В скором времени у нас стартует новый поток продвинутого курса «Machine Learning Pro + Deep Learning», а сегодня мы делимся постом, в котором рассказывается о подходах к реставрации с помощью глубокого обучения. Реставрация изображений в разрезе глубокого обучения — это задача заполнения потерянных пикселей так, чтобы итоговое изображение выглядело реалистично и соответствовало оригинальному контексту. Некоторые приложения метода, такие как удаление нежелательных объектов и интерактивное редактирование изображений, показаны на кдпв. Приложений на самом деле так много, как вы только можете себе представить.

Этот пост может рассматриваться как переработка материалов о реставрации через глубокое обучение для моих друзей или новичков. Я написал более 10 постов, связанных с подходами к реставрации изображений с помощью глубокого обучения. Настало время для краткого обзора того, чему научились читатели этих статей, а также для того, чтобы написать быстрое введение для новичков, которые хотят получить удовольствие вместе с нами.

Рис. 1. Пример повреждённого входного изображения (слева) и результата реставрации (справа). Изображение взято со страницы автора на Github
В показанном на рисунке 1 повреждённом вводе обычно определяются: а) неверные, пропущенные пиксели или дыры в качестве пикселей, расположенных в областях, которые должны быть заполнены; б) корректные, оставшиеся, настоящие пиксели, которыми мы можем воспользоваться, чтобы заполнить отсутствующие. Обратите внимание, что мы можем взять корректные пиксели и заполнить ими соответствующие связанные места.
Простейший способ заполнения отсутствующих частей — копирование и вставка. Ключевая идея — первым поиском найти самые похожие кусочки изображения из его оставшихся пикселей или найти их в большом наборе данных с миллионами изображений, затем напрямую вставить кусочки в отсутствующие части. Однако выполнение алгоритма поиска может занять много времени и включает в себя созданные вручную метрики измерения расстояния. Обобщение алгоритма и его эффективность ещё нуждаются в улучшении.
Благодаря подходам на основе глубокого обучения в эру больших данных у нас есть управляемые данными подходы к реставрации на основе глубокого обучения, с этими подходами мы генерируем пропущенные пиксели с хорошей согласованностью и мелкими текстурами. Посмотрим на 10 известных подходов к реставрации изображений на основе глубокого обучения. Уверен, что вы сможете понять и другие статьи, когда поймёте эти 10. Начнём.

