Есть много полезных инструментов, которые помогают отслеживать нагрузку на сервер, начиная с утилит Linux и заканчивая специализированными службами.
Простые утилиты Linux показывают текущее потребление памяти для каждого процесса, нагрузку на CPU, свободное место на диске и статистику по трафику.
Кроме того, есть платные и бесплатные сервисы, которые круглосуточно отслеживают состояние вашего сервера, регистрируют сбои в его работе или в сетевой доступности, а также проверяют производительность приложений.
Содержание
Утилиты Linux
Использование ресурсов
top
Один из самых инструментов для проверки использования ресурсов процессами. Утилита
top выдаёт простую таблицу с текущим потреблением ресурсов, где сверху указаны процессы с наибольшей нагрузкой.top - 14:45:52 up 29 min, 1 user, load average: 0.10, 0.09, 0.06
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 393756k used, 625844k free, 11136k buffers
Swap: 0k total, 0k used, 0k free, 316748k cached
PID %MEM VIRT SWAP RES CODE DATA SHR nFLT nDRT S PR NI %CPU COMMAND
832 1.3 32364 18m 12m 896 11m 1688 1 0 S 20 0 0.0 bash
820 0.4 89456 83m 4008 488 948 3040 12 0 S 20 0 0.0 sshd
812 0.3 49948 46m 2828 488 616 2216 0 0 S 20 0 0.0 sshd
1 0.2 24192 21m 2108 152 868 1300 23 0 S 20 0 0.0 init
400 0.1 243m 242m 1420 344 216m 1084 0 0 S 20 0 0.0 rsyslogdНепосредственно перед таблицей приводится некоторая общая статистика, включая среднюю нагрузку на CPU за последнюю минуту, 5 минут и 15 минут. Также показано потребление памяти, файла подкачки и состояние процессов.
Список обновляется в реальном времени: можете вывести его на второй монитор и наблюдать постоянно.
htop
Хотя утилита
top поставляется почти с каждым дистрибутивом, в большинстве репозиториев также доступна для скачивания улучшенная версия htop.Установка
htop на Ubuntu:apt-get install htopЗдесь мы видим почти такую же выдачу, но с подсветкой разными цветами и более интерактивную:
CPU[| 0.7%] Tasks: 21, 3 thr; 1 running
Mem[||||||||||||| 64/995MB] Load average: 0.00 0.02 0.05
Swp[ 0/0MB] Uptime: 00:37:37
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
2752 root 20 0 25660 1876 1364 R 0.0 0.2 0:00.06 htop
1 root 20 0 24192 2108 1300 S 0.0 0.2 0:00.55 /sbin/init
312 root 20 0 17224 640 444 S 0.0 0.1 0:00.04 upstart-udev-brid
314 root 20 0 21592 1360 760 S 0.0 0.1 0:00.04 /sbin/udevd --dae
394 messagebu 20 0 23808 688 436 S 0.0 0.1 0:00.01 dbus-daemon --sys
401 syslog 20 0 243M 1420 1084 S 0.0 0.1 0:00.07 rsyslogd -c5
402 syslog 20 0 243M 1420 1084 S 0.0 0.1 0:00.00 rsyslogd -c5Верхняя часть здесь яснее и лучше организована.
Вот некоторые ключи для более эффективного использования
htop:- M: сортировка процессов по использованию памяти
- P: сортировка процессов по использованию CPU
- ?: справка
- k: прекратить текущие/помеченные процессы
- F2: настройка (здесь можно выбрать опции для отображения)
- /: поиск процессов
Ряд других опций перечислен в справке и настройках. Изучение программы стоит начать из этих двух разделов.
Сетевой трафик
nethogs
nethogs — самая простая утилита для просмотра, сколько трафика приходится на каждую службу. На Ubuntu утилита устанавливается следующей командой:apt-get install nethogsЗатем её можно запустить без ключей. Выдача простая:
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/secЕсть всего несколько опций для изменения выдачи:
- m: переключение между kb/s, kb, b, mb
- r: сортировка по полученному трафику.
- s: сортировка по отправленному трафику
- q: выход
Хотя это простая утилита, но она отлично подходит для быстрого просмотра, какие приложения генерируют трафик.
IPTraf
IPTraf — ещё один способ мониторинга сетевого трафика, с большим количеством опций. Установка на Ubuntu:apt-get install iptrafЭта утилита предлагает выбрать один из интерактивных интерфейсов:
???????????????????????????????????
? IP traffic monitor ?
? General interface statistics ?
? Detailed interface statistics ?
? Statistical breakdowns... ?
? LAN station monitor ?
???????????????????????????????????
? Filters... ?
???????????????????????????????????
? Configure... ?
???????????????????????????????????
? Exit ?
???????????????????????????????????Например, для обзора всего сетевого трафика выбираем первый пункт меню:
? TCP Connections (Source Host:Port) ?????????? Packets ??? Bytes Flags Iface ?
??192.241.xxx.xxx:22 > 369 82420 -PA- eth0 ?
??72.43.xxx.xxx:49488 > 381 19860 --A- eth0 ?
? ?
? ?Чтобы IP-адреса резолвились в домены, нужно в конфигурации выбрать пункт 'Reverse DNS lookups'.
Вместе просмотром трафика по портам есть вариант просмотра трафика по сервисам (опция 'TCP/UDP service names'). С обеими включёнными опциями выдача будет выглядеть примерно так:
TCP Connections (Source Host:Port) ?????????? Packets ??? Bytes Flags Iface ?
