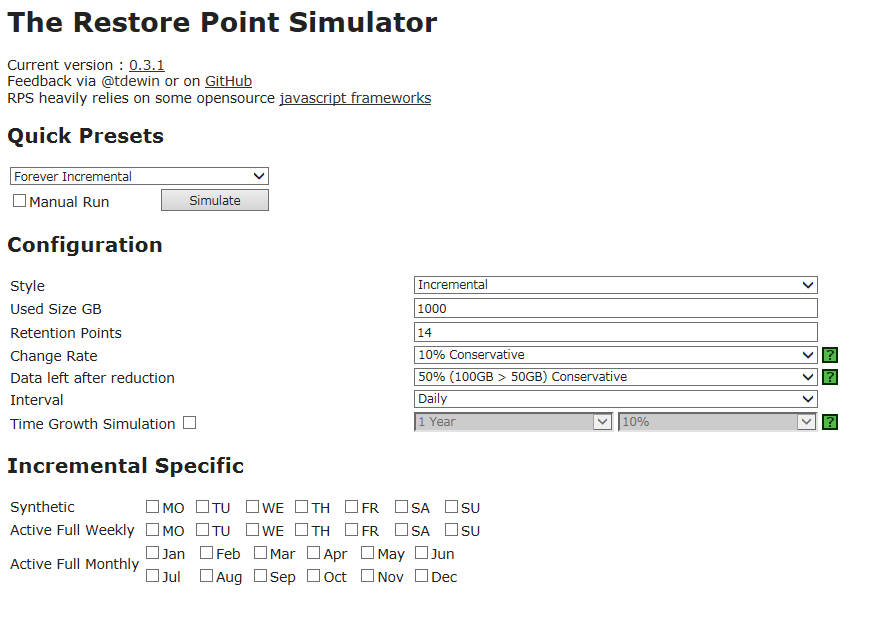
Чтобы при планировании ресурсов для Veeam Backup & Replication люди могли прикинуть, сколько места потребуется в репозитории для бэкапа виртуальной машины, в свое время был создан калькулятор-симулятор точек восстановления Restore Point Simulator (RPS).
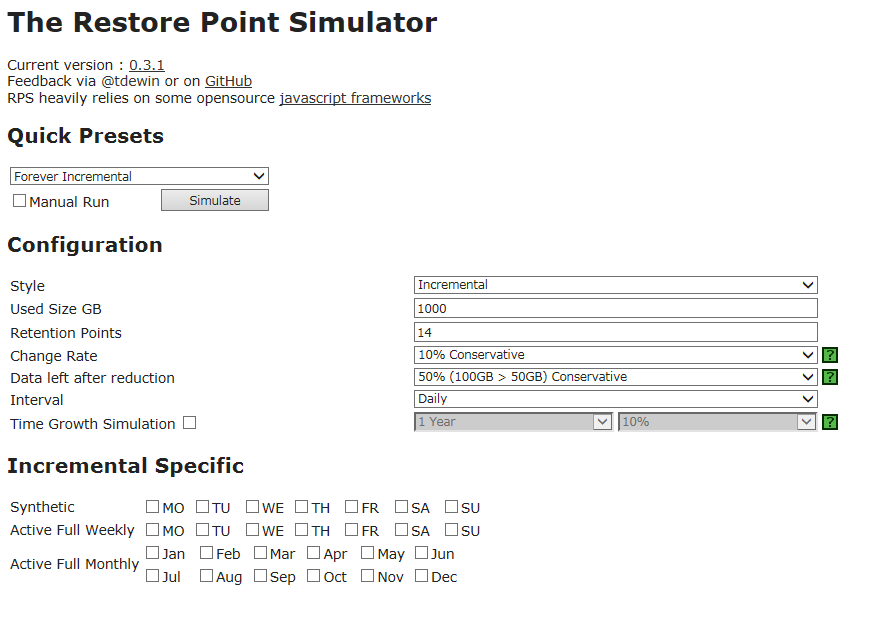
Но поскольку периодически приходится слышать от пользователей «А почему\зачем здесь это значение?», то сегодня я дам несколько пояснений насчет параметров ввода и расскажу, откуда взялись значения по умолчанию.
За подробностями добро пожаловать под кат.
Формула, которую используют для расчета размера бэкапа, получающегося за один проход задания резервного копирования, имеет вид:
Размер бэкапа (Backup Size) = C x (F x Data + R x D x Data)
Здесь:
Параметры этой формулы и калькулятора RPS соотносятся так:
У нас остались еще два параметра из формулы — F и R. Эти значения указывают, сколько вы хотите иметь полных бэкапов (Fulls) или инкрементальных бэкапов (incRements). С режимами Reverse incremental / Forever incremental все очевидно — для них будет:
F = 1
и
R = rps (общее число точек восстановления) — F
А если нужны weekly synthetics или active fulls? Тут все становится несколько сложнее, ибо нужно принимать во внимание настройки политики хранения. Например, если вам нужно строить инкрементальную цепочку forward incremental, делая вдобавок раз в неделю weekly full, а при этом политика предписывает хранить 2 точки восстановления (restore points), то у вас в какой-то момент может оказаться 9 точек – а все из-за зависимостей между инкрементами и полными бэкапами. Понятие «точка восстановления» нужно трактовать буквально (что и делает Veeam Backup & Replication) – это точка, из которой можно восстановиться. Если не будет полного бэкапа – «фундамента», от которого строится цепочка инкрементов-«этажей», то ни из какого инкремента-«этажа» восстановить машину («дом») будет нельзя.
