Comments 4
Гиперпараметр модели — это внешняя по отношению к модели конфигурация, значение которой не может оцениваться по данным. Например количество скрытых единиц измерения, скорость обучения и т. д.
У вас гугл-транслейт отклеился. Hidden unit это нейрон в скрытом слое.
Ну весьма странное и особо ни о чем не говорящее сравнение. Не секрет, что количество итераций для сходимости у SGD и его вариаций больше чем у того же Адама, но это ничего не говорит о том способен ли таки алгоритм достигнуть оптимума — лично в практике не раз сталкивался с тем, что в конечном счете SGD позволяет достигнуть меньших значений целевой функции, особенно если его грамотно настроить, а Адам очень быстро сходится, но «пройти ниже» не может.
Преимущества Адама вообще как будто с потолка взяты. Основное его преимущество (имхо) в том, что он в отличии от того же SGD требует куда меньшей настройки для достижения хорошего результата, а это идет последним пунктом. Пункты про простую реализацию, вычислительную эффективность и небольшие требования к памяти — это по сравнению с чем? В вакууме может так и есть, но если смотреть на его «конкурентов», то Адам здесь самый тяжеловесный и это сразу заметно, когда вы тренируете сетку с SGD, а потом Адамом. Что подразумевается под «нестационарной целью»? На основе чего сделан вывод «Хорошо подходит для больших с точки зрения данных и параметров задач»?
Преимущества Адама вообще как будто с потолка взяты. Основное его преимущество (имхо) в том, что он в отличии от того же SGD требует куда меньшей настройки для достижения хорошего результата, а это идет последним пунктом. Пункты про простую реализацию, вычислительную эффективность и небольшие требования к памяти — это по сравнению с чем? В вакууме может так и есть, но если смотреть на его «конкурентов», то Адам здесь самый тяжеловесный и это сразу заметно, когда вы тренируете сетку с SGD, а потом Адамом. Что подразумевается под «нестационарной целью»? На основе чего сделан вывод «Хорошо подходит для больших с точки зрения данных и параметров задач»?
Скорость обучения (α) — это параметр настройки в алгоритме оптимизации, определяющий размер шага на каждой итерации при движении к минимуму функции потерь (дополнительная информация здесь).
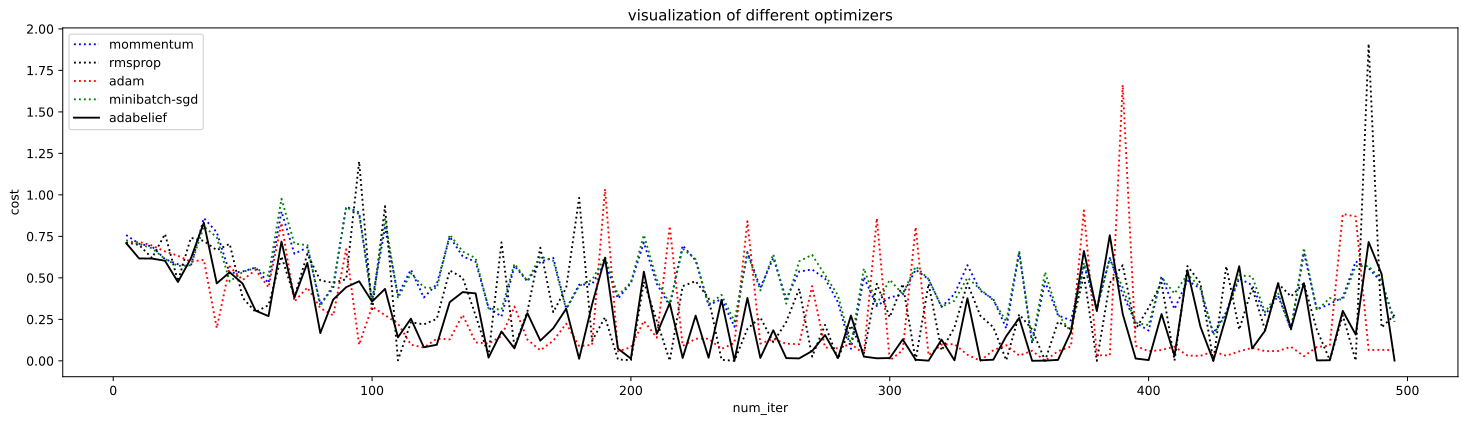
весьма многообещающе...
а если без шуток, то допускаю, что здесь могла быть ссылка
Sign up to leave a comment.
Реализуем и сравниваем оптимизаторы моделей в глубоком обучении