Этой статьей на Хабре мы с большим удовольствием анонсируем вам, друзья, что от шаблонных жестко структурированных документов мы перешли к распознаванию различных сложно структурированных. А это, поверьте, совсем другая песня! За деталями добро пожаловать под кат.
В каждой своей статье на Хабре мы не устаем повторять, что наша первостепенная цель — автоматизация ввода данных из любых документов в естественных неконтролируемых условиях без необходимости использования специального оборудования. Всего за несколько лет нам удалось довести систему распознавания ID-документов до промышленного уровня и сейчас большая часть финансовых приложений (включая даже некоторые приложения государственного значения) используют нашу технологию для ускорения и упрощения работы с приложением.
На этот год наша глобальная цель — распознавание любых документов, без дополнительных требований к шаблонам и бланкам. Как всегда, распознавание должно выполняться непосредственно на устройстве (будь то мобильный девайс или мощный сервер). Потратив большую часть времени на внутренний ресерч, переработав практически полностью свою базовую технологию Hieroglyph, мы создали первую версию программы распознавания универсальных документов — Smart DocumentReader.
Какие документы распознает Smart DocumentReader
Архитектурно программа Smart DocumentReader не содержит каких-либо ограничений по типам поддерживаемых документов и позволяет настроить распознавание любых сложно структурированных документов. Документы могут содержать различные смысловые элементы: таблицы, чекбоксы, области рукопечатного заполнения и т.п. Хотя, одно ограничение, вызванное скорее аппаратными особенностями мобильных устройств, у нашей программы присутствует: максимальный физический размер распознаваемых документов — формат А4. Но, согласитесь, это не сильное ограничение с точки зрения бюрократии в Российской Федерации. Все основные финансовые документы у нас печатаются на страницах А4: справка по форме 2-НДФЛ, счет, счет-фактура, акт, товарно-транспортная накладная (ТТН), товарная накладная по форме ТОРГ12, универсальный передаточный документ (УПД), устав, договор, инвойс, анкета, заявление и т.п.
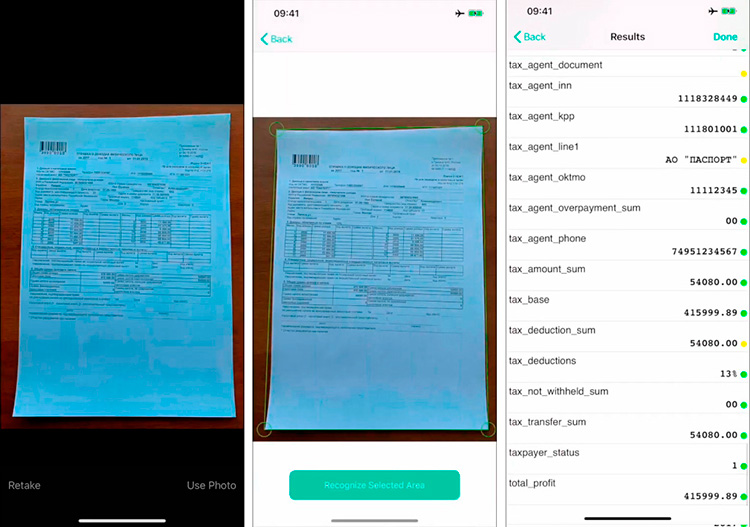
Распознавание справок 2-НДФЛ
В качестве первого примера, мы настроили программу Smart DocumentReader для распознавания справок по форме 2-НДФЛ. С точки зрения практического использования это очень популярный документ, который требуется например, банками при оформлении больших кредитов, государством для получения налоговых вычетов.
С точки зрения внутренней структуры, справка 2-НДФЛ является отличным примером сложно структурированного документа: на нем присутствуют обязательные и опциональные поля, несколько таблиц, существует логическая связь между отдельными атрибутами, большое количество распознаваемых полей.
Smart DocumentReader поддерживает распознавание многостраничных документов. Для этого программе следует поочередно показывать все страницы документа. По факту появления новых страниц, общий результат распознавания будет пополняться новыми данными.
Как и все наши предыдущие продукты, Smart DocumentReader запускается на широком диапазоне процессорных архитектур под управлением различных операционных систем. На сегодняшний день мы поддерживаем аппаратные платформы «Эльбрус», «Комдив», SPARC, MIPS, ARM, x86, операционные системы Sailfish Mobile OS RUS («Аврора»), iOS, Android, «Эльбрус», Linux, Windows, macOS, Solaris. Что касается скорости распознавания, то на мобильном телефоне одностраничный документ 2-НДФЛ распознается за 3-5 секунд.
P.S. В этой статье мы практически упустили техническую часть, предвкушая в ближайшем будущем целую серию серьезных публикаций о самых важных деталях, реализующих представленную функциональность.