Рис. 2. Архитектура сети контекстного энкодера (CE).
Контекстный энкодер (CE, 2016) [1] — первая реализация реставрации на основе GAN. Эта работа освещает полезные базовые понятия задач реставрации. Понятие «контекст» связано с пониманием изображения как такового, суть идеи энкодера — полносвязные слои по каналам (средний слой сети показан на рисунке 2). Подобно стандартному полносвязному слою, основной момент заключается в том, что все местоположения элементов на предыдущем слое будут вносить вклад в каждое местоположение элемента на текущем слое. Так сеть изучает взаимосвязь между всеми расположениями элементов и получает более глубокое семантическое представление всего изображения. CE рассматривается как базовый уровень, вы можете узнать больше о нём в моем посте [здесь].
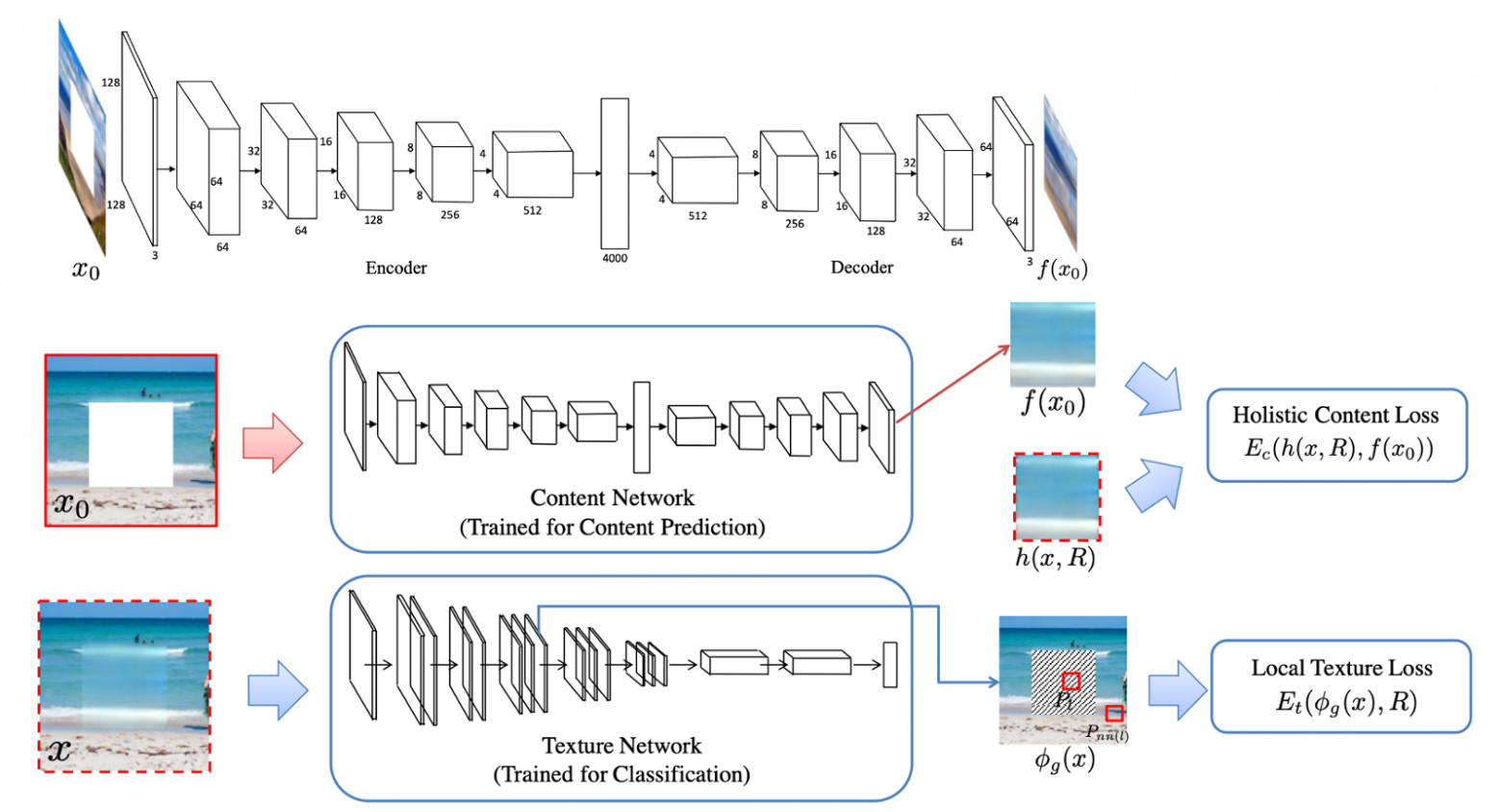
Рис. 3. Обзор контентной сети (модифицированный CE) и текстурной сети (VGG-19).
Мультимасштабный синтез нейронных патчей (MSNPS, 2016) [3] можно рассматривать как расширенную версию CE [1]. Авторы этой статьи использовали модифицированный CE для прогнозирования недостающих частей в изображении и текстурную сеть, чтобы декорировать прогноз для улучшения качества относительно недостающих частей заполняемой модели. Идея текстурной сети взята из задачи переноса стиля. Мы хотели перенести стиль наиболее похожих существующих пикселей на сгенерированные пиксели, чтобы улучшить детализацию локальной текстуры. Я бы сказал, что эта работа — ранняя версия двухэтапной структуры сети «от грубого к тонкому». Первая сеть контента (то есть здесь CE) отвечает за реконструкцию/прогнозирование недостающих частей, а вторая сеть (то есть сеть текстур) отвечает за уточнение заполняемых частей.
Кроме типичных пиксельных потерь при реконструкции (т. е. потерь L1) и стандартных состязательных потерь (Adversarial loss) концепция потери текстуры, предложенная в этой статье, играет важную роль в более поздних работах по реставрации изображений. На самом деле, потеря текстуры связана с перцептивной потерей и потерей стиля, которые широко используются во многих задачах генерации изображений, таких как нейронный перенос стиля. Чтобы узнать больше об этой статье, вы можете обратиться к моему предыдущему посту [здесь].

Рис. 4. Обзор предлагаемой модели, которая состоит из завершающей сети (сети «Генератора»), а также глобального и локального дискриминаторов.
Глобально и локально согласованное завершение изображения (GLCIC, 2017) [4] — веха в реставрации изображений через глубокое обучение, поскольку она определяет полностью свёрточную сеть с расширенными свёртками для этой области и на самом деле это типичная архитектура сети в реставрации изображений. Используя расширенные свертки, сеть способна понимать контекст изображения без использования дорогостоящих полносвязных слоёв и, следовательно, может обрабатывать изображения разных размеров.
Помимо полностью свёрточной сети с расширенными свёртками, также вместе с генераторной сетью обучались два дискриминатора на двух масштабах. Глобальный дискриминатор смотрит на всё изображение, тогда как локальный дискриминатор смотрит на заполняемую центральную область. С помощью как глобальных, так и локальных дискриминаторов заполненное изображение имеет лучшую глобальную и локальную согласованность. Обратите внимание, что многие более поздние статьи о реставрации изображений следуют этой конструкции мультимасштабных дискриминаторов. Если вы заинтересовались, пожалуйста, прочитайте мой предыдущий пост [здесь], чтобы получить больше информации.

Рис. 5. Предлагаемая архитектура генеративной ResNet и дискриминатор PGGAN.
Реставрацию на основе патчей с помощью сетей GAN [5] можно рассматривать как вариант GLCIC [4]. Проще говоря, две продвинутые концепции, а именно остаточное обучение [6] и PatchGAN [7], встроены в GLCIC для дальнейшего повышения производительности. Авторы этой статьи объединили остаточное соединение и расширенную свёртку, чтобы сформировать расширенный остаточный блок. Традиционный дискриминатор GAN был заменён дискриминатором PatchGAN, чтобы способствовать лучшим локальным деталям текстуры и согласованности глобальной структуры.
Основное различие между традиционным дискриминатором GAN и дискриминатором PatchGAN — в том, что традиционный дискриминатор GAN даёт только одну прогнозную метку (от 0 до 1), чтобы указать реалистичность входного сигнала, в то время как дискриминатор PatchGAN даёт матрицу меток (также от 0 до 1), чтобы указать реалистичность каждой локальной области входного сигнала. Обратите внимание, что каждый элемент матрицы представляет собой локальную область входных данных. Вы также можете ознакомиться с обзором остаточного обучения и PatchGAN [посетив этот мой пост].

