
Облака удобны своей гибкостью. Нужен мощный вычислительный кластер на восемь часов: арендовал в три клика, выполнил задачу и потушил машины. К сожалению, многие просто неверно понимают идеологию облачных ресурсов и часто разочаровываются, когда видят счета в конце месяца.
Чтобы оптимизировать затраты, нужно начать со сбора хорошей статистики. Я попробую вкратце описать подходящие для этого инструменты.
Ключевой принцип экономии — выключать всё ненужное и минимизировать резерв, насколько это возможно. Отвыкайте мыслить в парадигме локального сервера в инфраструктуре компании. Если сможете автоматизировать расширение и выключение облачных ресурсов в зависимости от нагрузки — ещё лучше.
Рассмотрим ситуации, когда выгоднее фиксированные тарифы, а когда — pay-as-you-go-концепция (PAYG). Плюс рассмотрим, что можно выключить лишнего, и где чаще всего впустую расходуются ресурсы. Пройдёмся по основным видам ресурсов: CPU, RAM, виртуальным дискам, сети и бэкапам.
Собираем информацию
Перед тем как совершать какие-то действия по оптимизации, надо для начала понять, как вообще нагружается ваша машина. Поэтому наиболее правильно начать с систем мониторинга, чтобы точно понимать характер нагрузки. Причём анализировать нагрузку следует в разных масштабах. Усреднённые данные за месяц будут полезны для понимания степени резервирования или нехватки ресурсов в целом. Также вы сможете спрогнозировать примерные сроки, когда текущей мощности перестанет хватать, если нагрузки постепенно растут. Данные за несколько дней смогут показать суточные колебания, обычно связанные с жизненным циклом часовых поясов, и резкие одиночные всплески, когда ресурсы оказываются в дефиците.
Чем мониторить
На выбор — огромное количество систем сбора и визуализации информации, но я хотел бы обратить внимание на ключевые:
- Zabbix — старый добрый швейцарский нож в системах мониторинга. Графики бедные и страшноватые, на мой вкус.
- Kibana — часть стека ELK. Подойдёт не для любого типа данных, но часто позволяет делать очень сложные визуализации, включая картографические.
- Grafana — очень гибкий инструмент, который позволяет интуитивно понятно сформировать красивые информационные панели. Мне кажется, что он наиболее разнообразен в плане различных типов графиков.
- Собственные панели вендора облака. Про них часто забывают, но часто они могут предоставить вам уникальную низкоуровневую картину потребления ресурсов вашими машинами.
Как оптимизировать тариф
Облако само по себе призвано экономить деньги, но также можно оптимизировать затраты, правильно потребляя облачные ресурсы. Оцените равномерность загрузки ваших машин. Если виртуальная машина стабильно загружена, то всё хорошо, и наиболее выгодным будет тариф с фиксированными лимитами и небольшим запасом мощности.

Во время пиковой нагрузки было задействовано только одно ядро. Можно сэкономить и не брать два.

Можно взять два ядра вместо четырёх без потери производительности.
Если больше 10 % времени ВМ простаивает, то нужно попробовать пересчитать на PAYG-модель. Только при этом машина должна быть выключена, когда не используется. Например, раз в сутки включается нода, компилирует проект и выключается обратно.
