Comments 61
позволил нам уже более четырех лет поддерживать высокий темп разработки, легко вводить в работу новых разработчиков и не замедляться с течением времени
и
с таким подходом Code Review проходит дольше обычного. Даже маленькие задачки могут задержаться на несколько дней
чёт какой то диссонанс у меня вызывают эти два предложения.
Так же в начале была озвучена например проблема легаси кода, но как ее решает конвенция непонятно, собственно никак.
чёт какой то диссонанс у меня вызывают эти два предложения.
Я понимаю, почему это вызывает удивление, но на самом деле всё объяснимо. Когда весь код написан по строгим стандартам, то разработка задачи занимает всегда понятное и предсказуемое время. Например, написание кода для условной задачи может занять неделю, а прохождение PR пару дней. Если же код не придерживается никаким правилам, то PR может пройдёт за пару часов, вот только разработка может занять 2 недели или дольше. В итоге PR проходит дольше, но «Time-To-Market» у задач намного меньше.
Так же в начале была озвучена например проблема легаси кода, но как ее решает конвенция непонятно, собственно никак.
Обычно слово «legacy» несет негативную окраску и по сути означает «дурно пахнущий код». По крайней мере в статье оно применено именно в таком смысле. Четкие правила и стандарты помогают, если не избавиться полностью, то свести к минимуму процент такого кода.
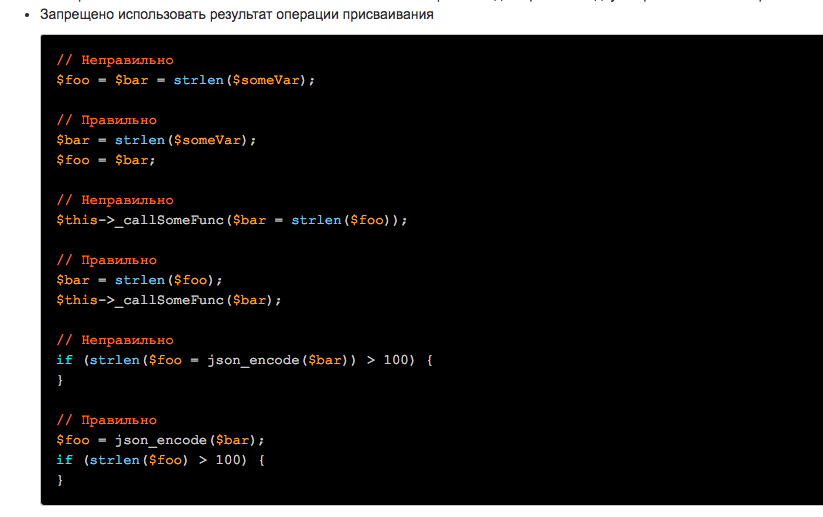
Нельзя изменять переменные, которые передаются в метод на вход
Судя по примерам может быть ситуация когда эти рекомендации… не согласуются друг с другом.
Как разруливаются такие случаи?
function loadUsers(array $ids) {
$usersIds = $ids;
// ...
unset($usersIds[0]);
// ...
}
Возможно что-то вроде этого.
Конкретно это можно реализовать через array_filter, но все-таки.
Все правила логичны и разумны, но их стоит применять обоснованно. И, в некоторых случае, как тут вполне можно использовать unset
В ином случае не вижу необходимости в потере производительности и дополнительному расходу памяти.
Выгоднее подобное делать как раз таки как исключение там где критичны такие нюансы (полагаю что 1 случай на 1000). А в подавляющем большинстве случаев лучше делать копию массива, работать с имутабельными структурами и т.д.
В случае работы с небольшим данными лучше использовать иммутабельные структуры. Если работаешь с массивом в несколько миллионов UUID, то лучше использовать мутабельные, но аккуратно, поскольку накралдные расходы на копирование такого массива перевесят все плюсы от иммутибельности.
Можно развернуть причины такой рекомендации?
В большом проекте очень много классов с одинаковыми названиями, но с разными неймспейсами. Если разработчик в коде видит условное new User(), то он не может точно быть уверен, что за User тут имеется в виду. Может Service\Repository\User. Или Entity\User. Разработчику приходится переходить к началу файла и обратно. Это затрудняет чтение кода. Гораздо удобнее читать new Entity\User().
