Обучение нейросети распознаванию образов — долгий и ресурсоемкий процесс. Особенно когда под рукой есть только недорогой ноут, а не компьютер с мощной видеокартой. В этом случае на помощь придёт Google Colaboratory, которая предлагает совершенно бесплатно воспользоваться GPU уровня Tesla K80 (подробнее).
В этой статье описан процесс подготовки данных, обучения модели tensorflow в Google Colaboratory и её запуск на android устройстве.
Подготовка данных
В качестве примера попробуем обучить нейросеть распознавать белые игральные кости на черном фоне. Соответственно, для начала, надо создать набор данных, достаточный для обучения (пока остановимся на ~100 фото).

Для обучения воспользуемся Tensorflow Object Detection API. Все необходимые для обучения данные мы подготовим на ноутбуке. Нам понадобится менеджер управления окружением и зависимостями conda. Инструкция по установке тут.
Создадим окружение для работы:
conda create -n object_detection_prepare pip python=3.6И активируем его:
conda activate object_detection_prepareУстановим зависимости которые нам понадобятся:
pip install --ignore-installed --upgrade tensorflow==1.14
pip install --ignore-installed pandas
pip install --ignore-installed Pillow
pip install lxml
conda install pyqt=5Создадим папку object_detection, и положим все наши фотографии в папку object_detection/images.
В Google Colab есть ограничение на использование памяти, поэтому перед разметкой данных нужно снизить разрешение фотографий, чтобы в процессе обучения не столкнутся с ошибкой "tcmalloc: large alloc....".
Создадим папку object_detection/preprocessing и добавим в неё подготовленные скрипты.
Для изменения размера фото используем скрипт:
python ./object_detection/preprocessing/image_resize.py -i ./object_detection/images --imageWidth=800 --imageHeight=600Этот скрипт пробежится по папке с указанными фото, изменит их размер до 800x600 и сложит их в object_detection/images/resized. Теперь можно заменить ими оригинальные фотографии в object_detection/images.
Для разметки данных воспользуемся тулзой labelImg.
Клонируем репозиторий labelImg в object_detection
Переходим в папку labelImg
cd [FULL_PATH]/object_detection/labelImg и выполняем команду:
pyrcc5 -o libs/resources.py resources.qrcПосле этого можно приступить к разметке данных (это самый долгий и скучный этап):
python labelImg.py
В “Open dir” указываем папку object_detection/images и проходим по всем фото, выделяя объекты для распознавания и указывая их класс. В нашем случае это номиналы игральных костей (1, 2, 3, 4, 5, 6). Сохраним метаданные (файлы *.xml) в той же папке.
Создадим папку object_detection/training_demo, которую мы чуть позже зальем в Google Colab для обучения.
Разделим наши фото (с метаданными) на тренировочные и тестовые в соотношение 80/20 и переместим их в соответствующие папки object_detection/training_demo/images/train и object_detection/training_demo/images/test.
Создадим папку object_detection/training_demo/annotations, в которую будем складывать файлы с метаданными необходимыми для обучения. Первым из них будет label_map.pbtxt, в котором укажем отношение класса объекта и целочисленного значения. В нашем случае это:
item {
id: 1
name: '1'
}
item {
id: 2
name: '2'
}
item {
id: 3
name: '3'
}
item {
id: 4
name: '4'
}
item {
id: 5
name: '5'
}
item {
id: 6
name: '6'
}Помните метаданные, которые мы получили в процессе разметки данных? Чтобы использовать их для обучения, необходимо конвертировать их в формат TFRecord. Для конвертации воспользуемся скриптами из источника [1].
