Comments 669
Если честно, Си вообще в принципе почти экзотика для энтерпрайза)
Подозреваю, что примерно про мой проект в статье и написано: Winter Novel. Подробнее о реализации тут
С90 и остальные "зверские" опции компилятора сейчас использую почти вместо PVS-Studio — они заставляют писать чище, потом меньше времени на отладку.
Я сталкивался с подобным наследством в медицинской области, где некоторые файлы были еще старше (там был сильнозапущеный принцип "работает — не трожь", помноженый на медицинскую специфику что любой код или либа по умолчанию считаются опасной и глючной). И проблем там была куча из-за этого, тот же кланг вообще не смог проанализировать или собрать проект из-за отсутствия -fpermissive и присутсвия в коде кнострукций void a(){ return 1;}
/* This is an open source non-commercial project. Dear PVS-Studio, please check it. * PVS-Studio Static Code Analyzer for C, C++ and C#: http://www.viva64.com */
Замечу, утилита для вставки комментариев так не умеет. Поэтому надо либо вставить комментарии вручную, либо доработать утилиту (на github доступен её исходный код).
Однозначно разумный и честный подход! Моё глубокое вам уважение!
Это, собственно, очень хороший первичный тест: если ваше начальство не знает о том, что «прайс по запросу» — это типичный способ продажи корпоративного софта и его практикуют, в частности, такие «мелкие китайские лавочки» как IBM или SAP, а также и конкуренты обсуждаемого здесь продукта, то, в общем, вам стоит сначала об этом с начальством поговорить, а не учить весь мир — как ему следует жить?
Я не понимаю зачем так делать? Чтобы каждому клиенту разные ценники выставлять?Именно. Я читал, что такое практикуется в Китае в ресторанчиках, куда захаживает, как местное население, так и туристы. Фиксированной цены в меню нет. Цена зависит от прикидки «на глазок» платежеспособности клиента. Более «продвинутые» китайцы делают два меню:
Некоторые рестораны (особенно часто мы это наблюдали в городе Санья, остров Хайнань) имеют меню на русском или английском языках. Такое меню ориентировано на иностранных гостей, но цены в нем завышены. Причем иногда в два раза. Заметив такое «кидалово», мой супруг, прищурившись, смотрит на официанта и просит «другое» меню.
Чтобы каждому клиенту разные ценники выставлять?
Если один клиент готов описывать свою проблему в письме на русском языке и ожидать ответ в течении суток, то разумеется цена поддержки для него будет отличатся от цены того кто хочет получить ответ немедленно, по телефону и на чистом мандаринском.
Не существует 2-х одинаковых крупных компаний (а на них и рассчитан данный инструмент) и процесс разработки у них поставлен по разному, при этом они хотят добавить продукт стат. анализа не изменяя данные процессы. В итоге ценник за внедрение у разных заказчиков будет разный.
Честные — это плата за рабочие места, за объем проверяемого кода, за дополнительные возможности программы, за скорость поддержки. Честные — описываются в прайсе.
А нечестные — это когда прайса нет, а есть оценка платежеспособности клиента.
Отдельно стоит продажа заказных и полузаказных решений. Когда продукт подтачивается напильником под клиента — да, цены разные, в зависимости от длины напильника.
Но у вас-то хотят узнать цены на коробочное решение. Ну если оно у вас есть, конечно.
Потому как из-за отсутствия прайса — впечатление хреновое. То ли обдерут как липку, то ли у людей нету продукта, а есть полузаказные (исследовательские) варианты программы.
то ли у людей нету продукта
Зайдите в раздел Downloads и скачайте. Сможете понять, продукт это или не продукт.
Если внедрение требует усилий от вас(и только от вас) — это не продукт.
А у вас, я так понимаю, приходится подпиливать код под заказчика. Что и означает, что программа у вас есть, а комплексного программного продукта нет.
Видели компилятор, который подпиливается под заказчика? Такой компилятор — не продукт, а решение. И прайс на него зависит от времени на допилку. Но большинство компиляторов — коробочные продукты. И подпиливания под заказчика не требуют.
P.S. Интересно, вы вспомните хоть один пример компилятора, подпиливаемого под заказчика?
P.S. Интересно, вы вспомните хоть один пример компилятора, подпиливаемого под заказчикаЛегко. ICC, SCC. Cygnus Solutions на этом специализировались (и да, скачать с сайта у них можно было весьма небольшую часть того, что можно было купить). Со временем, правда, компиляторы стали более «коробочными» — я знаю что пять лет назад они ещё вовсю пилились под конкретных заказчиков, но не знаю — пилятся ли всё ещё сейчас…
Но, повторюсь, это не продукты, а решения. Чуть иная категория.