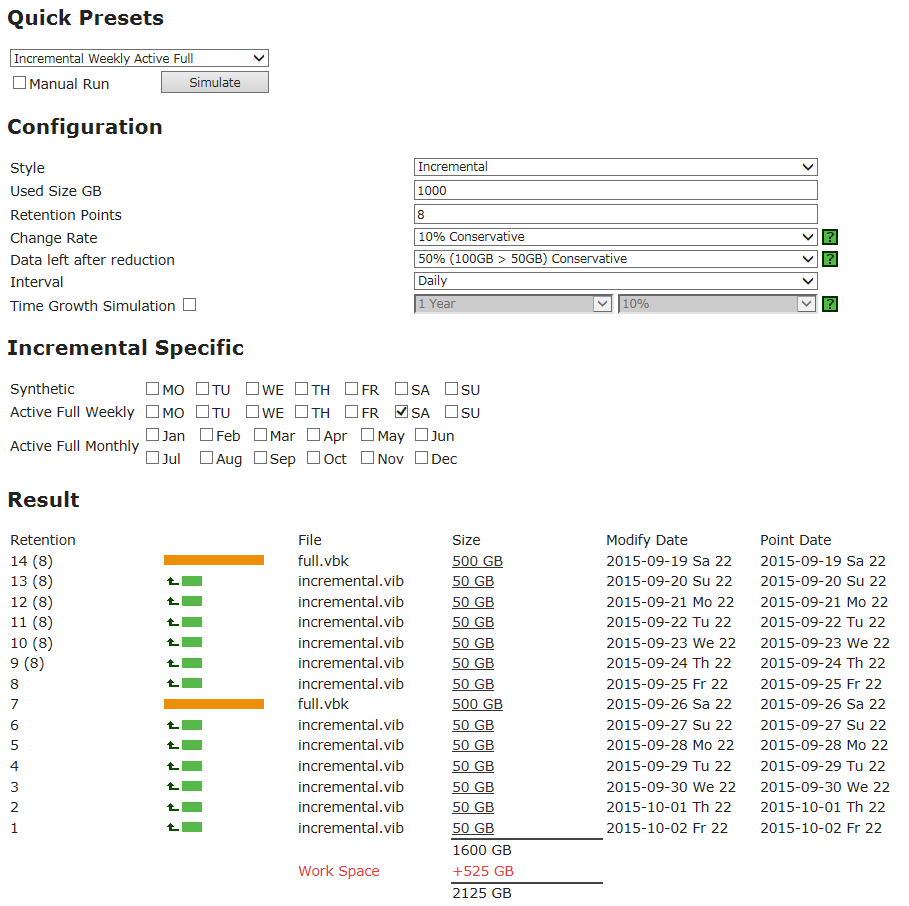
Калькулятор-симулятор тоже иллюстрирует эту зависимость: после того, как вы выберете режим, введете предписанное политикой число точек в поле Retention points и укажете другие параметры, а затем нажмете Simulate, то в секции результатов в колонке Retention вы увидите пару чисел N1 (N2). Это означает, что точка восстановления номер N1 будет храниться (не будет удалена), т.к. от нее зависит другая точка (N2).
Если считать на бумажке или на обычном калькуляторе, то формула будет выглядеть так:
F = (число недель) + 1
R = (F x 7 x число ежедневных бэкапов — F)
Например, если надо хранить 14 точек, а бэкап запускать ежедневно, то получится:
F = 2+1 =3
R = 3 x 7 x 1 — 3 = 21 — 3 = 18
Другая тонкость состоит в понимании того, сколько места будет занимать еженедельный бэкап, а сколько ежемесячный. Помните, что ежемесячный бэкап может иметь цепочку и из 30 точек. Если же настроить еженедельный weekly full, то цепочка составит максимум 7 дней, т.е. места на СХД понадобится меньше. Однако если настроить политику на хранение, скажем, 60 точек, то ежемесячный monthly full может оказаться выгоднее еженедельного.
Как вы уже заметили, некоторые поля калькулятора соответствуют полям интерфейса Veeam Backup & Replication 8; на картинках показаны оба UI – для наглядности и еще большей убедительности.
Итак, определяемся с политикой хранения точек восстановления. Если вам нужно хранить ежедневные бэкапы (по одному в день) в количестве 14 штук, то в поле Retention points укажите 14, а в поле Interval укажите Daily.
Важно! Помните, что в определенные моменты времени хранимых точек будет больше, чем вы указали – поскольку в расчет принимается не только выставленное вами значение, но и зависимости между инкрементами и полными бэкапами. Поэтому не рвитесь редактировать эти значения только из-за того, что вам кажется излишками – а лучше еще раз внимательно перечитайте предыдущий раздел про F и R.
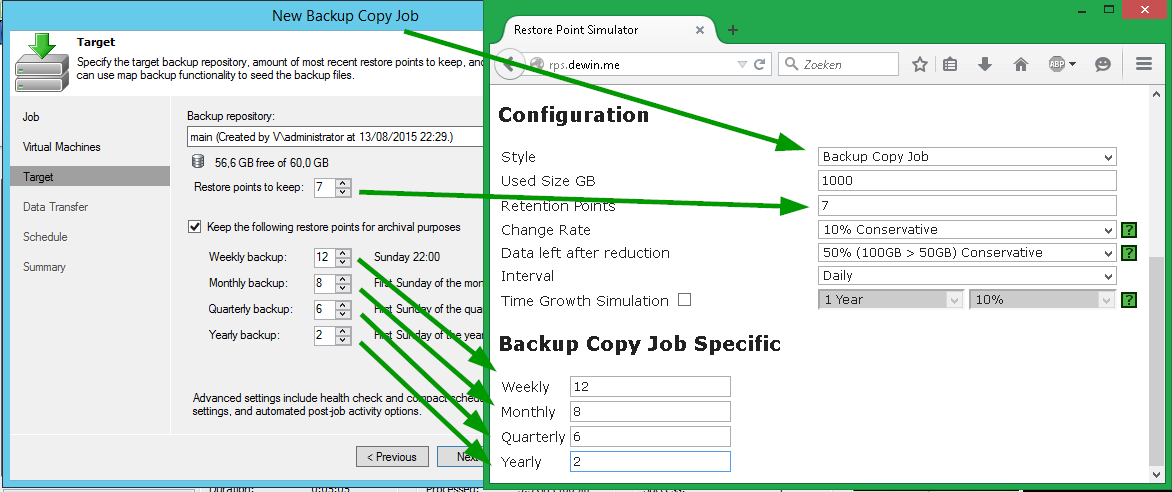
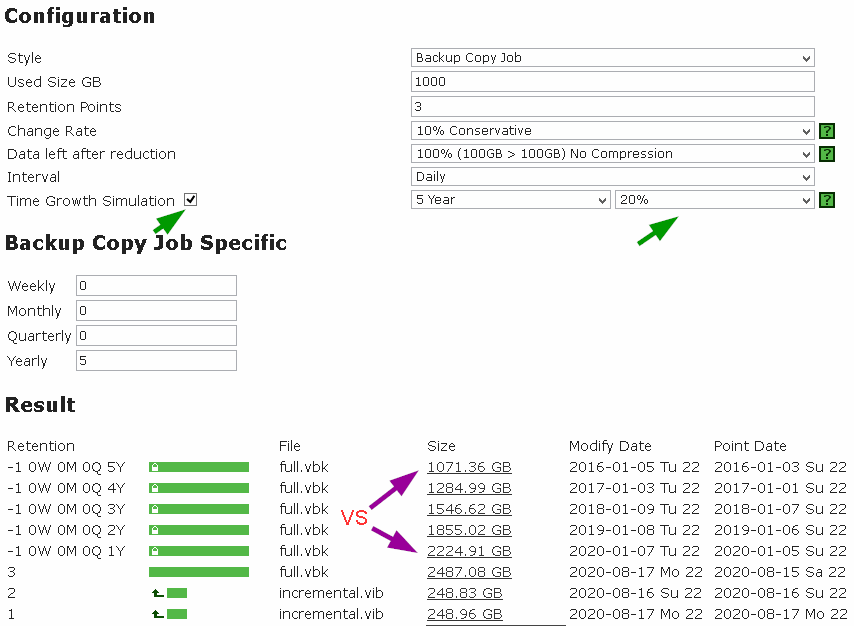
Количество задаваемых параметров зависит также и от того, что в нашем калькуляторе носит название Style (стиль, или способ создания точки восстановления, для которого нужно выполнить оценочные вычисления). Тут все аналогично консоли Veeam Backup & Replication. Например, возьмем «стиль» Backup Copy Job – очевидно, что если вы хотите сделать расчет для такого варианта, то будут использованы те же настройки, что вы задаете и при конфигурации Backup Copy Job в консоли Veeam:
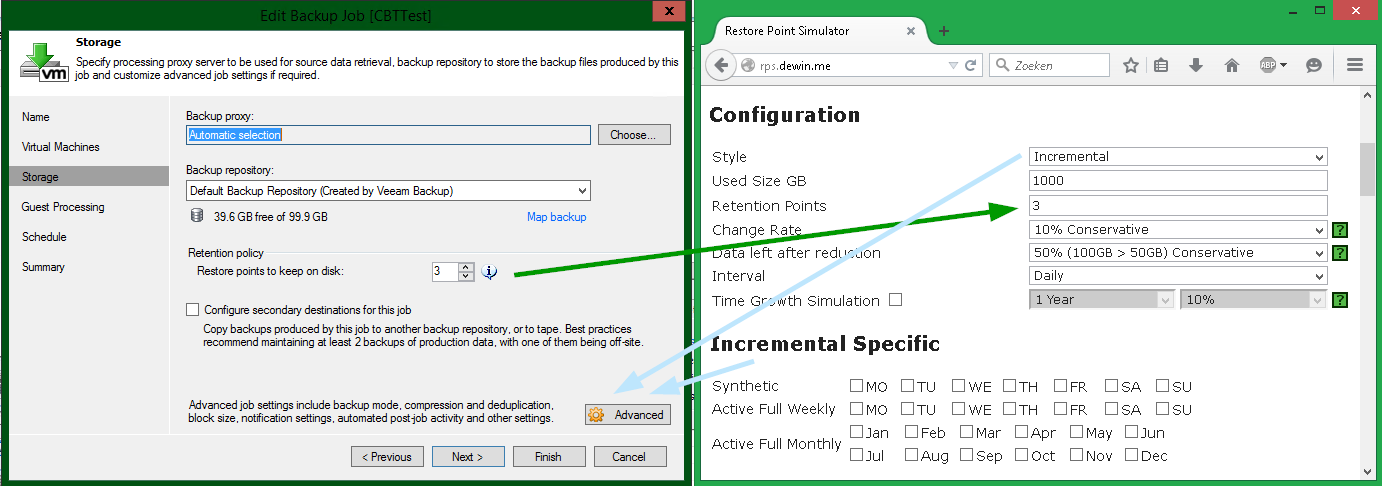
Для других «стилей», названных Incremental и Reverse, параметры калькуляции будут соответствовать настройкам задания резервного копирования Backup Job (за исключением Retention Points):
Примечание: Если вы выберете Incremental вовсе без полных бэкапов (active fulls или synthetic fulls), вы получите бесконечную цепочку инкрементов.