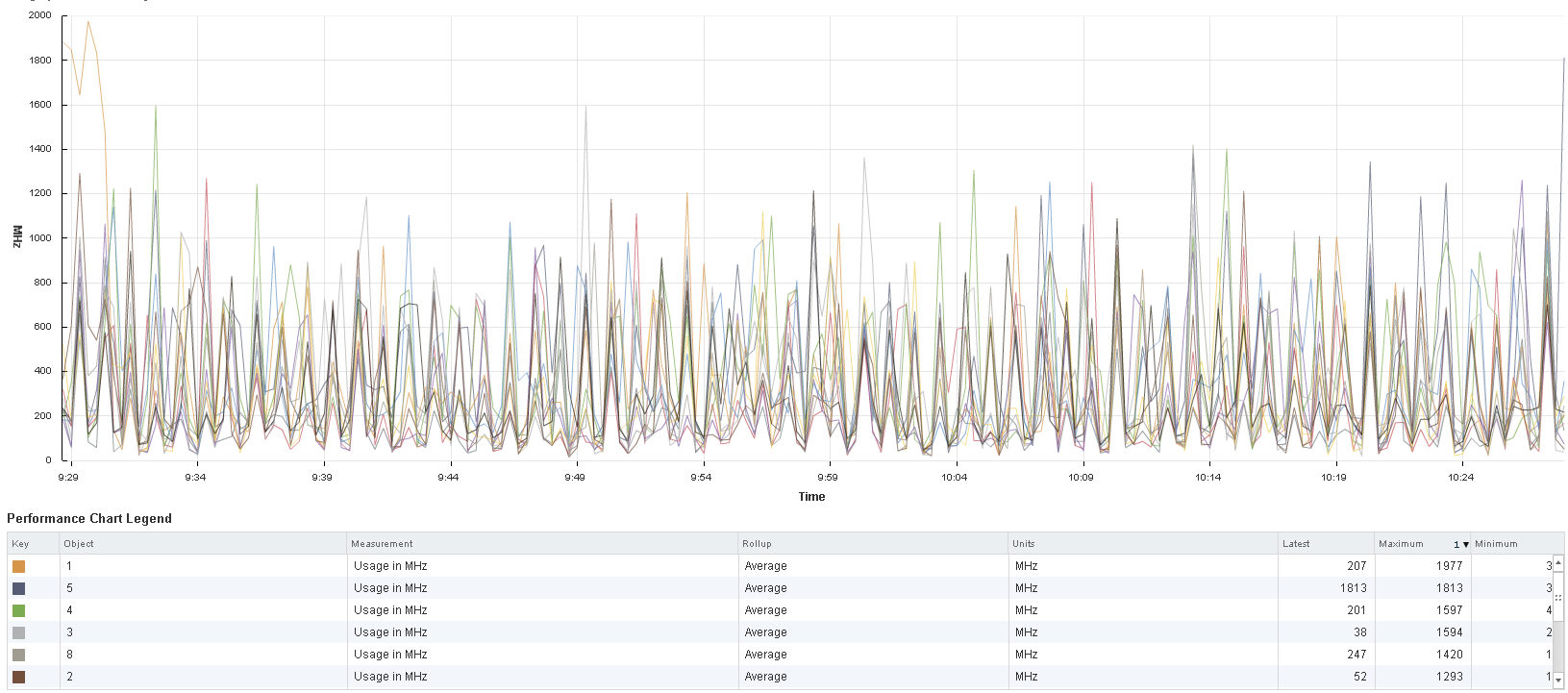
Все ядра равномерно загружены. Скорее всего, будет выгодно взять тариф с фиксированной оплатой.
Обычно тактика финансовой оптимизации выглядит так: вы разделяете элементы своей инфраструктуры на стабильные по потреблению и нестабильные с пиковыми загрузками. Элементы с постоянным потреблением стараемся перевести на фиксированный тариф, а нестабильные — на PAYG, чтобы иметь возможность недорого сглаживать одиночные всплески.
Аналогично поступаем с различными тестовыми и экспериментальными машинами. Чаще всего их выгоднее оплачивать по факту потреблённых ресурсов, а не с фиксированным тарифом. Если нашли машину, которая потребляет от силы 1 %, то выключаете и переводите на PAYG.
Нужно понимать, что в облаке вы платите не за нагрузку на процессор, а за сам факт использования ядер. Если вы используете тарифный план PAYG и вам не нужна ВМ в данный момент, например, вы провели на ней необходимые тесты и больше её не используете, то логичнее её выключить и тем самым сэкономить на стоимости виртуальной памяти и процессоров.
Некоторые клиенты используют API vCloud Director для того, чтобы включать и выключать ВМ по расписанию, чтобы ещё больше экономить на потребляемых ресурсах. Очень хорошим подходом будет использование оркестрации для управления облаком, включения и выключения нод при изменении нагрузки.
При этом за виртуальные диски платить придется всё равно. Если вам больше не нужна ВМ, то её лучше удалить. Либо, если вы используете её очень редко, то на время, пока она находится в выключенном состоянии, перенести её на более дешёвое хранилище. Еще на виртуальных дисках можно сэкономить, если разворачивать каждый раз узел из готового шаблона, а не держать выключенную готовую. А шаблоны держать уже на дешёвом хранилище.