Проведем конвертацию в два этапа: xml -> csv и csv -> record
Перейдём в папку preprocessing :
cd [FULL_PATH]\object_detection\preprocessing1.Из xml в csv
Тренировочные данные:
python xml_to_csv.py -i [FULL_PATH]/object_detection/training_demo/images/train -o [FULL_PATH]/object_detection/training_demo/annotations/train_labels.csvТестовые данные:
python xml_to_csv.py -i [FULL_PATH]/object_detection/training_demo/images/test -o [FULL_PATH]/object_detection/training_demo/annotations/test_labels.csv2. Из csv в record
Тренировочные данные:
python generate_tfrecord.py --label_map_path=[FULL_PATH]\object_detection\training_demo\annotations\label_map.pbtxt --csv_input=[FULL_PATH]\object_detection\training_demo\annotations\train_labels.csv --output_path=[FULL_PATH]\object_detection\training_demo\annotations\train.record --img_path=[FULL_PATH]\object_detection\training_demo\images\trainТестовые данные:
python generate_tfrecord.py --label_map_path=[FULL_PATH]\object_detection\training_demo\annotations\label_map.pbtxt --csv_input=[FULL_PATH]\object_detection\training_demo\annotations\test_labels.csv --output_path=[FULL_PATH]\object_detection\training_demo\annotations\test.record --img_path=[FULL_PATH]\object_detection\training_demo\images\testНа этом мы закончили подготовку данных, теперь надо выбрать модель, которую будем обучать.
Доступные модели для переобучения можно найти тут.
Сейчас мы выберем модель ssdlite_mobilenet_v2_coco, чтобы в дальнейшем запустить обученную модель на android устройстве.
Скачиваем архив с моделью и распаковываем его в object_detection/training_demo/pre-trained-model.
Должно получиться что-то вроде
object_detection/training_demo/pre-trained-model/ssdlite_mobilenet_v2_coco_2018_05_09
Из распакованного архива копируем файл pipeline.config в object_detection/training_demo/training и переименовываем его в ssdlite_mobilenet_v2_coco.config.
Далее нам надо настроить его под свою задачу, для этого:
1. Укажем количество классов
model.ssd.num_classes: 62. Укажем размер пакета (количество данных для обучения за одну итерацию), количество итераций и путь к сохраненной модели из архива, который мы скачали
train_config.batch_size: 18
train_config.num_steps: 20000
train_config.fine_tune_checkpoint:"./training_demo/pre-trained-model/ssdlite_mobilenet_v2_coco_2018_05_09/model.ckpt"3. Укажем количество фото в тренировочном наборе (object_detection/training_demo/images/train)
eval_config.num_examples: 644. Укажем путь к набору данных для тренировки
train_input_reader.label_map_path: "./training_demo/annotations/label_map.pbtxt"
train_input_reader.tf_record_input_reader.input_path:"./training_demo/annotations/train.record"5. Укажем путь к тестовому набору данных
eval_input_reader.label_map_path: "./training_demo/annotations/label_map.pbtxt"
eval_input_reader.tf_record_input_reader.input_path:"./training_demo/annotations/test.record"В итоге, у вас должно получиться что то вроде этого.
Далее архивируем папку training_demo и получившийся training_demo.zip заливаем в Google Drive.
В этой статье рассказывается как примонтировать google drive к виртуальной машине Google Colab, но нужно не забыть поменять все пути в конфигах и скриптах
На этом подготовка данных закончена, перейдем к обучению.
Обучение модели
В Google Drive выбираем training_demo.zip, кликаем на Get shareable link и из полученной ссылки сохраним себе id этого файла:
drive.google.com/open?id=[YOUR_FILE_ID_HERE]
Самый просто способ воспользоваться Google Colab — создать новый блокнот в Google Drive.