??192.241.xxx.xxx:ssh > 151 34924 -PA- eth0 ?
??rrcs-72-43-xxx-xxx.nyc.biz.rr.co:49488 > 155 8108 --A- eth0 ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? TCP: 1 entries ???????????????????????????????????????????????? Active ??
????????????????????????????????????????????????????????????????????????????????
? UDP (72 bytes) from 192.241.xxx.xxx:43463 to 8.8.8.8:domain on eth0 ?
? UDP (66 bytes) from 192.241.xxx.xxx:53140 to 8.8.8.8:domain on eth0 ?
? UDP (135 bytes) from 8.8.8.8:domain to 192.241.xxx.xxx:41429 on eth0 ?
? UDP (119 bytes) from 8.8.8.8:domain to 192.241.xxx.xxx:43463 on eth0 ?
? UDP (110 bytes) from google-public-dns-a.googl:domain to 192.241.xxx.xxx:531 ?Есть ещё несколько других интерфейсов, которые можете изучить самостоятельно.
netstat
Утилита
netstat — очень гибкий и мощный инструмент для сбора сетевой информации.По умолчанию
netstat выдаёт список открытых сокетов:Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .Если добавить опцию
-a, он покажет список всех портов:Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .Флаги
-t или -u фильтруют TCP- или UDP-соединения, соответственно. Флаг -s выводит статистику. Для постоянного обновления выдачи нужно запускать команду с ключом -c.Место на диске
df
Стандартная утилита для просмотра информации о смонтированных разделах — это
df. Она выводит список подключенных устройств и информацию о занятом месте.Filesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shmПо умолчанию выдача в байтах, что не очень удобно. Параметр
-h активирует выдачу в мегабайтах и гигабайтах:Filesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shmДля просмотра всего места на всех дисках добавляем опцию
--total.du
Утилита
df позволяет быстро получить общий обзор. Для более детальной информации лучше подходит программа du, которая анализирует текущую директорию и любые поддиректории. Выдача по умолчанию выглядит так:4 ./.cache
8 ./.ssh
28 .Опять же, более удобная для восприятия выдача включается ключом
-h.Просмотр размеров файлов и директорий включается флагом
-a, общий итог — флагами -c (подробности и сумма) и -s (только сумма).Улучшенные версии
Улучшенные версии df и du называются pydf и ncdu, на Ubuntu они устанавливаются командами
apt-get install pydf и apt-get install ncdu. Они организуют красивую выдачу в псевдографике с расцветкой:pydf -a
dev/vda 30G 1200M 27G 3.9 [........] /
udev 493M 4096B 493M 0.0 [........] /dev
devpts 0 0 0 - [........] /dev/pts
proc 0 0 0 - [........] /proc
tmpfs 199M 204k 199M 0.1 [........] /run
none 5120k 0 5120k 0.0 [........] /run/lock
none 498M 0 498M 0.0 [........] /run/shm
. . .ncdu
--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_historyЗдесь можно перемещаться по файловой системе клавишами со стрелками.
Использование памяти
free
Самый простой способ просмотра текущего использования оперативной памяти — команда
free. Выдача без опций выглядит таким образом: total used free shared buffers cached
Mem: 12286456 11715372 571084 0 81912 6545228
-/+ buffers/cache: 5088232 7198224
Swap: 24571408 54528 24516880Запуск с ключом
-m генерирует выдачу в мегабайтах.Средняя строка
-/+ buffers/cache показывает значение используемой памяти минус сумма буферов/кэша, а также количество свободной памяти плюс сумма буферов/кэша.Дело в том, что Linux как большинство современных ОС пытается использовать максимальный объём доступной оперативной памяти под буферы и кэш. Поэтому имеет значение вторая строка, которая показывает реальный объём потенциально доступной оперативной памяти для приложений, если игнорировать буферы и кэш. Этот объём будет освобождён автоматически, если он понадобится для приложений.
vmstat
Команда
vmstat выводит различную информацию о системе, включая память, файл подкачки, операции ввода-вывода и нагрузку на CPU.procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 2828 407616 335348 5511476 0 0 26 268 41 27 28 30 42 0 0В первой колонке
r указано количество активных процессов, во второй — количество процессов в состоянии непрерываемого ожидания.Колонки
si и so показывают объём памяти, которая считывается из файла подкачки и записывается в него, соответственно.Далее показано количество блоков, которые получены или отправлены на устройство блочного ввода вывода (bi, bo), количество прерываний в секунду, включая таймер (in), количество переключений контекста в секунду (cs) и статистика по CPU: процент времени, затраченного на обработку кода в пользовательском пространстве (us), на обработку кода ядра (sy), в спящем состоянии (id) и ожидании ввода-вывода (wa), а также времени, «украденного» у виртуальной машины (st), то есть когда виртуальный CPU ожидает действия реального CPU, когда гипервизор обслуживает другой виртуальный процессор.