Рис. 6. Архитектура сети Shift-Net. Слой соединения-сдвига добавляется с разрешением 32x32.
Shift-Net [8] использует как преимущества современных управляемых данными CNN, так и традиционный метод «копирования и вставки» в виде глубокого перераспределения элементов с использованием предложенного слоя соединений-сдвигов. В этой статье есть две основные идеи.
Во-первых, авторы предложили потерю ориентира, которая побуждает декодированные элементы отсутствующих частей (учитывая скрытую часть изображения) быть близкими к кодированным элементам отсутствующих частей (учитывая хорошее состояние изображения). В результате процесс декодирования может восполнить недостающие части с их разумной оценкой в изображении в хорошем состоянии (то есть источнике истины для недостающих частей).
Во-вторых, предлагаемый слой соединения-сдвига позволяет сети эффективно заимствовать информацию, предоставленную ближайшими соседями за пределами отсутствующих частей, для уточнения как глобальной семантической структуры, так и деталей локальной текстуры сгенерированных частей. Проще говоря, мы предоставляем подходящие ссылки для уточнения нашей оценки. Я думаю, что читателям, интересующимся реставрацией изображений, будет полезно закрепить предложенные в этой статье идеи. Я настоятельно рекомендую вам прочитать предыдущий пост [здесь] для получения подробной информации.

Рис. 7. Архитектура сети предлагаемого фреймворка.
Генеративную реставрацию с помощью контекстного внимания (CA, 2018), также называемую DeepFill v1 или CA [9], можно рассматривать как расширенную версию или вариант Shift-Net [8]. Авторы развивают идею копирования и вставки и предлагают слой контекстного внимания, дифференцируемый и полностью свёрточный.
Подобно слою соединения-сдвига в [8], сопоставляя сгенерированные элементы внутри пропущенных пикселей и характеристики вне пропущенных пикселей, мы можем узнать вклад всех элементов вне пропущенных пикселей в каждое местоположение внутри пропущенных пикселей. Следовательно, комбинация всех элементов снаружи может использоваться для уточнения сгенерированных элементов внутри недостающих пикселей. По сравнению со слоем соединения-сдвига, который ищет только самые похожие признаки (т. е. жёсткое, недифференцируемое назначение), слой CA в данной статье использует мягкое, дифференцируемое назначение, в котором все признаки имеют свои собственные веса, чтобы указать их вклад в каждое место внутри недостающих пикселей. Чтобы узнать больше о контекстном внимании, пожалуйста, прочитайте мой предыдущий пост [здесь], в нём вы найдёте примеры конкретнее.
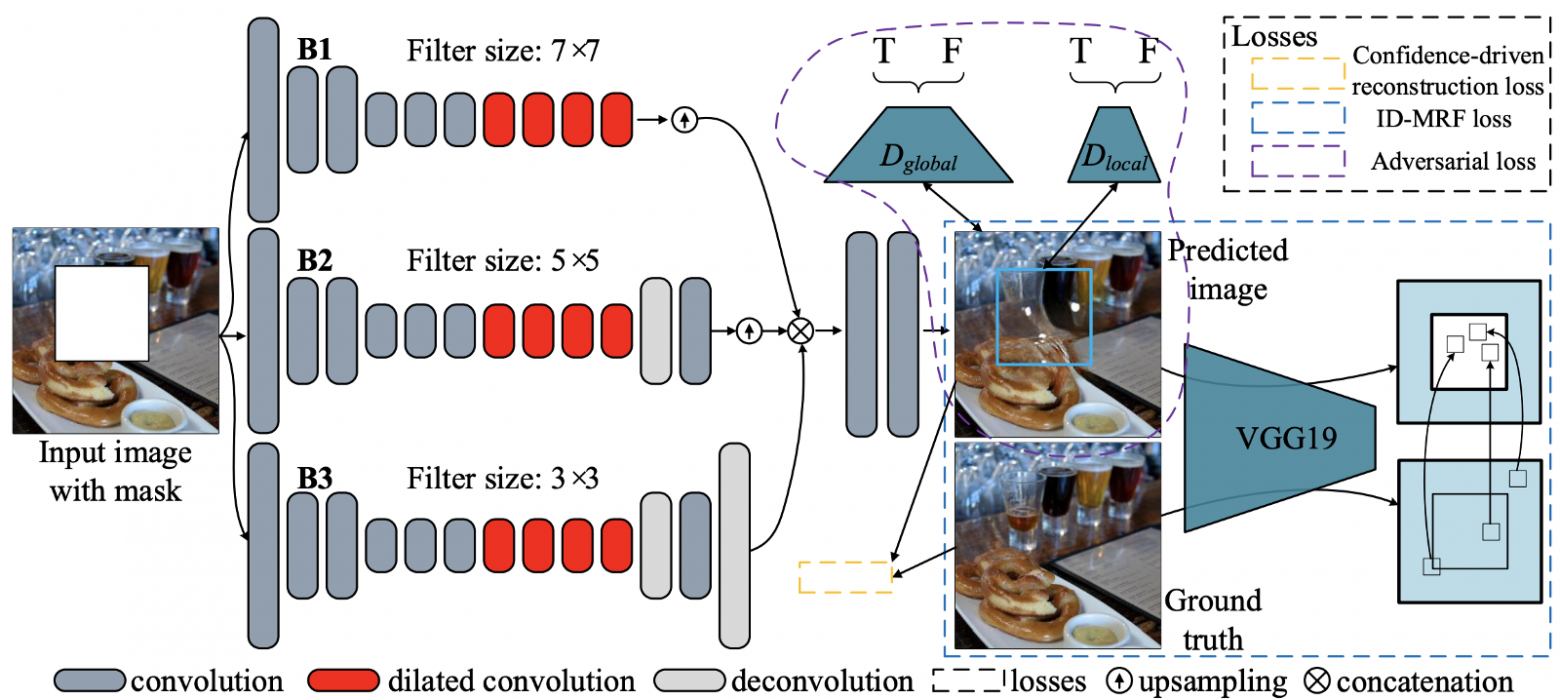
Рис. 8. Архитектура предлагаемой сети.
Генеративные мультиколоночные сверточные нейронные сети (GMCNN, 2018) [10] расширяют важность достаточных рецептивных полей для реставрации изображений и предлагают новые функции потерь для дальнейшего улучшения локальных текстурных деталей генерируемого контента. Как показано на рисунке 9, существует три ветви/колонки, и в каждой ветви используются три различных размера фильтров. Использование нескольких рецептивных полей (размеров фильтров) связано с тем, что размер рецептивного поля важен для задачи реставрации изображения. Поскольку локальные соседние пиксели отсутствуют, приходится заимствовать информацию, полученную из пространственно удалённых местоположений, чтобы заполнить локальные недостающие пиксели.
Для предлагаемых функций потерь основная идея потерь неявного диверсифицированного случайного поля Маркова (Implicit Diversified Markov Random Field — ID-MRF) заключается в том, чтобы направлять сгенерированные патчи элементов на поиск их ближайших соседей за пределами пропущенных областей в качестве ссылок, и эти ближайшие соседи должны быть достаточно диверсифицированы, чтобы можно было смоделировать больше деталей локальной текстуры. На самом деле, эта потеря — расширенная версия потерь текстуры, используемой в MSNPS [3]. Я настоятельно рекомендую вам прочитать мой пост [здесь], в нём представлено подробное объяснение этой потери.

