Comments 214
Да, это ведь не диалект питона
библиотек готовых мало — _любая_ сишная библиотека цепляется напрямую, т.к. Nim через генерацию Си кода компилируется
Я не изучал Num, он перед компиляцией генерирует код на Си??? Тогда тем более, зачем он? Только для питонистов.
Ошибка один: он не медленнее плюсов — позиции 9 и 10
Ошибка два: ООП есть
Ошибка три: без питоновских библиотек. Ну или для тонких ценителей
И это только первый абзац.
Ошибка три: без питоновских библиотек.
По ссылкам не понятно, эти три библиотеки имеют какое-то отношение к питону вообще? Как я понимаю, здесь релевантна только четвёртая ссылка, которая на nimpy.
Эти три библиотеки реализуют то, для чего вообще в большинстве случаев используется питон (первое что в голову пришло): ML, матрицедробилки, работа с БД.
То есть для целей, для которых обычно используется питон, библиотеки есть. На самый худой конец — можно использовать и питон непосредственно.
Переход на другой язык существенно усложняется, если там нельзя прозрачно использовать пакеты из питона. В любом молодом языке не будет сразу такой же экосистемы — сюда и работа с редкими типами файлов/БД, и проверенные временем решения для всяких графиков, включая интерактив, и разнообразные свои/от коллег модули с готовыми вычислениями, и клиенты к куче веб-сервисов.
Если nimpy действительно нормально поддерживает питон, включая передачу произвольных типаов объектов, вызов callback'ов в разные стороны, графику, и всё это без кучи бойлерплейта — то кажется действительно адекватным решением. По их readme это не понятно, и тут в коментах писали что использование питоновских модулей в nim'е не поддерживается — отсюда и вопросы.
Простите, но я совсем не улавливаю ход мысли. Java или Ruby тоже без питоновских библиотек. Получается, они тоже не нужны?
Nimpy действительно нормально поддерживает питон. Но это, честно говоря, скорее решение для для очень специфических случаев; в первую очередь — для разработки dynamic libraries, без геморроя на C и без костылей в духе cython.
Это другой язык. У него другая экосистема. Для большей части задач уже есть свои библиотеки/решения со своей идеологией.
Если питона хватает, то не нужно искать что-то лучшее. Если не хватает, то его, к сожалению, надо корчевать под корень.
Java или Ruby тоже без питоновских библиотек. Получается, они тоже не нужны?
Не передёргивайте — ведь я такого совсем не писал:
Переход [с питона] на другой язык существенно усложняется, если там нельзя прозрачно использовать пакеты из питона.
Да, если в java/ruby полноценно нельзя использовать питоновские библиотеки (я не знаю, так это или нет), то это усложняет переход (а не использование вообще!) на них. Ну и java всё-таки особо не позиционируется как замена питону, у неё множество своих ниш.
Если питона хватает, то не нужно искать что-то лучшее. Если не хватает, то его, к сожалению, надо корчевать под корень.
Очень странный подход, по-моему. Зачем корчевать сразу под корень, если можно писать код на другом языке, который нравится/удобнее/быстрее/расширяемее/<подставить своё>, но при этом использовать некоторые библиотеки из питона, которым (пока) нет полноценного аналога? Вы же не предлагаете сишные библиотеки выкидывать, правильно?
Например, судя по первой странице гугла, в nim пока отсутствуют: нормальные биндинги для таких пакетов построения графиков, как matplotlib/vega/vegalite/altair; библиотеки для оптимизации функций (есть только nlopt); байесовская статистика вообще; библиотека астрономических функций; пакеты для дифуров; работа с файлами форматов fits, parquet; готовых решений для машинлёрнинга тоже не увидел. Как минимум часть из этого (в первую очередь, графики) спокойно можно использовать через питон.
Для большей части задач уже есть свои библиотеки/решения со своей идеологией.
Для «большой части задач» — возможно, со стороны сложно судить. Но для «большей» — явно пока нет, я даже несколько удивился что ничего по своему списку (см. выше) не нашёл.
- Построение графиков: https://ggplot2.tidyverse.org/index.html, https://github.com/numforge/monocle
- nlopt
- байесовская статистика: https://github.com/bluenote10/NimData https://github.com/unicredit/alea… но тут по-моему все сложно.
- работа с файлами форматов fits, parquet — тут по-моему проще сгенерировать обертку вокруг c++ библиотеки.
- ML — https://github.com/sinkingsugar/nimtorch
Остальное — сильно специфическое, чтобы у меня были шансы оценить наличие и качество.
Тут как бы надо понимать, что это очень нишевый язык. Ну очень. Такого многообразия как pip install half-of-project тут не будет в принципе, в первую очередь за счет количества образованных волонтеров. Как бы в плане статистики и python-то на фоне R блекловато смотрится (или смотрелся лет 5 назад, как сейчас не знаю, честно говоря). Но вообще, если у Вас есть сложившаяся экосистема, которая Вас устраивает — то, честно говоря, не вижу смысла что-либо менять. Опять же, пока что-то менять не придется.
P.S: А использование интеропа с питоном в реальной жизни будет очень-очень сильно тормозить… так что совсем не вариант.
ggplot2.tidyverse.org/index.html
Это библиотека на R, и не интерактивная.
github.com/numforge/monocle
Здесь даже автор пишет, что просто proof of concept — а никак не нормальный пакет.
nlopt
Я же его упомянул в предыдущем сообщении. nlopt — это весьма узкая часть сферы оптимизации.
тут по-моему проще сгенерировать обертку вокруг c++ библиотеки
Конечно, не стоит это писать на pure nim — так (почти?) ни в каком языке не делают. Но уж библиотеки на Си считать в экосистему нима никак нельзя. Я как раз и веду речь о том, что этого в готовом виде в ниме нет — и часто было бы удобно использовать питоновские пакеты. У них интерфейс удобнее, чем у исходных сишных, и для многих задач чтения файлов оверхеда от разового вызова питоновской функции не заметно.
ML — github.com/sinkingsugar/nimtorch
Torch покрывает, по сути, только диплёрнинг — это малый кусок ML. Я скорее имел в виду традиционные методы: всякие деревья, knn, kernel methods,… — в общем то, что в питоне живёт в sklearn/xgboost/т.п.
Тут как бы надо понимать, что это очень нишевый язык. Ну очень.
Видимо, дело в том, что данная и пара других статей про ним, которые я видел, не содержат этого утверждения. При его наличии и ожидания от языка были бы совсем другими.
Как бы в плане статистики и python-то на фоне R блекловато смотрится
Про R это вы хорошо упомянули! Да, в питоне реализовано значительно меньше статистических методов, чем в R. Но зато есть пакет, позволяющий почти прозрачно вызывать код на R!
Но вообще, если у Вас есть сложившаяся экосистема, которая Вас устраивает — то, честно говоря, не вижу смысла что-либо менять.
Меня в питоне давно разные вещи не устраивали, и когда пару лет назад вышла (стабильная) julia я достаточно быстро перешёл. Там как раз есть библиотеки для удобного вызова питона и R — так что во-первых сразу можно использовать имеющиеся пакеты, которым нет нативной замены, а во-вторых не переписывать без необходимости свои старые функции с вычислениями. Да, они будут не такими быстрыми, не такими общими (обычно работают только с float) — но зато есть и сразу!
