Авторы статьи: Данила Перепечин DanilaPerepechin, Дмитрий Чеклов dcheklov.
Здравствуйте.
Data management platform (DMP) — это наша любимая тема во всей истории про онлайн рекламу. RTB is all about the data.
В продолжение цикла рассказов о технологическом стеке Targetix (SSP, DSP), сегодня я опишу один из инструментов, входящих
в DMP — Keyword Builder.

Keyword Builder помогает рекламодателям создавать очень узкие аудиторные сегменты (их еще называют микросегментами). Для построения таких аудиторий мы решили использовать следующий механизм: рекламодатель задает список ключевых слов, а на выходе получает аудиторию, состояющую из тех пользователей, которые посещали страницы с указанными ключевыми словами или искали эти слова в поиске. С одной стороны это очень простой инструмент, с другой — он дает маркетологам довольно большие возможности для экспериментов.
Основное преимущество этого инструмента — полный контроль над созданием аудитории. Рекламодатель четко понимает, какие пользователи в итоге увидят рекламу. Например, можно создать аудиторию на основе такого списка ключевых слов: ford focus, opel astra, toyota corola.
Как это выглядит со стороны рекламодателя:

В первую очередь, для решения этой задачи мы от всех возможных поставщиков данных (Raw Data Suppliers) получаем clickstream (история посещения страниц пользователем). Данные приходят к нам в таком виде:
Основное требование, которое мы предъявляли к инструменту — скорость создания аудитории. Этот процесс не должен занимать больше 5 минут даже для самых высокочастотных слов. Также важно, чтобы рекламодатель в интерфейсе при указании ключевого слова мог оценить размер аудитории. Оценка размера должна происходить в реальном времени при вводе слов (не более 100 мс, как видно на видео выше).
Для лучшего понимания приведём полный список требований, предъявляемых к инструменту:
Правда к этим требованиям мы пришли уже после создания первой версии этого инструмента :)
Вначале использовали MongoDB и всё шло довольно неплохо.
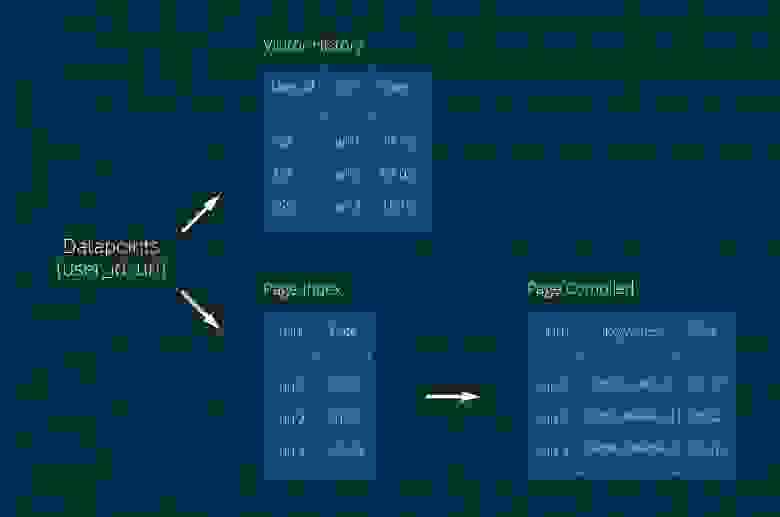
В коллекцию Visitor History записывали данные о пользователе, в Page Index — о страницах. URL страницы сам по себе ценности не представляет — страницу надо скачать и извлечь ключевые слова. Тут возникла первая проблема. Дело в том, что коллекции Page Compiled сначала не было, а ключевые слова записывались в Page Index, но одновременная запись ключевых слов и данных от поставщиков создавала слишком высокую нагрузку на эту коллекцию. Поле Keywords обычно большое, по нему необходим индекс, а в MongoDB той поры (версия 2.6) существовал lock на коллекцию целиком при операции записи. В общем, пришлось вынести ключевые слова в отдельную коллекцию Page Compiled. Пришлось — ну и что же, проблема решена — мы рады. Сейчас уже трудно вспомнить количество и характеристики серверов… что-то порядка 50 shard'ов.