Рис. 9. Визуальное сравнение предыдущих подходов, обученных с использованием обычных изображений с повреждениями и предложенного подхода частичной свёртки.
Реставрация пустот неправильной формы с помощью частичной свёртки (PartialConv или PConv) [11] расширяет границы глубокого обучения в реставрации изображений, предлагая способ обработки скрытых изображений с несколькими неправильными дырами. Очевидно, что основная идея этой статьи — частичная свёртка. При использовании PConv результаты свёртки будут зависеть только от допустимых пикселей, поэтому мы имеем контроль над передаваемой внутри сети информацией. Это первая работа о реставрации изображений, предназначенная для обработки неправильных пустот. Обратите внимание, что предыдущие модели для реставрации были обучены на правильных повреждённых изображениях, поэтому эти модели не подходят для реставрации изображений с неправильными пустотами.
Я привел простой пример, чтобы чётко объяснить, как выполняется частичная свёртка, в моем предыдущем посте [здесь]. Посетите ссылку и узнайте подробности. Надеюсь, вам понравится.

Рис. 10. Архитектура сети EdgeConnect. Как видите, есть два генератора и два дискриминатора.
EdgeConnect [12]: генеративная реставрация изображений с помощью Adversarial Edge Learning (EdgeConnect) [12] представляет интересный способ решения задачи реставрации изображений. Основная идея этой статьи состоит в том, чтобы разделить задачу реставрации на два шага с упрощением, а именно на прогнозирование краёв и завершение изображения на основе спрогнозированной карты краёв. Сначала прогнозируются края в недостающих областях, а затем завершения изображения в соответствии с прогнозом о краях. Большинство методов, используемых в этой статье, рассмотрены в моих предыдущих постах. Хорошо взглянуть на то, как различные методы могут использоваться вместе, чтобы сформировать новый подход реставрации изображений с помощью глубокого обучения. Возможно, вы разработаете свою собственную модель реставрации. Пожалуйста, посмотрите мой предыдущий пост [здесь], чтобы узнать больше об этой статье.
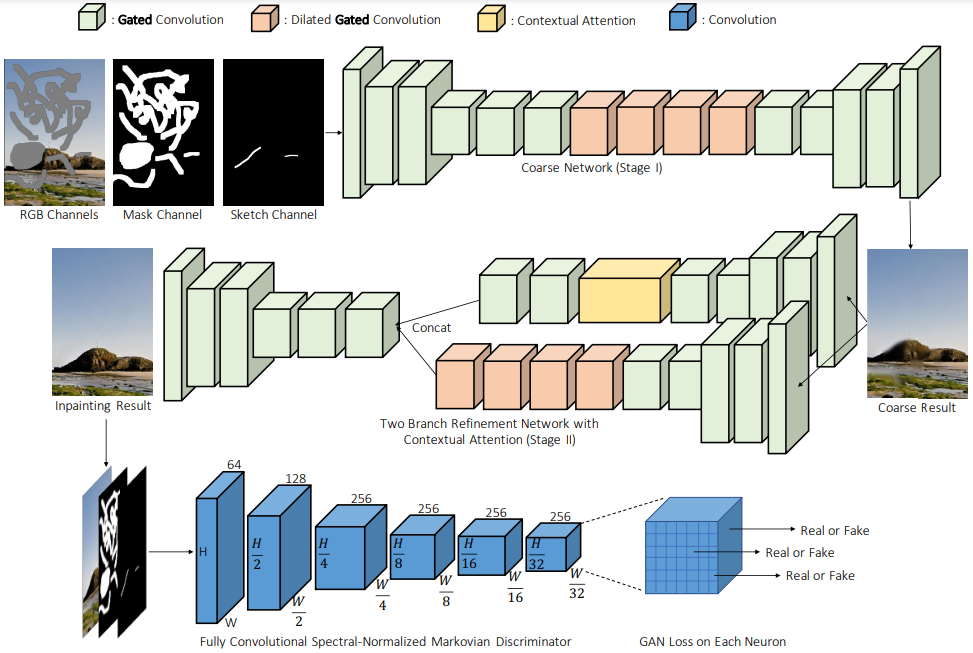
Рис. 11. Обзор архитектуры сети модели для свободной реставрации.
Реставрация свободной формы с помощью Gated Convolution (DeepFill v2 или GConv, 2019) [13]. Возможно, это самый практичный алгоритм реставрации изображений, который может использоваться непосредственно в ваших приложениях. Его можно рассматривать как расширенную версию DeepFill v1 [9], частичная свёртка [11] и EdgeConnect [12]. Основная идея работы — Gated Convolution, обучаемая версия частичной свёртки. Добавляя дополнительный стандартный свёрточный слой, за которым следует сигмоидная функция, можно узнать допустимость каждого местоположения пикселя/объекта, и, следовательно, также допускается дополнительный ввод пользовательского эскиза. помимо Gated Convolution, SN-PatchGAN используется для дальнейшей стабилизации обучения модели GAN. Чтобы узнать больше о разнице между частичной свёрткой и Gated Convolution, а также о том, как дополнительный пользовательский ввод эскиза может повлиять на результаты реставрации, пожалуйста, посмотрите мой последний пост [здесь].
Я надеюсь, теперь вы имеете базовое представление о реставрации изображений. Полагаю, что большинство распространённых методов, используемых в реставрации изображений с помощью глубокого обучения, рассмотрены в моих предыдущих постах. Если вы мой старый друг, я думаю, что теперь вы в состоянии понять другие работы о реставрации с помощью глубокого обучения. Если вы новичок, я хотел бы поприветствовать вас. Я надеюсь, что вы найдёте этот пост полезным для себя. На самом деле, этот пост даёт вам возможность присоединиться к нам и учиться вместе.
