Comments 370
Забавно, когда Haskell называют "более современным", чем Python или Java, хотя Haskell и Python появились одновременно, а Java — на 5 лет позже них.
Тоже об этом подумал. Тот момент, когда автору ну очень хочется написать статью, а разбираться в матчасти лень.
То есть, Haskell более соответствует уровню и требованиям настоящего времени? Мне кажется что доказать это в такой постановке будет еще сложнее.
А что не так? Рыбу сайта магазина я за пару часов сделал, сваггер есть, постгрес драйвер есть, веб-фреймворк вообще один из лучших (всяко лучше спринга, asp.net mvc core, express и прочих). Всё для типовой разработки имеется.
>постгрес драйвер есть
Ну, мне как-то нужно было написать быстро-быстро скрипт, который бы что-то доставал из базы MS SQL. Взял первое что подвернулось, python. Взял первый драйвер для MS SQL. Быстро-быстро выяснил, что varchar длиннее 100 символов обрезаются до 100, плюнул, написал на груви. Ну то есть, меня python в этом случае не устраивал, по моим меркам API для работы с СУБД не работал. Но формально — драйвер MS SQL тоже есть. То есть, в практике есть много других критериев, которым продукт может не удовлетворять.
Уверяю, что Persistent не занимается молчаливой модификацией данных, это вообще не в стиле ФП языков.
Но для тырпрайз разработки в скале конечно выбор побольше, там в крайнем случае можно сделать фоллбек на джава экосистему, в которой как известно есть фактически всё.
Да я и не сомневался. Я немножечко про другое — чем «тырпрайз разработка» в общем отличается от академических проектов, или проектов для себя? Тем что завтра может заявиться к вам условный безопасник (или заказчик), и сказать: «Делайте, что хотите, но чтобы через полчаса в лесу было светло, сухо и медведь!». Ну то есть, потребности тырпрайза широки и многообразны, вероятно сильно шире, чем у типового проекта ради фана. И вопрос пригодности тут стоит немного в другой плоскости. В том числе — в плоскости наличия на рынке выбора хороших разработчиков.
Я занимаюсь типичной тырпрайз разработкой, но у нас никакой безопасник или заказчик не придет и не скажет. Наверное, просто потому что можно работать вне гос/банковского сектора в продуктовой компании. И конечно же мы делаем проект не ради фана, а классический B2B продукт.
Никто не предлагает условный хаскелль как серебрянную пулю, но в некоторых достаточно простых допущениях он хорош. Для бодишопа где у начальника подчиненные — ничего не могущие бездари, а он у них — идиот, такой подход наверное не подойдет, ибо действительно определенная нишевость присутствует. Но компании в которых делается более взвешенное решение получается более конкурентноспособный продукт. Один из моих коллег кстати на следующей неделе выходит на фулл хаскель проект десятым разработчиком.
Мы вот о чем: habr.com/ru/company/ruvds/blog/515684/?reply_to=21987504#comment_21986124 предлагается критерий современности как пригодность для удовлетворения сегодняшних потребностей. Я сразу сказал, что доказать такое (как пожалуй и опровергнуть) будет довольно сложно. В том числе потому, что потребности разные. Как вообще померять это? Понятно что популярность и сложность тут играют роль — но ни на том, ни на другом все не заканчивается.
Ну в хаскелле есть алгебраические типы данных, причем даже в их расширенной версии GADT, тайпклассы, семейства типов, типы высших порядков, rank-N типы (они конечно редко когда нужны, но иногда все же полезны), и так далее
Как по мне, это всё вещи которые будут ещё лет 10+ пролезать в мейнстрим. В расте вон пока только АДТ и тайпклассы завезли, типы высших порядков будут в ограниченном виде в конце этого года, остальное пока даже не планируется.
Так что да, хаскель соверменнее.
Ну база у меня выглядит так:
connStr :: ConnectionString
connStr = "host=localhost dbname=operdenstorage user=pguser password=mycoolpass port=5432"
getPersonsInner :: (MonadIO m) => SqlPersist m [User]
getPersonsInner = do
people <- select $
from $ \person -> do
return person
pure $ fmap entityVal people
runInDb :: IsSqlBackend backend => ReaderT backend (NoLoggingT (ResourceT IO)) a -> IO a
runInDb f = runStderrLoggingT $ withPostgresqlPool connStr 10 $ \pool -> liftIO $ runSqlPersistMPool f pool
getPersons :: IO [User]
getPersons = runInDb getPersonsInnerHTTP хендлеры выглядят как большинство в других языках:
isaac :: User
isaac = User "Isaac Newton" 372 "isaac@newton.co.uk" (fromGregorian 1683 3 1)
albert :: User
albert = User "Albert Einstein" 136 "ae@mc2.org" (fromGregorian 1905 12 1)
users :: Handler [User]
users = liftIO getPersonsРегистрация в местном фреймворке тоже очевидная:
type UserAPI = "users" :> Get '[JSON] [User]
:<|> "albert" :> Get '[JSON] User
:<|> "isaac" :> Get '[JSON] User
userAPI :: Proxy API
userAPI = Proxy
type API = SwaggerSchemaUI "swagger-ui" "swagger.json"
:<|> UserAPI
server :: Server API
server = swaggerSchemaUIServer swaggerDoc :<|> users :<|> pure albert :<|> pure isaac
app :: Application
app = serve userAPI server
swaggerDoc :: Swagger
swaggerDoc = toSwagger (Proxy :: Proxy UserAPI)
& info.title .~ "Operden API"
& info.version .~ "1.0.0"
& info.description ?~ "This is an API that perform some operen actions"
main :: IO ()
main = run 8081 appВ хаскелле любят кастомные операторы для всяких таких вещей, сперва выглядит диковато, но на самом деле доволньо удобно. В частности оператор <|> это оператор альтернативы, то есть позволяет из отдельных хендлеров собирать приложение которое обрабатывает все эти роуты.
Правда, половину вашего кода все равно не понимаю, но теперь хотя бы понятно, что гуглить =)
Если что, "гуглить" лучше на Hoogle, он поддерживает поиск по именам (в том числе операторным) и по тИповым сигнатурам.
То есть, Haskell более соответствует уровню и требованиям настоящего времени?Этого мы не утверждали, мы лишь заметили, что современность определяется не так, что бы можно было опровергнуть ее таким аргументом
Haskell и Python появились одновременно, а Java — на 5 лет позже
Он появился раньше физически, но по факту это академический язык был на старте, а Java/Python — нет. А то что академия на 15-20 лет опережает мейнстрим вроде все и так знают.
Так что фактически утверждение верно.
"А то что академия на 15-20 лет опережает мейнстрим вроде все и так знают" — ну, это уж как повезёт. Из малораспространённых функциональных языков в мейнстрим действительно перетаскивают кое-что, но вот из Пролога, например (который я когда-то даже знал, но уже все забыл, ибо не пригождалось) — нет, он уникальный в своём роде. Ну, точнее, не то, чтобы прямо уникальный, есть ещё Mercury, например, но все это не мейнстрим.
Ну пролог используется, но не для языков общего назначения, а для, например, тайпчекеров. Потому что логику x :- subtype y очень удобно в таком вот виде записывать.
А языком общего назначения емнип пролог если и позиционировался, то недолго. Его удел вроде всегда были всякие экспертные системы и только.
Я к тому, что не все концепции из академических языков вообще попадают в мейнстрим. Бывает и так, что спустя не то что 15-20 лет, а и все 50 эти языки (и концепции) продолжают применяться очень нишево и в гомеопатических дозах. Поэтому я как-то не уверен, есть ли смысл давать академическим языкам заведомую фору в плане "современности".
Агащаз. То есть печатать, обновлять данные в базах, и прочее и прочее наша функциональная программа не будет? Реальная суть ФП скорее в изоляции функциональных эффектов. Уничтожением это называть просто неграмотно.
Учитывая это, можно сказать, что многие разработчики видят в Scala язык, который поможет им перейти от объектно-ориентированного к функциональному программированию.
Вот делать разработчикам на работе нечего, как только думать «а давай-ка я щас перейду от объектно-ориентированного к функциональному программированию». Разработчики видят в scala язык, который удобно позволяет пользоваться например средствами Spark, и работать с большими данными (примерно в том же стиле, как с данными обычными). Ну или работать с Akka, допустим. Или даже просто взять ScalaCheck, и заняться property based тестированием. Разработчики видят в ФП инструмент, позволяющий им более удобно решать какие-то свои практические задачи.
Скажем прямо, в scala и тем более Java — не самые сильные системы типов
В чем их слабость и в сравнении с чем?
>>> max([])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: max() arg is an empty sequenceПайтон дает взамен исключение, а исключения в пайтоне часто используются, как аналог Option (например функция-итератор возвращает или следующий элемент, или исключение, если элементы кончились).
Вероятно, с точки зрения сильно типизированных языков, такие приёмы выглядят костылями :)
Суть функционального программирования — это уничтожение побочных эффектов
Агащаз. То есть печатать, обновлять данные в базах, и прочее и прочее наша функциональная программа не будет? Реальная суть ФП скорее в изоляции функциональных эффектов. Уничтожением это называть просто неграмотно.
Суть в устранении побочных эффектов, а не любых. Достигается это выносом эффекта в результирующий тип функции, после чего он перестает быть побочным. Так что писать в БД без побочных эффектов — да, это то что делает ФП.
В общем, против вашей формулировки я не возражаю, она мне кажется просто взглядом с другой стороны, а вот авторская без пояснений — все равно фиговая.
Ничуть. Это именно изоляция. Сам побочный эффект никуда не пропадает. И не перестаёт таковым быть. Сохранение значения в БД, строго говоря, не является побочным эффектом. Это примерно то же, что присвоить значение переменной, просто она не принадлежит вашей программе, а существует вовне (грубо). И вот за это обращение вовне вы платите определённую цену: целевая сущность может отсутствовать, может иметь иной тип, может неожиданно пропасть… и вы никак не контролируете это на стороне вызывающего кода. Неопределённость взлетает до небес, но поведение программы не может быть недетерминированным. Приходится либо умножать сущности и вместо простого сохранения/получения информации получать хитрую структуру данных с кодом ошибки и анализировать его, либо бросать/ловить исключения, либо заворачивать всё в монаду и притворяться, что она и есть наша реальность (потому что как только вы попытаетесь её покинуть, побочные эффекты "сыграют" и разнесут всю чистоту на кирпичики).
