Зачем Ростелекому знать про адреса все и даже немного больше?
Интернет, при всем своем цифровом имидже, штука, созданная в аналоговом мире. И до сих пор для того, чтобы в доме был высокоскоростной интернет, к дому должен быть физически подведён кабель.
Именно адрес дома является ключевым объектом идентификации в многоступенчатом процессе предоставления услуг Интернета.
Адрес возникает в момент, когда клиент звонит к нам в Ростелеком с вопросом, можно ли подключить интернет. Оператору нужно знать адрес клиента, чтобы проверить, проведён ли к дому кабель с интернетом. Адрес используется вплоть до этапа сопровождения и обслуживания действующего клиента. При обращении в службу технической поддержки по адресу клиента проверяется, является ли проблема локальной, или авария массовая и проблема затронула целый квартал.

И конечно, на каждом шаге процесса важна скорость ответа клиенту.
В этом посте мы расскажем о том, насколько важен для наших внутренних систем адрес клиента, почему ФИАС — не панацея, и для чего был создан Единый паспорт дома.
Чем быстрее клиент получит подтверждение возможности подключить интернет, тем выше вероятность, что он выберет именно Ростелеком. Рынок услуг интернета высококонкурентный и малейшая задержка с ответом на запрос клиента может снизить его лояльность и спровоцировать уход к другому, более оперативному оператору связи.
Упрощенно, бизнес-процесс прохождения заявки на подключение интернета выглядит следующим образом. Заявка от клиента попадает в систему – это может быть сайт или другая система, где можно вести заявки. Далее запрос отправляется в систему линейно-технического учета для проверки наличия технической возможности подключения клиента по его адресу. Если техническая возможность есть, то заявка передается в рабочую систему для монтажников, которые выполнят подключение клиента к интернету. После включения услуги на сети заявка уходит в биллинг, где производится расчёт стоимости услуг для абонента. Из биллинга формируются ежемесячные выгрузки для отправки счетов и претензионных писем должникам.
Все эти информационные системы разрабатывались и внедрялись ещё до объединения Ростелеком, и как правило, до того, как рынок интернета стал столь высококонкурентным.
Действующие информационные системы обеспечивали непрерывный процесс продаж и подключения услуг связи по стране, но при этом интеграция между ними осуществлялась в полуавтоматизированном режиме. Системы были слабо связаны между собой и не проектировались для взаимодействия в рамках единого информационного пространства. В каждой системе использовались свои адресные каталоги, справочники, принципы идентификации объектов.
Для эффективного взаимодействия всех систем в едином централизованном бизнес-процессе продаж и обслуживания клиентов компании Ростелеком необходимо было обеспечить общий «протокол» общения – систему классификации и идентификации адресных объектов. При этом отправной точкой должен быть именно объект недвижимости, который может иметь адрес, может его не иметь, может иметь альтернативную адресацию, но в любом случае должен быть определен однозначно.
Для этих целей был запущен проект — Единый паспорт дома (ОРПОН), который обеспечил переход от разрозненных, неполных, противоречивых источников данных к единому интегрированному адресному пространству, в котором взаимодействие между ИТ-системами всех филиалов Ростелекома происходит автоматически, без ручной обработки.
Когда в компании возникает задача создания справочника, то всё кажется очень простым.
Во-первых, адрес — это что-то всем знакомое, каждый с этим сталкивается ежедневно, каждый знает, как писать адрес: как Бог на душу положит.
Во-вторых, после первых пятнадцати минут изучения вопроса в интернете вы узнаете, что адресный справочник на всю Россию уже создан в налоговой. И всё, что вам остается сделать – скачать базу ФИАС, загрузить в базу данных и адресный справочник готов. В некотором смысле, конечно, всё так и есть.
Существует федеральная информационная адресная система, в ней существуют адреса, они регулярно обновляются, и ФНС регулярно выкладывает обновления. Для многих задач этот справочник подходит, например, для задач ФНС.
Но проблемы Ростелекома ФИАС решить не мог. В адресных справочниках Ростелекома адресов значительно больше, чем в адресном справочнике налоговой, и Ростелеком узнает о строительстве нового дома в среднем на несколько лет раньше, чем этот дом появится в справочнике ФИАС. И Ростелекому важно знать не только про адреса, а однозначно связать адрес с объектом недвижимости, и определить все значимые характеристики этого объекта: год постройки, материал стен, назначение и 90 других очень важных параметров.
Но самая главная проблемы была в том, что на момент старта проекта в Ростелекоме существовало не менее 40 активно используемых систем, в каждой из которых был свой адресный справочник, была своя база с адресами, сопоставление которой с ФИАС давало на выходе около 60% совпадающих адресов и 40% адресов, о которых налоговая ничего не знает.
Определить эти 40% адресов как «мусор» было нельзя, потому что на них располагалось примерно столько же процентов абонентской базы, и отказ от адресов означает отказ и от абонентов тоже. По каждому адресу из отсева нужно было понимать: существует ли такой адрес и является ли данный адрес независимым, или является дублем другого адреса? Или может быть это угловой дом, и мы имеем дело с альтернативной адресацией?
Нужно было придумать решение, которое позволило бы связать между собой не менее 95% адресов. То есть для 35% адресов из тех, которые не сошлись с ФИАС, нужно было придумать алгоритм, который позволит принимать решения по ним. Это нужно было делать автоматически. Для того, чтобы обработать вручную около 40% адресной базы Ростелекома, понадобилось бы около 120 человеколет. Да и устранять проблему человеческого фактора с помощью человека не самое мудрое решение.
В рамках проекта требовалось решить две основные задачи: создать адресный справочник, который бы содержал все хорошие адреса и не содержал мусора, и разработать систему, которая бы позволила в online-режиме поддерживать адресный справочник в актуальном состоянии в периметре всего ИТ-ландшафта Ростелеком.
