Comments 14
UFO just landed and posted this here
Управление инцидентами, о котором говорилось в статье — это фиксация и отработка инфраструктурных проблем на production-серверах. Возможно, спустя некоторое время с нашим текущим подходом я буду готов поделиться опытом.
Могу предположить, что ситуации, о которых вы говорите, были связаны с услугой «бесконтактная доставка до двери» и некоторой путаницей на лестничной площадке. Служба заботы о клиентах оперативно решает такие проблемы: связывается с клиентами и дает компенсацию в случае проблем с заказом.
Большим вызовом для нас было наладить коммуникацию в цепочке Клиент-Закупщик-Курьер-КоллЦентр. Мы весной интегрировали сквозную CRM-систему во все служебные приложение, которая сохраняет всю историю взаимодействий по каждому заказу (ранее это было реализовано неудобно через сторонние чаты).
После исполнения заказа клиент выставляет оценки, сводные показатели которых real-time собираются в дэшборды. В них подсвечиваются лучшие курьеры и сборщики и те, кто сталкивается с проблемами.
С этим отчетами постоянно работают лидеры точек, чтобы держать руку на пульсе и улучшать работу команд.
Могу предположить, что ситуации, о которых вы говорите, были связаны с услугой «бесконтактная доставка до двери» и некоторой путаницей на лестничной площадке. Служба заботы о клиентах оперативно решает такие проблемы: связывается с клиентами и дает компенсацию в случае проблем с заказом.
Большим вызовом для нас было наладить коммуникацию в цепочке Клиент-Закупщик-Курьер-КоллЦентр. Мы весной интегрировали сквозную CRM-систему во все служебные приложение, которая сохраняет всю историю взаимодействий по каждому заказу (ранее это было реализовано неудобно через сторонние чаты).
После исполнения заказа клиент выставляет оценки, сводные показатели которых real-time собираются в дэшборды. В них подсвечиваются лучшие курьеры и сборщики и те, кто сталкивается с проблемами.
С этим отчетами постоянно работают лидеры точек, чтобы держать руку на пульсе и улучшать работу команд.
18к заказов это где-то 25 в минуту, разве это высокая производительность? Тем более для команды 200+
почему вы решили что они распределены равномерно по времени?
Оказалось, что «усреднение» графика поступления заказов не всегда работает на практике. Вот пример «горячей поры», когда у нас были забиты слоты на доставку и клиенты «ловили» свободные слоты, мы получали ~1000 заказов за 10 минут в 3 часа ночи.
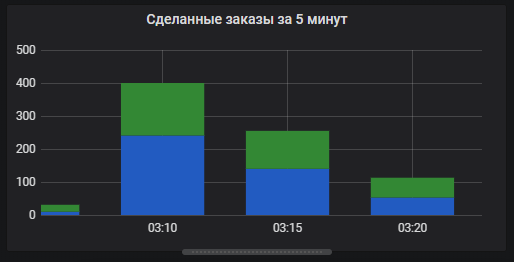
По нагрузке вопрос очень закономерный. Характер нашей работы с множеством магазинов, постоянного обновления цен по всем товаров создает дополнительную внутреннюю нагрузку. По внешней нагрузке мы выросли с 4000rpm до 45000 rpm (в 10+ раз) за короткий промежуток времени — это только backend размещения заказов (сборка обслуживается отдельно). Тогда это был для нас серьезный вызов, сейчас мы работаем с этой нагрузкой в штатном режиме.
Про размер команды:
С нами сотрудничает сейчас больше 10 тысяч курьеров и экспертов по закупкам, но в команде разработки и продукта суммарно всего 60 человек.
Мы планируем вырасти до 200 — задач у нас много.

По нагрузке вопрос очень закономерный. Характер нашей работы с множеством магазинов, постоянного обновления цен по всем товаров создает дополнительную внутреннюю нагрузку. По внешней нагрузке мы выросли с 4000rpm до 45000 rpm (в 10+ раз) за короткий промежуток времени — это только backend размещения заказов (сборка обслуживается отдельно). Тогда это был для нас серьезный вызов, сейчас мы работаем с этой нагрузкой в штатном режиме.
Про размер команды:
С нами сотрудничает сейчас больше 10 тысяч курьеров и экспертов по закупкам, но в команде разработки и продукта суммарно всего 60 человек.
Мы планируем вырасти до 200 — задач у нас много.
выбрали ТОП-запросов, дающих большую часть нагрузки и начали тюнинг
А какие инструменты для этого использовались? Просмотр slow лог? Счетчики в performance_schema (например events_statements_summary_by_digest)? Как именно определили что именно эти запросы загружают БД на столько-то процентов?
Со слейвами не совсем понятно. Вы написали, что из-за ошибки, бэкенды выполняли запросы на запись не только в мастер, но и в слейвы. Затем оба слейва перестали догонять мастера, вы исправили ошибку, отключили старые слейвы, и начали готовить новый. Но ведь все запросы на запись, которые ушли в эти слейвы на мастере в итоге не появились. Получается эти данные были утеряны?
Кстати можно еще более прозрачно отделить чтение от записи c помощью proxysql. А также настраивать хитрый роутинг запросов. Для бэкенда это будет выглядеть как обычная база, одна точка входа.
Ответил на первую часть вопроса про инструменты ниже, промахнулся комментарием ;)
Для анализа все способы выше применимы, но удобнее использовать утилиту из Percona Toolkit
Как использовать хорошо в доках показано. Приведу пример части вывода этой утилиты:
Удобно выводит Response time — общее время и процент от общего, даже утруждать себя подсчетами не нужно. В отчете по каждому запросу есть другая подробная информация, рекомендую.
pt-query-digest — Analyze MySQL queries from logs, processlist, and tcpdump.Удобно использовать, если есть возможность собирать и получить доступ к slow логам.
Как использовать хорошо в доках показано. Приведу пример части вывода этой утилиты:
# Profile
# Rank Query ID Response time Calls R/Call V/M I
# ==== =========================== ================ ======= ====== ===== =
# 1 0x3C0A5A053D9DA60145DF32... 22287.3511 50.1% 18708 1.1913 0.01 SELECT ***
# 2 0xFFFCA4D67EA0A788813031... 3255.4295 7.3% 38424 0.0847 0.03 COMMIT
# 3 0x3D546FC71D1245D04E4215... 2142.2965 4.8% 16518 0.1297 0.01 SELECT ***
# 4 0xEFBDDA4050BEB86ACA5DEF... 1403.1128 3.2% 15013 0.0935 0.01 SELECT ***
Удобно выводит Response time — общее время и процент от общего, даже утруждать себя подсчетами не нужно. В отчете по каждому запросу есть другая подробная информация, рекомендую.
Хотелось бы почитать продолжение — почему добавление железа ухудшило ситуацию… Только очень прошу побольше тех. деталей, а не просто бла бла.
Sign up to leave a comment.
Как мы пережили резкий рост нагрузки x10 на удаленке и какие выводы сделали