Праздники завершились, и мы возвращаемся с нашим вторым постом из серии по Istio Service Mesh.

Сегодняшняя тема – Circuit Breaker, что в переводе на русский электротехнический означает «автоматический выключатель», в просторечии – «автомат защиты». Только в Istio этот автомат отключает не коротнувшую или перегруженную цепь, а неисправные контейнеры.
Когда микросервисы управляются Kubernetes’ом, например, в рамках платформы OpenShift, они автоматически масштабируется вверх-вниз в зависимости от нагрузки. Поскольку микросервисы работают в pod’ах, на одной конечной точке может быть сразу несколько экземпляров контейнеризированного микросервиса, а Kubernetes будет маршрутизировать запросы и балансировать нагрузку между ними. И – в идеале – все это должно прекрасно работать.
Мы помним, что микросервисы – маленькие и эфемерные. Эфемерность, которая здесь означает простоту возникновения и исчезновения, часто недооценивают. Рождение и смерть очередного экземпляра микросервиса в pod’е – вещи вполне ожидаемые, OpenShift и Kubernetes с этим хорошо справляются, и всё замечательно работает – но опять же в теории.
А теперь представьте, что какой-то конкретный экземпляр микросервиса, то бишь контейнер, пришел в негодность: либо не отвечает (ошибка 503), либо – что неприятнее – реагирует, но слишком медленно. Иначе говоря, он подглючивает или не отвечает на запросы, но из пула он при этом автоматически не убирается. Что надо делать в этом случае? Повторить попытку? Убрать его из схемы маршрутизации? И что значит «слишком медленно» – сколько это в цифрах, и кто их определяет? Может быть, просто дать ему паузу и попробовать позднее? Если да, то насколько позднее?
И здесь на помощь приходит Istio со своими автоматами защиты Circuit Breaker, которые временно убирают неисправные контейнеры из пула ресурсов маршрутизации и балансировки нагрузки, реализуя процедуру Pool Ejection.
Используя стратегию обнаружения отклонений (outlier detection), Istio детектирует кривые pod’ы, которые выбиваются из общего ряда, и убирает их из пула ресурсов на заданное время, которое называется «окно сна» (sleep window).
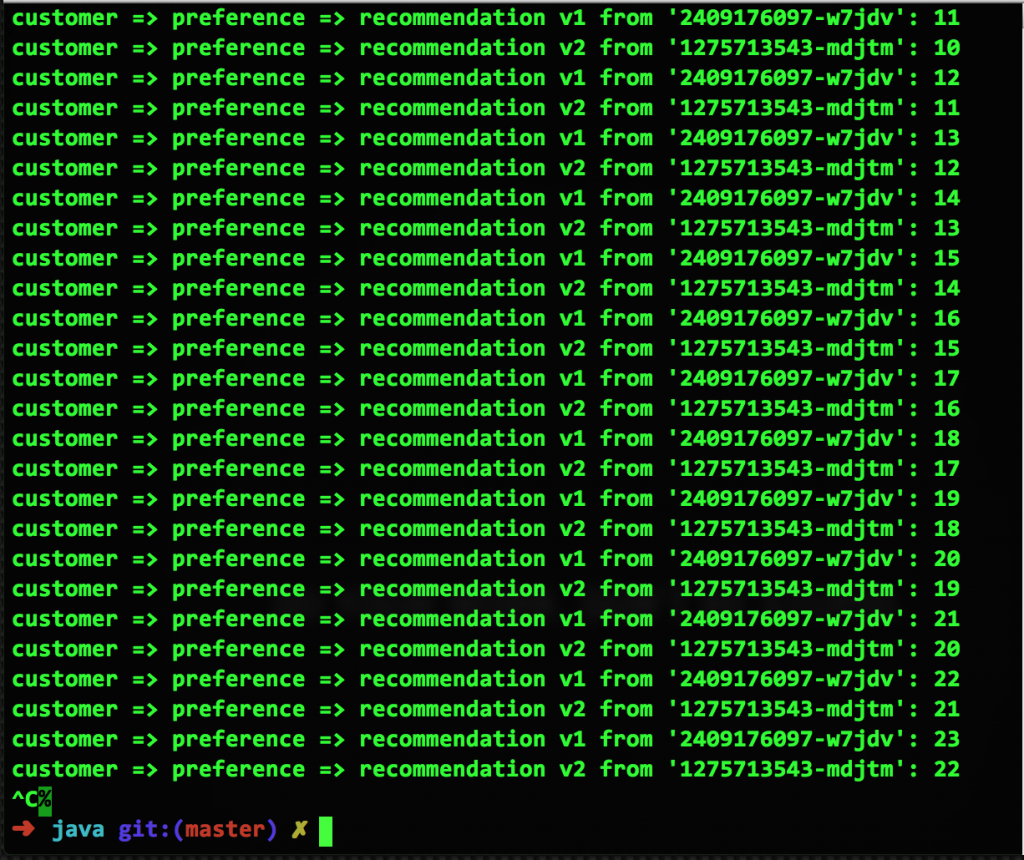
Чтобы показать, как это работает в Kubernetes на платформе OpenShift, начнем со скриншота нормально работающих микросервисов из примера в репозитории Red Hat Developer Demos. Здесь у нас есть два pod’а, v1 и v2, в каждом из которых работает по одному контейнеру. Когда правила маршрутизации Istio не используются, Kubernetes по умолчанию применяет равномерно сбалансированную циклическую маршрутизацию:
Прежде чем делать Pool Ejection, надо создать правило маршрутизации Istio. Допустим, мы хотим распределять запросы между pod’ами в отношении 50/50. Кроме того, мы увеличим количество контейнеров v2 с одного до двух, вот так:
Теперь задаем правило маршрутизации, чтобы трафик распределялся между pod’ами в отношении 50/50.

