Привет! Обладая нужной информацией, можно сделать много полезных (или много дико вредных) вещей, тут зависит от того, у кого эта информация и чем он мотивирован. Чтобы работать с информацией, делать нужные тебе выгрузки, составлять отчёты, нужно эту информацию где-то хранить. Поэтому мы создали огромное озеро данных для маркетинга
Меня зовут Андрей Наумов, я работаю в команде управления корпоративными данными и делаю продукт для маркетинга и продаж. Наша задача — наполнять это озеро данными (потому что какое оно тогда озеро данных без данных), чтобы с ним могли продуктивно работать и люди из бизнеса, и непосредственные пользователи из числа сотрудников, которым необходимо строить подробную аналитику.

Под катом — о том, почему нам вообще понадобилось такое озеро, как мы его строили, как оно помогает выходить на новые рынки продаж внутри страны и вне её, а также о наших планах на будущее.
До создания единого озера данных ситуация с обработкой информации оставляла желать лучшего. Нет, всё работало, но могло быть сильно лучше. Для начала расскажу, как вообще работают ребята в нашем маркетинге.
Работают они с колоссальным количеством информации из множества источников данных. Это и источники внутри СИБУРа, и снаружи, находящиеся в свободном доступе и доступные лишь по подписке, бесплатные и платные. В общем, зоопарк тот ещё. Большинство подобной информации — это огромный плоские файлы, для работы с которыми необходимо специализированное ПО. Зачастую при этом — для каждого вида данных своё ПО. Понятно дело, часто этот софт работает нестабильно или вообще откровенно тупит.
Для примера — большая часть работы маркетинга завязана на изучение товарных потоков (в т.ч. импорт и экспорт), с их помощью можно понять, какие товары уезжают из РФ, а какие, наоборот, приезжают. Нас тут интересует именно продукция, которую прямо или опосредованно может продавать или создавать СИБУР. Информация, которая обрабатывается этой системой, поступает пачками, по месяцам. Построить какую-то внятную аналитику, скажем, за год или десятилетие, было невозможно, потому что мы упирались в ограничения ПО — в том же экселе есть определенный максимум строк. А мы извлекали таблицы более чем на миллион строк. Рабочие ПК банально не осиливали подобные издевательства.
И это только товарные потоки как один из источников, а таких источников много — есть ещё железнодорожная статистика, информация из внутренних систем о продажах компании, экспертные источники, заказанные у внешних агентств отчёты и многое, многое другое.
Появилась задача — создать единую версию документации в одном месте, чтобы каждый пользователь мог работать с данными при помощи одного инструмента визуализации и построения аналитики. В варианте «До» у нас был дичайший расфокус маркетологов из-за самого этапа подготовки данных. Де-факто получалось, что наши маркетологи много времени тратили на работу в качестве инженеров данных. Это неправильно.
Было очень сложно работать и анализировать данные в разрезе больше года. Потому что даже подготовив и выгрузив определенные данные за год, приходилось их основательно чистить. От дубликатов, от ошибок, от некорректных названий. Некоторые строки требовали унификации, к примеру, у кого-то в таблице наша необъятная родина именовалась «Россия», у кого-то — «Российская Федерация», а кто-то лаконично вписывал «РФ». Всё это надо было привести к одному виду, и, как вы понимаете, пример с названием страны здесь далеко не единственный и не самый очевидный.
А ещё штука в том, что мы — холдинг, у нас множество организаций, причём далеко не у всех в названии есть слово «СИБУР». Поэтому, пытаясь искать по списку и желая в пару кликов отфильтровать названия так, чтобы увидеть только компании холдинга, добиться результата было непросто.
Кроме того, сколько людей — столько и подходов к решению рабочих задач. У каждого сотрудника существовала собственная методика обработки данных, их фильтрации, маппинга, объединения. Проблема в том, что эта методика существовала у сотрудника в голове. Поэтому в то время много было завязано на конкретного человека. Это тоже не самая веселая история, потому что надо тебе что-то выгрузить — а человек в отпуске. И сиди, жди его. Потому что без него это будут делать или сильно дольше, или сделают неправильно.
В общем, мы решили сделать так, чтобы не было зависимости от конкретного человека, чтобы вся информация была общая и доступна на едином уровне для любого пользователя, которому она может понадобиться.
