Привет, Хабр.
Меня зовут Миша Бутримов, я хотел бы хотел немного рассказать про Cassandra. Мой рассказ будет полезен тем, кто никогда не сталкивался с NoSQL-базами, — у нее есть очень много особенностей реализации и подводных камней, про которые нужно знать. И если кроме Oracle или любой другой реляционной базы вы ничего не видели, эти вещи спасут вам жизнь.
Чем хороша Cassandra? Это NoSQL-база данных, cпроектированная без единой точки отказа, которая хорошо масштабируется. Если вам нужно добавить пару терабайт для какой-нибудь базы, вы просто добавляете ноды в кольцо. Расширить ее на еще один дата-центр? Добавляете ноды в кластер. Увеличить обрабатываемый RPS? Добавляете ноды в кластер. В обратную сторону тоже работает.

В чем еще она хороша? В том, чтобы обрабатывать много запросов. Но много — это сколько? 10, 20, 30, 40 тысяч запросов в секунду — это немного. 100 тысяч запросов в секунду на запись — тоже. Есть компании, которые говорили, что они держат 2 млн. запросов в секунду. Вот им, наверное, придется поверить.
И в принципе у Cassandra есть одно большое отличие от реляционных данных — она вообще на них не похожа. И об этом очень важно помнить.
Как-то ко мне пришел коллега и спросил: «Вот СQL Cassandra query language, и в нем есть select statement, в нем есть where, в нем есть and. Я пишу буквы, и не работает. Почему?». Если относиться к Cassandra как к реляционной базе данных, то это идеальный способ закончить жизнь жестоким самоубийством. И я не пропагандирую, это запрещено в России. Вы просто спроектируете что-нибудь неправильно.
Например, к нам приходит заказчик и говорит: «Давайте построим базу данных для сериалов, или базу данных для справочника рецептов. У нас там будут блюда с продуктами или список сериалов и актеров в нем». Мы говорим радостно: «Давайте!». Это два байта переслать, пара табличек и все готово, все будет работать очень быстро, надежно. И все прекрасно, пока заказчики не приходят и не говорят, что домохозяйки решают еще и обратную задачу: у них есть список продуктов, и они хотят узнать, какое блюдо они хотят приготовить. Вы мертвы.
Все потому, что Cassandra — гибридная база данных: она одновременно и key value, и хранит данные в широких столбцах. Если говорить на языке Java или Kotlin, это можно было бы описать вот так:
То есть мапа, внутри которой лежит еще и отсортированная мапа. Первым ключом к этой мапе является Row key или Partition key — ключ партиционирования. Второй ключ, который является ключом к уже отсортированной мапе, это Clustering key.
