Comments 81
За гибкость конечно спасибо, но было совсем не весело играться с этим, когда нужно было просто увеличить размер диска под простенький сайтик. Особенно когда с LVM до этого не сталкивался и вообще познаний в линуксе хватает только на установку и настройку необходимых инструментов.
К тому же, узнал об этой фиче от сапорта после того, как уперся в недостаток места на диске (я-то надеялся, что размер системного раздела увеличился нормально).
Хотелось бы просто видеть галочку при увеличении размера диска в панели, наподобии «Я хочупотрахаться с разделами настроить разделы вручную». И если пользователь эту галочку не поставил, просто выполнять описанную в вашем посте процедуру автоматически, предупредив о перезагрузке машины.
К тому же, узнал об этой фиче от сапорта после того, как уперся в недостаток места на диске (я-то надеялся, что размер системного раздела увеличился нормально).
Хотелось бы просто видеть галочку при увеличении размера диска в панели, наподобии «Я хочу
Вы всегда можете просто подключить второй диск и смонтировать его в нужный каталог. Статья про системный диск, который требует особого отношения.
ЗЫ Маленький сайтик не потребует ресайза :)
ЗЫ Маленький сайтик не потребует ресайза :)
Окей, вот к примеру, я новый клиент. Все, что мне нужно — платформа для моего приложения.
Вот создаю я машину. Что я там вижу? Задание размера диска (up to 1750Gb, по дефолту 16Gb для дебиана). Отлично, создаю с расчетом система + приложение, логично же. Где я там вижу что-то вроде «после создания машины вы сможете создать себе дополнительные диски по мере необходимости, поэтому рекомендуем указывать размер диска только под систему»? Откуда тогда я вообще могу знать, что я смогу такое сделать?
И вообще, у вас там в панели нет никакой помощи: ни рекомендаций по использованию, ни FAQ… Мол, обращайтесь по любому поводу в сапорт. Не читал бы вас на хабре, вообще обо многом не узнал бы. До вашего ответа мне вообще в голову не приходила мысль вынести тот же /var/www на отдельный диск, как раз из-за того поля задания размера диска и опыта использования других облачных сервисов.
ЗЫ Простенький != маленький :)
Вот создаю я машину. Что я там вижу? Задание размера диска (up to 1750Gb, по дефолту 16Gb для дебиана). Отлично, создаю с расчетом система + приложение, логично же. Где я там вижу что-то вроде «после создания машины вы сможете создать себе дополнительные диски по мере необходимости, поэтому рекомендуем указывать размер диска только под систему»? Откуда тогда я вообще могу знать, что я смогу такое сделать?
И вообще, у вас там в панели нет никакой помощи: ни рекомендаций по использованию, ни FAQ… Мол, обращайтесь по любому поводу в сапорт. Не читал бы вас на хабре, вообще обо многом не узнал бы. До вашего ответа мне вообще в голову не приходила мысль вынести тот же /var/www на отдельный диск, как раз из-за того поля задания размера диска и опыта использования других облачных сервисов.
ЗЫ Простенький != маленький :)
Ну, на удивление, количество обращений в саппорт очень маленькое.
Насчёт разнесения приложений на свои разделы — это более-менее общепринятая админская практика (так легче регулировать потребление места, особенно при использовании LVM).
Ещё в свою админскую практику я всегда на LAMP'е разделял www, sql, logs на разные разделы так, чтобы переполнение в одном из, не приводило к проблемам у остальных. Крупные сайты вообще получали свой комплект LV.
Предполагаю, что часть пользователей вообще об этой проблеме толком не задумывалась (лежит маленький сайтик на системном разделе и лежит, есть не просит), а часть просто сама разобралась в интерфейсе.
Насчёт отсутствия справки — наверное, да, надо. Но если мы напишем, какой процент пользователей её прочитают?
Насчёт разнесения приложений на свои разделы — это более-менее общепринятая админская практика (так легче регулировать потребление места, особенно при использовании LVM).
Ещё в свою админскую практику я всегда на LAMP'е разделял www, sql, logs на разные разделы так, чтобы переполнение в одном из, не приводило к проблемам у остальных. Крупные сайты вообще получали свой комплект LV.
Предполагаю, что часть пользователей вообще об этой проблеме толком не задумывалась (лежит маленький сайтик на системном разделе и лежит, есть не просит), а часть просто сама разобралась в интерфейсе.
Насчёт отсутствия справки — наверное, да, надо. Но если мы напишем, какой процент пользователей её прочитают?
На обычных серверах — да, я бы тоже никогда не хранил пользовательские данные вместе с системой на одном разделе. Но тут вроде как облако, несколько другая система. И о чем я говорю, не видно нигде, что можно будет полноценно работать с дисками, как на реальном сервере. В панели в том же разделе с облачными дисками, нет кнопочки создать (отдельно от машины). Она есть только в параметрах уже созданной машины.
А справку будут читать такие как я, кто не любит дергать других людей если есть возможность разобраться самому. Не обязательно расписывать каждый чих, просто описать особенности работы с вашей системой.
А справку будут читать такие как я, кто не любит дергать других людей если есть возможность разобраться самому. Не обязательно расписывать каждый чих, просто описать особенности работы с вашей системой.
В этом и есть фундаментальная идея того, что я делаю: минимальные отличия от железных серверов в той части, где это удобно и общепринято, плюшки и фичи облака там, где облако удобнее.
Модель клонирования чужих инстансов лично мне очень не нравится (см. пример с «клонированным» шаблоном с забытым ssh-ключом у Амазона).
Для таких как вы я тут как раз и пишу. А так придётся сажать кого-то, кто плохо будет понимать то, о чём пишет (а моего интереса на написание документации к интерфейсу явно не хватит).
Модель клонирования чужих инстансов лично мне очень не нравится (см. пример с «клонированным» шаблоном с забытым ssh-ключом у Амазона).
Для таких как вы я тут как раз и пишу. А так придётся сажать кого-то, кто плохо будет понимать то, о чём пишет (а моего интереса на написание документации к интерфейсу явно не хватит).
Если глянуть на панель управления чуть внимательнее, то видно, что для дисков есть вообще отдельный раздел.
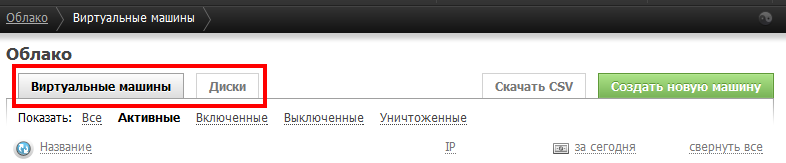

Раздел-то есть… Вот только в том разделе ничего создать нельзя, вот я о чем.
