Бойтесь операций, buffers приносящих…
На примере небольшого запроса рассмотрим некоторые универсальные подходы к оптимизации запросов на PostgreSQL. Пользоваться ими или нет — выбирать вам, но знать о них стоит.
В каких-то последующих версиях PG ситуация может измениться с «поумнением» планировщика, но для 9.4/9.6 она выглядит примерно одинаково, как примеры тут.
Возьму вполне реальный запрос:
Посмотрим на получившийся план:
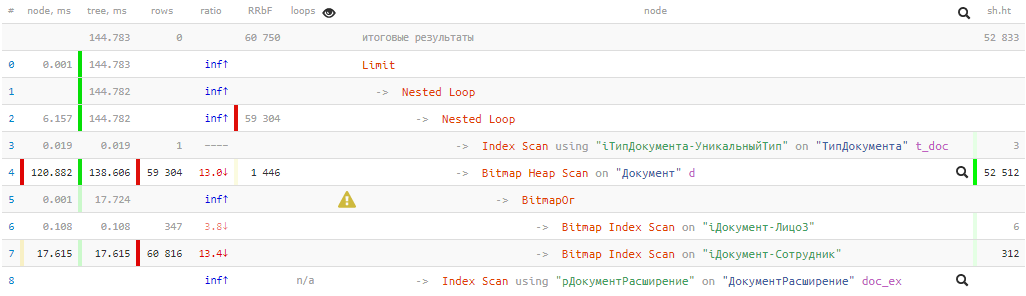
[посмотреть на explain.tensor.ru]
144ms и почти 53K buffers — то есть больше 400MB данных! И нам повезет, если все они окажутся в кэше к моменту нашего запроса, иначе он станет в разы дольше при вычитывании с диска.
Чтобы как-то оптимизировать любой запрос, надо сначала понять, что же он вообще должен делать.
Оставим пока за рамками этой статьи разработку самой структуры БД, и договоримся, что мы можем относительно «дешево» переписать запрос и/или накатить на базу какие-то нужные нам индексы.
Итак, запрос:
— проверяет существование хоть какого-то документа
— в нужном нам состоянии и определенного типа
— где автором или исполнителем является нужный нам сотрудник
Достаточно часто разработчику проще написать запрос, где сначала делается соединение большого количества таблиц, а потом из всего этого множества остается одна-единственная запись. Но проще для разработчика — не значит эффективнее для БД.
В нашем случае таблиц было всего 3 — а какой эффект…
Давайте для начала избавимся от соединения с таблицей «ТипДокумента», а заодно подскажем базе, что у запись типа у нас уникальна (мы-то это знаем, а вот планировщик пока не догадывается):
Да, если таблица/CTE состоит из единственного поля единственной же записи, то в PG можно писать даже так, вместо
В некоторых случаях Bitmap Heap Scan будет стоить нам очень дорого — например, в нашей ситуации, когда достаточно много записей подпадает под требуемое условие. Получили мы его из-за OR-условия, превратившегося в BitmapOr-операцию в плане.
Вернемся к исходной задаче — надо найти запись, соответствующую любому из условий — то есть незачем искать все 59K записей по обоим условиям. Есть способ отработать одно условие, а ко второму перейти только когда по первому ничего не нашлось. Нам поможет такая конструкция:
«Внешний» LIMIT 1 гарантирует, что поиск завершится при нахождении первой же записи. И если она найдется уже в первом блоке, выполнение второго осуществляться не будет (never executed в плане).
В исходном запросе есть крайне неудобный момент — проверка состояния по связанной таблице «ДокументРасширение». Независимо от истинности остальных условий в выражении (например, d.«Удален» IS NOT TRUE), это соединение выполняется всегда и «стоит ресурсов». Больше или меньше их будет потрачено — зависит от объема этой таблицы.
Но можно модифицировать запрос так, чтобы поиск связанной записи происходил бы только когда это действительно необходимо:
Раз из связываемой таблицы нам не нужно для результата ни одно из полей, то мы имеем возможность превратить JOIN в условие по подзапросу.
Оставим индексируемые поля «за скобками» CASE, простые условия от записи вносим в WHEN-блок — и теперь «тяжелый» запрос выполняется только при переходе в THEN.
Собираем результирующий запрос со всеми описанными выше механиками:
Наметанный глаз заметил, что индексируемые условия в подблоках UNION чуть разнятся — это потому, что у нас уже есть подходящие индексы на таблице. А если бы их не было — то стоило бы создать: Документ(Лицо3, ТипДокумента) и Документ(ТипДокумента, Сотрудник).
Что в плане?