Обращаю ваше внимание на различия в UI:
В этом случае настройки должны быть аналогичны тем, что на этой картинке (слева то, что вы указали бы в консоли Veeam, справа то, что нужно указать в калькуляторе):
Примечание: Опцию “Transform” калькулятор не воспроизводит одной по простой причине – пока что о ней автора никто не просил :).
Для расчета по сценарию с ежемесячным active full настройки должны быть такие, как на этой картинке:
Важно! Помните, что для задания бэкапа Backup Job нет схемы хранения GFS – такая схема может быть задана только в заданиях переноса резервных копий Backup Copy Job. (Один пользователь попробовал зачекать в задании бэкапа только январь, поскольку мечтал «иметь годовой бэкап для архива» — естественно, он был весьма удивлен, увидев, что получилось в результате его настроек. Разумеется, был сделан расчет по цепочке длиной в целый год, с созданием следующего полного бэкапа в январе).
Для расчета же по Reverse incremental настройки должны быть такие:
Осталось разъяснить толькосову одну опцию – симуляцию растущего объема данных Time Growth Simulator. Это недавнее и, по-моему, довольно полезное изобретение. Суть его в том, что если вы хотите, скажем, сделать расчет прироста объема данных на 3 года вперед, и при этом известно, что объем данных на входе растет на 10% в год, то вам просто нужно зачекать галку рядом с Time Growth Simulator и указать этот период и эти %, выбрав нужные значения из выпадающих списков.
Калькулятор берет значение Used Size GB (о нем говорилось выше) и рассчитывает ежедневный прирост объема данных по формуле:
Future Used Data = Used Size x ( 1 + 10% ) ^ (Day N/365)
Таким образом, на последний рассчитываемый день (через 3 года) получится:
Future Used Data = Used Size x ( 1 + 10%) ^ (1095/365)
Предположим, что вы выбрали метод бэкапа Reverse incremental, хотите рассчитать требуемый объем на 3 года вперед, учитывая ежегодный рост объема данных на 10%, а изначальный объем Used Size у вас равен 1000GB (для простоты коэффициент сжатия учитывать не будем).
Рассчитаем по формуле Future Used Data через 3 года:
Future Used Data=1000 x (1+10%)^(1095/365) = 1000 x (110%)^3 = 1000 x (1,10)^3 = 1000 x 1,10 x 1,10 x 1,10 = 1331
Проверим наш расчет с помощью калькулятора-симулятора:
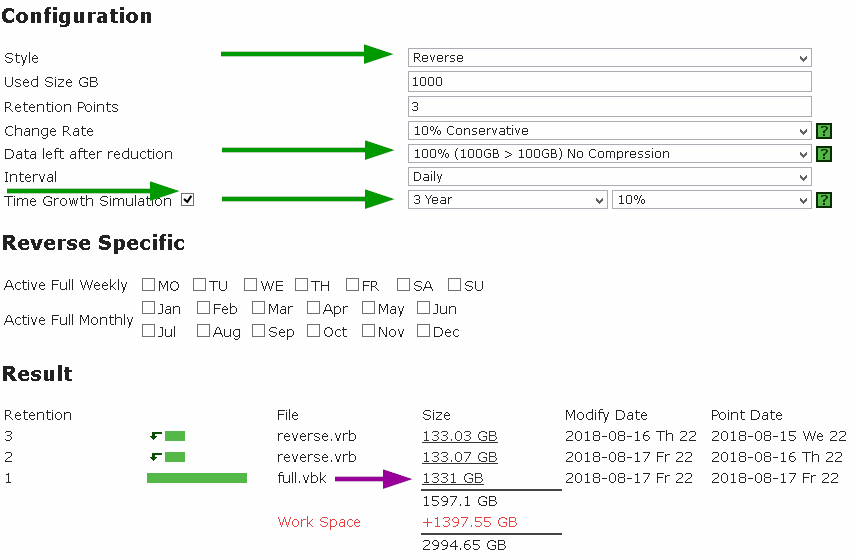
Кстати, заметьте, что у инкрементального бэкапа, который представляет точку восстановления, созданную за 2 дня до истечения 3-летнего срока, размер Future Used Data будет меньше – согласно все той же формуле:
Future Used Data = 1000 x (1+10%)^(1093/365) =~ 1330,30
Для стандартных заданий резервного копирования разница не очень-то велика, но если делать расчеты, скажем, для задания Backup Copy Job с политикой хранения GFS, то можно увидеть более значительный прирост.