Упрощенно, процесс реализации проекта можно описать как последовательность следующих шагов:
Рассказывать о каждом из этих шагов можно долго, каждый из них был по-своему интересен, но в рамках данной статьи мы решили сосредоточиться на двух самых интересных, на наш взгляд, аспектах – формирование алгоритма разбора адресов и рождение архитектуры решения.
Для решения проблемы с адресами нужно было выработать однозначный и непротиворечивый алгоритм разбора адресов, который базировался бы как на единой эталонной адресной базе ФИАС, так и учитывал бы региональную специфику ведения адресных пространств в разных субъектах РФ.
Полностью автоматизировать данный алгоритм, используя известные методы Левенштейна и Яро-Винклера, не получалось. Поэтому вместе с автоматизированным способом разбора адресов был применен и разработанный алгоритм оценки фактических допустимых отклонений адресных строк от эталонных данных.
Но и этого оказалось недостаточно!
Для максимально точного сопоставления адресных данных пришлось анализировать данные систем техучёта. Таким образом был сформирован пул дополнительных совсем не адресных атрибутов, которые входили в итоговый алгоритм подтверждения качества разбора. Такими атрибутами были, например, геокоординаты и идентификаторы оборудования. Так, если один и тот же коммутатор был привязан к адресам, которые были идентифицированы, как потенциальные дубли – это был маркер, который позволял «схлопнуть» адреса в один эталонный адресный объект. Наличие таких дополнительных сведений позволило собрать наиболее полную базу данных по всем «угловым» домам, которая отражает всю специфику альтернативной адресации в Российской федерации.
Но несмотря на наличие большого количества дополнительных сведений: данные систем техучёта, списки возврата корреспонденции, кросс-связи между адресными справочниками систем по идентификаторам абонентов, в некоторых филиалах серая зона – перечень адресов, которые не могли быть однозначно идентифицированы – могла доходить до 10%.
А что же делать с серой зоной? Ведь в неё включались не только неправильно написанные адреса, но и так называемые «технологические адреса» – объекты недвижимости, где установлено оборудование и оказываются услуги, но они располагаются совсем не в черте городских массивов и, соответственно, не имеют адресов в традиционном понимании. Эта задача была выделена в отдельное направление и с использованием всех известных методов геоаналитики и смыслового анализа данных, такие объекты были также уникально идентифицированы и вошли в эталонный адресный справочник.
Создание эталонного адресного справочника было результатом титанических усилий, но итогом этой работы стало повышение точности определения технической возможности подключения по таким домам, а значит цель была достигнута.
Второй не менее сложный и интересный аспект проекта был связан с разработкой архитектуры решения.
Рождению итоговой архитектуры решения предшествовало две ошибочных гипотезы:
И та и другая гипотеза оказались провальными. Промышленное MDM-решение, имея все преимущества платформы управления справочниками, не могло похвастаться алгоритмами нормализации российских адресов, и умением работать с адресом, как с характеристикой объекта недвижимости. И так как наведение порядка в адресах являлось ключевой целью проекта, то это стало критическим недостатком, который перевесил все немалые преимущества мощной промышленной MDM платформы. Кроме того, в том решении не было отказоустойчивой интеграционной платформы, которая была бы способна в режиме реального времени обеспечить интеграцию с десятками узлов внутренней сети по различным интеграционным сценариям.
Второй подход к построению архитектуры адресного справочника был основан на идее построение MDM на базе движка по разбору и нормализации адресов. Это казалось логичным решением, так как узким местом предыдущего архитектурного подхода была именно функция поиска и сопоставления адресов, приведения их к эталонному виду и возможности поиска потенциальных дубликатов.
Тем не менее, архитектура продуктов по разбору и нормализации адресов ориентирована на скорость обработки массивов адресов, точность подбора похожих адресных строк, минимизацию обратной ошибки, – именно эти показатели являются ключевой ценностью продукта по нормализации адресов, которые зачастую используются при обработке списков адресов почтовой рассылки и в подобных задачах. Основной идеей данных решений является использование единого эталонного адресного справочника – ФИАС – и приведение получаемых на вход списков к эталону с рассчитанной вероятностью.
Задачи Ростелеком требовали создания собственного, непрерывно пополняемого эталонного справочника, который с одной стороны базируется на ФИАС, но при этом наличие или отсутствие адреса в ФИАС не является определяющим для признания адреса эталонным. И это было нерешаемой задачей для большинства систем автоматической нормализации адресов.
В итоге долгих поисков было найдено компромиссное решение с гибридной архитектурой – MDM-платформа собственной разработки, интегрированная с поисковым движком HumanFactorLabs. Выбор данного поставщика был определен их готовностью доработать механизм поиска адресов для использования, в качестве эталона, адресного справочника Ростелеком, и реализовать механизм регулярной синхронизации адресного справочника Ростелеком с ФИАС. Данная доработка позволила предоставить пользователям удобный и качественный поиск адресов по строке, а построение MDM решения на базе OpenSource продуктов обеспечила гибкость в подходах к интеграции с ИТ-ландшафтом Ростелекома. В периметре ИТ-ландшафта Ростелекома существуют legacy-системы, которые используются в бизнес-процессе, но не могут быть существенно доработаны по причине своих конструктивных ограничений. Уход от промышленного решения в сторону собственной разработки позволил максимально адаптировать MDM-платформу под особенности ИТ-среды, сохраняя при этом основную архитектурную концепцию неизменной.
С учетом специфики построения ИТ-ландшафта Ростелеком первое внедрение системы должно было происходить непосредственно в промышленном контуре ИТ-ландшафта макрорегиона. На промышленном контуре в опытную эксплуатацию внедрялись новые интеграции с ключевыми системами ИТ-ландшафта, что оказывало эффект на техническую реализацию всех бизнес-процессов ПАО «Ростелеком»: Продажи и подключение, Ввод новых объектов связи в эксплуатацию, Модернизация домовых распределительных сетей, Монтаж, Поддержка на 2 и 3 линии, Планирование строительства, Предоставление отчетности. Риском ошибки внедрения была полная блокировка работы информационных потоков между информационными системами макрорегиона, остановка всех бизнес процессов, падение продаж и репутационные риски.