Побочный эффект — это эффект, который не видно в результате функции. Запись в базу или вывод в консоль — не побочный эффект если тип функции которая это делает IO a. Ну просто потому что проблема побочных эффектов — отсутствие ссылочной прозрачности, которой очевидно не существует для значений типа IO.
Существует ли оно вовне, в программе или ещё где совершенно неважно. Я уже писал, ФП — это про ссылочную прозрачность, а побочные эффекты их рушат. Поэтому про то как сделать прозрачные эффекты и говорят так много. Free/Freer/MTL/eff/fused-effects/polysemy/younameit…
В общем, посмотрите определеие, что такое побочный эффект. У людей заблуждение, что любое вычисление которое требует взаимодействие с внешним миром нельзя сделать чистым, поэтому ФП программы ничего полезного сделать не могут, ведь даже если она что-то посчитает, то ответ вывести не сможет!
Только оказывается, что это ложная дихотомия, и вывод в консоль или запись в БД точно так же может быть чистой и без побочных эффектов.
А как вообще будет выглядеть 2 монадических поведения?
Из самого очевидного (я не настоящий Хаскелист, просто действительно не очень понимаю насколько Хаскелл даже для небольших утилит подходит): логирование (чтобы можно было разобраться что случилось) и maybe (чтобы не писать всю логику «не получилось»).
Ничуть. Это именно изоляция. Сам побочный эффект никуда не пропадает. И не перестаёт таковым быть. Сохранение значения в БД, строго говоря, не является побочным эффектом. Это примерно то же, что присвоить значение переменной, просто она не принадлежит вашей программе, а существует вовне (грубо).
Очень интересно, но не понял. А зачем тогда вообще нужны чистые функции? Либо я могу распараллелить foreach на ядра/хосты/кластеры (как если бы всё оставалось чисто), либо после первого же SQL UPDATE сказка кончится и «непобочные эффекты» превратят консистентную до того БД в тыкву?
Или чистые функции нужны для чего-то иного?
Чистые функции это не "функции которые ничего не делают", а скорее "функции, все результаты которых видны в сигнтуре". запись лога это часть результата, изменение БД это часть результата. Поэтому когда в какой-нибудь джаве метод записи в базу возвращает просто int — это вранье, которое совсем не показывает, что происходит на самом деле.
Мне все же больше нравится формулировка, что мы их изолируем (в случае хаскеля при помощи IO), чтобы было четкое разделение на чистые функции, и функции с эффектом. И тогда уже вопросы типа этого будут иметь четкий ответ — чистые функции можно переупорядочивать, параллелить и т.п. с целью оптимизации, а вот эффекты в общем случае переупорядочивать нельзя, потому что в базе сначала INSERT, а уж потом UPDATE или DELETE. И это должно быть видно в коде, возможно в сигнатурах и т.п.
def something():
return 4
Впрочем там не только это неверно написано.
Про то что мол если заменить явные циклы на неявные ( через map reduce ) они почему-то должны выполнится быстрее ( магия не иначе ), про то что если модифицировать входной параметр а не глобальную переменную функция станет уже без побочных эффектов ( по идее модификация входных параметров тоже побочный эффект ).
Всё ещё непонятно как добавление self, как и любого другого количества скрытых аргументов, показывает что приветствуется функциональный стиль.
Явное лучше неявного. Разве не это заявляется главным плюсом ФП? :)
Ну особой неявности тут нет, все понимают в ООП что в foo.Bar() функция имеет доступ к foo. Но неявные (или явные) параметры ничего не говорят о ФПшности, потому ФПшность она про результат функции, а не то что она принимает.
А в остальном, сколько не пытаются преподнести фп как спасение от всех бед, на практике, как я вижу, используется в очень узких кругах… и в очень специфических задачах.
Я лично использую только для простенькой фильтрации или трансформации небольших объектов когда знаю что их количество ограничено числом N, и это число меня устраивает.
У вас никогда не было задержек в 15-30 секунд когда gc останавливает все что бы очистить память? Задача задаче рознь. Одно дело в воркере что то делать, с этим еще можно жить. А вот в веб сервере, когда это напрочь убивает весь перформанс, уже другое.
Самое простое например у нас, это работа с календарем. 365 дней в году.
Разная метадата на каждый день, потом накидываем всякие бизнес рулы на каждый день в отдельности, вот уже память и скачет.
Нет, конечно по возможности делаем прекалькулейшен и храним где-то, но по большому счету очень много операций синхронных, когда ответ нужно дать asap, бывает один такой вот тяжелый ендпоинт не дает спать по ночам, когда алерты приходят =))
У вас никогда не было задержек в 15-30 секунд когда gc останавливает все что бы очистить память? Задача задаче рознь. Одно дело в воркере что то делать, с этим еще можно жить. А вот в веб сервере, когда это напрочь убивает весь перформанс, уже другое.
Настройте гц на низкие задержки, делов-то. В современных жабовских ГЦ например терабайт мусора (да, там по несколько терабайт памяти ставят в машины) очищает за считанные микросекунды.
А у большинства людей с кучей <= 4 гигов проблем вообще никаких.
Ну у меня не жаба, а дотнет, но там тоже проблемы редко бывают. Пару раз только кастомизировал гц опциями, всегда этого хватало.
Можно конечно расти вертикально пока не упрешься в потолок или бюджет… и все же, просто игнорировать GC и другие накладные расходы в статьях про ФП это как-то не правильно.
ФП к эффективности ГЦ слабо относится, одно — язык, а другое — рантайм. Если же сравнивать у существующих языков, то у Haskell/Scala достаточно эффективный ГЦ, гигабайты мусора в секунду по крайней мере они собирают без каких-либо задержек со стороны приложения.
На хабре была статья, где сравнивалась производительность функционального и императивного кода на Scala и Rust.
И функциональный код на Scala работает намного медленнее, потому что требует создания и очистки многих объектов.
У меня есть пример когда человек спрашивал в телеграме почему его программа на хаскелле работает быстрее чем на расте. Оказалось, что он всё завернул в боксы и естественно аллокатор раста помер на этом, а гц пережевал гигабайты мусора без каких-либо проблем.
Нашел кстати пост, комменты выше есть если хочется восстановить контекст: https://t.me/rustlang_ru/243901
Пул объектов пробовали использовать?
Ну и я по времени не укладывался.
ПС
Отдельно хочу заметить, что даже не представляю как в этом случае профилировать программу на Haskell.
Что бы мы могли в любой момент заменить
value = f(arg)
array = [ value, value ]на
array = [ f(arg), f(arg) ]и наоборот.
При этом это только пример, а реально это используется для того, что бы безболезненно развивать существующие системы и, как минимум, адекватно тестировать написанный код.
Чтобы не сделать space leak достаточно аллокации тоже вынести на уровень типчиков, AllocMonad или что-нибудь в таком духе. Но не думаю, что с ней прям будет сильно удобно жить.
Он быстрее, так как тут не приходится перебирать множество элементов массива
Объясните, пожалуйста, где здесь ускорение? Чтобы получить массив квадратов чисел, нужно в исходном массиве их все перебрать. Или нет?
Речь о том, что каждый элемент массива посещается один раз. Потому что итераторы фьюзятся, и вместо трех циклов над требя коллекциями получится один цикл которые делает все три действия (фильтр, отображение, свертку).
Но написано через одно место, да.
Это особенности (правильной) реализации. Если тупо взять какую попало реализацию где-нибудь в js, то от замены цикла на map/reduce/filter как раз наоборот производительность может пострадать, и очень сильно.
Это особенность конкретно итераторов, а в жс эти функции реализованы на массивах. Если же взять жсовские итераторы то получите все те же плюсы.

Статья в целом не очень качественная.
Сия статья опоздала года на 3. Функциональные языки опят вышли из моды
Например, можно было бы упомянуть, что Scala это Java + типизация + ФП + Иммутабельность + Акторы (в т.ч. распределенные между хостами) + Spark + компиляция в JS + Scala Native
ФП несомненно полезный стиль программирования, но во встраиваемых системах, с ограниченными ресурсами ОЗУ и частотой ЦПУ приходится им часто жертвовать.
Потому, что передавая кучу входных аргументов функции, потребуется дополнительное время ЦПУ и свободное место в стеке. А их, зачастую нехватает. Вот и приходится выкручиваться используя глобальные переменные или передавая функции один указатель на структуру, как входной аргумент.
Не понял почему это обратный пример. В обоих случаях приводится пример, что абстракции иногда не позволяют писать эффективный код. Но иногда наоборот помогают. Так что тут в каждом случае нужно разбираться отдельно.
"неизменяемыми переменными" — оксюморон, отличное начало простого объяснения концепции.
В англоязычной среде immutable variable видимо тоже дурачки пишут.
Что поделать, смысл слов со временем меняется. "Незименяемая привязка к имени" мб и более корректна, но звучит ужасно. Иначе не было бы в языке слов вроде "сухая вода".
Если принять определение переменной как "именованная область памяти", то нкмзменяемая переменная — это именованная нкмзменяемая область памяти. Вроде норм.
Слово "переменная" означает, что она может принимать разные значения. А "неизменяемая" означает, что после принятия значения оно посередине вычислений поменяться уже не может.
Вспомните математику. Рассмотрим функцию f(x) = 2x+1. Можно вычислить f(2), а можно вычислить f(3). В одном случае икс будет равно двум, а во втором — трём, поэтому икс — переменная. Но неизменяемая, изменяемых переменных в математике нету.
Как вы его переведёте?
Вот в процессорах мы уперлись в максимальную тактовую частоту 4ггц. Усовершенствуем в них конвеер, кеш, системную шину, но в целом частота все та же. Зато пределов многоядерности еще не видно.
