Comments 68
Статья хорошая, надо обвести в рамочку но 80 утилит требуют классификации и какого-то быстрого поиска. Не знаю, например сделать то самое web-application с тегами, рубрикатором и функцией search.
Недавно обсуждали на hackernews, если не ошибаюсь, http://netdata.firehol.org
NetData (https://github.com/firehol/netdata). Тоже очень занятная штукенция
Есть еще Icinga, в отличие от Nagios от которого он берет начало активнейше развивается, но поддерживает его плагины.
Про icinga вообще мало слышно, хотя проект на самом деле очень хороший. Может кто-то хочет попробывать, я в прошлом году сделал контейнер для второй версии с графиками, веб мордой, ad, в общем со совсем фаршем(тут)
icinga2 — совершенно прекраснейшая вещь.
Быстрая, очень гибкая, но…
графики идут, как приблуда сверху. То есть, вы не получите аналитики, не узнаете отклонений от «обычного» поведения. Мне это не нужно(вернее, у меня нет на это ресурсов) — потому ок.
icinga2 активно разрабатывается — есть высокий риск получить падение программы в неожиданной ситуации.
Впрочем, при должном внимании — это легко решаемо, а при расследовании еще и становится понятно — «как не надо делать».
Важный минус — в веб-интерфейсе нет отчёта по SLA.
Через sql, конечно, можно всё, но кому-то будет минусом.
резюмируя: если бы сейчас я выбирал бы мониторинг — я бы несколько раз подумал в сторону более менеджероориентированных решений.
мимоходом посматриваю на influxdb/opentsdb.
С другой стороны, я не уверен, что они удержат 1500к проверок минуту на одном процессорном ядре.
Icinga скрипит, но держит.
Правда, пару недель назад я не успел оптимизировать часть проверок и потому теперь у меня 2 ядра на исингу))
Быстрая, очень гибкая, но…
графики идут, как приблуда сверху. То есть, вы не получите аналитики, не узнаете отклонений от «обычного» поведения. Мне это не нужно(вернее, у меня нет на это ресурсов) — потому ок.
icinga2 активно разрабатывается — есть высокий риск получить падение программы в неожиданной ситуации.
Впрочем, при должном внимании — это легко решаемо, а при расследовании еще и становится понятно — «как не надо делать».
Важный минус — в веб-интерфейсе нет отчёта по SLA.
Через sql, конечно, можно всё, но кому-то будет минусом.
резюмируя: если бы сейчас я выбирал бы мониторинг — я бы несколько раз подумал в сторону более менеджероориентированных решений.
мимоходом посматриваю на influxdb/opentsdb.
С другой стороны, я не уверен, что они удержат 1500к проверок минуту на одном процессорном ядре.
Icinga скрипит, но держит.
Правда, пару недель назад я не успел оптимизировать часть проверок и потому теперь у меня 2 ядра на исингу))
Graphite — собирает что приходит, отображает. у себя поднял — днсы в него данные кидают
остальное можно netcat'ом засунуть.
остальное можно netcat'ом засунуть.
Да кто ж спорит-то? В icinga можно даже настроить, чтобы данные в графит отправлялись на другой хост.
Я хотел сказать, что с одной стороны — icinga — очень быстрый мониторинг — именно за счёт отсутствия лишних функций.
С другой стороны — как только эти самые «лишние» функции вам становятся нужны — вы должны их сами.
В иных решениях некоторые aggerated/manager-специфичные вещи идут из коробки.
Это то, на что я хотел обратить внимание.
Я хотел сказать, что с одной стороны — icinga — очень быстрый мониторинг — именно за счёт отсутствия лишних функций.
С другой стороны — как только эти самые «лишние» функции вам становятся нужны — вы должны их сами.
В иных решениях некоторые aggerated/manager-специфичные вещи идут из коробки.
Это то, на что я хотел обратить внимание.
а как настроить чтобы данные об хостах/сервисах из бд брались? я возился, так и не осилил. Мне надо дать доступ к настройке но чтобы не надо было текстовые конфиги как в нагиосе править?
и кстати, как в графит данные отправлять?
и кстати, как в графит данные отправлять?
данные в графит отправить — graphite_writer или как-то так.
По документации гуглится легко — шлёт все perf данные в графит.
настраивай по api — я лично не пробовал, но возможность такая есть.
У меня небольшая специфика — хосты часто добавляются/удаляются.
Мониторинг _пока_ вне этого процесса — просто раз в несколько часов запрашиваю список хостовз Б по api… Это даёт много боли — icinga может упасть, если на хосте стоял даунтайм, а его внезапно удалили.
В следующей версии этот баг пофиксят, а работа по API решит все проблемы сразу.
По поводу хостов/сервисов из БД — у меня такая специфика — куча хостов в digitaocean и vcale
Я написал 2 скрипта для каждого провайдера, которые берут список хостов и генерируют конфиг в /etc/icinga2/conf.d/${provider}.conf
а потом ребутают мониторинг.
