Comments 61
Неожиданным оказалась то, что самые плюсуемые статьи — созданные в 4 утра по Москве. Хотя, при дальнейшем размышлении, кажется что это вполне логично — опубликованное глубокой ночью (время московское) прочитывается в начале рабочего дня жителями России, начиная с Владивостока и далее по территории страны, по мере наступления рабочего дня в соответствии с часовым поясом. При этом ещё много часов подряд публикация остаётся на первых страницах — большинство авторов (которые находятся в пределах часовых поясов европейской части России) ещё спят. И даже когда в самой Москве начинается рабочий день, статья ещё в числе самых верхних на странице.
Но тогда непонятно обрушение на следующем, 5-м часу. Разница с 4-мя часами утра, по идее, должна быть не такой резкой.
Я же надеюсь, что если статьи с Хабры собирались несколькими пауками, то их IP были из одного часового пояса?
Но тогда непонятно обрушение на следующем, 5-м часу. Разница с 4-мя часами утра, по идее, должна быть не такой резкой.
Я же надеюсь, что если статьи с Хабры собирались несколькими пауками, то их IP были из одного часового пояса?
Статьи собирались только с моего отдельного локального компьютера, так что время одно.
У меня есть подозрение, что это происходит именно потому, что новых написанных статей в 4 утра очень мало. Т.е. внимание читающих распределяется неким образом между новыми статьями, и количество новых статей в это время падает сильнее, чем количество читающих.
UFO just landed and posted this here
Объём этой статьи составляет 21500 символов (код поста – 60 тысяч) – ну, математика, не подведи исследователей! :)
p.s. Очень круто, спасибо!
p.s. Очень круто, спасибо!
Ещё кажется очень подозрительным высокая плюсуемость субботне-воскресных публикаций. На самом деле, это наихудшие дни в плане рейтинга — маленькая посещаемость из-за чего мало оценок.
Картина становится яснее, если убрать главный источник ссылок — сам Хабрахабр.
Повторяется дважды, второй раз в облаках с языками.
Да не только это, весь блок с графиками оптимального времени публикации задвоен (впрочем, это легко можно не заметить :)).
Да, во второй раз там должно быть что-то вроде «Посмотрим на самые популярные языки программирования вставок кода в хабе “Алгоритмы”:»
Да, действительно, вкрался повтор фразы, поправил. Спасибо!
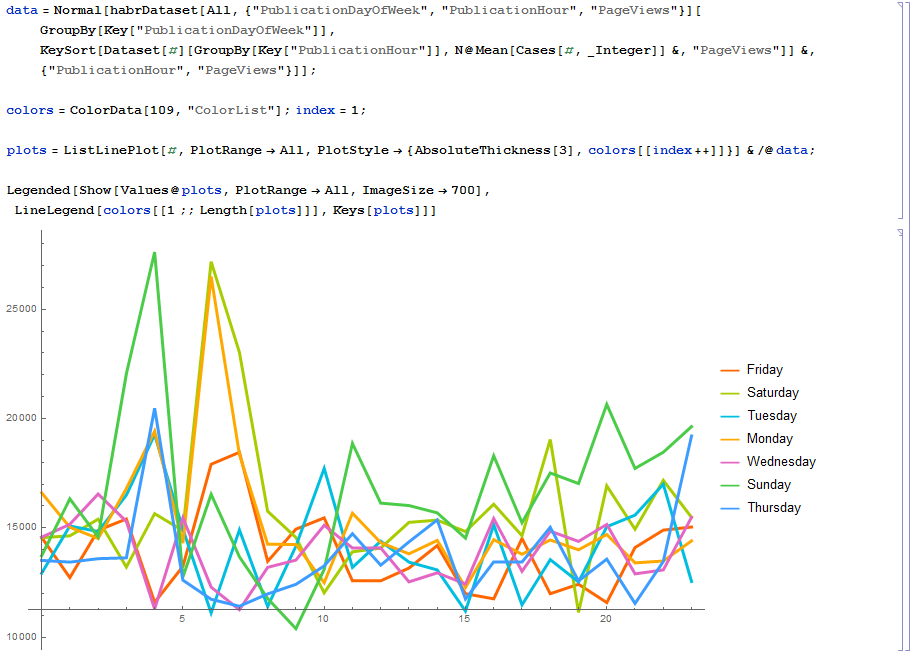
Постройте, пожалуйста, график среднего рейтинга поста в зависимости от дня недели и времени одновременно. Т.е. в начале графика понедельник с 0 до 23, затем вторник с 0 до 23 и в конце воскресенье с 0 до 23. Всего 24 * 7 точек. Спасибо.
Вот результат:

Код для копирования
data=Normal[habrDataset[All,{"PublicationDayOfWeek","PublicationHour","PageViews"}][GroupBy[Key["PublicationDayOfWeek"]],KeySort[Dataset[#][GroupBy[Key["PublicationHour"]],N@Mean[Cases[#,_Integer]]&,"PageViews"]]&,{"PublicationHour","PageViews"}]];
colors=ColorData[109,"ColorList"];index=1;
plots=ListLinePlot[#,PlotRange->All,PlotStyle->{AbsoluteThickness[3],colors[[index++]]}]&/@data;
Legended[Show[Values@plots,PlotRange->All,ImageSize->700],LineLegend[colors[[1;;Length[plots]]],Keys[plots]]]Спасибо! Очень интересны пики в 4 и 6 часов.
Моя гипотеза в том, что 4, 5, 6 часов по Москве — самое неудобное время для авторов статей, то есть до 3..4 часов ночи люди ещё могут посидеть, дописать и выложить статью, но как только время доходит до 5 часов, человек ложится спать и оставляет статью на потом.
Из-за этого в этом промежутке очень мало данных для полноценного анализа. Может быть идеальным временем публикации будет 5 часов в субботу, воскресенье или понедельник, но мы просто не имеем достаточно хороших статей, чтобы подтвердить эту гипотезу.
Моя гипотеза в том, что 4, 5, 6 часов по Москве — самое неудобное время для авторов статей, то есть до 3..4 часов ночи люди ещё могут посидеть, дописать и выложить статью, но как только время доходит до 5 часов, человек ложится спать и оставляет статью на потом.
Из-за этого в этом промежутке очень мало данных для полноценного анализа. Может быть идеальным временем публикации будет 5 часов в субботу, воскресенье или понедельник, но мы просто не имеем достаточно хороших статей, чтобы подтвердить эту гипотезу.
Ого, потрясающе фундаментальная работа! Судя по данным, технологии Wolfram наконец-то набирают популярность! Прекрасное исследование, огромное спасибо!
UFO just landed and posted this here
Было сложно но я доскролил до сюда, чтобы написать этот комментарий.
Кто такой David Virtser и почему на его сайт так много ссылок?
Когда-то давно он сделал хайлайтер кода для Хабра, который автоматом добавляет ссылку на его личный сайт. Но, к сожалению, сам хайлайтер уже давно не работает.
А почему у вас получилось, что рейтинг постов не бывает отрицательным? Не ошибка ли это извлечения рейтинга? (Имейте в виду, Хабр вместо минуса перед числом использует тире (ndash).)
Таких постов не так много. Рейтинг -1 у 669 постов, -2 у 113, -3 у 89 и -4 у 85. Меньше нет. В базе они есть.
Вы, похоже, ходили по страницам вида
Первое — это «Интересное. Записи, получившие положительную оценку (рейтинг ≥-4) пользователей», а второе — «Всё подряд. Все записи хаба (в хронологическом порядке)» (см. справку).
http://habrahabr.ru/hub/{hubname}/page{N}/, а надо было по http://habrahabr.ru/hub/{hubname}/all/page{N}/.Первое — это «Интересное. Записи, получившие положительную оценку (рейтинг ≥-4) пользователей», а второе — «Всё подряд. Все записи хаба (в хронологическом порядке)» (см. справку).
Но, вообще, вы правы. Из-за этого символа, который на первый взгляд и внутри Wolfram Language отображается как минус, я не заметил эту неточность. Сейчас поправлю все что относится к этому. Благо изменения будут всюду лишь в сотых, а на графиках их вообще заметить будет невозможно.
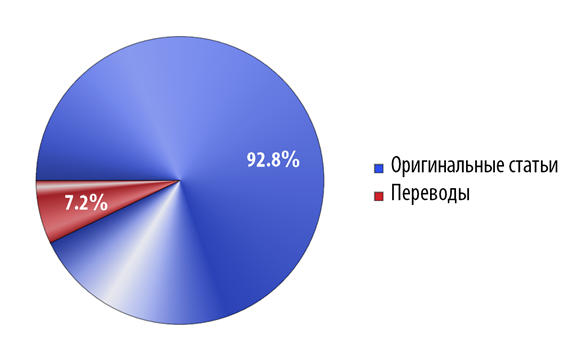
А есть ли у вас статистика по переводам (и помнится был формат топик-ссылка в прошлом)? Интересно сколько контента создано только для хабра
На данный момент нет, но вот теперь, добавил. В целом, даже не знаю, почему мне не пришла в голову мысль вставить это сразу)

