Каждый год появляется столько новых технологий (таких как Kubernetes или Habitat), что легко забыть о тех инструментах, которые тихо и незаметно поддерживают наши системы в промышленной эксплуатации. Одним из таких инструментов, который мы используем в Stripe на протяжении нескольких лет, является Consul. Consul помогает в обнаружении сервисов (то есть помогает находить тысячи работающих у нас серверов с запущенными на них тысячами различных сервисов и сообщать, какие из них доступны для использования). Это эффективное и практичное архитектурное решение не было чем-то совсем новым и особенно заметным, но оно верой и правдой служит делу предоставления надежных сервисов нашим пользователям по всему миру.
В этой статье мы собираемся поговорить о следующем:
- Что такое обнаружение сервисов и Consul.
- Как мы управляли рисками, возникавшими при внедрении критически важного программного продукта.
- Вызовы, с которыми мы столкнулись, и наши ответы на эти вызовы.
Хорошо известно, что нельзя просто так взять и установить новое ПО, рассчитывая, что оно как-то магически будет работать и решать все проблемы. Использование нового ПО — это процесс. И в этой статье описывается пример того, каким оказался для нас процесс использования нового ПО в промышленной эксплуатации.
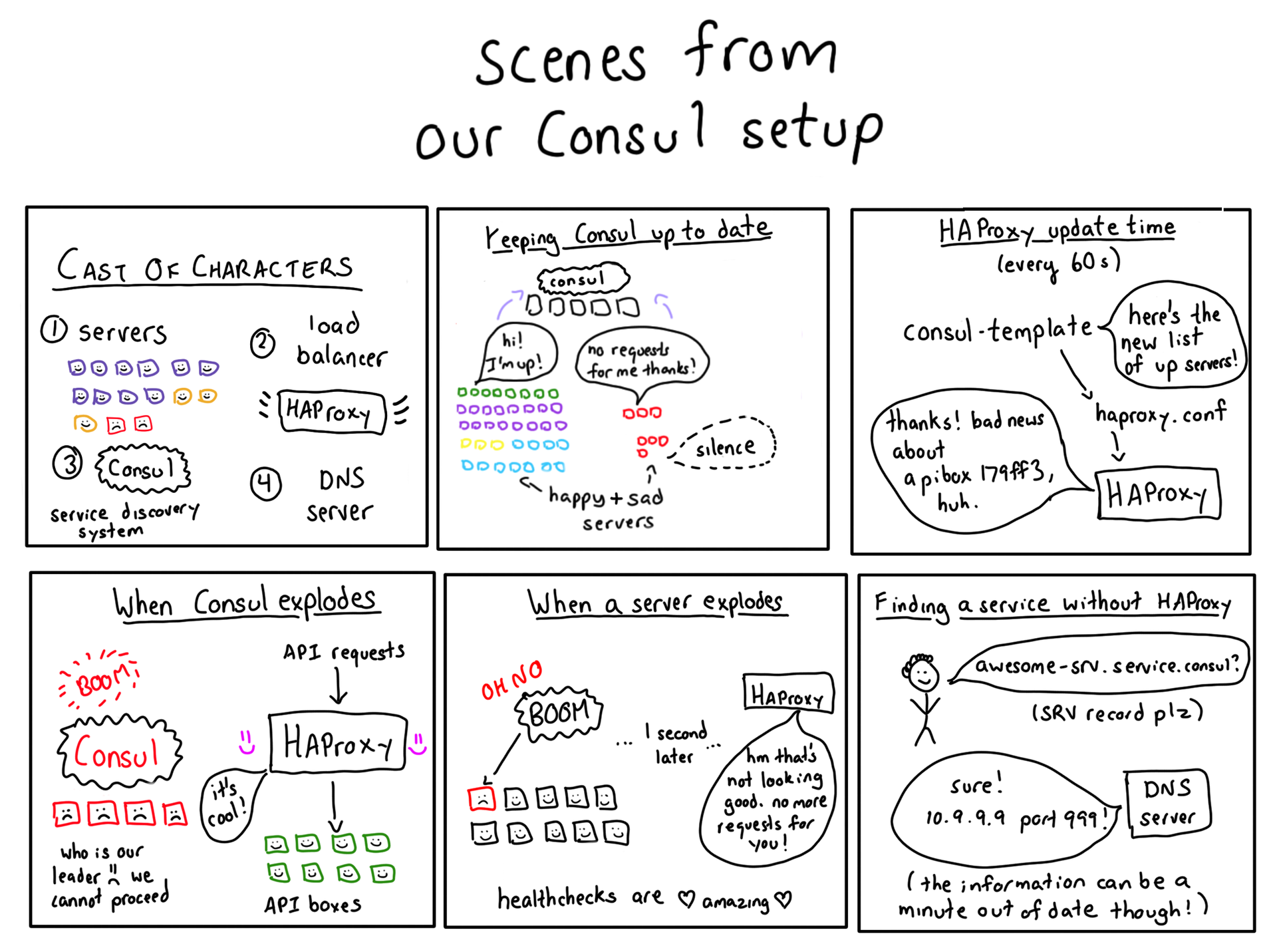
Что такое обнаружение сервисов?