Может это я ступил, конечно, но первая мысль по назначению этой вкладки — подключение неудаленных дисков от удаленных машин к существующим. Как-то так.
Ну теперь буду знать о таких фичах с дисками, буду пользоваться =)
Может это я ступил, конечно, но первая мысль по назначению этой вкладки — подключение неудаленных дисков от удаленных машин к существующим. Как-то так.
Ну теперь буду знать о таких фичах с дисками, буду пользоваться =)
Можно не сразу делать боевой проект, а создать машину, поиграться и удалить.
А вот потом — сделать заново, как надо.
А вот потом — сделать заново, как надо.
Мы логически рассуждали, что создавать диск «просто так» смысла нет (он никуда не подключен и ничего полезного с ним не сделать). Хотя ссылочку надо дать, сейчас issue повешу.
Спасибо за совет, добавили внизу списка дисков плашку с надписью «Новый диск можно создать на вкладке „диски“ любой виртуальной машины. „
«Перезагрузиться (спасибо линуксу, отказывающемуся делать перечитывание заблокированного диска с корневым разделом)»
Эм. Сижу, туплю. 1&1 позволяют ресайзить в том числе и корневой на cloud серверах без остановки.
Как так получается?
Эм. Сижу, туплю. 1&1 позволяют ресайзить в том числе и корневой на cloud серверах без остановки.
Как так получается?
Вероятнее всего они не используют таблицу разделов. Если сделать файловую систему на весь диск, то ресайз можно будет делать на ходу. Но в этом случае на разделе нельзя будет создавать дополнительные разделы раз, два, его нельзя будет увеличить дальше лимита на один диск (то есть вогнать в LVM больше одного диска), три, многие инсталлеры ОС не любят идею «ставиться прямо на ФС без раздела».
Там LVM, дефолтная набивка 4 раздела. Сечас, правда, нет ни одного живого, для тестов. Виртуализация на базе XEN.
и кстати, gparted помнится нормально ресайзил — зачем fdisk'ом del/create?
и еще вопрос — у вас таблица GPT?
и еще вопрос — у вас таблица GPT?
А консольная утилита partprobe разве не обновляет таблицу разделов для ядра? Что-то я не помню, что бы мне приходилось перегружать линух при смене размеров.
Нельзя обновить таблицу разделов у устройства, у которого есть примонтированные разделы.
на самом деле partprobe даже не нужен, достаточно blockdev --rereadpt /dev/xvda (делает то же самое, а есть во всех дистрибутивах).
# partprobe /dev/xvda
[ 140.167440] blkfront: write barrier: empty xvda op failed
[ 140.167448] blkfront: xvda: barrier: disabled
Error: Partition(s) 2 on /dev/xvda have been written, but we have been unable to
inform the kernel of the change, probably because it/they are in use. As a res
ult, the old partition(s) will remain in use. You should reboot now before maki
ng further changes.
на самом деле partprobe даже не нужен, достаточно blockdev --rereadpt /dev/xvda (делает то же самое, а есть во всех дистрибутивах).
Н-да. Действительно становится интерсно. На днях ресайзил рейд на cciss (пулреквест на гитхабе).
так ребутить пришлось дважды сервер: первырй раз чтоб прочухал что рейд стал втрое больше
второй раз чтоб перечитал после ptmax'а…
так ребутить пришлось дважды сервер: первырй раз чтоб прочухал что рейд стал втрое больше
второй раз чтоб перечитал после ptmax'а…
Скажите, а планируется ли создание жестких дисков с объемом «по требованию»?
Т.е. сколько используется по факту, столько и оплачивается.
Т.е. сколько используется по факту, столько и оплачивается.
Судя по статистике в панели, так оно и есть. Ограничен лишь максимальный объём, задаваемый при создании диска.
Вы платите за то, что вам на облаке выделили чисто для вас определенный объем HDD.
Это место зарезервировано только для вас, больше его никто не использует.
Поэтому, вы его уже купили, а то что оно простаивает — дело ваше.
Даже если технически и возможно выделять место на лету (в чем я сильно сомневаюсь), мне кажется это будет очень сложно и медленно. Ну и можно представить совсем гипотетическую ситуацию, когда вам понадобится залить что-то на сервер — а место кончилось!
Это место зарезервировано только для вас, больше его никто не использует.
Поэтому, вы его уже купили, а то что оно простаивает — дело ваше.
Даже если технически и возможно выделять место на лету (в чем я сильно сомневаюсь), мне кажется это будет очень сложно и медленно. Ну и можно представить совсем гипотетическую ситуацию, когда вам понадобится залить что-то на сервер — а место кончилось!
Хуже: вам пообещали 10Гб, вы заняли 5, апач пытается записать в лог и получает IO error из-за того, что места на самом деле больше нет.
По этой причине у нас нет thin provision'а.
По этой причине у нас нет thin provision'а.
В чем проблема мониторить объем запаса и при падении, скажем, ниже 1-2 Tb, добавлять новые диски?
А если не уследим или не успеем? У нас в истории была пара моментов, когда у нас резко приходил клиент с большими запросами и съедал всё свободное место. Для нас это означал ответ клиентам «извините, машины временно создавать нельзя из-за задержек с поставками оборудования».
А если мы будем это отвечать на вопрос «а почему у меня машина падает?». Спасибо, не надо.
C thin provision трудно предсказать потребление. Ну заказал кто-то себе на 4Тб дисков. Я слежу, чтобы было хотя бы 3 свободно. После чего (через месяц) человек решает-таки залить данные. И?
А если я буду резервировать достаточный запас — так это и есть текущая ситуация.
А если мы будем это отвечать на вопрос «а почему у меня машина падает?». Спасибо, не надо.
C thin provision трудно предсказать потребление. Ну заказал кто-то себе на 4Тб дисков. Я слежу, чтобы было хотя бы 3 свободно. После чего (через месяц) человек решает-таки залить данные. И?
А если я буду резервировать достаточный запас — так это и есть текущая ситуация.
Это вопросы такого же вида «а если будет не хватать» 1) памяти; 2) процессора 3) полосы. С ними же вы вопрос уже решили. А то, действительно, отсутствие биллинга по занятости диска, не дает складываться красивой картинке идеального pay by use.
В принципе, древняя теория массового обслуживания. Следить можно не в абсолютных цифрах, а в относительных. Оценивать скорость роста потребления.
Можно даже точно оценивать верхнюю границу по сумме остатков на клиентских счетах — больше, чем клиенты способны оплатить, они потребить диска не смогут.