При этом подключение неймспейса через use вместо класса не добавляет никаких сложностей и абсолютно бесплатно. Даже наоборот — меньше мусорного кода вначале файла. То есть мы «забесплатно» можем упростить человеку понимание кода. Не вижу причин не сделать этого.
Видишь ли ты какие-то причины подключать именно класс и прятать неймспейс?
А в вопросе говориться про разные классы в одном неймспейсе
use Entity\User;
use Entity\Project;
$user = new User();
$project = new Project();
Модель — простой объект со свойствами, не содержащий бизнес-логики
Должен стремиться к соблюдению принципов GRASP, ...
Так как ваши модели полностью нарушают первый и базовый принцип — Information Expert, а логика в вынесенная в сервисы приводи к увеличению Coupling и уменьшению Cohesion.
Но как раз для таких случаев у нас не только написано требование соблюдения GRASP, а есть подробные правила. Они расшифровывают этот и другие принципы и описывают, как их понимаем мы. В итоге документ создает единый стандарт. И добавлю, что на какую-то абсолютную истину мы не претендуем. Просто делимся опытом.)
с моей точки зрения именно такой подход соблюдает GRASP
Очень сильно зависит от того как используется "модель". Если эти тупые структуры данных используются внутри оболочки какой-то, то в целом я склонен с вами согласится (хотя эта оболочка и будет в этом случае являться моделью, хотя слово вообще бесполезное).
Но обычно оно используется в сервисах-менеджерах, которые имеют зависимость не только от "моделек" но еще и от репозиториев и прочих гейтвеях предоставляющих доступ к данным.
Собственно очень простой способ убедиться есть проблема или ее нет — вглянуть на юнит тесты бизнес логики (и убедиться что они именно юнит а не интеграционные).
class RestrictionService
{
//...
public function blockUser(int $id, string $reason): void
{
$user = $this->repository->get($id);
if ($user->isBlocked) {
throw new UserWasAlreadyBlockedException();
}
$user->isBlocked = true;
$user->blockedAt = \new DateTime();
//more magic ...
$user->reason = $reason;
$user->blockedCounter++;
}
}
лучше чем:
$user->block($reason);
class User
{
public function block(string $reason): void
{
if ($this->isBlocked) {
throw new UserWasAlreadyBlockedException();
}
$this->isBlocked = true;
$this->blockedAt = \new DateTime();
//more magic ...
$this->reason = $reason;
$this->blockedCounter++;
}
}
+ второго подхода:
- Не нарушается инкапсуляция, в первом случае кто-то может заблокировать пользователя в обход сервиса, или же написать отдельную «похожую» логику в другом месте и при след изменениях вы получите баг, что где-то блокировка работает не так, а во втором вы четко контролируете процесс изменения состояния блокировок через определенное поведение.
- Мне, как новому разработчику, проще разобраться, так как контракт описан в одном месте и не размазан по cервисам всего проекта.
- Проще писать юнит тесты. Я надеюсь вы их пишете. У меня когда-то был проект, где в тестах мокали с десяток сервисов — не самое лучше занятие разгребать dependency hell, где один сервис вызывает другой, а тот третий и пятый, и так далее.
- Первый подход больше близок к процедурному, нежели к объектному ориентированному — вы можете спокойно заменить ваши модели на массивы, а сервисы на функции (процедуры).
В наших проектах мы пишем логику и там и там, мы пишем юнит тесты на наши сущности и на сервисы, и стараемся последних писать как можно меньше и использовать больше для оркестрации действий.
В этой части рекомендации содержат противоречие. С одной стороны рекомендуется следовать GRASP, а это как вы сделали — нет вопросов, всё понятно и логично, а с другой стороны требуется чтобы в моделях не было логики, что явно противоречит GRASP. Как ни крути.
В целом есть ощущение что наши уважаемые коллеги поспешили с публикацией черновика своих Code Conventions.
требуется чтобы в моделях не было логики, что явно противоречит GRASP. Как ни крути.
