Привет, Хабр! Сегодня хотим представить вам некоммерческий открытый датасет, собранный командой студентов магистратуры «Наука о данных» НИТУ МИСиС и Zavtra.Online (подразделении SkillFactory по работе с вузами) в рамках первого учебного Дататона. Мероприятие проходило как один из форматов командной практики. Данная работа заняла первое место из 18 команд.
Датасет содержит полный список объектов торговли и услуг в Москве с транспортными, экономическими и географическими метаданными. Исходная гипотеза состоит в том, что близость объекта к транспортным узлам является одним из важнейших показателей и ключевым фактором экономического успеха. Мы попросили команду детально описать свой опыт сбора такого датасета, и вот что получилось.
TLTR: Ближе к концу статьи вы найдёте информативные графики, карты и ссылки.

Программа магистратуры «Наука о данных» НИТУ МИСиС и Zavtra.Online рассчитана на два года — т.е четыре семестра и раз в семестр для студентов будет проводиться хакатон, делая обучение больше ориентированным на решение практических задач. Первый хакатон был посвящен сбору датасета, поэтому и назвали его соответственно — «Дататон».
Всего в Дататоне приняло участие 90 студентов. Перед ними поставили задачу — собрать датасет, который может использоваться в продукте, основанном на Data Science.
Идею для сбора датасета предлагали сами студенты, с оглядкой на потребности общества или бизнеса — так что актуальность стала одним из главных критериев оценки и выбора победителей.
Оценивать команды позвали менторов — практикующих специалистов по Data Science высокого уровня из таких компаний как: Align Technology, Intellivision, Wrike, Мерлин АИ, Лаборатория Касперского, Auriga, Huawei, SkillFactory.
При выборе темы для нашего датасета мы руководствовались известным принципом «предвидеть — значит управлять». Поиск новых гипотез — не самая простая задача, особенно когда одними из критериев выступают практичность и ориентация на потребности гипотетического заказчика. Трудно найти неразмеченную область, используя только лишь открытые данные.
Основная работа по сбору и обработке была проделана за 5 дней, остальное время до публикации мы исправляли недостатки, незначительно обогащали датасет и оптимизировали его структуру.
Фундаментальной идеей нашего датасета является гипотеза, что окрестности перспективных транспортно-пересадочных узлов Москвы (далее — ТПУ) станут хорошими зонами для развития бизнеса. Что вообще представляет из себя концепция ТПУ?
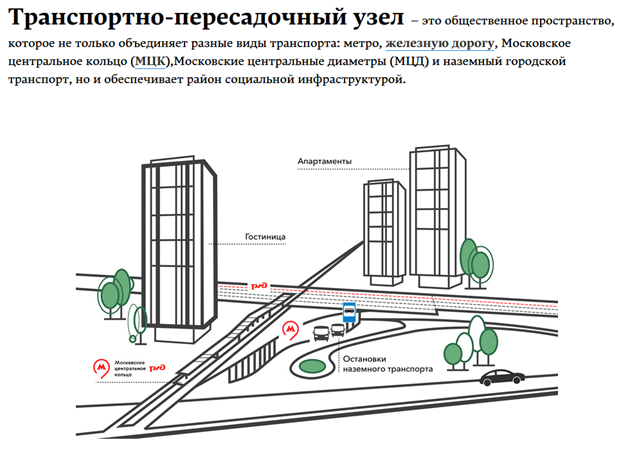
Источник: stroi.mos.ru
Основная гипотеза тривиальна и лежит на поверхности. Больший интерес представляют уточняющие вопросы от потенциального предпринимателя, которые можно задать, основываясь на ней. Например:
Таких вопросов может быть множество. Более того, часть из них порождает целое дерево уточняющих вопросов, которые играют важную роль при создании нового бизнеса или расширении действующего.
Наш датасет может служить основой для аналитики и обучения линейных или логистических регрессий, задач классификации или кластеризации. Он подходит для наглядной визуальной демонстрации действующих объектов торговли и услуг в Москве с привязкой к крупным транспортным узлам города. Мы уверены, что он содержит множество «скрытых данных», которые ждут, когда их обнаружат.
В датасете были использованы следующие данные с сайта Портал открытых данных правительства города Москвы:
Другие источники:
Основу структуры данных составляют уникальные объекты торговли и услуг, каждому из которых соответствует набор метаданных, включающих в себя такие сведения, как:
Часть данных представлена в виде словарей, что связано с вложенностью отдельных признаков. Например, ряд ТПУ представляет собой комплекс из отдельных объектов наземного и подземного транспорта, и рассматривать их по отдельности нелогично. Но при необходимости эти вложенные объекты легко могут быть извлечены, что мы и выполняем при визуализации объектов на карте.
Для сложных вложенных объектов мы использовали списки и словари, поскольку организованный доступ к такой структуре значительно проще, нежели парсинг строковых объектов. В целом датасет содержит большое разнообразие типов данных.

Это пример не только объединения, но и неточности отдельных полей, о чем будет следующий раздел
Качество исходных данных в целом оказалось удовлетворительным, но недостаточным для реализации всех наших амбиций. В ходе проверки мы обнаружили, что Москва значительно уступает по этому показателю ряду мировых столиц. Также мы заметили некоторые ошибки и неточности, которые пришлось обрабатывать как отдельные выбросы или оставлять на совести авторов источников.