В принципе, древняя теория массового обслуживания. Следить можно не в абсолютных цифрах, а в относительных. Оценивать скорость роста потребления.
Можно даже точно оценивать верхнюю границу по сумме остатков на клиентских счетах — больше, чем клиенты способны оплатить, они потребить диска не смогут.
Если вам не додадут 1% CPU, вы этого просто не заметите. Если не додадут 30% это будет относительно заметно, но терпимо. Если не хватит памяти — вы выползете в своп. Если не хватит полосы — будут потери пакетов и всё.
Если вам не «отдадут» зарезервированное место, вы получите фатальный сбой файловой системы, который полностью парализует работу этого диска, а возможно, и остальных. После этого у вас либо отвалится файловая система, либо перезагрузится виртуальная машина. В худшем случае после перезагрузки она повиснет в ожидании выполнения дисковой операции, которая не может выполниться из-за невозможности записать.
В этом фундаментальная проблема с 'space'. В отличие от остальных ресурсов (у которых есть graceful degradation), невозможность выполнить хотя бы одну дисковую операцию фатальна.
Если вам не «отдадут» зарезервированное место, вы получите фатальный сбой файловой системы, который полностью парализует работу этого диска, а возможно, и остальных. После этого у вас либо отвалится файловая система, либо перезагрузится виртуальная машина. В худшем случае после перезагрузки она повиснет в ожидании выполнения дисковой операции, которая не может выполниться из-за невозможности записать.
В этом фундаментальная проблема с 'space'. В отличие от остальных ресурсов (у которых есть graceful degradation), невозможность выполнить хотя бы одну дисковую операцию фатальна.
Нет, не логично. Никакой фундаментальной разницы. Все зависит от скорости деградации и реакции на нее.
Если вы не будете следить за сетью и потери доползут до 20%, это будет «всё» с большой буквы — отказ. Если будете недодавать памяти, то наступившие у клиентов убийства процессов из-за Out of Memory могут безвозвратно порушить данные. Если у клиента посещаемость вырастет в 10 раз, а вы ему не дадите процессора, это отнюдь не будет терпимо, его машина просто ляжет. А при невозможности записи на диск при журналируемой FS с работающими барьерами, авария будет ничуть не серьезнее.
Для дисков достаточно считать деградацией, требующей наращивания ресурсов, понижение свободного пространства, до, скажем, 20% с расстрелом допустившего понижение до 5%.
Если вы не будете следить за сетью и потери доползут до 20%, это будет «всё» с большой буквы — отказ. Если будете недодавать памяти, то наступившие у клиентов убийства процессов из-за Out of Memory могут безвозвратно порушить данные. Если у клиента посещаемость вырастет в 10 раз, а вы ему не дадите процессора, это отнюдь не будет терпимо, его машина просто ляжет. А при невозможности записи на диск при журналируемой FS с работающими барьерами, авария будет ничуть не серьезнее.
Для дисков достаточно считать деградацией, требующей наращивания ресурсов, понижение свободного пространства, до, скажем, 20% с расстрелом допустившего понижение до 5%.
Есть фундаментальная разница. После того, как проблема с полосой будет исправлена, ситуация мгновенно нормализуется. Если _после_ фейла из-за предъявленного места для оверкоммита я каким-то образом таки засуну в LVM с клиентскими дисками больше места, то у _ВСЕХ_ клиентов, у которых были проблемы из-за этого (а мой скромный прогноз в этот момент — примерно 90% всех, кто запущен) проблемы сохранятся и потребуют ручного вмешательства.
На фоне этого кратковременный взбрык сети с потерей пакетов — ерунда и говорить не о чем.
Далее, насчёт деградации… Дело в том, что главной проблемой является размер дисков и скорость их заполнения. Мне для ресайза LVM под XCP (мягко говоря не самая простая операция) потребуется не менее 4-5 часов возни по всем хостам. Операция не документированная, требующая ручного хака на каждом из хостов виртуализации с перемиграцией всех затронутых клиентов и т.д. Ад, кошмар и ужас. Я такое проделывал в начале 2011, когда мы только запустились и речь шла о примерно 400 клиентских машинах. Тогда на 20 хостах я справился (но проклял всё и вся). Теперь не справлюсь. У нас средняя плотность размещения — от 400 до 1000 дисков на каждом хранилище, и время «добавления» будет невозможно долгим.
Размер дисков очень серьёзный вопрос. Дело в том, что «взбрыкнувшийся клиент» по процессору сожрёт 800% CPU (у нас есть такие на постоянной основе). Ну выделен ему персональный хост и всё. То же и по памяти — ну съел он 40Гб и успокоился.
А с диском… Предъявил он к заполнению 2Тбх10 места. И? А я считал, что у меня ещё 15Тб в запасе.
На фоне этого кратковременный взбрык сети с потерей пакетов — ерунда и говорить не о чем.
Далее, насчёт деградации… Дело в том, что главной проблемой является размер дисков и скорость их заполнения. Мне для ресайза LVM под XCP (мягко говоря не самая простая операция) потребуется не менее 4-5 часов возни по всем хостам. Операция не документированная, требующая ручного хака на каждом из хостов виртуализации с перемиграцией всех затронутых клиентов и т.д. Ад, кошмар и ужас. Я такое проделывал в начале 2011, когда мы только запустились и речь шла о примерно 400 клиентских машинах. Тогда на 20 хостах я справился (но проклял всё и вся). Теперь не справлюсь. У нас средняя плотность размещения — от 400 до 1000 дисков на каждом хранилище, и время «добавления» будет невозможно долгим.
Размер дисков очень серьёзный вопрос. Дело в том, что «взбрыкнувшийся клиент» по процессору сожрёт 800% CPU (у нас есть такие на постоянной основе). Ну выделен ему персональный хост и всё. То же и по памяти — ну съел он 40Гб и успокоился.
А с диском… Предъявил он к заполнению 2Тбх10 места. И? А я считал, что у меня ещё 15Тб в запасе.
Не понимаю, зачем было делать так сложно, но, не буду спорить, вероятно, вам так удобнее.
Достаточно было сразу честно сказать, что из-за особенностей вашей дисковой системы это трудно или невозможно реализовать, а не придумывать мифические недостатки thin provisioning. У которой есть, разумеется, свои минусы, но совсем не те, о которых вы сейчас говорите.
Желающему записать 20 Тб при скорости 100 Мбайт/сек понадобится больше двух суток. То, что при этом у всех его соседей будет ощутимо тормозить диск и уже это будет деградацией сервиса, другой вопрос.