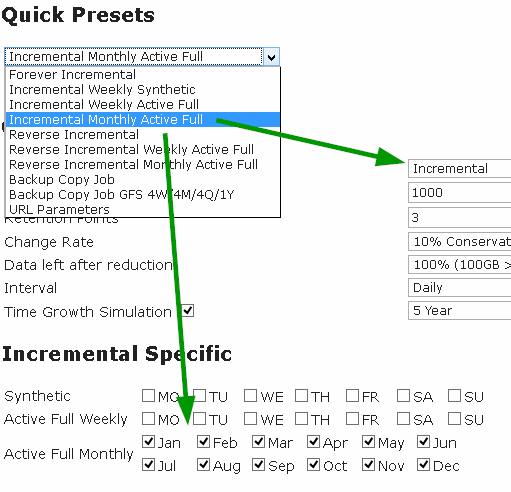
Ну и в завершение пара слов о Quick Presets – это типовые сценарии, которые чаще всего берутся для расчета. Например, сценарий Incremental Monthly Active Full рассчитает вам все ровно так же, как если бы вы выбрали Incremental в списке Style и зачекали все 12 месяцев в Active Full Monthly. Вот и все.
Спасибо за внимание!
Статья на Хабре о методах резервного копирования
Статья на Хабре о тестировании производительности систем хранения для бэкапов
Но поскольку периодически приходится слышать от пользователей «А почему\зачем здесь это значение?», то сегодня я дам несколько пояснений насчет параметров ввода и расскажу, откуда взялись значения по умолчанию.
За подробностями добро пожаловать под кат.
Расчетная формула на бумаге и в калькуляторе
Формула, которую используют для расчета размера бэкапа, получающегося за один проход задания резервного копирования, имеет вид:
Размер бэкапа (Backup Size) = C x (F x Data + R x D x Data)
Здесь:
- Data — суммарный размер всех виртуальных машин, обрабатываемых конкретным заданием резервного копирования (реально занимаемое место, а не выделенное)
- C — средний коэффициент сжатия\дедупликации (вообще-то зависит от целого ряда факторов, может быть очень высоким, но мы возьмем минимальный — 50%; о деталях чуть позже)
- F — количество полных бэкапов (VBK) в цепочке, согласно политике хранения (берем 1, если только не используется режим с периодическим созданием полных бэкапов, о чем тоже расскажу)
- R — количество инкрементальных бэкапов (VRB или VIB) в цепочке, согласно политике хранения (по умолчанию это 14)
- D (delta) — среднее количество изменений диска ВМ в интервале от одного прохода задания резервного копирования до другого (в нынешней версии калькулятора это значение равно 10%, но, возможно, в будущем поменяется на 5% согласно фидбэку от пользователей… вообще-то для основной массы ВМ это 1-2%, но для Exchange и SQL значение доходит до 10-20% из-за большого числа транзакций и, соответственно, записей в журналах, так что 5% будет вполне разумно).
Параметры этой формулы и калькулятора RPS соотносятся так:
- Data – то, что нужно ввести в поле калькулятора Used Size GB.
Это размер реально использованного места, т.е. если у вас есть ВМ с одним диском VMDK, то это значение равно числу блоков, в которые была выполнена запись. Скажем, если это был «толстый» (thick provisioned) диск на 50GB, а вы использовали 20GB на гесте, то в поле Used Size GB нужно ввести значение, близкое к 20GB. Можно сказать, Used Size GB — это место, которое реально занимала бы ВМ, будь у нее «тонкий» диск (thin provisioned), ведь поскольку Veeam копирует данные на уровне блоков, то как раз-таки «тонкий» диск (т.е. реально занятое место) соответствовал бы тому количеству данных, которое подлежит обработке при создании полного бэкапа (ну и плюс немного метаданных). - D, или дельта – это размер данных, которые изменяются между запусками задания бэкапа. В калькуляторе это поле Change rate. На выбор его значения влияют две вещи: как часто запускается задание (обычно это раз в сутки) и какое приложение работает на ВМ.
Занижать это значение не рекомендуется. Повторюсь, Veeam копирует данные на уровне блоков, и крохотное изменение может стать причиной изменения большего масштаба на уровне блока и диска – большего, чем вы заложили в калькулятор. Если запись на диск идет последовательно, как в случае, например, файлового сервера, то это, скорее всего, будет не так заметно, ибо 10 последовательных изменений вполне могут попасть в один блок. Но если приложение делает множество даже совсем небольших рандомных изменений в разных местах, значение может быстро вырасти. Из того, что мне доводилось наблюдать, значение в 5% — довольно оптимистичная оценка, а 10% — довольно консервативная.
Полезно: Если у вас развернуто решение Veeam ONE, то для оценки изменений в % конкретно по вашей инфраструктуре можно сгенерить отчет VM Change Rate Estimation из набора отчетов Infrastructure Assessment.
- C, оно же compression (сжатие) – в калькуляторе это поле Data left after reduction. Насчет его интерпретации среди аудитории бытуют разные мнения, но я предлагаю посмотреть на нашу формулу, которую можно записать так:
Backup Size = C x (Total Data In)
То есть, говоря по-русски:
Размер бэкапа = С x (общий объем данных на входе)
Из нее видно, что при умножении на C значение Total Data In изменяется пропорционально, давая нам Backup Size. Значит, коэффициент сжатия C показывает, на сколько (в %) уменьшился объем входящих данных, точнее, сколько осталось от первоначального объема после сжатия. Так, например, если выставить его в 40% (40/100) и принять объем входящих данных за 100 единиц, то размер бэкапа составит, очевидно, (40/100)*100=40 единиц. Если же выставить его в 60%, то получится, что вы ожидаете меньшего эффекта от сжатия, ибо согласно формуле получится, что размер бэкапа составит (60/100)*100=60 единиц. Итог: чем меньше значение коэффициента сжатия, тем лучше работает компрессия.
Кому-то это покажется интуитивно понятным, а кому-то привычнее видеть коэффициент сжатия «в 2 раза» или «в 3 раза». Это легко преобразовать – получится 1/N x 100%, то есть для «в два раза» будет 1/2 x 100%= 50%.