Для создания аудитории по ключевым словам мы делали запрос в коллекцию Page Compiled, получали список URL'ов, на которых встречались эти слова, с этим списком шли в коллекцию Visitor History и искали пользователей, которые посещали эти страницы. Работало всё хорошо (сарказм) и мы могли создать 5, а то и 10(!!!) аудиторных сегментов в сутки… если, конечно, ничего не упадёт. Нагрузка в то время была около 800 млн. datapoint'ов в сутки, TTL индекс — 2 недели: 800*14… данных было много. Работа спорилась и за 3 месяца нагрузка возросла вдвое. Но брать ещё N серверов для поддержания жизни этой странной конструкции было не комильфо.
Самый большой и очевидный минус этой архитектуры — вышеописанный запрос, связанный с получением списка URL. Результатом этого запроса могли быть тысячи, миллионы записей. А главное, по этому списку нужно было сделать запрос в другую коллекцию.
Прочие минусы архитектуры:
Плюсы:
Вообще, с самого начала было понятно, что что-то пошло не так, но теперь это стало очевидно. Мы пришли к выводу, что необходима таблица, которая будет обновляться в режиме реального времени и содержать записи следующего вида:
Проанализировав возможные решения, мы выбрали не на одну базу данных, а их комбинацию с небольшим дублированием данных. Сделали мы это потому, что издержки на дублирование данных были не сопоставимы с тем, какие возможности нам давала эта архитектура.

Первое решение — это платформа полнотекстового поиска Solr. Позволяет создавать распределенный индекс документов. Solr — популярное решение, имеющее большое количество документации и поддерживаемое в сервисе Cloudera. Однако работать с ним как с полноценной БД не получилось, мы решили добавить в архитектуру распределённую колоночную БД HBase.
В начале решили, что в Solr в качестве документа будет выступать user, в котором будет индексируемое поле keywords со всеми ключевыми словами. Но так как мы планировали удалять старые данные из таблицы, то решили в качестве документа использовать связку user+date, что стало полем User_id: то есть каждый документ должен хранить все ключевые слова пользователя за день. Такой подход позволяет удалять старые записи по TTL-индексу, а также строить аудитории с разной степенью «свежести». Поле Real_Id — настоящий id пользователя. Это поле используется для агрегации в запросах с указанной длительностью интереса.
Кстати, чтобы не хранить лишние данные в Solr, поле keywords сделали только индексируемым, что позволило нам существенно сократить объем хранимой информации. При этом сами ключевые слова, как вы уже поняли, можно достать из HBase.
Особенности Solr, которые нам пригодились в данной архитектуре:
Данные, дублирующиеся в HBase и в Solr, приложения записывают только в HBase, откуда сервис от Cloudera автоматически дублирует записи в Solr с указанными атрибутами полей и TTL индексом.
Таким образом мы смогли сократить издержки, связанные с тяжёлыми запросами. Но это не все элементы, которые оказались нам необходимы и стали нашим фундаментом. В первую очередь мы нуждались в обработке больших объёмов данных на лету и тут как нельзя кстати пригодился Apache Spark с его streaming-функционалом. А в качестве очереди данных мы выбрали Apache Kafka, которая как нельзя лучше подошла для этой роли.
Теперь рабочая схема выглядит следующим образом:
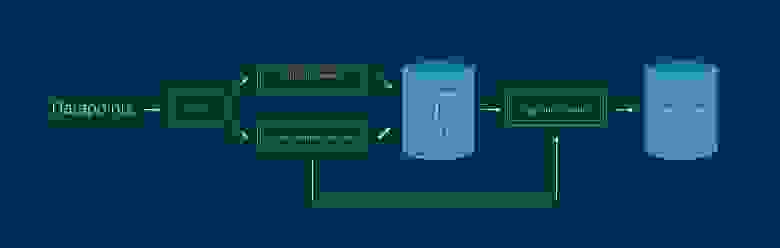
1. Из Kafka данные выбирают два процесса. Функционал очереди позволяет читать её нескольким независимым процессам, каждый из которых имеет свой курсор.
2. PageIndexer — из записи {user_id: [urls]} использует только URL. Работает только с таблицей Page Compiled.
3. VisitorActionReceiver —Собирает сохраненную в кафке информацию о действиях пользователей за 30 секунд (batch интервал).
4. SegmentBuilder строит аудитории и добавляет в уже существующие новых пользователей, в реальном времени.
Особенностью PageIndexer является выбор ключевых слов со страницы, для разных типов страниц — разные наборы слов.