Но зачем вы решили, что при коммите одного обязательно должны пострадать все? Ограничьте только клиента, который вдруг решил исчерпать хранилище. Скажите ему заранее, еще задолго до того, как все заполнится, что все, не можете дать больше. Ведь если он памяти сотню гигов запросит, то же самое ему скажете.
По какой схеме это делать, можете и сами додумать.
Достаточно было сразу честно сказать, что из-за особенностей вашей дисковой системы это трудно или невозможно реализовать, а не придумывать мифические недостатки thin provisioning. У которой есть, разумеется, свои минусы, но совсем не те, о которых вы сейчас говорите.
Желающему записать 20 Тб при скорости 100 Мбайт/сек понадобится больше двух суток. То, что при этом у всех его соседей будет ощутимо тормозить диск и уже это будет деградацией сервиса, другой вопрос.
Но зачем вы решили, что при коммите одного обязательно должны пострадать все? Ограничьте только клиента, который вдруг решил исчерпать хранилище. Скажите ему заранее, еще задолго до того, как все заполнится, что все, не можете дать больше. Ведь если он памяти сотню гигов запросит, то же самое ему скажете.
По какой схеме это делать, можете и сами додумать.
1) Соседи не будут тормозить :) Многократно проверялось. Способность СХД у нас — примерно 500Мб/с, плюс эти 500Мб/с не мешаются произвольному доступу (т.к. в flashcache идёт только рандом).
2) Для того, чтобы «предъявить» 20Тб к provisioning'у не нужно делать линейные операции — достаточно в каждый блок (у коммерческих СХД примерно 256кБ, у нас примерно 2Мб) записать по кусочку (2кб). Это даст очень быстрое исчерпание свободного места.
3) Я не могу ограничить клиента, потому что ему это уже было обещанно. Проблема ровно такая же, как при оверселле, но осложняющаяся последствиями.
«сами додумать» — я долго думал. Нет тут красивого решения.
2) Для того, чтобы «предъявить» 20Тб к provisioning'у не нужно делать линейные операции — достаточно в каждый блок (у коммерческих СХД примерно 256кБ, у нас примерно 2Мб) записать по кусочку (2кб). Это даст очень быстрое исчерпание свободного места.
3) Я не могу ограничить клиента, потому что ему это уже было обещанно. Проблема ровно такая же, как при оверселле, но осложняющаяся последствиями.
«сами додумать» — я долго думал. Нет тут красивого решения.
Если я правильно понимаю:
1) В итоге от 90% клиентов, пострадавших от thin provisioning, разговор пришел к одному пострадавшему, которому может не получится записать 20 Тб за пол-дня.
2) Главным препятствием реализации биллинга по потреблению диска является забота об этом гипотетическом клиенте, то, что у вас для него нет красивого решения.
3) Претензий к схеме thin provisioning самой по себе нет.
Так?
1) В итоге от 90% клиентов, пострадавших от thin provisioning, разговор пришел к одному пострадавшему, которому может не получится записать 20 Тб за пол-дня.
2) Главным препятствием реализации биллинга по потреблению диска является забота об этом гипотетическом клиенте, то, что у вас для него нет красивого решения.
3) Претензий к схеме thin provisioning самой по себе нет.
Так?
Вы не поняли. ОДИН такой человек создаст проблемы всем окружающим. Потому что thin provision приведёт к тому, что обещано было всем, а (частично) получил один. Остальные при записи получат ошибки записи даже при небольшом объёме «предъявления» provision к заполнению.
Аккаунтить thin provision мы готовы прямо сейчас (т.к. мы используем поле physical utilization из xapi). Для того, чтобы включить thin provision достаточно сказать device-config:allocation=thin при создании SR.
Аккаунтить thin provision мы готовы прямо сейчас (т.к. мы используем поле physical utilization из xapi). Для того, чтобы включить thin provision достаточно сказать device-config:allocation=thin при создании SR.
Сейчас вы говорите, что один создаст проблему всем. Я приводил раньше элементарное решение на этот случай и получил на это возражение «3) Я не могу ограничить клиента, потому что ему это уже было обещанно.» Где логика?
Если не случилось додумать решение, объясню подробнее:
Скажем, есть N клиентов, есть запас 20 Тб. Один клиент стал писать чудесным образом 500 Мб/сек и за 3 часа записал 5 Тб, свободных осталось 15 Тб.
Умные скрипты мониторинга видят, что дело грозит бедой и начинают ограничивать запись того одного, кто пишет так много. Можно самым простым способом — давать ему ошибку на запись, можно чуть сложнее — поставить для него шейпер записи на 1 Мбайт/сек. Можно еще проще — шейпить по скорости записи всех, но так лучше не делать.
Если не случилось додумать решение, объясню подробнее:
Скажем, есть N клиентов, есть запас 20 Тб. Один клиент стал писать чудесным образом 500 Мб/сек и за 3 часа записал 5 Тб, свободных осталось 15 Тб.
Умные скрипты мониторинга видят, что дело грозит бедой и начинают ограничивать запись того одного, кто пишет так много. Можно самым простым способом — давать ему ошибку на запись, можно чуть сложнее — поставить для него шейпер записи на 1 Мбайт/сек. Можно еще проще — шейпить по скорости записи всех, но так лучше не делать.
Я физически не могу ограничить клиента в рамках того, что ему предоставлено. В существующей модели thin provision она находится ниже, чем блочные устройства клиентов.
Какое многозначное слово «физический». Не можете физически, потому что обещано и будет нарушение договора, или не можете, потому что технически невозможно в используемом вами хранилище?
Только, пожалуйста, не нужно привлекать к ответственности ни в чем не повинную модель thin provisioning. Она на то и модель, концепция одного аспекта организации хранилища, и не создает технических ограничений.
То, что XCP не дает готового механизма защиты от переполнения при коммите в TP, не означает того, что это технически невозможно. Вполне себе заурядная задача по допиливанию.
Только, пожалуйста, не нужно привлекать к ответственности ни в чем не повинную модель thin provisioning. Она на то и модель, концепция одного аспекта организации хранилища, и не создает технических ограничений.
То, что XCP не дает готового механизма защиты от переполнения при коммите в TP, не означает того, что это технически невозможно. Вполне себе заурядная задача по допиливанию.
«Физически» означает, что если пытаться эту область переделать, то на выходе получится что-то, что уже не будет нашим облаком. Там будет другая модель списаний, другая модель выделения места и т.д.
Другими словами, это не «доработка», а принципиальное переделывание всего.