Поэтому перед первым внедрением скрупулёзно выверялся каждый шаг, каждый адрес и запуск системы в эксплуатацию, требовал дежурства в режиме 24х7 в течении двух недель после старта.
В момент первого запуска казалось, что все сложности пройдены и дальше будет просто тиражирование. Но с учетом того, что каждый макрорегион – это в недавнем прошлом отдельная компания со своим специфическим ИТ-ландшафтом, то каждый «тираж» превращался в полноценное новое внедрение.
Модульная структура системы представлена на рисунке.
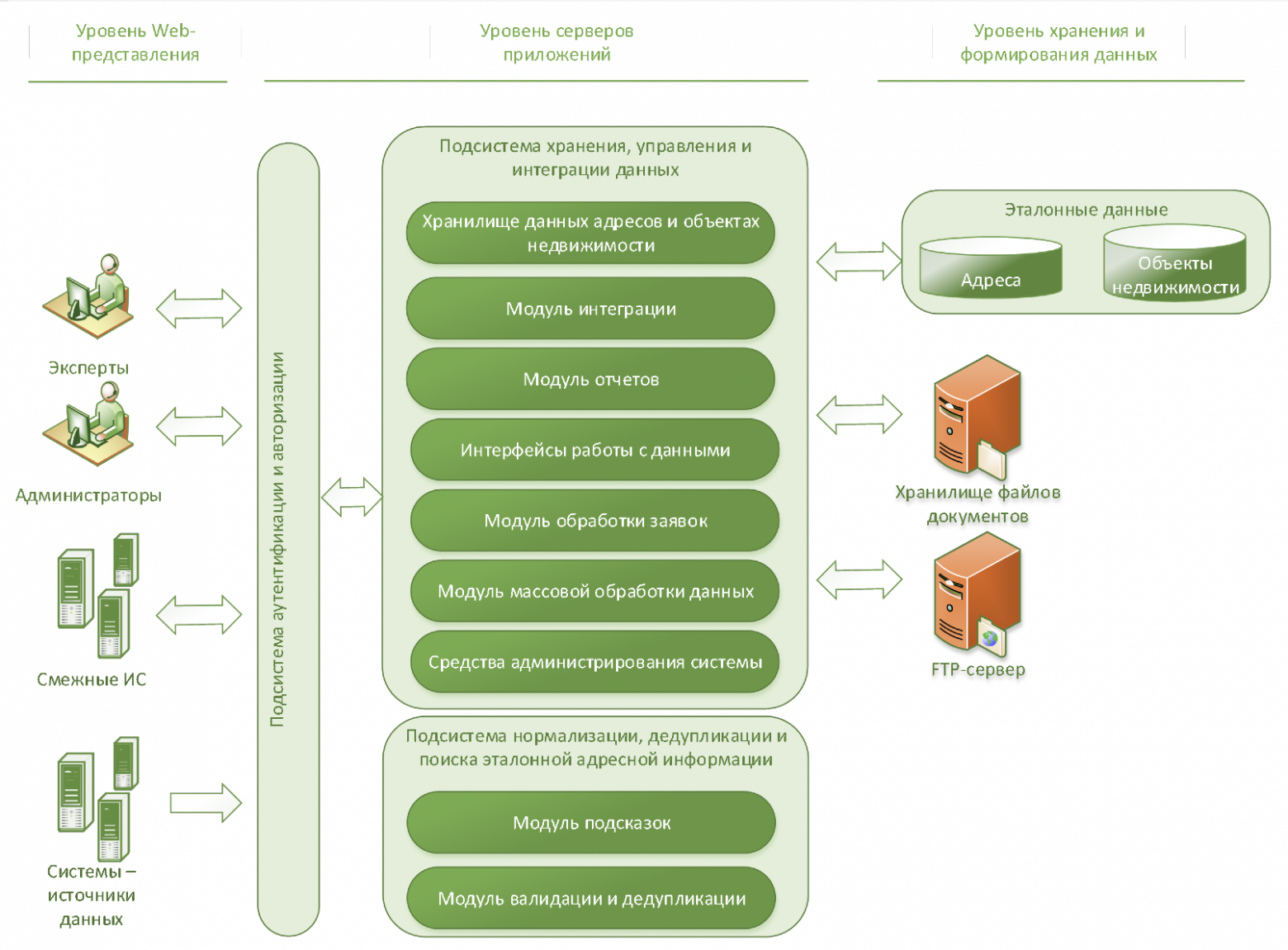
Кликабельно
Разработчики проекта занимаются не просто написанием кода, а являются полноценными творческими единицами: они принимают технические решения, предлагают идеи по дизайну интерфейса, удобству использования продукта. Любая новая функция обсуждается с разработчиками, учитывается их мнение и опыт. Любая задача оставляет разработчику пространство для творчества, поэтому любые маленькие удобства легко воплощаются в жизнь и не требуют подтверждения в куче инстанций.
В основе текущей проекта – технология Java EE и веб-сервер WildFly. Проект является монолитным, хотя сейчас как раз переживает планирование его «разделения» на отдельные микросервисы, потому что нагрузка на проект постепенно начинает достигать пика, и он требует нормального масштабирования.
Проект развивается довольно давно, и использует GWT на стороне фронтэнда. И, хоть это и тяжелая и устаревшая к 2019 году технология, она позволяет делать ряд вещей, которые не получится сделать на JavaScript-фреймворках: писать на Java и на клиенте, и на сервере, оперировать одними и теми же сущностями БД и там, и там, просто клонируя их через JpaCloner.
Никаких DTO и прочих перекладываний параметров из пустого в порожнее. Это позволяет делать полноценный продукт сравнительно небольшой командой программистов. Хотя хлопот эта технология доставляет не меньше: баги в Internet Explorer (а есть ведь и корпоративные стандарты ), огромное время компиляции, трудности с интеграцией с современными JavaScript-библиотеками. Поэтому в новой версии продукта планируется от этой технологии отказаться в пользу чего-то более современного.