Работает на 1-2 серверах 32GB RAM Xeon E5-2620, скачивает 15-30К страниц в минуту. При этом выбирая из очереди 200-400К записей.
А основным достоинством VisitorActionReceiver, то что помимо добавления записей в Solr/HBase, данные так же пересылаются в Segment Builder и новые пользователи добавляются в аудитории в реальном времени.
Segment Builder формирует в Solr сложный запрос, где словам с разных тегов присваивается различный вес, а также учитывается длительность интереса пользователя (краткосрочный, среднесрочный, долгосрочный). Все запросы на построение аудитории делаются при помощи edismax query, которая возвращает вес каждого документа, относительно запроса. Таким образом в аудитории попадают действительно релевантные пользователи.
В HBase в секунду приходит около 20К запросов на чтение и 2.5К на запись. Объём хранения данных — ~100 ГБ. Solr занимает ~250 ГБ, содержит ~250 млн записей TTL индекс 7 дней. (Все цифры без учёта репликации).
Коротко напомним основные элементы инфраструктуры:
Kafka — умная и устойчивая очередь, HBase — быстрая колоночная БД, Solr — давно зарекомендовавший себя поисковый движок, Spark — распределённые вычисления, включая streaming, а главное, всё это находится на HDFS, прекрасно масштабируется, мониторится и очень устойчиво. Работает в окружении Cloudera.

Может показаться, что мы усложнили рабочую схему большим разнообразием инструментов. На самом деле мы пошли по пути наибольшего упрощения. Да, одну монгу мы поменяли на список сервисов, но все они работают в той нише, для которой и создавались.
Теперь Keyword Builder действительно отвечает всем требованиям рекламодателей и здравому смыслу. Аудитории в 2.5 млн людей создаются за 1-7 минут. Оценка размера аудитории происходит в реальном времени. Задействовано всего 8 серверов (i7-4770, 32GB RAM). Добавление серверов влечёт за собой линейный рост производительности.
А получившийся инструмент вы всегда можете попробовать в ретаргетинговой платформе Hybrid.
Выражаю горячую благодарность пользователю dcheklov, за помощь в создании статьи и наставлении на путь истинный =).
Тема DMP начата и остаётся открытой, ждите нас в следующих выпусках.
Здравствуйте.
Data management platform (DMP) — это наша любимая тема во всей истории про онлайн рекламу. RTB is all about the data.
В продолжение цикла рассказов о технологическом стеке Targetix (SSP, DSP), сегодня я опишу один из инструментов, входящих
в DMP — Keyword Builder.
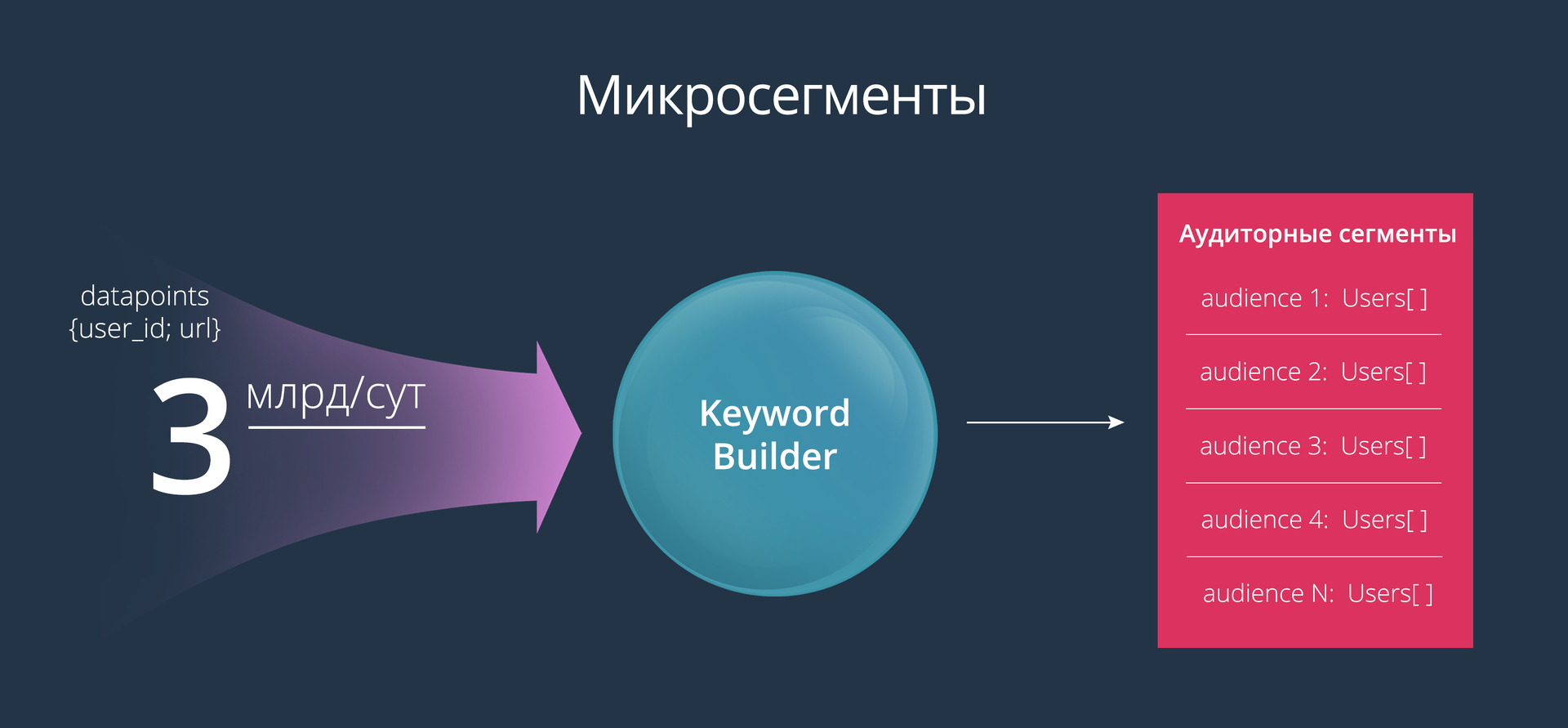
Микросегментирование