Подставим это значение в нашу формулу и получим: 50 backup size = 50% x (100 total data in)
Все верно, входящий объем данных ужался вдвое. Аналогично и для сжатия «в 3 раза»: 1/3 x 100% = 33% .
Примечание: Если вы планируете вовсе отключить сжатие данных, установите значение этого коэффициента в 100%.
Про точки восстановления и политику хранения
У нас остались еще два параметра из формулы — F и R. Эти значения указывают, сколько вы хотите иметь полных бэкапов (Fulls) или инкрементальных бэкапов (incRements). С режимами Reverse incremental / Forever incremental все очевидно — для них будет:
F = 1
и
R = rps (общее число точек восстановления) — F
А если нужны weekly synthetics или active fulls? Тут все становится несколько сложнее, ибо нужно принимать во внимание настройки политики хранения. Например, если вам нужно строить инкрементальную цепочку forward incremental, делая вдобавок раз в неделю weekly full, а при этом политика предписывает хранить 2 точки восстановления (restore points), то у вас в какой-то момент может оказаться 9 точек – а все из-за зависимостей между инкрементами и полными бэкапами. Понятие «точка восстановления» нужно трактовать буквально (что и делает Veeam Backup & Replication) – это точка, из которой можно восстановиться. Если не будет полного бэкапа – «фундамента», от которого строится цепочка инкрементов-«этажей», то ни из какого инкремента-«этажа» восстановить машину («дом») будет нельзя.
Калькулятор-симулятор тоже иллюстрирует эту зависимость: после того, как вы выберете режим, введете предписанное политикой число точек в поле Retention points и укажете другие параметры, а затем нажмете Simulate, то в секции результатов в колонке Retention вы увидите пару чисел N1 (N2). Это означает, что точка восстановления номер N1 будет храниться (не будет удалена), т.к. от нее зависит другая точка (N2).
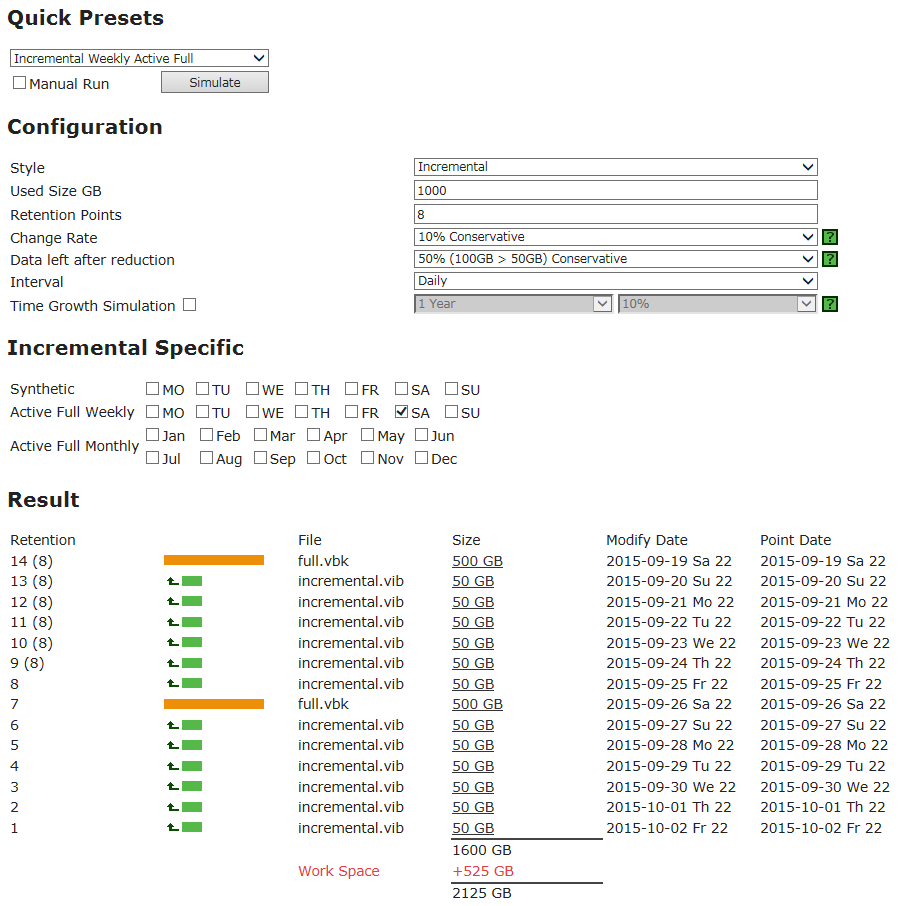
Если считать на бумажке или на обычном калькуляторе, то формула будет выглядеть так:
F = (число недель) + 1
R = (F x 7 x число ежедневных бэкапов — F)
Например, если надо хранить 14 точек, а бэкап запускать ежедневно, то получится:
F = 2+1 =3
R = 3 x 7 x 1 — 3 = 21 — 3 = 18
Другая тонкость состоит в понимании того, сколько места будет занимать еженедельный бэкап, а сколько ежемесячный. Помните, что ежемесячный бэкап может иметь цепочку и из 30 точек. Если же настроить еженедельный weekly full, то цепочка составит максимум 7 дней, т.е. места на СХД понадобится меньше. Однако если настроить политику на хранение, скажем, 60 точек, то ежемесячный monthly full может оказаться выгоднее еженедельного.
Вводная часть закончена, переходим к вводу
Как вы уже заметили, некоторые поля калькулятора соответствуют полям интерфейса Veeam Backup & Replication 8; на картинках показаны оба UI – для наглядности и еще большей убедительности.
Итак, определяемся с политикой хранения точек восстановления. Если вам нужно хранить ежедневные бэкапы (по одному в день) в количестве 14 штук, то в поле Retention points укажите 14, а в поле Interval укажите Daily.
Важно! Помните, что в определенные моменты времени хранимых точек будет больше, чем вы указали – поскольку в расчет принимается не только выставленное вами значение, но и зависимости между инкрементами и полными бэкапами. Поэтому не рвитесь редактировать эти значения только из-за того, что вам кажется излишками – а лучше еще раз внимательно перечитайте предыдущий раздел про F и R.