На мой взгляд, все еще сложно реставрировать изображения со сложными структурами сцены и большом количестве отсутствующих пикселей (например, когда нет 50 % пикселей). Разумеется, ещё одна сложная задача — реставрация изображений с высоким разрешением. Все эти задачи можно назвать экстремальными. Я думаю, что подход, основанный на новейших достижениях в области реставрации, в состоянии решить некоторые из этих проблем.

Этот пост может рассматриваться как переработка материалов о реставрации через глубокое обучение для моих друзей или новичков. Я написал более 10 постов, связанных с подходами к реставрации изображений с помощью глубокого обучения. Настало время для краткого обзора того, чему научились читатели этих статей, а также для того, чтобы написать быстрое введение для новичков, которые хотят получить удовольствие вместе с нами.
Терминология

Рис. 1. Пример повреждённого входного изображения (слева) и результата реставрации (справа). Изображение взято со страницы автора на Github
В показанном на рисунке 1 повреждённом вводе обычно определяются: а) неверные, пропущенные пиксели или дыры в качестве пикселей, расположенных в областях, которые должны быть заполнены; б) корректные, оставшиеся, настоящие пиксели, которыми мы можем воспользоваться, чтобы заполнить отсутствующие. Обратите внимание, что мы можем взять корректные пиксели и заполнить ими соответствующие связанные места.
Введение
Простейший способ заполнения отсутствующих частей — копирование и вставка. Ключевая идея — первым поиском найти самые похожие кусочки изображения из его оставшихся пикселей или найти их в большом наборе данных с миллионами изображений, затем напрямую вставить кусочки в отсутствующие части. Однако выполнение алгоритма поиска может занять много времени и включает в себя созданные вручную метрики измерения расстояния. Обобщение алгоритма и его эффективность ещё нуждаются в улучшении.
Благодаря подходам на основе глубокого обучения в эру больших данных у нас есть управляемые данными подходы к реставрации на основе глубокого обучения, с этими подходами мы генерируем пропущенные пиксели с хорошей согласованностью и мелкими текстурами. Посмотрим на 10 известных подходов к реставрации изображений на основе глубокого обучения. Уверен, что вы сможете понять и другие статьи, когда поймёте эти 10. Начнём.
Контекстный энкодер (первый алгоритм реставрации на основе GAN, 2016)

Рис. 2. Архитектура сети контекстного энкодера (CE).
Контекстный энкодер (CE, 2016) [1] — первая реализация реставрации на основе GAN. Эта работа освещает полезные базовые понятия задач реставрации. Понятие «контекст» связано с пониманием изображения как такового, суть идеи энкодера — полносвязные слои по каналам (средний слой сети показан на рисунке 2). Подобно стандартному полносвязному слою, основной момент заключается в том, что все местоположения элементов на предыдущем слое будут вносить вклад в каждое местоположение элемента на текущем слое. Так сеть изучает взаимосвязь между всеми расположениями элементов и получает более глубокое семантическое представление всего изображения. CE рассматривается как базовый уровень, вы можете узнать больше о нём в моем посте [здесь].
MSNPS (расширенный контекстный энкодер)