При этом убрать ложные часть ложных срабатываний они могут конфигурированием, а часть — требует дописывания (расширения) конфигурирования.
Ну как пример, что мы используем
#define CCASSERT(predicate) _x_CCASSERT_LINE(predicate, __LINE__)
#define _x_CCASSERT_LINE(predicate, line) _x_CCASSERT_LINE_CAT(predicate,line)
// cppcheck-suppress variableScope
#define _x_CCASSERT_LINE_CAT(predicate, line) \
typedef char constraint_violated_on_line_##line [2*((predicate)!=0)-1];
Это assert, работающий в compile-time. И подавление диагностики от cppcheck там не спроста. Но если вместо настройки макроопредений под систему статического анализа они пытаются сделать наоборот (настроить систему статанализа под используемые макро) регулярное добавление ручек в в конфиг является неизбежным…
Мой совет — спросите их напрямую, может быть расскажут… я лично сужу по куче признаков, начиная с конской цены в 25 миллионов рублей (информация с тех времен, когда они ещё цену не скрывали). Ну и см выше об отдельной цене для каждого заказчика.
я лично сужу по куче признаков, начиная с конской цены в 25 миллионов рублей (информация с тех времен, когда они ещё цену не скрывали)

В PVS-studio можно подавлять предупреждения комментариями.
Тогда я вас не понимаю. Что вам не нравится-то?
Нет, это вам в другой ветке не нравится. Тут вы говорили про подавление предупреждений.
Ну тогда почитайте, что пишут авторы PVS-Studio. Собственно я всего лишь попытался конкретизировать их слова
Наличие дистрибутива и кнопки «выполнить анализ», не гарантирует что всё у всех получится, и вот здесь и нужна поддержка. И дело не в том, что мы криворуки. Статический анализатор — это сложный продукт. И как следствие есть масса нюансов, которые невозможно учесть.
Это авторы PVS-studio считают, что нужно подтачивать их программу напильником, а не я. я всего лишь пояснил, в каких местах её, скорее всего, точат.
Или как постоянные посетители бара «Голубая устрица» компания Оракл — чтобы скачать что-то надо сперва зарегистрироваться на сайте, при попытке регистрации должно сперва письмо придти для окончания регистрации, а письмо-то и не приходит…
зы: хочу PVC studio для эмбеда (БЕЗ Visual Studio)
P.S. PVS-Studio без VS уже давно есть :)
Когда ты видишь, что SpaceX запросто указывает цены на свои ракеты-носители, понимаешь, насколько смехотворна эта «нормальная стандартная практика».
— Хотим вот эту позицию (тычет пальцем в прайс), плюс вот это, это и это. И чтобы ещё всё застраховано было по максимальному тарифу. Ах да, и ещё хотим контролировать каждый ваш чих в момент предоставления услуги.
— Не вопрос. Тогда цена будет вот такая.
— По рукам.
Так может попробуете «сломать систему» еще разок и сформировать подход при котором потенциальный клиент может заранее оценить затраты на внедрение?
От второго вы смогли отойти, попробуйте отойти и от первого.
Если у Вас есть интерес к PVS-Studio, то напишите с корпоративной почты и узнаете цены, секрета в них нет. А если интереса нет, то какая разница, указаны они на сайте или нет.
потому что не хочется быть лохом и покупать втридорога.
А искать ваших клиентов — откровенно лень. Потому, если уж покупать продукт для статического анализа — то не у вас, а у фирм, не скрывающих сои прайсы.
а у фирм, не скрывающих сои прайсы.
Жаль таких фирм почти нет.
… ну в общем все, у кого есть продуктовое решение, не требующее подтачивания напильником под клиента.
Сразу видно теоретика. Вам просто не нужно, вот и все.
Поэтому работаем по-старинке — код периодически компилируется дюжиной компиляторов под полудюжину операционок.
Ну и опять-таки, отпугивает необходимость адаптировать код PVS-studio под каждый проект.
Т.е. по вашему и покупателям IntelliJ CLion анализ не нужен, коли ваш продукт не покупают? Я конечно им не пользовался (на c/c++ не пишу), но сомневаюсь, что в этом продукте JetBrains отступились от своей практики внедрения он-лайн статического анализа с быстрыми проверками и возможностью более полного статического анализа по запросу…
с ним только одна проблема — это побочный клиент-сайд функционал
Прочитал статью на сайте обрадовался! Попытаюсь с ней разобраться. Спасибо за замечательный инструмент.
А для корпорации сам факт того, что подобный «обработанный файл» может случайно попасть в репозиторий и потом всплыть где-нибудь в суде — хороший повод так не играться.