Явно противоречит… Как ни крути… Я так понимаю тут уже всё понятно и мне нет смысла пытаться объяснять, что каждый может интерпретировать слова Ответственность должна быть назначена тому, кто владеет максимумом необходимой информации для исполнения совершенно по-разному?
Интерпретация по ссылке мне понятна, я понимаю как рассуждает автор, но мне она не близка. Я не настолько экспертен, чтобы говорить, что моя позиция единственно правильная «как ни крути», но всё же приведу ее ниже.
Модель является экспертом только в своих данных и манипуляциями с ними должна заниматься только она. Однако модель не является экспертом в других областях: она не может вызывать чужую бизнес-логику и даже не является экспертом в том, как сохранять себя в базу данных. То есть модель содержит сеттеры, которые правильно изменяют ее состояние. Но эти сеттеры не сохраняют модель в бд, они не вызывают цепочку зависимых сервисов и т.п. Чтобы сохранить модель в бд, не требуется никаких особых знаний. Грубо говоря, все модели сохраняются одинаково. Это довольно абстрактные вещи, чтобы их вот так объяснить в комментарии, но основная суть моей позиции должна быть понятна.
В целом есть ощущение что наши уважаемые коллеги поспешили с публикацией черновика своих Code Conventions.
Спасибо за критику. Для нас каждый отзыв важен.
Вы или ваш коллега прямо пишет что "y объектов с данными не может быть практически ничего кроме геттеров". Эта фраза исключает какую-либо другую интерпретацию кроме полного отказа от шаблона Information expert, который является частью GRASP. Вопросы?
Вы или ваш коллега прямо пишет что «y объектов с данными не может быть практически ничего кроме геттеров».
По приведенной ссылке общение идёт вообще по другому вопросу (там речь о том, что нужно опускать слово get у геттеров). В коде «$user->registrationDate()» метод «registrationDate()» не может быть ничем иным, кроме как геттером. То есть фраза вырвана из контекста.
Но в любом случае спасибо за отзыв. Это всегда полезно.
В самом документе говорится то же самое:
Модель — простой объект со свойствами, не содержащий бизнес-логики.
Эта требование исключает какую-либо другую интерпретацию кроме полного отказа от шаблона Information expert, который является частью GRASP.
что каждый может интерпретировать слова… совершенно по-разному?
То есть берем любой принцип и крутим и вертим им как хотим? Нет, это так не работает.
Суть Information expert в том что бы повысить кохижен и снизить каплинг. Если вы сможете мне продемонстрировать вариант при котором все согласно вашему кодстайлу и при этом все согласуется GRASP, было бы славно. И да, такой вариант более чем возможен, просто встречается в природе крайне редко.
она не может вызывать чужую бизнес-логику
потому выделяют application layer который этим заведует.
Но эти сеттеры не сохраняют модель в бд
а это тут причем?
Грубо говоря, все модели сохраняются одинаково.
Я потерял нить… вопервых они не всегда сохраняются одинаково. Во вторых, как вы выше отметили за сохранение отвечают всякие там репозитории, тэйбл гейтвеи и прочие штуки. А потому в контексте "где должна быть бизнес логика" это вообще пустой разговор.
Это довольно абстрактные вещи, чтобы их вот так объяснить в комментарии
предоставьте пример какой-либо простой фичи. Ну или сами предложите какой-либо юзкейс на котором мы сможем разобрать вопрос, а я реализую его в различных вариантах и подходах.
Хочу уточнить, как я понял, Вы считаете, что такой подход:… лучше чем: ...
Не совсем.
Во втором подходе в объекте User метод block() не содержит никакой другой логики, кроме как управления внутренним состоянием объекта. Для нас сеттеры и геттеры — это не обязательно отдать какое-то одно свойство или записать его, не делая никаких других операций с другими свойствами. Геттеры могут получать любые данные из внутреннего состояния объекта, а сеттеры — делать любые нужные манипуляции с ним. Это вскользь упоминается в Code Conv, но возможно стоит как-то более явно это написать. То есть второй вариант не нарушает нашего правила разделения логики.
Но, если мы во втором подходе вместо «more magic» добавим зависимость от каких-то внешних компонентов и внешней бизнес-логики, то это перестанет быть простым сеттером и станет тоже полноценной бизнес-логикой проекта. И тогда для нас это будет уже смешением данных и логики и нарушением Code Conv.