Keyword Builder помогает рекламодателям создавать очень узкие аудиторные сегменты (их еще называют микросегментами). Для построения таких аудиторий мы решили использовать следующий механизм: рекламодатель задает список ключевых слов, а на выходе получает аудиторию, состояющую из тех пользователей, которые посещали страницы с указанными ключевыми словами или искали эти слова в поиске. С одной стороны это очень простой инструмент, с другой — он дает маркетологам довольно большие возможности для экспериментов.
Основное преимущество этого инструмента — полный контроль над созданием аудитории. Рекламодатель четко понимает, какие пользователи в итоге увидят рекламу. Например, можно создать аудиторию на основе такого списка ключевых слов: ford focus, opel astra, toyota corola.
Как это выглядит со стороны рекламодателя:
В первую очередь, для решения этой задачи мы от всех возможных поставщиков данных (Raw Data Suppliers) получаем clickstream (история посещения страниц пользователем). Данные приходят к нам в таком виде:
{ user_id; url }
Цели и требования
Основное требование, которое мы предъявляли к инструменту — скорость создания аудитории. Этот процесс не должен занимать больше 5 минут даже для самых высокочастотных слов. Также важно, чтобы рекламодатель в интерфейсе при указании ключевого слова мог оценить размер аудитории. Оценка размера должна происходить в реальном времени при вводе слов (не более 100 мс, как видно на видео выше).
Для лучшего понимания приведём полный список требований, предъявляемых к инструменту:
- принцип локальности данных;
- высокая доступность базы данных (high availability);
- горизонтальная масштабируемость;
- высокая скорость записи;
- высокая скорость полнотекстового поиска;
- высокая скорость поиска по ключу.
Правда к этим требованиям мы пришли уже после создания первой версии этого инструмента :)
Первая архитектура, которая учит, «как не надо делать»
Вначале использовали MongoDB и всё шло довольно неплохо.

В коллекцию Visitor History записывали данные о пользователе, в Page Index — о страницах. URL страницы сам по себе ценности не представляет — страницу надо скачать и извлечь ключевые слова. Тут возникла первая проблема. Дело в том, что коллекции Page Compiled сначала не было, а ключевые слова записывались в Page Index, но одновременная запись ключевых слов и данных от поставщиков создавала слишком высокую нагрузку на эту коллекцию. Поле Keywords обычно большое, по нему необходим индекс, а в MongoDB той поры (версия 2.6) существовал lock на коллекцию целиком при операции записи. В общем, пришлось вынести ключевые слова в отдельную коллекцию Page Compiled. Пришлось — ну и что же, проблема решена — мы рады. Сейчас уже трудно вспомнить количество и характеристики серверов… что-то порядка 50 shard'ов.