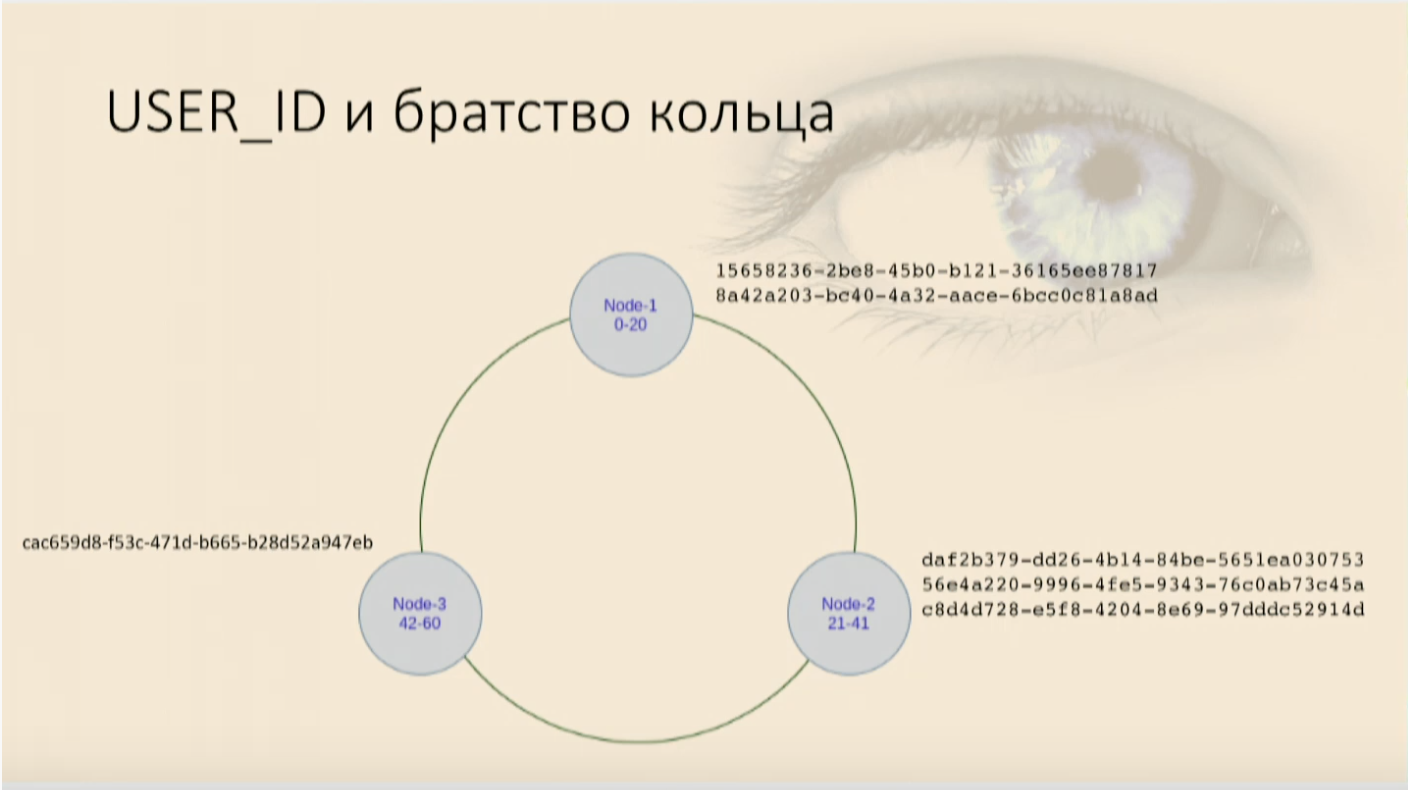
Для иллюстрации распределенности базы данных нарисуем три ноды. Теперь нужно понять, как разложить данные на ноды. Потому что если мы будем пихать все в одну (их, кстати, может быть тысяча, две тысячи, пять — сколько угодно), это не очень-то про распределенность. Поэтому нам нужна математическая функция, которая будет возвращать число. Просто число, длинный int, который будет попадать в какой-то диапазон. И у нас одна нода будет отвечать за один диапазон, вторая — за второй, n-ная — за n-ый.

Это число берется с помощью хеш-функции, которая применяется как раз к тому, что мы называем Partition key. Это тот столбец, который указывается в директиве Primary key, и это тот столбец, который будет первым и самым основным ключом мапы. Он определяет, на какую ноду какие данные попадут. Таблица создается в Cassandra почти с таким же синтаксисом, как в SQL:
Primary key в данном случае состоит из одной колонки, и она же является ключом партиционирования.
Как у нас лягут пользователи? Часть попадет на одну ноду, часть — на другую, и часть — на третью. Получается обыкновенная хэш-таблица, она же map, она же в Python — словарь, она же — простая Key value-структура, из которой мы можем читать все значения, читать и писать по ключу.
Давайте напишем какой-нибудь select statement:
Когда мы гоняем на тестовых данных, то все прекрасно. А когда вы выполняем запрос в продакшене, где у нас, к примеру, 4 миллиона записей, то у нас все не очень хорошо. Потому что allow filtering — это директива, которая позволяет Cassandra собрать все данные из этой таблицы со всех нод, всех дата-центров (если их много в этом кластере), и только потом уже отфильтровать. Это аналог Full Scan, и вряд ли от него кто-то в восторге.
Если бы нам нужны были пользователи только по идентификаторам, нас бы это устроило. Но иногда нам нужно писать другие запросы и накладывать другие ограничения на выборку. Поэтому вспоминаем: это все у нас мапа, у которой есть ключ партиционирования, но внутри нее — отсортированная мапа.
И у нее тоже есть ключ, который мы называем Сlustering Key. Этот ключ, который, в свою очередь, состоит из колонок, которые мы выберем, с помощью которого Cassandra понимает, как у нее данные физически отсортируются и будут лежать на каждой ноде. То есть, для какого-то Partition key Clustering key расскажет, как именно данные запихнуть в это дерево, какое место они там займут.