А с другой стороны память — ее объемы и скорость доступа неуклонно растут и пока предела тоже не видно.
Отсюда выгоднее для всей индустрии писать слабосвязанные куски кода, пусть даже ценой большего расхода памяти — потому что они лучше параллелятся.
И кстати, фанатов ФП (активно засирающих комменты) всего-то 3-4 человека. Хотя да, комментов они наплодили бесконечное множество. И вот такое море флуда нам выставляют как доказательство того, что «разработчики влюбляются в ФП». То есть тупо гонят агрессивную рекламу, максимально массово и полностью безапелляционно. Выхватывают какую-то частность и уводят куда-то в дебри (теория категорий, ага). Но для непосвящённого читателя всё выглядит оживлённой дискуссией. Только нормальным людям никогда в голову не придёт спорить с уводящими в теории категорий про то, что на самом-то деле от циклов никуда не денешься. Поэтому массовый вброс от всего 3-4-х человек кажется «аргументом» в пользу ФП.
Ну а основной аргумент против — никто ещё не сумел с помощью ФП решить ни одной задачи, которую бы до них не решили императивно.
Поэтому фанаты ФП — это фанаты стиля. Я понимаю, скажем, математиков — они привыкли к математическому виду своих рассуждений, и тут хаскель с его очень похожим подходом, ну и математиков «попёрло». А все остальные — либо не понимают и просто следуют за авторитетом математики, либо… Ну в общем в обоих случаях — не понимают.
Даже больше — агрессивное отношение фанатов ФП ко всем «не фанатам» губительно для ФП. Но фанатам этого не понять.
фанаты ФП — это фанаты стиля.
Ну не совсем, элементы ФП (неизменяемые структуры, функции без побочных эффектов) очень помогают для многопоточного программирования (например, в Java). Поэтому, как минимум, элементы ФП в ООП/императивном языке — полезны.
элементы ФП в ООП/императивном языке — полезны.
Обсуждалось. Это не «элементы ФП». Это давно известные способы написания процедурных программ.
Если есть желание, вы можете писать без побочных эффектов, если нет желания — можете с побочными. Это называется «свобода». В ФП же свободы нет. Только чистые функции. То же самое касается всего остального. Вплоть до передачи функции в качестве параметра — это тоже ФП заимствовал из императива.
Фанаты ФП вещают из башни, с которой сами не видят мир. Они видят лишь своё, видят его удобство, но при этом понятия не имеют, откуда растут корни этого удобства. Потому что бросились сразу от математики зубрить хаскель.
@mayorovp
Вы конечно же считаете себя умным, но суть возражения просто не поняли.
Свобода ведёт к хаосу, хаос ведёт к багам, притом количество багов растёт в лучшем случае как квадрат размера кода, поскольку баги "прячутся" в паразитных связях между частями программы.
Чем сложнее программы, тем важнее наводить в них порядок. Да, это всегда происходит ценой ограничения свободы программиста. Статическая типизация, обобщенный код, LSP, ФП, завтипы — всё это инструменты, разменивающие свободу программиста на уменьшение количества тех самых паразитных связей.
Свобода ведёт к хаосу, хаос ведёт к багам
О да, достаточно продекларировать некий набор слов, и доказательство крутости ФП в кармане!
Свобода расширяет возможности. Несвобода сужает. Вроде бы очевидно, но нет, адепты «несвободы» увидели хаос…
Ладно, давайте более конкретно. В JavaScript нет возможности ограничивать себя типами данных. То есть в JavaScript меньше возможностей. В типизированных языках возможность ограничивать себя типами данных есть. То есть в типизированных языках больше возможностей. К типизированным языкам относятся как множество императивных, так и множество функциональных. То есть фанатам ФП должно быть стыдно за критику в адрес наличия дополнительных возможностей, которые присутствуют и в их любимом подходе к программированию.
Далее сравниваем. ФП запрещает нам целый ряд конструкций. Здесь уместно вспомнить JavaScript, который точно так же запрещает нам целый ряд конструкций. И на этом фоне есть императивные языки, поддерживающие то, что не хочет JS и то, что не хочет ФП. То есть возможностей в императиве больше, чем в ФП и в JS. Но да, я понимаю, признавать своё поражение неприятно…
Хотя… ещё раз ладно. Объясню ещё нагляднее (а то-ж не все понимают). Вы что-то там про зависимые типы говорили. Было? Так вот, это тоже есть расширение возможностей. Хочет кто-то их использовать — использует. Не хочет — пишет на подможестве языка а-ля чистый хаскель. Теперь сравниваем с императивом — там тоже если кто-то хочет — пользует чистые функции и всё прочее, а если не хочет — не пользует. И вот приходит фанат ФП и заявляет — свобода ведёт к хаосу! Это таким образом он запрещает нам (сторонникам императива) свободу в выборе способа написания наших программ. Но сразу после этого тот же самый человек заявляет — завтипы наше всё! И получается, что в одной ситуации он против, а в другой, полностью аналогичной первой — он «за».
Павел (скорее всего вас так зовут), вы пристрастны. Хотя вроде бы и не сторонник душить за альтернативное мнение (то есть сами ищете истину). Но ваша пристрастность душит ваши собственные позывы.
vedenin1980
Вы почти всё правильно поняли. Различие в спорах — только стилистическое. Но ваша картинка, к сожалению, относится именно к фанатам ФП. Точнее — к худшей и небольшой их части, которая владеет рядом умов на этой площадке.
Здесь всего-то несколько активных фанатов, толкающих идею исключительности ФП в массы. Но у них есть то ли клонированные юзеры, то ли группа поддержки из студентов-одногруппников. Гляньте на мою карму — почти все минусы от них за участие в подобных обсуждениях. За каждое обсуждение 10-15 минусов. Но вроде у засранцев более нет клонов (уже не портят карму). И вот эта ничтожная группка и создала образ «крепости на том берегу», прямо как на вашей картинке.
Надеюсь, читающие это обсуждение не повторят ошибок тех фанатов ФП, которые следуют жестокому правилу «давить любые возражения», и всё ведь исключительно ради поддержания ЧСВ этой ничтожной группки зазнавшихся и очень обидчивых «молодых лидеров».
Если у вас статическая типизация — это расширение возможностей по ограничению себя типами данных, то и ФП — это такое же расширение возможностей по ограничению себя типами побочных эффектов.
то и ФП — это такое же расширение возможностей по ограничению себя типами побочных эффектов.
Вы опять не поняли сказанного. Уже настораживает.
Объясняю. В ФП нет других вариантов, кроме того, что требует ФП. А в императиве есть. В ФП один подход, а в императиве минимум два. Внимание, детский вопрос — где больше? Один или два? Вы выше заявили, что один больше двух. Поэтому срочно просыпайтесь и не пытайтесь отвечать как всегда — первой пришедшей в голову мыслью. Она у вас всегда ошибочная. Доказано хотя бы данной перепиской.
Я "проснусь" только после того, как увижу код (на любом из известных мне языков), аналог которому ну вот никак нельзя написать в рамках ФП.
Удар ниже пояса почти :) Ведь вроде как машина Тьюринга и Лямбда-исчисление эквивалентны. То есть "будить" вас нужно, залезая в конкретные детали реализации и "разбудить" без большой практике в ФП не получится ))
Хэшмапу смогли реализовать только когда в хаскель линейные типы затащили. Или какую-нибудь инплейс быструю сортировку.
По сути, все что в ST это такой алгоритм.
Что там от этого ФП остается. По сути эмбед императивщины в монаду же.
А то так остается заключить, что кроме ФП ничего и не существует, просто весь код в императивных языках неявно заключен IO a, который не пишется по тем же причинам, почему никто не пишет T | bottom для каждой нетотальной функции.
Ну лично мне ближе идея к тому, что ФП — это когда код не использует лишних возможностей. То есть функция возведения в квадрат в стд не имеет вид Int -> IO Int.
«А почему этому мальчику можно добавлять монады в код, а мне нельзя?»
Потому что писать с монадами чуть больнее. В ООП если полениться, то можешь сломать архитектуру/абстракцию, в Haskell нужно быть активным придурком. Чтобы сломать, прикладывать усилия нужно.
add :: IO Int -> IO Int -> IO Int
add x y = do
a <- x
b <- y
return (a + b)
add2 :: Int -> Int -> Int
add2 x y = x + yНапример, если вы написали функцию, которая отбивает строку слева пробелами, а там нужно IO, то что-то не так.
А если я решу, что этой функции нужен файловый кэш, чтобы не тратить уйму вычислительных ресурсов на решение этой сложной вычислительной задачи, и хочу его прозрачно для потребителей добавить. Я так понимаю, что в рамках типичных функциональных языков эта задача нерешаема?
Что за формулировка вопроса! Утрируя можно перефразировать:
— IO не нужно при простой работе со строками.
— Я хочу работу со строками и файлами.
— Для работы с файловой системой нужно IO.
— Хочу файловую систему без IO монады. Я так понимаю, что в рамках типичных функциональных языков эта задача нерешаема?
Насколько я знаю, предполагается такой подход для кеширования: делаете свою монаду, которая позволяет не все действия из IO, а только чтение-запись в конкретный кэш; используете её в функциях, которые связаны с кэшем; профит. Да, если до этого был вызов такой же функции, но без кэша, то его надо будет поправить. Однако зато получаете гарантии, что ни в какие другие файлы/сеть/etc эти функции не лазят — только в кэш.
А если я решу, что этой функции нужен файловый кэш, чтобы не тратить уйму вычислительных ресурсов на решение этой сложной вычислительной задачи, и хочу его прозрачно для потребителей добавить. Я так понимаю, что в рамках типичных функциональных языков эта задача нерешаема?
"Решаема" хаками которые позволяют выполнять ссылочно непрозрачный код, но да, если вам вдруг захотелось файловый кэш использовать, это должно быть видно из сигнатуры. Но я бы не хотел использовать код, написанный с таким подходом.
Я кажется рассказывал историю, как у меня в сишарпе в одной библиотеке безобидная функция для перевода времени из одного часового пояса лезла в БД через статический глобальный коннекшн потому что там хранились информации по таймзонам и оффсетам. А в сигнатуре ничего, безобидный DateTime -> DateTime.