[посмотреть на explain.tensor.ru]
К сожалению, нам не повезло, и в первом UNION-блоке ничего не нашлось, поэтому второй все-таки пошел на выполнение. Но даже при этом — всего 0.037ms и 11 buffers!
Мы ускорили запрос и сократили «прокачку» данных в памяти в несколько тысяч раз, воспользовавшись достаточно простыми методиками — неплохой результат при небольшой копипасте. :)
На примере небольшого запроса рассмотрим некоторые универсальные подходы к оптимизации запросов на PostgreSQL. Пользоваться ими или нет — выбирать вам, но знать о них стоит.
В каких-то последующих версиях PG ситуация может измениться с «поумнением» планировщика, но для 9.4/9.6 она выглядит примерно одинаково, как примеры тут.
Возьму вполне реальный запрос:
SELECT
TRUE
FROM
"Документ" d
INNER JOIN
"ДокументРасширение" doc_ex
USING("@Документ")
INNER JOIN
"ТипДокумента" t_doc ON
t_doc."@ТипДокумента" = d."ТипДокумента"
WHERE
(d."Лицо3" = 19091 or d."Сотрудник" = 19091) AND
d."$Черновик" IS NULL AND
d."Удален" IS NOT TRUE AND
doc_ex."Состояние"[1] IS TRUE AND
t_doc."ТипДокумента" = 'ПланРабот'
LIMIT 1;про имена таблиц и полей
К «русским» названиям полей и таблиц можно относиться по-разному, но это дело вкуса. Поскольку у нас в «Тензоре» нет разработчиков-иностранцев, а PostgreSQL позволяет нам давать названия хоть иероглифами, если они заключены в кавычки, то мы предпочитаем именовать объекты однозначно-понятно, чтобы не возникало разночтений.
Посмотрим на получившийся план:
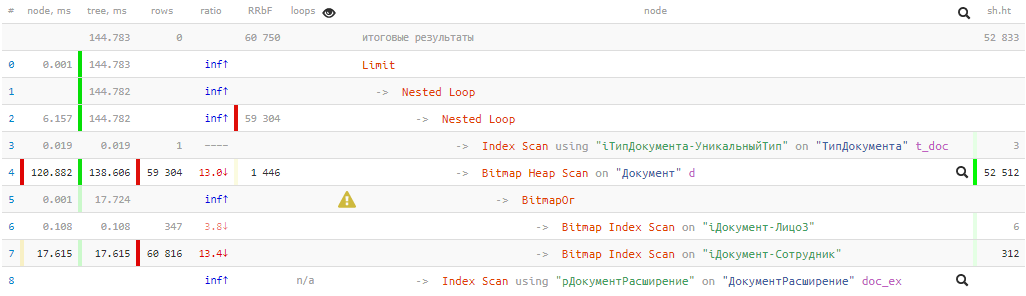
[посмотреть на explain.tensor.ru]
144ms и почти 53K buffers — то есть больше 400MB данных! И нам повезет, если все они окажутся в кэше к моменту нашего запроса, иначе он станет в разы дольше при вычитывании с диска.
Алгоритм важнее всего!
Чтобы как-то оптимизировать любой запрос, надо сначала понять, что же он вообще должен делать.
Оставим пока за рамками этой статьи разработку самой структуры БД, и договоримся, что мы можем относительно «дешево» переписать запрос и/или накатить на базу какие-то нужные нам индексы.
Итак, запрос:
— проверяет существование хоть какого-то документа
— в нужном нам состоянии и определенного типа
— где автором или исполнителем является нужный нам сотрудник
JOIN + LIMIT 1
Достаточно часто разработчику проще написать запрос, где сначала делается соединение большого количества таблиц, а потом из всего этого множества остается одна-единственная запись. Но проще для разработчика — не значит эффективнее для БД.
В нашем случае таблиц было всего 3 — а какой эффект…
Давайте для начала избавимся от соединения с таблицей «ТипДокумента», а заодно подскажем базе, что у запись типа у нас уникальна (мы-то это знаем, а вот планировщик пока не догадывается):
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
LIMIT 1
)
...
WHERE
d."ТипДокумента" = (TABLE T)
...Да, если таблица/CTE состоит из единственного поля единственной же записи, то в PG можно писать даже так, вместо
d."ТипДокумента" = (SELECT "@ТипДокумента" FROM T LIMIT 1)«Ленивые» вычисления в запросах PostgreSQL
BitmapOr vs UNION
В некоторых случаях Bitmap Heap Scan будет стоить нам очень дорого — например, в нашей ситуации, когда достаточно много записей подпадает под требуемое условие. Получили мы его из-за OR-условия, превратившегося в BitmapOr-операцию в плане.