В системе реализовано более 20 различных сценариев интеграции с системами-потребителями информации справочников ОРПОН.
Сценарии интеграции позволяют передавать как единичный адрес, так и массовый список адресов или адресных элементов. Система ОРПОН может инициировать передачу адреса и списка адресов самостоятельно, например, при вводе в систему нового адреса экспертом или при загрузке изменений ФИАС, или может выполнить данные действия в ответ на запрос смежной системы. Передача справочников, атрибутов объектов недвижимости – само собой, разумеется.
Самым необычным сценарием, наверное, можно считать сценарий контроля последовательности передачи адресов. В сложных бизнес-процессах подключения, которые проходят в режиме Online, очень важно контролировать – в какую из систем в первую очередь должен попасть адрес, чтобы избежать нарушения таких процессов. И эту задачу тоже нам нужно было решить с помощью типовых сценариев.
ОРПОН не является высоконагруженной системой реального времени – в каждой системе-потребителе адресных справочников есть своя копия эталонной системы, и для поиска адреса система обращается не к ОРПОН, а идет в свою собственную базу данных. В ОРПОН система-потребитель обращается, если запрашиваемый адрес не найден в локальном хранилище. Данное архитектурное решение позволило значительно снизить нагрузку на приложение и обеспечить заданные технические характеристики отклика и стабильности с использованием кластеров из двух серверов. Инфраструктурная схема компонентов системы приведена на рисунке ниже.
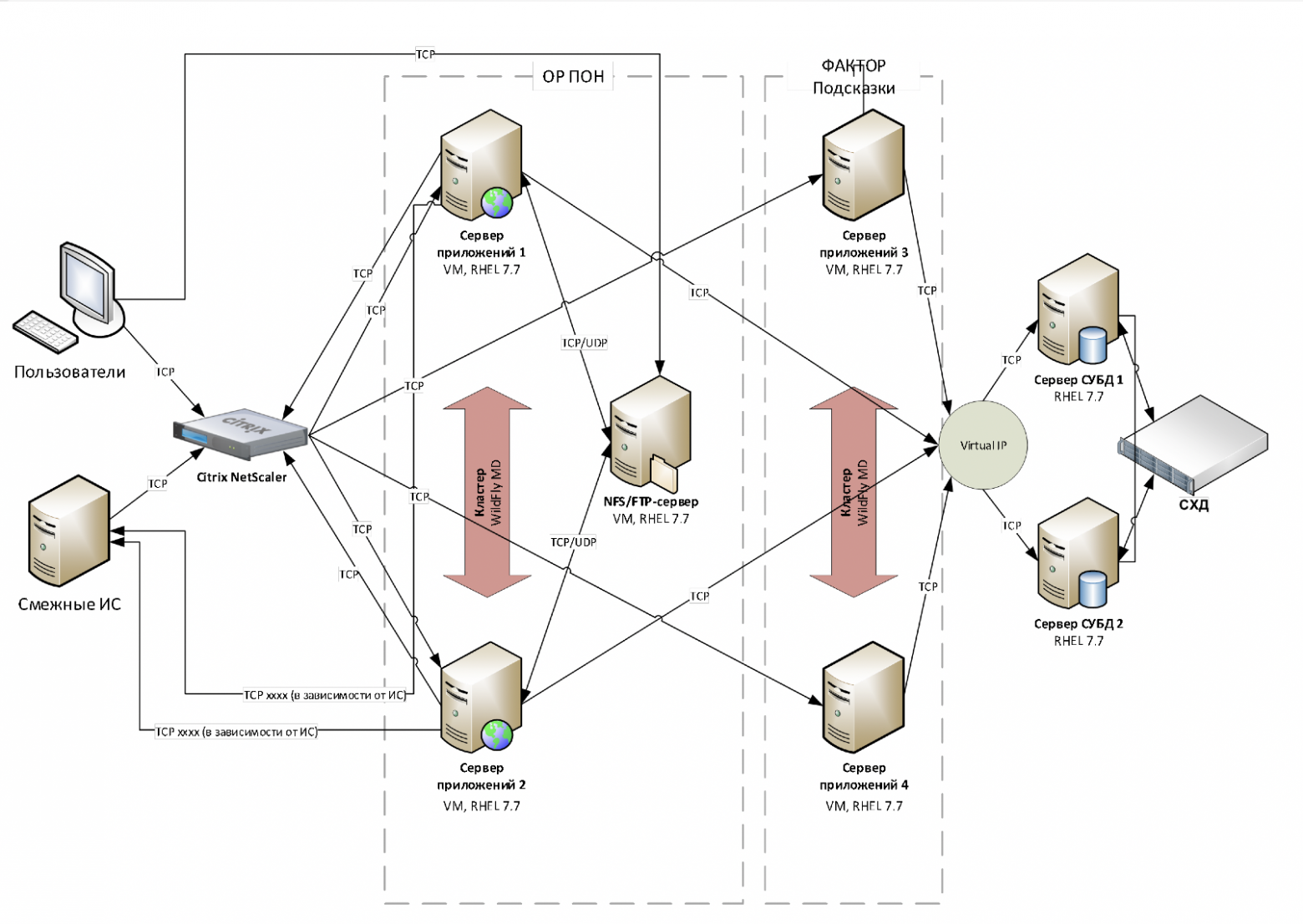
Кликабельно
Состав программных приложений каждого кластера выглядит следующим образом:
Зачастую сложно измерить эффект от внедрения информационных систем, многие изменения происходят сразу и нет однозначного ответа – был ли эффект, и если вдруг был, то что послужило причиной положительных или отрицательных последствий. Тем более, если ты поднимаешь инфраструктурный проект, который находится в самом сердце твоего ИТ-ландшафта.