Флаг
-S M активирует выдачу в мегабайтах. Запуск с опцией -s показывает общую статистику.Сервисы мониторинга
Если вам необходимо круглосуточно отслеживать состояние сервера (память, CPU, свободное место, производительность, время отклика и проч.), то можно воспользоваться бесплатным или платным сервисом мониторинга. Таких сервисов много, вот небольшой список в алфавитном порядке:
- Anturis
- AppDynamics
- AppNeta
- Atera
- BigPanda
- CollectD
- Datadog
- eG Innovations
- Ganglia
- Icinga (бесплатная адаптация Nagios Core)
- Instrumental
- LogicMonitor
- ManageEngine OpManager
- Monitis
- Motadata
- Nagios XI (бесплатная версия называется Nagios Core)
- Navicat Monitor
- NinjaRMM
- Op5 Monitor
- OpenNMS
- Pandora FMS
- Panopta
- PRTG Network Monitor
- SeaLion
- Server Density
- Site24x7
- SolarWinds Server and Application Monitor
- Spiceworks Network Monitor (бесплатно)
- Stackify
- WhatsUpGold
- Zabbix (бесплатный системный монитор)
Некоторые мониторы лучше подходят для малого бизнеса, а другие для крупных компаний. Отдельные специализируются на мониторинге облачных систем. Есть сервисы, которые работают только на Linux-серверах. Системы отличаются по масштабируемости, набору функций и уровню автоматизации действий. Несколько мониторов распространяются с открытым исходным кодом.
Для примера, рассмотрим три относительно популярных сервиса для мониторинга.
SolarWinds Server and Application Monitor
Один из самых продвинутых серверных мониторов на рынке — SolarWinds Server and Application Monitor (SAM). Хотя инструмент устанавливается только на Windows Server 2016+, но может отслеживать любое оборудование, в том числе Linux-серверы.
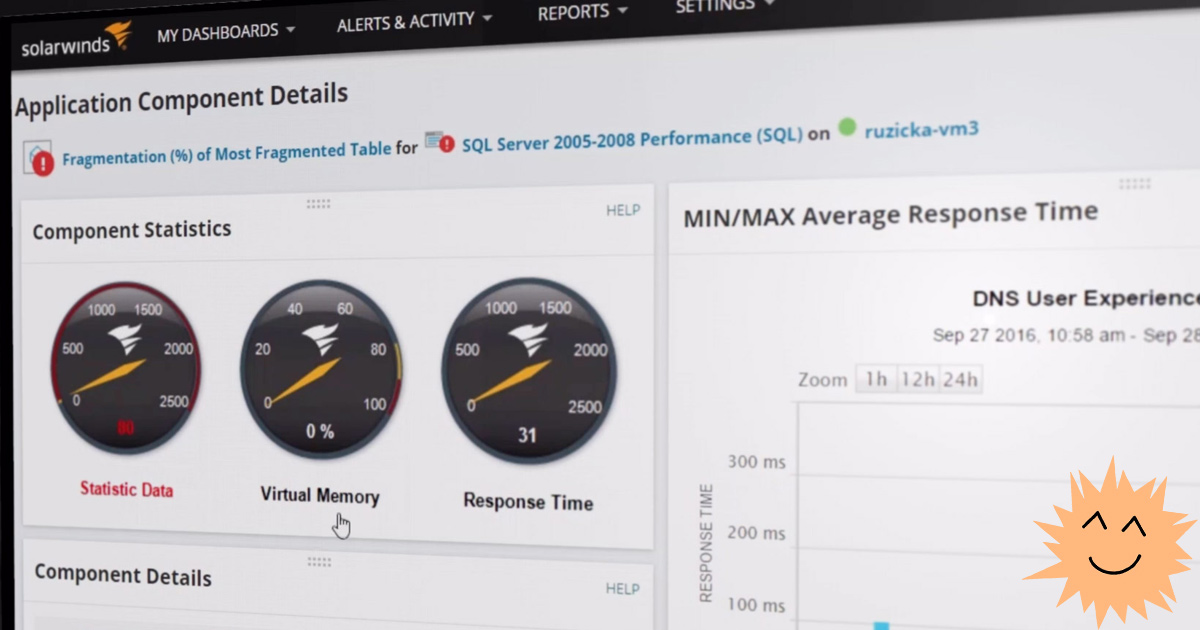
Монитор отслеживает производительность сервера, сообщает о проблемах, а также предоставляет некоторые возможности по управлению: позволяет перезапускать сервер, снимать процессы и перезапускать службы, то есть это инструмент не только для мониторинга, но и для администрирования.

Программа лучше подходит для крупных корпораций. Заявлена совместимость с серверами Dell PowerEdge, HP ProLiant, IBM eServer xSeries, Dell PowerEdge Blade, HP BladeSystem, Microsoft Windows Server и VMware vSphere. В то же время SAM мониторит и облачные инстансы AWS и Azure.