А если серьезно, то мы отлично понимаем, что систему можно обойти. Более того, её легко было обойти и раньше. Вся идея в том, что тот, кто готов заниматься подобным не является нашим клиентом. Есть компании, которые умеют ценить время и понимают, что приобретают не только программу, но и сопровождение, что крайне важно в больших и сложных проектах. На них мы и ориентируемся.
А по-факту, скрипт, который добавляет-удаляет всё, что нужно, я сваяю левой ногой минут за пять, а потом повешу pre-commit hook-ом (или как там оно называется), и мне даже хоткей никакой нажимать не придётся.
Не забудьте на гитхаб выложить и опубликовать ссылку! :)
Знаете, написать приложеньку для такого трюка стоит по времени гораздо дешевле, чем стоимость годовой лицензии на человека (в составе команды из 10 человек). Впрочем, в моей, например, компании, даже и в git это можно было бы залить без проблем. Но совесть. Поэтому сидим без лицензии (один год попользовались, профит меньше ожидаемого, продлевать не стали).
По-моему, вашу — действительно очень здравую и хорошую — задумку с бесплатным использованием лучше продвигать и обсуждать в терминах совести, а не игры в кошки-мышки.
Вывод — без поддержки вы не обойдетесь. Ну, или по крайней мере дорого выйдет самим колупаться. Логические бомбы — они такие
Казалось бы, если продукт содержит логические бомбы и с ним нельзя работать без постоянной поддержки, то его качество вызывает большие сомнения и покупать его себе дороже.
При этом мой небольшой опыт работы с PVS Studio говорит, что это вполне нормальный подукт, которым можно пользоваться без посторонней помощи. Отсюда вопрос — что именно входит в ту поддержку, без которой не обойтись, какие операции, какая помощь? Может, я пропустил какие-то важные ее возможности, с которыми от студии был бы гораздо больший профит?
Спасибо, прочел. Не лишено смысла, но пара ссылок на документацию — это явно не та поддержка. которая требуется годами. В целом, аргументация "почему у нас подписочная модель оплаты" у PVS очень слабая (поддержка, добавление новых правил, ...) и искусственная, призванная заменить настоящую мотивацию "нам надо больше денег". Поэтому дальше обсуждать ее, наверное, бесполезно.
Да ну ладно вам. Я от мира С очень далёк, но я напишу такой скрипт, ну, скажем, за два часа. Это сколько-то тысяч рублей. На этом я сэкономлю компании все деньги на покупку вашего продукта. Я это даже чисто из любви к компании могу сделать, в свободное время, просто потому что для меня это интересный челлендж. И цена моего времени вообще ни при чём тут.
С другой же стороны, эффективные менеджеры слыхом не слыхивали ни про какое PVS-Studio, а ещё меньше того про него слышал юридический отдел. Надо переговорить с начальником, замначальника, начальником начальника, представителем юридического отдела, написать заявление от руки в пяти экземплярах, подписать, пере-подписать, размножить, подшить, отксерить, похерить, вот это вот всё, уйдут годы на эту деятельность, которой нормальный разработчик вряд ли желает заниматься. Даже в лучшем случае, когда просто говоришь своему менеджеру, чего ты хочешь, это ждать, ждать, ждать, пока он ответит (если ещё не забудет). Вот с этой стороны да — несложное техническое решение, и сразу играйся с цацкой.
Зачастую вообще боятся бесплатного ПО (да, именно бесплатного, безо всяких ограничений) из соображений «а вот как бы чего не вышло», типа у них на душе неспокойно, пока за него денег кому-то не занесли
Все проще. У больших контор там (там), как правило, процессы зрелые, деньги посчитаны, и есть такая штука — операционные риски. И один из рисков — ПО, которое развернуто без наличия поддержки. Это риск. Вдруг в один прекрасный день обнаружится баг, уязвимость, и прочие радости мира ПО. И остановится какой-то важный процесс, компания будет терять реальные деньги. В результате, появляется требование — любое ПО должно иметь поддержку. Очевидно, у бесплатного, поддержки скорее всего не будет. И второе требование, поставщик поддержки — не компания-однодневка.
Кстати, в связи с этим и процветают конторы типа Red Hat и т.д.
К счастью, или к сожалению, за операционные риски отвечает чувак, как правило, далекий от ИТ. Этот умный чувак пишет правила. Задача всех прочих, в том числе ИТ-шников, эти правила соблюдать. Написали: все ПО должно быть с поддержкой, это значит все (все) ПО должны быть с поддержкой.
Авторы PVS пробуют еще один канал продажи. Больше каналов хороших и полезных!
И зачем тогда так извращаются герои статьи, если все, кто могут заплатить, и так заплатят?Затем что при работе в больших компаниях «здравый смысл» часто можно оставить за дверью.