То что добавление кэша ломающее изменение — хорошо и правильно.
Более правильным решением написать функцию относительно любого эффекта который умеет то что нужно. foo :: (Monad m) => m (). И дальше если вам эффект не нужен, то вы просто передаёте пустой эффект Id, а если нужен, то передаете что нужно: кэш или еще там что-то.
foo :: (Monad m) => m ()Только(если я правильно понимаю о чём речь), в такой функции никаким конкретным эффектом воспользоваться не получится.
Ну это буквально "я работаю с любой монадой". То есть функция будет пользоваться тем эффектом, который передан аргументом. Например, у меня есть вот такая хелпер-функция в идрисе:
whileM' : (Monad m, Monad f, Alternative f) => (a -> Bool) -> m a -> m (f a)
whileM' p f = go
where go = do
x <- f
if p x
then do
xs <- go
pure (pure x <|> xs)
else pure empty
whileM : Monad m => (a -> Bool) -> m a -> m (List a)
whileM = whileM'Который работает для любой монады. Можно проверить для m = Maybe, m = IO, m = Async, ...
Пример использования:
readToBlank : IO (List String)
readToBlank = whileM (/= "") getLineТо есть если бы в языке был запрет на глобальные переменные, то это решило бы все проблемы? Или чтото еще нужно?
Мне не нужен запрет на глобальные переменные, более обще запретить эффекты. Я знаю, что функция вида
Int -> Int
- не мутирует стейт
- не делает сетевых запросов
- не ходит в базу
- не пишетт логов
- не кэшируется
- ...
И я хочу видеть эти опции из сигнатуры.
Допишем к функции суффикс Pure?
Плюс, если действует запрет на глобальные переменные, то что из вышеперечисленного такая функция сможет сделать?
Допишем к функции суффикс Pure?
Я не верю в соглашения, только в компилятор
Плюс, если действует запрет на глобальные переменные, то что из вышеперечисленного такая функция сможет сделать?
Вызвать сишный printf?
Хм, я подозреваю, что сишный printf тоже использует глобальные переменные.
С одной стороны можно точно также запретить в языке неявный printf. С другой стороны, иногда конечно всетаки хочется без лишнего геморроя вывести чтото в лог.
С другой стороны, иногда конечно всетаки хочется без лишнего геморроя вывести чтото в лог.
… или отправить по сети, или считать файл, или многое другое. Запись эффектов явным образом в сигнатуре функции делается как раз для того, чтобы вызывающий код знал если что-то такое может произойти.
С другой стороны, иногда конечно всетаки хочется без лишнего геморроя вывести чтото в лог.
А питонистам хочется иногда без лишнего геморроя прицепить к объекту какие-нибудь динамические данные или иногда вместо числа возвращать например строку. А в какой-нибудь джаве гадкие типы им мешают и не дают этого сделать.
Точно так же как типы джавы не разрешают просто так прицепить что-то к объекту, типы хаскелля не разрешают просто так "вывести что-нибудь в лог". Я пользуюсь джавой потому что она не разрешает цеплять к объектам мусор, и пользуюсь хаскелем потому что я вижу что функция не делает под шумок какой-нибудь дичи.
// void врёт
А можно чуть подробнее? Почему врёт? Кому врёт? При компиляции C-кода void функции с return или неявным return будет однозначная ассемблерная конструкция RET без какого-либо возвращаемого значения в стэке, регистре, или где там по очередной конвенции о вызове. (бывают исключения в этих конвенциях). То есть реально ничего не возвращает.
На предыдущем комменте про это удержался, а теперь нет )
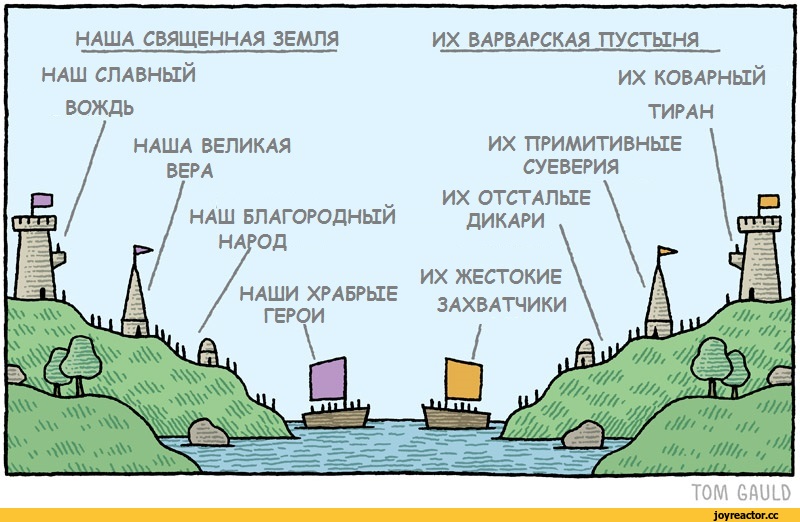
На мой взгляд ФП это просто принцип — «Если вы используете функции без побочных эффектов и неизменяемые структуры данных — вы имеете меньше проблем с многопоточностью и поиском ошибок». Разумеется о нем догадывались до появления самого термина и разумеется на этом принципе можно построить весь язык (что не так гибко и удобно, зато защищает от дурака), либо просто небольшие его части языка или проекта.
То же самое ООП это просто принцип — давайте разделять классы и данные на небольшие общие изолированные части и давать другим частям взаимодействовать только с открытым api, либо переиспользовать код, но строго определенным способом.
Вы, конечно же, можете писать одни и те же алгоритмы каждый раз сами, но я предпочитаю использовать библиотечные функции. Даже если я не знаю их реализации (но это редко, потому что я любопытный).
newlist = []
def append_to_list2(x, some_list): some_list.append(x)
append_to_list2(1,newlist)Я может чего-то не понимаю, но разве тут append_to_list2 — чистая функция?
По идее, она была бы чистой, если мы возвращали новый массив с значением 1, тогда ее всегда можно было бы заменить на результат вычисления. А тут в полный рост встает вопрос многопоточности и прочего (можно легко получить ошибки или неверные значения если тот же код выполняется во множестве потоков).
То есть, получается автор статьи сам не понимает, что такое функциональное программирование и чистые функции?
Если натянуть сову на глобус и считать что append_to_list это функция в монаде то получится чистая.
Но вообще я бы её такой не назвал.
А теперь — ещё один вариант этого кода:
from functools import reduce integers = [1,2,3,4,5,6] odd_ints = filter(lambda n: n % 2 == 1, integers) squared_odds = map(lambda n: n * n, odd_ints) total = reduce(lambda acc, n: acc + n, squared_odds)
Это — полностью функциональный код. Он короче.
integers = [1,2,3,4,5,6]
total = sum(i*i for i in integers if i%2)Так еще короче. Чем в данном случае такой код хуже?
>если количество итераций — расчетное
Это логичный вопрос, но такой цикл не заменяют map-ом.
Ну он возможно будет несколько хуже расширяться (хотя честно говоря, и оригинальный авторский код в этом смысле так себе). map и filter это средства композиции решения из частей, а эта композиция имеет свойство меняться, в том числе при изменении постановки задачи.
То есть, если у вас есть набор функций, f1, f2, f3, вы можете скомпоновать из них обработку как integers.map(f1).map(f2).map(f3), а можете построить композицию функций f123, и даже доказать, что integers.map(f123) будет эквивалентно. А в вашем варианте эти части где? i*i, i%2? Для однострочника норм, а в перспективе может оказаться не очень.
comprehension это и есть короткая запись для filter/map, но если добавить чуть больше шагов (например группировка после фильтрации но до отображения) или любые другие нетривиальные шаги то всё развалится.
что делать, если количество итераций цикла не 6, а 1000 или 10000? И мне вот интересно, как выгребать ошибки в составлении списка «integers».
что делать, если количество итераций цикла не 6, а 1000 или 10000? И мне вот интересно, как выгребать ошибки в составлении списка «integers».
например вот так:
integers = range(1, 10000)Примеры [1,2,3,4,5,6] составляют для наглядности, это не всегда скопированный из прода код.
Просто я ООП в работе мало пользуюсь, больше аналогом ФП. Мне вот такие сентенции в качестве примера не слишком понятны.
Это не значит, что Java — плохой язык. Но он не создан для решения тех задач, для решения которых отлично подходит функциональное программирование. Например — для управления базами данных или для разработки приложений из сферы машинного обучения.
Эм, джава, которая в куче энтерпрайз софта, и которая отлично работает с базами данных, оказывается не для этого создана?
Как мне кажется, для работы с базами данных джава отлично подходит. По логике в статье метод, в котором вставляются данные в БД (insert) уже не будет чистым — ведь он ничего не возвращает. Но в реальной жизни у нас есть изменяемое состояние (та же БД), и пример выше кажется надуманным.
Функция вставки записи в таблицу, примет на вход таблицу и запись и вернёт новую таблицу :) Или даже примет базу и вернёт новую базу
Что-то мне подсказывает, что автор статьи записал в функциональные языки ещё и SQL.
Участовать в споре функциональный ли язык SQL или нет, я не собираюсь, но, вообще-то, нечто общее у SQL с ФП есть — и уж, по-любому, в SQL реализована никак не императивная парадигма программирования.
А то, что SQL в качестве языка доступа к данным в БД (DML) сильно лучше императивных языков — это, думаю, ощутил на своей шкуре всякий достаточно опытный программист, которому приходилось в качестве DML где-нибудь в 1-й половине 90-х помучаться с чем-нибудь из серии Clipper/FoxPro/Paradox для написания запросов на получение данных из нескольких таблиц, да ещё и с фильтрами по значениям полей — тем, что в SQL делается в одну строчку.
А то, что SQL в качестве языка доступа к данным в БД (DML) сильно лучше императивных языков — это, думаю, ощутил на своей шкуре всякий достаточно опытный программист
Всегда? Ок, простая разминка для ума, у вас есть таблица с значениями id, parent_id описывающие дерево, силами чистого SQL найдите самую длинную ветку от корня.