Отличный вопрос! Представьте себя балансировщиком нагрузки компании Stripe. К вам поступает запрос на проведение платежа, который нужно перенаправить на сервер API. Любой север API!
У нас работают тысячи серверов, на которых запущены различные сервисы. Какие из них серверы API? На каком порту запущен сервис API? Одним из «замечательных» свойств Amazon Web Services является то, что наши инстансы могут выйти из строя в любой момент, поэтому мы должны быть готовы:
- потерять любой сервер API;
- добавить в оборот новые серверы, если нужна дополнительная мощность.
Отслеживание изменений состояния доступности сетевых служб называется обнаружением сервисов (service discovery). Для выполнения этой работы мы используем инструмент под названием Consul, разрабатываемый HashiCorp.
Тот факт, что наши инстансы в любой момент могут выйти из строя, на самом деле очень помогает, так как наша инфраструктура постоянно практикуется, регулярно теряя инстансы и разрешая такие ситуации в автоматическом режиме. Поэтому, когда непредвиденная ситуация случается, ничего страшного не происходит. Это обычное дело, рутина. Тем более что корректно отработать сбой гораздо проще, когда сбои происходят достаточно часто.
Введение в Consul
Consul — это инструмент обнаружения сервисов, который дает возможность сервисам регистрироваться и находить другие сервисы. С помощью специального клиента Consul записывает информацию о работающих сервисах в БД, а другое клиентское ПО пользуется этой базой. Составных частей тут немало — есть с чем повозиться.
Самая главная часть Consul — это база данных. Она содержит записи типа «api-service запущен на IP 10.99.99.99, порт 12345. Он доступен».
Отдельные машины говорят Consul: «Привет! У меня запущен api-service, порт 12345! Я живой!»
Затем, если нужно обратиться к API-сервису, можно спросить Consul «Какие из api-services доступны?» В ответ он вернет список соответствующих IP-адресов и портов.
Сам Consul — тоже распределенная система (помните, что мы можем потерять любую машину в любое время, и Consul в том числе!), поэтому, чтобы поддерживать базу данных в синхронизированном состоянии, в Consul используется алгоритм достижения консенсуса под названием Raft.
Почитать о достижении консенсуса в Consul можно здесь.
Consul в Stripe: Начало
На первом этапе мы ограничились конфигурацией, в которой машины с клиентом Consul на борту писали на сервер отчеты о своей доступности. Для обнаружения сервисов эта информация не использовалась. Чтобы настроить такую систему, мы написали конфигурацию Puppet, что оказалось не так уж и сложно!
Таким образом мы смогли выявить потенциальные проблемы с клиентом Consul и получить опыт его использования на тысячах машин. На начальном этапе мы не применяли Consul для обнаружения каких-либо сервисов.
Что здесь могло пойти не так?
Утечки памяти
Если вы ставите какое-то ПО на все машины своей инфраструктуры, у вас однозначно могут начаться проблемы. Практически сразу мы столкнулись с утечками памяти в статистической библиотеке Consul. Мы заметили, что одна из машин заняла больше 100 МБ оперативной памяти, и потребление росло. Всему виной была ошибка в Consul, которую мы поправили.
100 МБ — небольшая утечка, но она быстро увеличивалась. В общем случае утечки памяти представляют серьезную опасность, так как из-за них всего один процесс может полностью парализовать машину, на которой запущен.
Как хорошо, что мы не стали с самого начала использовать Consul для обнаружения сервисов! Нам удалось избежать серьезных проблем и практически безболезненно устранить найденные ошибки за счет того, что сначала мы дали Consul поработать на нескольких боевых серверах, при этом следя за потреблением памяти.
Начинаем заниматься обнаружением сервисов
Поскольку мы были уверены, что с выполнением Consul на наших серверах не будет проблем, мы начали добавлять клиентов, опрашивающих Consul. Чтобы снизить риски, мы сделали следующее:
- для начала стали использовать Consul ограниченно;
- сохранили резервную систему, чтобы продолжать функционировать во время перебоев в работе Consul.
Вот несколько проблем, с которыми пришлось столкнуться. Здесь мы не пытаемся жаловаться на Consul, а скорее хотим подчеркнуть, что при использовании новой технологии очень важно разворачивать систему не торопясь и быть осмотрительным.