Оперативная память
Не стоит выделять на ВМ больше памяти, чем это требуется. Очень часто пользователи облака конфигурируют ВМ эмпирически: «Ну примерно столько-то памяти нужно отсыпать и столько ядер». При этом именно оперативная память, как правило, — самый дорогой ресурс в облаке.
Используя тарифный план PAYG, есть смысл конфигурировать ВМ так, чтобы она оптимально утилизировала выделенные ей ресурсы, имея запас по производительности для пиковых нагрузок. При этом резерв не должен быть x4 или x10 от среднего потребления вашего приложения: это просто нерационально дорого. Конечно, лимиты всегда определяются индивидуально под каждую задачу, но чаще всего стоит стремиться, чтобы запас не превышал 25 %.
Виртуальные диски
Один из важных ресурсов — это виртуальные диски. Есть несколько типов виртуальных дисков, отличающихся по скорости и цене. Чем диск быстрее, тем он ожидаемо дороже. Поэтому экономию по этому параметру надо начинать с анализа и разделения данных на «холодные» и «горячие».

Неправильный вариант. Политика размещения ВМ настроена так, что своп ВМ, конфигурация и диски будут размещены на дорогих дисках, если явно не указать другое.
ВМ может одновременно использовать разные типы дисков, которые можно разместить на быстром и медленном хранилищах. Соответственно, если вы храните какие-то архивы данных или логи, то есть смысл их размещать на медленных дисках. Базы данных критичны к IOPS, поэтому их мы отправляем на быстрые хранилища.

Правильный вариант. Каждому типу данных — своя скорость диска.
Теперь надо решить вопрос, на каком диске размещать саму ВМ. У платформы vСloud Director есть особенность: она резервирует на диске место под оперативную память ВМ в момент её запуска. При этом вы заранее выбираете тип хранилища. Сама ОС не слишком критична к IOPS, большинство компонентов уже загружено в RAM, и диск не нагружают. Тем не менее, если вы сэкономите и разместитесь на медленном диске, то получите долгий ребут и пробуждение из спящего режима из-за невысокой скорости чтения swap и конфигурационных файлов.
Учитывайте этот фактор, если для вас критично быстрое поднятие виртуальной машины после перезагрузки. В остальных случаях можно сэкономить.
Диски под БД
Очень часто диски под БД берут «на вырост». Это типичная ошибка для облачных систем. Если вам нужно 60 ГБ, то и берите сколько нужно с небольшим запасом. Условные 200 ГБ быстрого диска будут съедать финансы и простаивать.
В отличие от железного сервера тут нет никакой проблемы постепенно расширять диск в объёме по мере необходимости. Только не забудьте повесить мониторинг с триггерами на переполнение диска, чтобы не пропустить момент, когда пора расширить место. Если хотите сделать совсем красиво, то можно попробовать автоматически увеличивать пространство по мере заполнения через API.
Единственный минус такого подхода — нельзя уменьшать размер дисков, изменения только в сторону расширения. Если уменьшить всё-таки нужно, то эта процедура выполняется с переносом данных на меньший объём и удалением старого диска. Не забывайте про бэкапы и тщательное тестирование на этом этапе.
Не забывайте сбрасывать логи на отдельное медленное хранилище, чтобы не тратить драгоценное место на быстром диске с БД. Они имеют тенденцию к очень быстрому поглощению свободного места, особенно в случае MS SQL. Также крайне желательно исключать логи из образов регулярных бэкапов.
Сеть
С Сетью поступаем аналогично: не гонимся за круглыми цифрами 1–10–100 мегабит, а сразу берем 45 мегабит, если у вас средняя загруженность канала — в районе 40. Берите ресурсов ровно столько, сколько необходимо.
Уточняйте возможность управления этим параметром с вашей стороны. У нас клиент сам не может его менять, то есть pay-as-you-go не работает, а смена ширины канала возможна раз в месяц. Тем не менее есть облака, где этот параметр настраивается в реальном времени.

В облаке на базе vCloud Director есть замечательная штука NSX Edge — виртуальный маршрутизатор. Он бесплатный и может заменить собой более дорогие решения, которые требуют дополнительных мощностей и покупки лицензий. В нём есть балансировщик, который в простых ситуациях может заменить такие решения, как Haproxy и виртуальные appliance Citrix NetScaler. Не нужно покупать лицензии для коммерческих продуктов, и за ресурсы NSX Edge вы не платите. Он есть по умолчанию.