Пример спорных данных
После предварительной оценки имеющихся в распоряжении первичных данных (а это были данные об объектах торговли, услуг и ТПУ на территории Москвы) мы поняли, что ключевым элементом нашего датасета будут уникальные объекты торговли и услуг, которые мы объединили в единый центральный датасет. Всего мы получили более 78 000 записей, для которых помимо уникального ID и названия имеются сведения о:
Эту информацию, в том числе географические и демографические параметры, мы обнаружили на Википедии в относительно актуальном состоянии на начало 2020 года. Мы автоматизировали процесс выгрузки сведений путём написания собственной функции для парсинга html-страниц. Незначительными трудностями, с которыми мы столкнулись, стали:
В дальнейшем мы нашли геоданные о границах районов. Эта информация оказалась очень полезна при визуальном отображении слоев на карте.
Зоны охвата являются не объективной оценкой, а лишь одной из теоретических методик оценки эффективности того или иного объекта торговли. Мы обнаружили методику оценки, которая разделяет объекты на 4 группы. В нашем случае достаточно было ввести лишь 3 из них — маленькие, средние и большие. Разделение мы осуществляли путем анализа типов и названий объектов. Например, приставка «Гипер-» с большой долей вероятности соответствует большому объекту. Исходя из размера мы определили зону, в радиусе которой торговый объект является привлекательным для клиентов.
В имеющемся датасете под ТПУ подразумевается любой транспортный объект, которых на территории Москвы более 250. Поэтому нам пришлось объединять их в комплексы, исходя из названий и расстояний между ними. Сведения об объектах включают в себя такие данные, как:
В теории они легко объединяются в кластеры, но на практике обнаружился ТПУ «Планерная», который рушил всю систему. Одна станция находится в районе метро «Речной вокзал», а вторая — за Химками. Расстояние между ними составляет около 6 км, и очевидно, что учитывать их как единый комплекс при расчёте транспортной доступности нельзя. Подобные отклонения вносят шум в данные и вынуждают создавать сложные алгоритмы обработки.
Каждый полученный комплекс центрирован относительно всех включенных объектов, при этом мы сохранили все данные об исходных ТПУ — они хранятся внутри в виде словарей, где ключами выступают оригинальные ID ТПУ.
Этот раздел стал одним из самых сложных, поскольку всё, что связано с недвижимостью, сильно монетизировано и является ценной информацией. В открытом виде актуальные сведения по каждому району получить очень трудно. Риэлторские агентства и торговые площадки не предоставляют бесплатные API, а парсинг торговых площадок был слишком ресурсозатратным в условиях ограничений срока проекта.
Поэтому мы не стали изобретать велосипед, а просто нашли наиболее удобный ресурс и вручную сохранили статистические сведения о стоимости продажи и аренды коммерческой недвижимости для торговых объектов, отдельно стоящих зданий и объектов общего назначения за 2020 год.
Несмотря на значительное количество пропусков и отдельные неточности, эти данные отражают ситуацию на рынке недвижимости и строятся на реальных объявлениях.
Эта секция тоже оказалась достаточно проблемной, поскольку изначально идея найти такие сведения в актуальном виде показалась нереальной, а официальные ответы оказалось ждать очень долго (и не факт, что они были бы положительными). Долгое время эта задача оставалось нерешённой, и нам пришлось повторно рассматривать буквально каждую крупицу информации, даже явно устаревшей.
Иронично, что обнаруженная ошибка в старом источнике позволила обнаружить подходящие данные. После повторной проверки мы поняли, что в одном из источников использованы данные за 2019 год, при этом подпись содержит указание на 2016 год. Эта подпись и сбила нас при первой оценке. Актуальность подтвердилась наличием данных по построенным в 2019 году объектам метро.
Впрочем, сами данные тоже оказались не оптимизированы для парсинга. Мы столкнулись с дублями и артефактами типа «100000 тыс. тыс. чел в сутки», которые пришлось отыскивать и приводить к общему виду. Тем не менее, как уже упомянуто в разделе о качестве данных, отдельные показатели по станциям явно завышены и ошибочны. И эту проблему можно решить только уточнением из первоисточника.
Собрать числовые или строковые данные — мало. Эти данные важно уметь трактовать и выделять на их основе новые параметры или свойства. Поскольку наша гипотеза строилась на принадлежности объекта к ближайшему ТПУ, мы написали алгоритм поиска ближайших объектов и для каждого уникального объекта сопоставили:

Небольшой кусок датасета с бинарными признаками
В результате объединения мы получили датасет размерностью 44 столбца и 78086 строк. В формате Pandas он занимает около 25,9+ MB. Если разбить столбцы на тематические сегменты, то в нём содержатся данные о:

Что можно сказать по полученной корреляционной матрице?
Остальные взаимосвязи между параметрами не столь явные, и трудно сделать по ним однозначные выводы.
Наконец-то мы дошли до самой интересной части любого датасета, своеобразный момент истины! Апогеем сбора является визуализация данных, где можно не только оценить качество данных, но и найти коллизии, ошибки и выбросы.
Для визуализации мы написали свою функцию, которая использует библиотеку Folium. Метод удобен тем, что достаточно гибко визуализирует практически любые выборки из общего датасета. Параметры функции позволяют гибко настраивать визуальные признаки объектов. Поскольку каждый объект в нашем случае — слой, мешающие группы объектов легко отключить и оставить лишь необходимые.
Для большей наглядности на карте реализованы слои в виде административного деления по районам. В нашем случае за стандартное отображение мы приняли плотность объектов на каждый район города.
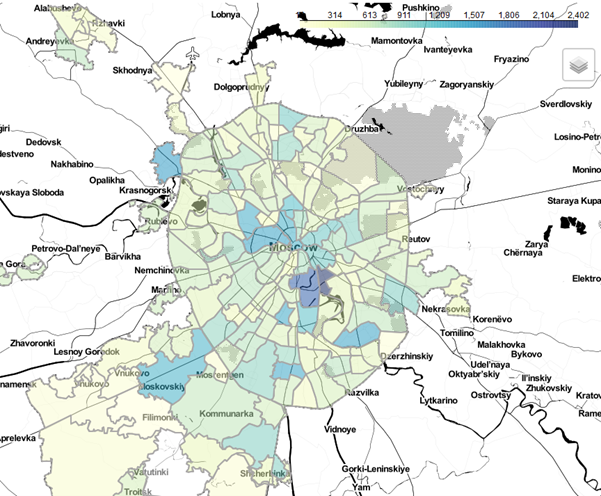
Пример отображения районов по плотности размещения объектов