Для создания аудитории по ключевым словам мы делали запрос в коллекцию Page Compiled, получали список URL'ов, на которых встречались эти слова, с этим списком шли в коллекцию Visitor History и искали пользователей, которые посещали эти страницы. Работало всё хорошо (сарказм) и мы могли создать 5, а то и 10(!!!) аудиторных сегментов в сутки… если, конечно, ничего не упадёт. Нагрузка в то время была около 800 млн. datapoint'ов в сутки, TTL индекс — 2 недели: 800*14… данных было много. Работа спорилась и за 3 месяца нагрузка возросла вдвое. Но брать ещё N серверов для поддержания жизни этой странной конструкции было не комильфо.
Самый большой и очевидный минус этой архитектуры — вышеописанный запрос, связанный с получением списка URL. Результатом этого запроса могли быть тысячи, миллионы записей. А главное, по этому списку нужно было сделать запрос в другую коллекцию.
Прочие минусы архитектуры:
- неудобная запись из-за глобального lock'а;
- огромный размер индекса, который разрастался, несмотря на удаление данных;
- сложность мониторинга большого кластера;
- необходимость самостоятельно создавать упрощённую версию полнотекстового поиска;
- отсутствие принципа локальности при обработке данных;
- невозможность быстрой оценки размера аудитории;
- невозможность добавления пользователей в аудиторию на лету.
Плюсы:
- мы поняли все минусы.
К чему мы пришли
Вообще, с самого начала было понятно, что что-то пошло не так, но теперь это стало очевидно. Мы пришли к выводу, что необходима таблица, которая будет обновляться в режиме реального времени и содержать записи следующего вида:
user {
user_id; keywords[]
}
Проанализировав возможные решения, мы выбрали не на одну базу данных, а их комбинацию с небольшим дублированием данных. Сделали мы это потому, что издержки на дублирование данных были не сопоставимы с тем, какие возможности нам давала эта архитектура.

Первое решение — это платформа полнотекстового поиска Solr. Позволяет создавать распределенный индекс документов. Solr — популярное решение, имеющее большое количество документации и поддерживаемое в сервисе Cloudera. Однако работать с ним как с полноценной БД не получилось, мы решили добавить в архитектуру распределённую колоночную БД HBase.
В начале решили, что в Solr в качестве документа будет выступать user, в котором будет индексируемое поле keywords со всеми ключевыми словами. Но так как мы планировали удалять старые данные из таблицы, то решили в качестве документа использовать связку user+date, что стало полем User_id: то есть каждый документ должен хранить все ключевые слова пользователя за день. Такой подход позволяет удалять старые записи по TTL-индексу, а также строить аудитории с разной степенью «свежести». Поле Real_Id — настоящий id пользователя. Это поле используется для агрегации в запросах с указанной длительностью интереса.
Кстати, чтобы не хранить лишние данные в Solr, поле keywords сделали только индексируемым, что позволило нам существенно сократить объем хранимой информации. При этом сами ключевые слова, как вы уже поняли, можно достать из HBase.
Особенности Solr, которые нам пригодились в данной архитектуре:
- быстрая индексация;
- компактный индекс;
- полнотекстовый поиск;
- оценка количества документов, соответствующих запросу;
- оптимизация индекса после удаления данных (предотвращает его разрастание, как это часто бывает в других БД).
Данные, дублирующиеся в HBase и в Solr, приложения записывают только в HBase, откуда сервис от Cloudera автоматически дублирует записи в Solr с указанными атрибутами полей и TTL индексом.
Таким образом мы смогли сократить издержки, связанные с тяжёлыми запросами. Но это не все элементы, которые оказались нам необходимы и стали нашим фундаментом. В первую очередь мы нуждались в обработке больших объёмов данных на лету и тут как нельзя кстати пригодился Apache Spark с его streaming-функционалом. А в качестве очереди данных мы выбрали Apache Kafka, которая как нельзя лучше подошла для этой роли.
