Перевод поста Риты Крук (Rita Crook) "Benedict Cumberbatch Can Charm Humans, but Can He Fool a Computer?".
Вышедший на этой неделе, весьма ожидаемый, в прокат фильм "Игра в имитацию" (The Imitation Game) рассказывает о жизни Алана Тьюринга (100-лет со дня рождения которого совпали с 22-м днем рождения системы Mathematica — подробнее см. пост Стивена Вольфрама Happy Birthday, Alan Turing). Центральной темой фильма являются машины Тьюринга. Интересно, что в 2007 году компания Wolfram Research объявила приз за доказательство универсальности 2,3 машины Тьюринга.
Конечно же, промоушн-видео Бенедикта Камбербэтча, в котором он имитирует голоса и поведение других известных актеров многим понравилось. Но мне захотелось выяснить, сможет ли функционал Mathematica из области Machine Learning распознать его голос, или же он сможет «одурачить» и компьютер тоже.
Лично я не могу сдержать смеха при просмотре этого видео, но мне хочется посмотреть на эти пародии непредвзято.
Итак, я задалась вопросом: Действительно ли он так хорошо подражает голосам других актеров или же все мы, и я в том числе, просто очарованы его персоной?
Может быть мой разум обманывает меня? Если взять всю выборку исходных голосов, то действительно ли пародии будут неотличимы от них?
Для того, чтобы получить ответ на этот вопрос, 10 лет назад нам пришлось бы ходить по улицам и проигрывать звуковые фрагменты из Джеймса Бонда, Сияния, Бэтмена и подражающего им Камбербэтча, опрашивая человек 300 и затем анализируя их мнение.
В современном мире можно воспользоваться системами вроде Mathematica, чтобы ответить на эти вопросы!
В язык Wolfram Language встроен функционал, который позволяет создать классификатор на основе обучающих выборок аудио фрагментов, что в итоге позволит нам выяснить, сможет ли Камбербэтч «обмануть» компьютер. Итак, я поставила перед собой задачу создать достаточно «приличную» базу данных фрагментов голосов, в дополнение к этому я выделила фрагменты, соответствующий каждой из пародий Камбербэтча и, наконец, позволила остальное сделать за меня Mathematica.
Построим путь к каждой из баз данных фрагментов голосов, которые будут использоваться Mathematica для анализа.

Теперь импортируем все оригинальные голоса:

Классификатор был создан с помощью функции Classify, которой на вход подавалась обучающая выборка. Для увеличения производительности, единожды созданный классификатор (ClassifierFunction) затем можно подгружать в систему мгновенно из файла cfActorWDX.wdx (в закомментированной части кода находится, собственно, конструкция, создающая классификатор):

В мою базу данных вошли: образцы оригинального голоса Бенедикта, голосов актеров, которым подражает Бенедикт и, наконец, фрагменты пародий Бенедикта. Источники для создания обучающей выборки были взяты отсюда: Алан Рикман, Кристофер Уокен, Джек Николсон, Джон Малкович, Майкл Кейн, Оуэн Уилсон, Шон Коннери, Том Хиддлстон, и Бенедикт Камбербэтч. Я использовала в общей сложности 560 фрагментов, но, конечно, чем больше будет использовано данных, тем более надежным будет результат. При этом, образцы должны быть настолько «чистыми», насколько это возможно (без смеха, музыки, разговоров других людей и и пр.)
Они также должны иметь в точности одинаковую длину (3.00 с). Для того, чтобы быть уверенными в том, что у всех длина одинакова, можно использовать такую конструкцию на языке Wolfram Language:

Некоторые из файлов не были одноканальными, так что эту особенность также нужно было устранить для того, чтобы оптимизировать наши результаты еще на стадии генерации и экспорта образцов.

Я благодарю Мартина Хадли (Martin Hadley) и Джона Маклуна (Jon McLoon) за помощь в создании этого кода.
Барабанная дробь… время рассказать о результатах!
Наверное сейчас я разобью всем сердце, и я определенно не хотела бы делать этого… так что я «обвиню» во всем Mathematica, так как Machine Learning на самом деле позволяет определить чей голос звучит в том или ином фрагменте, а значит позволяет распознать подражание голоса и определить кто, собственно, говорил на самом деле.
Результаты ниже показывают, кому из актеров и с какой вероятностью Mathematica отдала «авторство» в каждом из фрагментов «подражания» Бенедикта голосам других актеров:

В большинстве случаев, вероятность того, что говорил кто-то из актеров, помимо Бенедикта Камбербэтча или Алана Рикмана ничтожна.
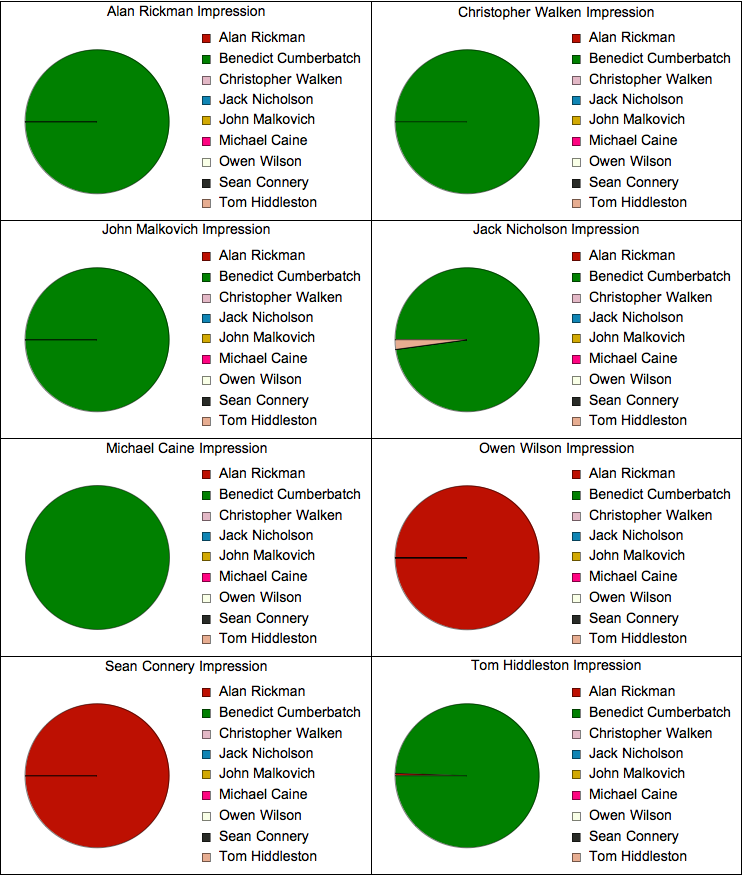
Может быть, стоит отметить, что Рикман, Коннери и Уилсон все имеют довольно медленную манеру говорить с большим количеством пауз (что довольно заметно в использованных мною фрагментах), что в целом может несколько «запутать» алгоритм.

Теперь настало время преодолеть это небольшое потрясение, не держа «обиды» на Бенедикта. Он по прежнему, безусловно, остается очень обаятельным.
Я в целом восхищена его талантом и с нетерпением хочу посмотреть на его игру в фильме, о котором говорила в самом начале моего небольшого поста.
Ресурсы для изучения Wolfram Language (Mathematica) на русском языке: http://habrahabr.ru/post/244451
Вышедший на этой неделе, весьма ожидаемый, в прокат фильм "Игра в имитацию" (The Imitation Game) рассказывает о жизни Алана Тьюринга (100-лет со дня рождения которого совпали с 22-м днем рождения системы Mathematica — подробнее см. пост Стивена Вольфрама Happy Birthday, Alan Turing). Центральной темой фильма являются машины Тьюринга. Интересно, что в 2007 году компания Wolfram Research объявила приз за доказательство универсальности 2,3 машины Тьюринга.
Конечно же, промоушн-видео Бенедикта Камбербэтча, в котором он имитирует голоса и поведение других известных актеров многим понравилось. Но мне захотелось выяснить, сможет ли функционал Mathematica из области Machine Learning распознать его голос, или же он сможет «одурачить» и компьютер тоже.
Лично я не могу сдержать смеха при просмотре этого видео, но мне хочется посмотреть на эти пародии непредвзято.
Итак, я задалась вопросом: Действительно ли он так хорошо подражает голосам других актеров или же все мы, и я в том числе, просто очарованы его персоной?
Может быть мой разум обманывает меня? Если взять всю выборку исходных голосов, то действительно ли пародии будут неотличимы от них?
Для того, чтобы получить ответ на этот вопрос, 10 лет назад нам пришлось бы ходить по улицам и проигрывать звуковые фрагменты из Джеймса Бонда, Сияния, Бэтмена и подражающего им Камбербэтча, опрашивая человек 300 и затем анализируя их мнение.
В современном мире можно воспользоваться системами вроде Mathematica, чтобы ответить на эти вопросы!
В язык Wolfram Language встроен функционал, который позволяет создать классификатор на основе обучающих выборок аудио фрагментов, что в итоге позволит нам выяснить, сможет ли Камбербэтч «обмануть» компьютер. Итак, я поставила перед собой задачу создать достаточно «приличную» базу данных фрагментов голосов, в дополнение к этому я выделила фрагменты, соответствующий каждой из пародий Камбербэтча и, наконец, позволила остальное сделать за меня Mathematica.
Построим путь к каждой из баз данных фрагментов голосов, которые будут использоваться Mathematica для анализа.

