Привет, Хабр! Время долгожданного поста про внутреннее устройство Vexor – облачного continuous integration для разработчиков, позволяющего эффективно тестировать проекты и платить только за те ресурсы, которые реально используются.

История
Проект появился из внутренних наработок компании Evrone. Изначально для прогона тестов мы использовали Jenkins. Но когда стало очевидно, что CI-сервис нужно дорабатывать под наши специфические задачи, мы поменяли его на GitlabCI. Этому было несколько причин:
За время использования, как это часто бывает, GitlabCI довольно сильно мутировал. И в тот момент, когда он уже имел мало общего с оригиналом, мы просто переписали все с нуля. Так появилась первая версия Vexor, которая использовалась только внутри команды.
В Evrone параллельно ведется разработка нескольких проектов. Некоторые из них очень большие, и в них с каждым коммитом необходимо прогонять много тестов. А значит, под воркеры постоянно нужно держать наготове много серверов. И соответственно, платить за них по полной.
Но если задуматься, то понимаешь:
Очевидно, что воркеры нужно поднимать и удалять автоматически, ориентируясь на текущие запросы.
Первая версия автоматического масштабирования была написана за пару часов на основе Amazon EC2. Реализация была очень наивной, но даже с ней у нас сразу снизились чеки за использование серверов. CI стал работать намного стабильнее, потому что мы исключили ситуацию, когда внезапный наплыв тестов приводил к нехватке воркеров. Потом интеграция с облаком была несколько раз переделана.
Сейчас в облаке держится пул серверов. Управляет этим отдельное приложение, к которому подключаются воркеры. Приложение мониторит их статусы: живой/упал/не удалось стартовать/нет работы. Приложение автоматически меняет размер этого пула, в зависимости от текущего состояния воркеров, размера очереди задач и примерной оценки затрат времени на их выполнения.
Первоначально в качестве облака мы использовали Amazon EC2. Но на Amazon диски, которые подключаются к серверам, физически находятся не на хосте, а в отдельном хранилище, которое подключено по сети. Когда диски интенсивно используются (а скорость прогона тестов очень зависит от скорости работы дисков), скорость будет упираться в пропускную способность канала до хранилища и выделенной полосы. Amazon решает эту проблему только за отдельные деньги, платить которые совершенно не хотелось. Рассмотрели другие варианты: Rackspace, DigitalOcean, Azure и GCE. Сравнив их, мы остановились на Rackcspace.
Архитектура
Теперь немного об архитектуре.
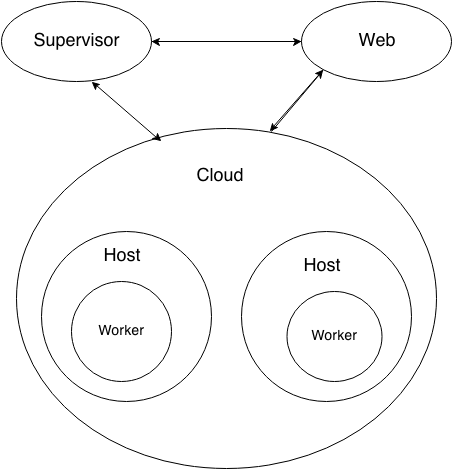
VexorCI – не монолитное приложение, а набор связанных между собой приложений. Для общения между ними используется преимущественно RabbitMQ. Чем в нашем случае хорош кролик:
Есть у RabbitMQ и известные недостатки, с которыми тоже приходится иметь дело:
Так как наши серверы физически размещены в нескольких датацентрах, а пул с воркерами, в случае каких-либо проблем у Rackspace, может переключаться на другой датацентр, для обеспечения стабильной работы RabbitMQ мы используем federation.
Логи
SOA-архитектура влечет за собой еще одну сложность: сбор логов становится нетривиальной задачей. Когда у вас всего пара приложений, можно не задумываться над этим: логи лежат на немногочисленных хостах, на которые всегда можно зайти и грепнуть необходимое. А вот когда приложений много, а одно событие обрабатывается несколькими сервисами, необходим единый сервис, на котором будут храниться логи.