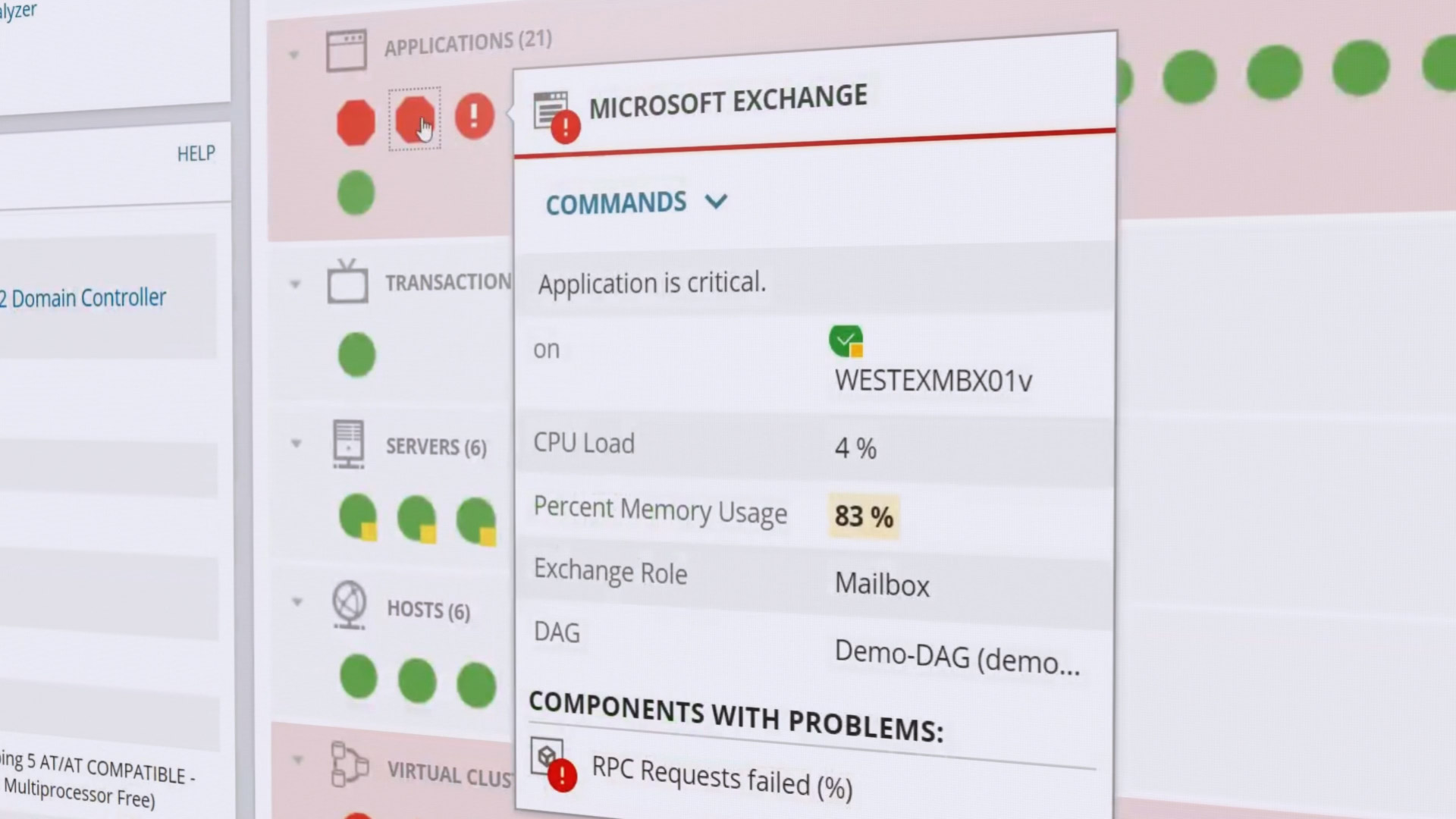
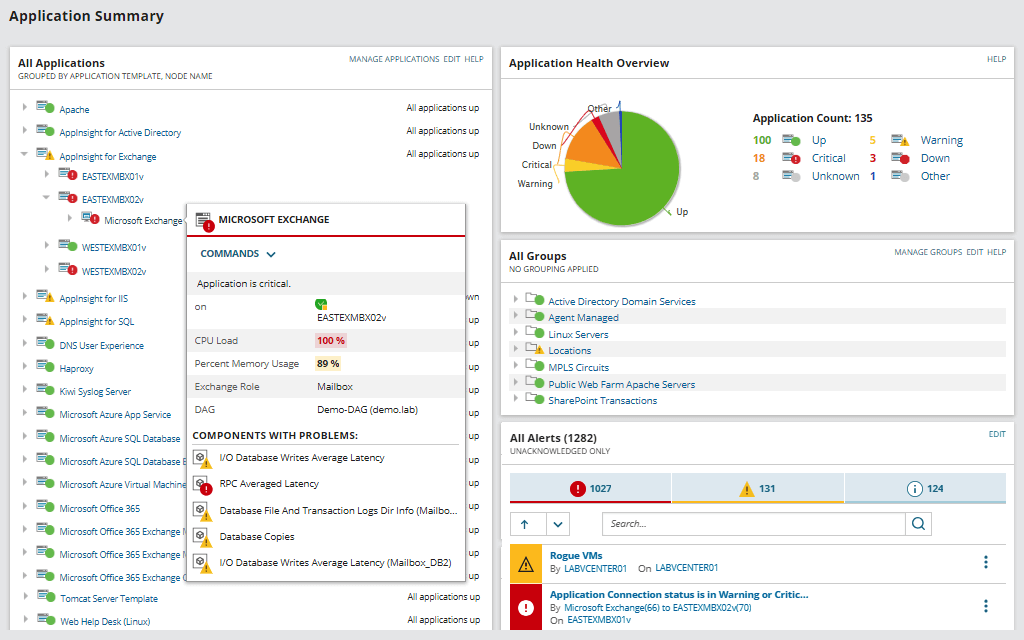
Он показывает статистику по времени отклика, загрузке CPU, памяти и др. Отслеживается производительность отдельных приложений: встроена поддержка более 1200 разных приложений. Также проверяется состояние оборудования: использование CPU, нагрузка на диски, энергопитание, статус вентиляторов и т. д. Статусы кодируются цветом от зелёного до красного, чтобы было легко оценить здоровье системы с первого взгляда.