в первом случае кто-то может заблокировать пользователя в обход сервиса, или же написать отдельную «похожую» логику в другом месте
Я не очень понял. Никто не мешает человеку написать свой метод или вызывать изменение параметров напрямую в обход метода как в первом варианте, так и во втором. Это уже вопрос подхода. Если у вас логика лежит с данными, то люди ищут метод там. Если логика лежит в сервисах, то люди ищут метод в них. Когда человек захочет добавить новый метод, он попадет в то место, где уже кто-то добавил метод и не станет добавлять свой дублирующий. Главное, чтобы это место всегда было чётко определено.
В обоих кейсах на самом деле есть проблема и неполноценное следование тому же GRASP. Например, во втором кейсе логика блокировки полностью завязана на объект User, в который эту логику вставили. То есть я не могу создать свой объект MyUser и воспользоваться существующей логикой. Логика строго превязана к конкретному объекту вместо того, чтобы работать с нужным ей интерфейсом и не требовать конкретной реализации. То есть данный код страдает «high coupling» из GRASP. В том числе это за собой тянет нарушение SRP и других принципов.
И тогда для нас это будет уже смешением данных и логики и нарушением Code Conv.
то есть проблема в терминологии… вы сеттером называется практически любой метод изменяющий стэйт объекта. Я правильно понимаю?
Логика строго превязана к конкретному объекту вместо того, чтобы работать с нужным ей интерфейсом и не требовать конкретной реализации.
А вот тут есть простор для интерпритации принципов, в силу того что на них влияют ограничения вашего языка программирования. По сути это ограничение классовой модели объектов. Если бы рассматривали язык который наследует объектную модель не от simula а что-то более "объектно ориентированное", то там все уже будет чуть по другому.
Если я вас правильно понял, то вы хотите иметь возможность подменять поведение вокруг одной и той же модели данных. Так?
То есть данный код страдает «high coupling» из GRASP.
нет, так как это один модуль. Внутри модуля высокая связанность между элементами модуля это нормально. Это про ту часть которая high cohesion.
В том числе это за собой тянет нарушение SRP и других принципов.
все упирается в то как вы дробите логику. Если мы возьмем скажем все что связано с юзером и запихнем это в одну сущность мы действительно можем получить нарушение SRP и т.д. но логика внутри сущности может вообще не пересекаться и может быть разделена на отдельные объекты.
Как правильно организовать архитектуру с соблюдением принципов ООП?
Сложный вопрос, в силу того что "правильно" не бывает. Бывает компромис между "гибко" и "просто".
То есть вместо одного универсального подхода, который решает все проблемы, можно рассмотреть десяток различных вариантов с рассморением их плюсов и минусов.
Еще важный момент, это учет ограничений инфраструктуры, которые накладывают свой отпечаток на то, как с кодом работать. Ну и не стоит забывать немаловажный факт, что существуют ограничения языка, которые не позволяют удобно соблюдать многие "ООП Принципы".
Если примитинельно к примеру выше, где мы блокируем юзера и мы должны отправить ему email об этом, то довольно удобный вариант был бы воспользоваться событиями.
public function block(string $reason): void
{
// ...
$this->recordThat(UserWasBlockedEvent::occurred($this->id));
}Это событие пойдет на обработку только после того, как транзакция будет закоммичена и "события" эти превратятся в факты.
По вашему примеру, что будет в методе
recordThat()? Он будет внешнюю зависимость дергать, или там будет запись в публичную переменную, которую потом кто-то прочитает, или еще как-то?Действие «создать пользователя» вряд ли должно быть в классе, обозначающем пользователя.
именно, по хорошему для того что бы создать один объект нам всегда будет нужен другой объект.
Значит оно будет где-то в сервисе.
не обязательно. Это может быть и другая "моделька". Тут можно воспользоваться и просто более глубоким анализом предметной области в духе "а откуда у нас пользователи приходят?" в плодь до pure fabrication из grasp. Да и чем сервис отличается принципиально от "модельки"? Ну то есть с точки зрения клиентского кода.