Транспортная схема Москвы: здесь отображаются только ТПУ

Пример отображения с объектами — в данной выборке всего 10000 объектов из более чем 78 000

Пример отображения объектов по выделенному адресу — описание сформировано в виде HTML-кода
Графики — отличный инструмент для анализа. В качестве демонстрации мы подготовили ряд графиков, чтобы наглядно продемонстрировать статистику по наиболее интересным параметрам датасета.
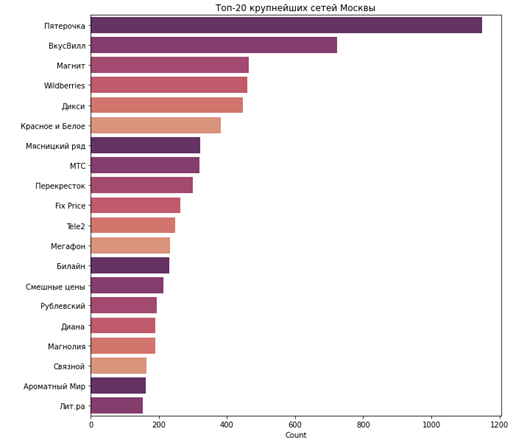
Вот, например, 20 крупнейших торговых сетей Москвы:
А если посмотреть, какие типы объектов самые популярные?

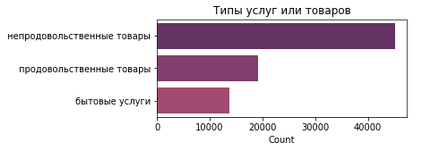
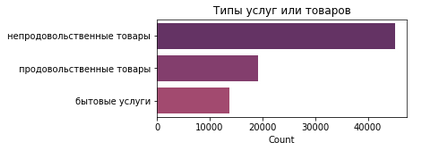
По типам услуг всё не так интересно, зато понятно, сколько всего объектов каждого типа есть в городе.
Теперь чуть более интересные цифры — количество объектов при ТПУ.

Руки чешутся посмотреть на самый верхний ТПУ «Профсоюзная». Почему бы и да? На этом скриншоте размещаются больше 2000 объектов, для которых этот ТПУ ближайший.
Хорошо, как насчёт того, чтобы узнать, сколько из объектов в городе являются сетевыми? Получается красивый пирог с почти идеальной четвертью. Занятно. Пусть 1 и 0 вас не пугают, это как раз и есть пример бинарного признака, где 1 означает, что объект входит в какую-либо крупную сеть.
Раз уж мы решили строить топы, почему бы не узнать адрес, по которому располагается большее число объектов? Легко!

Найти его не так уж сложно. Список впечатляет:

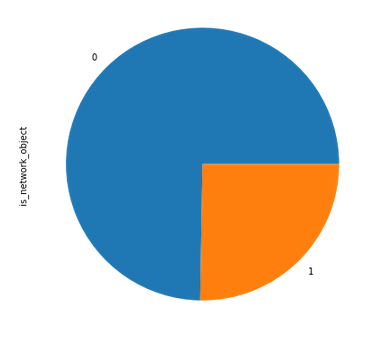
И напоследок — немного более сложной экономической статистики. Что если поделить все ТПУ на группы от проектируемых до уже сданных в эксплуатацию? Какое стандартное отклонение (сигма), в рублях, за аренду торговых площадей или, скажем, при приобретении отдельно стоящих зданий будет в этих группах?

Судя по графикам, разброс цен на аренду и покупку недвижимости около уже построенных ТПУ заметно больше, рынок недвижимости стабильнее в районах со строящимися или проектируемыми ТПУ. Это можно использовать для оценки эффективности инвестиций в недвижимость.
Представленные графики — лишь малая часть потенциала датасета, который может быть расширен в дальнейшем.
Наш датасет включает в себя большое количество демографических, географических, экономических и описательных данных, которые расширяют представление об имеющихся объектах торговли и услуг.
Спектр применения этих данных очень широк. Они могут быть сегментированы или объединены в новые признаки, на основе которых можно строить модели машинного обучения. Наиболее очевидные варианты применения:
Датасет может быть интересен:
Недостатки нашего датасета обусловлены объективными причинами — многие информационные источники содержат неточные или неполные сведения, что невозможно нивелировать постобработкой. Часть сведений вообще невозможно найти в открытом доступе. Однако мы создали все условия, чтобы на практике данные можно было легко обновить или добавить новые.
При использовании датасета стоит учитывать наиболее проблемные участки, которые могут создать заметные шумы. Особое внимание стоит обратить на следующие нюансы:
Весь процесс обработки закомментирован и может быть воспроизведён, в том числе при изменении данных в оригинальных источниках. Мы подумали об удобстве дальнейшего использования и постарались минимизировать необходимость дальнейшей предобработки для использования в обучении моделей путем:
Надеемся, что наши наработки не останутся без внимания и их будут использовать для обучения моделей и поиска инсайтов как в учебных целях, так и для решения проблем реального бизнеса.
GitHub и сайт датасета.
Узнать больше про магистратуру можно на сайте data.misis.ru и в Telegram канале.
Артем Филиппенко — Тимлид / Программирование / Автор статьи
Юлия Компаниец — Программирование / Алгоритмизация / Визуализация
Егор Петров — Программирование / Парсинг / Поддержка репозитория
Вячеслав Кандыбин — Парсинг / Поиск источников
Ильдар Габитов — Координация / Анализ
Сергей Гильдт — Помощь в составлении статьи
Ну и конечно не магистратурой единой! Хотите узнать больше про машинное и глубокое обучение — заглядывайте к нам на соответствующий курс, будет непросто, но увлекательно. А промокод HABR — поможет в стремлении освоить новое, добавив 10% к скидке на баннере.

