Comments 56
По их подсчетам, на каждый потраченный доллар (а стоимость процессора составляет $1995) пользователь получит производительность в 4 раза.
Бессмыслица какая-то.
Кроме того, на графиках интеловские процессоры сравниваются в неким Falkor. Какое он имеет отношение к рассматриваемому Qualcomm Centriq 2400 вообще не понятно.
blog.cloudflare.com/arm-takes-wing
Centriq это название процессора — Falkor это архитектура или название версии. Так же как и Skylake у интела. Автор почему-то про это не написал. Тоесть Falkor на графиках это и есть Centriq.
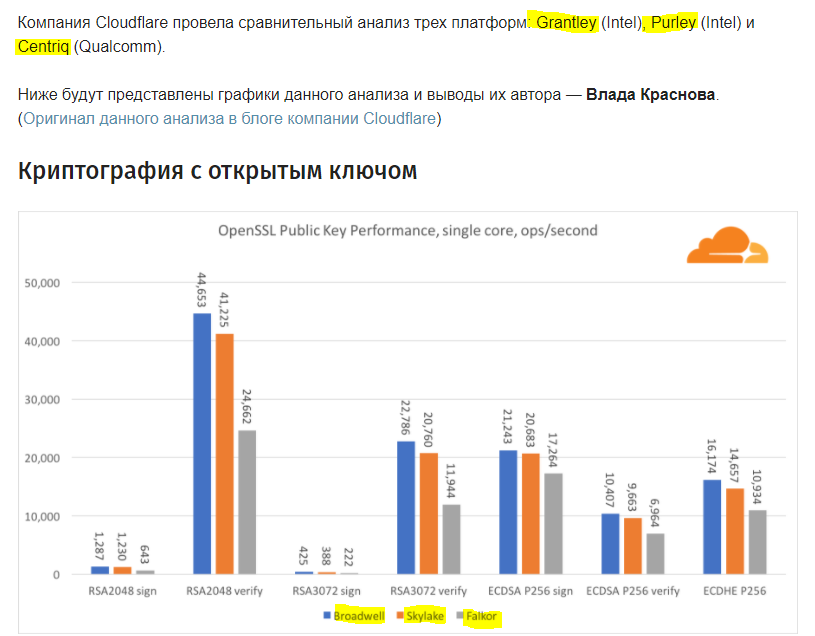
Пока что выглядит не очень, если честно. Даже на графиках (которые тоже не очень понятны, где там быстрее всех и лучше).
Думаю тут все будет упираться в цену продукта и потом ДЦ посчитают каждый для себя, что ему выгоднее ставить.
Если производительность будет даже просто на том же уровне при той же цене, то уже за счет меньшего энергопотребления и соответственно меньшие расходы обсулживание, то уже имеет смысл.
Если реально проще и дешевле будет платить за электричество хотя бы, то никто этим заниматься не будет. И не забываем про контракты, которые предусматривают всякие вот такие вот моменты. Нельзя так просто взять и перейти к новому поставщику железа, потому что так захотелось.
Без вопросов. Когда есть выбор и новый игрок на рынке железа, это приведёт к переставновке сил и цены поползут вниз. Но для того чтобы это случилось, то что показали в прессрелизе, маловато будет для революции на таком уже устоявшемся рынке. :)
Сначала все о Centriq 2400, а потом лихо появляется какой-то Фалкор)
Производственная версия Centriq SoC будет содержать 48 Falkor ядер,— в самом конце мы узнаем что это так микроархитектура ядер(?) называется (вроде как есть Pentium 4 а есть ядра NetBurst)
Со слов про Влада Краснова начинается blog.cloudflare.com/arm-takes-wing. Причем пропущено начало поста Влада где объяснение терминов.
www.anandtech.com/show/10158/the-intel-xeon-e5-v4-review/2
Ой, это же Интел породил. Ну тогда это гениальное произведение инженерного исскуства!
К слову задержки межядерного обмена при grid-топологии у Skylake-X выше, хотя и равномернее.
forum.ixbt.com/topic.cgi?id=8:25158:4965#4965
Cavium Thunderx2 можно использовать в двухпроцессорных нодах, плюс он поддерживает больше памяти.
Но как бы не приключилась та же история, как с Cavuim… Объявили год назад, внятного плана отгрузки до сих пор нет.
У нас уже почти год готовы серверы по Cavium Thunderx2:
2U 4x нодовый сервер,
1U двухпроцессорный сервер.
OpenPower9 тоже выглядит неплохо. В феврале приедет пара нод, будем тестить.
Минус 40% трат на электричество.
Плюс 9000% трат на замену оборудования, адаптацию существующего и написание нового софта под него, поддержку нестандартного решения.
Вот когда они все свои сервера на свои процессоры переведут, тогда и поговорим :)
Модифицируемость микрокода обновлениями серьезно ограничена.
Есть описание AMD K8 — основной микрокод зашит в ROM, обновления попадают в небольшую RAM. Патчи микрокода могут изменить лишь 8 адресов ROM (т.е. пропатчить микрокод/"отбросить ненужные" можно только для очень ограниченного числа команд): https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-koppe.pdf стр 6 Figure 1
По интелу — обновления микрокода имеют размер до 16 КБ https://www.dcddcc.com/docs/2014_paper_microcode.pdf (стр 16) и, вероятно, также являются лишь частичными патчами для ROM-микрокода.
Также следует помнить, что большинство простых операций декодируются без микрокода, аппаратными декодерами (3-4 шт), т.е. "конвертер" вшит физически. (https://www.dcddcc.com/docs/2014_paper_microcode.pdf — Simple instructions are directly decoded into a short sequence of fixed-length RISC-like operations… by hardware, whereas complex instructions are decoded by microcode ROM. Examples of the former include ADD, XOR, and JMP, while the latter include MOVS, REP, and CPUID.; http://www.agner.org/optimize/ http://www.agner.org/optimize/instruction_tables.pdf ops<=3, μops<=3 вероятно directly decoded аппаратурой)
Ведь тогда и никакого случайного исполнения критического кода бы не было и производительность была бы выше, т.к. процессор не пытался бы угадать что исполнять тратя на это ресурсы и угадывая криво, а исполнял бы заранее заданные ветки.
Да и сложность программирования бы не выросла. Статический анализатор вполне способ понять, каокй код будет выполняться чаще и расставить соответствующие метки.
Плюс и сейчас программист пищущий важный код должен учитывать особенности работа кэша и спекулятивного исполнения, вместо того, чтобы просто указать что исполнять чаще.
stackoverflow.com/questions/14332848/intel-x86-0x2e-0x3e-prefix-branch-prediction-actually-used?lq=1
Который подальше, или который поближе?
0F 18 / 81 RETIRET0 m8 Mark data from m8 as evictable from T0 to T1,T2,RAM
0F 18 / 02 PREFETCHT1 m8 Move data from m8 closer to processor using T1 hint
0F 18 / 82 RETIRET1 m8 Mark data from m8 as evictable from T0,T1 to T2,RAM
0F 18 / 03 PREFETCHT1 m8 Move data from m8 closer to processor using T2 hint
0F 18 / 83 RETIRET1 m8 Mark data from m8 as evictable from T0,T1,T2 to RAM
К сожалению, замечаю тенденцию, когда людям надо бы что по-проще, в том числе в области программирования.
Пусть лучше где-то там (махнув рукой в сторону железа) будет сложно.
Пока соотношение — не очень. Не взлетает.
Процессор-пионер Qualcomm Centriq 2400. Убийца Intel?