А вот как выглядит результат работы этого правила:

Можно придраться, что на этом скрине не 50/50, а 14:9, но со временем ситуация выправится.
А теперь выведем из строя один из двух контейнеров v2, чтобы у нас был один исправный контейнер v1, один исправный контейнер v2 и один неисправный контейнер v2:
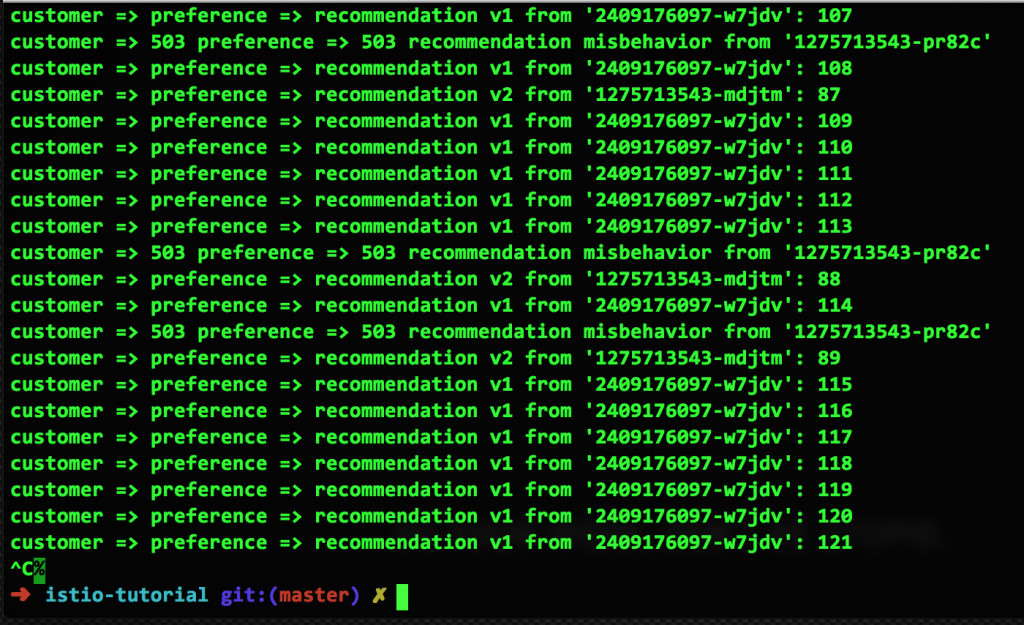
Итак, у нас есть неисправный контейнер, и настала пора Pool Ejection. С помощью очень простого конфига мы исключим этот сбойный контейнер из любых схем маршрутизации на 15 секунд в расчете на то, что он сам вернется в исправное состояние (либо перезапустится, либо восстановит производительность). Вот как выглядит этот конфиг и результаты его работы:

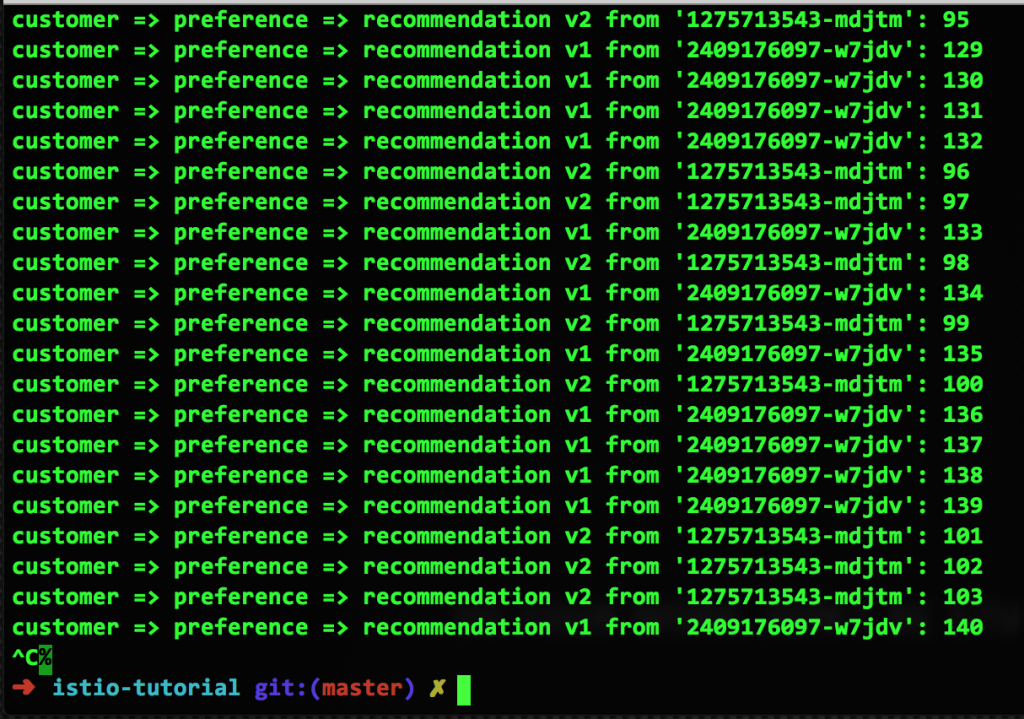
Как видно, неисправный контейнер v2 больше не используется при маршрутизации запросов, поскольку его убрали из пула. Но по истечении 15 секунд он автоматически вернется в пул. Собственно, мы только что показали, как работает Pool Ejection.
Pool Ejection в сочетании с возможностями мониторинга Istio позволяет начать выстраивать фреймворк автоматической замены неисправных контейнеров, чтобы сократить, а то и вовсе устранить простои и сбои.
У NASA есть один громкий девиз – Failure Is Not an Option, автором которого считается руководитель полетов Джин Кранц. На русский его можно перевести как «Поражение – это не вариант», и смысл здесь в том, что всё можно заставить работать, имея на то достаточно воли. Однако в реальной жизни отказы не просто случаются, они неизбежны, везде и во всем. И как же с ними справляться в случае микросервисов? На наш взгляд, лучше полагаться не на силу воли, а на возможности контейнеров, Kubernetes, Red Hat OpenShift, и Istio.
Istio, как мы уже писали выше, реализует прекрасно зарекомендовавшую себя в физическом мире концепцию автоматических выключателей. И как электрический автомат отключает проблемный участок цепи, так и программный Circuit Breaker в Istio размыкает связь между потоком запросов и проблемным контейнером, когда с конечной точкой что-то не в порядке, например, когда сервер упал или начал тормозить.
Причем во втором случае проблем только больше, поскольку тормоза одного контейнера не только вызывают каскад задержек в обращающихся к нему сервисах и, как следствие, снижают производительность системы в целом, но и порождают повтор запросов к и так уже медленно работающему сервису, что только усугубляет ситуацию.