P.S: А использование интеропа с питоном в реальной жизни будет очень-очень сильно тормозить… так что совсем не вариант.
Не знаю, какая такая «реальная жизнь», но например для графиков, разового чтения файлов, небольших вычислений оверхед одного вызова питоновской функции вообще незаметен.
Я, кажется, понял ваш юзкейз. Честно говоря, с таким желанием (подключать библиотеки на языке высокого уровня из языка низкого уровня) еще ни разу не сталкивался.
Периодически сам сталкиваюсь с необходимостью использовать что-то "чужеродное", (из последнего: https://github.com/readbeyond/aeneas ), но в подавляющем большинстве случаев обхожусь обертками над exec .
В принципе, как "язык верхнего уровня" по отношению к питону он, думаю, вам не подойдет. Это скорее инструмент "нижнего уровня" ([число|строко]дробилка, простая обертка над c-библиотекой для использования в питоне и т.д. ).
А с нативными математическими библиотеками даже у монстров типа c#/java туговато будет, что уж говорить о.
Честно говоря, с таким желанием (подключать библиотеки на языке высокого уровня из языка низкого уровня) еще ни разу не сталкивался.
То есть nim предполагается для низкоуровневого программирования типа системных программ, микроконтроллеров и т.п.?
Это скорее инструмент «нижнего уровня» ([число|строко]дробилка, простая обертка над c-библиотекой для использования в питоне и т.д. ).
Но ведь для числодробилок совершенно не требуется переходить на языки ниже уровнем [абстракции], чем питон. И тем более совершенно не хочется писать вычислительное ядро на одном языке, а удобный «интерфейс» его использования на другом.
А с нативными математическими библиотеками даже у монстров типа c#/java туговато будет, что уж говорить о.
Нативных в каком смысле? «Сделанных специально для <языка>?» — так сюда numpy & компания подходит. «Написанных почти полностью на <языке>?» — это про джулию, там по части пунктов математическая библиотека вообще лучшая, по части конкурентная с Си, по части [пока] несколько отстаёт или не полностью реализована нативно. При этом уж что-что, а «уровень» языка явно не ниже питона.
Про swift ещё что-то слышал в таком же духе, но детально не знаю. А C#/java из вашего примера не особо и метят в нишу вычислений и на замену питона, насколько я понимаю.
Проблема Жулии — счет с 1 (куча гемора из-за этого).
В общем ничего лучше — написал на Питоне, потом оптимизуй — нет.
Проблема Жулии — счет с 1 (куча гемора из-за этого).
Уже второй раз на хабре вижу это, и совершенно не могу понять почему кто-то так серьёзно относится к выбору первого индекса массива по дефолту. Хоть с 0 в питоне, хоть с 1 в джулии, никаких проблем не замечал. Часто если индексы при обращении важны, то удобнее их брать не 0:n-1, а например -n:n, и джулия в отличие от питона это легко позволяет сделать. Ну а обычно просто нужно что-то типа прохода по массиву — тогда индексы вообще не используются.
Конечно, недостатки у джулии как языка есть — не бывает ничего идеального — но странно записывать в них выбор дефолтного начала отсчёта индексов.
На самом деле неудобнее не то, что индексы с 1 (они часто несколько менее удобны, чем с 0), а то, что диапазоны включают обе границы. Это, в общем-то, ясно как из теоретических соображений, так и из практики
Правда я с железом на низком уровне не работаю — там, вероятно, действительно лучше с 0 начинать и интерпретировать как сдвиг указателя.
например отбросить последние 2 элемента a[:-2]
Вот уж что-то, а обозначение отступа с конца отрицательными значениями — явно неудобство питона, я не раз на этом попадался. В нём «a[x]» значит принципиально разные вещи в зависимости от знака x, лучше бы ошибку выдавало. В джулии отступ с конца идёт как «a[end — 2]», и такой неоднозначности нет.
21 век — тренд в сторону декларативного подхода даже не в «функциональных» языках, а у вас все примеры императивные.
Приведённый первым хелловорлд на питоне можно уместить в одну строку
print(*filter(lambda x: x[0] < 10 and x[0] * x[1] == 25, enumerate(nums)), )
Что там в Ним с функциональным программированием?
И с Фибоначчи, пример «плохого» алгоритма, у вас без ленивых вычислений, но с ограничениями и по рекурсии и по размерности результата.
Что там в Ним с функциональным программированием?
А что там с функциональным программированием у Python?
- присутствуют функции высших порядков
- хочешь чистые функции — пиши чистые функции
- обработка списков от list comprehension до map-filter-reduce (см. функции высших порядков)
- рекурсия (а где её нет, но это тоже одна из концепций функционального программирования)
- ленивые вычисления
- замыкания, каррирование и т.д. и т.п.
А почему примеры в этой статье должны быть обязательно в функциональном стиле? Чисто религиозные заморочки?
рекурсия
Без оптимизации хвостовой рекурсии
замыкания, каррирование и т.д. и т.п.
Где там "каррирование и т.д. и т.п." из коробки? Модуль functools что-ли с "reduce", "partial" и "lru_cache"?
Есть библиотека toolz там побольше всего. От фанатов для фанатов. С любовью.
Не должны, я просто спросил, «Что там в Ним с функциональным программированием». И посетовал, что нет совсем примеров в декларативном стиле (есть, кстати, sequtils, всяко лучше этот пример привести, чем бесконечный цикл в хелловорлде). Ну, неужели, надо всё по два раза повторять, чтобы исключить неверное толкование своих слов.
С примерами «всё плохо».
21 век — тренд в сторону декларативного подхода даже не в «функциональных» языках, а у вас все примеры императивные.
Вот это — это не вопросы, а явные утверждения. Причём похоже по форме на претензию. Да, писать так, чтобы исключить неверное толкование сложнее, чем может показаться :)
Ну а как же
def func(arg1):
def _func(arg2):
...
return _func
func('arg1')('arg2')
И вы ещё питоновские лямбды вспомните. Но они есть, уж как есть.
Это у вас результат преобразования, а где тут сама исходная функция func(arg1, arg2)?
Суть в том, чтобы получить из func(x, y) с помощью оператора каррирования func(x)(y). Такого из коробки нет.
— Вы, чего, и конфеты за меня есть будете?
— Ага!
И что вы хотите этим сказать? Вы ставите знак равенства между частичным применением (фиксацией аргументов) и каррированием?
Кстати, надо заметить, что functools.partial применима не всегда, что становится особенно актуальным с добавлением в язык positional only аргументов, доступных из python-кода. Зафиксировать можно либо позиционные аргументы слева-направо (leftmost), либо keyword-аргументы. Смотрите https://www.python.org/dev/peps/pep-0309/
Попробуйте сделать функцию pow2 (x^2) с помощью functools.partial из функции pow.
Хочется про тот же ним статью, но как-то с нормальными примерами, а не с бесконечным циклом в хелловорлде.
На nim-lang.org очень всё хорошо и полно. И, главное, там нет сравнения с питоном )
И не на одном, причём не все допилены.
Nim's memory management is deterministic and customizable with destructors and move semantics, inspired by C++ and Rust. It is well-suited for embedded, hard-realtime systems.При использовании GC это ложь.