Теперь рабочая схема выглядит следующим образом:
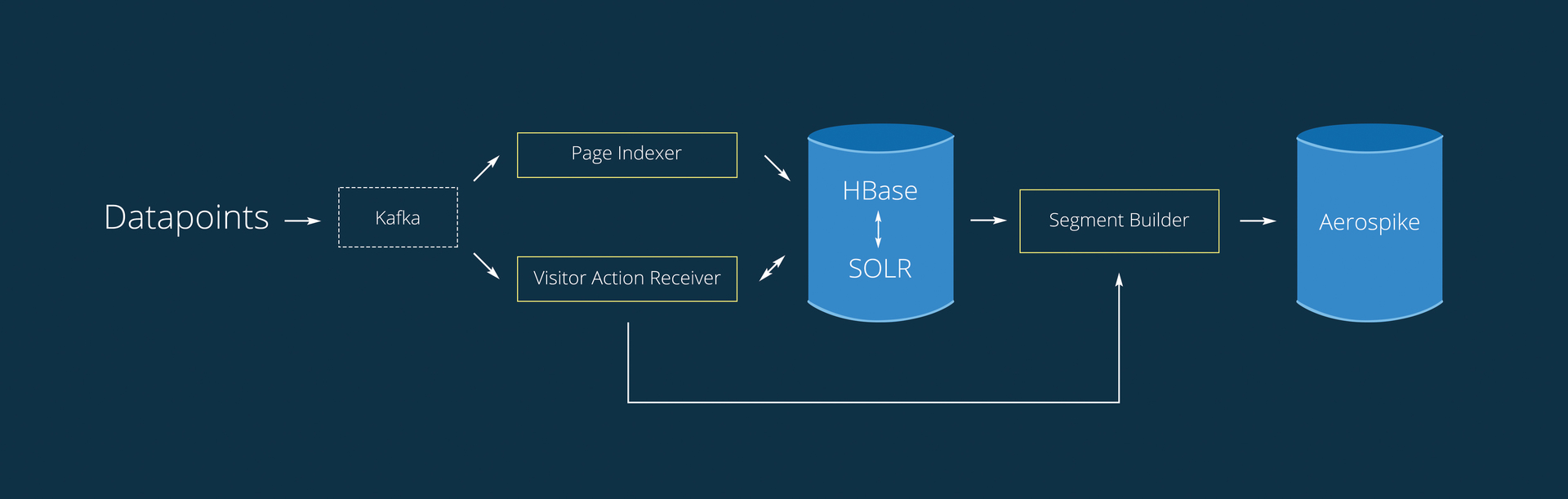
1. Из Kafka данные выбирают два процесса. Функционал очереди позволяет читать её нескольким независимым процессам, каждый из которых имеет свой курсор.
2. PageIndexer — из записи {user_id: [urls]} использует только URL. Работает только с таблицей Page Compiled.
- При поступлении datapoint'а, делает запрос в HBase для проверки, скачивалась ли уже страница или нет
- Если страница не была обнаружена в базе, экстрагирует с неё ключевые слова
- Записывает данные в HBase.
3. VisitorActionReceiver —Собирает сохраненную в кафке информацию о действиях пользователей за 30 секунд (batch интервал).
- Удаление дубликатов из очереди
- Создание записи вида {user_id: [urls]}
- Запрос в HBase в таблицу Page Compiled и получение ключевых слов, создание записи вида {user_id: [keywords]}
- Запрос в HBase в таблицу Visitor Keywords и получение уже содержащихся у пользователя ключевых слов
- Объединение ключевых слов для пользователя
- Запись в Solr и HBase
4. SegmentBuilder строит аудитории и добавляет в уже существующие новых пользователей, в реальном времени.
- По таймеру проверяет наличие необработанных аудиторий.
- Формирует запрос в Solr и получает пользователей для аудитории.
- Записывает данные в Aerospike
Особенностью PageIndexer является выбор ключевых слов со страницы, для разных типов страниц — разные наборы слов.
Работает на 1-2 серверах 32GB RAM Xeon E5-2620, скачивает 15-30К страниц в минуту. При этом выбирая из очереди 200-400К записей.
А основным достоинством VisitorActionReceiver, то что помимо добавления записей в Solr/HBase, данные так же пересылаются в Segment Builder и новые пользователи добавляются в аудитории в реальном времени.