Это реально дерево, там просто вызывается компаратор, в который мы передаем некий набор колонок в виде объекта, и задается он тоже в виде перечисления колонок.
Обратите внимание на директиву Primary key, у нее первый аргумент (в нашем случае год) всегда идет Partition key. Он может состоять из одной или нескольких колонок, это не важно. Если колонок несколько, его нужно еще раз в скобки убрать, чтобы препроцессор языка понял, что это именно Primary key, а за ним все остальные колонки — Clustering key. При этом они будут в компараторе передаваться в том порядке, в котором они идут. То есть, первая колонка более значимая, вторая — менее значимая и так далее. Как мы для data classes пишем, например, поля equals: перечисляем поля, и для них пишем, какие больше, а какие меньше. В Cassandra это, условно говоря, поля data class, к которому будет применяться написанный для него equals.
Нужно помнить, что порядок сортировки (убывающая, возрастающая, не важно) задается в тот же момент, когда создается ключ, и поменять его потом будет нельзя. Он физически определяет, как будут рассортированы данные и как они будут лежать. Если нужно будет изменить Clustering key или порядок сортировки, придется создавать новую таблицу и переливать в нее данные. С уже существующей так не получится.

Мы заполнили нашу таблицу пользователями и увидели, что они легли в кольцо сначала по году рождения, а потом внутри на каждой ноде по зарплате и по user ID. Теперь мы можем селектить, накладывая ограничения.
Появляется снова наш работающий
Если мы хотим иметь возможность доставать пользователей по ID или по возрасту, или по зарплате, что делать? Ничего. Просто использовать две таблицы. Если надо будет доставать пользователей тремя разными способами — таблиц будет три. Прошли те времена, когда мы экономили место на винте. Это самый дешевый ресурс. Он стоит гораздо дешевле, чем время ответа, которое может быть губительным для пользователя. Пользователю гораздо приятнее получить что-то за секунду, чем за 10 минут.
Мы обмениваем излишнее занимаемое место, денормализованные данные на возможность хорошо масштабироваться, надежно работать. Ведь на самом деле кластер, который состоит из трех дата-центров, в каждом из которых по пять нод, при приемлемом уровне сохранения данных (когда точно ничего не потеряется), способен пережить гибель одного дата-центра полностью. И еще по две ноды в каждом из двух оставшихся. И вот только после этого начнутся проблемы. Это довольно хорошее резервирование, оно стоит пары-тройки лишних ssd-накопителей и процессоров. Поэтому для того, чтобы использовать Cassandra, которая ни разу не SQL, в которой нет отношений, внешних ключей, нужно знать простые правила.
Проектируем все от запроса. Главными становятся не данные, а то, как приложение собирается с ними работать. Если ему нужно получать разные данные разными способами или одни и те же данные разными способами, мы должны положить их так, как будет удобно приложению. Иначе мы будем проваливаться в Full Scan и никакого преимущества Cassandra нам не даст.
Денормализовать данные — это норма. Забываем про нормальные формы, у нас больше не реляционные базы. Положим что-нибудь 100 раз, будет лежать 100 раз. Это все равно дешевле, чем стормозить.
Выбираем ключи для партиционирования так, чтобы они нормально распределялись. Нам не нужно, чтобы хэш от наших ключей попадал в один узкий диапазон. То есть, год рождения в примере выше — плохой пример. Вернее, он хороший, если у нас пользователи по году рождения нормально распределены, и плохой, если речь идет об учениках 5-го класса — там не очень хорошо будет партиционироваться.
Сортировка выбирается один раз на этапе создания Clustering Key. Если ее нужно будет изменить, то придется переливать нашу таблицу с другим ключом.
И самое важное: если нам нужно 100 разными способами забрать одни и те же данные, значит у нас будет 100 разных таблиц.
Меня зовут Миша Бутримов, я хотел бы хотел немного рассказать про Cassandra. Мой рассказ будет полезен тем, кто никогда не сталкивался с NoSQL-базами, — у нее есть очень много особенностей реализации и подводных камней, про которые нужно знать. И если кроме Oracle или любой другой реляционной базы вы ничего не видели, эти вещи спасут вам жизнь.
Чем хороша Cassandra? Это NoSQL-база данных, cпроектированная без единой точки отказа, которая хорошо масштабируется. Если вам нужно добавить пару терабайт для какой-нибудь базы, вы просто добавляете ноды в кольцо. Расширить ее на еще один дата-центр? Добавляете ноды в кластер. Увеличить обрабатываемый RPS? Добавляете ноды в кластер. В обратную сторону тоже работает.