Тем более, что тут же в оф.доке пишут честно про Soft realtime support
--gc:arc. Plain reference counting with move semantic optimizations, offers a shared heap. It offers deterministic performance for hard realtime systems. Reference cycles cause memory leaks, beware.Ждем обещанную в релизнотах статью с подробностями.
Например следующую функцию перенести в язык, где нету option/maybe (в каком-нибудь виде) невозможно по концептуальным причинам.
def f (x):
if x > 2:
return x
else:
return None
питон же не строго типизированный— строго, но динамически.
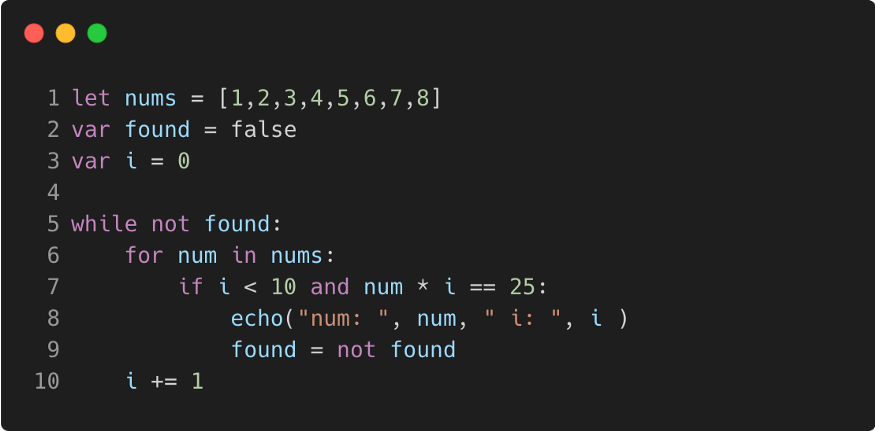
И раз уж такая пляска, вот моя реализация (далеко не идеальная, конечно) чисел Фибоначчи на питоне:
from time import time
def fibo(number):
if number < 3:
return 1
num1 = 1
num2 = 1
num3 = num1 + num2
counter = 3
while counter < number:
num1 = num2
num2 = num3
num3 = num1 + num2
counter += 1
return num3
start = time()
print(fibo(40))
print(time() - start)102334155
1.4066696166992188e-05 //секунд исполнялся кодПроводить бенчмарк на заведомо непроизводительной конструкции (рекурсия) — не очень показательно. Но даже в таком случае, поразительно, как 40-ое число могло считаться 37 (!) СЕКУНД. (у меня код из гитхаба проекта выполнялся 22 секунды на python3.7 AMD Ryzen 5 2600).
Суть моего комметария не показать, что язык плох или статья плохая, а что сравнивать производительность на такой специфичной (и редко используемой там, где нужна скорость) операции как минимум странно.
А то, echo — это вывод на экран(?), стало ясно только из текста.
Что не отменяет того, что так писать, конечно, не стоит.
Пока в nums нет дупликатов и found — это просто про умножение (а не про, например, взятие по модулю) это свойство (не больше одного совпадения во внутреннем цикле) не зависит от констант (и их можно произвольно менять).
Но да, если оставлять так, то нужно внимательно следить за условием (для произвольного условия good(num, i, 25) этот код не подходит).
Суть тут скорее в том, чтобы показать показать синтаксис, чем больше разных операций — тем лучше.
У Nim почти 10000 звезд на GitHubпочему-то мне кажется, что почти все звёзды оставили питонисты, наткнувшиеся на Nim в результате гуглёжки чего-то вроде «как ускорить Python», вздохнув после этого и вернувшись к Пайтону
Стоит ли переходить с Python на Nim ради производительности?
Нет, потому что питон используют не из-за производительности, ниши уже заняты, легаси останется навсегда и Nim никогда не взлетит, как и остальные нескучные языки общего назначения, и это понимает каждый кто писал хоть что-то кроме лаб в универе.
Хотя, все мы конечно понимаем что статья запощена ради возможности еще раз вбросить рекламы в конце поста, как и любая другая статья любого другого корпоративного блога тут.
Проект живой, библиотеки есть и новые пишутся. Если чего-то нет, то не сильно сложно подтянуть код с/с++. Для меня он прочно занял нишу домашних проектов. Зачем вам взлёт нужен?
Очень долго присматривался к Nim, даже пару игрух написал и пачку консольных тулзов/строкодробилок по мелочи.
Но тащить на прод в результате не решился.
Пайтон по скорости это конечно совсем ужас-ужас. Но повода переходить именно на это при наличии куда более жизнеспособных конкурентов (c#/go/Java) ни одного резона нет.
Хотя язык очень приятный в работе, да
Не особо согласен что резонов прямо уж нету:
c#/java не конкуренты — это гораздо более "энтерпрайз" решения — писать много и долго.
go — писать меньше, но не всех устраивает язык, с набором слов как у Эллочки из !2 стульев
А вот тут приходится выбирать, к сожалению — шашечки или ехать.
Для крупняка таки ничего лучшее кровавого энтерпрайза не придумали.
А вот если нужно что-то одноразовомелкое — тут уже или набор слов не важен (хотя сам не представляю, как на этом можно излагать мысли), или скорость работы не важна, или скорость разработки не важна. Но обычно ничего вообще не важно, кроме наличия чужой библиотеки, решающей 90% задач и наличия в радиусе 100км еще хотя бы одного специалиста по этой технологии. А с этим у нима таки серьезные проблемы: за 5 лет дело с мертвой точки не сдвинулось.
Относительно библиотек, у Нима всё очень неплохо, учитывая его "популярность", так как биндинги к C пишутся очень просто. А есть ещё и биндинги к питон и JS, но я просто не интересовался.
хочу сказать, что я действительно поторопился. быстренько прошелся по своему "вишлисту", и с библиотеками действительно очень неплохо. особенно если сравнивать с ~0.8, когда ситуация реально была где-то между "библиотеки нет" и "есть, но пользоваться в реальных задачах невозможно". надо вообще заценить что изменилось.
Кстати, в этом году обещают зарелизить Crystal 1.0 — пока про него никто в комментах не вспомнил.
Всё вообще не так.
Во-первых, руби это не только веб (ну да, проклятие Rails). Во-вторых, у Crystal синтаксис всё же отличается, поэтому gem'ы не скомпилятся без исправлений.
Зато у Crystal — всё лучшее от руби и при этом строгая типизация, компилируется в бинарник, по скорости сравнимо с C'шным кодом. Поддерживает и аналог goroutine (называется Fiber), и ядерные треды.
Фактически, везде, где Go применяется, там можно и Crystal применить.
c#/java не конкуренты — это гораздо более «энтерпрайз» решения — писать много и долго.Ну совсем необязательно так: и сами языки с возрастом приобретают в лаконичности и функциональности, и у обоих есть достаточно широкая экосистема, которая, что важно, поддерживается другими языками (и уж под JVM точно языки на любой вкус по лаконичности можно найти).
Не смотря на сомнительное качество статьи, поделюсь положительным впечатлением от Нима;
Nim встретил не так давно: решил попробовать что за язык и за 2-3часа написал функционал сервис, который до этого писал на расте около трёх недель. При этом я писал async-await на Nim впервые. Ещё больше удивление вызвало, когда этот наколенный код ел cpu в два раза меньше.