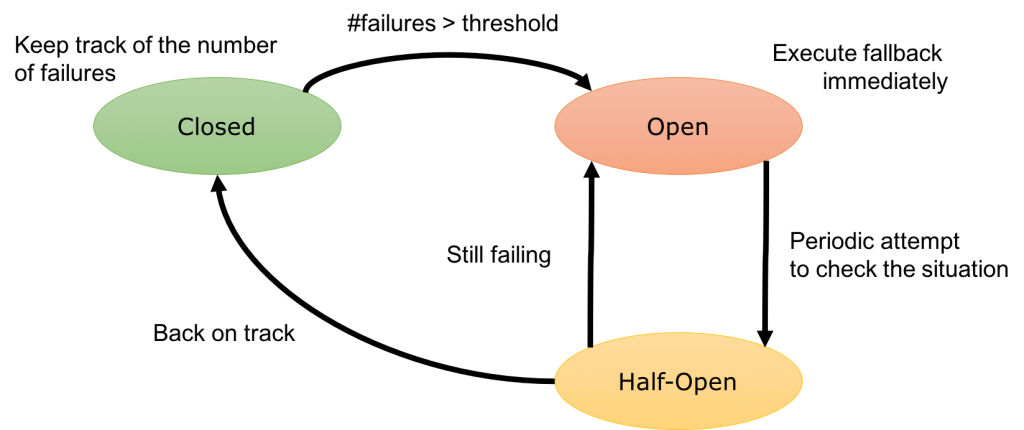
Circuit Breaker – это прокси, который контролирует поток к запросов к конечной точке. Когда эта точка перестает работать или – в зависимости от заданных настроек – начинает тормозить, прокси разрывает связь с контейнером. Трафик после этого перенаправляется на другие контейнеры, ну просто из-за балансировки нагрузки. Связь остается разомкнутой (open) на протяжении заданного окна сна, скажем, две минуты, а затем считается полуразомкнутой (half-open). Попытка отправить следующий запрос определяет дальнейшее состояние связи. Если с сервисом все ОК, связь возвращается в рабочее состояние и опять становится замкнутой (closed). Если же с сервисом по-прежнему что-то не то, связь размыкается и заново включается окно сна. Вот как выглядит упрощенная диаграмма смены состояний Circuit Breaker:
Здесь важно отметить, что все это происходит на уровне, так сказать, системной архитектуры. Поэтому в какой-то момент вам придется научить свои приложения работать с Circuit Breaker, например, предоставлять в ответ значение по умолчанию или же, если это возможно, игнорировать существование сервиса. Для этого используется bulkhead pattern, но он выходит за рамки этой статьи.
Для примера мы запустим на OpenShift две версии нашего микросервиса рекомендаций. Версия 1 будет работать нормально, а вот в v2 мы встроим задержку, чтобы имитировать тормоза на сервере. Для просмотра результатов используется инструмент siege:

Все вроде бы работает, но какой ценой? На первый взгляд у нас 100 % доступность, но присмотритесь – максимальная длительность транзакции составляет целых 12 секунд. Это явно узкое место, и его надо расшивать.
Для этого мы с помощью Istio исключим обращения к медленным контейнерам. Вот как выглядит соответствующий конфиг с использованием Circuit Breaker:

Последняя строка с параметром httpMaxRequestsPerConnection сигнализирует, что связь с должна размыкаться при попытке создать еще одно – второе – подключение вдобавок к уже имеющемуся. Поскольку наш контейнер имитирует тормозящий сервис, такие ситуации будут периодически возникать, и тогда Istio будет возвращать ошибку 503, а вот что покажет siege:
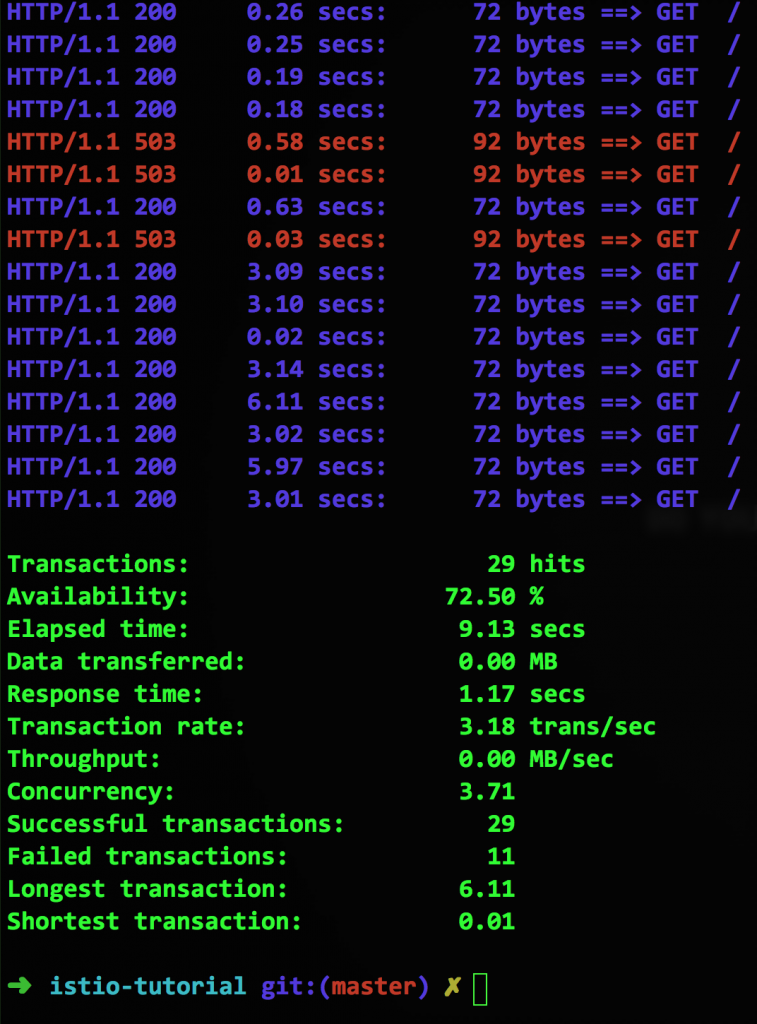
Итак, мы реализовали автоматическое отключение, совершенно не трогая исходный код самих сервисов. Используя Circuit Breaker и описанную выше процедуру Pool Ejection, мы можем убирать из пула ресурсов тормозные контейнеры до тех пор, пока они не придут в норму, и проверять их состояние с заданной периодичностью – в нашем примере, это две минуты (параметр sleepWindow).
Обратите внимание, что способность приложения реагировать на ошибку 503 все еще задается на уровне его исходного кода. Существует множество стратегий работы с Circuit Breaker, которые применяются в зависимости от ситуации.
В следующем посте: расскажем о трассировке и мониторинге, которые уже встроены или легко добавляются в Istio, а также о том, как вносить ошибки в систему намеренно.