Результат вычислений таков:

Код для копирования
extractData["TranslationQ"][data_]:=If[
FreeQ[data,XMLElement["span",{"class"->"flag flag_translation"},{"перевод"}]],"Original","Translation"]Результат вычислений таков:

Офигенно интересно! Спасибо.
Насчёт анализа вероятностей, а лотерею просчитать можешь? ;)
Насчёт анализа вероятностей, а лотерею просчитать можешь? ;)
Статистика «только уникальные статьи (относящиеся только к одному хабу)»
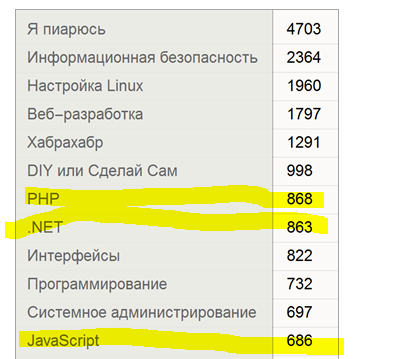
Немного удивлен порядком. Ведь можно говорить как о тренде и популярности? JS неожиданно ниже.
Немного удивлен порядком. Ведь можно говорить как о тренде и популярности? JS неожиданно ниже.
С одной стороны да, с другой ясно, что Javascript очень связан с другими хабами, куда, почти автоматом, также добавляют пост при публикации. Так что да, «монохабных» постов в нем получается меньше.
Вот с какими хабами тесно связан хаб Javascript