Нам повезло, и в одном из макрорегионов мы смогли провести чистый эксперимент. За период времени происходило только одно изменение в организационных и ИТ процессах, и это было внедрение Единого адресного справочника – ОРПОН. Масштаб эффекта был колоссальный – количество положительных ответов на проверку технической возможности подключения выросло на 22% после внедрения системы. До внедрения в макрорегионе не было однозначной связи между адресом в системе, откуда идет запрос на техвозможность и системой техучёта, где возможность проверяется – какой адрес будет выбран, было лотереей. Кроме того, в СЛТУ было много дублей и оборудование, которое находилось в доме, могло быть случайным образом распределено по нескольким адресам, один из которых случайным образом выбирался для проверки техвозможности. Внедрение системы позволило снизить данную неопределенность до 0, и как следствие устранить потерю клиентов на этапе ввода заявки на сайте RT.RU из-за ошибок определения технической возможности предоставления услуги по адресу.
Когда мы получили данные результаты, мы не поверили своим глазам! Эти цифры превзошли самые смелые наши ожидания.
Статья подготовлена командой управления данными «Ростелеком»
Интернет, при всем своем цифровом имидже, штука, созданная в аналоговом мире. И до сих пор для того, чтобы в доме был высокоскоростной интернет, к дому должен быть физически подведён кабель.
Именно адрес дома является ключевым объектом идентификации в многоступенчатом процессе предоставления услуг Интернета.
Адрес возникает в момент, когда клиент звонит к нам в Ростелеком с вопросом, можно ли подключить интернет. Оператору нужно знать адрес клиента, чтобы проверить, проведён ли к дому кабель с интернетом. Адрес используется вплоть до этапа сопровождения и обслуживания действующего клиента. При обращении в службу технической поддержки по адресу клиента проверяется, является ли проблема локальной, или авария массовая и проблема затронула целый квартал.

И конечно, на каждом шаге процесса важна скорость ответа клиенту.
В этом посте мы расскажем о том, насколько важен для наших внутренних систем адрес клиента, почему ФИАС — не панацея, и для чего был создан Единый паспорт дома.
Чем быстрее клиент получит подтверждение возможности подключить интернет, тем выше вероятность, что он выберет именно Ростелеком. Рынок услуг интернета высококонкурентный и малейшая задержка с ответом на запрос клиента может снизить его лояльность и спровоцировать уход к другому, более оперативному оператору связи.
Упрощенно, бизнес-процесс прохождения заявки на подключение интернета выглядит следующим образом. Заявка от клиента попадает в систему – это может быть сайт или другая система, где можно вести заявки. Далее запрос отправляется в систему линейно-технического учета для проверки наличия технической возможности подключения клиента по его адресу. Если техническая возможность есть, то заявка передается в рабочую систему для монтажников, которые выполнят подключение клиента к интернету. После включения услуги на сети заявка уходит в биллинг, где производится расчёт стоимости услуг для абонента. Из биллинга формируются ежемесячные выгрузки для отправки счетов и претензионных писем должникам.
Все эти информационные системы разрабатывались и внедрялись ещё до объединения Ростелеком, и как правило, до того, как рынок интернета стал столь высококонкурентным.
Действующие информационные системы обеспечивали непрерывный процесс продаж и подключения услуг связи по стране, но при этом интеграция между ними осуществлялась в полуавтоматизированном режиме. Системы были слабо связаны между собой и не проектировались для взаимодействия в рамках единого информационного пространства. В каждой системе использовались свои адресные каталоги, справочники, принципы идентификации объектов.
Для эффективного взаимодействия всех систем в едином централизованном бизнес-процессе продаж и обслуживания клиентов компании Ростелеком необходимо было обеспечить общий «протокол» общения – систему классификации и идентификации адресных объектов. При этом отправной точкой должен быть именно объект недвижимости, который может иметь адрес, может его не иметь, может иметь альтернативную адресацию, но в любом случае должен быть определен однозначно.
Для этих целей был запущен проект — Единый паспорт дома (ОРПОН), который обеспечил переход от разрозненных, неполных, противоречивых источников данных к единому интегрированному адресному пространству, в котором взаимодействие между ИТ-системами всех филиалов Ростелекома происходит автоматически, без ручной обработки.
Как все было до единого адресного справочника? Почему не подходит ФИАС? Почему все сложнее, чем кажется?
Когда в компании возникает задача создания справочника, то всё кажется очень простым.
Во-первых, адрес — это что-то всем знакомое, каждый с этим сталкивается ежедневно, каждый знает, как писать адрес: как Бог на душу положит.
Во-вторых, после первых пятнадцати минут изучения вопроса в интернете вы узнаете, что адресный справочник на всю Россию уже создан в налоговой. И всё, что вам остается сделать – скачать базу ФИАС, загрузить в базу данных и адресный справочник готов. В некотором смысле, конечно, всё так и есть.
Существует федеральная информационная адресная система, в ней существуют адреса, они регулярно обновляются, и ФНС регулярно выкладывает обновления. Для многих задач этот справочник подходит, например, для задач ФНС.
Но проблемы Ростелекома ФИАС решить не мог. В адресных справочниках Ростелекома адресов значительно больше, чем в адресном справочнике налоговой, и Ростелеком узнает о строительстве нового дома в среднем на несколько лет раньше, чем этот дом появится в справочнике ФИАС. И Ростелекому важно знать не только про адреса, а однозначно связать адрес с объектом недвижимости, и определить все значимые характеристики этого объекта: год постройки, материал стен, назначение и 90 других очень важных параметров.
Но самая главная проблемы была в том, что на момент старта проекта в Ростелекоме существовало не менее 40 активно используемых систем, в каждой из которых был свой адресный справочник, была своя база с адресами, сопоставление которой с ФИАС давало на выходе около 60% совпадающих адресов и 40% адресов, о которых налоговая ничего не знает.
Определить эти 40% адресов как «мусор» было нельзя, потому что на них располагалось примерно столько же процентов абонентской базы, и отказ от адресов означает отказ и от абонентов тоже. По каждому адресу из отсева нужно было понимать: существует ли такой адрес и является ли данный адрес независимым, или является дублем другого адреса? Или может быть это угловой дом, и мы имеем дело с альтернативной адресацией?