Теперь импортируем все оригинальные голоса:
Классификатор был создан с помощью функции Classify, которой на вход подавалась обучающая выборка. Для увеличения производительности, единожды созданный классификатор (ClassifierFunction) затем можно подгружать в систему мгновенно из файла cfActorWDX.wdx (в закомментированной части кода находится, собственно, конструкция, создающая классификатор):

В мою базу данных вошли: образцы оригинального голоса Бенедикта, голосов актеров, которым подражает Бенедикт и, наконец, фрагменты пародий Бенедикта. Источники для создания обучающей выборки были взяты отсюда: Алан Рикман, Кристофер Уокен, Джек Николсон, Джон Малкович, Майкл Кейн, Оуэн Уилсон, Шон Коннери, Том Хиддлстон, и Бенедикт Камбербэтч. Я использовала в общей сложности 560 фрагментов, но, конечно, чем больше будет использовано данных, тем более надежным будет результат. При этом, образцы должны быть настолько «чистыми», насколько это возможно (без смеха, музыки, разговоров других людей и и пр.)
Они также должны иметь в точности одинаковую длину (3.00 с). Для того, чтобы быть уверенными в том, что у всех длина одинакова, можно использовать такую конструкцию на языке Wolfram Language:

Некоторые из файлов не были одноканальными, так что эту особенность также нужно было устранить для того, чтобы оптимизировать наши результаты еще на стадии генерации и экспорта образцов.

Я благодарю Мартина Хадли (Martin Hadley) и Джона Маклуна (Jon McLoon) за помощь в создании этого кода.
Барабанная дробь… время рассказать о результатах!
Наверное сейчас я разобью всем сердце, и я определенно не хотела бы делать этого… так что я «обвиню» во всем Mathematica, так как Machine Learning на самом деле позволяет определить чей голос звучит в том или ином фрагменте, а значит позволяет распознать подражание голоса и определить кто, собственно, говорил на самом деле.
Результаты ниже показывают, кому из актеров и с какой вероятностью Mathematica отдала «авторство» в каждом из фрагментов «подражания» Бенедикта голосам других актеров:

В большинстве случаев, вероятность того, что говорил кто-то из актеров, помимо Бенедикта Камбербэтча или Алана Рикмана ничтожна.
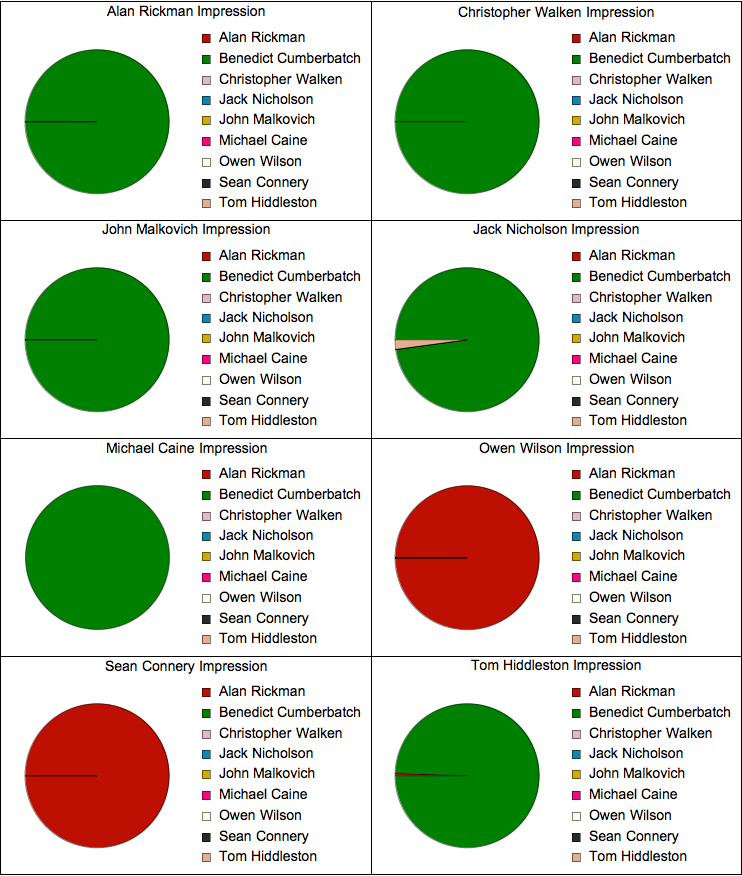
Может быть, стоит отметить, что Рикман, Коннери и Уилсон все имеют довольно медленную манеру говорить с большим количеством пауз (что довольно заметно в использованных мною фрагментах), что в целом может несколько «запутать» алгоритм.

Теперь настало время преодолеть это небольшое потрясение, не держа «обиды» на Бенедикта. Он по прежнему, безусловно, остается очень обаятельным.
Я в целом восхищена его талантом и с нетерпением хочу посмотреть на его игру в фильме, о котором говорила в самом начале моего небольшого поста.
Ресурсы для изучения Wolfram Language (Mathematica) на русском языке: http://habrahabr.ru/post/244451