Количество задаваемых параметров зависит также и от того, что в нашем калькуляторе носит название Style (стиль, или способ создания точки восстановления, для которого нужно выполнить оценочные вычисления). Тут все аналогично консоли Veeam Backup & Replication. Например, возьмем «стиль» Backup Copy Job – очевидно, что если вы хотите сделать расчет для такого варианта, то будут использованы те же настройки, что вы задаете и при конфигурации Backup Copy Job в консоли Veeam:
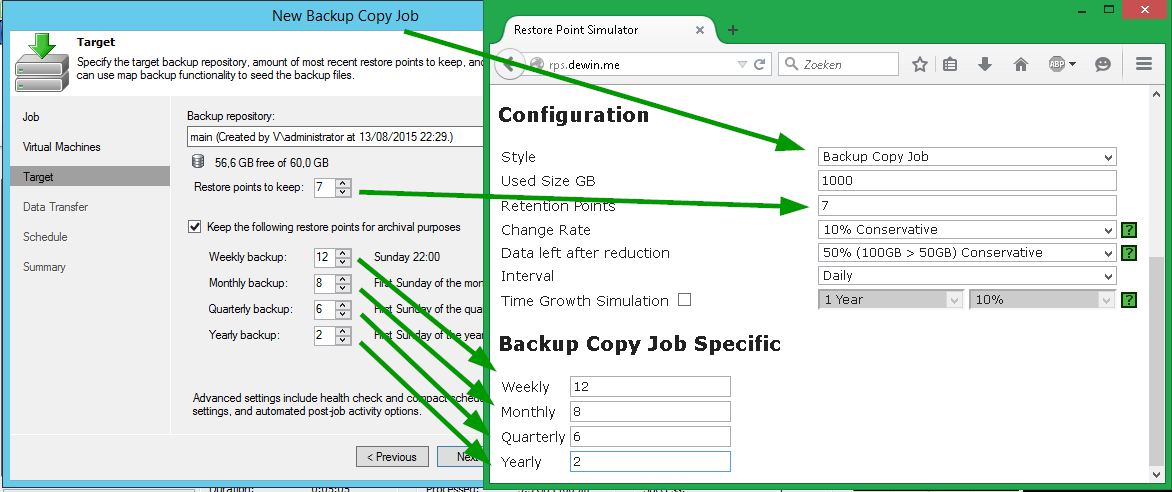
Для других «стилей», названных Incremental и Reverse, параметры калькуляции будут соответствовать настройкам задания резервного копирования Backup Job (за исключением Retention Points):
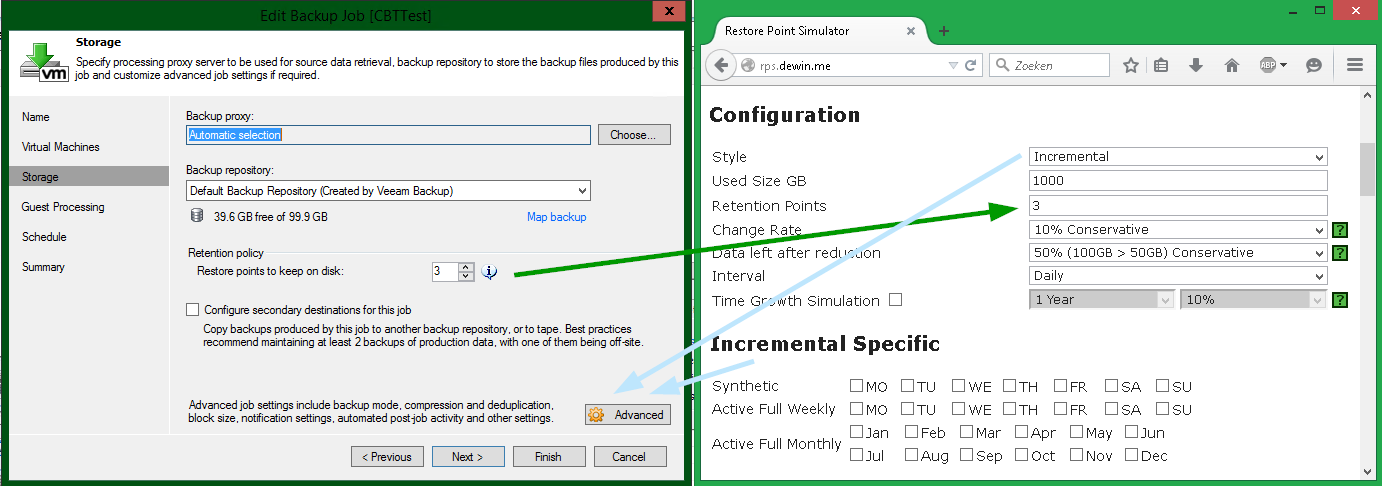
Примечание: Если вы выберете Incremental вовсе без полных бэкапов (active fulls или synthetic fulls), вы получите бесконечную цепочку инкрементов.
Обращаю ваше внимание на различия в UI:
- В интерфейсе Veeam соответствующие настройки октрываются по нажатию кнопки Advanced на шаге Storage (разумеется) мастера задания бэкапа. Параметры расписания, по которому должен создаваться полный бэкап, в Advanced Settings открываются по нажатию кнопок Days и Months.
- В калькуляторе как такового чекбокса «Enable Active» или “Enable Synthetic” вы не увидите, однако зачекивание любой галки в секции Incremental Specific приведет как раз-таки к выбору Active Full или Synthetic Full.
- Ну и вдобавок в калькуляторе у опции Monthly приоритет над опцией Weekly – в Veeam GUI вы можете выбрать только одну из них, а здесь хоть обе, но если будет выбрана Monthly, то Weekly будет игнорироваться.