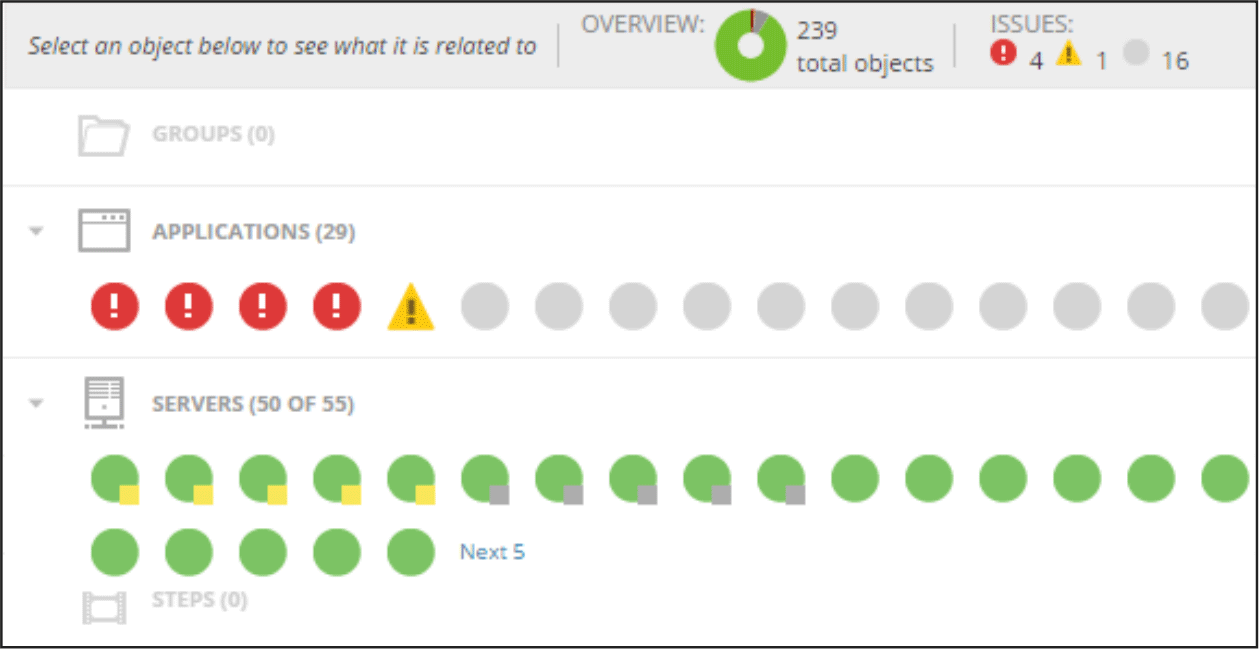
Монитор автоматически определяет новое оборудование и программное обеспечение в вашем кластере, сразу добавляя его на панель мониторинга. Это одна из ключевых особенностей SAM, также как максимальная автоматизация — подготовленные шаблоны для автоматизации регулярных задач по мониторингу и обслуживанию, заготовки для отчётов и уведомлений.
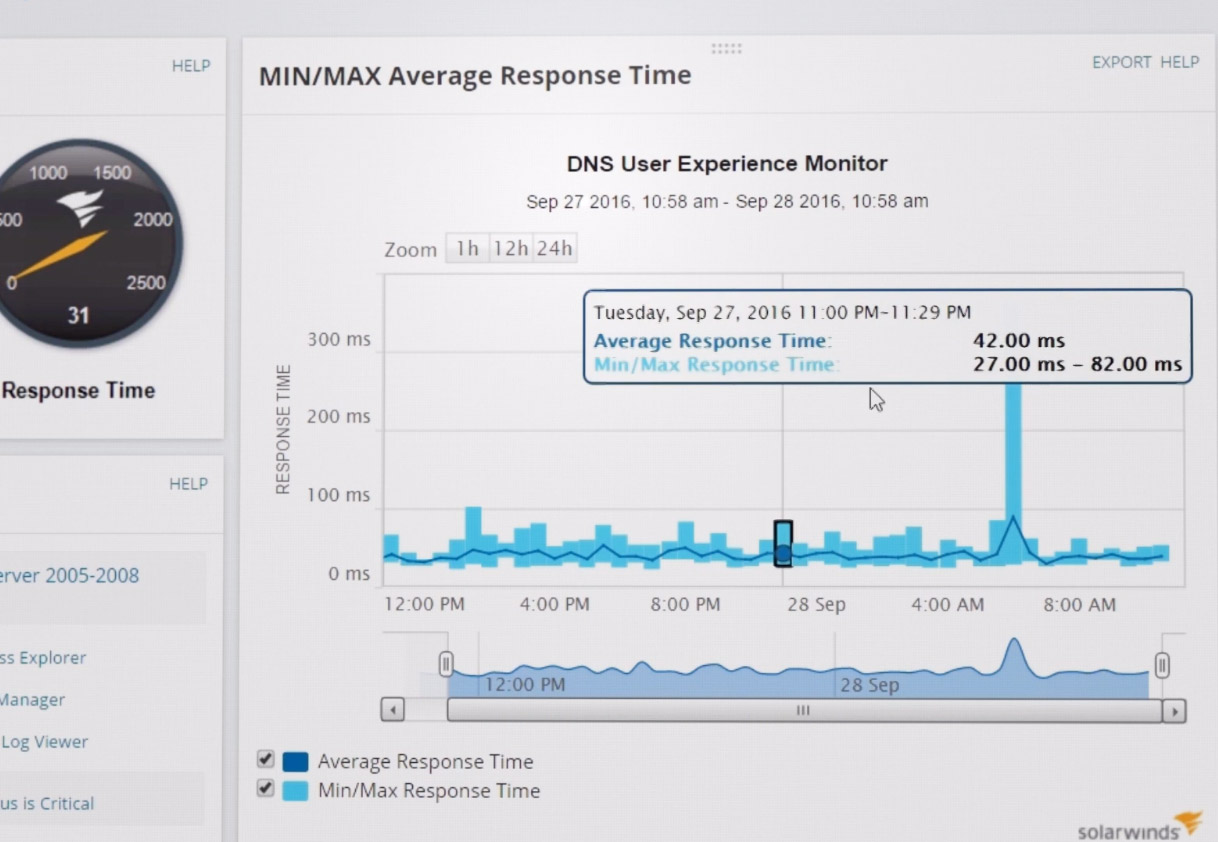
Обычно у таких сервисов имеется бесплатный пробный период, а стоимость может зависеть от набора используемой функциональности. Здесь тоже есть пробный период, а стоимость SolarWinds Server and Application Monitor начинается от 1275 евро в минимальной функциональности.