То что не все так просто с SQL говорит тот факт, что почти любая база реализует какой-нибудь PL-SQL или Transact-SQL, которые уже явно не чисто функциональные.
Плюс, вы просто всякие hibernat'ы не встречали, существует множество библиотек, позволяющих из импреативной программы делать запросы ничуть не хуже чем SQL, например просто превращать иерархию классов в таблицы базы данных (у них свои проблемы с производительностью, но вот кое какие вещи на чистом SQL писать намного тяжелее).
За стандартный SQL не скажу (стандартов не читал давно), но вот в Transact-SQL для MS SQL Server рекурсивное получение данных из таблицы с id и parent_id, хранящей дерево (или даже целый лес), в виде набора записей, содержащих и вычисленную длину от корня дерева, вполне возможно и в чисто декларативном стиле — через использование Common Table Expresions (CTE) и UNION ALL. Как-то, типа (синтаксическую проверку не делал) так:
WITH Nodes(parent_id, id, node_level) AS (
SELECT parent_id, id, 0 as node_level FROM tree_table WHERE parent_id IS NULL
UNION ALL
SELECT t.parent_id, t.id, node_level+1 FROM tree_table t
INNER JOIN Nodes n ON t.parent_id = n.id
)
SELECT * FROM Nodes
Ну, а в оконечном SELECT (который я в простейшем виде записал) можно уже делать что нужно — например отсортировать записи в порядке убывания node_level и взять верхнюю.
Да, средства построения запросов SQL разной степени навороченности существуют, естественно: иначе бы программистам, которые обучены обычному императивному программирванию (а таких, наверное, большинство) было бы совсем грустно писать свои программы, которым по жизни часто с БД работать приходится.
средства построения запросов SQL разной степени навороченности существуют, естественно: иначе бы программистам, которые обучены обычному императивному программирванию (а таких, наверное, большинство) было бы совсем грустно писать свои программы, которым по жизни часто с БД работать приходится.
В результате вы сами себе противоречите — с одной стороны, что любой программист должен считать SQL самым лучшим языком для работы с БД, с другой внезапно большинство программистов внезапно вместо SQL используют совсем другие средства в качестве обертки над SQL, вместо того чтобы писать простыни SQL запросов в программе.
На самом деле, SQL, на мой взгляд, далеко не самый удобный и простой способ работы с БД, SQL больше похож на ассемблер или javascript — нативный, быстрый (по сравнению с обертками над ним), но многословный и тяжелый для написани и использования. Отладка и написание огромных простынь SQL запросов — боль, а попытка запихнуть вcю бизнес логику в какой-нибудь PL-SQL — создает монстров.
В результате вы сами себе противоречите — с одной стороны, что любой программист должен считать SQL самым лучшим языком для работы с БД, с другой внезапно большинство программистов внезапно вместо SQL используют совсем другие средства в качестве обертки над SQL
Противоречия нет — есть нюанс: не только лишь все программисты умеют в SQL.
Конечно, сферический программист в вакууме, в совершенстве знающий все языки, чаще (значительно чаще IMHO) будет использовать SQL для доступа к данным в базе. Но вот реальный программист, которого удалось нанять на проект за разумные(на самом деле — не совсем, потому что «всем нужен программист») деньги, от SQL с немалой вероятностью окажется далек — чисто потому, что SQL не похож на его основной рабочий язык. И вот потому применение всяких средств уклонения от написания кода на SQL — от ORM до конструкторов запросов (которые в GIU мышкой) оказывается более чем оправданным.
Но у этой опраданности есть и другая, тёмная сторона. В качестве примера её расскажу историю. Я как-то (в довольно давние уже времена, впрочем) был привлечен к выяснению вопроса, почему так тормозит свежеразработанный местными веб-программистами сайт. Недолгое колдунство с SQL Profiler однажды вечером, когда число запросов на сайт было далеко от пика, но общее торможение оставалось, позволило найти дивные SQL-запросы, выполнявшиеся по 15 секунд — причем это были не отчеты и не поиск по БД, а обычная генерация страниц квазистатического контента. Тем не менее, планировщику СУБД от этих запросов конкретно плохело — и не зря: просмотр текста запроса — крайне сложного и запутанного — ввел меня в глубокую задумчивость, как такое можно вообще написать? Вопрос этот (с примерами) я резонно переадресовал команде веб-программистов — на что получил честный ответ типа «А мы сами не знаем, оно автоматически создается» (потом они, правда, зная, где именно творится безобразие, все же что-то с ним сделали). Короче, думаю, мораль понятна.
SQL, повторяю, на мой взгляд, сложен для привыкших к императивному программированию (коих среди программистов большинство) своей непривычностью — и уж никоим образом не многословностью и необходимостью учитывать множество мелочей, как ассемблер. Мне, например, не приходилось писать действительно огромные простыни именно на SQL (а не на каком-нибудь расширении его для создания хранимых процедур): всё самое сложное, что было нужно, укладывалось в несколько (всяко меньше десятка) связанных друг с другом подзапросов. Правда нередко сразу было не очевидно, как их писать, и приходилось писать код не с начала, а буквально с середины. Но в итоге код запроса получался довольно компактным.
А вот в защиту бизнес-логики на хранимых процедурах у меня слов мало найдется. По-моему это — пережиток той уже давней эпохи, когда приложения были чисто клиент-серверные, с «толстым клиентом» (иными словами — «тощим» сервером, который был по сути СУБД), а удобных технологий вынесения бизнес-логики на сервер («трехзвенные приложения») ещё не существовало. Вот тогда, с теми ограничениями, бизнес-логика на PL-SQL и ему подобных была как-то оправдана. Сейчас же оправдание такой архитектуры для новых проектов я найти не могу.
И вот потому применение всяких средств уклонения от написания кода на SQL — от ORM до… оказывается более чем оправданным.
Справедливости ради:
- ORM — не средство уклонения от написания SQL, одно другое не исключает, самые быстрые ORM у меня были как раз с вручную написанными SQL запросами. ORM — лишь средство представить содержимое реляционной БД, строк в табличках в виде графа объектов и наоборот. Понятно, что без SQL запросов там не обойтись обычно, вопрос лишь в том генерируются SQL код программой из где-то задекларированного в коде/конфиге/аннотациях маппинге или пишется вручную из маппинга в голове программиста.
- различные QueryBuilder'ы часто являются 1:1 маппингом формально императивного, но псевдодекларативного кода на SQL:
$users = (new QueryBuilder($connection))->from('users', 'u')->where('u.isActive')->select()->execute->all(); $users = $connection->execute('SELECT * FROM users AS u WHERE u.isActive = 1')->execute()->all();
Как-то, по-моему, не сильно влияет на способ мышления разные способы записи.
SQL всяко лучше любого кастомного дсл. Но как я уже замечал, проблема в маппинге этого SQL на типы. В ОРМ весь билдер тащит типчики, а при написании запросов надо не забыть, что на что маппися и как.
ORM — не средство уклонения от написания SQL, одно другое не исключает,
Справедливо. Но ORM может использоваться как средство написания запросов на SQL. Но есть и другие средства. В частности, упомянутый выше 15-секундный запрос был написан отнюдь не ORM, потому что испольуемая там технология была VB+ASP(не .NET ещё).
различные QueryBuilder'ы часто являются 1:1 маппингом формально императивного, но псевдодекларативного кода на SQL
Этот код не «псевдо-» — он декларативный по сути, просто он записан не на SQL. Кстати, с непривычки такой код писать и читать труднее (сужу, естественно, по себе), чем привычные с юности вложенные циклы.
То что нельзя сделать чистую вставку в бд или вывод на консоль — это заблуждение. Конечно же на хаскелле можно и в базу ходить, и на экран печатать. В конце концов хелло ворлд же на хаскелле написать можно:
main :: IO ()
main = putStrLn "Hello World"Тем не менее этот main — чистая функция.
Если на пальцах, то чистота означает не то что функция не делате ничего полезного, а то что её резульат действий всегда есть в сигнатуре. Например если функция возвращает () (юнит тип, воид в терминах сишных языков), то значит она ничего полезного не делает. А вот если она возвращает SqlInsert () или IO (), значит она выполняет какие-то действия, в результате которых получится тот же самый (). Но теперь кроме результата у нас есть действия, которые функции должна выполнить.
В си у вас функция которая ничего не делает выглядит как void foo() и функция которая печатает в консоль тоже выглядит как void bar(). В хаскелле же первая будет foo :: () а вторая bar :: IO (). И эта разница принципиальна.
Так что чистота, если грубо на пальцах объяснить, это когда из сигнатуры видно, будет ходить функция в базу или нет. А не то, ходит ли она в принципе или нет.
Если на пальцах, то чистота означает не то что функция не делате ничего полезного, а то что её резульат действий всегда есть в сигнатуре.
А я думал, что это ещё и означает, что при одинаковых входах она возвращает одинаковый результат… Но c другой стороны, если считать результатом функции не сам вывод в консоль (который может при равных входящих как завершиться как успешно, так и с ошибкой, а это считай два разных результата), а операцию вывода в консоль (ну типа паттерн "команда"), то наверное такую функцию и правда можно назвать чистой
Но c другой стороны, если считать результатом функции не сам вывод в консоль (который может при равных входящих как завершиться как успешно, так и с ошибкой, а это считай два разных результата), а операцию вывода в консоль (ну типа паттерн "команда"), то наверное такую функцию и правда можно назвать чистой
Именно так.
Так что чистота, если грубо на пальцах объяснить, это когда из сигнатуры видно, будет ходить функция в базу или нет. А не то, ходит ли она в принципе или нет.
А из сигнатуры будет видно — пойдёт функция в базу или в консоль?
Ну например из моего пет проекта:
getPersonsInner :: (IsSqlBackend backend) => SqlPersist backend [User]
getPersonsInner = do
people <- select $
from $ \person -> do
pure person
pure $ fmap entityVal peopleСобственно SqlPersist backend [User] показывает, что операция будет ходить в базу и вернет список юзеров.