Для этого мы прежде всего пошли к бизнесу и уточнили у них, какие из источников данных были бы им наиболее интересны. Выделили именно их, подготовили для них пилотное хранилище данных с технологиями озера данных (подробно и со схемами это озеро мы описывали в этом посте). А потом при помощи ряда ETL-инструментов разово залили туда все эти нужные источники: товарные потоки, статистику по продуктам и прочее, заботливо сложили это в БД (Vertica). Стояла задача сделать интеграцию всего, что можно, что мы и сделали.
Для визуализации данных мы используем Tableau, его серверная версия была прикручена к хранилищу и мы дали пользователям доступ сразу ко всем данным разом. Пользователи, надо сказать, были воодушевлены — раньше ты сидел и пялился в таблицы (огромные таблицы), а теперь тебе всё красиво и удобно визуализировали.
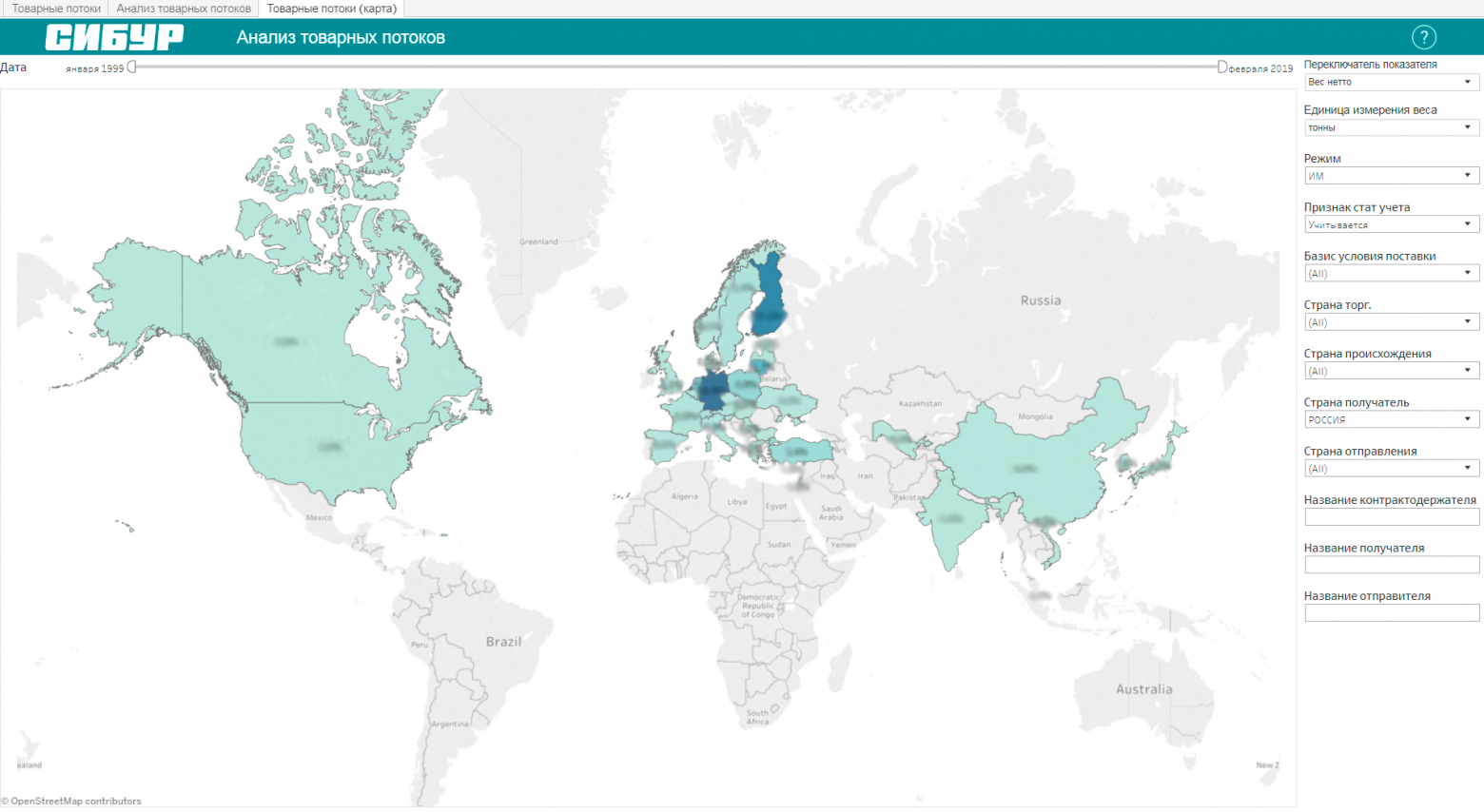
Анализ товарных потоков
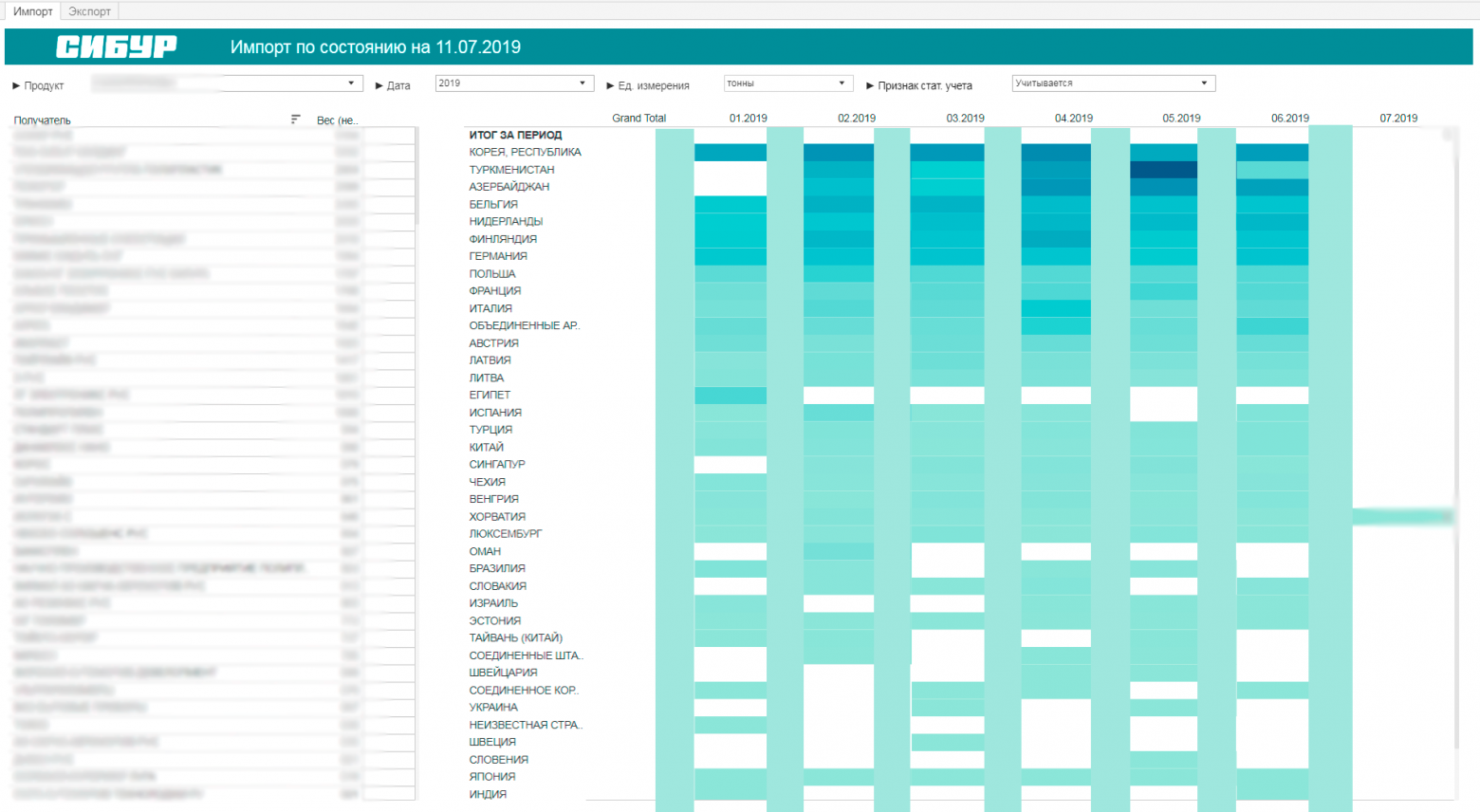
Анализ продукта
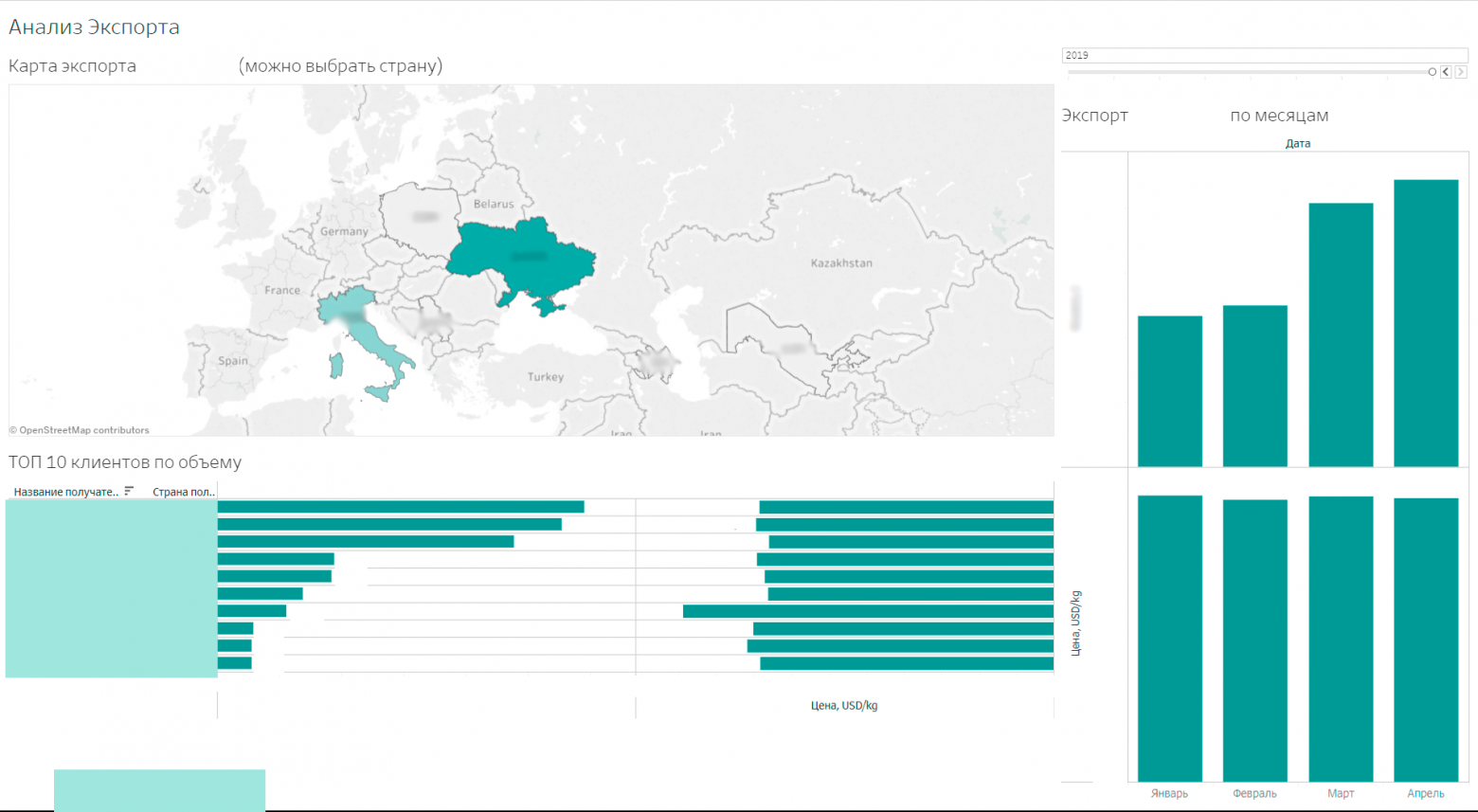 Анализ конкурентов
Анализ конкурентов
Конечно, наши аналитики видят не кучу замазанных строк на экране, а вполне реальные цифры и названия контрагентов, но показать мы их не можем.
Далее от пользователей пошла полезная обратная связь. Нам дали понять, что raw-данные (сырые) им не очень-то интересны, потому что каждый из них занимался собственной предподготовкой. Поэтому мы стали прорабатывать наиболее частые маппинги и переименования, переписали контрагентов, исправили множество ошибок — в колонках могли встречаться дубли, знаки препинания, кто-то мог рядом с названием компании заодно вписать и ее контрагентов. В общем, мусора было достаточно.