Огромное количество переключений Raft. Помните, что Consul использует протокол достижения консенсуса? Он копирует все данные одного сервера кластера Consul на другие серверы этого кластера. У первичного сервера было много проблем с вводом/выводом: диски были недостаточно быстры и не успевали выполнить все пожелания Consul, что приводило к зависанию первичного сервера целиком. Raft говорил: «Ох, первичный сервер опять недоступен!», выбирал новый первичный сервер, и этот порочный цикл повторялся. В то время когда Consul был занят выборами нового первичного сервера, он блокировал базу данных на запись и чтение (так как по умолчанию установлены согласованные чтения).
В версии 0.3 полностью сломали SSL. Для обеспечения безопасного обмена данными между нашими нодами мы использовали SSL-функционал Consul (технически, TLS), который был успешно сломан в очередном релизе. Мы его починили. Это пример такого рода проблем, которые нетрудно обнаружить и которых не стоит бояться (в цикле QA мы осознали, что SSL сломан, и просто не стали переходить на новый релиз), но они достаточно распространены в программном обеспечении, находящемся на ранних стадиях разработки.
Утечки goroutine. Мы начали использовать выборы лидера Consul, а там оказалась утечка goroutine, приводившая к тому, что Consul съедал всю доступную память. Люди из команды Consul нам очень помогли в решении этой проблемы, и мы убрали несколько утечек памяти (уже других, не тех, что нашли раньше).
Когда все проблемы были исправлены, мы оказались уже в гораздо лучшем положении. Дорога от «наш первый клиент Consul» до «мы исправили все проблемы в production» заняла чуть менее года выполнения фоновых рабочих циклов.
Масштабирование Consul с целью обнаружения доступных сервисов
Итак, мы нашли и поправили несколько ошибок в Consul. Все стало работать намного лучше. Но помните, о каком шаге мы говорили в начале? Где вы спрашиваете Consul: «Хэй, какие машинки доступны для api-service?» С такими запросами у нас периодически возникали проблемы: сервер Consul отвечал медленно или не отвечал вовсе.
В основном это происходило во время raft-переключений или периодов нестабильности. Поскольку Consul использует строго согласованное хранилище, его доступность всегда будет хуже, чем доступность системы, не имеющей таких ограничений. Особенно тяжело нам приходилось в самом начале.
У нас все еще происходили переключения, и перебои в работе Consul стали для нас достаточно болезненными. В таких ситуациях мы переходили на жестко прописанный набор DNS-имен (например, “apibox1”). Когда мы только развернули Consul, такой подход работал нормально, но в процессе масштабирования и расширения области применения Consul он становился все менее жизнеспособным.
Consul Template в помощь
Мы не могли положиться на получение от Consul информации о доступности сервисов (через его HTTP API). Но во всём остальном он нас полностью устраивал!
Нам хотелось получать от Consul информацию о доступных сервисах не через его API. Но как это сделать?
ОК, Consul берет имя (например, monkey-srv) и переводит его в один или несколько IP-адресов («вот где живет monkey-srv»). Знаете, кто еще получает на вход имя и возвращает IP-адрес? DNS-сервер! В общем, мы заменили Consul DNS-сервером. Вот как мы это сделали: Consul Template — это программа на Go, которая генерирует статические конфигурационные файлы на основе базы данных Consul.
Мы начали использовать Consul Template для генерации DNS-записей о сервисах Consul. Если monkey-srv был запущен на IP 10.99.99.99, мы генерировали DNS-запись:
monkey-srv.service.consul IN A 10.99.99.99Код выглядит так. А здесь вы можете найти нашу рабочую конфигурацию Consul Template, которая немного сложнее.
{{range service $service.Name}}
{{$service.Name}}.service.consul. IN A {{.Address}}
{{end}}Если вы скажете: «Подождите, в записях DNS есть только IP-адрес, а нужен еще и порт!», то будете совершенно правы! DNS A-записи (тот тип, который чаще всего встречается) содержат только IP-адрес. Однако DNS SRV-записи могут иметь также и порт, поэтому наш Consul Template генерирует SRV-записи.
Мы запускаем Consul Template с помощью cron каждые 60 секунд. В Consul Template также есть установленный по умолчанию режим слежения (“watch” mode), в котором файлы конфигурации обновляются постоянно по мере поступления новой информации в базу данных. Когда мы в первый раз включили режим слежения, он положил наш сервер Consul чрезмерным количество запросов, поэтому мы решили от него отказаться.
Итак, пока наш Consul-сервер недоступен, на внутреннем DNS-сервере есть все необходимые записи! Возможно, они не совсем свежие, но ничего страшного. У нашего DNS-сервера есть одна замечательная особенность: он не является новомодной распределенной мегасистемой, и относительная простота делает его менее склонным к внезапным поломкам. То есть я могу просто сделать nslookup monkey-srv.service.consul, получить IP и наконец начать работать с моим API-сервисом!