Вернемся к исходной задаче — надо найти запись, соответствующую любому из условий — то есть незачем искать все 59K записей по обоим условиям. Есть способ отработать одно условие, а ко второму перейти только когда по первому ничего не нашлось. Нам поможет такая конструкция:
(
SELECT
...
LIMIT 1
)
UNION ALL
(
SELECT
...
LIMIT 1
)
LIMIT 1«Внешний» LIMIT 1 гарантирует, что поиск завершится при нахождении первой же записи. И если она найдется уже в первом блоке, выполнение второго осуществляться не будет (never executed в плане).
«Прячем под CASE» сложные условия
В исходном запросе есть крайне неудобный момент — проверка состояния по связанной таблице «ДокументРасширение». Независимо от истинности остальных условий в выражении (например, d.«Удален» IS NOT TRUE), это соединение выполняется всегда и «стоит ресурсов». Больше или меньше их будет потрачено — зависит от объема этой таблицы.
Но можно модифицировать запрос так, чтобы поиск связанной записи происходил бы только когда это действительно необходимо:
SELECT
...
FROM
"Документ" d
WHERE
... /*index cond*/ AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
ENDРаз из связываемой таблицы нам не нужно для результата ни одно из полей, то мы имеем возможность превратить JOIN в условие по подзапросу.
Оставим индексируемые поля «за скобками» CASE, простые условия от записи вносим в WHEN-блок — и теперь «тяжелый» запрос выполняется только при переходе в THEN.
Моя фамилия «Итого»
Собираем результирующий запрос со всеми описанными выше механиками:
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
)
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("Лицо3", "ТипДокумента") = (19091, (TABLE T)) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
UNION ALL
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("ТипДокумента", "Сотрудник") = ((TABLE T), 19091) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
LIMIT 1;Подгоняем [под] индексы
Наметанный глаз заметил, что индексируемые условия в подблоках UNION чуть разнятся — это потому, что у нас уже есть подходящие индексы на таблице. А если бы их не было — то стоило бы создать: Документ(Лицо3, ТипДокумента) и Документ(ТипДокумента, Сотрудник).
о порядке полей в ROW-условиях
С точки зрения планировщика, конечно, можно написать и (A, B) = (constA, constB), и (B, A) = (constB, constA). Но при записи в порядке следования полей в индексе, такой запрос просто удобнее потом отлаживать.
Что в плане?
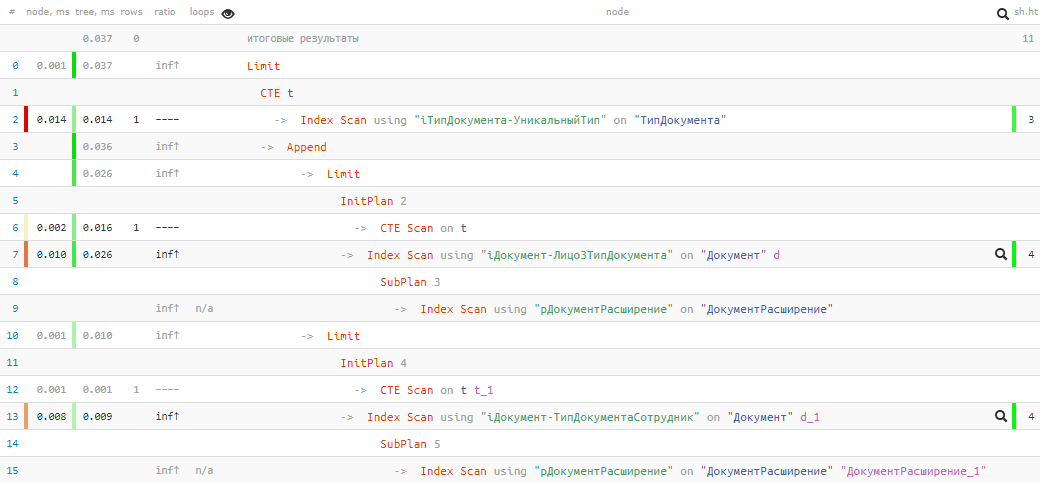
[посмотреть на explain.tensor.ru]
К сожалению, нам не повезло, и в первом UNION-блоке ничего не нашлось, поэтому второй все-таки пошел на выполнение. Но даже при этом — всего 0.037ms и 11 buffers!
Мы ускорили запрос и сократили «прокачку» данных в памяти в несколько тысяч раз, воспользовавшись достаточно простыми методиками — неплохой результат при небольшой копипасте. :)