Привели страны к общему виду, это помогло схлопывать и расхлопывать их по регионам — сотрудники могут в пару кликов делать выгрузку по СНГ, по странам Южной Америки или Северной, что довольно важно для правильной аналитики. Схлопывание — штука удобная, поэтому решили распространить такую практику и на юрлица — как со странами, только масштабов холдингов и отдельных юрлиц.
Благодаря проделанной работе стало возможным вывести отчёты за последние 15-20 лет в плане импорта и экспорта, и при этом не сойти с ума и не спалить пару рабочих ПК. Теперь можно взять этот временной промежуток и развернуть его по годам или провалиться по месяцам.
Так вот. В товарных потоках есть такая штука как ТНВЭД, товарная номенклатура внешнеэкономической деятельности. Это число из 10 цифр максимум. Чем больше цифр — тем конкретнее указание на тот или иной товар.
Вот смотрите на примере с кофе.
09 — кофе, чай, мате, парагвайский чай, пряности. Довольно общая категория.
0901 2 — уже даст нам понять, что речь идет именно о жареном кофе.
0901 21 — жареный кофе с кофеином (у нежареного и без кофеина другой код).
0901 21 000 2 — те самые финальные 10 цифр, это уже робуста (Coffea canephora).
То же самое и с товарам, которые важны для нас. То есть — которые мы продаем и производим. Конечно, кофе тоже важен, но мы пока потребляем его не в таких количествах, чтобы выгружать статистику по импорту.
А важны нам полимеры, пластики и сырье, необходимое для их изготовления.
Тут уже коды выглядят таким образом.
39-40 — пластмассы и изделия из них; каучук, резина и изделия из них.
3901 — полимеры этилена в первичных формах
3901 1 — полиэтилен с удельным весом менее 0,94
3901 10 100 0 — полиэтилен линейный.
И так для каждого полимера или вида сырья, проваливаемся от общего к частному. Зачем вообще за этим следить. С помощью данных по потокам можно довольно подробно понять, что в РФ ввезли за год определенное количество полимеров. Или сырья. То есть кто-то закупает вне страны продукцию, которые производим в том числе и мы здесь, в РФ. Дальше есть возможность посмотреть, в каких масштабах её закупают, с помощью ребят из продвинутой аналитики можно прицелиться в нужные цены, и в итоге сделать так, чтобы выйти к такому заказчику с аналогичным товаром, но который мы делаем здесь, и предложить ему такой товар по вменяемой цене. С учётом тех средств, которые он тратит на таможенные пошлины и перевозку.
С экспортом то же самое. Какой-то из интересных нам товаров часто экспортируется зарубеж. Значит, на него есть спрос, в весьма постоянных и неплохих масштабах. Значит, можно посмотреть, что это, к кому оно едет и сколько за это платят. Потом прикинуть, сможем ли мы делать то же самое с учетом трат на логистику, имеет ли это смысл или нет.
А ещё это помогает смотреть за активностью конкурентов в этой же области и при необходимости корректировать свои цифры.
Но было бы слишком просто, если бы ТНВЭД всегда давал точно понять, какой товар едет, да?
Поэтому некоторые граждане завозят полиэтилен под другим кодом ТНВЭД, но тут наши аналитики могут изучать другие поля в данных товарных потоков, и потом по совокупности признаков понять, что это таки точно полиэтилен, а не то, что указано в коде. Это помогает увидеть добавочные объёмы экспорта и импорта, которые при первых проверках могут ускользнуть от внимания. На основании таких данных можно уже прикинуть — а вдруг нам имеет смысл открывать дополнительное производство, которое окупится, судя по цифрам и объёмам.
Такие отчёты с помощью анализа и экспертизы самих сотрудников мы можем дополнительно обогащать — в БД появляется новое поле, к примеру, «продукт», по которому теперь тоже можно делать выборки и строить отчёты. И по каждому конкретному продукту (а это определяется как по ТНВЭД, так и по экспертным знаниям коллег) смотреть, что у нас есть пара потенциальных клиентов внутри страны, а еще несколько и за её пределами. Поэтому можно начинать делать для них сырьё, или даже конечный продукт.
Можно пойти дальше — выбрав таких получателей внутри страны, мы можем посмотреть, что эти ребята еще заказывают себе из тех товаров, к которым мы имеем отношение. Вдруг им интересен не только полиэтилен, но еще и полипропилен, а также некоторые виды БОПП-пленки? Получается довольно обширный скоуп знаний о конкретном потребителе, изучив который, можно сразу предложить ему и товар, и правильную цену, и комфортные условия.