В Vexor за это отвечает связка elasticsearch+logstash+logstash-forwarder. Все логи наших приложений пишутся сразу в JSON формате, логируются все события с приложений, а также дополнительно собираются логи PG, RabbitMQ, Docker и прочие системные сообщения (dmesg, mail и другие). Мы стараемся писать все по максимуму, ведь воркеры работают только определенное время. После отключения сервера с воркером мы не узнаем о проблеме ничего, кроме того, что сохранится в логах.
Контейнер
Для запуска тестов воркерами мы используем Docker. Это отличное решение для работы с изолированными контейнерами, которое предоставляет все необходимые инструменты. Сейчас Docker работает очень стабильно и доставляет минимум проблем (особенно при условии, что у вас свежее ядро OS). Хотя баги тоже встречаются, например, вот такой.
Тесты в Vexor запускаются в контейнере на базе Ubuntu 14.04, в котором предустановлены необходимые для работы популярные сервисы и библиотеки. Полный список пакетов и их версии можно посмотреть тут. Мы периодически обновляем образ, поэтому набор предустановленного софта всегда свежий.
Для того, чтобы использовать один образ для всех поддерживаемых языков и не делать размер образа слишком большим, нужные версии языков (Ruby, Python, Node.js, Go — полный и актуальный список поддерживаемых языков тут) мы ставим из пакетов при запуске билдов. Эта довольно быстрая процедура занимает несколько секунд, при этом такое решение позволяет нам легко поддерживать большой набор версий языков, не перегружая образ.
Deb-пакеты для образа мы пересобираем минимум раз в неделю. Они всегда доступны в публичном репозитории по адресу “https://mirror.pkg.vexor.io/trusty main”. Если, например, вы используете Ubuntu 14.04 amd64, то при его подключении можете получить сразу 12 версий Ruby, уже скомпиллированных вместе с последними версиями bundler и gem, полностью готовыми к установке.
Для того чтобы не делать apt-get update при установке пакетов в runtime и использовать fuzzy matching для версий, мы написали утилиту, с помощью которой можно очень быстро ставить пакеты нужных версий из нашего репозитория, например:
$ time vxvm install go 1.3
Installed to /opt/vexor/packages/go-1.3
…
real 0m3.765s
Конфигурация
В идеале, Vexor сам понимает, что ему нужно запустить для работы вашего проекта. Мы работаем над тем, чтобы распознать автоматически, какие технологии вам нужны и запускать их. Но это возможно не всегда. Поэтому для нераспознанных случаев мы просим пользователей сделать для проекта файл конфигурации.
Чтобы не изобретать велосипед, мы используем файл конфигурации .travis.yml. Travis CI один из самых популярных и известных сервисов сегодня, а значит хорошо, если пользователи будут испытывать минимум трудностей при переходе с него. Ведь если в корневой директории проекта уже есть .travis.yml, то все запустится мгновенно. Ну и команда получит радости быстрого CI за наши скромные поминутные тарифы :)
Серверы
Мы администрируем много серверов, на которых выполняется много задач. Поэтому мы активно используем различные инструменты, например Ansible, Packer и Vagrant. Ansible отвечает за выделение и настройку серверов и отлично выполняет свои задачи. Packer и Vagrant используются для сборки и тестирования образов Docker и серверов с воркерами. Для автоматизации сборки образов используется сам же VexorCI, который автоматически пересобирает все нужное.
Кому подходит наш проект?
Небольшим проектам, которые гоняют тесты не так много и часто, но при этом не хотят платить много и думать о системном администрировании и развертывании, наслаждаясь прелестями continous integration.
Крупным проектам, где много тестов, мы даем неограниченное количество ресурсов, умеем распараллеливать тесты и ускорять их прогон в разы.
Для проектов с большой командой мы решаем проблему с «очередями на просчет тестов». Теперь любое количество тестов может прогоняться одновременно, исключая долгие ожидания.
Друзья, в завершение хотим пригласить всех в наш Vexor. Подключайте ваши проекты и наслаждайтесь преимуществами.

История
Проект появился из внутренних наработок компании Evrone. Изначально для прогона тестов мы использовали Jenkins. Но когда стало очевидно, что CI-сервис нужно дорабатывать под наши специфические задачи, мы поменяли его на GitlabCI. Этому было несколько причин:
- GitlabCI написан на Ruby, который является родным языком команды
- он небольшой и простой, а значит его легко дорабатывать.
За время использования, как это часто бывает, GitlabCI довольно сильно мутировал. И в тот момент, когда он уже имел мало общего с оригиналом, мы просто переписали все с нуля. Так появилась первая версия Vexor, которая использовалась только внутри команды.