Кроме того, общая проблема thin provision — oversubscription не может быть решена. Никакими средствами с точки зрения платформы виртуализации.
Есть красивое решение — в нём будут специальные файловые системы, готовые к «бесконечному» диску, выделяющие место по мере надобности и освобождающие его так же, способые gracefully пережить невыделение места и т.д. — но я точно могу сказать, что мы в ближайшие годы даже близко не подойдём к такому уровню разработки.
Другими словами, это не «доработка», а принципиальное переделывание всего.
Кроме того, общая проблема thin provision — oversubscription не может быть решена. Никакими средствами с точки зрения платформы виртуализации.
Есть красивое решение — в нём будут специальные файловые системы, готовые к «бесконечному» диску, выделяющие место по мере надобности и освобождающие его так же, способые gracefully пережить невыделение места и т.д. — но я точно могу сказать, что мы в ближайшие годы даже близко не подойдём к такому уровню разработки.
Кроме того, общая проблема thin provision — oversubscription не может быть решена. Никакими средствами с точки зрения платформы виртуализации.
Я указал уже три рабочих варианта, а вы — «не может быть решена». И упорно гнобите thin provisioning вообще, в то время как ограничение касается только выбранной вами реализации.
Понятно, что если какую-то функцию не хочется реализовывать или просто сложно, то можно найти сотню других причин, объясняющих, почему это не надо делать. Возводить при этом напраслину на технологии — это какая-то мелкая подлость. Достаточно сказать, экономический эффект не ясен — бюджет на такую переделку не предусмотрен.
Кстати, специальной файловой системой заниматься смысла тоже не больше. Она может быть и переживет невыделение места, а mysqld при проблеме записи может падать точно также аварийно.
Я указал уже три рабочих варианта, а вы — «не может быть решена». И упорно гнобите thin provisioning вообще, в то время как ограничение касается только выбранной вами реализации.
Понятно, что если какую-то функцию не хочется реализовывать или просто сложно, то можно найти сотню других причин, объясняющих, почему это не надо делать. Возводить при этом напраслину на технологии — это какая-то мелкая подлость. Достаточно сказать, экономический эффект не ясен — бюджет на такую переделку не предусмотрен.
Кстати, специальной файловой системой заниматься смысла тоже не больше. Она может быть и переживет невыделение места, а mysqld при проблеме записи может падать точно также аварийно.
Я ещё раз повторю, что в отличие от остальных видов «недопоставки», в которых предоставление дополнительных ресурсов автоматически снимает проблему, «недопоставка» места приводит к фатальным последствиям для клиентов, в т.ч. и не связанных с «виновником» резкого запроса.
Внезапный всплеск активности на нескольких машинах — и проблемы касаются сотен других.
Предложение «шейпить плохих» приводит к вопросу: а кто плохой? Ведь место по-чуть-чуть занимают все (логи, их ротация, борьба с фрагментацией разных ФС и т.д.), и когда я ощутил «не хватает места» — что я должен сделать? Снизить скорость записи всем? Ведь в момент записи неизвестно куда идёт запрос — на tp или на новое место. Если же я буду шейпить всех, кто много пишет, то это больно ударит по совершенно ничего не подозревающихлюдей программ, которые мурыжат одну и ту же базу на 2к IOPS'ах.
Внезапный всплеск активности на нескольких машинах — и проблемы касаются сотен других.
Предложение «шейпить плохих» приводит к вопросу: а кто плохой? Ведь место по-чуть-чуть занимают все (логи, их ротация, борьба с фрагментацией разных ФС и т.д.), и когда я ощутил «не хватает места» — что я должен сделать? Снизить скорость записи всем? Ведь в момент записи неизвестно куда идёт запрос — на tp или на новое место. Если же я буду шейпить всех, кто много пишет, то это больно ударит по совершенно ничего не подозревающих
Вас злой демон заставляет реализовать самый плохой вариант? Проявите благоразумие, выбирайте хороший вариант. Тем более, даже думать можно не трудиться, я его уже вам писал ранее.
Блокируйте или ставьте шейпер на проблемного клиента в тот момент, когда срабатывает порог минимального запаса, 10%-20%. Как определить, кто проблемный? Элементарно. Тот, кто при экстраполяции потребления исчерпает ресурс быстрее, чем будет возможно его нарастить. Если лень с математикой заморачиваться, просто считать проблеными лидеров по росту потребления диска за последний день.
Если хотите показать недостатки thin provisioning, давайте, поспорьте с этим вариантом. Не нужно залезать на посторонние шкафы и спорить с тем, что будет видно с них.
Блокируйте или ставьте шейпер на проблемного клиента в тот момент, когда срабатывает порог минимального запаса, 10%-20%. Как определить, кто проблемный? Элементарно. Тот, кто при экстраполяции потребления исчерпает ресурс быстрее, чем будет возможно его нарастить. Если лень с математикой заморачиваться, просто считать проблеными лидеров по росту потребления диска за последний день.
Если хотите показать недостатки thin provisioning, давайте, поспорьте с этим вариантом. Не нужно залезать на посторонние шкафы и спорить с тем, что будет видно с них.
Меня горький опыт заставляет всегда говорить про самый плохой сценарий. Не подумаешь заранее, будешь думать в аварийном режиме «на месте».
Кроме того, ваши предложения по резервированию сильно крутые. Допустим, у меня размер одного SR 30Тб. Какой я могу себе позволить overprovision и сколько надо резервировать до начала «прижатия»?
Кроме того, ваши предложения по резервированию сильно крутые. Допустим, у меня размер одного SR 30Тб. Какой я могу себе позволить overprovision и сколько надо резервировать до начала «прижатия»?
Сценарий и реализация — совершенно разные вещи. В разных реализациях худшие сценарии могут сильно отличаться. Чтобы не попадать часто в аварийный режим, выбирать хорошую реализацию, в которой худший сценарий даст минимальный ущерб.
Про 20 Тб — это просто так за число зацепился. Порог и прочее по задаче можно точнее считать. Например, если вы уже знаете, что средняя скорость роста объема данных для вас за последний месяц составила 100 Гб в день, время добавления в СХД новых 10 Тб составляет 7 дней, то запас свободного места должен быть достаточным для того, чтобы без спешки успеть провести апгрейд и учетом рисков поставки оборудования невовремя или задержек по другим причинам. Скажем, считать что на апгрейд требуется 20 дней. Тогда порог срабатывания должен быть 2 Тб остатка. Схема общая, ее можно еще в зависимости от условий усложнять.