Нужно было придумать решение, которое позволило бы связать между собой не менее 95% адресов. То есть для 35% адресов из тех, которые не сошлись с ФИАС, нужно было придумать алгоритм, который позволит принимать решения по ним. Это нужно было делать автоматически. Для того, чтобы обработать вручную около 40% адресной базы Ростелекома, понадобилось бы около 120 человеколет. Да и устранять проблему человеческого фактора с помощью человека не самое мудрое решение.
Как мы всё это делали и почему так долго
В рамках проекта требовалось решить две основные задачи: создать адресный справочник, который бы содержал все хорошие адреса и не содержал мусора, и разработать систему, которая бы позволила в online-режиме поддерживать адресный справочник в актуальном состоянии в периметре всего ИТ-ландшафта Ростелеком.
Упрощенно, процесс реализации проекта можно описать как последовательность следующих шагов:
- Провести аудит всех систем, которые используют адреса в своих бизнес-процессах. То есть, провести аудит всего ИТ-ландшафта Ростелекома.
- Определить сценарий внедрения и сценарии интеграции эталонного адресного справочника в каждом макрорегионе.
- Исходя из определенных сценариев внедрения и сценариев интеграции разработать программный комплекс.
- Выгрузить адресные справочники из всех систем в периметре интеграции, создать на основе этих данных эталонный адресный справочник и мэппинг локальных адресов на эталонные.
- Произвести разработку эталонного справочника объектов недвижимости и связать эталонные адреса с объектами недвижимости связью многие-ко-многим
- Произвести интеграцию с каждой информационной системой
- Разработать процесс ведения адресов и обучить экспертов
- Нажать большую красную кнопку «Пуск» и растиражировать решение на все 7 макрорегионов Ростелеком.
Рассказывать о каждом из этих шагов можно долго, каждый из них был по-своему интересен, но в рамках данной статьи мы решили сосредоточиться на двух самых интересных, на наш взгляд, аспектах – формирование алгоритма разбора адресов и рождение архитектуры решения.
Для решения проблемы с адресами нужно было выработать однозначный и непротиворечивый алгоритм разбора адресов, который базировался бы как на единой эталонной адресной базе ФИАС, так и учитывал бы региональную специфику ведения адресных пространств в разных субъектах РФ.
Полностью автоматизировать данный алгоритм, используя известные методы Левенштейна и Яро-Винклера, не получалось. Поэтому вместе с автоматизированным способом разбора адресов был применен и разработанный алгоритм оценки фактических допустимых отклонений адресных строк от эталонных данных.
Но и этого оказалось недостаточно!
Для максимально точного сопоставления адресных данных пришлось анализировать данные систем техучёта. Таким образом был сформирован пул дополнительных совсем не адресных атрибутов, которые входили в итоговый алгоритм подтверждения качества разбора. Такими атрибутами были, например, геокоординаты и идентификаторы оборудования. Так, если один и тот же коммутатор был привязан к адресам, которые были идентифицированы, как потенциальные дубли – это был маркер, который позволял «схлопнуть» адреса в один эталонный адресный объект. Наличие таких дополнительных сведений позволило собрать наиболее полную базу данных по всем «угловым» домам, которая отражает всю специфику альтернативной адресации в Российской федерации.
Но несмотря на наличие большого количества дополнительных сведений: данные систем техучёта, списки возврата корреспонденции, кросс-связи между адресными справочниками систем по идентификаторам абонентов, в некоторых филиалах серая зона – перечень адресов, которые не могли быть однозначно идентифицированы – могла доходить до 10%.
А что же делать с серой зоной? Ведь в неё включались не только неправильно написанные адреса, но и так называемые «технологические адреса» – объекты недвижимости, где установлено оборудование и оказываются услуги, но они располагаются совсем не в черте городских массивов и, соответственно, не имеют адресов в традиционном понимании. Эта задача была выделена в отдельное направление и с использованием всех известных методов геоаналитики и смыслового анализа данных, такие объекты были также уникально идентифицированы и вошли в эталонный адресный справочник.
Создание эталонного адресного справочника было результатом титанических усилий, но итогом этой работы стало повышение точности определения технической возможности подключения по таким домам, а значит цель была достигнута.
Второй не менее сложный и интересный аспект проекта был связан с разработкой архитектуры решения.
Рождению итоговой архитектуры решения предшествовало две ошибочных гипотезы:
- адресный справочник Ростелекома можно построить на базе промышленной MDM платформы.
- адресный справочник Ростелекома можно построить на базе промышленной платформы разбора и нормализации адресов.
И та и другая гипотеза оказались провальными. Промышленное MDM-решение, имея все преимущества платформы управления справочниками, не могло похвастаться алгоритмами нормализации российских адресов, и умением работать с адресом, как с характеристикой объекта недвижимости. И так как наведение порядка в адресах являлось ключевой целью проекта, то это стало критическим недостатком, который перевесил все немалые преимущества мощной промышленной MDM платформы. Кроме того, в том решении не было отказоустойчивой интеграционной платформы, которая была бы способна в режиме реального времени обеспечить интеграцию с десятками узлов внутренней сети по различным интеграционным сценариям.
Второй подход к построению архитектуры адресного справочника был основан на идее построение MDM на базе движка по разбору и нормализации адресов. Это казалось логичным решением, так как узким местом предыдущего архитектурного подхода была именно функция поиска и сопоставления адресов, приведения их к эталонному виду и возможности поиска потенциальных дубликатов.
Тем не менее, архитектура продуктов по разбору и нормализации адресов ориентирована на скорость обработки массивов адресов, точность подбора похожих адресных строк, минимизацию обратной ошибки, – именно эти показатели являются ключевой ценностью продукта по нормализации адресов, которые зачастую используются при обработке списков адресов почтовой рассылки и в подобных задачах. Основной идеей данных решений является использование единого эталонного адресного справочника – ФИАС – и приведение получаемых на вход списков к эталону с рассчитанной вероятностью.