Navicat Monitor
Другой пример — Navicat Monitor, который специализируется на мониторинге баз данных. Он поддерживает MySQL, MariaDB, SQL Server, а также облачные СУБД, такие как Amazon RDS, Amazon Aurora, Oracle Cloud, Google Cloud и Microsoft Azure.

Стандартный вид
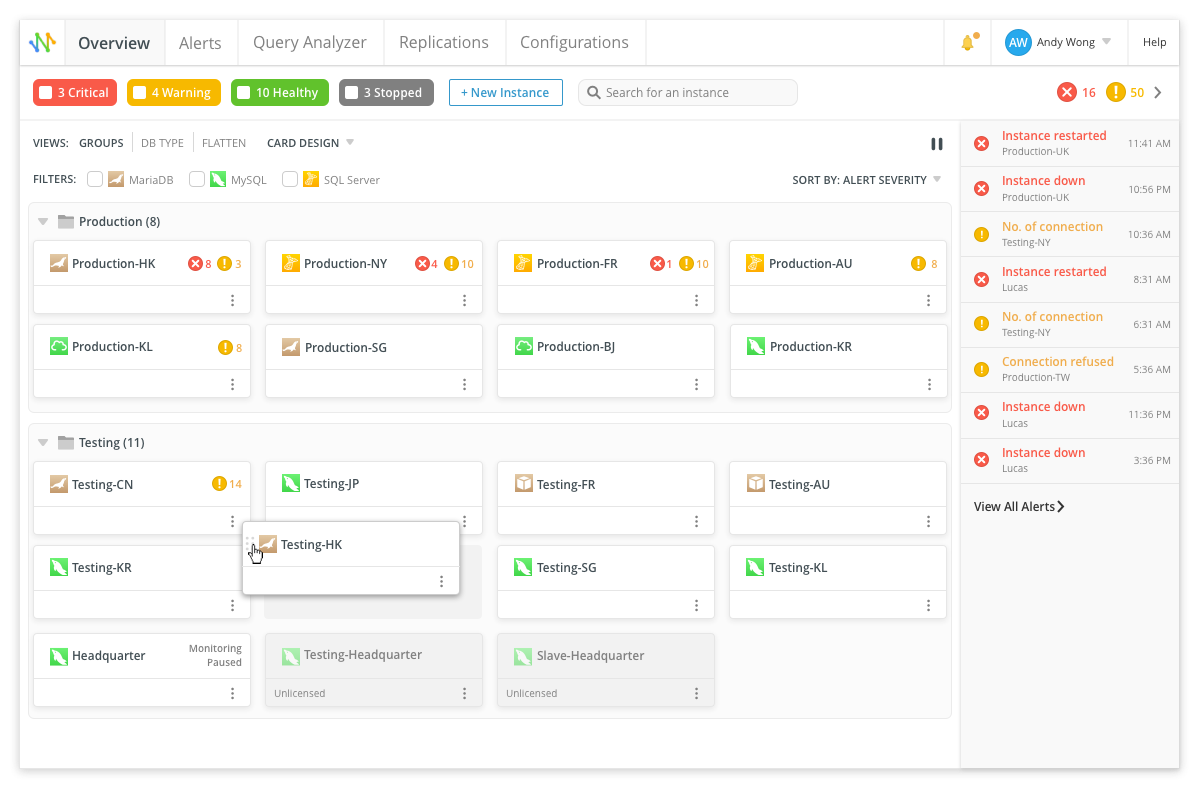
Компактный вид
Монитор отслеживает время выполнения конкретных запросов, запуская их с заданным интервалом.