Есть один отдел — он считает риски. И с его точки зрения продукт (тем более бесплатный) от фирмы-однодневки — страшный риск.
Есть другой отдел — он отвечает за закупки. И старается закупать, разумеется, подешевше (а как иначе?). Может и бесплатную версию за'approve'ить, если фирма уже первым отделом одобрена.
А у PVS'ников задача — пройти их все и получить денег, однако…
Для небольших групп можно сделать как у Unreal Engine, типо в проектах с прибылью до скольки то там, юзай бесплатно, как превысил — отчисляй пенни.
Unity требует покупки Pro лицензий, если годовой доход организации превышает $200k. Не знаю, как они проверяют и проверяют ли вообще, но смысл в том, что им не важно, чем занимается контора.
Контора может
- делать продукты на Unity и продавать;
- раздавать их даром, зарабатывая на рекламе или поддержке;
- использовать Unity для каких-то внутренних целей (обучение сотрудников, хз);
- жить пожертвования пользователей или получать деньги из гос. бюджета.
Вообще не важно, откуда берутся деньги, но если откуда-то всё-таки берутся, изволь купить лицензии.
Меня, как независимого разработчика под лин, это устраивает почти на 100%.
А с заказчиками по поводу «лишних строк в начале файла» договориться не сложно: внести допусловие в стандартный договори и/или озвучить цену того, чтоб этих строк не было. :)
Единственная просьба, разрешите, чтоб эти сроки были не первые в файле, просто в пределах «шапки», в пределах ~20 строк, например. Все же, информация о разработчике и владельце прав на код важнее, имхо.
Тогда давайте проясним один момент. Допустимо ли, с Вашей точки зрения, удаление «шапки» после окончания разработки?
Еще одним примером является момент запуска продукта в серию.
Вот у PVS-Studio окончание разработки — это когда продукт на кладбище окажется, как мне кажется. А у вас как?
«Пользуетесь PVS-Studio — вставляйте комментарии. Перестали пользоваться — можно удалить.»?
— Право, я боюсь на первых-то порах, чтобы как-нибудь не понести убытку. Может быть, ты, отец мой, меня обманываешь, а они того… они больше как-нибудь стоят.
Понятна вполне ваша боязнь понести убытку, но ответить-то можно на поставленный конкретный ответ, а не изворачиваться, как аскариды в прямой кишке?
Проекты они разные бывают. Бывают, внезапно, и со статическим и полным ТЗ. ТЗ выполнил — работа окончена, код изменениям более не подвергается.
/* -*- mode: c++; coding: windows-1251-dos; fill-column:160 -*- */
Это некий компромиссc между удобством на Windows и linux. На Windows — удобнее комментарии в 1251, на линуск — в UTF-8. вот и приходится сообщать редактору о кодировке файла.
Qt Creater вроде как только в utf работает. Visual Studio тоже без разницы, в локальной там или в utf'е, главное, чтобы BOM был. Если какие-то среды, которые BOM в файлах не понимают?
А кто ещё может брейкопйнты на изменение значений, просмотр структур с изменением их полей и так далее??? Ну Qt Creator советуют посмотреть, а кого ещё?
Работает-то оно под linux в основном. А отладка комфортнее на винде.
А кто ещё может брейкопйнты на изменение значений, просмотр структур с изменением их полей и так далее??? Ну Qt Creator советуют посмотреть, а кого ещё?
Вы не поверите, лучшая иде всех времён и народов, ака Visual Studio, это всё умеет уже лет как N'дцать. Qt creater в плане удобства отладки, даже рядом не валялся.
Кстати, советую, ещё https://blogs.msdn.microsoft.com/vcblog/2016/07/11/debugging-tips-and-tricks-for-c-in-visual-studio/ прочитать/посмотреть, может там что заинтересует ещё, а вот например Parallel Stacks так для себя открыл, уже пару раз реально помогло.
P.S. Примите соболезнования по поводу необходимости работать в иде и с компилятором 2000-го года выпуска. Может вам стоит совершить сумасбродство, и перейти на C++ Builder 6.0? :)
Вы не поверите, лучшая иде всех времён и народов, ака Visual Studio, это всё умеет уже лет как N'дцать
Почитал. Аппаратные брекопоинты — явно недоделанные. Мало того, что их нет для Си, так ещё и вручную считать размер данных. И пересчитать адрес после перекомпиляции автоматически он сам не может.
Окна для изменения данных в структуре — просто нет. И даже не вижу окна для просмотра структуры с разворачиваем и сворачиваем её подструктур…
Окна регистров FPU тоже не вижу. Не говорю уже о том, что для VS++ POSIX — это оbsolete. Короче, отказать. Глючный и очень неудобный.