В чем еще она хороша? В том, чтобы обрабатывать много запросов. Но много — это сколько? 10, 20, 30, 40 тысяч запросов в секунду — это немного. 100 тысяч запросов в секунду на запись — тоже. Есть компании, которые говорили, что они держат 2 млн. запросов в секунду. Вот им, наверное, придется поверить.
И в принципе у Cassandra есть одно большое отличие от реляционных данных — она вообще на них не похожа. И об этом очень важно помнить.
Не все, что выглядит одинаково, работает одинаково
Как-то ко мне пришел коллега и спросил: «Вот СQL Cassandra query language, и в нем есть select statement, в нем есть where, в нем есть and. Я пишу буквы, и не работает. Почему?». Если относиться к Cassandra как к реляционной базе данных, то это идеальный способ закончить жизнь жестоким самоубийством. И я не пропагандирую, это запрещено в России. Вы просто спроектируете что-нибудь неправильно.
Например, к нам приходит заказчик и говорит: «Давайте построим базу данных для сериалов, или базу данных для справочника рецептов. У нас там будут блюда с продуктами или список сериалов и актеров в нем». Мы говорим радостно: «Давайте!». Это два байта переслать, пара табличек и все готово, все будет работать очень быстро, надежно. И все прекрасно, пока заказчики не приходят и не говорят, что домохозяйки решают еще и обратную задачу: у них есть список продуктов, и они хотят узнать, какое блюдо они хотят приготовить. Вы мертвы.
Все потому, что Cassandra — гибридная база данных: она одновременно и key value, и хранит данные в широких столбцах. Если говорить на языке Java или Kotlin, это можно было бы описать вот так:
Map<RowKey, SortedMap<ColumnKey, ColumnValue>>То есть мапа, внутри которой лежит еще и отсортированная мапа. Первым ключом к этой мапе является Row key или Partition key — ключ партиционирования. Второй ключ, который является ключом к уже отсортированной мапе, это Clustering key.
Для иллюстрации распределенности базы данных нарисуем три ноды. Теперь нужно понять, как разложить данные на ноды. Потому что если мы будем пихать все в одну (их, кстати, может быть тысяча, две тысячи, пять — сколько угодно), это не очень-то про распределенность. Поэтому нам нужна математическая функция, которая будет возвращать число. Просто число, длинный int, который будет попадать в какой-то диапазон. И у нас одна нода будет отвечать за один диапазон, вторая — за второй, n-ная — за n-ый.

Это число берется с помощью хеш-функции, которая применяется как раз к тому, что мы называем Partition key. Это тот столбец, который указывается в директиве Primary key, и это тот столбец, который будет первым и самым основным ключом мапы. Он определяет, на какую ноду какие данные попадут. Таблица создается в Cassandra почти с таким же синтаксисом, как в SQL:
CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
Primary key в данном случае состоит из одной колонки, и она же является ключом партиционирования.
Как у нас лягут пользователи? Часть попадет на одну ноду, часть — на другую, и часть — на третью. Получается обыкновенная хэш-таблица, она же map, она же в Python — словарь, она же — простая Key value-структура, из которой мы можем читать все значения, читать и писать по ключу.

Select: когда allow filtering превращается в full scan, или как не надо делать
Давайте напишем какой-нибудь select statement:
select * from users where, userid = . Получается вроде бы как в Oracle: пишем select, указываем условия и все работает, пользователи достаются. Но если выбрать, например, пользователя с определенным годом рождения, Cassandra ругается, что она не может выполнить запрос. Потому что она вообще ничего не знает про то, как у нас распределяются данные о годе рождения — у нее в качестве ключа указана только одна колонка. Тогда она говорит: «Хорошо, я могу по-прежнему выполнить этот запрос. Добавьте allow filtering». Мы добавляем директиву, все работает. И в этот момент происходит страшное. Когда мы гоняем на тестовых данных, то все прекрасно. А когда вы выполняем запрос в продакшене, где у нас, к примеру, 4 миллиона записей, то у нас все не очень хорошо. Потому что allow filtering — это директива, которая позволяет Cassandra собрать все данные из этой таблицы со всех нод, всех дата-центров (если их много в этом кластере), и только потом уже отфильтровать. Это аналог Full Scan, и вряд ли от него кто-то в восторге.