Сегодняшняя тема – Circuit Breaker, что в переводе на русский электротехнический означает «автоматический выключатель», в просторечии – «автомат защиты». Только в Istio этот автомат отключает не коротнувшую или перегруженную цепь, а неисправные контейнеры.
Как это должно работать в идеале
Когда микросервисы управляются Kubernetes’ом, например, в рамках платформы OpenShift, они автоматически масштабируется вверх-вниз в зависимости от нагрузки. Поскольку микросервисы работают в pod’ах, на одной конечной точке может быть сразу несколько экземпляров контейнеризированного микросервиса, а Kubernetes будет маршрутизировать запросы и балансировать нагрузку между ними. И – в идеале – все это должно прекрасно работать.
Мы помним, что микросервисы – маленькие и эфемерные. Эфемерность, которая здесь означает простоту возникновения и исчезновения, часто недооценивают. Рождение и смерть очередного экземпляра микросервиса в pod’е – вещи вполне ожидаемые, OpenShift и Kubernetes с этим хорошо справляются, и всё замечательно работает – но опять же в теории.
Как это работает на самом деле
А теперь представьте, что какой-то конкретный экземпляр микросервиса, то бишь контейнер, пришел в негодность: либо не отвечает (ошибка 503), либо – что неприятнее – реагирует, но слишком медленно. Иначе говоря, он подглючивает или не отвечает на запросы, но из пула он при этом автоматически не убирается. Что надо делать в этом случае? Повторить попытку? Убрать его из схемы маршрутизации? И что значит «слишком медленно» – сколько это в цифрах, и кто их определяет? Может быть, просто дать ему паузу и попробовать позднее? Если да, то насколько позднее?
Что такое Pool Ejection в Istio
И здесь на помощь приходит Istio со своими автоматами защиты Circuit Breaker, которые временно убирают неисправные контейнеры из пула ресурсов маршрутизации и балансировки нагрузки, реализуя процедуру Pool Ejection.
Используя стратегию обнаружения отклонений (outlier detection), Istio детектирует кривые pod’ы, которые выбиваются из общего ряда, и убирает их из пула ресурсов на заданное время, которое называется «окно сна» (sleep window).
Чтобы показать, как это работает в Kubernetes на платформе OpenShift, начнем со скриншота нормально работающих микросервисов из примера в репозитории Red Hat Developer Demos. Здесь у нас есть два pod’а, v1 и v2, в каждом из которых работает по одному контейнеру. Когда правила маршрутизации Istio не используются, Kubernetes по умолчанию применяет равномерно сбалансированную циклическую маршрутизацию:

Готовимся к сбою
Прежде чем делать Pool Ejection, надо создать правило маршрутизации Istio. Допустим, мы хотим распределять запросы между pod’ами в отношении 50/50. Кроме того, мы увеличим количество контейнеров v2 с одного до двух, вот так:
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
Теперь задаем правило маршрутизации, чтобы трафик распределялся между pod’ами в отношении 50/50.

А вот как выглядит результат работы этого правила:

Можно придраться, что на этом скрине не 50/50, а 14:9, но со временем ситуация выправится.
Устраиваем сбой
А теперь выведем из строя один из двух контейнеров v2, чтобы у нас был один исправный контейнер v1, один исправный контейнер v2 и один неисправный контейнер v2:

Чиним сбой
Итак, у нас есть неисправный контейнер, и настала пора Pool Ejection. С помощью очень простого конфига мы исключим этот сбойный контейнер из любых схем маршрутизации на 15 секунд в расчете на то, что он сам вернется в исправное состояние (либо перезапустится, либо восстановит производительность). Вот как выглядит этот конфиг и результаты его работы:


Как видно, неисправный контейнер v2 больше не используется при маршрутизации запросов, поскольку его убрали из пула. Но по истечении 15 секунд он автоматически вернется в пул. Собственно, мы только что показали, как работает Pool Ejection.
Начинаем строить архитектуру
Pool Ejection в сочетании с возможностями мониторинга Istio позволяет начать выстраивать фреймворк автоматической замены неисправных контейнеров, чтобы сократить, а то и вовсе устранить простои и сбои.
У NASA есть один громкий девиз – Failure Is Not an Option, автором которого считается руководитель полетов Джин Кранц. На русский его можно перевести как «Поражение – это не вариант», и смысл здесь в том, что всё можно заставить работать, имея на то достаточно воли. Однако в реальной жизни отказы не просто случаются, они неизбежны, везде и во всем. И как же с ними справляться в случае микросервисов? На наш взгляд, лучше полагаться не на силу воли, а на возможности контейнеров, Kubernetes, Red Hat OpenShift, и Istio.
Istio, как мы уже писали выше, реализует прекрасно зарекомендовавшую себя в физическом мире концепцию автоматических выключателей. И как электрический автомат отключает проблемный участок цепи, так и программный Circuit Breaker в Istio размыкает связь между потоком запросов и проблемным контейнером, когда с конечной точкой что-то не в порядке, например, когда сервер упал или начал тормозить.
Причем во втором случае проблем только больше, поскольку тормоза одного контейнера не только вызывают каскад задержек в обращающихся к нему сервисах и, как следствие, снижают производительность системы в целом, но и порождают повтор запросов к и так уже медленно работающему сервису, что только усугубляет ситуацию.
Circuit Breaker в теории
Circuit Breaker – это прокси, который контролирует поток к запросов к конечной точке. Когда эта точка перестает работать или – в зависимости от заданных настроек – начинает тормозить, прокси разрывает связь с контейнером. Трафик после этого перенаправляется на другие контейнеры, ну просто из-за балансировки нагрузки. Связь остается разомкнутой (open) на протяжении заданного окна сна, скажем, две минуты, а затем считается полуразомкнутой (half-open). Попытка отправить следующий запрос определяет дальнейшее состояние связи. Если с сервисом все ОК, связь возвращается в рабочее состояние и опять становится замкнутой (closed). Если же с сервисом по-прежнему что-то не то, связь размыкается и заново включается окно сна. Вот как выглядит упрощенная диаграмма смены состояний Circuit Breaker:

Здесь важно отметить, что все это происходит на уровне, так сказать, системной архитектуры. Поэтому в какой-то момент вам придется научить свои приложения работать с Circuit Breaker, например, предоставлять в ответ значение по умолчанию или же, если это возможно, игнорировать существование сервиса. Для этого используется bulkhead pattern, но он выходит за рамки этой статьи.
Circuit Breaker на практике
Для примера мы запустим на OpenShift две версии нашего микросервиса рекомендаций. Версия 1 будет работать нормально, а вот в v2 мы встроим задержку, чтобы имитировать тормоза на сервере. Для просмотра результатов используется инструмент siege:
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io

Все вроде бы работает, но какой ценой? На первый взгляд у нас 100 % доступность, но присмотритесь – максимальная длительность транзакции составляет целых 12 секунд. Это явно узкое место, и его надо расшивать.
Для этого мы с помощью Istio исключим обращения к медленным контейнерам. Вот как выглядит соответствующий конфиг с использованием Circuit Breaker:

Последняя строка с параметром httpMaxRequestsPerConnection сигнализирует, что связь с должна размыкаться при попытке создать еще одно – второе – подключение вдобавок к уже имеющемуся. Поскольку наш контейнер имитирует тормозящий сервис, такие ситуации будут периодически возникать, и тогда Istio будет возвращать ошибку 503, а вот что покажет siege:

ОК, у нас есть Circuit Breaker, что дальше?
Итак, мы реализовали автоматическое отключение, совершенно не трогая исходный код самих сервисов. Используя Circuit Breaker и описанную выше процедуру Pool Ejection, мы можем убирать из пула ресурсов тормозные контейнеры до тех пор, пока они не придут в норму, и проверять их состояние с заданной периодичностью – в нашем примере, это две минуты (параметр sleepWindow).
Обратите внимание, что способность приложения реагировать на ошибку 503 все еще задается на уровне его исходного кода. Существует множество стратегий работы с Circuit Breaker, которые применяются в зависимости от ситуации.
В следующем посте: расскажем о трассировке и мониторинге, которые уже встроены или легко добавляются в Istio, а также о том, как вносить ошибки в систему намеренно.