Значит можно и обновление туда же поместить.
можно много чего сделать, вопрос зачем.
Туда же можно пробросить компонент, отвечающий за уведомления
А потом, что бы быть уверенным в том что email о регистрации уйдет уже после того как мы сохраним данные в базе, запихнем туда еще что-то что позволит нам эту самую транзакцию в базе закоммитить. И вот мы уже "выжали" логику из объектов в "одно место", полностью забили на разделение ответственности и повысили связанность (просто посчитайте afferent/efferent coupling методов вашей системы, пускай я и не очень люблю оперироваться на метрики при проектировании).
Тут следует выделить плюсы и минусы описанного вами подхода. Определенно плюсом будет то, что вся операция определена в одном месте. То есть если мы хотим посмотреть "что же происходит при регистрации пользователя" нам надо открыть один метод одного сервиса и полностью прочитать весь юзкейс.
Минус тоже весьма значительный — это наименее гибкий способ масштабирования логики приложения. Тут стоит заметить что для многих проектов это не столь критично (пускай и должно было бы быть критичным).
Ну и важный момент — это то как наши языки ограничивают нас. Можете попробовать ознакомиться с "альтернативными" идеями, которые вроде как и про ваш вариант и про мой.
Он будет внешнюю зависимость дергать, или там будет запись в публичную переменную, которую потом кто-то прочитает, или еще как-то?
да, это будет просто запись в стэйт объекта. Список событий. Его прочтут извне когда мы закоммитим транзакцию. Дальше все упирается в выбранные вами варианты управления данными, декомпозицию системы и инфраструктуру. Но суть примерно одинаковая.
Это может быть и другая "моделька"
Ну так можно создание любой сущности в аккаунт пользователя-оператора запихать. Он же их создает, из интерфейса. Промежуточных сущностей тут нет.
Да и чем сервис отличается принципиально от "модельки"? Ну то есть с точки зрения клиентского кода.
Сервис всегда в одном экземпляре, его создание это операция инфраструктуры, а не бизнес-логики.
можно много чего сделать, вопрос зачем
Чтобы не разбрасывать связанные понятия по разным местам.
А потом, что бы быть уверенным в том что email о регистрации уйдет уже после того как мы сохраним данные в базе
Тут согласен, не подумал об этом. Но если у нас ActiveRecord, и сохранение происходит в методе сервиса, то если с сохранением данных будут проблемы, то упадет сразу, и до отправки не дойдет. А если данные сохранились, но транзакция упала при коммите, то значит произошло что-то серьезное, и лишний email мало что значит.
это наименее гибкий способ масштабирования логики приложения
А в чем могут быть проблемы по сравнению с логикой в User?
Промежуточных сущностей тут нет.
или есть, это уже надо смотреть по ситуации.
Сервис всегда в одном экземпляре, его создание это операция инфраструктуры, а не бизнес-логики.
Ну то есть все различие в жизненном цикле. Обычно про тот самый жизненный цикл знает только код, который занимается порождением сущности. Остальной "клиентский код" может вполне себе пользоваться сущностями как сервисами. Я их так же буду мокать в юнит тестах как и сервисы ну и т.д.
Чтобы не разбрасывать связанные понятия по разным местам.
ммм… как по мне в таком варианте связанные понятия как раз и не разбрасываются. Высокий кохижен, все дела.
Но если у нас ActiveRecord
Ну вот я не использую Active Record. Хотите сказать что "сам себе яму выкопал со своими этими Unit of work-ами"?
Хотите сказать что "сам себе яму выкопал со своими этими Unit of work-ами"?
Да нет конечно) Просто хочу уяснить различия.
как по мне в таком варианте связанные понятия как раз и не разбрасываются
Так я потому и спрашиваю. Где у вас будут действия "создать пользователя" и "обновить пользователя" (или любую другую сущность), принимающие на вход введенные данные?
лично у меня — я могу это хоть в контроллере делать, могу запихнуть в сервис-юзкейс (если приложение побольше — в этом есть масса плюсов с организационной точки зрения), который не должен иметь ни одного условия или цикла с условием, и который будет строго декларировать сценарий. Что бы можно было читая код сверху вниз полностью понять как работает юзкейс.