Что у нас сейчас
Мы продолжаем работать итеративно — вносим данные, собираем с пользователей обратную связь, уточняем наши аналитические правила. Получается своего рода командная работа, мы чему-то учимся у них, они — у нас, потому что у них очень хорошие экспертные знания, а у нас — технические.
После закачивания самых критичных источников и базовой подготовки этих данных мы наконец переезжаем с тестового хранилища (всё это время мы пока в тесте, да) на боевое. Это снимет кучу проблем, потому что боевое = сертифицированное, и там хранится множество данных, которые нельзя было скармливать тестовому (коммерческие тайны и прочие штуки, которые тоже важны для аналитики). Теперь же это будет на самом деле единое озеро данных с огромным количеством источников. Включая данные по котировкам — наши коллеги из продвинутой аналитики умеют предсказывать цены на тот или иной продукт, анализируя множество факторов — это могут быть акции самой компании, стихийные бедствия в регионах производства, слухи о слиянии и поглощении, да даже неудачный твит кого-то из руководства.
Предсказательная аналитика использует данные и выдает прогнозы, эти же прогнозы складываются в озеро данных, и маркетинг может использовать их для своих отчётов и аналитики.
Получается такой круговорот данных в рамках одного озера. Довольны пока все — бизнес, отзывы максимально положительные, потому что понимает, какую уйму времени и сил этот проект экономит, и сами аналитики.
Так что работаем дальше. А кто хочет извлекать из данных максимум вместе с нами — добро пожаловать на страницу вакансий в hh.ru.
Меня зовут Андрей Наумов, я работаю в команде управления корпоративными данными и делаю продукт для маркетинга и продаж. Наша задача — наполнять это озеро данными (потому что какое оно тогда озеро данных без данных), чтобы с ним могли продуктивно работать и люди из бизнеса, и непосредственные пользователи из числа сотрудников, которым необходимо строить подробную аналитику.

Под катом — о том, почему нам вообще понадобилось такое озеро, как мы его строили, как оно помогает выходить на новые рынки продаж внутри страны и вне её, а также о наших планах на будущее.
Зачем оно вообще нужно
До создания единого озера данных ситуация с обработкой информации оставляла желать лучшего. Нет, всё работало, но могло быть сильно лучше. Для начала расскажу, как вообще работают ребята в нашем маркетинге.
Работают они с колоссальным количеством информации из множества источников данных. Это и источники внутри СИБУРа, и снаружи, находящиеся в свободном доступе и доступные лишь по подписке, бесплатные и платные. В общем, зоопарк тот ещё. Большинство подобной информации — это огромный плоские файлы, для работы с которыми необходимо специализированное ПО. Зачастую при этом — для каждого вида данных своё ПО. Понятно дело, часто этот софт работает нестабильно или вообще откровенно тупит.
Для примера — большая часть работы маркетинга завязана на изучение товарных потоков (в т.ч. импорт и экспорт), с их помощью можно понять, какие товары уезжают из РФ, а какие, наоборот, приезжают. Нас тут интересует именно продукция, которую прямо или опосредованно может продавать или создавать СИБУР. Информация, которая обрабатывается этой системой, поступает пачками, по месяцам. Построить какую-то внятную аналитику, скажем, за год или десятилетие, было невозможно, потому что мы упирались в ограничения ПО — в том же экселе есть определенный максимум строк. А мы извлекали таблицы более чем на миллион строк. Рабочие ПК банально не осиливали подобные издевательства.
И это только товарные потоки как один из источников, а таких источников много — есть ещё железнодорожная статистика, информация из внутренних систем о продажах компании, экспертные источники, заказанные у внешних агентств отчёты и многое, многое другое.
Что же делать
Появилась задача — создать единую версию документации в одном месте, чтобы каждый пользователь мог работать с данными при помощи одного инструмента визуализации и построения аналитики. В варианте «До» у нас был дичайший расфокус маркетологов из-за самого этапа подготовки данных. Де-факто получалось, что наши маркетологи много времени тратили на работу в качестве инженеров данных. Это неправильно.
Было очень сложно работать и анализировать данные в разрезе больше года. Потому что даже подготовив и выгрузив определенные данные за год, приходилось их основательно чистить. От дубликатов, от ошибок, от некорректных названий. Некоторые строки требовали унификации, к примеру, у кого-то в таблице наша необъятная родина именовалась «Россия», у кого-то — «Российская Федерация», а кто-то лаконично вписывал «РФ». Всё это надо было привести к одному виду, и, как вы понимаете, пример с названием страны здесь далеко не единственный и не самый очевидный.