Датасет содержит полный список объектов торговли и услуг в Москве с транспортными, экономическими и географическими метаданными. Исходная гипотеза состоит в том, что близость объекта к транспортным узлам является одним из важнейших показателей и ключевым фактором экономического успеха. Мы попросили команду детально описать свой опыт сбора такого датасета, и вот что получилось.
TLTR: Ближе к концу статьи вы найдёте информативные графики, карты и ссылки.
Немного про сам Дататон
Программа магистратуры «Наука о данных» НИТУ МИСиС и Zavtra.Online рассчитана на два года — т.е четыре семестра и раз в семестр для студентов будет проводиться хакатон, делая обучение больше ориентированным на решение практических задач. Первый хакатон был посвящен сбору датасета, поэтому и назвали его соответственно — «Дататон».
Всего в Дататоне приняло участие 90 студентов. Перед ними поставили задачу — собрать датасет, который может использоваться в продукте, основанном на Data Science.
Идею для сбора датасета предлагали сами студенты, с оглядкой на потребности общества или бизнеса — так что актуальность стала одним из главных критериев оценки и выбора победителей.
Оценивать команды позвали менторов — практикующих специалистов по Data Science высокого уровня из таких компаний как: Align Technology, Intellivision, Wrike, Мерлин АИ, Лаборатория Касперского, Auriga, Huawei, SkillFactory.
Начало работы над датасетом
При выборе темы для нашего датасета мы руководствовались известным принципом «предвидеть — значит управлять». Поиск новых гипотез — не самая простая задача, особенно когда одними из критериев выступают практичность и ориентация на потребности гипотетического заказчика. Трудно найти неразмеченную область, используя только лишь открытые данные.
Основная работа по сбору и обработке была проделана за 5 дней, остальное время до публикации мы исправляли недостатки, незначительно обогащали датасет и оптимизировали его структуру.
Фундаментальной идеей нашего датасета является гипотеза, что окрестности перспективных транспортно-пересадочных узлов Москвы (далее — ТПУ) станут хорошими зонами для развития бизнеса. Что вообще представляет из себя концепция ТПУ?
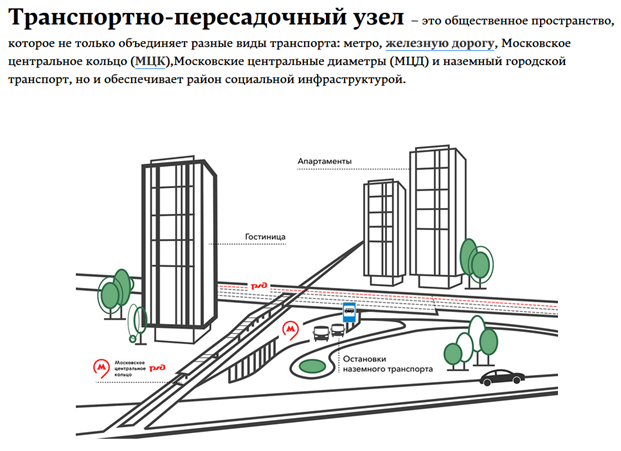
Источник: stroi.mos.ru
Какие проблемы решает датасет?
Основная гипотеза тривиальна и лежит на поверхности. Больший интерес представляют уточняющие вопросы от потенциального предпринимателя, которые можно задать, основываясь на ней. Например:
- Я хочу открыть новую торговую точку по адресу X, сколько прямых конкурентов будет вокруг?
- В окрестностях какого из строящихся ТПУ будут самые благоприятные условия для развития торговой точки?
- В каких условиях сейчас работают мои непосредственные конкуренты?
- Будет ли моя торговая точка входить в зону охвата уже существующего или строящегося ТПУ?
- Мои клиенты используют автомобили, где лучше разместиться, чтобы им было удобнее посещать мой магазин?
Таких вопросов может быть множество. Более того, часть из них порождает целое дерево уточняющих вопросов, которые играют важную роль при создании нового бизнеса или расширении действующего.
Наш датасет может служить основой для аналитики и обучения линейных или логистических регрессий, задач классификации или кластеризации. Он подходит для наглядной визуальной демонстрации действующих объектов торговли и услуг в Москве с привязкой к крупным транспортным узлам города. Мы уверены, что он содержит множество «скрытых данных», которые ждут, когда их обнаружат.
1. Описание источников
1.1 Источники
В датасете были использованы следующие данные с сайта Портал открытых данных правительства города Москвы:
Другие источники:
- Расчёт торговой зоны и зоны охвата магазина был произведён на основе таблицы из статьи «Расчёт торговой зоны и зоны охвата магазина».
- Информация о районах: Wikipedia: Список районов и поселений Москвы.
- Информация о ценах на коммерческую недвижимость: по данным на сайте агентства Restate.
- Сведения о пассажиропотоке на станциях: Рекламное агентство Метро Москвы.
- Геоданные о форме административных районов и округов Москвы.
1.2 Структура датасета
Основу структуры данных составляют уникальные объекты торговли и услуг, каждому из которых соответствует набор метаданных, включающих в себя такие сведения, как:
- Информация о ближайшем ТПУ.
- Информация о районе размещения.
- График работы и транспортная доступность.
- Данные о стоимости коммерческой недвижимости в районе.
- Данные о зоне охвата и размере объекта.
Часть данных представлена в виде словарей, что связано с вложенностью отдельных признаков. Например, ряд ТПУ представляет собой комплекс из отдельных объектов наземного и подземного транспорта, и рассматривать их по отдельности нелогично. Но при необходимости эти вложенные объекты легко могут быть извлечены, что мы и выполняем при визуализации объектов на карте.
Для сложных вложенных объектов мы использовали списки и словари, поскольку организованный доступ к такой структуре значительно проще, нежели парсинг строковых объектов. В целом датасет содержит большое разнообразие типов данных.