Рис. 3. Обзор контентной сети (модифицированный CE) и текстурной сети (VGG-19).
Мультимасштабный синтез нейронных патчей (MSNPS, 2016) [3] можно рассматривать как расширенную версию CE [1]. Авторы этой статьи использовали модифицированный CE для прогнозирования недостающих частей в изображении и текстурную сеть, чтобы декорировать прогноз для улучшения качества относительно недостающих частей заполняемой модели. Идея текстурной сети взята из задачи переноса стиля. Мы хотели перенести стиль наиболее похожих существующих пикселей на сгенерированные пиксели, чтобы улучшить детализацию локальной текстуры. Я бы сказал, что эта работа — ранняя версия двухэтапной структуры сети «от грубого к тонкому». Первая сеть контента (то есть здесь CE) отвечает за реконструкцию/прогнозирование недостающих частей, а вторая сеть (то есть сеть текстур) отвечает за уточнение заполняемых частей.
Кроме типичных пиксельных потерь при реконструкции (т. е. потерь L1) и стандартных состязательных потерь (Adversarial loss) концепция потери текстуры, предложенная в этой статье, играет важную роль в более поздних работах по реставрации изображений. На самом деле, потеря текстуры связана с перцептивной потерей и потерей стиля, которые широко используются во многих задачах генерации изображений, таких как нейронный перенос стиля. Чтобы узнать больше об этой статье, вы можете обратиться к моему предыдущему посту [здесь].
GLCIC (веха в реставрации с помощью глубокого обучения, 2017)
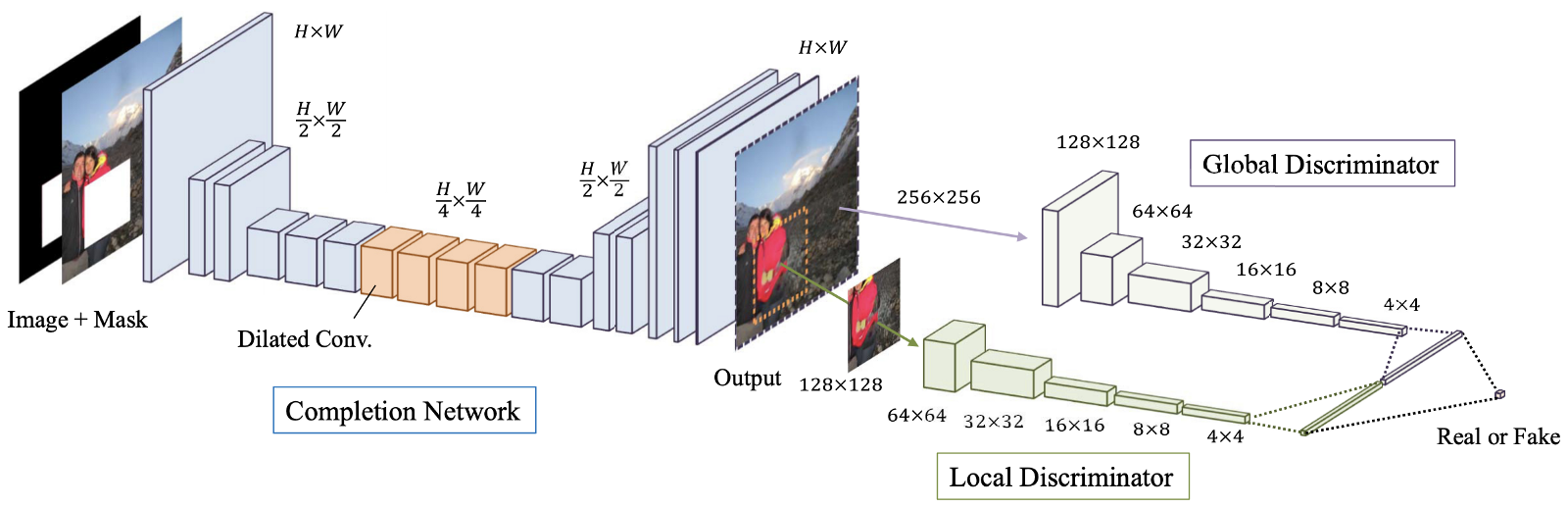
Рис. 4. Обзор предлагаемой модели, которая состоит из завершающей сети (сети «Генератора»), а также глобального и локального дискриминаторов.
Глобально и локально согласованное завершение изображения (GLCIC, 2017) [4] — веха в реставрации изображений через глубокое обучение, поскольку она определяет полностью свёрточную сеть с расширенными свёртками для этой области и на самом деле это типичная архитектура сети в реставрации изображений. Используя расширенные свертки, сеть способна понимать контекст изображения без использования дорогостоящих полносвязных слоёв и, следовательно, может обрабатывать изображения разных размеров.
Помимо полностью свёрточной сети с расширенными свёртками, также вместе с генераторной сетью обучались два дискриминатора на двух масштабах. Глобальный дискриминатор смотрит на всё изображение, тогда как локальный дискриминатор смотрит на заполняемую центральную область. С помощью как глобальных, так и локальных дискриминаторов заполненное изображение имеет лучшую глобальную и локальную согласованность. Обратите внимание, что многие более поздние статьи о реставрации изображений следуют этой конструкции мультимасштабных дискриминаторов. Если вы заинтересовались, пожалуйста, прочитайте мой предыдущий пост [здесь], чтобы получить больше информации.
Реставрация на основе патчей с сетями GAN (вариация GLCIC, 2018)