хм, и эта функция тоже считается чистой?
и как чисто по этой аннотации понять, что IsSqlBackend — это какой-то внешний источник и каждый вызов
getPersonsInner backendможет вернуть разные результаты (а стало быть может быть мемоизован лишь с оговорками)?
Хм, действительно, интересный подход!
И по типам можно определить, является ли результат функции действиями для такого интерпретатора (и для какого именно) или "базовыми примитивами" (тут я понимаю, что вступаю на скользкую дорожку и что скорее всего мне ответят, что действия тоже являются базовыми примитивами)
Как теперь заставить программиста четко выражать свои намерения, а не ставить везде IO?
Как выше написали, этот внешний источник возвращает данные разные при интерпретации, но функция getPersonsInner возвращает не результат запроса, а описатель этого запроса.
Вот я в качестве интереса набрасывал мою реализацию IO на расте:
https://gist.github.com/Pzixel/3fc17be254f6c6bcaf88711e12bddd2c
Обратите внимание, что get_line или read_line чистый по-определению, например можно сделать:
get_line().flat_map(|x|
get_line().flat_map(|y|
write_line(concat!(x,y))))эквивалентно:
let line = get_line();
line.flat_map(|x|
line.flat_map(|y|
write_line(concat!(x,y))))Такое разделение очень полезно по многим причинам. Во-первых сразу видно, какие виды действий делает функция. Отдельно выделяется функция, которая не делает никаких вычислений, например функция Length или какой-нибудь Sqrt. Во-вторых появляется возможность "отменять" действия по каким-нибудь причинам, потому что пока вы не начали интерпретировать, действие не запустится.
на самом деле в этом нет никакой магии, как видно в примере выше любой язык позволяет писать в таком духе. Вопрос только, хотят ли этим люди заниматься или нет. В общем случае, если СТД и библиотеки в таком виде не написаны, то воевать против всего мира не получится.
никакой магии нет, но определенная сложность в понимании есть. Самый простой способ — попробовать в таком виде пописать. Сразу вся "волшебность" отпадает и остается только зрелое понимание, как это работает и зачем нужно.
Foo<TError, TResult>(bla bla, ba bla); //syntax is not trueудивился что так можно было. По сути прокачанный ООП, где вместо стандартного возврата типа было бы что-нибудь такое
IWorker{
class WorkerResult;
class WorkerError: WorkerResult, Error
WorkerResult Work(WorkerInput Input) => if(Input is null) return new WorkerError("Guy, who programmed this, is {(int)Input} meaning")
}
То есть абсолютно типизированная обработка и входов и выходов функции — рай ООП.
p.s. даже не знаю теперь, фреймворк написать или сразу язык.
Ну это обычное использование Either для ошибок, весь раст на этом построен (там типчик Result называется).
В ООП языках неудобно потому что там или нет достаточно мощного свитча для этого, или он есть, но писать постоянно обработку кейса когда наш WorkerResult это и не WorkerOk и не WorkerError, а что-то другое.
Either и Result — это одно и то же. То что это частный случай sum types — очевидно, как например "синглтон" или "фабрика" это частный случай классов.
А вот как chain of responsibility это расширяет — непонятно. Как и со стратегией — стратегия предполагает открытое множество, собственно, "стратегий", а АДТ — нет.
Если же искать что-то похожее в ООП, то самое близкое это визитор.
Монады можно применять в том числе чтобы делать эффекты чистыми. Само ИО тоже чистое, если взять определение. Оно и было придумано, чтобы "упаковывать" всякую грязь в чистый язык.
Соответственно чистая функция монаде не противопоставляется, поэтому второй вопрос не очень корректный. Если же вопрос, когда стоит писать в монаде а когда нет — аналогичен "когда стоит выносить функционал в интерфейс/базовый класс, а когда — нет". Если так удобнее, то стоит, если нет — то нет.
Отличие в том, что в интерфейсах самих по себе ничего плогохо нет. В той же Java, например, интерфейс — это основопологающая концепция. Как правило, нет ничего плохого чтобы создать очередной интерфейс. Да, всегда можно упороться и начать городить «фабрики фабрик», но как правило человека от этого останавливает обычная лень. А что останавливает человека от оборачивания всего и вся в IO? И насколько всеже IO антипаттерн? Может мы неправильно понимаем ФП, и нужно вообще все писать в IO?
А что останавливает человека от оборачивания всего и вся в IO?
Ровно та же "лень", про которую вы пишете, ну и вообще здравый смысл
Вон выше пример писали — функция add в монаде IO, и чистая:
add :: IO Int -> IO Int -> IO Int
add x y = do
a <- x
b <- y
return (a + b)
add2 :: Int -> Int -> Int
add2 x y = x + yПо-моему при написании функции обычно не возникает проблемы определить, требуется ей доступ в сеть или нет (для примера). Нужен — используете, не нужен — пишете чистую функцию.
А что останавливает человека от оборачивания всего и вся в IO? И насколько всеже IO антипаттерн? Может мы неправильно понимаем ФП, и нужно вообще все писать в IO?
А что останавливает человека от того, чтобы все функции писать как асинхронные, а где асинхронности по факту не надо просто возвращать Task.FromResult()/Promise.resolve/...? Здравый смысл, наверное.
Меня интересует, какие препятствия ставит haskell от неправильного применения монад, в том числе IO. Насколько сложнее писать код в монаде IO, чем не в монаде IO?
Примерно настолько же, насколько легко писать асинхронные функции с async/await :dunno:
Я вопрос не понимаю. Правило простое: пишите без монад пока вам компилятор не скажет что не компилируется т.к. какая-то из вызываемых функций требует монаду. Профит. Прямо как с асинком. Пишем синхронно пока компилятор не говорит что у нас тут асинхронность. Вставляем авейт, становимся асинхронными.
Потомучто здравый смысл — а что считать здравым смыслом? Давайте в любом другом языке будем приписывать суффикс pure к чистым функциям. Это будет считаться здравым смыслом?
> Примерно настолько же, насколько легко писать асинхронные функции с async/await
Ну например, теже акторные фреймворки вынуждают программистов писать в асинхронном стиле. Там очень сложно засинхронизироваться, и поэтому, один раз написав асинхронную функцию, вы на большую часть разработки оказываетесь привязанны к асинхронному коду.
Я понял. Вы считаете, что стилем кода по большей части управляет здравый смысл. Я считаю, что им управляет лень. То есть мы просто говорим на разных языках.
Потомучто здравый смысл — а что считать здравым смыслом? Давайте в любом другом языке будем приписывать суффикс pure к чистым функциям. Это будет считаться здравым смыслом?
С точки зрения лени IO — лищние буковки, которые можно не писать.
Ну например, теже акторные фреймворки вынуждают программистов писать в асинхронном стиле. Там очень сложно засинхронизироваться, и поэтому, один раз написав асинхронную функцию, вы на большую часть разработки оказываетесь привязанны к асинхронному коду.
асинк это один из видов монад. Его особенности распространяются на их все, включая ИО. Если где-то внизу коллстека появился эффект, то за редким исключением он будет протекать до самого верха.
А если эти лишние буковки упрощают написание остального кода? В результате лишних буковок становится много меньше
Поймите, я не хочу писать весь код в IO просто ради хулиганства. Я хочу его писать там просто потому, что мне например проще мыслить в императивном стиле, а не функциональном. Мне проще сходить в сеть когда мне захочется, а не когда мне это позволят. Записать в лог чтото в произвольном месте кода. Что меня остановит?
> асинк это один из видов монад
Мне кажется, обсуждение ушло в другое русло
Мне проще сходить в сеть когда мне захочется, а не когда мне это позволят. Записать в лог чтото в произвольном месте кода. Что меня остановит?
Ничего не остановит от написания всех функций в IO — ровно так же, как от написания всего кода проекта в одном файле или даже одной функции, например. Вы же в условной джаве указываете тип функции не object f(object a, object b), а int f(string a, int b), хотя в принципе можно везде с object'ами работать.
А вот написать весь код в одном файле — удобно. Поэтому с этим борются всякими административными методами.
А вот написать весь код в одном файле — удобно. Поэтому с этим борются всякими административными методами.
Нет, не удобно и не административными методами с этим борются, по крайней мере преимущественно. Иначе бы все личные pet projects на гитхабе состояли из одного файла — ведь никакой "администрации" там не руководит.
Тем не менее и на гитхабе попадаются проекты из одного файла
Тем не менее и на гитхабе попадаются проекты из одного файла
Обычно чем более квалифицированный человек пишет код на гитхабе, тем больше он похож на корпоративный проект. У достаточно опытного разработчика будет декомпозиция по файлам, ридми, примеры, опубликованная в местном пакетнике версия, настроенные билды, и так далее.
Вопрос в том, что если вырабатывать в себе какуюто самодисциплину, то какая по большому счету разница, в каком языке это делать? Да, haskell в какихто случаях лучше других языков, как и любой один язык в чемто лучше любого другого. Но есть ли прям какаято киллер-фича, без которой никуда?
«Пиши код в таком стиле — тогда не будет побочных эффектов». Да, круто, но в таком стиле я могу писать код и на другом языке, это как я уже сказал, вопрос самодисциплины
"Самодисциплина" не проверяется компилятором: достаточно один раз с недосыпа забыть где-нибудь во внутрнней функции вставить какой-нибудь запрос к сети, и это пойдёт через весь код который её вызывает.
Но есть ли прям какаято киллер-фича, без которой никуда?
Такого нет ни в каком языке: если бы была фича, "без которой никуда", то ни на каком языке без этой фичи писать было бы невозможно.
«Пиши код в таком стиле — тогда не будет побочных эффектов». Да, круто, но в таком стиле я могу писать код и на другом языке, это как я уже сказал, вопрос самодисциплины
И в каком другом языке компилятор не разрешит из функции
sqr :: Int -> Int вызвать printf?
Поймите, я не хочу писать весь код в IO просто ради хулиганства. Я хочу его писать там просто потому, что мне например проще мыслить в императивном стиле, а не функциональном. Мне проще сходить в сеть когда мне захочется, а не когда мне это позволят. Записать в лог чтото в произвольном месте кода. Что меня остановит?