Это не очень правильное решение, но для меня оно работает.
если бы я делал это сейчас с нуля — я бы тоже самое сделал через API icinga.
Про сервисы — кажется там всё просто — на основе переменных у хоста — применяем сервисы.
В общем, опиши в личку специфику — глядишь что и посоветую.
По документации гуглится легко — шлёт все perf данные в графит.
настраивай по api — я лично не пробовал, но возможность такая есть.
У меня небольшая специфика — хосты часто добавляются/удаляются.
Мониторинг _пока_ вне этого процесса — просто раз в несколько часов запрашиваю список хостовз Б по api… Это даёт много боли — icinga может упасть, если на хосте стоял даунтайм, а его внезапно удалили.
В следующей версии этот баг пофиксят, а работа по API решит все проблемы сразу.
По поводу хостов/сервисов из БД — у меня такая специфика — куча хостов в digitaocean и vcale
Я написал 2 скрипта для каждого провайдера, которые берут список хостов и генерируют конфиг в /etc/icinga2/conf.d/${provider}.conf
а потом ребутают мониторинг.
Это не очень правильное решение, но для меня оно работает.
если бы я делал это сейчас с нуля — я бы тоже самое сделал через API icinga.
Про сервисы — кажется там всё просто — на основе переменных у хоста — применяем сервисы.
В общем, опиши в личку специфику — глядишь что и посоветую.
В «Log monitoring tools» можно еще добавить logstalgia — утилита которая визуализирует логи apache в реальном времени.
А как же утилиты мониторинга whoami и pwd?
Если ifconfig — средство мониторинга, то почему whoami нет?
Если ifconfig — средство мониторинга, то почему whoami нет?
dtrace для Linux не существует.
Graphite не хватает, по-моему.
и Grafana к нему
curl'ом бы в неё научиться данные добавлять — netcat не везде есть возможность поставить.
А ещё я с формулами не могу разобраться, чтобы рисовалось относительное значение прироста, а не сам прирост в 90 градсной диаграмме
А ещё я с формулами не могу разобраться, чтобы рисовалось относительное значение прироста, а не сам прирост в 90 градсной диаграмме
Странно что есть apachetop, но забыт [url=https://github.com/lebinh/ngxtop]ngxtop[/url]. Иногда помогает :)
невнимательность мой враг :( ngxtop
Для os aix существует topas встроенная утилита.
Есть ли для линукса утилиты разгона?
Как-то ставил для изучения Ubuntu, но столкнулся с проблемой, что процессор и видеокарта почти всегда работали на максимальных частотах. Хотя в Виндовсе я понизил частоту ГПУ с 850 до 51Мгц через MSI Afterburner. Хватает даже для фотошопа
Я бы NetXMS еще добавил.
Труд хороший, но бесполезный — кому надо и так знает, а кто не знает — не поможет.
Лучше бы расписали — в каких случаях какая утилита поможет, имхо, ес-но.
Лучше бы расписали — в каких случаях какая утилита поможет, имхо, ес-но.
Есть еще такая интересная софтина http://riemann.io/ — поверх collectd
«newrelic.com» не будет лишний в этом списке. Ставится в качестве демона, раз в N минут шлет логи на свой сервер, и рисует там красивые графики:
Правда на бесплатном аккаунте доступны логи лишь за 1 сутки, но зато есть возможности уведомлений если начинается оверлоад или место заканчивается. В общем — это один из фломастеров, который, возможно, будет полезен.
Screenshot

Правда на бесплатном аккаунте доступны логи лишь за 1 сутки, но зато есть возможности уведомлений если начинается оверлоад или место заканчивается. В общем — это один из фломастеров, который, возможно, будет полезен.
WebMin не ахти решение, помимо того что он часто изменяет свой конфиг прибивая etckeeper, так у него ещё и свой взгляд на то как должны выглядеть конфиги других программ, что практически ограничивает их настройку за пределами последнего…
Перлоподелие было годным тогда, когда альтернатив не было.
Сейчас есть гораздо более красивые «управлялки» — Ajenti, например, лично пользовал, проникся.
Правда, я сейчас на рельсах пишу свою панель управления хостингом приложений кластерным, так что я из всех этих plesk/cpanel/vesta/ajenti/webmin идеи собираю в копилочку
Сейчас есть гораздо более красивые «управлялки» — Ajenti, например, лично пользовал, проникся.
Правда, я сейчас на рельсах пишу свою панель управления хостингом приложений кластерным, так что я из всех этих plesk/cpanel/vesta/ajenti/webmin идеи собираю в копилочку
Отличная статья, о многих инструментах даже не знал)
Но так как список большой, надо бы как-то систематизировать, и полное описание со скринами можно под спойлеры чпрятать, будет вообще сказка.
Но так как список большой, надо бы как-то систематизировать, и полное описание со скринами можно под спойлеры чпрятать, будет вообще сказка.
