Размышления об информации, памяти, аналитике и распределениях
Все, что воспринимают наши чувства, — это данные, хотя их хранение в наших черепушках оставляет желать лучшего. Записать это немного надежнее, особенно когда мы записываем это на компьютере. Когда эти записи хорошо организованы, мы называем их данными… хотя я видел, как некоторые ужасно организованные электронные каракули получают то же имя. Я не уверен, почему некоторые люди произносят слово data так, как будто оно имеет заглавную букву D.
Почему мы произносим data с большой буквы?
Нам нужно научиться быть непочтительно прагматичными в отношении данных, поэтому эта статья поможет новичкам заглянуть за кулисы и помочь практикующим объяснить основы новичкам, у которых проявляются симптомы поклонения данным.
Смысл и смыслы
Если вы начнете свое путешествие с покупки наборов данных в Интернете, вы рискуете забыть, откуда они берутся. Я начну с нуля, чтобы показать вам, что вы можете делать данные в любое время и в любом месте.
Вот несколько постоянных обитателей моей кладовой, расставленных на полу.

Эта фотография представляет собой данные — она хранится как информация, которую ваше устройство использует для отображения красивых цветов.
Давайте разберемся в том, на что мы смотрим. У нас есть бесконечные варианты того, на что обращать внимание и помнить. Вот что я вижу, когда смотрю на продукты.

Если вы закрываете глаза, вы помните каждую деталь того, что вы только что видели? Нет? И я нет. Вот почему мы собираем данные. Если бы мы могли помнить и обрабатывать это безупречно в наших головах, в этом не было бы необходимости. Интернет мог быть одним отшельником в пещере, рассказывая обо всех твитах человечества и прекрасно передавая каждую из наших миллиардов фотографий кошек.
Письмо и долговечность
Поскольку человеческая память — это дырявое ведро, было бы лучше записать информацию так, как мы делали это раньше, когда я училась в школе статистики, еще в далекие года. Вот именно, друзья мои, у меня все еще где-то здесь есть бумага! Давайте запишем эти 27 данных.

