ноды. Они мощнее контроллеров, и к тому же контроллеру не обязательно заниматься обработкой всего — он должен выдать задание исполняющему узлу, а узел его выполнит.

Перенесли агентов на compute-ноды
Однако и этого оказалось недостаточно, потому что такое расположение плохо сказывалось на производительности виртуальных машин. При плотности в 14 виртуальных ядер на одно физическое, если один сетевой агент начинал загружать поток, это могло задеть сразу несколько виртуальных машин.
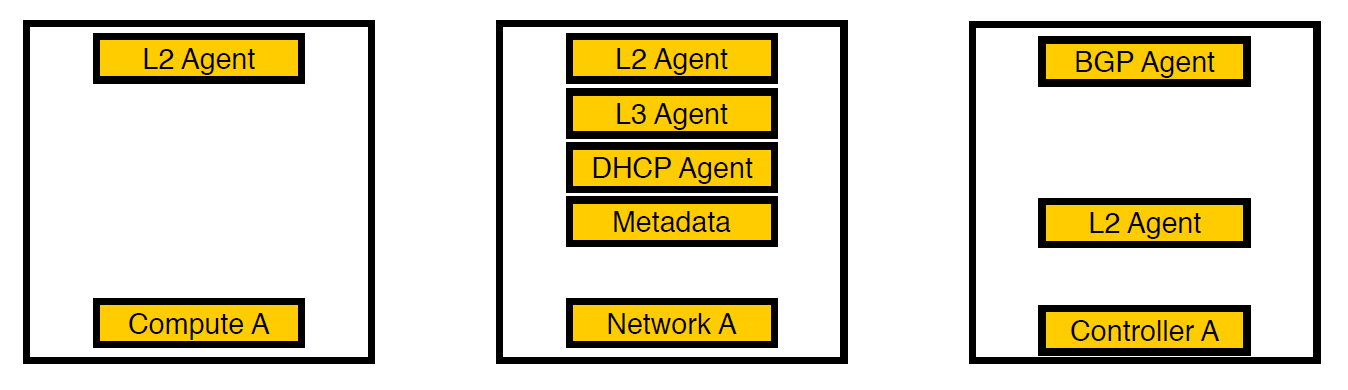
Третья итерация. Появились выделенные ноды
Мы подумали и вынесли агенты на отдельные сетевые узлы. Теперь на compute-нодах остались лишь сервисы для виртуальных машин, все агенты работают на сетевых узлах, а на контроллерах остаются только bgp-агенты, которые занимаются v6-сетью (так как один bgp-агент может обслуживать только один тип сети). L2 остался везде, потому что без него, как мы писали выше, в сети не будет связности.
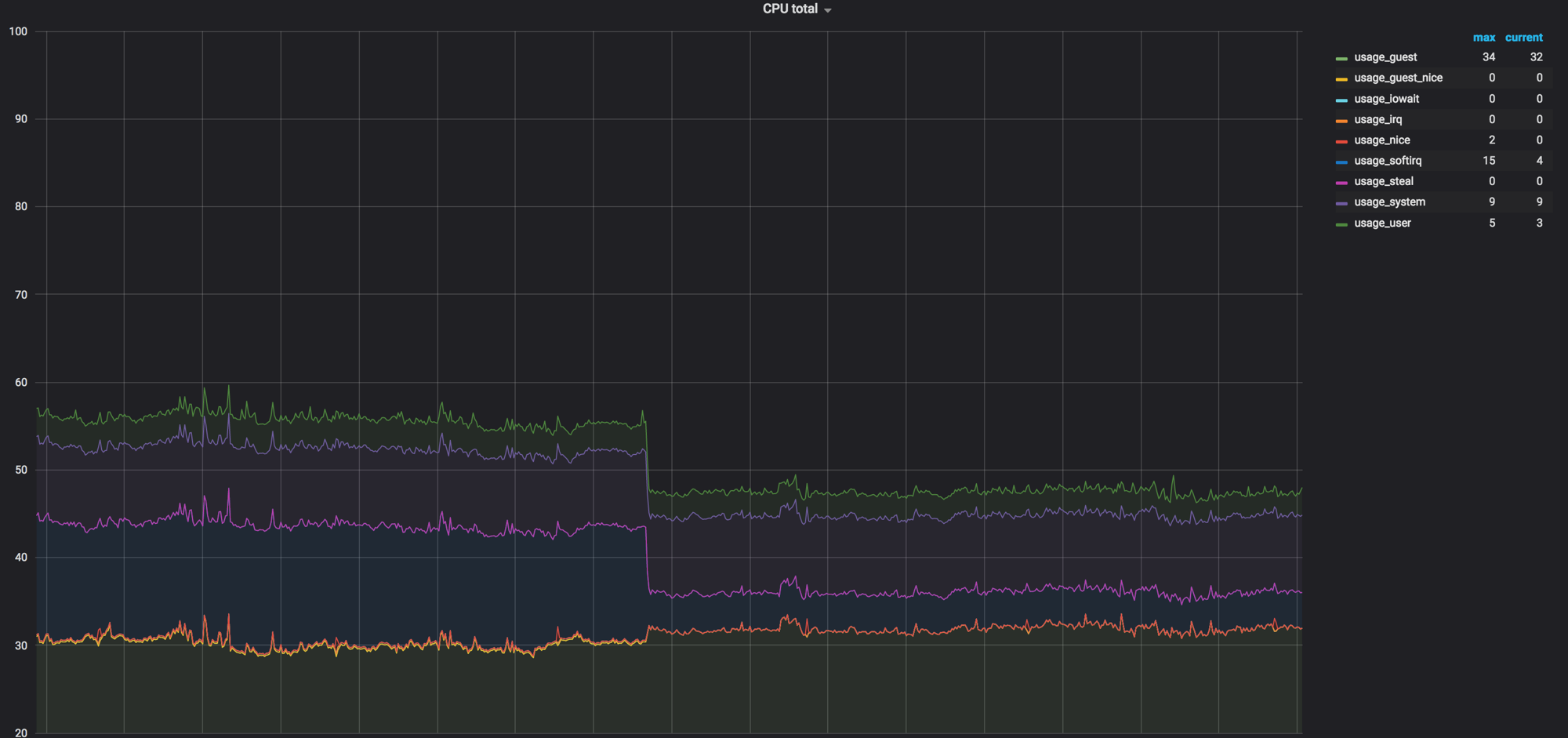
График нагрузки compute-ноды до того, как всё перемешали. Было около 60%, но нагрузка упала несущественно

Нагрузка на softirq, до того как с compute-нод убрали сетевые агенты. Остались нагружены 3 ядра. На тот момент мы посчитали, что это нормально
Code as Documentation
Иногда бывает так, что код и есть документация, особенно в таких больших сервисах, как OpenStack. С релизным циклом в полгода разработчики забывают либо просто не успевают документировать какие-то вещи, и получается так, как в примере ниже.
Про таймауты
Однажды мы увидели, что обращения Neutron к Open vSwitch не укладываются в пять секунд и падают по таймауту.
127.0.0.1:29696: no response to inactivity probe after 10 seconds,
disconnecting
neutron.agent.ovsdb.native.commands TimeoutException:
Commands [DbSetCommand(table=Port, col_values=((’tag’, 11),),
record=qtoq69a81c6-e2)] exceeded timeout 5 secondsКонечно, мы предположили, что где-то в настройках это исправляется. Посмотрели в конфиги, документацию и deb-пакет, но сначала ничего не нашли. В итоге описание нужной настройки нашлось на пятой странице поисковой выдачи — посмотрели в код ещё раз и нашли нужное место. Настройка такая:
ovs_vsctl_timeout = 30Мы выставили её на 30 секунд (было 5), и всё стало работать чуть лучше.