Про 20 Тб — это просто так за число зацепился. Порог и прочее по задаче можно точнее считать. Например, если вы уже знаете, что средняя скорость роста объема данных для вас за последний месяц составила 100 Гб в день, время добавления в СХД новых 10 Тб составляет 7 дней, то запас свободного места должен быть достаточным для того, чтобы без спешки успеть провести апгрейд и учетом рисков поставки оборудования невовремя или задержек по другим причинам. Скажем, считать что на апгрейд требуется 20 дней. Тогда порог срабатывания должен быть 2 Тб остатка. Схема общая, ее можно еще в зависимости от условий усложнять.
Вот именно тут и есть тонкость. Если с сетью, процессорами и памятью можно использовать именно эту схему «ой, что-то тесновато стало, начинаем апгрейд сети/вводим новые хосты в пул», то с thin provision возможна ситуация «резервировали 2Тб, их сожрали за три часа». Причём сожрали не для себя (сами себе злобные буратины), а для соседей. Что сильно червато и чего следует избегать.
Такое ощущение, что вы у меня все это время одно слово из десяти читаете. Или лень чуть-чуть подумать. Я уже писал об это раз пять. Давайте я последний раз напишу. Если и сейчас останется непонятно, закрываем тему и буратины остаются сами себе теми, кто есть.
Когда ререзв становится меньше порога, начинать шейпить того клиента, потребление которого грозит исчерпать резевр быстрее, чем сделается апгрейд. Если он не один, то шейпить всех, у кого потребление превышает «нормальное». Соседи не страдают вообще. А тот или те, кто стали вдруг очень много писать, замедлятся, чтобы для них успели нарастить хранилище.
Если ситуация, когда нужно шейпить и апгрейдить, случается часто, это означает одну хорошую вещь и одноу плохую. Хорошая — продажа услуги быстро растет. Плохая — тот, кто планирует резерв, неоправданно его жмотит. Когда клиенты каждую субботу сжирают по 2 Тб за три часа, глупо держать резевр 2 Тб. Можете воспользоваться самостоятельно той формулой, для расчета запаса, которую я уже давал — добавьте в нее еще эти 2 Тб в неделю.
Для этого всего нужен QoS или просто шейпинг. Но если у вас шейпинг невозможно или трудно реализовать, то это не проблема thin provisioning как модели, а проблемы вашей конкретной реализации хранилища.
Когда ререзв становится меньше порога, начинать шейпить того клиента, потребление которого грозит исчерпать резевр быстрее, чем сделается апгрейд. Если он не один, то шейпить всех, у кого потребление превышает «нормальное». Соседи не страдают вообще. А тот или те, кто стали вдруг очень много писать, замедлятся, чтобы для них успели нарастить хранилище.
Если ситуация, когда нужно шейпить и апгрейдить, случается часто, это означает одну хорошую вещь и одноу плохую. Хорошая — продажа услуги быстро растет. Плохая — тот, кто планирует резерв, неоправданно его жмотит. Когда клиенты каждую субботу сжирают по 2 Тб за три часа, глупо держать резевр 2 Тб. Можете воспользоваться самостоятельно той формулой, для расчета запаса, которую я уже давал — добавьте в нее еще эти 2 Тб в неделю.
Для этого всего нужен QoS или просто шейпинг. Но если у вас шейпинг невозможно или трудно реализовать, то это не проблема thin provisioning как модели, а проблемы вашей конкретной реализации хранилища.
И, да, на тот случай, если шейпера нет, а защитить соседей хочется, то достаточно после пересечения порога блокировать запись только для «опасного» клиента. Но это я уже тоже писал раньше.
Два замечания:
1) На основании чего (пункт договора?) вы будете шейпить клиента (ухудшать качество сервиса), исправно платящего за услуги и не нарушающего договор?
2) Кажется, весь этот спор зашел не туда. Изначально вопрос был в том, чтобы клиент платил только за фактически занятое место. К сожалению, thin provisioning никакого отношения к этому не имеет, так как если клиент займет блок данными, то даже если данные потом оттуда удалит (на уровне ФС), то блок все равно останется за клиентом, и он будет за него платить.
(По сути, отсутствие thin provisioning это наша проблема, так как надо закупать больше хранилок, даже если они используются не полностью)
Это фундаментальная проблема. Мы видим данные клиента на уровне блочного устройства, а не на уровне ФС, и никак не можем реально отслеживать «только используемый объем данных».
Настоящая альтернатива- это услуги хранилища на уровне файлов (ФС, например, S3, если не ошибаюсь), но такие хранилища невозможны (пока?) для использования в качестве ФС системного раздела.
Оптимальный для клиента вариант: системные данные на небольшом блочном устройстве фиксированного размера, остальные данные на распределенных ФС на уровне файлов с оплатой по факту занятого места (к сожалению, у нас такого сейчас нет).
1) На основании чего (пункт договора?) вы будете шейпить клиента (ухудшать качество сервиса), исправно платящего за услуги и не нарушающего договор?
2) Кажется, весь этот спор зашел не туда. Изначально вопрос был в том, чтобы клиент платил только за фактически занятое место. К сожалению, thin provisioning никакого отношения к этому не имеет, так как если клиент займет блок данными, то даже если данные потом оттуда удалит (на уровне ФС), то блок все равно останется за клиентом, и он будет за него платить.
(По сути, отсутствие thin provisioning это наша проблема, так как надо закупать больше хранилок, даже если они используются не полностью)
Это фундаментальная проблема. Мы видим данные клиента на уровне блочного устройства, а не на уровне ФС, и никак не можем реально отслеживать «только используемый объем данных».
Настоящая альтернатива- это услуги хранилища на уровне файлов (ФС, например, S3, если не ошибаюсь), но такие хранилища невозможны (пока?) для использования в качестве ФС системного раздела.
Оптимальный для клиента вариант: системные данные на небольшом блочном устройстве фиксированного размера, остальные данные на распределенных ФС на уровне файлов с оплатой по факту занятого места (к сожалению, у нас такого сейчас нет).
Клиента можно шейпить на том же основании, на котором ему может быть не предоставлено процессорное время или увеличение оперативной памяти. Это вопрос не техничесикй, а формулировки в договоре.
По поводу того, куда зашел спор, не стоит писать это мне. Я спорю о другом. Amarao утверждает, что проблема, когда клиент съедает много места и вредит остальным клиентам, является проблемой thin provisioning. Я возражаю тем, что это проблема конкретной реализации хранилища и существует много способов решения проблемы. которые от thin provisioning не зависят.