Задачи Ростелеком требовали создания собственного, непрерывно пополняемого эталонного справочника, который с одной стороны базируется на ФИАС, но при этом наличие или отсутствие адреса в ФИАС не является определяющим для признания адреса эталонным. И это было нерешаемой задачей для большинства систем автоматической нормализации адресов.
В итоге долгих поисков было найдено компромиссное решение с гибридной архитектурой – MDM-платформа собственной разработки, интегрированная с поисковым движком HumanFactorLabs. Выбор данного поставщика был определен их готовностью доработать механизм поиска адресов для использования, в качестве эталона, адресного справочника Ростелеком, и реализовать механизм регулярной синхронизации адресного справочника Ростелеком с ФИАС. Данная доработка позволила предоставить пользователям удобный и качественный поиск адресов по строке, а построение MDM решения на базе OpenSource продуктов обеспечила гибкость в подходах к интеграции с ИТ-ландшафтом Ростелекома. В периметре ИТ-ландшафта Ростелекома существуют legacy-системы, которые используются в бизнес-процессе, но не могут быть существенно доработаны по причине своих конструктивных ограничений. Уход от промышленного решения в сторону собственной разработки позволил максимально адаптировать MDM-платформу под особенности ИТ-среды, сохраняя при этом основную архитектурную концепцию неизменной.
Почему так сложно?
С учетом специфики построения ИТ-ландшафта Ростелеком первое внедрение системы должно было происходить непосредственно в промышленном контуре ИТ-ландшафта макрорегиона. На промышленном контуре в опытную эксплуатацию внедрялись новые интеграции с ключевыми системами ИТ-ландшафта, что оказывало эффект на техническую реализацию всех бизнес-процессов ПАО «Ростелеком»: Продажи и подключение, Ввод новых объектов связи в эксплуатацию, Модернизация домовых распределительных сетей, Монтаж, Поддержка на 2 и 3 линии, Планирование строительства, Предоставление отчетности. Риском ошибки внедрения была полная блокировка работы информационных потоков между информационными системами макрорегиона, остановка всех бизнес процессов, падение продаж и репутационные риски.
Поэтому перед первым внедрением скрупулёзно выверялся каждый шаг, каждый адрес и запуск системы в эксплуатацию, требовал дежурства в режиме 24х7 в течении двух недель после старта.
В момент первого запуска казалось, что все сложности пройдены и дальше будет просто тиражирование. Но с учетом того, что каждый макрорегион – это в недавнем прошлом отдельная компания со своим специфическим ИТ-ландшафтом, то каждый «тираж» превращался в полноценное новое внедрение.
Использованные технологии и инструменты
Модульная структура системы представлена на рисунке.

Кликабельно
О техпроцессе
Разработчики проекта занимаются не просто написанием кода, а являются полноценными творческими единицами: они принимают технические решения, предлагают идеи по дизайну интерфейса, удобству использования продукта. Любая новая функция обсуждается с разработчиками, учитывается их мнение и опыт. Любая задача оставляет разработчику пространство для творчества, поэтому любые маленькие удобства легко воплощаются в жизнь и не требуют подтверждения в куче инстанций.
О бэкэнде
В основе текущей проекта – технология Java EE и веб-сервер WildFly. Проект является монолитным, хотя сейчас как раз переживает планирование его «разделения» на отдельные микросервисы, потому что нагрузка на проект постепенно начинает достигать пика, и он требует нормального масштабирования.
О фронтэнде
Проект развивается довольно давно, и использует GWT на стороне фронтэнда. И, хоть это и тяжелая и устаревшая к 2019 году технология, она позволяет делать ряд вещей, которые не получится сделать на JavaScript-фреймворках: писать на Java и на клиенте, и на сервере, оперировать одними и теми же сущностями БД и там, и там, просто клонируя их через JpaCloner.
Никаких DTO и прочих перекладываний параметров из пустого в порожнее. Это позволяет делать полноценный продукт сравнительно небольшой командой программистов. Хотя хлопот эта технология доставляет не меньше: баги в Internet Explorer (а есть ведь и корпоративные стандарты ), огромное время компиляции, трудности с интеграцией с современными JavaScript-библиотеками. Поэтому в новой версии продукта планируется от этой технологии отказаться в пользу чего-то более современного.
О сценариях интеграции
В системе реализовано более 20 различных сценариев интеграции с системами-потребителями информации справочников ОРПОН.
Сценарии интеграции позволяют передавать как единичный адрес, так и массовый список адресов или адресных элементов. Система ОРПОН может инициировать передачу адреса и списка адресов самостоятельно, например, при вводе в систему нового адреса экспертом или при загрузке изменений ФИАС, или может выполнить данные действия в ответ на запрос смежной системы. Передача справочников, атрибутов объектов недвижимости – само собой, разумеется.
Самым необычным сценарием, наверное, можно считать сценарий контроля последовательности передачи адресов. В сложных бизнес-процессах подключения, которые проходят в режиме Online, очень важно контролировать – в какую из систем в первую очередь должен попасть адрес, чтобы избежать нарушения таких процессов. И эту задачу тоже нам нужно было решить с помощью типовых сценариев.
Об инфраструктуре
ОРПОН не является высоконагруженной системой реального времени – в каждой системе-потребителе адресных справочников есть своя копия эталонной системы, и для поиска адреса система обращается не к ОРПОН, а идет в свою собственную базу данных. В ОРПОН система-потребитель обращается, если запрашиваемый адрес не найден в локальном хранилище. Данное архитектурное решение позволило значительно снизить нагрузку на приложение и обеспечить заданные технические характеристики отклика и стабильности с использованием кластеров из двух серверов. Инфраструктурная схема компонентов системы приведена на рисунке ниже.