У коллег в VS++ только debug-сборка работает. В релизе у них просто не собирается… Ну в общем VS++ — для тех, кто не видел возможности удобных отладчиков.
Примите соболезнования по поводу необходимости работать в иде и с компилятором 2000-го года выпуска.
Вообще-то, BC++ 3.1 — 1992ого года. А что вас так удивляет? Новое дороже и тормозней, но с чего вы взяли, что оно удобней? Не говоря уже о том, что вряд ли вы найдете компилятор под MS-DOS новее 1995ого года.
Может вам стоит совершить сумасбродство, и перейти на C++ Builder 6.0? :)
Зачем? Назовите хоть один важный для меня плюс. А важных минусов — много.
Главный минус — Kylix, то есть CLX. Это потребовало перетряски VCL, в итоге что Delphi 6, что C++ Builder 6 — основано на прилично забагованной библиотеке.
В семерке стало получше, но вмешалась кадровая ошибка. В ядро VCL пустили человека, плохо понимающего работу в многопоточной среде. Итогом стало несколько неприятных ошибок.
Мы купили 10.1 Berlin, но я пока его не смотрел. Из очевидных минусов — gcc в качестве компилятора. А чем больше разных компиляторов — тем проще с портируемостью.
У коллег в VS++ только debug-сборка работает. В релизе у них просто не собирается…
Самая глупая отмазка из тех которые я видел. Если кто-то перемудрил с директивами условной компиляции — это не является недостатком ни IDE, ни компилятора.
Ошибки компиляции надо взять и исправить.
Ошибки компиляции надо взять и исправить.
Ну-ну… Скачайте и разберитесь.
я понимаю, вы не занимаетесь АСУТП. Но подумайте о том, что баги в продуктах мирософта видели все. Ни о какой надежности там речи не идет, зато ИнСат — это работа на рынке, где требуется очень высокая надежность. Это защиты АЭС, это автоматизация котла ТЭЦ (а современный котле без автоматики или тухнет ил взрывается), это автоматизация изготовления сопел ракет, это климат-контроль на производстве банковских карт., это автоматизация компрессорной магистрального газопровода, это мониторинг теплоснабжения миллионного города…
Так что уж извините, но ИнСат писать код умеет. Потому что о багах и в их продуктах я не слышал.
Может быть, вы круче их и сумеете решить эту проблему. Но скорее всего это очередное
Чтобы никогда не использовать VC++ мне хватает того, что они объявили POSIX obsolete и ввели свои, нестандартные вызовы. Поскольку целевой системой у нас Linux и FreeRTOS, То проще уж отлаживаться там, где POSIX не вызывает таких проблем.
Собственно это повтор истории про осла. Когда IE захватил рынок, он диктовал свои стандарты. Ну и где он сейчас?
Может быть, вы круче их и сумеете решить эту проблему. Но скорее всего это очередное дурацкое ограничение у микрософта — EXE, рассчитанный на подключение dll отладочной сборки, не может подключить dll релизной сборки. Хотя в других системах это проблем не вызывает.
Это не "дурацкое ограничение", а конфликт зависимостей. До тех пор, пока отладочный рантайм и релизный рантайм — это две разных библиотеки, проблема будет существовать.
Решается она, кстати, очень просто. Например, принудительным использованием нужной версии рантайма.
Но скорее всего это очередное дурацкое ограничение у микрософта — EXE, рассчитанный на подключение dll отладочной сборки, не может подключить dll релизной сборки
Ну, если вы так изначально рассчитывали, что же потом удивляетесь?
Вот если бы не хотели такого ограничения, то написали бы сразу exe, который рассчитывает, что ему пофигу с какой dll работать — с релизной или с дебажной. :-).
А если серьёзно, то у майкрософт таких ограничений, конечно же нет, это вы придумали. Вот гляньте на ffmpeg, например. Ты собрал dll'ки, хоть в релизе, хоть в дебаге, хоть другим компилятором, например интеловским. И дальше используй хоть в релизном, хоть в дебажном exe'шнике.
Чтобы никогда не использовать VC++ мне хватает того, что они объявили POSIX obsolete и ввели свои, нестандартные вызовы. Поскольку целевой системой у нас Linux и FreeRTOS, То проще уж отлаживаться там, где POSIX не вызывает таких проблем.
Я уже писал выше, что вы всё перепутали, и майкрософт наоборот, вместо нестандартных платформозависимых POSIX функций, ввела обычные стандартные, прямо из ISO C++, функции.
Так вот, в стандарте C++ нет ничего, например, про strcmpi. Но есть _strcmpi. Поэтому VS честно предупредит, если вы используете этот анахронизм. И да, как вы понимаете, я не говорю не про C++98, где strcmpi — это норма. Ну что же, за 19 лет мир немного поменялся.