В Evrone параллельно ведется разработка нескольких проектов. Некоторые из них очень большие, и в них с каждым коммитом необходимо прогонять много тестов. А значит, под воркеры постоянно нужно держать наготове много серверов. И соответственно, платить за них по полной.
Но если задуматься, то понимаешь:
- По ночам и выходным воркеры под тесты не нужны вообще.
- Если команда большая и процесс построен так, что одновременно делается много коммитов, то параллельных воркеров нужно очень и очень много. Например, если используются недельные итерации, то обычно в конце итерации релизится несколько фич и одновременно делается 5-20 пулл-реквестов, каждый их которых сопровождается прогоном тестов. Складывается ситуация, при которой нужно, например 20+ воркеров.
Очевидно, что воркеры нужно поднимать и удалять автоматически, ориентируясь на текущие запросы.
Первая версия автоматического масштабирования была написана за пару часов на основе Amazon EC2. Реализация была очень наивной, но даже с ней у нас сразу снизились чеки за использование серверов. CI стал работать намного стабильнее, потому что мы исключили ситуацию, когда внезапный наплыв тестов приводил к нехватке воркеров. Потом интеграция с облаком была несколько раз переделана.
Сейчас в облаке держится пул серверов. Управляет этим отдельное приложение, к которому подключаются воркеры. Приложение мониторит их статусы: живой/упал/не удалось стартовать/нет работы. Приложение автоматически меняет размер этого пула, в зависимости от текущего состояния воркеров, размера очереди задач и примерной оценки затрат времени на их выполнения.
Первоначально в качестве облака мы использовали Amazon EC2. Но на Amazon диски, которые подключаются к серверам, физически находятся не на хосте, а в отдельном хранилище, которое подключено по сети. Когда диски интенсивно используются (а скорость прогона тестов очень зависит от скорости работы дисков), скорость будет упираться в пропускную способность канала до хранилища и выделенной полосы. Amazon решает эту проблему только за отдельные деньги, платить которые совершенно не хотелось. Рассмотрели другие варианты: Rackspace, DigitalOcean, Azure и GCE. Сравнив их, мы остановились на Rackcspace.
Архитектура
Теперь немного об архитектуре.

VexorCI – не монолитное приложение, а набор связанных между собой приложений. Для общения между ними используется преимущественно RabbitMQ. Чем в нашем случае хорош кролик:
- Он умеет message acknowledgement и publisher confirm. Это позволяет решить массу проблем, в частности, позволяет писать приложения в популярном в Erlang’е стиле “Let it crash”. То есть при возникновении любых проблем происходит падение, но как только сервис вернется к нормальной работе, все задачи будут выполнены и ни одна из их не будет потеряна.
- RabbitMQ – это брокер с возможностью строить развесистые топологии очередей и точек обмена, а также настраивать роутинг между ними. Это позволяет, например, легко тестировать новые версии сервисов в продакшн-окружении на текущих продакшн-задачах.
- RabbitMQ устойчиво работает с сообщениями большого размера. Рекорд на сегодняшний день – 120Mb в одном сообщении. В VexorCI не стоит задача обрабатывать миллионы сообщений в минуту, но само сообщение может весить десятки Mb или больше (например, при передаче логов).
Есть у RabbitMQ и известные недостатки, с которыми тоже приходится иметь дело:
- Он требует идеально работающей сети между клиентом и сервером. В идеале, сервер должен находиться на том же физическом хосте, что и клиенты. Иначе клиенты кролика будут вести себя как канарейки на подводной лодке: падать при любых проблемах, которые ни один другой сервис не видит.
- C RabbitMQ сложно обеспечить высокую доступность. Есть целых три решения для этого, но реальную высокую доступность обеспечивают только federation и shovel. Которые, в отличие от cluster (про который можно прочитать тут), не так просто интегрировать в существующую архитектуру приложения, так как они не обеспечивают консистентность данных.
Так как наши серверы физически размещены в нескольких датацентрах, а пул с воркерами, в случае каких-либо проблем у Rackspace, может переключаться на другой датацентр, для обеспечения стабильной работы RabbitMQ мы используем federation.