По поводу того, куда зашел спор, не стоит писать это мне. Я спорю о другом. Amarao утверждает, что проблема, когда клиент съедает много места и вредит остальным клиентам, является проблемой thin provisioning. Я возражаю тем, что это проблема конкретной реализации хранилища и существует много способов решения проблемы. которые от thin provisioning не зависят.
>>1) памяти; 2) процессора 3) полосы.
Нехватка всех этих ресурсов решается миграцией машин между хостами. Мигрировать данные между хранилищами, как вы понимаете, не возможно.
Нехватка всех этих ресурсов решается миграцией машин между хостами. Мигрировать данные между хранилищами, как вы понимаете, не возможно.
Если все машины перегружены, миграция не поможет. К хранилищу можно подключить еще дисков.
Мы всегда держим хосты с приличным резервом (на случай поломки одного из или прихода прожорливого клиента). В отдельное хранилище дисков не добавить (уже все места заняты), растянуть клиентский диск на несколько хранилищ также не возможно технически.
В принципе, с некоторым скрипом, возможна. Но проблема именно в том, что если хост на 300% (ядер) перегружен и у нас там 30 виртуалок, то это 10% подтормаживание для всех жаждущих. Неприятно — но едва ощутимо. И есть время смигрировать, и как только смигрируются, всё станет хорошо.
А с дисками «как только, так станет хорошо» не покатит, потому что «как только, так сразу очень плохо».
А с дисками «как только, так станет хорошо» не покатит, потому что «как только, так сразу очень плохо».
Очень тяжёлый вопрос. Проблема в том, что по-настоящему быстрым можно сделать только блочный уровень, а его сделать «по требованию» трудно. А файловый доступ будет медленным. Хотя, наверное, что-то подобное мы запустим.
Ага, такого сервиса не хватает. Для бэкапов, например. Вообще, мне очень нравится организация Amazon S3. И вебморда есть, и API, и права доступа, и отдача по HTTP, что очень важно, под своим доменом. Я держу у вас машину, но файлохранилище (в том числе файлопомойку) держу отдельно на амазоне.
C S3-подобными системами есть следующая проблема: вы не можете его использовать как настоящую ФС. Например, туда нельзя положить БД от Postgre/MySQL.
У меня есть несколько идей, как его можно реализовать, но всё натыкается на простую проблему: придётся написать дохрена кода на очень низком уровне, а потом долго и нудно пушить в апстрим. Это дорого (грубая оценка такого удовольствия — больше 10 миллионов рублей, и это best case, когда задуманное будет работать как задумано).
У меня есть несколько идей, как его можно реализовать, но всё натыкается на простую проблему: придётся написать дохрена кода на очень низком уровне, а потом долго и нудно пушить в апстрим. Это дорого (грубая оценка такого удовольствия — больше 10 миллионов рублей, и это best case, когда задуманное будет работать как задумано).
Практика показывает, что даже такой сервис («который невозможно использовать как настоящую ФС») востребован. Бэкапы, архивы, помойки и обменники. Есть множество сервисов (как публичных, так и внутрекорпоративных, например), с которыми было бы удобно использовать «резиновое» хранилище. А тот факт, что файл можно отдать в веб по адресу my-s3-storage.mysite.ru/filename (как у S3) придает хранилищу еще больший функционал.
Причем в данном случае, при внезапной нехватке места вы просто отдадите ошибку. И это ничего не поломает, так как пользователь обязан обрабатывать такие ошибки. В смысле, у пользователя ничего не упадет, в отличии от ситуации, которую вы описывали выше.
Вывод: такой сервис — хороший компромисс между резиновостью и качеством. А резиновые диски для виртуалок, на мой взгляд не нужны. Проблемы с большими перепадами требуемого места на диске нужно решать иначе…
Причем в данном случае, при внезапной нехватке места вы просто отдадите ошибку. И это ничего не поломает, так как пользователь обязан обрабатывать такие ошибки. В смысле, у пользователя ничего не упадет, в отличии от ситуации, которую вы описывали выше.
Вывод: такой сервис — хороший компромисс между резиновостью и качеством. А резиновые диски для виртуалок, на мой взгляд не нужны. Проблемы с большими перепадами требуемого места на диске нужно решать иначе…
Немного терпения ;)
Кстати… А есть организации блочного рейда а-ля drbd но на 3 и более нод? Чтоб слить десяток нод в единое пространство, которое живо пока жива хотя бы половина их.
drbd такое не позволяет — «многоуровневая» схема становится негомогенной…
drbd такое не позволяет — «многоуровневая» схема становится негомогенной…
Увы, нет, и это очень раздражает. Второе, что раздражает. что drbd не является device-mapper устройством со всеми вытекающими из-за этого странностями во взаимодействии…
От drbd я уже отказался, после нескольких весёлых дней и ночей с brainsplit, тормозами на ресинхронизации и глюками после ресайза.
А глустер не понравился скоростью.
А глустер не понравился скоростью.
Кстати, что-то до меня тихо доходит, что нельзя линейно масштабировать оставляя выживаемость на уровне половины.
Число копий должно быть больше числа машин, допустимых к смерти. То есть если у нас 5 машин и допустима смерть 2х машин, это надо тройную копию. Соответственно, пространство масштабироваться будет совсем не линейно, и толку становится не много…
Мы имеем в итоге пространство равное 3/5 от суммарного… в принципе, это уже лучше, чем 1/2.
С другой стороны — это же лучше, чем 2 машины и допустимо сдыхание только одной…
Что-то даже и не знаю. Может, попытаться обточить напильником drbd? Используя мультикаст адреса для связи, вполне можно оставить траффик на приемлимом даже для gige уровне ведь.
В случае всё тех же 5 нод и 3х копий, запись в один слайс будет отсылаться на мультикаст, который ловить будут две ноды — но отсылка одна, надо только будет дождаться ответа не от одной, а от двух нод.
В принципе, отличие будет не сильно велико от двунодового кластера. А читать можно будет с трёх дисков, что даст сильную прибавку в случае обычных SATA дисков.
И позволит получить плюс, при использовании SAS дисков и минимум 3хгигабитному линку между ними…
Число копий должно быть больше числа машин, допустимых к смерти. То есть если у нас 5 машин и допустима смерть 2х машин, это надо тройную копию. Соответственно, пространство масштабироваться будет совсем не линейно, и толку становится не много…
A1 A2 A3 == == == B1 B2 B3 == == == C1 C2 C3 D3 == == D1 D2 F2 F3 == == F1
Мы имеем в итоге пространство равное 3/5 от суммарного… в принципе, это уже лучше, чем 1/2.