Многие скептически говорят про ним: "ещё один нескучный язык, который не несёт никакой идеи", это не совсем так, Ним во главу угла ставит именно удобство программирования, при этом интегрируя в себя многие идеи из других языков: Синтаксис — питоно-подобный, немного от паскаля, статическая типизация, концепты, async-await, сейчас он пытается избавиться от GC, в языке есть разделение на чистые и нечистые функции. Да, целиком нельзя назвать что-то ключевой особенностью языка кроме цели — быть удобным, как и питон, однако, в отличие от питона это очень производительное, и при этом статически типизируемое, при этом эти особенности не добавляют много оверхеда при написании.
Кстати — метапрограммирование — очень сильная сторона Нима.
В моей практике, в случае любого численного моделирования если алгоритм явно не ложится на то что уже есть в numpy, или ещё какую то библиотеку то всё становится медленным. Хорошо что многие алгоритмы паралелятся и их можно запусить на десятках цпу. На практите я естественно переписываю что либо очень редко. Иногда беру numba, иногда проще подождать дольше чем думать как это всё ускорять и переписывать.
а зачем?
ради риалтайма
вы часто упираетесь в производительность питона? любопытно, в каких задачах?
да в любых. из головы:
- сериализация в json (что-то типа 3мб в секунду против 100+ у newtonsoft)
- дичайший оверхед по памяти
- невозможность толком распараллелить работу из-за GIL
Конечно же, если нужна просто числодробилка, для которой хватает numpy, то претензий нет вообще. Но при чем здесь python?
Вдобавок: сборка python'овых контейнеров — это что-то с чем-то. node_modules — это прямо дистрофик по сравнению с site_packages.
— Ты сравнивал стандартную библиотеку питона с third-party фреймворком?
— Насколько все таки огромным был оверхед по памяти?
— Что за задачи такие, для которых не подходит multiprocessing?
- я все перепробовал (кроме ручной генерации по токенам/ записи в StringIO)
- на моих задачах (сравнивал с тем же C#) 3-4 раза. 12гб вместо 3 — это больно.
- плотно общающиеся друг с другом. Стандартный пример: несколько процессов пишут в очередь, много процессов очередь разгребают, один процесс собирает результаты в кучу. Тут или какие-нибудь IPC костыли, или никак.
P.S: я на питоне лет 8 "от звонка до звонка". язык люблю, знаю, все еще использую… иногда. Но производительность у него (за пределами нативных модулей) реально ужас-ужас.
- В основном за счёт борров-чекера в асинке, не говоря о проблема, например в связке с монгой
- Видимо хочется автоматического от, он и сейчас возможен, но надо прилагать руки
- Часто, как только начинают появляться критические части в самом питоне, за пределами нампи, например
вы часто упираетесь в производительность питона? любопытно, в каких задачах?
Очень часто. В любой вычислителной задаче напрямую питон применять нельзя, провал по скорости будет в тысячи раз. При этом питон — самый популярный язык для анализа данных, машинного обучения и нейросетей. Он даже используется для вычислительного моделирования
Парадокс?
Дело в том, что чистый питон никто не использует для этих целей. Используются фреймворки написанные на C (+CUDA) или фортране, которые предоставляют интерфейсы для тензорных операций (numpy, cupy, для нейросетей Chainer, pyTorch, Tensorflow). Вычислительный алгоритм нужно переработать в набор тензорных операций, тогда производительность будет сравнима с решениями на C. Но истинная боль начинается если вы не можете какие-то части представить в виде тензорных операций…
Это напоминает строительство дома из панельных блоков — пока вы хотите что-то стандартное, все идет легко, сделать что-то нестандартное можно только при помощи хаков и ухищрений.
Создатели Julia собирались решить эту проблему, чтобы было возможно комбинировать прямое итерирование по циклам например с высокоуровненвыми тензорными операциями.
В чём его проблемы?
Cython это урезанный си с питоно-подобным синтаксисом. Т.е. такая полу-мера.
Если ничего кроме питона не знаешь, и надо написать не много строчек, то сойдёт.
Для чего-то более сложного лучше взять полноценный язык, с нормальной поддержкой ide и всеми фичами этого языка. А для полу-мер сейчас есть numba jit, которая как и cython требует аннотировать часть типов, но при это остается чистый синтаксис питона.
Динамически типизированная с возможностью явно указать компилятору информацию о типах. Но все проверки всё равно будут в runtime. Указание типов позволяет сгенерировать более эффективный код и значительно ускорить работу программы, но никаких проверок до запуска программы не будет.
https://stackoverflow.com/questions/28078089/is-julia-dynamically-typed
Так-то можно написать типы ко всем переменным, запаковать программу в main() и смотреть @code_warntype main() на предмет невыведенных типов.
Соглашусь с ответом Карпинского здесь, что в рамках Julia максимум "статической типизации", что можно сделать — кидать предупреждения, если компилятор вывел гарантированный MethodError и, опционально, если в выведенных типах появляются большие Unionы или абстрактные типы.
Карпински вроде считает, что это можно сделать, но пока нет героя, кто за это бы взялся.
Я не особо хочу рассматривать цифры тестов из самой статьи, так как я писал, что качество под вопросом, но, по опыту, ним компилится в C, и, обычно, если надо очень сильно соптимизировать, то делается это уже смотря на C-шный код, соответственно оптимизация обычно заключается в поиске того где ним что-то сделал неоптимально, соответственно в 90% случаях что я видел или сама генерация из ним была +- на C уровне, или как минимум (при необходимости) оптимизировалась до C-шного варианта
Насчёт GC хотелось бы уточнить — конечно проводится много работы в сторону ARC/ORC, но дефолтным GC в будущем будем скорее всего ORC (ARC со сборщиком циклов). ARC сам по себе не является полноценным GC, это так. Просто немного неправильно звучит "избавиться от GC" :)
Так то GC — перерасход памяти, ARC — дорогой по сумме затрат, итп
Есть when defined (gcDestructors) — но это мало где нужно, в большинстве случаев никаких изменений не нужно, только если оптимизации именно для ARC (я про вещи типа sink/lent). И да, ARC — это automatic reference counting (ну и move semantics), это не atomic reference counting (некоторые путают с ARC в Swift)
С появлением LLVM расплодилось много языков. В чём фишка Nim я так и не понял.
Есть rust — там есть бороучекер и забавная система трейтов.
Есть Julia — там рекламируют какую-то полу динамическую типизацию с jit.
Про остальные толком никто мне на хабре пока не объяснил :)
Ним к llvm никаким боком.
github.com/arnetheduck/nlvm
Ну а в чём фишка-то. Убрали скобочки?
я ответил в другом коменте: https://habr.com/ru/company/vdsina/blog/512028/#comment_21877684
Джулия — язык для математики, другой профиль.
А в чём удобство? Не надо думать об управление памятью? Есть исключения? В чём отличие от java/c#?
А так есть все фичи для «удобства» написания программ — и автоматическое управление памятью, и исключения, и так далее, и всё быстро и удобно :)
Про теоркат и типы спишу на выпендрёж — слишком далеко от реальности.