Если бы нам нужны были пользователи только по идентификаторам, нас бы это устроило. Но иногда нам нужно писать другие запросы и накладывать другие ограничения на выборку. Поэтому вспоминаем: это все у нас мапа, у которой есть ключ партиционирования, но внутри нее — отсортированная мапа.
И у нее тоже есть ключ, который мы называем Сlustering Key. Этот ключ, который, в свою очередь, состоит из колонок, которые мы выберем, с помощью которого Cassandra понимает, как у нее данные физически отсортируются и будут лежать на каждой ноде. То есть, для какого-то Partition key Clustering key расскажет, как именно данные запихнуть в это дерево, какое место они там займут.
Это реально дерево, там просто вызывается компаратор, в который мы передаем некий набор колонок в виде объекта, и задается он тоже в виде перечисления колонок.
CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
Обратите внимание на директиву Primary key, у нее первый аргумент (в нашем случае год) всегда идет Partition key. Он может состоять из одной или нескольких колонок, это не важно. Если колонок несколько, его нужно еще раз в скобки убрать, чтобы препроцессор языка понял, что это именно Primary key, а за ним все остальные колонки — Clustering key. При этом они будут в компараторе передаваться в том порядке, в котором они идут. То есть, первая колонка более значимая, вторая — менее значимая и так далее. Как мы для data classes пишем, например, поля equals: перечисляем поля, и для них пишем, какие больше, а какие меньше. В Cassandra это, условно говоря, поля data class, к которому будет применяться написанный для него equals.
Задаем сортировку, накладываем ограничения
Нужно помнить, что порядок сортировки (убывающая, возрастающая, не важно) задается в тот же момент, когда создается ключ, и поменять его потом будет нельзя. Он физически определяет, как будут рассортированы данные и как они будут лежать. Если нужно будет изменить Clustering key или порядок сортировки, придется создавать новую таблицу и переливать в нее данные. С уже существующей так не получится.
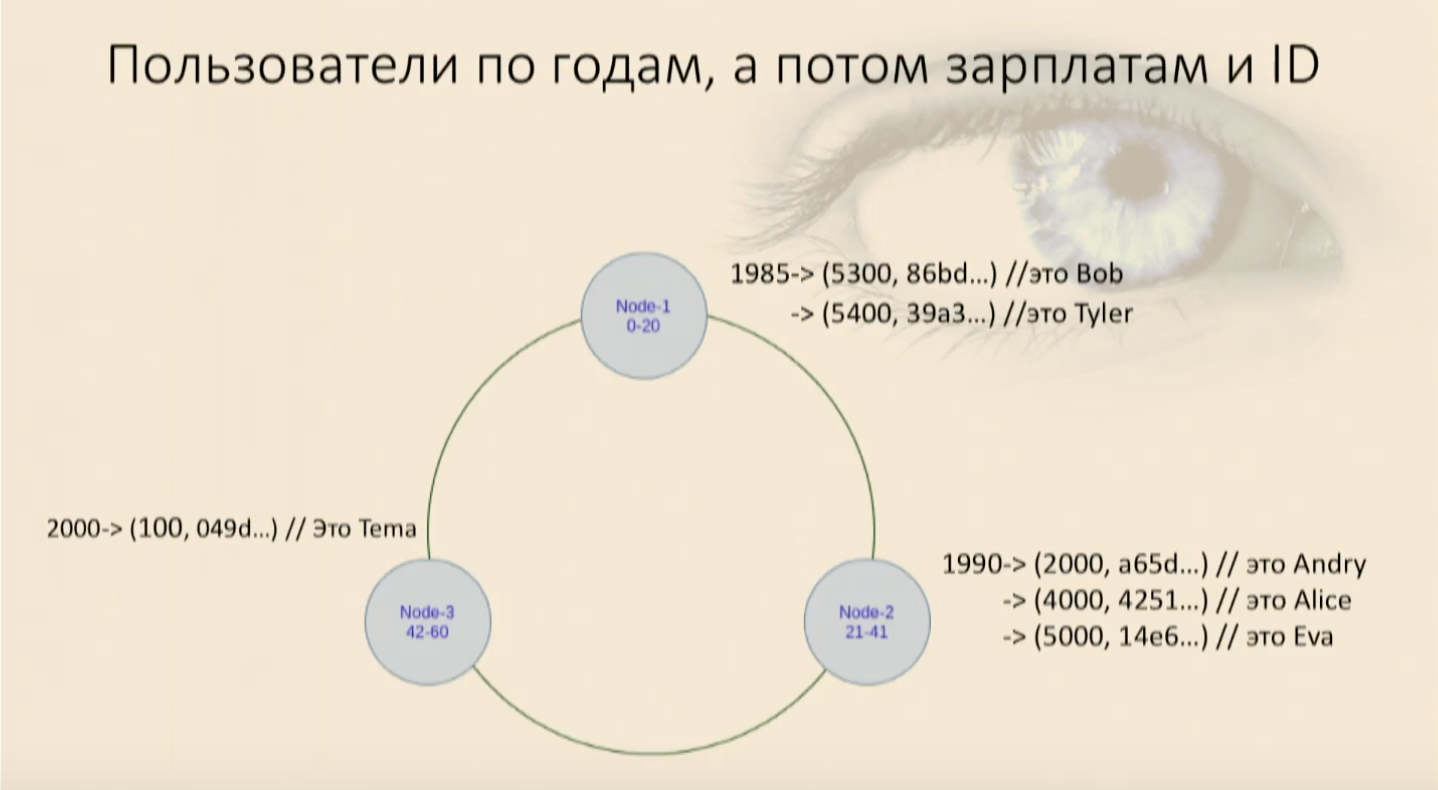
Мы заполнили нашу таблицу пользователями и увидели, что они легли в кольцо сначала по году рождения, а потом внутри на каждой ноде по зарплате и по user ID. Теперь мы можем селектить, накладывая ограничения.
Появляется снова наш работающий
where, and, и пользователи нам достаются, и все снова хорошо. Но если мы попробуем использовать только часть Clustering key, причем менее значимую, то Cassandra тут же ругнется, что не может в нашей мапе найти место, где этот объект, у которого вот эти поля для компаратора null, а вот этот, который только что задали, — где он лежит. Мне придется снова поднять все данные с этой ноды и отфильтровать их. И это аналог Full Scan в рамках ноды, это плохо.В любой непонятной ситуации создавай новую таблицу