А ещё штука в том, что мы — холдинг, у нас множество организаций, причём далеко не у всех в названии есть слово «СИБУР». Поэтому, пытаясь искать по списку и желая в пару кликов отфильтровать названия так, чтобы увидеть только компании холдинга, добиться результата было непросто.
Кроме того, сколько людей — столько и подходов к решению рабочих задач. У каждого сотрудника существовала собственная методика обработки данных, их фильтрации, маппинга, объединения. Проблема в том, что эта методика существовала у сотрудника в голове. Поэтому в то время много было завязано на конкретного человека. Это тоже не самая веселая история, потому что надо тебе что-то выгрузить — а человек в отпуске. И сиди, жди его. Потому что без него это будут делать или сильно дольше, или сделают неправильно.
В общем, мы решили сделать так, чтобы не было зависимости от конкретного человека, чтобы вся информация была общая и доступна на едином уровне для любого пользователя, которому она может понадобиться.
Для этого мы прежде всего пошли к бизнесу и уточнили у них, какие из источников данных были бы им наиболее интересны. Выделили именно их, подготовили для них пилотное хранилище данных с технологиями озера данных (подробно и со схемами это озеро мы описывали в этом посте). А потом при помощи ряда ETL-инструментов разово залили туда все эти нужные источники: товарные потоки, статистику по продуктам и прочее, заботливо сложили это в БД (Vertica). Стояла задача сделать интеграцию всего, что можно, что мы и сделали.
Для визуализации данных мы используем Tableau, его серверная версия была прикручена к хранилищу и мы дали пользователям доступ сразу ко всем данным разом. Пользователи, надо сказать, были воодушевлены — раньше ты сидел и пялился в таблицы (огромные таблицы), а теперь тебе всё красиво и удобно визуализировали.

Анализ товарных потоков

Анализ продукта
 Анализ конкурентов
Анализ конкурентовКонечно, наши аналитики видят не кучу замазанных строк на экране, а вполне реальные цифры и названия контрагентов, но показать мы их не можем.
Далее от пользователей пошла полезная обратная связь. Нам дали понять, что raw-данные (сырые) им не очень-то интересны, потому что каждый из них занимался собственной предподготовкой. Поэтому мы стали прорабатывать наиболее частые маппинги и переименования, переписали контрагентов, исправили множество ошибок — в колонках могли встречаться дубли, знаки препинания, кто-то мог рядом с названием компании заодно вписать и ее контрагентов. В общем, мусора было достаточно.
Привели страны к общему виду, это помогло схлопывать и расхлопывать их по регионам — сотрудники могут в пару кликов делать выгрузку по СНГ, по странам Южной Америки или Северной, что довольно важно для правильной аналитики. Схлопывание — штука удобная, поэтому решили распространить такую практику и на юрлица — как со странами, только масштабов холдингов и отдельных юрлиц.
Почему анализ важен для работы с рынком
Благодаря проделанной работе стало возможным вывести отчёты за последние 15-20 лет в плане импорта и экспорта, и при этом не сойти с ума и не спалить пару рабочих ПК. Теперь можно взять этот временной промежуток и развернуть его по годам или провалиться по месяцам.
Так вот. В товарных потоках есть такая штука как ТНВЭД, товарная номенклатура внешнеэкономической деятельности. Это число из 10 цифр максимум. Чем больше цифр — тем конкретнее указание на тот или иной товар.
Вот смотрите на примере с кофе.
09 — кофе, чай, мате, парагвайский чай, пряности. Довольно общая категория.
0901 2 — уже даст нам понять, что речь идет именно о жареном кофе.
0901 21 — жареный кофе с кофеином (у нежареного и без кофеина другой код).
0901 21 000 2 — те самые финальные 10 цифр, это уже робуста (Coffea canephora).
То же самое и с товарам, которые важны для нас. То есть — которые мы продаем и производим. Конечно, кофе тоже важен, но мы пока потребляем его не в таких количествах, чтобы выгружать статистику по импорту.
А важны нам полимеры, пластики и сырье, необходимое для их изготовления.
Тут уже коды выглядят таким образом.
39-40 — пластмассы и изделия из них; каучук, резина и изделия из них.