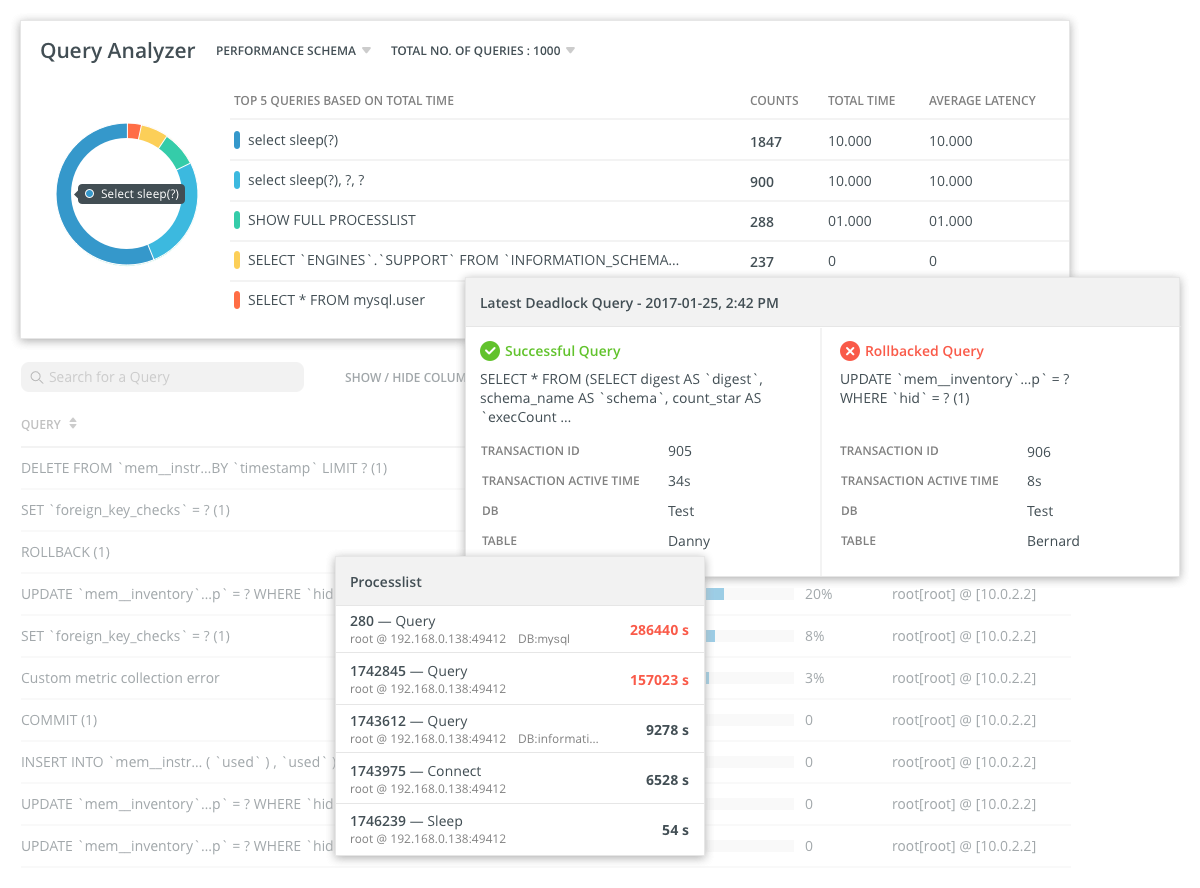
Кроме запросов к БД, периодически отправляются и другие запросы к серверам для мониторинга показателей производительности системы ввода-вывода, сети и проч. Собирается статистика по использованию CPU, загрузке памяти и другие стандартные метрики.
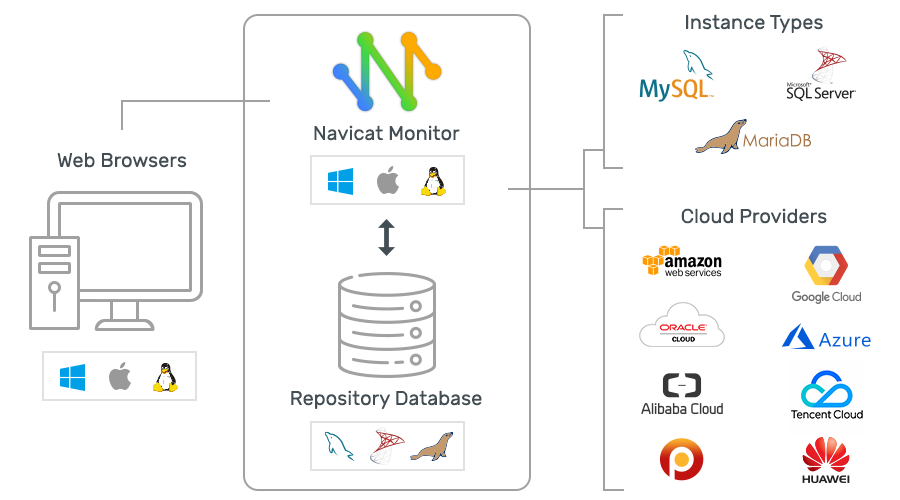
Архитектура Navicat Monitor не предусматривает установку программного обеспечения на объекты мониторинга
Минимальная цена Navicat Monitor — $32,99 за один токен в месяц (один токен соответствует мониторингу одного сервера или четырёх баз Azure). Есть полнофункциональная пробная версия на 14 дней.
Zabbix
Zabbix — это бесплатный опенсорсный инструмент, который отслеживает состояние сети, приложений и самого сервера. Поставляется с готовыми шаблонами для мониторинга популярных серверов и ОС, включая HP, IBM, Lenovo, Dell, Linux-серверы, Ubuntu и Solaris. За годы существования Zabbix сообщество подготовило шаблоны для различных сценариев.
