Бесплатный вводный урок — фишка школы Skyeng. Потенциальный ученик может на нем познакомиться с платформой, проверить свой уровень английского, наконец, просто развлечься. Для школы же вводный урок — часть воронки продаж, за которой должна последовать первая оплата. Его проводит методист вводного урока — специальный человек, совмещающий в себе педагога и продажника, его время оплачивается вне зависимости от того, купил клиент первый пакет или нет, и явился ли вообще на урок. Неявка — очень частое явление, из-за которого цена урока становится слишком большой.
В этой статье мы расскажем, как с помощью аналитической модели и опыта авиакомпаний смогли сократить издержки на вводный урок почти вдвое.
Воронка продаж Skyeng состоит из пяти ступеней: регистрация на сайте, звонок первой линии продаж с записью на вводный урок, вводный урок, звонок второй линии продаж, оплата первого пакета. Раньше после первого созвона мы назначали время урока у конкретного методиста вводного урока, тот в это время ждал ученика. Если человек записался и не пришел, методист впустую тратит свое время, а школа – деньги на оплату этого времени. Неявка случается в среднем в половине случаев; треть клиентов покупают первый пакет после проведенного вводного урока. Таким образом, конверсия из записи на вводный урок в оплату составляет всего 0,15. Успешный (сконвертированный в оплату) вводный урок в старой схеме обходился нам в 4 000 руб, и с этим надо было что-то делать.
Можно просто от него отказаться, но в этом случае итоговая конверсия из лида в оплату сильно упадет, что нас не устраивает. Придется искать другое решение, строить модели, считать и экспериментировать.
Первый блин
Мы обратились к опыту авиакомпаний, конкретно к практике овербукинга. Перевозчики знают, что на рейс редко является 100% пассажиров, купивших билет, и пользуются этим, продавая больше билетов, чем мест в самолете. Если вдруг на посадку явятся все пассажиры, можно найти среди них добровольцев, готовых за какую-нибудь плюшку улететь следующим рейсом. Авиакомпании таким образом повышают свою прибыль, а мы похожим методом можем снизить издержки.
Итак: отказываемся от записи к конкретному человеку, создаем пул методистов вводного урока, раскидываем между ними заявки из расчета, что половина не явится. А если пришло больше – предлагаем записаться на другой день. Мы запустили такой MVP в тест и сразу же поняли, что сделали все неправильно.
Половина выходящих на вводный урок – это статистика, в реальности доля сильно колеблется в зависимости от времени, дня, канала, из которого пришел человек. При этом больше 80% потенциальных учеников в ответ на предложение перенести урок или сразу отваливаются, или не приходят по второй записи. Все это могло привести к тому, что в неудачные дни мы бы теряли до трети клиентов. Тест свернули и пошли все делать по-умному.
Модель, прогнозы, полиномы
В первую очередь надо было выяснить, от чего зависит доля выходящих на вводный урок. Первое наблюдение – она зависит от маркетингового канала, откуда человек пришел. Мы делим эти каналы с точки зрения конверсии в оплату на «горячие», где конверсия выше, «теплые» и «холодные», где она ниже; выяснилось, что «температура канала» влияет на конверсию в выход на вводный урок примерно так же.
Продолжая авиационную аналогию, мы сделали разные «стойки регистрации» для лидов из разных каналов, расставив им коэффициенты, соответствующие исторической вероятности выхода этого канала: 0,8, 0,4 и 0,2. Для «горячих» каналов выделяем больше методистов, «холодным» — меньше. Это работало лучше, но все равно в неудачные дни было больше 20% «вылетов» (ситуаций, когда на вводный урок вышло больше клиентов, чем было свободных методистов). Попробовали увеличить коэффициенты, добавив запас в 0,1: с одной стороны, чем больше выводим методистов, тем меньше теряем клиентов, с другой — затраты на проведение вводных уроков растут.
Из этих наблюдений выросла вторая MVP. Для каждого записавшегося мы строим прогноз вероятности его выхода на вводный урок. Делаем совместное распределение вероятностей и доверительный интервал с уровнем доверия 95%. Для редких случаев, когда выходит больше клиентов, чем планировалось, держим резервный пул методистов – преподавателей, которые в данный момент заняты несрочной работой типа проверки сочинений.
Для расчета прогноза для конкретного ученика мы построили статистическую модель, основанную на наших исторических данных и учитывающую несколько факторов: канал, регион, ребенок/взрослый, частный/корпоративный клиент, время от записи до самого вводного урока.
Модель оперирует понятиями:
- слот: дата и время вводного урока;
- поправляющий коэффициент: вероятность аномального выхода в этот день и час;
- вес заявки: допустимая вероятность выхода данного клиента;
- вылет: необслуженная заявка (клиент вышел, все методисты заняты);
- простой методиста: вышло меньше, чем прогнозировалось, люди сидят без дела;
- ограничение: % на доверительном интервале, после достижения которого модель запрещает добавлять заявки в слот.
В каждом слоте находится N методистов, а сам слот обладает поправляющим коэффициентом k (с базой 100). Количество доступных для модели методистов определяется как round(N*k/100). При появлении заявки модель определяет ее вес, смотрит сумму таких весов, уже находящихся в слоте, и определяет слот как доступный, если в результате добавления этой заявки сумма весов заявок в слоте не будет превышать количество методистов. Метриками для оценки модели служат: доля вылетов (необходимо минимизировать), загрузка слота (максимизируется), время ожидания вводного урока клиентом (минимизируется). К изменяемым параметрам модели относятся вес заявки и ограничение.
Для прогноза, сколько выйдет клиентов, использовалась формула произведения вероятностей:

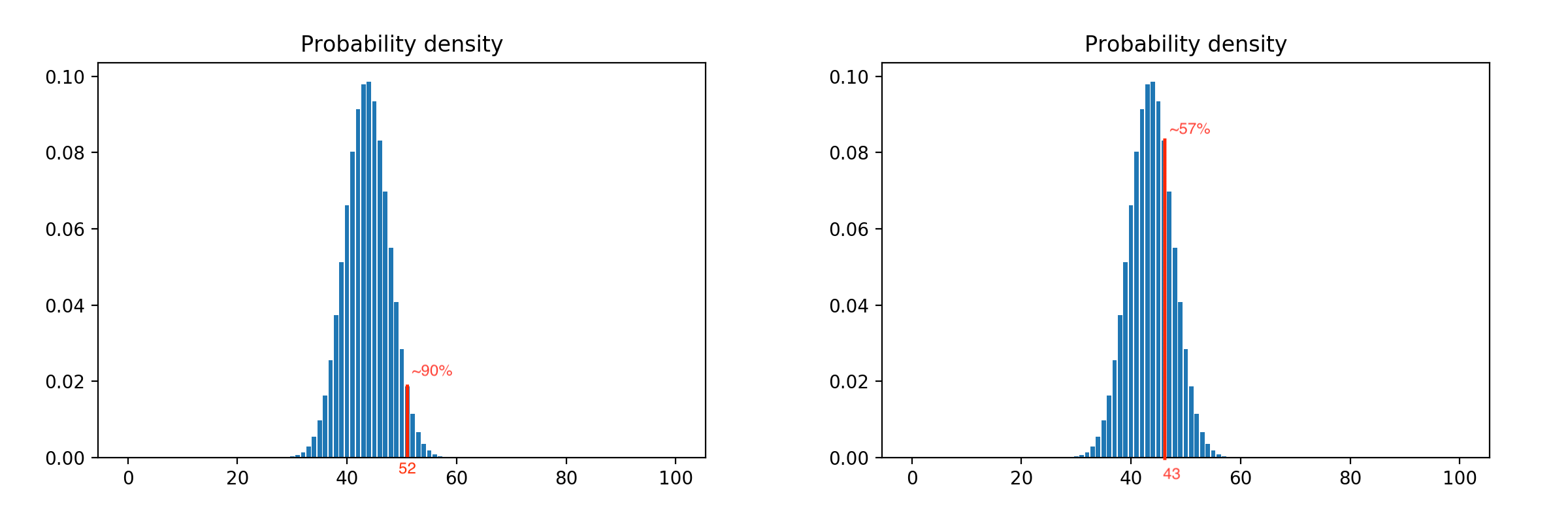
Рассматривая все возможные комбинации выходов, мы получаем очень близкое к естественному распределение вероятностей. Распределение для ста клиентов выглядит так:

Применив к нему доверительный интервал, мы можем регулировать агрессивность модели. Например, сдвиг ограничения влево ее увеличивает, т.е. мы выпускаем больше клиентов при том же числе методистов, а сдвиг вправо – уменьшает, т.к. ограничение срабатывает раньше. Пример с ограничениями на 90% и 57%:
Кроме того, агрессивность модели можно регулировать поправочным коэффициентом: уменьшение ее снижает, увеличение – поднимает. Это полезно, когда мы знаем, что в конкретный день/час некие внешние факторы могут сделать выходимость аномальной.
Формула с перемножением вероятностей хорошо показала себя в тестах, но была тяжеловата с вычислительной точки зрения, поэтому мы переписали ее полиномами:

К минусам модели можно отнести:
- из-за того, что она опирается на исторические данные, она плохо реагирует на резкие изменения выходимости;
- если у методиста случился форс-мажор и он выпадает из слота, это почти гарантированный вылет, менеджерам надо срочно переназначать урок;
- если падает динамическая разметка “теплоты” каналов, модель неверно оценивает вероятность выхода клиента.
В результате использования этой модели мы получили до 45% экономии затрат на вводный урок с минимальными потерями клиентов.
Почему не машинное обучение?
Потому что статистическая модель и так неплохо работает, и вместо того, чтобы улучшать точность существующего прогноза при помощи ML, выгоднее направить силы ML-разработчиков на другие задачи.
Например, мы разрабатываем систему скоринга потенциального клиента, отдаленно похожую на банковскую. Банки с помощью скоринга определяют вероятность возврата кредита, а мы можем определять вероятность первой оплаты. Если она совсем низкая – незачем тратить ресурсы на организацию вводного урока; если, напротив, очень высокая – можно сразу отправлять клиента на страницу оплаты.
Но эта история для другого раза.