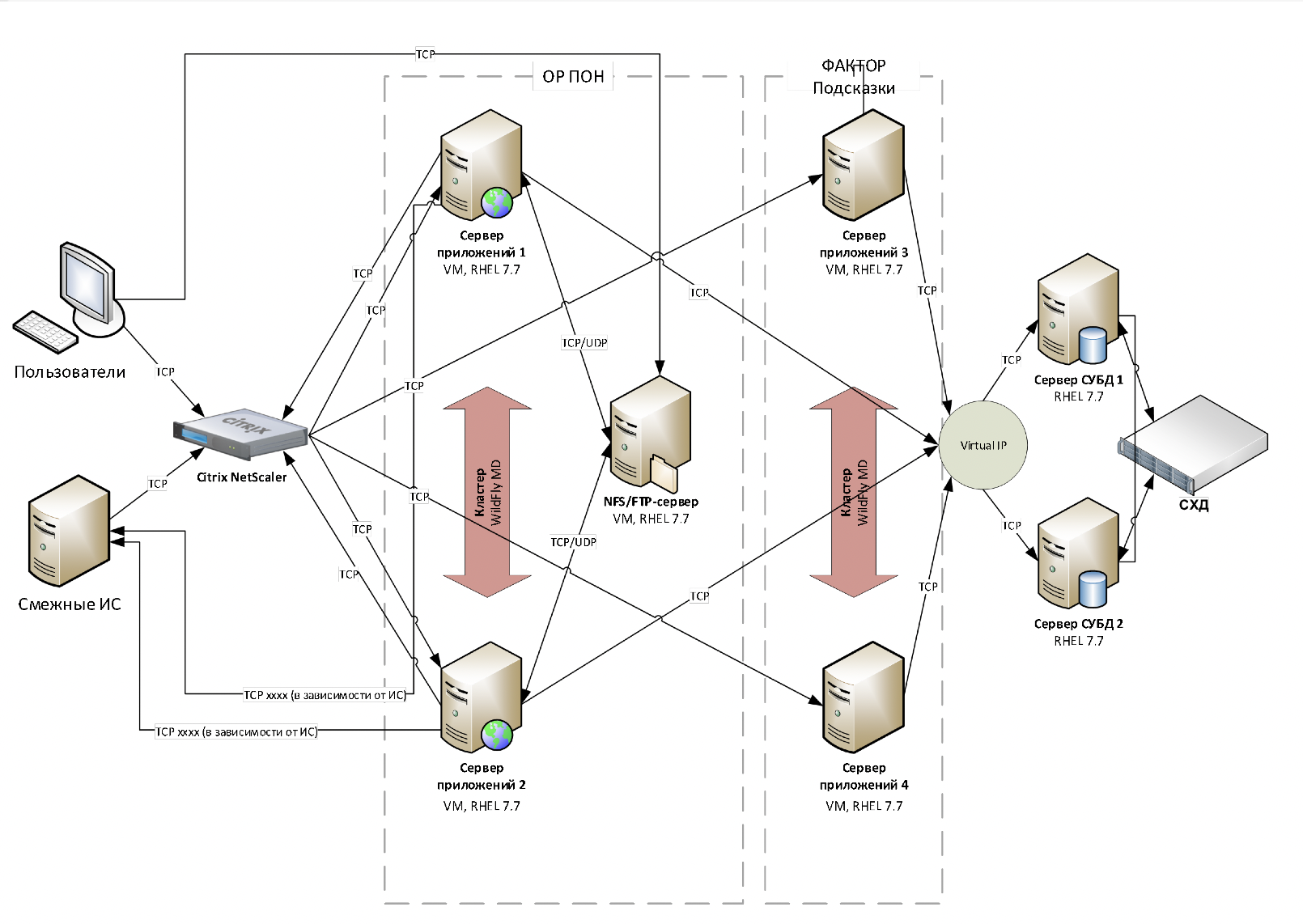
Кликабельно
Состав программных приложений каждого кластера выглядит следующим образом:
- Кластер СУБД PostgreSQL
- RedHat Enterprise Linux 7.7 (64-bit)
- PostgreSQL Server 11.4 (64-bit)
- ClusterLabs Pacemaker|Corosync
- Кластер серверов приложений
- RedHat Enterprise Linux 7.7 (64-bit)
- WildFly Application Server 17 (64-bit)
- ПО Citrix Balancer
- ПО ОР ПОН
- Кластер платформы подсказок и ПО Фактор
- WildFly Application Server 17 (64-bit)
- ПО Citrix Balancer
- Программный продукт ФАКТОР
- Программный продукт «Подсказки»
Что нам это дало
Зачастую сложно измерить эффект от внедрения информационных систем, многие изменения происходят сразу и нет однозначного ответа – был ли эффект, и если вдруг был, то что послужило причиной положительных или отрицательных последствий. Тем более, если ты поднимаешь инфраструктурный проект, который находится в самом сердце твоего ИТ-ландшафта.
Нам повезло, и в одном из макрорегионов мы смогли провести чистый эксперимент. За период времени происходило только одно изменение в организационных и ИТ процессах, и это было внедрение Единого адресного справочника – ОРПОН. Масштаб эффекта был колоссальный – количество положительных ответов на проверку технической возможности подключения выросло на 22% после внедрения системы. До внедрения в макрорегионе не было однозначной связи между адресом в системе, откуда идет запрос на техвозможность и системой техучёта, где возможность проверяется – какой адрес будет выбран, было лотереей. Кроме того, в СЛТУ было много дублей и оборудование, которое находилось в доме, могло быть случайным образом распределено по нескольким адресам, один из которых случайным образом выбирался для проверки техвозможности. Внедрение системы позволило снизить данную неопределенность до 0, и как следствие устранить потерю клиентов на этапе ввода заявки на сайте RT.RU из-за ошибок определения технической возможности предоставления услуги по адресу.
Когда мы получили данные результаты, мы не поверили своим глазам! Эти цифры превзошли самые смелые наши ожидания.
Статья подготовлена командой управления данными «Ростелеком»