Поскольку DNS является неразделяемой, в конечном счете согласованной системой, мы можем ее многократно кэшировать и реплицировать (у нас есть 5 канонических DNS-серверов, на каждом из которых есть локальный DNS-кэш и информация об остальных 5 канонических серверах). Поэтому наша резервная DNS-система просто по определению гораздо надежнее Consul.
Добавляем балансировщик нагрузки для более быстрых проверок состояния
Только что мы говорили о том, что обновляем DNS-записи на основании данных из Consul каждые 60 секунд. Так что же происходит, когда мы теряем API-сервер? Продолжаем ли мы направлять запросы на этот IP в течение примерно 45 секунд, пока не обновится DNS? Нет! В этой истории есть еще один герой — HAProxy.
HAProxy — это балансировщик нагрузки. Если настроить соответствующие проверки, он может следить за состоянием сервисов, на которые пересылает запросы. Все наши API-запросы по факту идут через HAProxy. Вот как это работает.
- Consul Template каждые 60 секунд переписывает конфигурационный файл HAProxy.
- Таким образом, у HAProxy всегда есть более или менее корректный список доступных внутренних серверов.
- Если машина уходит в off-line, HAProxy узнает об этом достаточно быстро (он выполняет проверки каждые 2 секунды).
Получается, что мы перезапускаем HAProxy каждые 60 секунд. Но значит ли это, что мы заодно обрываем соединения? Нет. Чтобы избежать сброса соединений во время перезапусков, мы используем функцию мягкого перезапуска (graceful restart) HAProxy. При этом сохраняется риск потерять некоторое количество сетевого трафика (согласно вот этой статье), но наш трафик не настолько велик, чтобы это стало проблемой.
Мы используем стандартную конечную точку (endpoint) проверки состояния сервисов. Практически у каждого сервиса есть конечная точка /healthcheck, которая вернет 200, если с сервисом всё в порядке, и выдаст ошибки, если что-то пошло не так. Наличие стандарта очень важно, так как помогает нам легко настраивать в HAProxy проверки состояния сервисов.
Если Consul падает, у HAProxy остается в наличии пусть и немного неактуальная, но вполне работоспособная конфигурация.
Меняем согласованность на доступность
Если вы внимательно следили за повествованием, то могли заметить, что система, с которой мы начали (строго согласованная база данных, гарантированно имеющая все обновления), очень сильно отличается от системы, к которой мы пришли (DNS-сервер, который может запаздывать на время, доходящее до одной минуты). Отказ от согласованности позволил нам создать гораздо более отзывчивую систему, так как перебои в работе Consul практически не влияют на нашу способность обнаруживать сервисы.
Отсюда можно извлечь полезный урок: согласованность имеет свою цену! Нужно быть готовым заплатить за систему с хорошей доступностью. И если вы собираетесь использовать строгую согласованность, важно убедиться, что вам нужна именно она.
Что происходит при создании запроса
В этой статье мы уже о многом успели поговорить, так что давайте теперь посмотрим на путь, которым идут запросы, раз уж мы разобрались, как это работает.
Что происходит, когда вы запрашиваете https://stripe.com/? Как этот запрос попадает на нужный сервер? Вот несколько упрощенное описание.
- Сначала запрос приходит на один из наших публичных балансировщиков нагрузки, на котором запущен HAProxy.
- Consul Template уже записал список серверов, обслуживающих stripe.com, в конфигурационный файл /etc/haproxy.conf.
- HAProxy перезагружает свою конфигурацию каждые 60 секунд.
- HAProxy пересылает запрос на сервер stripe.com, убедившись, что он доступен.
В реальной жизни процесс не так прост (там есть дополнительный слой, да и запросы Stripe API посложнее, так как у нас есть системы, обеспечивающие соблюдение стандарта PCI), но реализация выполнена согласно идеям, описанным в этой статье.
Это значит, что, когда мы добавляем или убираем серверы, Consul автоматически обновляет конфигурационные файлы HAProxy. Руками ничего делать не нужно.
Больше года мирной жизни
В нашем подходе к обнаружению сервисов осталось еще немало вещей, которые мы бы хотели улучшить. Чтобы это сделать, в первую очередь нужна активная разработка, и мы видим возможности изящно решить вопрос интеграции нашей инфраструктуры планирования и инфраструктуры маршрутизации запросов.
Однако мы пришли к выводу, что простые решения часто оказываются еще и самыми верными. Описанная в статье система надежно служит нам уже более года без каких-либо инцидентов. При том что Stripe по количеству обрабатываемых запросов очень далек от Twitter или Facebook, мы стараемся добиться максимальной надежности. Иногда бывает, что самым выигрышным оказывается не новаторское, а стабильное и отлично выполняющее свои функции решение.