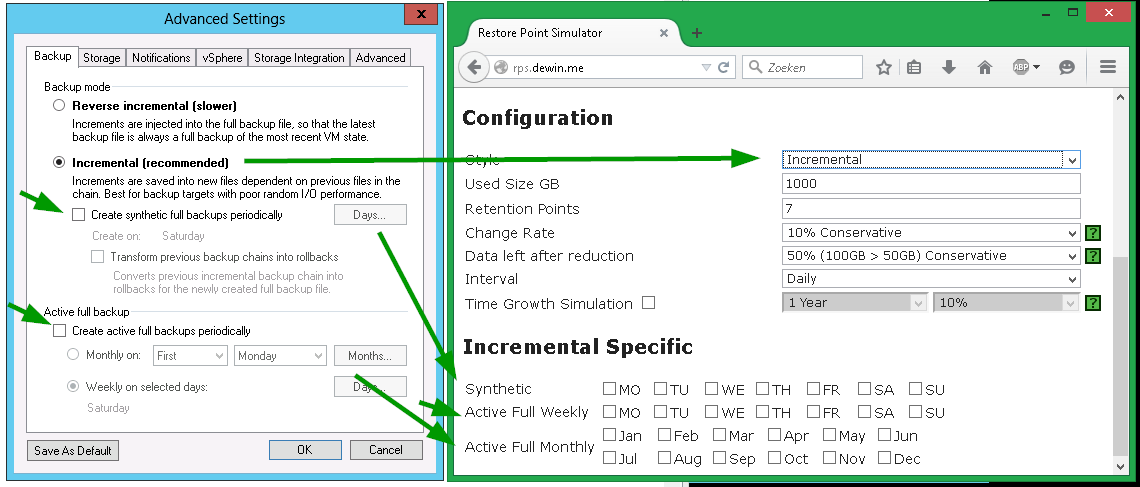
Пример №1: инкрементный бэкап с еженедельным synthetic full
В этом случае настройки должны быть аналогичны тем, что на этой картинке (слева то, что вы указали бы в консоли Veeam, справа то, что нужно указать в калькуляторе):
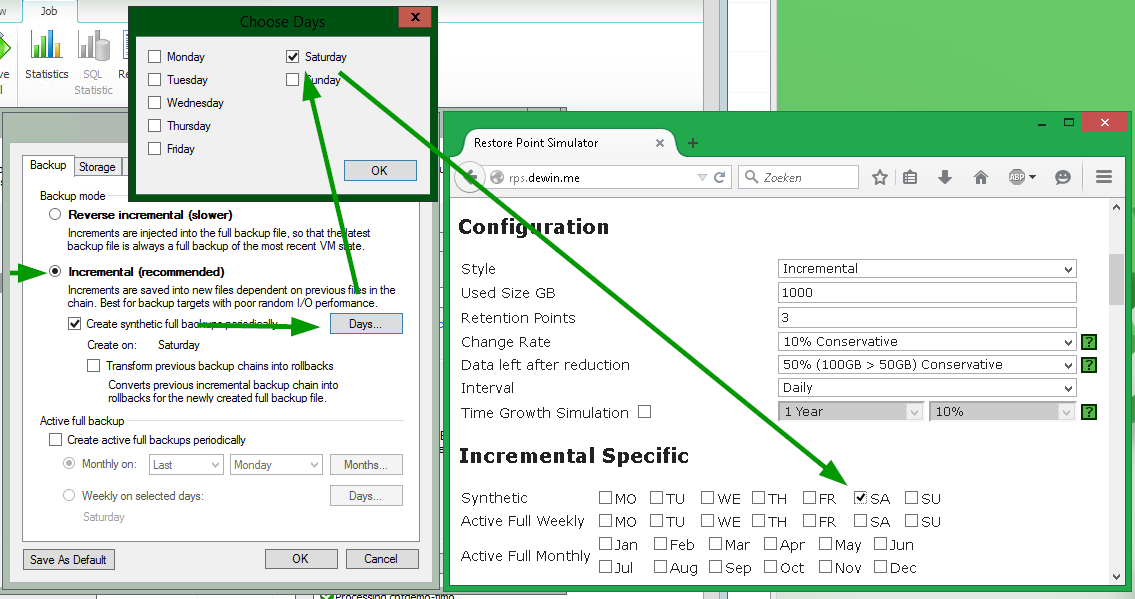
Примечание: Опцию “Transform” калькулятор не воспроизводит одной по простой причине – пока что о ней автора никто не просил :).
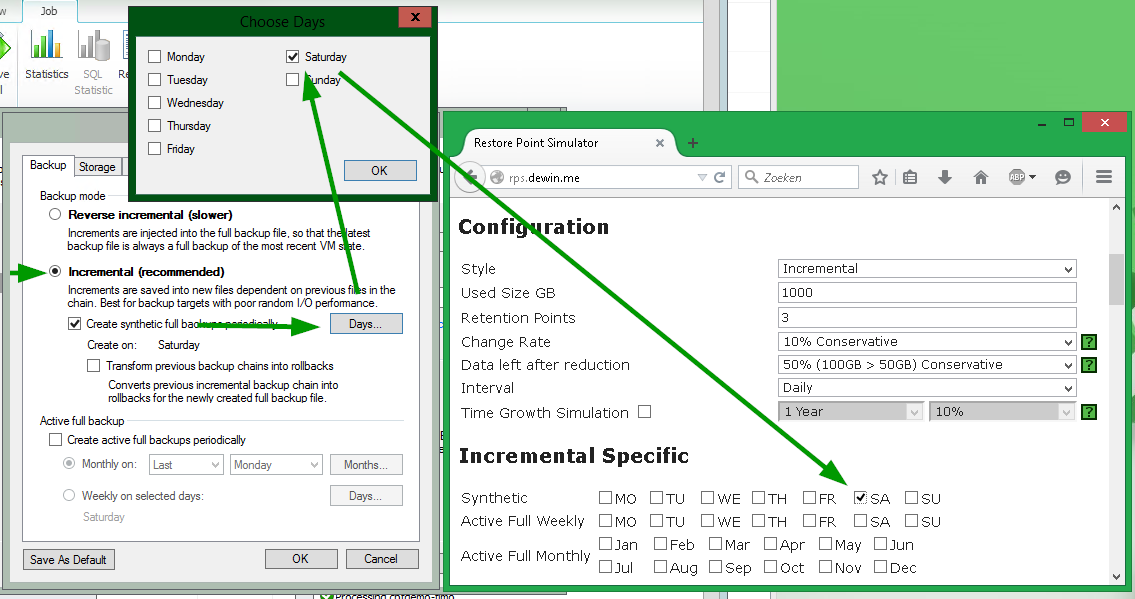
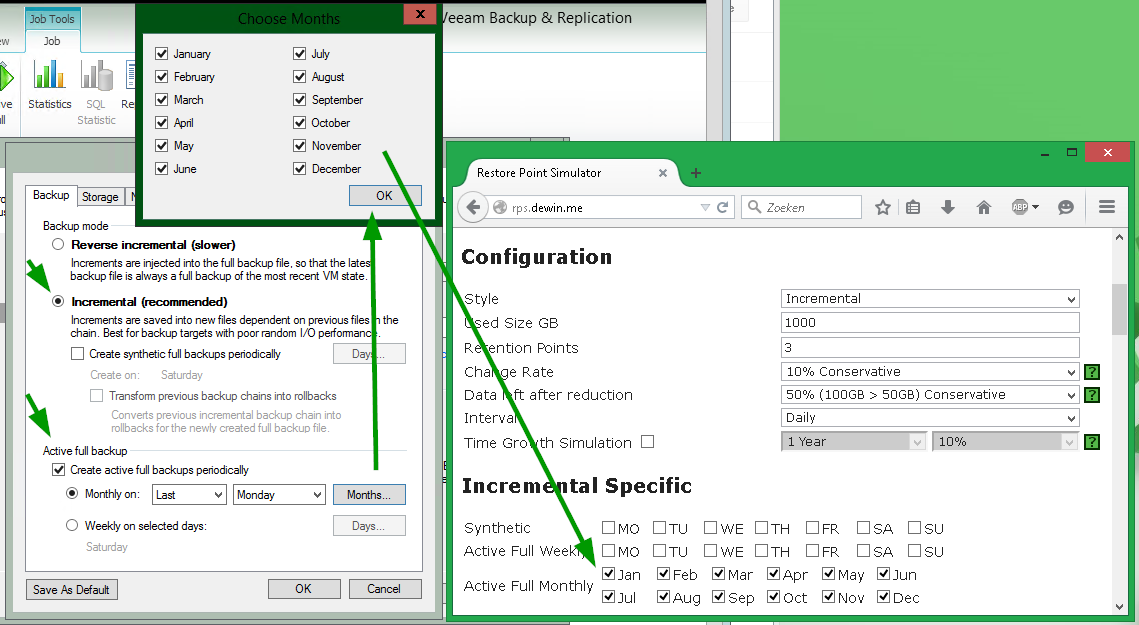
Пример №2: инкрементный бэкап с ежемесячным active full
Для расчета по сценарию с ежемесячным active full настройки должны быть такие, как на этой картинке:

Важно! Помните, что для задания бэкапа Backup Job нет схемы хранения GFS – такая схема может быть задана только в заданиях переноса резервных копий Backup Copy Job. (Один пользователь попробовал зачекать в задании бэкапа только январь, поскольку мечтал «иметь годовой бэкап для архива» — естественно, он был весьма удивлен, увидев, что получилось в результате его настроек. Разумеется, был сделан расчет по цепочке длиной в целый год, с созданием следующего полного бэкапа в январе).