Логи
SOA-архитектура влечет за собой еще одну сложность: сбор логов становится нетривиальной задачей. Когда у вас всего пара приложений, можно не задумываться над этим: логи лежат на немногочисленных хостах, на которые всегда можно зайти и грепнуть необходимое. А вот когда приложений много, а одно событие обрабатывается несколькими сервисами, необходим единый сервис, на котором будут храниться логи.
В Vexor за это отвечает связка elasticsearch+logstash+logstash-forwarder. Все логи наших приложений пишутся сразу в JSON формате, логируются все события с приложений, а также дополнительно собираются логи PG, RabbitMQ, Docker и прочие системные сообщения (dmesg, mail и другие). Мы стараемся писать все по максимуму, ведь воркеры работают только определенное время. После отключения сервера с воркером мы не узнаем о проблеме ничего, кроме того, что сохранится в логах.
Контейнер
Для запуска тестов воркерами мы используем Docker. Это отличное решение для работы с изолированными контейнерами, которое предоставляет все необходимые инструменты. Сейчас Docker работает очень стабильно и доставляет минимум проблем (особенно при условии, что у вас свежее ядро OS). Хотя баги тоже встречаются, например, вот такой.
Тесты в Vexor запускаются в контейнере на базе Ubuntu 14.04, в котором предустановлены необходимые для работы популярные сервисы и библиотеки. Полный список пакетов и их версии можно посмотреть тут. Мы периодически обновляем образ, поэтому набор предустановленного софта всегда свежий.
Для того, чтобы использовать один образ для всех поддерживаемых языков и не делать размер образа слишком большим, нужные версии языков (Ruby, Python, Node.js, Go — полный и актуальный список поддерживаемых языков тут) мы ставим из пакетов при запуске билдов. Эта довольно быстрая процедура занимает несколько секунд, при этом такое решение позволяет нам легко поддерживать большой набор версий языков, не перегружая образ.
Deb-пакеты для образа мы пересобираем минимум раз в неделю. Они всегда доступны в публичном репозитории по адресу “https://mirror.pkg.vexor.io/trusty main”. Если, например, вы используете Ubuntu 14.04 amd64, то при его подключении можете получить сразу 12 версий Ruby, уже скомпиллированных вместе с последними версиями bundler и gem, полностью готовыми к установке.
Для того чтобы не делать apt-get update при установке пакетов в runtime и использовать fuzzy matching для версий, мы написали утилиту, с помощью которой можно очень быстро ставить пакеты нужных версий из нашего репозитория, например:
$ time vxvm install go 1.3
Installed to /opt/vexor/packages/go-1.3
…
real 0m3.765s
Конфигурация
В идеале, Vexor сам понимает, что ему нужно запустить для работы вашего проекта. Мы работаем над тем, чтобы распознать автоматически, какие технологии вам нужны и запускать их. Но это возможно не всегда. Поэтому для нераспознанных случаев мы просим пользователей сделать для проекта файл конфигурации.
Чтобы не изобретать велосипед, мы используем файл конфигурации .travis.yml. Travis CI один из самых популярных и известных сервисов сегодня, а значит хорошо, если пользователи будут испытывать минимум трудностей при переходе с него. Ведь если в корневой директории проекта уже есть .travis.yml, то все запустится мгновенно. Ну и команда получит радости быстрого CI за наши скромные поминутные тарифы :)
Серверы
Мы администрируем много серверов, на которых выполняется много задач. Поэтому мы активно используем различные инструменты, например Ansible, Packer и Vagrant. Ansible отвечает за выделение и настройку серверов и отлично выполняет свои задачи. Packer и Vagrant используются для сборки и тестирования образов Docker и серверов с воркерами. Для автоматизации сборки образов используется сам же VexorCI, который автоматически пересобирает все нужное.
Кому подходит наш проект?
Небольшим проектам, которые гоняют тесты не так много и часто, но при этом не хотят платить много и думать о системном администрировании и развертывании, наслаждаясь прелестями continous integration.
Крупным проектам, где много тестов, мы даем неограниченное количество ресурсов, умеем распараллеливать тесты и ускорять их прогон в разы.
Для проектов с большой командой мы решаем проблему с «очередями на просчет тестов». Теперь любое количество тестов может прогоняться одновременно, исключая долгие ожидания.
Друзья, в завершение хотим пригласить всех в наш Vexor. Подключайте ваши проекты и наслаждайтесь преимуществами.