Ну это как ваше доказательство алгоритма эвклида. Круто, но это скорее из серии придумал на листике а потом выразил в коде.
Важно знать что размерности векторов и матриц правильные, потому что эти операции часто довольно абстрактные. А вот конкретная формула из прикладной области — её не доказать правильная она или нет. Можно совершить опечатку при переписывании её с листика...
Да и вообще насколько хорошо можно что то доказывать про float числа? Выходят ли зав-типы за рамки дискретной математики?
Кстати что реально инетересно это доказательство корректонсти всяких интринзиков. Потому что если не писать SSE инструкции каждый день, то сделать ошибку легко, а компилятор там помогает как в си.
Фунты и килограммы это какой то фронтенд. В симуляциях должны быть безразмерные величины.
Да, упомянутые ошибки выдаются не до начала выполнения программы, а во время компиляции конкретной функции, или при её выполнении если зависят от конкретных значений. Но случайно проглотить их таки не получится.
Кстати, в математику ещё статистика/анализ данных входит — это тоже очень широко в джулии представлено.
А что там кодят в теоркате было бы интересно почитать на простом уровне :) Статью не планируете написать?
Это в смысле JIT'а? То есть, там либо остаются проверки на случай деоптимизации для других типов, либо там как-то что-то доказывается, что других типов там не может быть?
Для каждого места вызова каждой функции в коде компилятор выводит, какой тип она может вернуть. Это может быть Float64, Number, Union{Float64, Nothing}, Union{Int, Vector{Int}, Nothing}, Any,…. Потом компилятор переходит к следующему выражению, и так далее. Этот вывод всегда верный в том смысле, что вызов функции заведомо вернёт значение выведенного типа. Поэтому проверки после компиляции остаются если тип не конкретный: если выведено, что какое-то значение типа Union{Int, Nothing}, затем оно передаётся в другую функцию, то при выборе какой вариант этой функции вызывать (для Int или для Nothing) будет стоят if. Если выведено Any, то при его передаче куда-то будет динамический диспатч, и т.п. Можно вручную типы значений указывать — тогда будет во-первых дополнительная проверка (при компиляции или при выполнении — зависит от), а во-вторых после этого не будет динамического диспатча. Но вызываемая функция в любом случае всегда компилируется для конкретного типа.
Ну чем раньше они вылезают, тем лучше. В идеале — когда я код набираю, чтобы оно красненьким мне подсвечивало всякое неправильное.
Да, с этим я не спорю конечно.
Для библиотечного кода — про тип, возвращаемый даже простейшей функцией «f(a::T, b::T) = a + b», ничего нельзя сказать пока неизвестен T.
С сильно статически типизированными языками я особо не работал — только «игрушечные» вещи писал — не знаю как там обычно эти проблемы решаются.
data = JSON.read("file.json")
mean(data["field"])
то полностью статическую типизацию, вроде, не накрутить. И тут уж выбор создателей языка — либо мы перед вызовом mean требуем явно привести к конкретному типу, либо оставляем динамическую типизацию.
А каков тип +?
Зависит от типа аргументов — я могу сделать свой тип MyT и оператор MyT + MyT -> MyOtherT. Или даже возвращать значения разных типов в зависимости от значения: "+(x::MyT, y::MyT) = x == y? 0: 'a'". Для оператора + это выглядит странно, но с другими функциями часто полезно.
Даже если это множественный диспатч в стиле ad-hoc polymorphism (умное название для перегрузки функций) — рано или поздно в точке вызова функции её конкретный тип станет известен.
В точке вызова в момент вызова — да, конечно, функция именно тогда и компилируется. В точке вызова в момент компиляции — нет, см. пример с чтением файла.
Если хочется писать в духе
data = JSON.read("file.json") mean(data["field"])
то полностью статическую типизацию, вроде, не накрутить. И тут уж выбор создателей языка — либо мы перед вызовом mean требуем явно привести к конкретному типу, либо оставляем динамическую типизацию.
Ошибаетесь, это вполне возможно. На самом деле, если нам структура данных известна лишь частично, то мы может ровно эту степень знаний выразить в типах и использовать для этой части всеми преимуществами статической типизации, а для остальных данных оставить слабо структурированное представление. Собственно, вот пример кода выше на статически типизированном языке.
(Там весь код был, я просто ссылку поменял на рабочую).
И тут уж выбор создателей языка — либо мы перед вызовом mean требуем явно привести к конкретному типу, либо оставляем динамическую типизацию.
А именно, у вас явным образом в коде задаётся конкретный тип data.field:
struct Data {
field: Vec<f64>,Если брать чтение не из json, а из более богатых форматов, то там вместо вектора float64 может быть, к примеру, Set{BigFloat}, или весь объект data окажется ленивым DataFrame, где колонка field это что-то типа LazyVector{Int}. При этом 'mean(read(«data_file»).field)' продолжит работать — если тип файла поддерживается, конечно.
Я не утверждают, что это безусловно лучше статической типизации, но то, что в статике тут будет больше кода, показывает даже непосредственно ваш пример.
Кстати, mean из вашего кода работает только для массивов float64, как я понял — но здесь не уверен, приведено ли это просто для примера, или система типов rust'а ограничивает общность.
Если брать чтение не из json, а из более богатых форматов, то там вместо вектора float64 может быть, к примеру, Set{BigFloat}, или весь объект data окажется ленивым DataFrame, где колонка field это что-то типа LazyVector{Int}. При этом 'mean(read(«data_file»).field)' продолжит работать — если тип файла поддерживается, конечно.
Не совсем. Функция mean ожидает, что переданный ей аргумент — это нечто итерируемое, что выдаёт значения, которые можно складывать и делить, и на неверные данные в файле (если это ленивое чтение из файла) не выдаёт мусорные данные, а кидает исключение. Если эти ожидания нарушаются — функция падает в рантайме. Статическая типизация позволяет эти предположения выразить в проверяемой программой форме, и, вдобавок, заметить, когда эти предположения меняются, и соответствующим образом поменять код, который на эти предположения опирается.
Я не утверждают, что это безусловно лучше статической типизации, но то, что в статике тут будет больше кода, показывает даже непосредственно ваш пример.
По мере роста кодовой базы разница становится несущественной. Собственно, из дополнительного кода у меня только определение структуры с парой атрибутов, которое чётко выражает, в какой порции данных мы заинтересованы. Да и поле rest в примере для наглядности, можно убрать его (вместе с соответствующим выводом) и код продолжит работать.
Кстати, mean из вашего кода работает только для массивов float64, как я понял — но здесь не уверен, приведено ли это просто для примера, или система типов rust'а ограничивает общность.
Просто для примера, да, на Rust можно написать и обобщённую версию.
Функция mean ожидает, что переданный ей аргумент — это нечто итерируемое, что выдаёт значения, которые можно складывать и делить
Да, это почти так, в неплохом приближении.
Статическая типизация позволяет эти предположения выразить в проверяемой программой форме, и, вдобавок, заметить, когда эти предположения меняются, и соответствующим образом поменять код, который на эти предположения опирается.
Ну вот по вашему примеру не понятно, как тут помогает статическая типизация.