Порядок вызовов VisitorActionReceiver:
public static void main(String[] args) {
SparkConf conf = getSparkConf();
JavaStreamingContext jssc = new JavaStreamingContext(conf, new Duration(STREAMING_BATCH_SIZE));
JavaPairInputDStream<String, byte[]> rawStream = Utils.createDirectStream(jssc, KAFKA_TOPIC_NAME, KAFKA_BROKERS);
JavaPairDStream<String, String> pairUrlVid = rawStream.mapPartitionsToPair(rawMessageIterator -> convertRawMessage(rawMessageIterator));
Utils.GetCountInStreamRDD(pairUrlVid, "before_distinct");
JavaPairDStream<String,String> reducedUrlVid = pairUrlVid.reduceByKey((old_s, next_s) -> reduceByUrl(old_s, next_s), LEVEL_PARALLELISM).repartition(LEVEL_PARALLELISM).persist(StorageLevel.MEMORY_ONLY_SER());
Utils.GetCountInStreamRDD(reducedUrlVid, "after_distinct");
JavaDStream<SolrInputDocument> solrDocumentsStream = reducedUrlVid.mapPartitions(reducedMessages -> getKeywordsFromHbase(reducedMessages)).repartition(SOLR_SHARD_COUNT).persist(StorageLevel.MEMORY_ONLY_SER());
Utils.GetCountInStreamRDD(solrDocumentsStream, "hbase");
SolrSupport.indexDStreamOfDocs(SOLR_ZK_CONNECT, SOLR_COLLECTION_NAME, SOLR_BATCH_SIZE, solrDocumentsStream);
jssc.start();
jssc.awaitTermination();
}
Segment Builder формирует в Solr сложный запрос, где словам с разных тегов присваивается различный вес, а также учитывается длительность интереса пользователя (краткосрочный, среднесрочный, долгосрочный). Все запросы на построение аудитории делаются при помощи edismax query, которая возвращает вес каждого документа, относительно запроса. Таким образом в аудитории попадают действительно релевантные пользователи.