Что хорошего в этой версии — относительно того, что находится в моем гиппокампе или на моем полу — то, что она более долговечна и надежна.
Человеческая память — дырявое ведро.
Мы считаем революцию памяти само собой разумеющейся, так как она началась тысячелетия назад с торговцев, нуждающихся в надежном учете того, кто кому продал, сколько бушелей чего. Потратьте немного времени, чтобы понять, как прекрасно иметь универсальную систему письма, которая хранит цифры лучше, чем наш мозг. Когда мы записываем данные, мы производим неверное искажение наших богато воспринимаемых реалий, но после этого мы можем передавать нетленные копии результата другим представителям нашего вида с идеальной точностью. Писать потрясающе! Маленькие кусочки ума и памяти, которые живут вне нашего тела.
Когда мы анализируем данные, мы получаем доступ к чужим воспоминаниям.
Беспокоитесь о машинах, превосходящих наш мозг? Даже бумага может сделать это! Эти 27 маленьких цифр — большой объем для вашего мозга, но долговечность гарантирована, если у вас есть пишущий инструмент под рукой.
Хотя это и выигрыш в долговечности, но работа с бумагой раздражает. Например, что, если мне вдруг взбредет в голову переставить их от большего к меньшему? Абракадабра, бумага, покажи мне лучший порядок! — Нет? Черт.
Компьютеры и магические заклинания
Вы знаете, что удивительного в программном обеспечении? Абракадабра на самом деле работает! Итак, давайте перейдем с бумаги на компьютер.
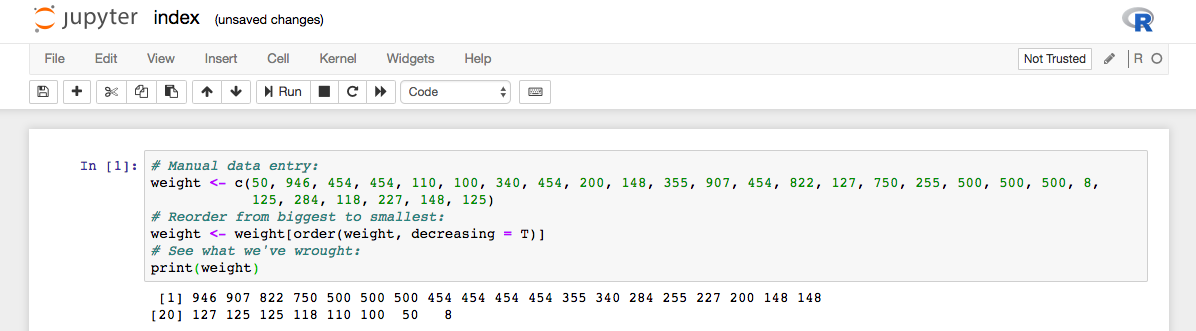
Электронные таблицы оставляют меня равнодушным. Они очень ограничены по сравнению с современными инструментами обработки данных. Я предпочитаю колебаться между R и Python, так что давайте на этот раз возьмем R. Вы можете повторять за мной в вашем браузере с помощью Jupyter: выберите вкладку «with R», затем несколько раз нажмите значок ножниц, пока все не будет удалено. Поздравляю, это заняло 5 секунд, и вы готовы вставить мои фрагменты кода и запустить его [Shift + Enter].
weight <- c(50, 946, 454, 454, 110, 100, 340, 454, 200, 148, 355, 907, 454, 822, 127, 750, 255, 500, 500, 500, 8, 125, 284, 118, 227, 148, 125)
weight <- weight[order(weight, decreasing = TRUE)]
print(weight)Вы заметите, что абракадабра R для сортировки ваших данных не очевидна, если вы новичок в этом.
Ну, это верно для самого слова «абракадабра», а также для меню в программном обеспечении электронных таблиц. Вы знаете эти вещи только потому, что были подвержены им, а не потому, что они являются универсальными законами. Чтобы что-то сделать с компьютером, вам нужно попросить своего местного мудреца о волшебных словах/жестах, а затем попрактиковаться в их использовании. Мой любимый мудрец называется Интернет и знает все на свете.
Чтобы ускорить обучение, не просто вставляйте волшебные слова — попробуйте изменить их и посмотреть, что произойдет. Например, что изменится, если вы превратите TRUE в FALSE во фрагменте выше?
Разве не удивительно, как быстро вы получаете ответ? Одна из причин, по которой я люблю программирование, заключается в том, что это нечто среднее между магическими заклинаниями и LEGO.
Если вы когда-нибудь хотели, чтобы вы могли творить чудеса, просто научитесь писать код.
Вот вкратце о программировании: спросите Интернет, как сделать что-то, возьмите волшебные слова, которые вы только что выучили, посмотрите, что произойдет, когда вы их отрегулируете, а затем соедините их вместе, как блоки LEGO, чтобы выполнить ваш код.
Аналитика и обобщение
Проблема с этими 27 числами состоит в том, что даже если они отсортированы, они мало что значат для нас. Читая их, мы забываем то, что читали секунду назад. Это человеческий мозг для вас; попросите нас прочитать отсортированный список из миллиона номеров, и в лучшем случае мы запомним последние несколько. Нам нужен быстрый способ сортировки и суммирования, чтобы мы могли понять, на что мы смотрим.
Вот для чего нужна аналитика!
median(weight)При правильном заклинании мы можем мгновенно узнать, каков средний вес. (Медиана означает «среднее».)
Оказывается, ответ 284г. Кто не любит мгновенного удовлетворения? Существуют всевозможные варианты сводки: min(), max(), mean(), median(), mode(), variance()… попробуйте все! Или попробуйте это волшебное слово, чтобы узнать, что происходит.
summary(weight)Кстати, эти вещи называются статистикой. Статистика — это любой способ собрать ваши данные. Это не то, что представляет собой область статистики — вот 8-минутное введение в академическую дисциплину.

Построение и визуализация
Этот раздел не о типе заговора, который включает мировое господство (следите за новостями этой статьи). Речь идет о суммировании данных с помощью изображений. Оказывается, картинка может быть информативнее тысячи слов.

Если мы хотим знать, как распределяются веса в наших данных — например, есть ли еще пункты между 0 и 200 г или между 600 и 800 г? — гистограмма — наш лучший друг.