Собственно это повтор истории про осла. Когда IE захватил рынок, он диктовал свои стандарты. Ну и где он сейчас?
А это к чему? Компилятор от MS сейчас вролне поддерживает стандарты C++. Да есть свои extension'ы, но ИМХО, в том же gcc их уже больше :-). А так, например VS 2013 поддерживала C++11 лучше, чем скажем вышедший одновременно Intel composer 2013.
Но подумайте о том, что баги в продуктах мирософта видели все. Ни о какой надежности там речи не идет, зато ИнСат — это работа на рынке, где требуется очень высокая надежность. Это защиты АЭС, это автоматизация котла ТЭЦ (а современный котле без автоматики или тухнет ил взрывается), это автоматизация изготовления сопел ракет, это климат-контроль на производстве банковских карт., это автоматизация компрессорной магистрального газопровода, это мониторинг теплоснабжения миллионного города…
Так что уж извините, но ИнСат писать код умеет. Потому что о багах и в их продуктах я не слышал.
Я скажу так, не бывает идеальных программ без багов, так как не бывает идеальных аналитиков, которые написали бы ТЗ без противоречий, не существует идеальных системных архитектов, не бывает идеальных программистов, которые написали бы код без багов, не бывает идеальных тестеров, которые не пропустили бы ни одной баги, и т.д…
То, что баги есть — это нормально, это надо понимать. Да что там, я лично более 2-х десятков багов репортил на vs connect. А вот то, что вы не слышали не про одну багу в продуктах ИНСАТ или любой другой компании, это не значит, что их там нет. У нас вот в компании тоже половина программистов свято уверена, что у наших клиентов нет никаких проблем, типа это они круто пишут, что багов мало, а те что есть, типа все находятся тестированием. А когда периодически всплывает, что дня без клиентской проблемы не обходится, так делают круглые глаза. Я к тому, что неспособность скомпилировать свой же код в релизе — говорит о многом. Я бы не хотел работать с такими партнёрами, чтобы они для меня код писали. И да, у меня соседний департамент имеет схожую проблему, они не умеют собирать дебажные сборки. Так что о проблеме, её источнике, и т.д., я знаю не понаслышке.
Мир АСУТП и embeded -это несколько иной мир, чем мир visual studio. За программу типа Word, падающую при ошибке в любой части без сохранения данных, в АСУТП бы оторвали… Ну в общем что оторвали, то бы и оторвали.
Но если нужен ответ именно в комменте — я отвечу.
А кто вам сказал, что они несовместимы?
До тех пор, пока отладочный рантайм и релизный рантайм — это две разных библиотеки, проблема будет существовать.
Всё остальное — спор о терминах. я в нем участвовать не хочу.
Отладочный рантайм и релизный рантайм — это две разных совместимых библиотеки
Это совсем иная ситуация, чем два разных варианта одной библиотеки, собранные из одних и тех же сорцов и отличающихся лишь ключами компиляции. А совсем уж сильное отличие от ситуации, когда две библиотеки отличаются лишь отладочной информацией.
Для доказательства несовместимости — достаточно одной ситуации, где библиотеки не взаимозаменяемы. Искомая ситуация описана выше. Если программа, собранная для одного из рантаймов не может вызвать dll с другим рантаймом — значит они несовместимы. Были бы совместмы -легко бы совмещались в одном проекте.
Кстати, это именно тот случай когда «два разных варианта одной библиотеки, собранные из одних и тех же сорцов и отличающихся лишь ключами компиляции».
А так как, что это 2 разные библиотеки — это не бага, как пытается jef представить, а фича! Да, если для тебя это «большая, реальная» проблема, что не хочется иметь 2 набора бинарников — не используй это. А так дебажный рантайм даёт много полезных фич нужный для отладки (на например, там при каждой деаллокации памяти куча проверяется по этому адресу, или итераторы чекаются, что они в валидном слейте. То же со строками, например, в дебаге, там даже в обычном std::string'е новые мемберы появляются, нужные для последующей фоновой валидации строк).
Если вам не нужны все эти возможности, потому что вы не можете их осились/понять/другая_надуманная_причина, то не используйте эту фичу. Собирайте свой код без оптимизации, и отлаживайтесь на нём. Тогда у вас будет только одна версия crt и cprt.
Кстати, это именно тот случай когда «два разных варианта одной библиотеки, собранные из одних и тех же сорцов и отличающихся лишь ключами компиляции».
А так дебажный рантайм даёт много полезных фич нужный для отладки (на например, там при каждой деаллокации памяти куча проверяется по этому адресу, или итераторы чекаются, что они в валидном слейте. То же со строками, например, в дебаге, там даже в обычном std::string'е новые мемберы появляются, нужные для последующей фоновой валидации строк).