В HBase в секунду приходит около 20К запросов на чтение и 2.5К на запись. Объём хранения данных — ~100 ГБ. Solr занимает ~250 ГБ, содержит ~250 млн записей TTL индекс 7 дней. (Все цифры без учёта репликации).
Коротко напомним основные элементы инфраструктуры:
Kafka — умная и устойчивая очередь, HBase — быстрая колоночная БД, Solr — давно зарекомендовавший себя поисковый движок, Spark — распределённые вычисления, включая streaming, а главное, всё это находится на HDFS, прекрасно масштабируется, мониторится и очень устойчиво. Работает в окружении Cloudera.
Яркая иллюстрация устойчивости
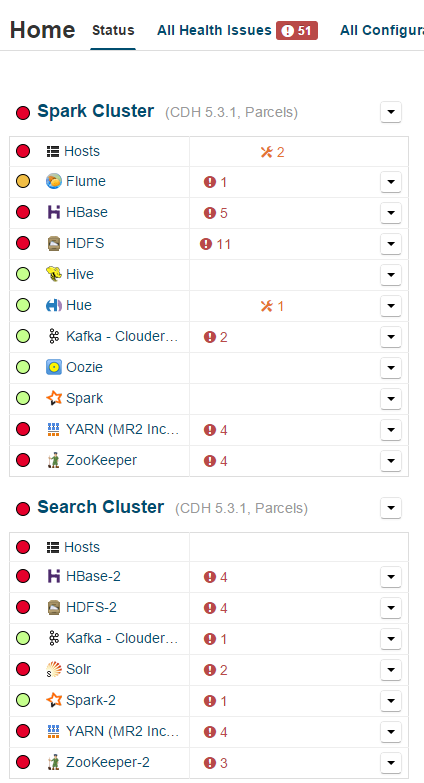
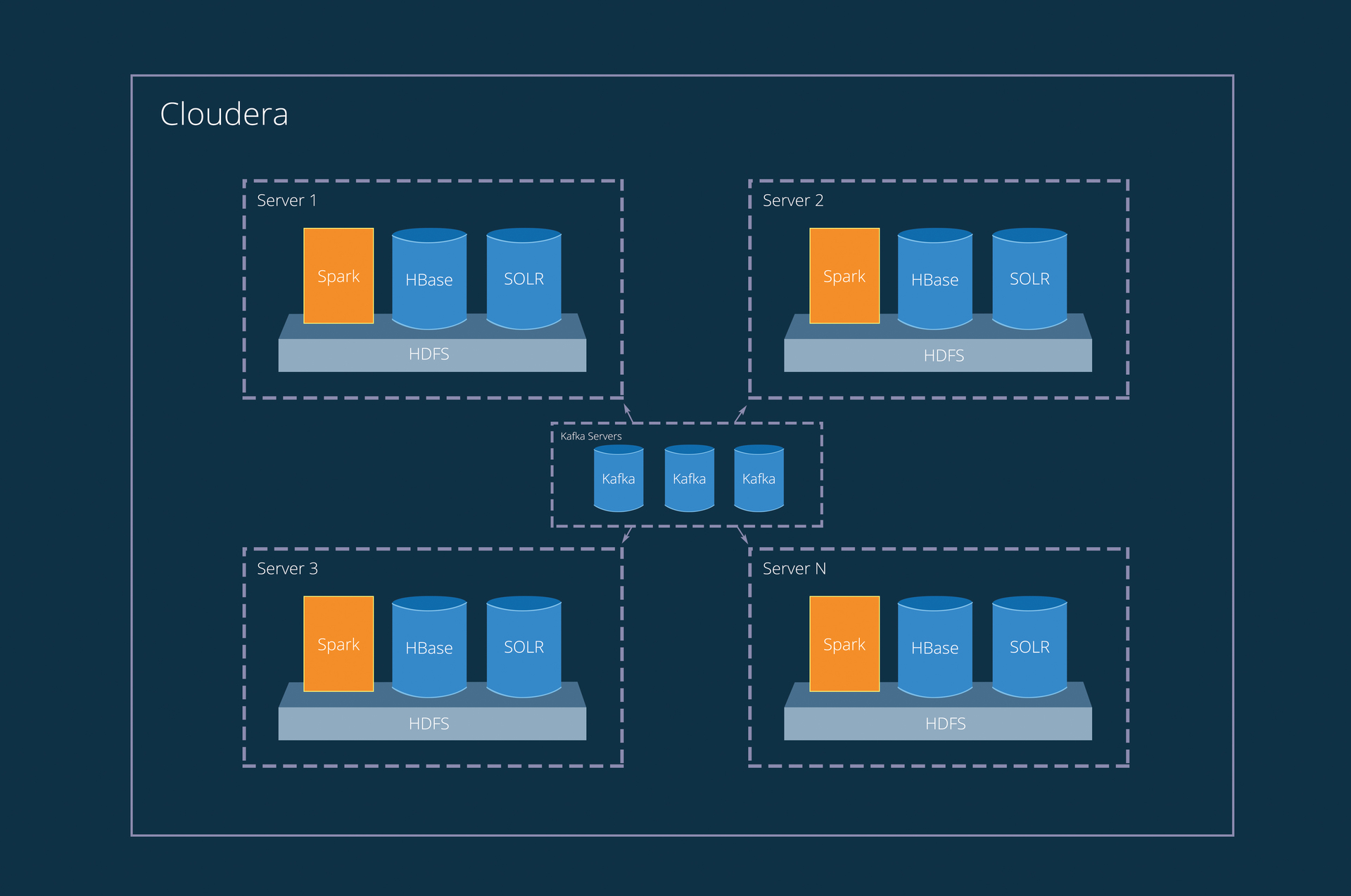
Заключение
Может показаться, что мы усложнили рабочую схему большим разнообразием инструментов. На самом деле мы пошли по пути наибольшего упрощения. Да, одну монгу мы поменяли на список сервисов, но все они работают в той нише, для которой и создавались.
Теперь Keyword Builder действительно отвечает всем требованиям рекламодателей и здравому смыслу. Аудитории в 2.5 млн людей создаются за 1-7 минут. Оценка размера аудитории происходит в реальном времени. Задействовано всего 8 серверов (i7-4770, 32GB RAM). Добавление серверов влечёт за собой линейный рост производительности.
А получившийся инструмент вы всегда можете попробовать в ретаргетинговой платформе Hybrid.
Выражаю горячую благодарность пользователю dcheklov, за помощь в создании статьи и наставлении на путь истинный =).
Тема DMP начата и остаётся открытой, ждите нас в следующих выпусках.