Это пример не только объединения, но и неточности отдельных полей, о чем будет следующий раздел
1.3 Качество данных и проблемы при их сборе
Качество исходных данных в целом оказалось удовлетворительным, но недостаточным для реализации всех наших амбиций. В ходе проверки мы обнаружили, что Москва значительно уступает по этому показателю ряду мировых столиц. Также мы заметили некоторые ошибки и неточности, которые пришлось обрабатывать как отдельные выбросы или оставлять на совести авторов источников.
- Сведения по статусу и срокам сдачи отдельных ТПУ можно считать устаревшими.
- Обнаружилась путаница в единичных случаях указаниях широты и долготы, из-за чего некоторые объекты «убегали» в другие страны.
- Данные о пассажиропотоке опубликованы с неточностями в форматировании, отдельные записи явно сильно завышены. Яркий пример — данные по пассажиропотоку на станции «Авиамоторная». Цифра в 400 000 пассажиров в сутки кажется явно завышенной, впрочем, как и в ряде других случаев. Беглый поиск показал, что реальная цифра может быть в разы меньше. Исправить такие артефакты крайне сложно.
- Данные о ценах на коммерческую недвижимость пришлось собирать в ручном режиме.
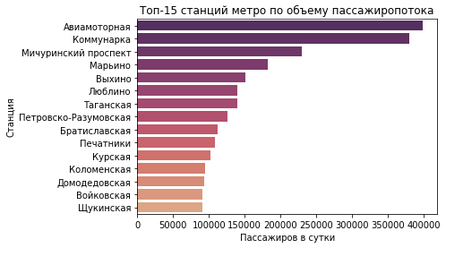
Пример спорных данных
2. Обработка данных
2.1 Данные об объектах
После предварительной оценки имеющихся в распоряжении первичных данных (а это были данные об объектах торговли, услуг и ТПУ на территории Москвы) мы поняли, что ключевым элементом нашего датасета будут уникальные объекты торговли и услуг, которые мы объединили в единый центральный датасет. Всего мы получили более 78 000 записей, для которых помимо уникального ID и названия имеются сведения о:
- Времени работы.
- Типе объекта.
- Принадлежности к сетевым объектам.
- Адресе и координатах расположения.
- Административной принадлежности.
2.2 Данные об административном делении
Эту информацию, в том числе географические и демографические параметры, мы обнаружили на Википедии в относительно актуальном состоянии на начало 2020 года. Мы автоматизировали процесс выгрузки сведений путём написания собственной функции для парсинга html-страниц. Незначительными трудностями, с которыми мы столкнулись, стали:
- Использование специальных символов для сносок.
- Необходимость приведения всех данных к общим единицам измерения.
В дальнейшем мы нашли геоданные о границах районов. Эта информация оказалась очень полезна при визуальном отображении слоев на карте.
2.3 Данные о зонах охвата
Зоны охвата являются не объективной оценкой, а лишь одной из теоретических методик оценки эффективности того или иного объекта торговли. Мы обнаружили методику оценки, которая разделяет объекты на 4 группы. В нашем случае достаточно было ввести лишь 3 из них — маленькие, средние и большие. Разделение мы осуществляли путем анализа типов и названий объектов. Например, приставка «Гипер-» с большой долей вероятности соответствует большому объекту. Исходя из размера мы определили зону, в радиусе которой торговый объект является привлекательным для клиентов.
2.4 Данные о ТПУ
В имеющемся датасете под ТПУ подразумевается любой транспортный объект, которых на территории Москвы более 250. Поэтому нам пришлось объединять их в комплексы, исходя из названий и расстояний между ними. Сведения об объектах включают в себя такие данные, как:
- Административные данные и географическое расположение.
- Типы транспорта.
- Год сдачи и статус объекта (от проекта до завершения).
- Ближашая станция.
В теории они легко объединяются в кластеры, но на практике обнаружился ТПУ «Планерная», который рушил всю систему. Одна станция находится в районе метро «Речной вокзал», а вторая — за Химками. Расстояние между ними составляет около 6 км, и очевидно, что учитывать их как единый комплекс при расчёте транспортной доступности нельзя. Подобные отклонения вносят шум в данные и вынуждают создавать сложные алгоритмы обработки.
Каждый полученный комплекс центрирован относительно всех включенных объектов, при этом мы сохранили все данные об исходных ТПУ — они хранятся внутри в виде словарей, где ключами выступают оригинальные ID ТПУ.
2.5 Данные о стоимости аренды и покупки коммерческой недвижимости
Этот раздел стал одним из самых сложных, поскольку всё, что связано с недвижимостью, сильно монетизировано и является ценной информацией. В открытом виде актуальные сведения по каждому району получить очень трудно. Риэлторские агентства и торговые площадки не предоставляют бесплатные API, а парсинг торговых площадок был слишком ресурсозатратным в условиях ограничений срока проекта.
Поэтому мы не стали изобретать велосипед, а просто нашли наиболее удобный ресурс и вручную сохранили статистические сведения о стоимости продажи и аренды коммерческой недвижимости для торговых объектов, отдельно стоящих зданий и объектов общего назначения за 2020 год.
Несмотря на значительное количество пропусков и отдельные неточности, эти данные отражают ситуацию на рынке недвижимости и строятся на реальных объявлениях.
2.6 Данные о пассажиропотоке на станциях метро
Эта секция тоже оказалась достаточно проблемной, поскольку изначально идея найти такие сведения в актуальном виде показалась нереальной, а официальные ответы оказалось ждать очень долго (и не факт, что они были бы положительными). Долгое время эта задача оставалось нерешённой, и нам пришлось повторно рассматривать буквально каждую крупицу информации, даже явно устаревшей.
Иронично, что обнаруженная ошибка в старом источнике позволила обнаружить подходящие данные. После повторной проверки мы поняли, что в одном из источников использованы данные за 2019 год, при этом подпись содержит указание на 2016 год. Эта подпись и сбила нас при первой оценке. Актуальность подтвердилась наличием данных по построенным в 2019 году объектам метро.
Впрочем, сами данные тоже оказались не оптимизированы для парсинга. Мы столкнулись с дублями и артефактами типа «100000 тыс. тыс. чел в сутки», которые пришлось отыскивать и приводить к общему виду. Тем не менее, как уже упомянуто в разделе о качестве данных, отдельные показатели по станциям явно завышены и ошибочны. И эту проблему можно решить только уточнением из первоисточника.
2.7 Новые признаки и данные
Собрать числовые или строковые данные — мало. Эти данные важно уметь трактовать и выделять на их основе новые параметры или свойства. Поскольку наша гипотеза строилась на принадлежности объекта к ближайшему ТПУ, мы написали алгоритм поиска ближайших объектов и для каждого уникального объекта сопоставили:
- Параметры ближайшего ТПУ.
- Расстояние до ТПУ.
- Радиус охвата объекта.
- Входит ли ТПУ в зону охвата?
- К какому классу относится объект?