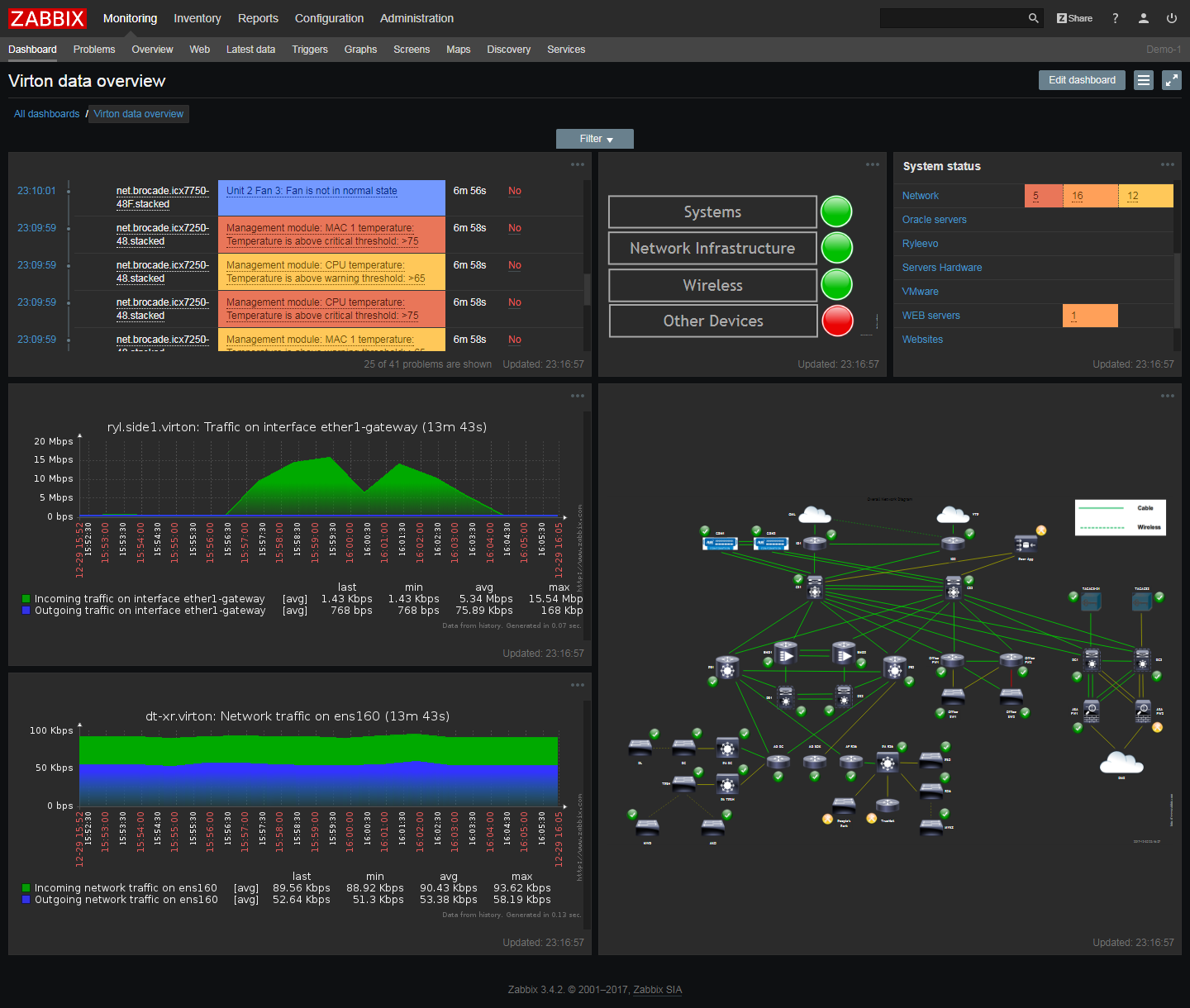
Ключевые модули Zabbix следят за нагрузкой CPU, использованием памяти, уровнем ошибок ввода-вывода, свободным местом на диске, статусе вентиляторов, температурой и характеристиками системы питания. Сетевой модуль проверяет трафик, доступность сети, уровень потерь пакетов, качество TCP-соединений и пропускную способность маршрутизаторов.
Zabbix ведёт список установленного программного обеспечения и версий прошивок, чтобы сигнализировать о несанкционированной установке ПО.

Системный администратор может запрограммировать в Zabbix уведомления по произвольным условиям, а также изменить важность действующих уведомлений. На панели управления можно добавить пользователей — и направлять каждому из них определённые типы уведомлений, а скрипты автоматизации позволяют автоматически заводить задачи и присваивать их сотрудникам.
Благодаря функции удалённого доступа и управления Zabbix можно назвать хорошим инструментом администрирования сервера.
Единственный недостаток этой системы — если вы для мониторинга добавлено около 1000 серверов или более, то из-за большого количества сообщений и процедур шифрования Zabbix начинает медленно реагировать на команды, так что для очень больших компаний этот инструмент не слишком подходит
Системы серверного мониторинга отличаются по функциональности. Не все могут следить за работоспособностью отдельных приложений, производительностью сервера и временем отклика. Но эти недостатки можно исправить с помощью дополнительных инструментов: например, систем аналитики и мониторинга логов.
Надёжный сервер в аренду и правильный выбор тарифного плана позволят меньше отвлекаться на неприятные уведомления мониторинга — всё будет работать без сбоев и с очень высоким uptime!