Можно сделать так, чтобы каждая функция явно накладывала ограничения типа «хочу что-то, что итерирует значения, которые можно складывать и умножать на число». Но языков, где это удобно сделано, я не видел (раст не знаю) — видимо, не всё так просто. При этом ведь ещё и перегрузка по этим признакам нужна: если дали плотный массив, а не просто итератор, то будем использовать simd.
Возможно, сам по себе факт статической типизации действительно позволяет не накладывать лишних ограничений на структуры данных. Но по факту тот код, что я видел в языках со статической типизацией, добавляет кучу ограничений. Вот кто-то, как вы в примере, пишет небольшую функцию mean — она принимает массив float64, и ничего больше туда не передать. Для получения общности нужно специально заморачиваться, скорее всего писать больше кода. В динамике же наоборот: по-умолчанию функция, определённая как 'mean(x) = sum(x) / length(x)' будет работать для всех значений, которые умеют считать свою сумму и длину. Большая часть функций пишется для конкретной цели, и в статике они скорее всего будут принимать или конкретный тип, или недостаточно общий шаблонный. Соответственно, в другой ситуации их использовать затруднительно/неоптимально.
Мне кажется, дело как раз в том, что в статике достаточно общие типы описывать просто громоздко.
По мере роста кодовой базы разница становится несущественной.
Вероятно, разница действительно уменьшается с ростом размера проекта. Но такие мелкие вещи — взять файл, посмотреть на его часть, идти дальше — часто встречаются в интерактивной работе, и очень не хочется каждый раз эти все структуры писать.
Как пример, который менее «вырожден» по сравнению с mean:
data = JSON.read("data.json")
plt.scatter(data.field_1, data.field_2)
нарисует график с точками field_1 vs field_2 независимо от того, числа там или строки.
Можно сделать так, чтобы каждая функция явно накладывала ограничения типа «хочу что-то, что итерирует значения, которые можно складывать и умножать на число». Но языков, где это удобно сделано, я не видел (раст не знаю) — видимо, не всё так просто.
Посмотрите на Haskell.
При этом ведь ещё и перегрузка по этим признакам нужна: если дали плотный массив, а не просто итератор, то будем использовать simd.
Во-первых, ничто не мешает подобные перегрузки специализации сделать и в языке со статической типизацией. Во-вторых, конкретно это я бы оставил на откуп Достаточно Умного(TM) компилятора, тем более что с типами такие оптимизации проводить куда проще.
В динамике же наоборот: по-умолчанию функция, определённая как 'mean(x) = sum(x) / length(x)' будет работать для всех значений, которые умеют считать свою сумму и длину.
Отнюдь, тут неявных предположений куда больше. Помимо того, что x — это что-то, с чем умеют работать sum и length, тут ещё есть неявное предположение, что на значениях, возвращаемых sum и length, определена операция деления, и что sum и length не меняют свои аргументы (так что если x является потоком данных из файла, то mean правильно работать не будет). А, ещё и то, что "типы" возвращаемых значений от вызова к вызову не меняются и не зависят от конкретных значений аргументов.
По мере роста кодовой базы разница становится несущественной.Вероятно, разница действительно уменьшается с ростом размера проекта. Но такие мелкие вещи — взять файл, посмотреть на его часть, идти дальше — часто встречаются в интерактивной работе, и очень не хочется каждый раз эти все структуры писать.
Так никто и не заставляет, можно же просто десериализовать в что-то такое и обрабатывать несуществующие поля по месту. Разумеется, в этом случае типизация помогает меньше в том смысле, что у нас нет гарантии наличия определённых полей, но мы всё равно знаем, что значение гарантированно является валидным представлением JSON-файла.
Как пример, который менее «вырожден» по сравнению с mean:
data = JSON.read("data.json") plt.scatter(data.field_1, data.field_2)
нарисует график с точками field_1 vs field_2 независимо от того, числа там или строки.И обрушится в рантайме, если там что-то другое. Нет, спасибо, я в своё время наелся pyplot, очень неудобно пользоваться из-за того, что хрен поймёшь, какие у функций сигнатуры.
я в своё время наелся pyplot, очень неудобно пользоваться из-за того, что хрен поймёшь, какие у функций сигнатуры.
Какую замену нашли?
Посмотрите на Haskell.
Смотрел, даже писал игрушечные проекты, разбирался и в абстракциях языка, и в библиотеках. Заложенные идеи мне весьма понравились, но всё-таки оставалось ощущение слишком «жёсткой» структуры при написании небольших программ.
Во-первых, ничто не мешает подобные перегрузки специализации сделать и в языке со статической типизацией. Во-вторых, конкретно это я бы оставил на откуп Достаточно Умного(TM) компилятора, тем более что с типами такие оптимизации проводить куда проще.
В принципе, ничего не мешает. Как я писал в предыдущем сообщении, недостаток общности в типичном статически типизированном коде — это, скорее, не фундаментальные ограничения языка или системы, а самый простой путь при написании. Поэтому бОльшая часть статически типизированного кода накладывает неоправданно жёсткие ограничения на аргументы.
Ну и оптимизации на компилятор перекладывать можно только относительно очень сильно ограниченных, преимущественно локальных, преобразований. Какой-нибудь mean к simd'у наверное соптимизируется, а вот наивное перемножение матриц явно недотянет до скорости blas'а независимо от компилятора.
… 'mean(x) = sum(x) / length(x)'...
Отнюдь, тут неявных предположений куда больше.
Неявных предположений действительно больше, но зато автоматом будет работать для кучи типов контейнеров. А предположений вообще явно меньше, чем в вашем варианте. Я же здесь сравниваю простейшую реализацию mean в вашем примере по ссылке (вероятно, многие программисты на условном rust напишут именно такой код, если им нужно находить среднее значение массивов из float64), и простейшую реализацию на julia как примере динамически типизированного языка (большинство людей напишут примерно такую реализацию, если им скажут что нужно усреднить массив float'ов). И здесь по количеству предположений на входные данные явно выигрывает второй вариант.
Конечно, это не самый общий случай, вы тут правильно подметили — я сравнил именно «решение по-умолчанию». Это согласуется с моим внутренним ощущением, как выглядит значительная часть кода на статически типизированных языках, и на динамических.
И обрушится в рантайме, если там что-то другое. Нет, спасибо, я в своё время наелся pyplot, очень неудобно пользоваться из-за того, что хрен поймёшь, какие у функций сигнатуры.
Вы так говорите «обрушится», как будто выдаст сегфолт как в С :) В большинстве случаев будут относительно разумные exception, типа размер не совпадает, или подали в качестве значений непонятную зверушку. Да, матплотлиб действительно не эталон идеального API и ошибок, но тут дело не в динамичности языка, а то что они изначально решили чересчур аггрессивно угадывать, что хотел пользователь. Если бы не это, то можно было бы выдавать более адекватные ошибки типов сразу при попытке вызова функции. Но если выбирать между текущим поведением и необходимость каждый раз вместо
data = JSON.read("data.json")
plt.scatter(data["field_1"], data["field_2"])писать что-то типа
data = JSON.read("data.json")
plt.scatter(data.as_float_array("field_1").unwrap(), data.field_2.as_int_array("field_1").unwrap())то я выбираю нынешний вариант.