Небольшой кусок датасета с бинарными признаками
2.8 Итоговый датасет
В результате объединения мы получили датасет размерностью 44 столбца и 78086 строк. В формате Pandas он занимает около 25,9+ MB. Если разбить столбцы на тематические сегменты, то в нём содержатся данные о:
- Объекте.
- Близлежащем ТПУ и его составе.
- Районе объекта.
- Стоимости покупки и аренды площадей.
2.9 Корреляционная матрица
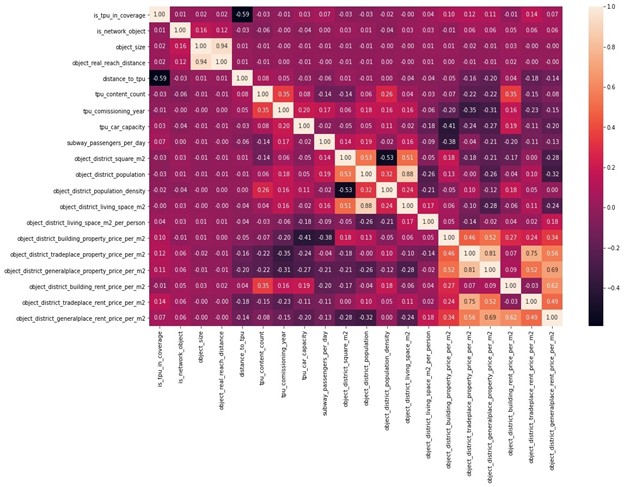
Что можно сказать по полученной корреляционной матрице?
- Данные по стоимости коммерческой недвижимости заметно более коррелированы, а значит, использовать их стоит осторожно.
- Первая идея, которая приходит в голову, — создание на их основе новых индексов оценки.
- Демографические признаки также ожидаемо имеют выраженную положительную корреляцию.
- Большой отрицательный сдвиг наблюдается между стоимостью коммерческой недвижимости и демографическими признаками районов, что в целом логично.
Остальные взаимосвязи между параметрами не столь явные, и трудно сделать по ним однозначные выводы.
3. Немного визуализаций
3.1 Датасет на карте Москвы
Наконец-то мы дошли до самой интересной части любого датасета, своеобразный момент истины! Апогеем сбора является визуализация данных, где можно не только оценить качество данных, но и найти коллизии, ошибки и выбросы.
Для визуализации мы написали свою функцию, которая использует библиотеку Folium. Метод удобен тем, что достаточно гибко визуализирует практически любые выборки из общего датасета. Параметры функции позволяют гибко настраивать визуальные признаки объектов. Поскольку каждый объект в нашем случае — слой, мешающие группы объектов легко отключить и оставить лишь необходимые.
Для большей наглядности на карте реализованы слои в виде административного деления по районам. В нашем случае за стандартное отображение мы приняли плотность объектов на каждый район города.
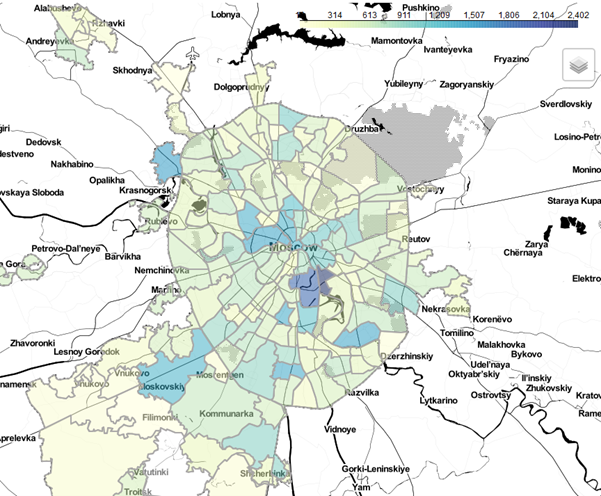
Пример отображения районов по плотности размещения объектов
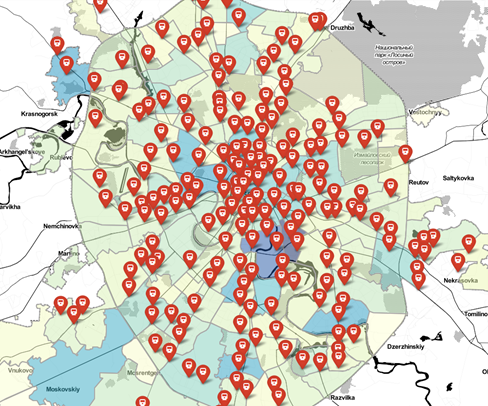
Транспортная схема Москвы: здесь отображаются только ТПУ
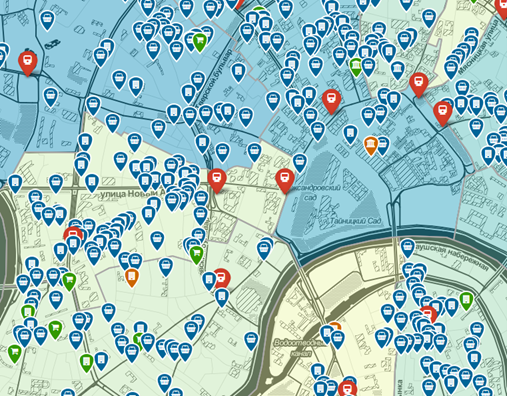
Пример отображения с объектами — в данной выборке всего 10000 объектов из более чем 78 000
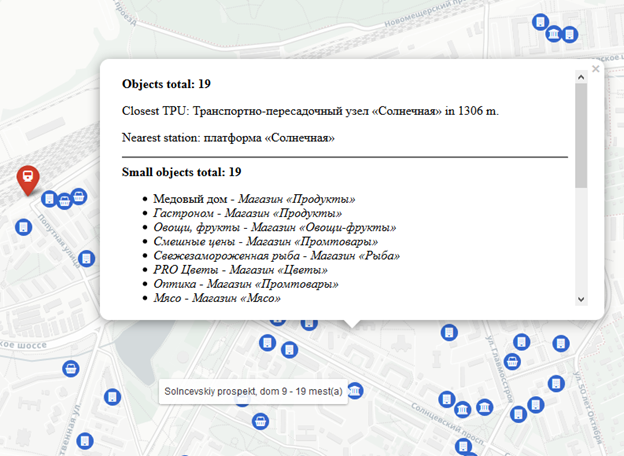
Пример отображения объектов по выделенному адресу — описание сформировано в виде HTML-кода
3.2 (Не)много графиков
Графики — отличный инструмент для анализа. В качестве демонстрации мы подготовили ряд графиков, чтобы наглядно продемонстрировать статистику по наиболее интересным параметрам датасета.
Вот, например, 20 крупнейших торговых сетей Москвы:

А если посмотреть, какие типы объектов самые популярные?
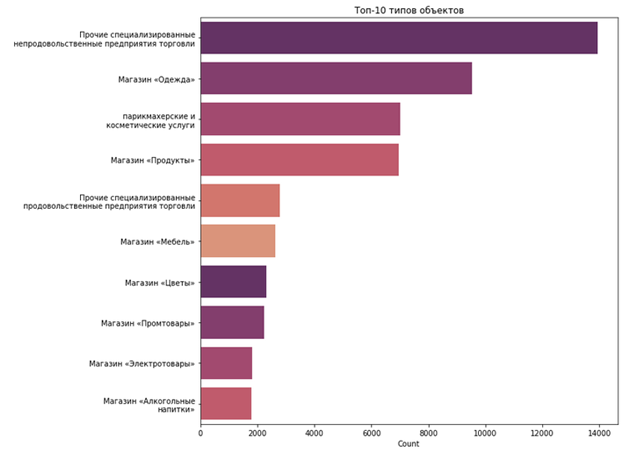
По типам услуг всё не так интересно, зато понятно, сколько всего объектов каждого типа есть в городе.
Теперь чуть более интересные цифры — количество объектов при ТПУ.

Руки чешутся посмотреть на самый верхний ТПУ «Профсоюзная». Почему бы и да? На этом скриншоте размещаются больше 2000 объектов, для которых этот ТПУ ближайший.
Хорошо, как насчёт того, чтобы узнать, сколько из объектов в городе являются сетевыми? Получается красивый пирог с почти идеальной четвертью. Занятно. Пусть 1 и 0 вас не пугают, это как раз и есть пример бинарного признака, где 1 означает, что объект входит в какую-либо крупную сеть.