Нетрудно догадаться, что или одно или другое. Но не оба вместе.
скорее всего там много #ifdef, то есть сорцы одни, но отличия — совсем не только в ключах компиляции, а ещё и в дефайнах сборки
Ну и регулярно вижу споры «эта фича не нужна, потому что студия её не умеет». Не, я лучше буду там, где умеют все, что нужно.
При этом вполне допускаю, что в иных задачах — VC++ лучше всех. Ну скажем драйвер windows я бы на нём писал, несмотря на все его неудобства.
При этом в варианте «как все» часто вижу стон «в релизе не пашет, в дебаг все хорошо». Уж на что я далек от форумов по VC++, но даже до меня этот стон долетал.
Ещё раз повторю свой совет: меньше случать горе-партнёров-коллег, интернет и бабок у подъезда. Лучше сперва попробовать самому и сформировать своё личное мнение.
«в релизе не пашет, в дебаг все хорошо»
Этот стон, если и раздаётся, то на порядки реже, чем стон «у меня на компе работает, а у тестеров нет» или «у нас в лабе работает, а у клиента нет». При этом если стонет человек адекватный, и он понимает, что тестеры тестирует на 20 ядерном ксеоне, а он на 4-х ядерном проце, то он просто идёт и начинает искать, например, race condition.
Ну и регулярно вижу споры «эта фича не нужна, потому что студия её не умеет». Не, я лучше буду там, где умеют все, что нужно.
Я вот уверен, что студия умеет гораздо больше стандартного, чем любой другой 19-ти летний компилятор, и в обратном вы меня не убедите. Ваши споршики видимо мало отличаются от ваших партнёров (может это они же?) :-)
При этом вполне допускаю, что в иных задачах — VC++ лучше всех. Ну скажем драйвер windows я бы на нём писал, несмотря на все его неудобства.
Ну хоть на этом спасибо :-).
Лучше сперва попробовать самому и сформировать своё личное мнение.
Увы, по правилам хабра мат запрещен. А без обсценной лексики личное мнение о VС++ не излагается :-) Увы, пробовал я эту поделку…
«у нас в лабе работает, а у клиента нет».
Ну чтобы понять, что делает клиент, надо зело великую фантазию иметь… я когда был главным альфатестером T-Mail такого навидался… Ну вроде FIDO не совсем для чайников, но корректно описывают баги единицы.
«у меня на компе работает, а у тестеров нет»
А это качество работы тестеров. Пример. Тыкаю мышкой — баг 100%. Тыкает мышкой второй тестер (@yole) — 50%баг. Тыкает мышкой автор — нету бага. Оказалось, что для бага надо было в однопиксельную полоску попасть.
Я вот уверен, что студия умеет гораздо больше стандартного,
я сказал нужного. А то, что мои задачи нестандартные — это факт.
При этом в варианте «как все» часто вижу стон «в релизе не пашет, в дебаг все хорошо»Это вы что-то с чем-то путаете. Можете писать код в gcc и запускать его только с -O0, а потом попытаться оптимизации включить. Скажите «ССЗБ»? И будете правы. Только почему-то в случае с GCC это [справедливо] считается проблмой кривых рук программиста, а в случае с Visual Studio — это, типа, проблема компилятора. Проблемой «другого рантайма» это является в лучшем случае в одном случае из 100.
Ещё раз: попробуйте поработать с Visual Studio — а уже потом сказки рассказывать.
Со студией я немного работал, мнение нецензурное.
выдавать релиз без всяких лишних проверок.
Без тестирования, ага. А ещё у меня есть коллега джавист, так он говорит, что после него код вообще тестировать не надо, если он закоммител, то сразу можно клиенту ставить. Только причём тут C++, VC++ и т.д. если проблема в мозгах?
Ладно, извиняюсь, на сегодня хватит бреда.
Проекты Visual Studio имеют отдельные конфигурации выпуска и отладки для вашей программы. Как следует из самих названий, производится построение отладочной версии для отладки и версии выпуска для окончательного выпуска программы.
Как думаете откуда эта кривь? А это из MSDN. Ну да, строго формально это связано не с самой студией, а с её документацией микрософтом. И дальше эта кривь копируется большинством учебников по VC++.
И где кривь то? Отлаживаем/разрабатываем на дебаге, тестируем/деплоим релиз.
Это и есть кривь. Если фирма большая, есть отдельный отдел тестирования, то есть и некоторая культура программирования. А если фирма мелкая, то тестирование совмещено с отладкой. И получается кривь: тестируем и отлаживаемся на debug. а в деплоим релиз.
Вы поспрашивайте джуниоров — многие ли отличают тестирование от отладки?