Вот еще неочевидное — при перезагрузке сетевых компонент некоторые настройки Open vSwitch могут сбрасываться. Так, например, происходит с ovs-vsctl inactivity_probe. Это тоже timeout, но он влияет на обращения самого ovs-vsctl к своей базе данных. Мы добавили её в systemd init, что позволило при старте запускать все свичи с нужными нам параметрами.
ovs-vsctl set Controller "br-int" inactivity_probe=30000Про настройки сетевого стека
Также пришлось немного отойти от общепринятых настроек в сетевом стеке, которые мы используем на других наших серверах.
Вот настройка того, сколько времени нужно хранить ARP-записи в таблице:
net.ipv4.neigh.default.base_reachable_time = 60
net.ipv4.neigh.default.gc_stale_time=60Значение по умолчанию — 1 день. Вообще, одна схема может жить пару недель, но за день схемы могут пересоздаваться 4-6 раз, при этом постоянно меняется соответствие MAC-адреса и IP-адреса. Чтобы мусор не копился, мы выставили время в одну минуту.
net.ipv4.conf.default.arp_notify = 1
net.nf_conntrack_max = 1000000 (default 262144)
net.netfilter.nf_conntrack_max = 1000000 (default 262144)Вдобавок мы сделали принудительную отправку ARP-нотификаций при поднятии сетевого интерфейса. Также увеличили conntrack-таблицу, потому что при использовании NAT и плавающих ip нам не хватало значения по умолчанию. Увеличили до миллиона (при дефолтном в 262 144), всё стало ещё лучше.
Правим размер MAC-таблицы самого Open vSwitch:
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048)
После всех настроек 40% нагрузки превратились практически в ноль
rx-flow-hash
Чтобы распределить обработку udp-трафика по всем очередям и потокам процессора, мы включили rx-flow-hash. На сетевых картах Intel, а именно в драйвере i40e, данная опция выключена по-умолчанию. У нас в инфраструктуре есть гипервизоры с 72 ядрами, и если занято только одно, то это не очень оптимально.
Делается это так:
ethtool -N eno50 rx-flow-hash udp4 sdfn
Важный вывод: настроить можно вообще всё. Конфигурация по умолчанию сгодится до какого-то момента (как было и у нас), но проблема с таймаутами привела к необходимости искать. И это нормально.
Правила безопасности
По требованиям службы безопасности, у всех проектов внутри компании есть персональные и глобальные правила — их довольно много. Когда мы перевалили за рубеж в 300 виртуальных машин на один гипервизор, всё это вытекло в 80 тысяч правил для iptables. Для самого iptables это не проблема, но Neutron подгружает эти правила из RabbitMQ в один поток (потому что написан на Python, а там всё грустно с многопоточностью). Происходят зависания Neutron-агента, потеря связи с RabbitMQ и цепная реакция из таймаутов, а после восстановления Neutron заново запрашивает все правила, начинает синхронизацию, и всё начинается сначала.
Вместе с этим увеличилось время создания стендов — с 20-40 минут до, в лучшем случае, часа.
Сначала мы просто обернули всё ретраями (уже на данном этапе мы поняли, что так быстро проблему не решить), а потом начали использовать FWaaS. С его помощью мы вынесли правила безопасности с compute-нод на отдельные сетевые ноды, где расположен сам роутер.

Источник — docs.openstack.org
Таким образом, внутри проекта есть полный доступ ко всему, что нужно, а для внешних соединений применяются правила безопасности. Так мы снизили нагрузку на Neutron и вернулись обратно к 20-30 минутам создания тестовой среды.
Итог
OpenStack — классная штука, в которой можно утилизировать железо, создать внутреннее облако и на его базе создать что-то другое. Вдобавок к этому есть большое комьюнити и активная группа в Telegram, где нам и подсказали по поводу таймаутов.
На этом всё. Задавайте вопросы, мы с коллегами готовы ответить и поделиться опытом.