Раз уж мы решили строить топы, почему бы не узнать адрес, по которому располагается большее число объектов? Легко!

Найти его не так уж сложно. Список впечатляет:

И напоследок — немного более сложной экономической статистики. Что если поделить все ТПУ на группы от проектируемых до уже сданных в эксплуатацию? Какое стандартное отклонение (сигма), в рублях, за аренду торговых площадей или, скажем, при приобретении отдельно стоящих зданий будет в этих группах?

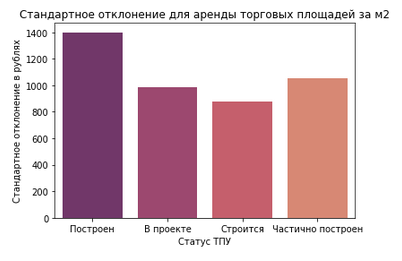
Судя по графикам, разброс цен на аренду и покупку недвижимости около уже построенных ТПУ заметно больше, рынок недвижимости стабильнее в районах со строящимися или проектируемыми ТПУ. Это можно использовать для оценки эффективности инвестиций в недвижимость.
Представленные графики — лишь малая часть потенциала датасета, который может быть расширен в дальнейшем.
4. Заключение
4.1 Варианты применения
Наш датасет включает в себя большое количество демографических, географических, экономических и описательных данных, которые расширяют представление об имеющихся объектах торговли и услуг.
Спектр применения этих данных очень широк. Они могут быть сегментированы или объединены в новые признаки, на основе которых можно строить модели машинного обучения. Наиболее очевидные варианты применения:
- Визуализация объектов и ТПУ по определённым критериям. Например: отобразить на карте новые объекты, которые будут сданы в 2022 году.
- Анализ типов объектов и условий их работы. Например: составить статистику о графиках работы ближайших конкурентов и проанализировать результаты.
- Проверка известных гипотез на имеющихся практических данных. Например: добавить в датасет известные данные по обороту торговой сети и сопоставить с данными по пассажиропотоку и пешей доступности.
4.2 Целевая аудитория
Датасет может быть интересен:
- Девелоперам,
- Инвесторам,
- Бизнесу (торговля и услуги),
- Риэлторам и консультантам,
- Частным исследователям и урбанистам.
4.3 Достоинства и недостатки
Недостатки нашего датасета обусловлены объективными причинами — многие информационные источники содержат неточные или неполные сведения, что невозможно нивелировать постобработкой. Часть сведений вообще невозможно найти в открытом доступе. Однако мы создали все условия, чтобы на практике данные можно было легко обновить или добавить новые.
При использовании датасета стоит учитывать наиболее проблемные участки, которые могут создать заметные шумы. Особое внимание стоит обратить на следующие нюансы:
- Статус и год ввода в эксплуатацию некоторых ТПУ сомнителен — данные требуют проверки и актуализации.
- Значения пассажиропотока требуют уточнения, особенно самые большие.
- Размер отдельных крупных и средних объектов требует уточнения, поскольку в датасете могут быть ошибки, связанные с ограничениями методики классификации. Например, по использованию «Торговый дом» в названии алгоритм может неверно присвоить класс, что повлияет на дальнейшие выборки.
Весь процесс обработки закомментирован и может быть воспроизведён, в том числе при изменении данных в оригинальных источниках. Мы подумали об удобстве дальнейшего использования и постарались минимизировать необходимость дальнейшей предобработки для использования в обучении моделей путем:
- Преобразования некоторых данных к бинарному представлению — 1/0.
- Приведения всех отсутствующих данных к единой форме «NaN».’
- Создания служебных колонок, описывающих длину вложенных словарей.
- Разбиения столбцов на логические секции и с детальными именами.
- Опоры на источники. Все данные могут быть получены путём непосредственного доступа к первоисточнику.
- Упрощения визуализации. Она организована удобными функциями, которые принимают на вход много служебных параметров и сводят отображение нужных данных к паре строк кода.
4.4 Вместо резюме
Надеемся, что наши наработки не останутся без внимания и их будут использовать для обучения моделей и поиска инсайтов как в учебных целях, так и для решения проблем реального бизнеса.
GitHub и сайт датасета.
Узнать больше про магистратуру можно на сайте data.misis.ru и в Telegram канале.
Участники команды Data SkyScrapers
Артем Филиппенко — Тимлид / Программирование / Автор статьи
Юлия Компаниец — Программирование / Алгоритмизация / Визуализация
Егор Петров — Программирование / Парсинг / Поддержка репозитория
Вячеслав Кандыбин — Парсинг / Поиск источников
Ильдар Габитов — Координация / Анализ
Сергей Гильдт — Помощь в составлении статьи
Мы хотели бы выразить благодарность кураторам, преподавателям и экспертам за организацию Дататона. Это был отличный опыт и возможность самостоятельно проявить себя в решении практических задач, а также получить развернутую оценку от профессиональных Дата-сайентистов.
Ну и конечно не магистратурой единой! Хотите узнать больше про машинное и глубокое обучение — заглядывайте к нам на соответствующий курс, будет непросто, но увлекательно. А промокод HABR — поможет в стремлении освоить новое, добавив 10% к скидке на баннере.

- Курс по Machine Learning
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Обучение профессии Data Science
- Обучение профессии Data Analyst
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
- Профессия Java-разработчик
- Профессия Frontend-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
- Профессия Веб-разработчик
КУРСЫ
- Курс «Python для веб-разработки»
- Курс по JavaScript
- Курс «Математика и Machine Learning для Data Science»
- Курс по аналитике данных
- Курс по DevOps