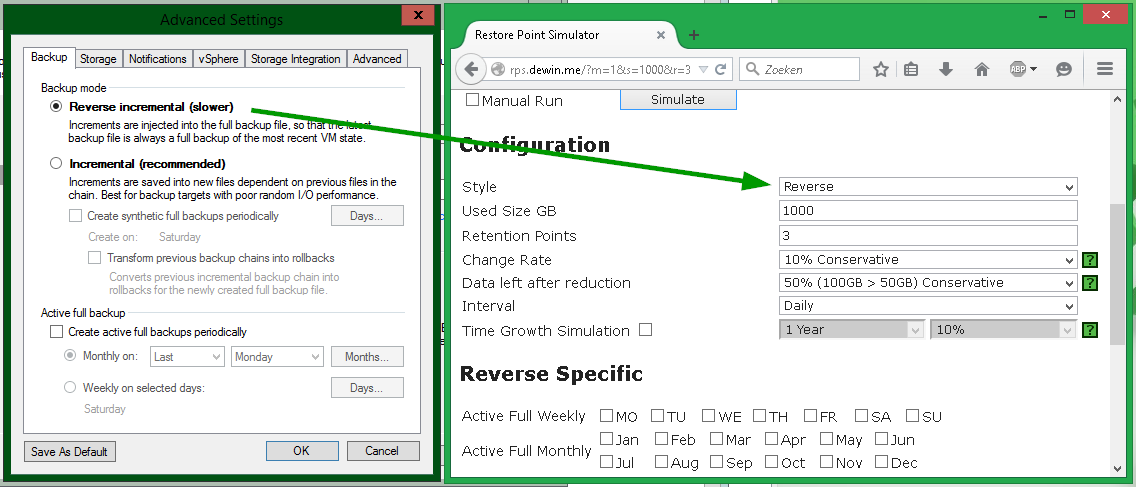
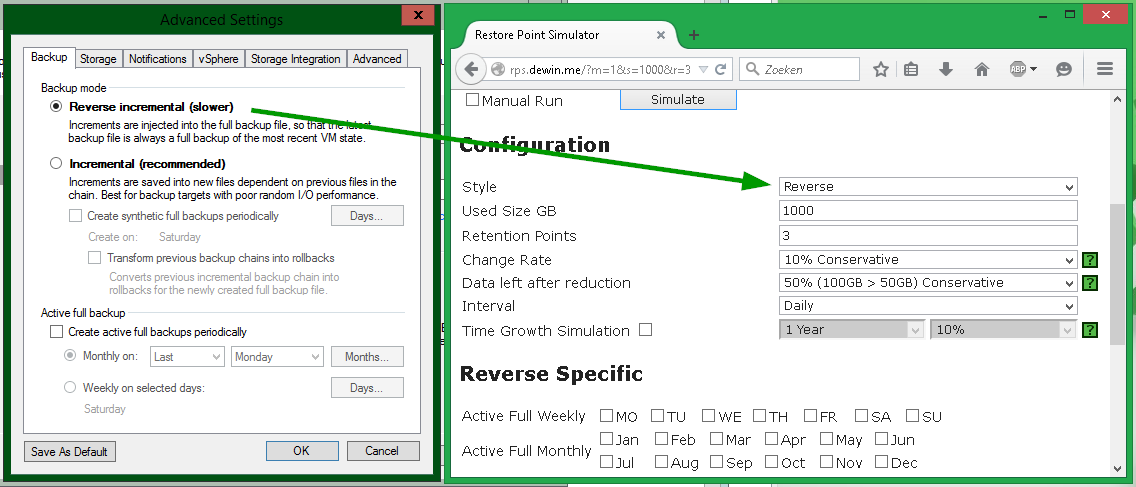
Пример №3: реверсивный инкрементный бэкап
Для расчета же по Reverse incremental настройки должны быть такие:
А долгосрочные прогнозы делаете?
Осталось разъяснить только
Калькулятор берет значение Used Size GB (о нем говорилось выше) и рассчитывает ежедневный прирост объема данных по формуле:
Future Used Data = Used Size x ( 1 + 10% ) ^ (Day N/365)
Таким образом, на последний рассчитываемый день (через 3 года) получится:
Future Used Data = Used Size x ( 1 + 10%) ^ (1095/365)
Пример №4
Предположим, что вы выбрали метод бэкапа Reverse incremental, хотите рассчитать требуемый объем на 3 года вперед, учитывая ежегодный рост объема данных на 10%, а изначальный объем Used Size у вас равен 1000GB (для простоты коэффициент сжатия учитывать не будем).
Рассчитаем по формуле Future Used Data через 3 года:
Future Used Data=1000 x (1+10%)^(1095/365) = 1000 x (110%)^3 = 1000 x (1,10)^3 = 1000 x 1,10 x 1,10 x 1,10 = 1331
Проверим наш расчет с помощью калькулятора-симулятора:

Кстати, заметьте, что у инкрементального бэкапа, который представляет точку восстановления, созданную за 2 дня до истечения 3-летнего срока, размер Future Used Data будет меньше – согласно все той же формуле:
Future Used Data = 1000 x (1+10%)^(1093/365) =~ 1330,30
Для стандартных заданий резервного копирования разница не очень-то велика, но если делать расчеты, скажем, для задания Backup Copy Job с политикой хранения GFS, то можно увидеть более значительный прирост.

Ну и в завершение пара слов о Quick Presets – это типовые сценарии, которые чаще всего берутся для расчета. Например, сценарий Incremental Monthly Active Full рассчитает вам все ровно так же, как если бы вы выбрали Incremental в списке Style и зачекали все 12 месяцев в Active Full Monthly. Вот и все.

Спасибо за внимание!
PS: Что еще почитать
Статья на Хабре о методах резервного копирования
Статья на Хабре о тестировании производительности систем хранения для бэкапов