Ну и матплотлиб написан на питоне, в котором множество недостатков, не вызванных напрямую динамической типизацией. Пользуюсь просто потому, что в нём можно быть уверенным, что в итоге график будет выглядеть ровно как задумывалось. Подстройка даже редких параметров отображения легко гуглится в силу популярности — с другими библиотеками нужного результата не всегда получалось добиться.
Ну и оптимизации на компилятор перекладывать можно только относительно очень сильно ограниченных, преимущественно локальных, преобразований. Какой-нибудь mean к simd'у наверное соптимизируется, а вот наивное перемножение матриц явно недотянет до скорости blas'а независимо от компилятора.
Безусловно, но даже это будет работать быстрее, чем массивы в динамически типизированных языках, которые гетерогенные без дополнительных телодвижений.
Неявных предположений действительно больше, но зато автоматом будет работать для кучи типов контейнеров.
Опять-таки, это лишь пример. Ничто не мешает мне написать что-то вроде
fn mean<I>(values: I) -> f64
where
I: IntoIterator<Item = f64>,
I::IntoIter: ExactSizeIterator,
{
let values = values.into_iter();
let len = values.len();
values.sum::<f64>() / len as f64
}— примерно тот же код, что и для вашего варианта. И это будет замечательно работать с массивами и множествами. А если не пытаться вычислять длину заранее, то мы можем считать количество элементов на лету и отказаться от ограничения ExactSizeIterator.
Вы так говорите «обрушится», как будто выдаст сегфолт как в С :) В большинстве случаев будут относительно разумные exception, типа размер не совпадает, или подали в качестве значений непонятную зверушку.
Или не будет. У меня вот знакомый жаловался на бажный код:
if inputs.get_shape().ndims == 2:
result = tf.matmul(inputs, weight)
else:
reshaped_inputs = tf.reshape(inputs, [-1, input_dim])
result = tf.matmul(reshaped_inputs, weight)
result = tf.reshape(result, tf.pack(tf.unpack(tf.shape(inputs))[:-1] + [output_dim]))
if biases:
result = tf.nn.bias_add(
result,
lib.param(
name + '.b',
np.zeros((output_dim,), dtype='float32')
)
)
return resultГоворит, что смог поймать баг только тогда, когда начал выписывать размерности промежуточных тензоров, и сетовал на недостаток статического анализа, который бы помог найти ошибку гораздо быстрее.
Ну и, разумеется, обнаружения несоответствия типов срабатывает только в том случае, если их, собственно, проверяют. Если аргументы просто разбирают и прокидывают дальше, то ошибка о несоответствии типов может всплыть совсем не там, где она изначальна была внесена. Особенно это "полезно", когда вместо нужного типа оказывается какой-нибудь None — сиди теперь и думай, где ты передал, скажем, коллбек, мутирующий аргумент, вместо коллбека, который должен возвращать новое значение.
Но если выбирать между текущим поведением и необходимость каждый раз вместо
data = JSON.read("data.json") plt.scatter(data["field_1"], data["field_2"])
писать что-то типа
data = JSON.read("data.json") plt.scatter(data.as_float_array("field_1").unwrap(), data.field_2.as_int_array("field_1").unwrap())
то я выбираю нынешний вариант.
Эта разница сильно заметна только на таких вырожденных примерах. Вдобавок, ничто не мешает проверить типы нужных полей ровно один раз и потом пользоваться данными, не рискуя напороться на исключение каждый раз при обращении к данным (в том числе и из-за опечатки в имени поля).
Ничто не мешает мне написать что-то вроде <...> — примерно тот же код, что и для вашего варианта.
Серьёзно, «примерно тот же код» :)? Здесь явно требуется бОльшее знание раста, чем в изначальной вашей реализации, которую я сразу понял. При этом ограничение на float осталось.
Ну и в расте нет (по крайней мере раньше не было) перегрузок функций. То есть эффективные методы а-ля mean(Multiset), mean(AggregateStatistics), mean(ArrayWithCachedSum), mean(RandomDistribution) не добавить — а ведь из таких вещей и складывается переиспользование/расширяемость библиотек.
Глобально у меня такое ощущение, что вы во многом путаете свойства динамической типизации и характеристики её конкретной реализации (питона). Это аналогично тому, что мы возьмём джаву (no offense) и будем считать её преимущества/недостатки присущими статический типизации вообще.
Пара примеров этого:
Во-вторых, конкретно это я бы оставил на откуп Достаточно Умного(TM) компилятора, тем более что с типами такие оптимизации проводить куда проще.
Безусловно, но даже это будет работать быстрее, чем массивы в динамически типизированных языках, которые гетерогенные без дополнительных телодвижений.
Производительность и статичность/динамичность типизации особо не связаны друг с другом. То, что конкретные типы аргументов аргументов функции становятся известны только непосредственно перед её запуском, никак не мешает её скомпилировать с нужными оптимизациями в это время. При этом (после компиляции всех нужных вариантов функций) оверхед абсолютно нулевой: исполняется такой же машинный код, что был бы при компиляции «заранее».
В большинстве случаев будут относительно разумные exception, ...
Или не будет.
…
Ну и, разумеется, обнаружения несоответствия типов срабатывает только в том случае, если их, собственно, проверяют. Если аргументы просто разбирают и прокидывают дальше, то ошибка о несоответствии типов может всплыть совсем не там, где она изначальна была внесена.
Так если никакого эксепшена не выдалось, значит не было проверки типов вообще, ни статической, ни динамической. С массивами во всяких numpy/theano/… достаточно много всяких попыток угадать, что же хочет пользователь — мне тоже не очень нравится, но это сознательное решение создателей библиотеки и типизация тут ни при чём. Уверен, что на условном C++ с шаблонами (и на более богатых языках) тоже можно написать библиотеку массивов так, что функции будут принимать массивы почти любого размера и пытаться согласовать их друг с другом. В таком случае никаких ошибок не будет и окажется тот же неожиданный результат.
Вообще же я абсолютно не против проверки типов до запуска — при прочих равных с ней бесспорно лучше. Конкретно в джулии, например, можно реализовать некую промежуточную опциональную проверку типов: когда в какую-то функцию подаётся аргумент конкретного типа, пусть проверяется и компилируется сразу и эта функция, и все вызываемые из неё. Если нашлось место, где не согласуются типы или вызывается несуществующий метод — сразу давать ошибку. Если типы не получилось полностью вывести и где-то оказался «Any» — выдавать ворнинг. Основная часть этой машинерии уже есть, ведь компилятор и так делает ровно эти действия, просто не сразу для всех вызываемых далее функций. Возможно, когда-нибудь и реализуют такое — но я отлично понимаю авторов, у которых это не в приоритете.
Числодробилки? Ну, мне хочется типами гарантировать, что мои вычисления имеют смысл, и я не складываю случайно килограммы с фунтами, и тут, судя по тому, что я видел, джулия тоже не в топе.
Unitful.jl — и складывайте килограммы хоть с фунтами, хоть с каратами, лишь бы не с джоулями.
В числодробилках с плавающей точкой обычно другое волнует, в первую очередь — что задача в ходе преобразований не потеряет устойчивость или обусловленность. Проблема в том, что теоремы об ограниченности решения и т.д., доказанные в действительных числах, при переносе на числа с плавающей точкой не обязательно сохраняют силу, и тут более изощрённая типизация вряд ли поможет.