ИО не позволяет писать в императивном стиле. State позволяет ST позволяет, а ИО — нет.
Так если вы просто хотите внутри функции писать код "в императивном стиле" с изменением локальных переменных, то можно его писать в монаде ST и вызывать runST как тут уже писали. Итоговая функция будет безо всяких монад в сигнатуре: действительно, пользователю не нужно знать как она реализована, если внешне-видимой разницы от этого нет.
То есть должен ли я насиловать себя, и стараться писать любой код «чисто» (то бишь без монад в таком понимании), или это позволительно расслабиться и сделать как проще?
Вы видимо исходите из того, что "проще" писать в императивном стиле — хотя множество примеров показывает, что часто это не так.
Вы точно читаете предыдущие сообщения? Буквально 10 минут назад я писал про монаду ST и чистые функции. В других цепочках тут тоже про неё упоминали в контексте написания алгоритмов, которые более естественно ложатся на мутабельные переменные.
Пишите, где удобнее. Но по факту St не вижу почти нигде, разве что когда кальку с императивных алгоритмов снимают типа инплейс квиксорта.
newlist = []
def append_to_list2(x, some_list):
some_list.append(x)
append_to_list2(1,newlist)
append_to_list2(2,newlist)
newlist
Мы избавились от побочных эффектов. И это очень хорошо.
А что разве в данном случае append_to_list2 — не создает побочных эффектов? Она же меняет внешний newlist, который потом выводится?
Тут вопрос не в ФП, а в гц. На каком-нибудь сишарпе наверное лоу-латенси не особо попишешь.
Товарищ из майкрософта который actix писал (на который azure iot перевели) как раз жаловался, что код на шарпах аллоцирует как не в себя даже на IO bound задачах, на затюненном приложении. И уверяю, что если майкрософт не умеет готовить C#, то никто не умеет.
Это он жаловался до появления Pipelines или после?
ну Actix писался в 2017-2018 годах, полагаю сравнение было примерно в этом районе.
Pipelines тоже в 2017-2018 годах делались...
Ну я не думаю что там что-то поменялось. Аллокации на каждый чих (если пользоваться структурами, то о наследовании можно забыть), при том что все стандартные типы типа строк и массивов — исключительно хиповые. Span на стакаллок память работает хорошо только на бумаге, все задачи всегда выполняются на тредпуле, который нафиг для ИО не нужен, и так далее… Это всё кишки CLR и BCL, я не думаю что Pipelines или что-то ещё с этим может что-то сделать.
Есть же ArrayPool
Но способа выполнять таски не на тредпуле а на current thread например я не знаю. В BCL зашито что оно все в тредпуле, все эти ISyncronizationContext и все остальное прям вопит об этом.
Пул это хорошо, но не всегда удобно и/или возможно.
Но способа выполнять таски не на тредпуле а на current thread например я не знаю.
TaskScheduler.FromCurrentSynchronizationContext() (в ContinueWith, в конструкторе TaskFactory) — не оно?
Правда, для этого упомянутый SynchronizationContext должен быть. Впрочем, там где это очень важно (в GUI к примеру, где все обращение к GUI должно быть в выделенном для этого потоке) MS уже изначально об этом позаботилась, а для желающих странного есть возможность реализовать SynchronizationContext самостоятельно.
Всё что тут описано как "функциональный подход" используется в ООП. Влюбляются в фп те, кому не хочется разбираться с возможности ООП, т.к. единственное, что отличает фп от ооп — отсутствие классов (если грубо округлить)
Вывод: то что действительно важно — это классы(если грубо округлить).
Пишу на сишарпе с иерархиями, наследованием и всем остальным в ФП стиле (за исключением монад, но тут уж понятно). ЧЯДНТ?
P.S. а вывод «ФП это просто процедурное программирование» вас не смущает? Это как сказать чёрное это белое…
Нет, не получается просто ООП. Даже дядюшка Боб уже писал, что ООП и ФП непротиворечат друг другу. И сказать "Да эт опросто ООП" — это свернуть весь спектр до одной точки.
монада State это такой типичный объектчто делает State объектом(с точки зрения ООП)?
Ниже дедфуд и выше психаст уже ответили
Что-то не вижу ответа на мой вопрос — ни ниже, ни выше.
Мне просто интересно, почему по вашему монада State это не объект?состояние торчит наружу, объекты имеют внутреннее состояние. Разные объекты могут взаимодействовать друг с другом путём отправки сообщений, обрабатывать сообщения. В Java, например, этот механизм редуцирован до (subtype)полиморфных методов. State же подобных механизмов не имеет.
И да, это не значит что ООП на hs нельзя изобразить, вполне себе можно. Только, как и везде(в т.ч. Java), это очень редко нужно.
А какой-нибудь data-bean с геттером-сеттером и без других методов – это уже не объект?
Что-то не вижу ответа на мой вопрос — ни ниже, ни выше.
Глаза протрите.
состояние торчит наружу
То есть по вашему ООП про приватное состояние и получается что в каком нибудь Python ООП нет? Шире мыслить надо. Objects are poor man's closures ООП оно про то что результат вычисления зависит не только от входных параметров его метода но и от каких-то еще данных и эти данные вполне могут быть публичными. Какой нибудь контроллер который возвращает какое нибудь значение которое ему возвращает какой-то репозиторий которым он обладает это таки типичный объект потому что он возвращает значения на основе данных которые ему отдает его репозиторий (который тоже может обладать стейтом или в просто виде массива или в виде БД) а не только тех данных которые ему передали в качестве параметров.Только вот обычно сам объект идет неким параметром в каждом методе. this или self. Ничего не напоминает? А ну да например >>= первым параметром принимает саму монаду т. е. this aka self. Для любой монады результат do x< — monad return x зависит от того какое значение было до этого в монаде (например если было None то None и вернется) поэтому вообще любая монада это объект. Не несите фигни. А то как в той поговорке, научили грамоте осла раньше он просто глупости говорил а теперь он говорит глупости грамотно. Еще раз для таких как вы повторяю — ООП оно про то что функция или метод связанный с объектом возвращает значение или вызывает эффект на основе текущего состояния этого объект и абсолютно не важно публичное ли это состояние или нет.
Глаза протрите.Не надо хамить
То есть по вашему ООП про приватное состояние и получается что в каком нибудь Python ООП нет? Шире мыслить надо.Это был один из критериев, вы путаете инкапсуляцию и сокрытие. Далее был описан пример data-bean, в котором есть сокрытие, но нет инкапсуляции.
ООП оно про то что результат вычисления зависит не только от входных параметров его метода но и от каких-то еще данных и эти данные вполне могут быть публичнымиОпять же — Вы путаете ООП и процедурное программирование, ООП совсем не про это.
ООП про объекты, их поведение и взаимодействие(сообщения), про инкапсуляцию внутреннего состояния.
Только вот обычно сам объект идет неким параметром в каждом методе. this или self. Ничего не напоминает? А ну да например >>= первым параметром принимает саму монаду т. е. this aka self. Для любой монады результат do x< — monad return x зависит от того какое значение было до этого в монаде (например если было None то None и вернется) поэтому вообще любая монада это объект.Да чего мелочиться то? f x = x зависит от того какое значение было до этого в x (например если было None то None и вернется) поэтому вообще всё что угодно это объект. А если назвать x 'this', то и комар носа не подточит. f this = this. Матерь божья, где-то я это уже видел:
public A f(A this) {
return this;
}
...
a.f();Те же каррированные функции это объекты и какой нибудь
def add(a)(b)
val c = add(1)
val r = c(2)
будет равен по сути своей вызову у инстанса объекта Int метода add вот так
var r = 1.add(2)
Вообще да в скале 1 реально инстанс объекта и у 1 реально есть метод + и по сути 1 + 2 это в Scala синтаксический сахар над вызовом метода объекта Int. Такие дела.
Объект это структура данных и набор функций ака методов для работы с ней. Связанных с ней. Поэтому List и Maybe это объекты.А вас не смущает, что для любой структуры данных есть функции, которые с ней работают? Если всё ООП, то нет никакого ООП, т.к. нет смысла отдельно упоминать о том, что есть везде и по умолчанию.
Ну вообще Алан Кей, который придумал понятие ООП, объекты как акторы и определял.
Смысл ООПроектирования чтобы выделить все функции которые работаю именно с этой структурой в единый объект.
Все-все-все? А если потом новых функций придумали?
Ну вообще Алан Кей, который придумал понятие ООП, объекты как акторы и определялВ том-то и дело, что он задумал их (пусть не самый первый, а на плечах предшественников) как акторы, обменивающиеся сообщениями. Но в мейнстриме (C++, Java) победила (пока?) другая версия ООП, которая служит в основном переиспользованию кода — наследование и полиморфизм. А у этих победителей и с инкапсуляцией все плохо, и с хрупкостью кода, и с расширяемостью. Но народ пока терпит…
Анемичная модель (класс со свойствами и только тупыми геттерами/сеттерами) — хороший пример одновременно ООП(грамирования) без ООП(роектирования).
Вообще ООП оно про взаимодействие объектов друг с другом так или иначе и в том же Хаскель в прикладном каком нибудь коде так же будут объекты Order, User, Item и взаимодействие их с друг другом через связанные с ними функцииТо, что всё объект и везде ООП, Вы уже объяснили. Пойдём от обратного — возможно ли писать не объектно ориентированный код? Можно пример такого кода?
Например
val x = 1
val notOopX = mul(add(x,2),3)
val oopX = x.add(2).mul(3)Разница тут в вызвать у объекта X метод или вызвать функцию add с передачей ей x в качестве параметра. То бишь оба вариант могу быть ООП если для вас важнее какие у меня есть X и что он может сделать чем какие у меня есть функции и что они могут сделать.
list.map(x=>x+1)
Объект это экземпляр какого-то типа и связанные с ним методы использующие данные этого конкретного экземпляра.
int x = 1; int y = 2; int z = x + y;x, y, z — это объекты? Код(java) объектно-ориентирован?(вопрос в том, что даже в терминологии Java ничего из объявленного — не объект).