Гистограммы являются одним из способов (среди многих) суммирования и отображения наших выборочных данных. Более высокие блоки для более популярных значений данных.
Думайте о гистограммах как о конкурсах популярности.
Чтобы создать приложение для работы с электронными таблицами, волшебное заклинание представляет собой долгий ряд нажатий на различные меню. В R это быстрее:
Вот что мы получили с помощью одной строки:
hist(weight)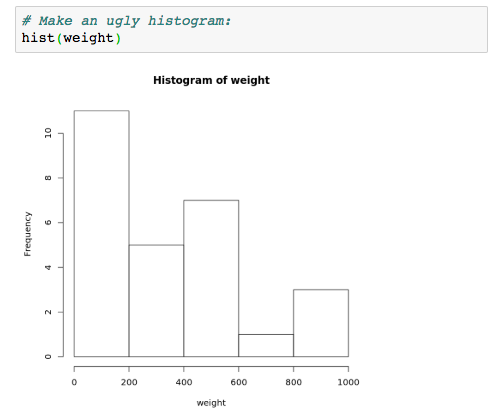
На что мы смотрим?
На горизонтальной оси у нас есть столбцы. По умолчанию они установлены с шагом 200г, но мы изменим это через мгновение. На вертикальной оси находятся отсчеты: сколько раз мы видели вес от 0 до 200 г? График говорит 11. Как насчет между 600 г и 800 г? Только один (это поваренная соль, если память не изменяет).
Мы можем выбрать размер наших столбцов — по умолчанию, которую мы получили без возни с кодом, — 200 г, но, возможно, мы хотим использовать 100 г, вместо этого. Нет проблем! Маги в процессе обучения могут переделать мое заклинание, чтобы узнать, как оно работает.
hist(weight, col = "salmon2", breaks = seq(0, 1000, 100))Вот результат:
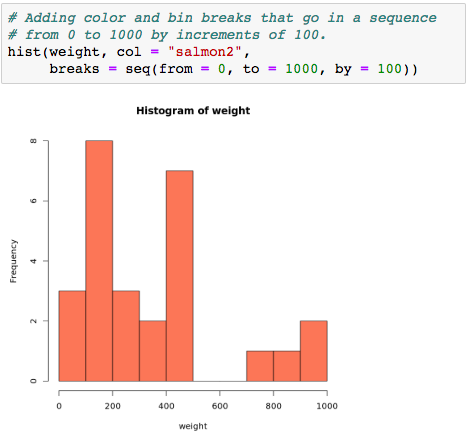
Теперь мы можем ясно видеть, что двумя наиболее распространенными категориями являются 100–200 и 400–500. Кому-нибудь интересно? Возможно нет. Мы сделали это только потому, что могли. Настоящий аналитик, с другой стороны, преуспевает в науке быстрого просмотра данных и искусстве смотреть, где лежат интересные самородки. Если они хороши в своем ремесле, они на вес золота.
Что такое распределение
Если эти 27 пунктов — это все, что нас волнует, то приведенная мною выборочная гистограмма также отражает распределение совокупности.
Это почти то же самое, что и распределение: это гистограмма, которую вы получили бы, если бы применили Hist() ко всей совокупности (ко всей информации, которая вас интересует), а не только к выборке (данным, которые у вас есть под рукой). Есть несколько сносок, например, шкала по оси Y, но мы оставим их для другого поста в блоге — пожалуйста, не бейте меня, математики!
Если бы наше население когда-либо упаковывало все продукты питания, распределение было бы в форме гистограммы всех их весов. Такое распределение существует только в нашем воображении как теоретическая идея — некоторые упакованные продукты питания теряются в глубине веков. Мы не можем сделать этот набор данных, даже если бы захотели, поэтому лучшее, что мы можем сделать, — это угадать, используя хороший пример.
Что такое Data Science
Существует множество мнений, но я предпочитаю следующее определение: «Наука о данных — это дисциплина, которая делает данные полезными». Три ее подраздела включают анализ большого количества информации для поиска инсайтов (аналитика), разумное принятие решений на основе ограниченной информации (статистика) и использование шаблонов в данных для автоматизации задач (ML/AI).
Вся наука о данных сводится к следующему: знание это сила.
Вселенная полна информации, ожидающей сбора и использования. Хотя наш мозг прекрасно разбирается в наших реалиях, он не так хорош в хранении и обработке некоторых видов очень полезной информации.
Вот почему человечество обратилось сначала к глиняным табличкам, затем к бумаге и, в конечном итоге, к кремнию за помощью. Мы разработали программное обеспечение для быстрого просмотра информации, и в наши дни люди, которые знают, как ее использовать, называют себя учеными или аналитиками данных. Настоящие герои — это те, кто создает инструменты, которые позволяют этим практикующим лучше и быстрее овладеть информацией. Кстати, даже интернет — это аналитический инструмент — мы просто редко думаем об этом, потому что даже дети могут проводить такой анализ данных.

Апгрейд памяти для всех
Все, что мы воспринимаем, хранится где-то, по крайней мере, временно. В данных нет ничего волшебного, кроме того, что они записаны более надежно, чем мозг. Некоторая информация полезна, часть вводит в заблуждение, остальное посередине. То же самое касается данных.
Мы все аналитики данных и всегда ими были.
Мы принимаем наши удивительные биологические возможности как должное и преувеличиваем разницу между нашей врожденной обработкой информации и автоматическим разнообразием. Разница заключается в долговечности, скорости и масштабе… но в обоих случаях применяются одни и те же правила здравого смысла. Почему эти правила выходят в окно при первом знаке уравнения?
Я рада, что мы называем информацию топливом для прогресса, но поклоняться данным как чему-то мистическому для меня не имеет смысла. Лучше просто говорить о данных, так как мы все аналитики данных, и так было всегда. Давайте дадим возможность каждому увидеть себя такими.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Курс по Machine Learning (12 недель)
- Курс «Профессия Data Scientist» (24 месяца)
- Курс «Профессия Data Analyst» (18 месяцев)
- Курс «Python для веб-разработки» (9 месяцев)