С другой стороны — это же лучше, чем 2 машины и допустимо сдыхание только одной…
Что-то даже и не знаю. Может, попытаться обточить напильником drbd? Используя мультикаст адреса для связи, вполне можно оставить траффик на приемлимом даже для gige уровне ведь.
В случае всё тех же 5 нод и 3х копий, запись в один слайс будет отсылаться на мультикаст, который ловить будут две ноды — но отсылка одна, надо только будет дождаться ответа не от одной, а от двух нод.
В принципе, отличие будет не сильно велико от двунодового кластера. А читать можно будет с трёх дисков, что даст сильную прибавку в случае обычных SATA дисков.
И позволит получить плюс, при использовании SAS дисков и минимум 3хгигабитному линку между ними…
Не надо пытаться делать сложный стек из drbd. У нас сейчас главным потолком производительности выступает latency DRBD. Если их будет несколько — это будет смерть всему живому.
Вообще, насколько я понимаю, под linux нет (полу)готового решения сетевого резервирования (кроме DRBD).
Вообще, насколько я понимаю, под linux нет (полу)готового решения сетевого резервирования (кроме DRBD).
А это точно latency именно DRBD, а не сетевого стека?
На inifniband'е вроде latency должен приближаться к нулю…
По крайней мере, гораздо ниже чем на гиге.
На inifniband'е вроде latency должен приближаться к нулю…
По крайней мере, гораздо ниже чем на гиге.
Во-первых у нас 10G, раз, два, где ж это видано, когда суммарная latency от iscsi и tapdisk (драйвер диска для виртуалки) больше, чем аналогичная у drbd через аналогичные же каналы?
Если ручками сетевую latency мерять, там получается что-то вроде
rtt min/avg/max/mdev = 0.089/0.160/0.232/0.042 ms
Оно явно не должно влиять.
Если ручками сетевую latency мерять, там получается что-то вроде
rtt min/avg/max/mdev = 0.089/0.160/0.232/0.042 ms
Оно явно не должно влиять.
Хмм… А, тьфу ж protocol C… Как по мне, так в ситуациях с мультинодами надо использовать протокол B. Так что вполне можно получить на базе drbd, если убрать эти ограничения.
Хотя, учитывая что для эффективного использования многонод надо что-то типа RAID6 делать, нагрузка на сру увеличится до чёртиков, и не факт что общее решение вида обычного процессора под это дело будет эффективно.
Потому может и нету FOSS решений — тупо из-за неэффективности.
Хотя, учитывая что для эффективного использования многонод надо что-то типа RAID6 делать, нагрузка на сру увеличится до чёртиков, и не факт что общее решение вида обычного процессора под это дело будет эффективно.
Потому может и нету FOSS решений — тупо из-за неэффективности.
Вру, есть еще извращения вида [agde]?ndb + mdadm поверх.
Но это именно что извращения, так как нода, которая будет держать mdadm будет SPOFом
Но это именно что извращения, так как нода, которая будет держать mdadm будет SPOFом
оффтоп.
ув. amarao, каждый раз читая ваши посты, я думаю о Селектеле, как об отличной компании. Вы делаете хорошее дело и стараетесь делать его хорошо. Да, у вас есть свои косяки, иногда довольно масштабные, но у вас хоть информацию о причинах/следствиях можно получить, в отличие от вашего главного конкурента.
Чтобы кто-то чего-то не подумал, у меня сервера в обеих компаниях, я огреб обе последних аварии, а потому могу сравнивать качество услуг.
ув. amarao, каждый раз читая ваши посты, я думаю о Селектеле, как об отличной компании. Вы делаете хорошее дело и стараетесь делать его хорошо. Да, у вас есть свои косяки, иногда довольно масштабные, но у вас хоть информацию о причинах/следствиях можно получить, в отличие от вашего главного конкурента.
Чтобы кто-то чего-то не подумал, у меня сервера в обеих компаниях, я огреб обе последних аварии, а потому могу сравнивать качество услуг.
Спасибо! LVM как нельзя кстати. Раз уж теперь можно выбирать ядро и параметры загрузки, не могли бы вы кратко прокомментировать, как в общем случае адаптировать ванильный дистрибутив линукса для работы в вашем облаке? Думаю, многим было бы интересно.
У меня почти получилось завести там gentoo с дополнительного lvm-раздела под вашим рекоммендуемым ядром: всё работало, за исключением того, что утилиты lvm отказывались видеть физические тома:
А в dmesg появлялось следующее:
На ваших адаптированных машинах такого не происходит.
У меня почти получилось завести там gentoo с дополнительного lvm-раздела под вашим рекоммендуемым ядром: всё работало, за исключением того, что утилиты lvm отказывались видеть физические тома:
/dev/xvda1: Not in udev db
Device /dev/xvda1 not found (or ignored by filtering).А в dmesg появлялось следующее:
[ 0.382840] blkfront: xvda: barrier: enabled
[ 9.854950] blkfront: write barrier: empty xvda op failed
[ 9.854955] blkfront: xvda: barrier: disabledНа ваших адаптированных машинах такого не происходит.
1) Ядро -xen. Можете взять наше или собрать своё с патчами от SUSE. pv_ops (ванильное) — гарантированные проблемы и наш отказ помогать их решать.
2) правильная настройка консоли (скопируйте из существующей машины /etc/inittab)
3) опция barrier=0 при монтировании FS
4) Для LVM — проверьте фильтры в /etc/lvm/lvm.conf и сделайте pvscan, vgscan и т.д.
5) Никто вас не заставляет использовать именно LVM. Если уж начали развлекаться — можете просто на диске FS положить.
6) Погодите чуток, мы управление загрузкой выкатим, там проще будет.
7) В качестве временной меры — указывайте root на /dev/xvdb1 и т.д. (/boot по-прежнему на /dev/xvda).
Disclamer: Вся ответственность за все глюки и т.д. — на вас.
2) правильная настройка консоли (скопируйте из существующей машины /etc/inittab)
3) опция barrier=0 при монтировании FS
4) Для LVM — проверьте фильтры в /etc/lvm/lvm.conf и сделайте pvscan, vgscan и т.д.
5) Никто вас не заставляет использовать именно LVM. Если уж начали развлекаться — можете просто на диске FS положить.
6) Погодите чуток, мы управление загрузкой выкатим, там проще будет.
7) В качестве временной меры — указывайте root на /dev/xvdb1 и т.д. (/boot по-прежнему на /dev/xvda).
Disclamer: Вся ответственность за все глюки и т.д. — на вас.
Sign up to leave a comment.
Организация разделов на системном диске в облаке Селектел