Рис. 5. Предлагаемая архитектура генеративной ResNet и дискриминатор PGGAN.
Реставрацию на основе патчей с помощью сетей GAN [5] можно рассматривать как вариант GLCIC [4]. Проще говоря, две продвинутые концепции, а именно остаточное обучение [6] и PatchGAN [7], встроены в GLCIC для дальнейшего повышения производительности. Авторы этой статьи объединили остаточное соединение и расширенную свёртку, чтобы сформировать расширенный остаточный блок. Традиционный дискриминатор GAN был заменён дискриминатором PatchGAN, чтобы способствовать лучшим локальным деталям текстуры и согласованности глобальной структуры.
Основное различие между традиционным дискриминатором GAN и дискриминатором PatchGAN — в том, что традиционный дискриминатор GAN даёт только одну прогнозную метку (от 0 до 1), чтобы указать реалистичность входного сигнала, в то время как дискриминатор PatchGAN даёт матрицу меток (также от 0 до 1), чтобы указать реалистичность каждой локальной области входного сигнала. Обратите внимание, что каждый элемент матрицы представляет собой локальную область входных данных. Вы также можете ознакомиться с обзором остаточного обучения и PatchGAN [посетив этот мой пост].
Shift-Net («Копирование и вставка на основе глубокого обучения», 2018)

Рис. 6. Архитектура сети Shift-Net. Слой соединения-сдвига добавляется с разрешением 32x32.
Shift-Net [8] использует как преимущества современных управляемых данными CNN, так и традиционный метод «копирования и вставки» в виде глубокого перераспределения элементов с использованием предложенного слоя соединений-сдвигов. В этой статье есть две основные идеи.
Во-первых, авторы предложили потерю ориентира, которая побуждает декодированные элементы отсутствующих частей (учитывая скрытую часть изображения) быть близкими к кодированным элементам отсутствующих частей (учитывая хорошее состояние изображения). В результате процесс декодирования может восполнить недостающие части с их разумной оценкой в изображении в хорошем состоянии (то есть источнике истины для недостающих частей).
Во-вторых, предлагаемый слой соединения-сдвига позволяет сети эффективно заимствовать информацию, предоставленную ближайшими соседями за пределами отсутствующих частей, для уточнения как глобальной семантической структуры, так и деталей локальной текстуры сгенерированных частей. Проще говоря, мы предоставляем подходящие ссылки для уточнения нашей оценки. Я думаю, что читателям, интересующимся реставрацией изображений, будет полезно закрепить предложенные в этой статье идеи. Я настоятельно рекомендую вам прочитать предыдущий пост [здесь] для получения подробной информации.
DeepFill v1 (Прорыв реставрации изображений, 2018)

Рис. 7. Архитектура сети предлагаемого фреймворка.
Генеративную реставрацию с помощью контекстного внимания (CA, 2018), также называемую DeepFill v1 или CA [9], можно рассматривать как расширенную версию или вариант Shift-Net [8]. Авторы развивают идею копирования и вставки и предлагают слой контекстного внимания, дифференцируемый и полностью свёрточный.
Подобно слою соединения-сдвига в [8], сопоставляя сгенерированные элементы внутри пропущенных пикселей и характеристики вне пропущенных пикселей, мы можем узнать вклад всех элементов вне пропущенных пикселей в каждое местоположение внутри пропущенных пикселей. Следовательно, комбинация всех элементов снаружи может использоваться для уточнения сгенерированных элементов внутри недостающих пикселей. По сравнению со слоем соединения-сдвига, который ищет только самые похожие признаки (т. е. жёсткое, недифференцируемое назначение), слой CA в данной статье использует мягкое, дифференцируемое назначение, в котором все признаки имеют свои собственные веса, чтобы указать их вклад в каждое место внутри недостающих пикселей. Чтобы узнать больше о контекстном внимании, пожалуйста, прочитайте мой предыдущий пост [здесь], в нём вы найдёте примеры конкретнее.
GMCNN (мульти-колоночные CNNs для реставрации изображений, 2018)

Рис. 8. Архитектура предлагаемой сети.
Генеративные мультиколоночные сверточные нейронные сети (GMCNN, 2018) [10] расширяют важность достаточных рецептивных полей для реставрации изображений и предлагают новые функции потерь для дальнейшего улучшения локальных текстурных деталей генерируемого контента. Как показано на рисунке 9, существует три ветви/колонки, и в каждой ветви используются три различных размера фильтров. Использование нескольких рецептивных полей (размеров фильтров) связано с тем, что размер рецептивного поля важен для задачи реставрации изображения. Поскольку локальные соседние пиксели отсутствуют, приходится заимствовать информацию, полученную из пространственно удалённых местоположений, чтобы заполнить локальные недостающие пиксели.
Для предлагаемых функций потерь основная идея потерь неявного диверсифицированного случайного поля Маркова (Implicit Diversified Markov Random Field — ID-MRF) заключается в том, чтобы направлять сгенерированные патчи элементов на поиск их ближайших соседей за пределами пропущенных областей в качестве ссылок, и эти ближайшие соседи должны быть достаточно диверсифицированы, чтобы можно было смоделировать больше деталей локальной текстуры. На самом деле, эта потеря — расширенная версия потерь текстуры, используемой в MSNPS [3]. Я настоятельно рекомендую вам прочитать мой пост [здесь], в нём представлено подробное объяснение этой потери.
PartialConv (раздвигает ограничения реставрации через глубокое обучение для пустот неправильной формы, 2018)