Но в последнее время я от этой идеи отказался и делаю так только в тех ситуациях где мне выгодно зависимости изолировать.
Но при это у Вас по документу только и встречаются в примерах «Хорошо» именно использование геттеров с get. Как-то получается противоречие.
Например:
Сервисы
Вместо лишней конкатенации используем подстановку переменных в двойных кавычках
Вместо лишней конкатенации используем подстановку переменных в двойных кавычках
Спасибо, поправил. Там была речь про кавычки, так что никто не обращал внимание на геттер.)
Сервисы
А тут, кстати, не совсем то. У сервиса нет геттеров по определению. У сервиса просто методы, которые могут начинаться на get, но это не геттеры. Геттер в нашем документе — это метод, который возвращает какие-то данные из состояния объекта. А у сервисов состояний нет. Их методы, начинающиеся get, просто получают откуда-то какие-то данные.
Я не знаю откуда такие устоявшиеся конвенции… не вижу ничего плохого что внутри команды конценция своя а нэйминг методов исходит исключительно из того что метод делает. То есть getProduct(string $productId) а не fetchProduct или id(): string вместо getId().
У Kevlin Henney есть пара любопытных лекций на тему привычек, и там он рассматривает вот эти непонятные привычки начинать методы с get/set.
Со хранением даты и времени в UTC вы рискуете наступить на грабли с временными зонами, которые поменялись задним числом, или поменяются в будущем. Например, человек просит чтобы его в девять утра разбудили через год. Вы посчитали сколько это будет по UTC сейчас и записали, а за год временная зона поменялась и вы разбудили человека не в девять, а в десять. Так себе хорошая идея требовать всегда хранить время по UTC.
Правильно хранить всегда дату и время с временной зоной. Да, программистам будет сложней, но так вы точно никаких концов не потеряете.
Пользователь попросил напомнить ему о чем-то 1 июня 2018 года в 12:00 по Москве (UTC+03). Это определенная точка во времени, когда ему надо напомнить о событии. Если юзер переехал в другое место, то не факт, что точка должна смещаться за ним. Мы по-прежнему напомнить ему должны в 12:00 по Мск. А 12:00 UTC+03 навсегда останется одинаковым и будет равнозначно 09:00 UTC0. Если же в задаче описано так, что при перемещении пользователя данное событие должно тоже двигаться, то хранение зоны в БД нам никак не поможет, нам надо всё равно писать логику, обрабатывающую этот процесс перемещения.
Можешь подробнее написать какой-то пример конкретной задачи?
Хороший пример с Москвой. Пользователь никуда не уезжал из Москвы, но вы записали в БД время 12 часов дня как 09:00 UTC0. Спустя полгода в РФ снова ввели зимнее время, и вот уже ваши 09:00 UTC0 не соответствуют 12 часам дня.
Всё гораздо интересней когда зоны меняются задним числом. Африканские страны всякие интересные есть.
Но спасибо за уточнение. Интересная мысль, которую обязательно будем иметь в виду.
Дело в том что вы пишите инструкции для кода с заделом на будущее, "for long term projects", а на такие известные и понятные кейсы не рассчитываете. Это противоречие. Вам бы или убрать приставку "for long term projects", или перейти на хранение времени вместе с называнием временной зоны.
Например, вы можете сейчас сохранить время в UTC, а через десять лет потребуется узнать в какой же исходной временной зоне было это время. Что вы будете делать, искать программиста который это писал, менеджера, который время в БД заводил?.. Не для того люди поддерживают базу часовых поясов чтобы вы вот так просто на неё плюнули и побежали изобретать свой очередной велосипед потому что вам неудобно или что. Мир часовых поясов действительно неудобен, нелогичен, далёк от человека. Такой есть, это необходимо учитывать в проектах с расчётом на десятилетия.
Вы пытаетесь найти аргументы почему ваш подход — правильный, но при этом упускаете общую картину. Например, а что если это не один пользователь, а какая-то другая сущность, у которой нет своей временной зоны, которая присуща только ей? Вы тоже будете выдумывать какие-то способы решить проблему, там, сохраняя временную зону в соседней колонке? Согласитесь, странно!