Если мы хотим иметь возможность доставать пользователей по ID или по возрасту, или по зарплате, что делать? Ничего. Просто использовать две таблицы. Если надо будет доставать пользователей тремя разными способами — таблиц будет три. Прошли те времена, когда мы экономили место на винте. Это самый дешевый ресурс. Он стоит гораздо дешевле, чем время ответа, которое может быть губительным для пользователя. Пользователю гораздо приятнее получить что-то за секунду, чем за 10 минут.
Мы обмениваем излишнее занимаемое место, денормализованные данные на возможность хорошо масштабироваться, надежно работать. Ведь на самом деле кластер, который состоит из трех дата-центров, в каждом из которых по пять нод, при приемлемом уровне сохранения данных (когда точно ничего не потеряется), способен пережить гибель одного дата-центра полностью. И еще по две ноды в каждом из двух оставшихся. И вот только после этого начнутся проблемы. Это довольно хорошее резервирование, оно стоит пары-тройки лишних ssd-накопителей и процессоров. Поэтому для того, чтобы использовать Cassandra, которая ни разу не SQL, в которой нет отношений, внешних ключей, нужно знать простые правила.
Проектируем все от запроса. Главными становятся не данные, а то, как приложение собирается с ними работать. Если ему нужно получать разные данные разными способами или одни и те же данные разными способами, мы должны положить их так, как будет удобно приложению. Иначе мы будем проваливаться в Full Scan и никакого преимущества Cassandra нам не даст.
Денормализовать данные — это норма. Забываем про нормальные формы, у нас больше не реляционные базы. Положим что-нибудь 100 раз, будет лежать 100 раз. Это все равно дешевле, чем стормозить.
Выбираем ключи для партиционирования так, чтобы они нормально распределялись. Нам не нужно, чтобы хэш от наших ключей попадал в один узкий диапазон. То есть, год рождения в примере выше — плохой пример. Вернее, он хороший, если у нас пользователи по году рождения нормально распределены, и плохой, если речь идет об учениках 5-го класса — там не очень хорошо будет партиционироваться.
Сортировка выбирается один раз на этапе создания Clustering Key. Если ее нужно будет изменить, то придется переливать нашу таблицу с другим ключом.
И самое важное: если нам нужно 100 разными способами забрать одни и те же данные, значит у нас будет 100 разных таблиц.