Есть еще argus.tcp4me.com
Использую его для мониторинга доступности хостов по ping. Так же может проверять доступность портов. Простая в использовании штука с очень простым веб-интерфейсом.
Использую его для мониторинга доступности хостов по ping. Так же может проверять доступность портов. Простая в использовании штука с очень простым веб-интерфейсом.
Точней говоря, RRDTool — кольцевая база (плюс утилиты) с периодом дискретизации 1сек и более, а Munin — система мониторинга с плагинами на базе RRDTool. Если надо мониторить что-то с периодом 100мс, то rrdtool уже не годится :(
sngrep забыли
А мне нравится PRTG.
Забыли добавить сюда Sensu, который вообще может всё при наличии прямых рук и его богатый репозиторий плагинов (https://github.com/sensu-plugins) выручает почти всегда. Особенно если эту радость сдружить с Graphite и выводить всё по красоте
pgtop — PostgreSQL performance monitoring tool akin to top
еще есть https://prometheus.io/ http://demo.robustperception.io:9090/consoles/index.html
Про traceroute написали, а про tcptraceroute нет. Хотя утилита может быть очень полезна
1. Приятно было бы пользоваться список со ссылками в самом начале поста
2. По своему опыту, положил бы рядом все утилиты из пакета sysstat
2. По своему опыту, положил бы рядом все утилиты из пакета sysstat
Как сюда попал cpulimit?
Не пугайте людей — скриншот от OpenNMS просто ужасно древний :)
Уже давно она весьма симпатична на морду лица и всё столь же беспощадна в настройке.
Уже давно она весьма симпатична на морду лица и всё столь же беспощадна в настройке.
Люди часто недооценивают htop. У него помимо дефолтных сенсоров, есть ещё пару десятков других, которые по умолчанию он не показывает. Например, htop вполне умеет показывать использование диска, и в битах в секунду и в операциях в секунду.
Отличная статья :)
Список безусловно большой, вот только непонятно как это всё использовать. Свели бы всё в какую-нибудь общую таблицу по всем параметрам.
Ну и из насущного, может посоветуете что-то для анализа трафа для VDS на debian, чтобы с графикой, красиво, не сильно отягощал и без большого количества зависимостей при установке.
Ну и из насущного, может посоветуете что-то для анализа трафа для VDS на debian, чтобы с графикой, красиво, не сильно отягощал и без большого количества зависимостей при установке.
Сначала хотел просить «Что за шрифт в терминале с „htop“?», но когда увидел „зоопарк“ скриншотов — передумал.
А если по делу, то забыли про замечательную утилиту „trafshow“ для мониторинга трафика по интерфейсам и нетолько, отечественная разработка вышедшая из недр Новосибирского провайдера „АО Ринет“ «RISP Telecome»
А если по делу, то забыли про замечательную утилиту „trafshow“ для мониторинга трафика по интерфейсам и нетолько, отечественная разработка вышедшая из недр Новосибирского провайдера „АО Ринет“ «RISP Telecome»
Кажется, вы добавилив мой «любимый» арсенал пару команд ) Спасибо
Для мониторинга сети еще можно добавить tcptrack и slurm.
За incron огромное спасибо, не знал! Надеюсь, можно будет выкинуть баш-скрипт из системы, заменив его этой программой.
apache2ctl status / apachectl show fullstatus не в списке :(
Я df -h обычно использую в паре с ncdu, показывает статистику использования диска файлами и папками.
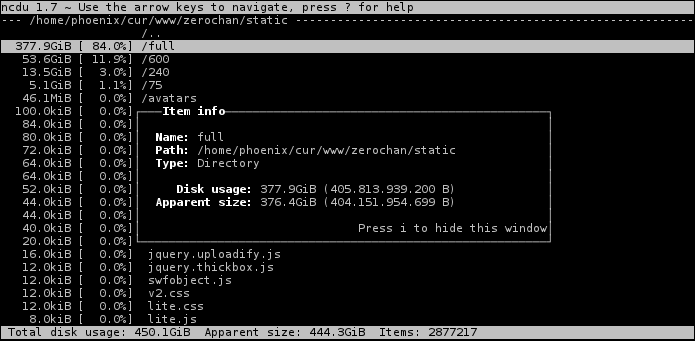
По ссылке выше доступны ещё альтернативы.

По ссылке выше доступны ещё альтернативы.
Ещё можно посмотреть в сторону ATSD (time-series database). Представляет мощный инструмент для сбора и анализа данных, есть бесплатная версия. Можно отсылать данные с тех же nmon, vmstat и прочьих утилит.
Из плюшек — агрегация практически любого типа данных, прогнозы, масштабируемость (работает на стеке hadoop-hbase)
Из плюшек — агрегация практически любого типа данных, прогнозы, масштабируемость (работает на стеке hadoop-hbase)
Sign up to leave a comment.
Более чем 80 средств мониторинга системы Linux