Вот с какими хабами тесно связан хаб Javascript

Код для копирования
habs=
Association@KeyValueMap[#1<>" ("<>ToString[#2]<>")"->#2&,KeySelect[Drop[Normal[Reverse@Sort[Counts[Flatten[habrDataset[Select[And[MemberQ[#Habs,"JavaScript"]]&],"Habs"]]]]],1],Not[StringMatchQ[#,"Блог"~~__]]&]];
Quiet[WordCloud[habs,ImageSize->800,MaxItems->All]]UFO just landed and posted this here
Великолепно, фундаментальная работа!
Грандиозная работа, большое спасибо за неё!
Несколько графиков немного сбивают с толку: «Количество %object_name%, публикуемых в %hab_name% за год» — почему-то у всех завален правый край.
Я конечно понимаю, что 2015 год ещё не закончился и значение за этот год меньше, но ведь можно было или экстраполировать по данным за первые 4 месяца на весь год, или просто урезать график по ширине до первых 4 месяцев 2015 года.
Несколько графиков немного сбивают с толку: «Количество %object_name%, публикуемых в %hab_name% за год» — почему-то у всех завален правый край.
Я конечно понимаю, что 2015 год ещё не закончился и значение за этот год меньше, но ведь можно было или экстраполировать по данным за первые 4 месяца на весь год, или просто урезать график по ширине до первых 4 месяцев 2015 года.
Согласен, но это скорее дело вкуса. Я думаю, что все читатели поняли, что в 2015 году меньше только по причине того, что прошло еще только 4 месяца. Экстраполяция потребовала бы довольно много дополнительных объяснений, построения доп. моделей, выяснения их состоятельности и пр.
UFO just landed and posted this here
У меня есть предположение, что случайная величина — отношение числа голосов (не рейтинга!) за статью к числу ее просмотров подчинена распределению Пуассона. Могли бы Вы привести этот график (ось абсцисс — число голосов, ось ординат — отношение)?
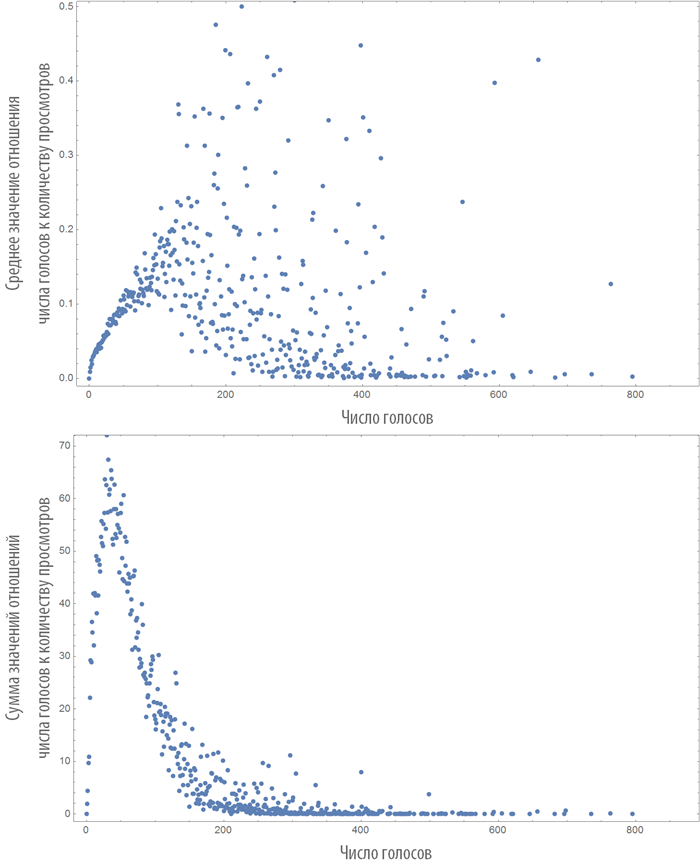
Эпичный пост, однозначно плюс! Всегда было интересно, как делают облачка и фигуры из слов, а тут еще и математически :)
Вы маньяк в хорошем смысле этого слова.
Классная статья!
К сожалению, познакомился с Mathematica лишь недавно, но сразу на курсе лекций был поражён тем, что умеет данный программный пакет, если знать, как с ним обращаться. Хотел про него для Хабра написать, но моих знаний определённо не хватит даже на 1 процентик от данной статьи)))
И ещё раз спасибо!
К сожалению, познакомился с Mathematica лишь недавно, но сразу на курсе лекций был поражён тем, что умеет данный программный пакет, если знать, как с ним обращаться. Хотел про него для Хабра написать, но моих знаний определённо не хватит даже на 1 процентик от данной статьи)))
И ещё раз спасибо!
А можете сравнить частоту слов: яв~~ и джав~~?

Благодарю. Давно об этом мечтал.
Поделитесь, если возможно, почему?
Отчасти поэтому.
Очень круто. Спасибо.
Спасибо большое. Огромная полезная работа. Шикарный пост, в избранном.
Напросился только печальный вывод: хабр говорит про OpenSource, но бОльшей части хабра плевать на OpenSource (уникальные посты этой темы в… внизу). Поправьте меня, если я не прав.
Напросился только печальный вывод: хабр говорит про OpenSource, но бОльшей части хабра плевать на OpenSource (уникальные посты этой темы в… внизу). Поправьте меня, если я не прав.
Класс. Громадное исследование, спасибо… Представил прямо инструмент для хабры (типа «чего хочет хабра»), который в процессе работы над публикацией позволяет глянуть перспективы этой публикации.
Sign up to leave a comment.
Детальный анализ Хабрахабра с помощью языка Wolfram Language (Mathematica)