А для того же кода на haskell — x, y, z это объекты? Код объектно ориентирован?
x = 1 :: Int
y = 2 :: Int
z = x + y
На мой взгляд Ваше определение термина «объект» имеет место в целом в computer science, но никакого отношения к термину «объект» объектно-ориентированного программирования не имеет(во всяком случае это разные вещи).
Само определение объекта ООП таким образом, просто обесценивает ООП, ведь по сути нельзя написать не объектно-ориентированный код — в чём тогда ценность термина?
Допустим у вас ЯП без генериков и кодо генерации. Вам нужно сделать метода добавления и умножения для Int и для Float.
В ООП стиле — вы сделаете модуль где будут методы Add и Mul для Int Потом сделает отдельный модуль где будут методы Add и Mull для Float
Без ООП стиля — вы сделаете модуль где будут все Методы Add и модуль где будут все методы Mul. Потому что вам важнее что за функции у вас есть и что они делают. В ООП наоборот для вас важнее что за структуры данных у вас есть и что с ними можно сделать. Теперь разницу поняли?
Вам просто надо перестать смотреть на объекты как на классы из JavaЯ уже объяснял, и не раз, что такое объект ООП на мой взгляд. Когда я говорю о Java я специально помечаю что речь об объекте в терминологии Java, а не об объекте ООП.
более общая абстракция которая по сути значит инстансы неких типов данныхНет не значит, по крайнем мере в ООП. Объект это не просто струтура данных, объект имеет собственное поведение, которое зависит от состояния, инкапсулируемого объектом.
да, любую структуру данных можно представить как объект. И обратное тоже верно. Можно любую структуру данных рассматривать как просто данные для вашей функции. 1 это и объект тип Int и одновременно не объект. Все зависит от того на основе какого предположения вы будете проектировать и писать свой код.если речь том, что одну и ту же сущность можно представить в виде объекта, или не объекта — я с этим согласен. Беда в том, что по вашему определению это в любом случае будет объект. И никакой ценности представление в том или инном виде не имеет.
Теперь разницу поняли?Конечно, сенсей. Не понял только, что общего State a имеет с ООП. По моему самое логичное объяснение «Если из всех инструментов у тебя есть только молоток, то в каждой проблеме ты увидишь гвоздь». Т.е. Вы просто не воспринимаете других подходов, ведь не знаете ничего кроме ООП.
Я просто много подходов знаю и умеюкруто, наверное, много уметь. Видимо, настолько расширенные взгляды позволяют Вам утверждать что
ООП рука об руку идет с TyDDХотя казалось бы — какая связь? Ведь ООП это вообще не про статическую типизацию. И вполне нормально себя чувствует и в динамически типизированных языках.
Но куда нам, простым смертным. Видимо, остаётся поверить на слово.
ООП вообще никакого отношения к TyDD не имеет.
ООП прямое отношение имеет к типамА в названии TyDD как раз есть слово «тип». А всё что можно назвать «объектом» — это ООП.
Так уфологи, видимо, были основоположниками ООП, ведь они исследовали НЛО. Вот, нашли применение этим объектам в программировании.
Следующим шагом предлагаю провозгласить любую программу не только объектно ориентированной, но и функциональной(ФП), ведь в любой программе, определённо есть функции.
TyDD без проверки компилятором — всё равно что TeDD со случайным запуском тестов.
В js есть типы — значит js идёт рука об руку с TyDD, так?
Но ведь в js нет типов.

В прототипном ООП (JS-стайл) никаких особо типов, кроме object, нет (и то, говорят, не тип, а рантайм-тег), и тем не менее как-то работает и полиморфирует.
//Это не объект хоть и класс C#
class Calculator
{
int Add(int a, int b) => a + b
}
//Вот это объект
class Service
{
public IRepository Repo{get;set;}
public int Count() => Repository.Count()
}class User {
String name;
String something;
}Да в Scala у него могут появится методы от тайпклассовimplicit class, не type class
Грубо говоря в той же Java можно сказать что Методы это процедуры которые первым параметром принимают сам объект как thisзато у методов в Java есть исключительное право на доступ к приватным полям. Да и вообще — методы в Java это лишь отражение системы сообщений прежних языков, в которых развивалось ООП. И, конечно, метод в Java это не то же самое что обычная процедура.(да, я не сомневаюсь что Вы знаете про виртуальность, но по моему это очень важное отличие, которое позволяет изменить поведение объекта).
Динамическая типизация это значит что типы проверяются во время выполнения а не во время компиляции.Да, а TyDD это про статическую проверку.
В JS number — не объект. А полноценные объекты могут создаваться без явного объявления class или функции-конструктора. Тупо на литералах и динамических "объявлениях" методов. У всех объектов сложной системы будет один тип object, если исключить встроенные типы вроде Date или Number (не путать с number)
КМК, всё-таки идеологически мешает.
ООП — оно об инкапсуляции стейта в объектах, в том числе об изменении этого стейта в ответ на внешние раздражители. Без мутабельности методы объектов — просто пачка частично-применённых функций.
К тому же всегда будет проблема с несовместимостью разных объектных систем(за неимением встроенной в язык). Оно и понятно — язык то не объектно ориентированный.
Лист в хаскеле всё-таки больше управляющая конструкция, чем коллекция данных.
инкапсуялиция она про собирать вместе, включать в себя а сокрытие про то что с наружи не видноИнкапсуляция это когда внутреннее устройство компонента отделено от его интерфейса. (Компонент выступает в роли черного ящика).
Так List в хаскеле ничего не инкапсулирует, вся его структура доступна любому желающему.
Заучили баз ворды и теперь повторяете их как попугай«TyDD», «Type class», какие ещё были «баз ворды»?
Тратить на вас время бессмысленноПравильно, время лучше не тратить, а использовать. Например, для улучшения собственных навыков и знаний.
Все равно не поймете.Согласен, мне действительно не понять почему hs List это ООП объект, и с чего вдруг ООП «намертво связанно в TyDD». Видимо, тут нужен Lead 80го уровня =)
Немного есть опыт работы с C++ и Haskell, хотя оба языка не являются идеальными ООП и ФП в вакууме. Если сравнивать более менее сформировавшиеся проекты, в которые до сих пор вносятся изменения, то их состояние можно описать как неустойчивое и устойчивое равновесие.
Все особенности ООП подхода с разными шаблонами, постоянными спорами "ты не так понимаешь принцип единственной ответственности" делает состояние согласованной и однородной кодовой базы весьма красивым, но со временем оно склонно разваливаться. Костыли писать весьма легко. Делать зависимость локального логгера от подключения к БД вам никто не помешает. Конечно можно сказать "Нормально делай — нормально будет", но формального определения нормального в ООП нет, есть только несколько общепринятых трактовок, внутри которых также остается пространство для спекуляций. Чтобы проект придерживался архитектуры приходится прикладывать усилия.
С другой стороны, особенность системы типов Haskell состоит в строгих ограничивающих требованиях к процессу разработки. Обходить эти требования больнее, чем пользоваться языком в рамках нормы. Ограниченность побочных эффектов автоматически проецируется в гексагональную (луковую) архитектуру приложения. Притом это происходит не из-за усилий идеологов чистого ФП, а само собой. Как в ситуации с устойчивым равновесием.
Плюсами я пользуюсь в большей степени, уж как-то пришлось разобраться с особенностями ООП, но любовь к ФП у меня точно не из-за того, что мне лень разбираться с классами.
Почему разработчики влюбляются в функциональное программирование?
Потому, что разработчикам свойственно влюбляться во все новое, загадочное и прекрасное. Это что-то вроде эффекта Кулиджа в интерпретации на программирование. Но строить долговременные отношения, все же, лучше с теми, кто тебя поддерживает и понимает.
В разработке основная борьба идет со сложностью. Хаскели копают уже больше 30 лет. Согласитесь, это достаточный срок для того, чтобы индустрия могла развернуться к ним лицом, давай все эти милые ФП трюки, хотя бы 20% преимуществ на практике (в терминах сроков, бюджетов или сопровождения). Пусть даже не вся, я согласен принять как аргумент в пользу, если доминирование ФП будет заметным хотя бы в каких-то определенных нишах.
На чём пишут компиляторы C++, Java, C#, Fortran, Rust, Go?
Часто пишут на OCaml, он для этого очень хорош. А потом обычно бутстрапят, просто потому что с догфудингом повышается надежность и качество фичей языка. Ну и плюс это некоторый критерий успешности и взрослости.
А с ними-то что не так?
На языках со сборщиком мусора подобные структуры данных копируются при необходимости модификации и не копируются (передаются по неизменяемой ссылке) когда модификация не требуется.
На языках без сборщика мусора так тоже можно делать, но понадобится подсчёт ссылок.
Короткий ответ — да, должно копироваться, и нет, по факту не копируется. См. персистентные структуры данных.
За длинным есть классическая книжка на эту тему, что-то вроде банды четырех для ООП или Кнута для сишников:

Если описать функциональное программирование простыми словами, то это — создание функций для работы с неизменяемыми переменными.
И сразу с места в карьер мимо. Функциональное программирование — оно про функции как объекты первого порядка, поэтому оно и называется функциональным. Здесь и далее в статье вы описываете Haskell. По вашему описанию, вся из себя функциональная Scheme функциональщиной не является, потому что про побочные эффекты там вообще ничего нет, и доступно мутирование состояния через set!.
Понять это можно, если учесть тот факт, что у каждой функции, по умолчанию, есть, как минимум, один параметр — self
Снова чушь. Прежде чем позориться, взяли бы на себя труд узнать про то, как и зачем в питоне работает self.
По вашему описанию, вся из себя функциональная Scheme функциональщиной не является, потому что про побочные эффекты там вообще ничего нет, и доступно мутирование состояния через set!.
Именно, не является. Как и любой лисп, в общем-то.
Понять это можно, если учесть тот факт, что у каждой функции, по умолчанию, есть, как минимум, один параметр — self.
Вы уверены в этом? )
Почему разработчики влюбляются в функциональное программирование?