Рис. 9. Визуальное сравнение предыдущих подходов, обученных с использованием обычных изображений с повреждениями и предложенного подхода частичной свёртки.
Реставрация пустот неправильной формы с помощью частичной свёртки (PartialConv или PConv) [11] расширяет границы глубокого обучения в реставрации изображений, предлагая способ обработки скрытых изображений с несколькими неправильными дырами. Очевидно, что основная идея этой статьи — частичная свёртка. При использовании PConv результаты свёртки будут зависеть только от допустимых пикселей, поэтому мы имеем контроль над передаваемой внутри сети информацией. Это первая работа о реставрации изображений, предназначенная для обработки неправильных пустот. Обратите внимание, что предыдущие модели для реставрации были обучены на правильных повреждённых изображениях, поэтому эти модели не подходят для реставрации изображений с неправильными пустотами.
Я привел простой пример, чтобы чётко объяснить, как выполняется частичная свёртка, в моем предыдущем посте [здесь]. Посетите ссылку и узнайте подробности. Надеюсь, вам понравится.
EdgeConnect — «сначала контуры, затем цвета», 2019

Рис. 10. Архитектура сети EdgeConnect. Как видите, есть два генератора и два дискриминатора.
EdgeConnect [12]: генеративная реставрация изображений с помощью Adversarial Edge Learning (EdgeConnect) [12] представляет интересный способ решения задачи реставрации изображений. Основная идея этой статьи состоит в том, чтобы разделить задачу реставрации на два шага с упрощением, а именно на прогнозирование краёв и завершение изображения на основе спрогнозированной карты краёв. Сначала прогнозируются края в недостающих областях, а затем завершения изображения в соответствии с прогнозом о краях. Большинство методов, используемых в этой статье, рассмотрены в моих предыдущих постах. Хорошо взглянуть на то, как различные методы могут использоваться вместе, чтобы сформировать новый подход реставрации изображений с помощью глубокого обучения. Возможно, вы разработаете свою собственную модель реставрации. Пожалуйста, посмотрите мой предыдущий пост [здесь], чтобы узнать больше об этой статье.
DeepFill v2 (Практичный подход к генеративной реставрации изображений, 2019)

Рис. 11. Обзор архитектуры сети модели для свободной реставрации.
Реставрация свободной формы с помощью Gated Convolution (DeepFill v2 или GConv, 2019) [13]. Возможно, это самый практичный алгоритм реставрации изображений, который может использоваться непосредственно в ваших приложениях. Его можно рассматривать как расширенную версию DeepFill v1 [9], частичная свёртка [11] и EdgeConnect [12]. Основная идея работы — Gated Convolution, обучаемая версия частичной свёртки. Добавляя дополнительный стандартный свёрточный слой, за которым следует сигмоидная функция, можно узнать допустимость каждого местоположения пикселя/объекта, и, следовательно, также допускается дополнительный ввод пользовательского эскиза. помимо Gated Convolution, SN-PatchGAN используется для дальнейшей стабилизации обучения модели GAN. Чтобы узнать больше о разнице между частичной свёрткой и Gated Convolution, а также о том, как дополнительный пользовательский ввод эскиза может повлиять на результаты реставрации, пожалуйста, посмотрите мой последний пост [здесь].
Заключение
Я надеюсь, теперь вы имеете базовое представление о реставрации изображений. Полагаю, что большинство распространённых методов, используемых в реставрации изображений с помощью глубокого обучения, рассмотрены в моих предыдущих постах. Если вы мой старый друг, я думаю, что теперь вы в состоянии понять другие работы о реставрации с помощью глубокого обучения. Если вы новичок, я хотел бы поприветствовать вас. Я надеюсь, что вы найдёте этот пост полезным для себя. На самом деле, этот пост даёт вам возможность присоединиться к нам и учиться вместе.
На мой взгляд, все еще сложно реставрировать изображения со сложными структурами сцены и большом количестве отсутствующих пикселей (например, когда нет 50 % пикселей). Разумеется, ещё одна сложная задача — реставрация изображений с высоким разрешением. Все эти задачи можно назвать экстремальными. Я думаю, что подход, основанный на новейших достижениях в области реставрации, в состоянии решить некоторые из этих проблем.
Ссылки на статьи
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “Context Encoders: Feature Learning by Inpainting,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.

- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс по Machine Learning
- Обучение профессии Data Science
- Обучение профессии Data Analyst
- Курс «Python для веб-разработки»
Eще курсы
- Курс «Математика и Machine Learning для Data Science»
- Профессия Этичный хакер
- Разработчик игр на Unity
- Курс по JavaScript
- Профессия Веб-разработчик
- Профессия Java-разработчик
- C++ разработчик
- Курс по аналитике данных
- Курс по DevOps
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
Рекомендуемые статьи
- Сколько зарабатывает дата-сайентист: обзор зарплат и вакансий в 2020
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в 2020
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Machine Learning и Computer Vision в добывающей промышленности
- Machine Learning и Computer Vision на обогатительных фабриках