Есть, например, такое. Или есть такое
Т.е. это какие-то символьные вычисления на хаскеле? В которые потом подставляются числа?
Кстати, в джулии из такого есть: развитые пакеты для точной интервальной арифметики, включая гарантированный поиск корней/экстремумов; целая экосистема автоматического дифференцирования; ну и разные варианты uncertainty propagation тоже, конечно. Причём это всё добро применимо к более-менее любому джулия-коду.
Я напарывался на случаи, когда «ой, тут матрица была транспонированная, надо было по строкам идти, чтобы получить значения одной фичи», равно как и на «чёрт, PCA забыл, вот бы было круто это в типах выразить…»
Ну на этом уровне да, может быть полезно. Хотя вопрос, не придётся ли потом всю выстроенную систему типов перелопачивать, если вдруг вместо транспонирования и PCA встанет что-то другое, хотя с уровнем описания AbstractMatrix ничего особо и трогать бы не пришлось. (ну да, утешение — что с типами достаточно умный компилятор хоть подскажет, где оно сломалось).
Есть, например, такое. Или есть такое — вот прям ровно для анализа неопределённостей.
Как я понимаю, в подобных вещах опять же используются свойства "правильных" действительных чисел, т.е. они дают одинаковые оценки погрешности для алгебраически эквивалентных выражений. Но с плавающей точкой это будет не совсем так.
А вообще, я имел в виду несколько другое, в стиле автоматического вывода области входных данных, при которых алгоритм не потеряет устойчивость из-за ошибок округления. Ну если уж от типов хотеть гарантий, что вычисления имеют смысл.
Язык без библиотек, имхо, мертв.
Вот с этим кстати всё прекрасно. Дружит с любой C-библиотекой буквально после пары телодвижений.
Вообще, для разработки питоновских модулей очень неплохой вариант.
-d:release, то у меня получается ускорение в 6 раз. Не совсем понятно, почему автор для бэнчмарка использует debug версию.А с
--gc:arc ускорение в 9 раз, время тоже что и у си версии.Nim чувствителен только к регистру первого символа.
То есть, HelloWorld и helloWorld он различает, а helloWorld, helloworld и hello_world — нет.
Неожиданный подход, интересно зачем?
Это описано в оффициально документации: для первого варианта удобно различать имя типа и переменной, когда как во втором это имя переменных, просто в разных case
Позволяет использовать библиотеку в snake_case в camelCase проекте сохраняя стиль написания даже для библиотечных символов. Да, фича довольно необычная, но почему нет?
Пример с числами Фиббоначи не нагляден — работать просто целыми числами примерно одинаково просто на языках как высокого, так и низкого уровня. Вот привели бы вы пример работы со строками и структурами данных — разница была бы гораздо заметнее. Например, "посчитать количество разных слов в файле".
Макросы и метапрограммирование в Nim — одна из очень сильных сторон языка. Увы, в статье про это одно упоминание вскользь и абсолютно ненаглядный пример.
Некоторое время назад пробовал Nim и был сильно разочарован тем, что для него нет нормального отладчика. Можно вооружиться шаманским бубном и попытаться использовать универсальный LDB, но посмотреть значения переменных во время остановки программы нельзя: Nim транслируется в Си, и уже Си компилируется в бинарник, и сгенерировать правильные отладочные символы абсолютно нетривиальная задача. На мой взгляд, это сильно срезает поток потенциальных пользователей языка.
import tables, os, strutils
var words = initCountTable[string]()
for word in readFile(paramStr(1)).split():
words.inc(word)
echo wordsfrom collections import Counter
import sys
words = Counter()
with open(sys.argv[1],'r') as f:
for line in f:
words.update(line.split())
print(words) Средний результат на гигабайтном файле с русской художественной литературой:
NIM NIM(GC:ARC) PYTHON
real 0m20.575s real 0m16.782s real 0m37.684s
user 0m17.600s user 0m13.735s user 0m34.921s
sys 0m1.063s sys 0m1.083s sys 0m0.967s
Стандартная утилита wc:
real 0m16.413s
user 0m16.273s
sys 0m0.114s
Хотя она просто считает кол-во слов, а не ведёт подсчёт каждого. Но время почему-то одинаковое.
UPD: Выше для nim посоветовали -d:danger
real 0m12.107s
user 0m11.518s
sys 0m0.555s
См. github.com/yakkomajuri/fibonacci-benchmark/issues/1 насчёт бенчмарка и forum.nim-lang.org/t/6577 для мнения от другого человека :)
1) определение типа
2) определение блока
3) установление значений
А это не смущает?
Nim чувствителен только к регистру первого символа.
То есть, HelloWorld и helloWorld он различает, а helloWorld, helloworld и hello_world — нет.
Зачем так делать вообще?
Предложите разумные варианты применения этой фичи.
Я пока нахожу только неразумные, которые позволяют писать неподдерживаемый код, усложняющий жизнь разработчикам, статическим анализаторам и любому автоматическому и полуавтоматическому инструментарию для работы с кодом.
И о чём мне должны сказать эти два слова? Вернее, что вы хотите сказать этим? Раскройте мысль чуть более подробно, покажите реальный пример, как бы вы использовали столь интересную особенность языка в своём коде.
Мне когда-то приходилось иметь дело с кодом, в котором происходило преобразование полей вида fooBar в foo_bar, но всё это делалось на уровне ключей словарей или при динамическом построении объектов, для согласования API, создания фасадов и т. п.
Я представляю, как бы дико выглядел кейс, в котором есть некая библиотека, у которой сущности именуются в lowerCamelCase, а кто-то у себя в коде работает с ней через snake_case, потому что ему так удобнее, потому что code style и потому что язык это позволяет, так почему бы и нет чёрт возьми. :)
Эта статья (оригинал) довольно низкого качества. Плохие бенчмарки, никакого углубления в тему.
Вот эта статья, на мой взгляд, даёт гораздо более полное представление о том, что такое Nim.
всё же Nim это не cython, не pypy и не mypy и в нишу языков для обслуживания питона не стремится, хотя статья про питон.
Вы упомянули юпитер ноутбук, он конечно не только для питона, но в основном. Как там, например, дела у раста с юпитером?
… вы будете тратить гораздо больше времени на написание и отладку своего кода на C, он будет громоздким и менее читабельным. И именно поэтому C уже не так востребован, а Python популярен.
Ну подумаешь, в 60 раз разница в производительности, зато более читабельный… Ха-ха-ха.
Странно, что не слышно воя питонистов об ошибках с количеством пробелов в отступах. Это довольно большая мина в языке.
Это не мина. Ну разве что с древними кривыми редакторами, но такое сейчас ещё поискать надо.
А вот что существенно — это проблемы поиска границ блоков. Можно, конечно, говорить, что функции длиннее 20 строк это зло, но случай бывает разный. А с {} оно решается простейшими методами.
Популярность таких языков говорит лишь о деградациии среднего уровня программистов по больнице. 97% общей массы не понимаю, как работать с С/С++ указателями и что это такое. Для этой серой массы и придумали эрзац-язык Питон.
Если только ме-е-е-дленные эстонские роботы ))
Конечно, после завершения таска все причесывали.
deleted
Стоит ли переходить с Python на Nim ради производительности?