Если сохранять время вместе с временной зоной, для чего есть все необходимые технические средства в PHP и большинстве других языков программирования, то не нужно будет ничего делать специально кроме этого. Не нужно будет отдельно записывать временную зону, не нужно будет отдельно вычислять как изменилось время в моменте относительно данных пользователя, ничего такого делать не нужно будет.
Статические вызовы можно делать только у самого класса. У экземпляра можно обращаться только к его свойствам и методам.
Плохо:
$type = $user::TYPE;
Ну вообще-то это не то, о чем вы пишете, а получение константы класса, имя которого в переменной $user. То есть string $user. И ничего криминального в такой конструкции нет.
Код должен быть таким, чтобы его можно было автоматически отрефакторить в IDE (например, Find usages и Rename в PHPStorm). То есть должен быть слинкован типизацией и PHPDoc'ами
В общем случае комментарии запрещены
Желание добавить комментарий — признак плохо читаемого кода.
Ну тут можно только словами анекдота ответить — или трусы снимите, или крестик наденьте…
Читающий не должен держать что-то в уме, возвращаться назад и интерпретировать код иначе. Например, надо избегать обратных циклов do {} while ();
Вы действительно понимаете разницу между циклами с предусловием и постусловием? Это не «возврат назад», а условие, которое впервые будет проверено после первой итерации. Именно поэтому оно и пишется после итерации.
Очень странный пункт, очень.
Модель — простой объект со свойствами, не содержащий никакой другой бизнес-логики, кроме геттеров и сеттеров.
Вы случайно с DTO не путаете? «Модель» в смысле ActiveRecord, например, вполне себе содержит логику.
Желательно делать модели неизменяемыми, см. Работа с объектами.
Нет логики, иммутабельность… Value Objects, да?
API-объект
— Скажите, как его зовут?
— D, парам-пам-парам-пам!
— T, парам-пам-парам-пам!
— O, парам-пам-парам-пам!
— D-T-O!
Файлы классов должны быть расположены в директориях в соответствии со стандартом PSR-0
Deprecated
К переменной нельзя обращаться по ссылке (через &)
Вот так вот взяли и снесли курочке яичко… Не вижу никаких обоснований для неиспользования ссылок. Ну кроме одного — вы не понимаете, что это такое.
Нельзя сортировать ассоциативные массивы
Нельзя смешивать в массиве строковые и числовые ключи
Для проверки наличия значения по индексу в обычных (не ассоциативных) массивах используем count($array) > N
Еще кучу яиц снесли. Второе еще можно понять, первое понять очень сложно, третье — полная жесть. С чего вы взяли, что в PHP есть «обычные» и «ассоциативные» массивы?
В PHPDoc в возвращаемом значении не надо указывать void и null
Полное отсутствие логического обоснования. А если действительно возвращается null или void?
Все методы класса по умолчанию должны быть private
Унаследовал, хочешь перекрыть — попроси разрешения тимлида? Зачем?
Запрещается кешировать данные в статических переменных метода
Причина, видимо, всё та же — не понимаете, что это такое…
В шаблонах не должны вызываться методы объектов
Вообще любимое место…
В целом-то норм, видно, что большая работа проделана. Но что-то мне говорит, что это не действующие правила, а скорее пожелания к коду. Слишком много правил, из которых в реальности постоянно придется делать исключения.
получение константы класса, имя которого в переменной $user. То есть string $user.
нет, там именно то, о чем они и пишут:
$user = new User();
$user::TYPE; Не знаю почему вы подумали иначе. Описанный вами вариант так же "криминалет" тем, что мы теряем информацию о типе, что делает код более сложным в анализе.
Ну тут можно только словами анекдота ответить — или трусы снимите, или крестик наденьте…
Значит вы не понимаете разницы между phpdoc для описания типов (потому что php не позволяет это все описать только за счет тайп хинтов) и "комментариев".
Очень странный пункт, очень.
Тут соглашусь. Если мы выносим тело цикла в метод с понятным названием, то не вижу никаких причин не использовать do while.
Вы случайно с DTO не путаете?