По умолчанию обучение будет выполняться на CPU. Чтобы использовать GPU, нужно поменять тип runtime.


Готовый блокнот можно взять тут.
Обучение состоит из следующих этапов:
1. Клонируем репозиторий TensorFlow Models:
!git clone https://github.com/tensorflow/models.git 2. Устанавливаем protobuf и компилируем необходимые файлы в object_detection:
!apt-get -qq install libprotobuf-java protobuf-compiler
%cd ./models/research/
!protoc object_detection/protos/*.proto --python_out=.
%cd ../..3. Добавляем необходимые пути в переменную окружения PYTHONPATH:
import os
os.environ['PYTHONPATH'] += ":/content/models/research/"
os.environ['PYTHONPATH'] += ":/content/models/research/slim"
os.environ['PYTHONPATH'] += ":/content/models/research/object_detection"
os.environ['PYTHONPATH'] += ":/content/models/research/object_detection/utils"4. Для получения файла из Google Drive устанавливаем PyDrive и авторизируемся:
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)5. Скачиваем архив (нужно указать id вашего файла) и разархивируем его:
drive_file_id="[YOUR_FILE_ID_HERE]"
training_demo_zip = drive.CreateFile({'id': drive_file_id})
training_demo_zip.GetContentFile('training_demo.zip')
!unzip training_demo.zip
!rm training_demo.zip6. Запускаем процесс обучения:
!python ./models/research/object_detection/legacy/train.py --logtostderr --train_dir=./training_demo/training --pipeline_config_path=./training_demo/training/ssdlite_mobilenet_v2_coco.config--train_dir=./training_demo/training — путь к директории, где будут лежать
результаты обучение
--pipeline_config_path=./training_demo/training/ssdlite_mobilenet_v2_coco.config — путь к конфигу
7. Конвертируем результат обучения в frozen graph, который можно будет использовать:
!python /content/models/research/object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path /content/training_demo/training/ssdlite_mobilenet_v2_coco.config --trained_checkpoint_prefix /content/training_demo/training/model.ckpt-[CHECKPOINT_NUMBER]
--output_directory /content/training_demo/training/output_inference_graph_v1.pb--pipeline_config_path /content/training_demo/training/ssdlite_mobilenet_v2_coco.config — путь к конфигу
--trained_checkpoint_prefix /content/training_demo/training/model.ckpt-[CHECKPOINT_NUMBER] — путь к чекпоинту, который мы хотим конвертировать.
--output_directory /content/training_demo/training/output_inference_graph_v1.pb — имя сконвертированной модели
Номер чекпоинта [CHECKPOINT_NUMBER], можно посмотреть в папке content/training_demo/training/. ПОСЛЕ обучения там должны появиться файлы типа model.ckpt-1440.index, model.ckpt-1440.meta. 1440 — это и [CHECKPOINT_NUMBER] и номер итерации обучения.

Для визуализации результата обучения в блокноте есть специальный скрипт. На рисунке ниже показан результат распознавания изображения из тестового набора данных после ~20000 итераций обучения.

8. Конвертация обученной модели в tflite.
Для использования tensorflow lite нужно конвертировать модель в формат tflite. Для этого конвертируем результат обучения в frozen graph который поддерживает конвертацию в tflite (параметры такие же как при использовании скрипта export_inference_graph.py):
!python /content/models/research/object_detection/export_tflite_ssd_graph.py --pipeline_config_path /content/training_demo/training/ssdlite_mobilenet_v2_coco.config --trained_checkpoint_prefix /content/training_demo/training/model.ckpt-[CHECKPOINT_NUMBER] --output_directory /content/training_demo/training/output_inference_graph_tf_lite.pbДля конвертации в tflite нам нужна дополнительная информация о модели, для её получения скачиваем модель из output_inference_graph_tf_lite.pb:

И открываем её в тулзе Netron. Нас интересует названия и размерность входного и выходного узлов модели.
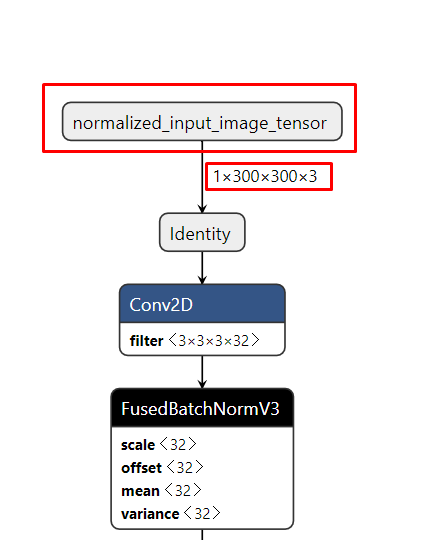