В случае необходимости NSX Edge можно масштабировать. Умеет работать как VPN трёх видов:
- IPsec VPN-тоннель Site-to-Site — для организации защищённого канала между облаком и офисом или другими облаками, где размещены ресурсы клиента.
- SSL VPN — для доступа клиента с мобильных устройств и персональных компов, при этом можно не использовать более дорогие решения вроде Checkpoint Cisco и Fortigate.
- L2VPN — так же, как IPSEC Site-to-Site, но соединяет на уровне L2.
CPU
Здесь можно обеспечить экономию несколькими вариантами.
Для начала нужно тщательно выбрать оптимальный тип процессора по частоте и количеству ядер. Всё будет зависеть от особенностей лицензирования ПО, которое крутится на этой машине. Например, сервер AD или терминальный сервер удобно держать на гипервизорах с большим количеством ядер средней производительности. На серверах с ПО, лицензируемых по количеству ядер, уже становится важна частота отдельного ядра. Такие машины получаются более дорогими, но более выгодными с точки зрения производительности на одно ядро.
Вовсе не обязательно использовать одинаковые процессоры на всех своих машинах. Более того, комбинация из инстансов с частотой ядра 2,4 ГГц и, например, 3,1 ГГц может оказаться более экономически привлекательна.
Также можно использовать гибридные архитектуры. Если у вас есть своя инфраструктура и вы не хотите всё переносить, то хорошим решением будет смешанный вариант, когда часть крутится в офисе, а другая — в облаке. При этом ресурсы облака берутся только для сглаживания пиковой нагрузки собственной инфраструктуры.
Обратите внимание: уменьшать оперативную память и CPU облако даст только при выключенной ВМ, иначе система могла бы запаниковать. Расширять же ресурсы можно на работающей машине, если ОС поддерживает и включён режим горячего добавления.
Резервное копирование
Клиент при использовании услуги Резервного копирования платит за две вещи: за количество ВМ и за объём данных на дисковом пространстве. Опять начинаем с анализа.
Подумайте, нужны ли вам копии Active Directory годичной давности, или будет достаточно инкрементального ежедневного бэкапа глубиной в одну-две недели. Определитесь, как долго могут оставаться незамеченными испорченные данные, и настройте соответственно хранение резервных копий. Рабочие машины, на которых только крутится сервис, как правило, нет смысла хранить дольше недели. В случае же с БД может понадобиться восстановление и из копии полугодичной давности, если кто-то испортит данные, а это заметят не сразу.
Второй момент — это скорость восстановления. Если сервис имеет резерв, то можно ограничиться полным бэкапом и инкрементальными копиями. При этом восстанавливается последняя копия, но перед этим надо поэтапно считать все изменения из инкрементальных копий. Это долго. Но в случае работающих резервных нод сервис продолжит функционировать, пока одна из нод восстанавливается.
Если резерва нет по какой-то причине, то стоит подумать о хранении актуального полного бэкапа без инкремента. Места съест больше, но зато развёртывается гораздо быстрее и минимизирует простой сервиса. Разница в скорости может быть в полтора-два раза.
Если хранить резервные копии нужно долго, то стоит рассмотреть вариант холодных хранилищ. Обычно это ленточные библиотеки с медленным восстановлением. Вариант идеален для архивных данных. Хороший пример — Amazon Glacier, где начало развёртывания из старого бэкапа начинается через три–пять часов после запроса. Условно ваши данные нужно физически найти, достать со склада и считать. Зато и стоимость за гигабайт хранения становится намного выгоднее.
У нас можно воспользоваться объектным хранилищем по тарифу «Единый». У него небольшая стоимость хранения с прогрессивной скидкой: чем больший объём хранишь, тем дешевле обходится гигабайт данных.
Резюме
Сэкономить ресурсы на облаке получится только в случае тщательного анализа нагрузки и минимизации резервной мощности. Начните со сбора качественной статистики и начинайте плавно резать ресурсы до минимально необходимых.
Если потребление ноды стабильно и не меняется — переходите на собственную инфраструктуру для данной задачи или выбирайте фиксированные тарифы.
Не забывайте также про возможность гибридных схем. Использование облачных ресурсов для сглаживания нерегулярных пиковых нагрузок практически идеально укладывается в концепцию pay-as-you-go.