выше уже обсуждали, и выяснилось странная трактовка терминов "геттер" и "сеттер". То есть в целом правильнее было бы тогда определять методы которые работают исключительно со стэйтом этого объекта. Но других методов как бы сложно представить...
Нет логики, иммутабельность… Value Objects, да?
VO без логики — это вещь слегка бесполезная.
Не вижу никаких обоснований для неиспользования ссылок.
обоснование очень простое — устранение одного из источников сайд эффектов. При том что в реальности ситуация где нужны ссылки в PHP приложении крайне редки. Из того что вспомню сходу — ссылки любят применять в каком-то инфраструктурном коде, в коде гидраторов и различных мэпперов данных… при этом код из-за этого усложняется а не упрощается.
Унаследовал, хочешь перекрыть — попроси разрешения тимлида? Зачем?
что бы не юзать наследование для расширения функционала. Очень хорошее ограничение. Я бы отдельно еще абсолютно запретил делать protected стэйт.
Причина, видимо, всё та же — не понимаете, что это такое…
нет, проблема в сайд эффектах и в том что это по сути глобальный стэйт без которого легко можно обойтись.
Вообще любимое место…
вы забыли добавить "(геттеры не в счет)". Можете пояснить что именно вам так "нравится" в этом пункте? Ну то есть, вы не согласны что данные должны быть загружены ДО того как данные будут применяться в шаблоне?
Слишком много правил, из которых в реальности постоянно придется делать исключения.
по поводу того что исключения придется делать, это да, но если это "часто" то надо просто пересмотреть правила.
С другой стороны большую часть этих правил вполне легко соблюдать.
$user = new User();
$user::TYPE;
Блин. Спасибо. Я бы ни за что не подумал…
sandbox.onlinephpfunctions.com/code/572ad62764a572996de145986d3552ed94a5bafa
Тут полностью с вами согласен — такое из кода выпиливать без сожаления.
Хотя в целом разумный СС получился.
Можно ссылку на него?
Вот hsto.org/webt/5w/xn/6s/5wxn6sy8djsqvcopbdf-rtte4xw.png
{kind=link}
/**
* @param string $projectName
*/
public function someMethod($projectName = null) {
// ...
}
может все таки хотя бы так
/**
* @param string|null $projectName
*/
public function someMethod($projectName = null)
{
// ...
}
Вместо лишней конкатенации используем подстановку переменных в двойных кавычках
Хорошо:
$string = «Object with type \»{$object->type()}\" has been removed";
Такой вариант у вас не приемлим?
$string = sprintf('Object with type "%s" has been removed', $object->type());
Методы и свойства в классе должны быть отсортированы по уровням видимости и по порядку использования сверху вниз
Это правило противоречит
Последовательным. Код должен читаться сверху вниз. Читающий не должен держать что-то в уме, возвращаться назад и интерпретировать код иначе.
public-методы обычно вызывают private/protected методы и соотвественно, код уже нельзя будет читать сверху вниз.
И тоже самое про абстрактные классы: мне кажется хорошо, когда абстрактные методы выносятся в самое начало класса (независимо от их области), до всех объявлений. Таким образом, сразу понимаешь что должен реализовать наследник и что будут вызывать public-методы этого абстрактного класса. Иначе, если абстрактный метод protected, то он уедет вниз после всех public-методов, что порой заставляет скакать по коду, чтобы понять абстрактное или нет вызывается из паблика.
Я бы ещё добавил правило про наследование:
наследование должно происходить только от абстрактного, каждый конкретный класс должен быть финальным.
Порой хорошо помогает понять что если хочешь поменять часть логики конкретного класса, то надо это делать не через наследование, а через композицию или вынесение общего куска в абстрактный класс.
return [
// email isValid
['test@test.ru', true ],
['invalidEmail', false],
// ...
];… а вот так:
return [
'valid e-mail' => ['test@test.ru', true ],
'email without @' => ['invalidEmail', false],
// ...
]Так phpunit еще и выведет название проблемного dataset'а, если тест зафейлится — найти его будет проще, чем что-то типа «dataset #1», и смысл проблемы будет сразу понятен прямо из отчета phpunit.
Code Conventions: как мы сохраняем быстрый темп разработки PHP-проекта