Зная их можно конвертировать pb модель в tflite формат:
!tflite_convert --output_file=/content/training_demo/training/model_q.tflite --graph_def_file=/content/training_demo/training/output_inference_graph_tf_lite_v1.pb/tflite_graph.pb --input_arrays=normalized_input_image_tensor --output_arrays='TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3' --input_shapes=1,300,300,3 --enable_select_tf_ops --allow_custom_ops --inference_input_type=QUANTIZED_UINT8 --inference_type=FLOAT --mean_values=128 --std_dev_values=128--output_file=/content/training_demo/training/model_q.tflite — путь к результату конвертации
--graph_def_file=/content/training_demo/training/output_inference_graph_tf_lite_v1.pb/tflite_graph.pb — путь к frozen graph, который нужно конвертировать
--input_arrays=normalized_input_image_tensor — название входного узла, которое мы узнали выше
--output_arrays='TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3' — названия выходных узлов, которые мы узнали выше
--input_shapes=1,300,300,3 — размерность входных данных, которые мы узнали выше
--enable_select_tf_ops — для использования расширенного runtime TensorFlow Lite
--allow_custom_ops — для использования TensorFlow Lite Optimizing Converter
--inference_type=FLOAT — тип данных для всех массивов в модели кроме входных
--inference_input_type=QUANTIZED_UINT8 — тип данных для всех входных массивов в модели
--mean_values=128 --std_dev_values=128 — среднее значение и стандартное отклонение входных данных, для использования QUANTIZED_UINT8
Архивируем папку с результатами обучения и заливаем её в Google Drive:
!zip -r ./training_demo/training.zip ./training_demo/training/
training_result = drive.CreateFile({'title': 'training_result.zip'})
training_result.SetContentFile('training_demo/training.zip')
training_result.Upload()Если будет ошибка Invalid client secrets file, то нужно сделать повторную авторизацию в google drive.
Запуск модели на android устройстве
В основе android приложения был использован официальный гайд по object detection, но он был полностью переписан с использованием kotlin и CameraX. Полностью код можно посмотреть тут.
CameraX уже имеет механизм для анализа входящих фреймов с камеры с помощью ImageAnalysis. Логика по распознаванию находится в ObjectDetectorAnalyzer.
Весь процесс распознавания изображения можно разбить на несколько этапов:
1. На вход мы получаем изображение которое имеет YUV формат. Для дальнейшей работы его нужно конвертировать в RGB формат:
val rgbArray = convertYuvToRgb(image)2. Далее нужно трансформировать изображение (повернуть, если есть необходимость, и изменить размер до входных значений модели, в нашем случае это 300x300), для этого отрисуем массив с пикселями на Bitmap и применим на нём трансформацию:
val rgbBitmap = getRgbBitmap(rgbArray, image.width, image.height)
val transformation = getTransformation(rotationDegrees, image.width, image.height)
Canvas(resizedBitmap).drawBitmap(rgbBitmap, transformation, null)3. Конвертируем bitmap в массив пикселей, и отдадим его на вход детектора:
ImageUtil.storePixels(resizedBitmap, inputArray)
val objects = detect(inputArray)4. Для визуализации передадим результат распознавания в RecognitionResultOverlayView и преобразуем координаты с соблюдением соотношения сторон:
val scaleFactorX = measuredWidth / result.imageWidth.toFloat()
val scaleFactorY = measuredHeight / result.imageHeight.toFloat()
result.objects.forEach { obj ->
val left = obj.location.left * scaleFactorX
val top = obj.location.top * scaleFactorY
val right = obj.location.right * scaleFactorX
val bottom = obj.location.bottom * scaleFactorY
canvas.drawRect(left, top, right, bottom, boxPaint)
canvas.drawText(obj.text, left, top - 25f, textPaint)
}Чтобы запустить нашу модель в приложении, нужно заменить в assets файл с моделью на training_demo/training/model_q.tflite (переименовав её в detect.tflite) и файл с метками labelmap.txt, в нашем случае это:
1
2
3
4
5
6Так как в официальном гайде используется SSD Mobilenet V1, в котором индексация меток начинает с 1, а не с 0, нужно поменять labelOffset с 1 на 0 в методе collectDetectionResult класса ObjectDetector.
На этом всё.
На видео результат того, как обученная модель работает на стареньком Xiaomi Redmi 4X :
В процессе работы использовались следующие ресурсы:
- https://tensorflow-object-detection-api-tutorial.readthedocs.io
- https://github.com/EdjeElectronics/TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10
- https://lutzroeder.github.io/netron/