3901 — полимеры этилена в первичных формах
3901 1 — полиэтилен с удельным весом менее 0,94
3901 10 100 0 — полиэтилен линейный.
И так для каждого полимера или вида сырья, проваливаемся от общего к частному. Зачем вообще за этим следить. С помощью данных по потокам можно довольно подробно понять, что в РФ ввезли за год определенное количество полимеров. Или сырья. То есть кто-то закупает вне страны продукцию, которые производим в том числе и мы здесь, в РФ. Дальше есть возможность посмотреть, в каких масштабах её закупают, с помощью ребят из продвинутой аналитики можно прицелиться в нужные цены, и в итоге сделать так, чтобы выйти к такому заказчику с аналогичным товаром, но который мы делаем здесь, и предложить ему такой товар по вменяемой цене. С учётом тех средств, которые он тратит на таможенные пошлины и перевозку.
С экспортом то же самое. Какой-то из интересных нам товаров часто экспортируется зарубеж. Значит, на него есть спрос, в весьма постоянных и неплохих масштабах. Значит, можно посмотреть, что это, к кому оно едет и сколько за это платят. Потом прикинуть, сможем ли мы делать то же самое с учетом трат на логистику, имеет ли это смысл или нет.
А ещё это помогает смотреть за активностью конкурентов в этой же области и при необходимости корректировать свои цифры.
Но было бы слишком просто, если бы ТНВЭД всегда давал точно понять, какой товар едет, да?
Поэтому некоторые граждане завозят полиэтилен под другим кодом ТНВЭД, но тут наши аналитики могут изучать другие поля в данных товарных потоков, и потом по совокупности признаков понять, что это таки точно полиэтилен, а не то, что указано в коде. Это помогает увидеть добавочные объёмы экспорта и импорта, которые при первых проверках могут ускользнуть от внимания. На основании таких данных можно уже прикинуть — а вдруг нам имеет смысл открывать дополнительное производство, которое окупится, судя по цифрам и объёмам.
Такие отчёты с помощью анализа и экспертизы самих сотрудников мы можем дополнительно обогащать — в БД появляется новое поле, к примеру, «продукт», по которому теперь тоже можно делать выборки и строить отчёты. И по каждому конкретному продукту (а это определяется как по ТНВЭД, так и по экспертным знаниям коллег) смотреть, что у нас есть пара потенциальных клиентов внутри страны, а еще несколько и за её пределами. Поэтому можно начинать делать для них сырьё, или даже конечный продукт.
We need to go deeper
Можно пойти дальше — выбрав таких получателей внутри страны, мы можем посмотреть, что эти ребята еще заказывают себе из тех товаров, к которым мы имеем отношение. Вдруг им интересен не только полиэтилен, но еще и полипропилен, а также некоторые виды БОПП-пленки? Получается довольно обширный скоуп знаний о конкретном потребителе, изучив который, можно сразу предложить ему и товар, и правильную цену, и комфортные условия.
Что у нас сейчас
Мы продолжаем работать итеративно — вносим данные, собираем с пользователей обратную связь, уточняем наши аналитические правила. Получается своего рода командная работа, мы чему-то учимся у них, они — у нас, потому что у них очень хорошие экспертные знания, а у нас — технические.
После закачивания самых критичных источников и базовой подготовки этих данных мы наконец переезжаем с тестового хранилища (всё это время мы пока в тесте, да) на боевое. Это снимет кучу проблем, потому что боевое = сертифицированное, и там хранится множество данных, которые нельзя было скармливать тестовому (коммерческие тайны и прочие штуки, которые тоже важны для аналитики). Теперь же это будет на самом деле единое озеро данных с огромным количеством источников. Включая данные по котировкам — наши коллеги из продвинутой аналитики умеют предсказывать цены на тот или иной продукт, анализируя множество факторов — это могут быть акции самой компании, стихийные бедствия в регионах производства, слухи о слиянии и поглощении, да даже неудачный твит кого-то из руководства.
Предсказательная аналитика использует данные и выдает прогнозы, эти же прогнозы складываются в озеро данных, и маркетинг может использовать их для своих отчётов и аналитики.
Получается такой круговорот данных в рамках одного озера. Довольны пока все — бизнес, отзывы максимально положительные, потому что понимает, какую уйму времени и сил этот проект экономит, и сами аналитики.
Так что работаем дальше. А кто хочет извлекать из данных максимум вместе с нами — добро пожаловать на страницу вакансий в hh.ru.