В любом случае, схема дебуг-релиз производит менее надежные приложения, чем когда отладка идет на единой, релизной версии. Есть некоторое количество тонких проблем, видимых лишь под отладчиком.
Поэтому там, где требуется надежность — отладка идет на единой версии. И включение-выключение отладочных функций делается не перекомпиляцией, а командой программе.
Более того, делается удаленное управление, чтобы не ехать за пару тысяч километров, а из конторы (или из дома) залезть в сбоящий прибор, посмотреть, что там происходит и подправить конфигурацию. А в конфигурации — некоторое количество ручек, делающих плавную деградацию. И возможность дистанционного обновления прошивки.
Вся беда в том, что у тестеров нету собственного завода, ТЭЦ, лефортовского тунеля, корабля, близости к Сирии… у тестеров — имитаторы. А основной этап тестирования называется опытная эксплуатация и делается у заказчика.
Мой коллега (переманилии!!!) — создатель одного из фоторадаров. Так вот, он хвалится, что потребность поехать и дернуть питания была всего лишь один раз на несколько тысяч установок. И то, сам виноват, ошибся и загасил установку при ребуте. И даже в этом случае справились местными силами.
И ещё раз дисклеймер. Это У НАС так. У настоящих программистов — иначе. Там, где для тестирования не нужен завод, корабль, локомотив, туннель — там можно и дебаг/релиз применять.
Байка от того же коллеги. Опытная эксплуатация, Лефортовский туннель. Фоторадар показывает 320 километров в час, программер судорожно думает, где же он посадил багу в коде. Сообщение от гайцев: не ищите багу, козел реально с такой скоростью летел. :-) Ну кто из тестеров додумается, что лихач может разогнаться быстрее истребителя на взлете? Так что опытная эксплуатация — главный этап и тестирования и отладки. Все, что до него — это лишь цветочки.
Это и есть кривь.
Это кривь только у вас в голове. Да, если, в компании настолько надёжный код, что тестирует разработчик на своей машине, то тут ничего не поможет. Ну хотят денег на тестировании съэкономить — пусть экономят.
И опять, в дебаге функциональность отлаживать проще: нет оптимизации, видны все переменные, куча дебажных проверок, в том числе на порчу кучи и т.д. При разработке только в релизе, часть проблем может оказаться не найдеными, да и время гораздо больше уйдёт. Да и вообще не верю я в разработку с /O2. Поэтому схема дебуг-релиз производит более надежные приложения. В принципе у нас в компании это очень хорошо видно. Один департамент в одной схеме работает, второй в другой (они не умеют дебаг собирать). Очень хорошо разницу видно.
Полноценное тестирование есть только там, где нету реального мира. А есть искусственный цифровой мир. Который можно скопировать для целей тестирования.
И опять, в дебаге функциональность отлаживать проще
Пьяный мужик что-то ищет под фонарем. Тут к нему под ходит милиционер и
спрашивает: «Что вы тут делаете?» Мужик отвечает: «Ключи от квартиры
ищу». «А где потерял?». «В парке». «А зачем здесь ищешь?».
«А здесь светлее ».
Согласен, проще. В тяжелых случаях используется и перекомпиляция с -O0 и вставка специального отладочного кода.
При разработке только в релизе, часть проблем может оказаться не найдеными, да и время гораздо больше уйдёт.
Так все-таки тестеры у вас работают с дебаг-версией? Или тестирует сам программист? Короче, кто находит проблемы в дебуг-версии?
Да и вообще не верю я в разработку с /O2. Поэтому схема дебуг-релиз производит более надежные приложения.
Только потому, что вы не верите? Мне очень грустно за вас стало…
Один департамент в одной схеме работает, второй в другой (они не умеют дебаг собирать). Очень хорошо разницу видно.
А вы заведите себе третий департамент, который не собирает релиз, а скорости достигает оптимизацией алгоритмов. я же говорил вам, что у нас отладка не выкидывается из продуктов. И ибо продукты проходят опытную эксплуатацию.
а пока такого департамента у вас нету — вы не то сравниваете.
Почитал. Аппаратные брекопоинты — явно недоделанные. Мало того, что их нет для Си, так ещё и вручную считать размер данных. И пересчитать адрес после перекомпиляции автоматически он сам не может.
Скажу честно. Недоделанными их можно назвать, по сравнению с тем, что, например, Windbg умеет. Т.е. да, студия умеет следить только когда значение по некому адресу меняется (это именно то, что вы хотели). А про Си я вообще не понял.
Окна для изменения данных в структуре — просто нет. И даже не вижу окна для просмотра структуры с разворачиваем и сворачиваем её подструктур…
Если вы не видите окна для просмотра структуры, то с вами пока неочём разговаривать. Смотреть и редоктировать данные можно во многих местах (Locals, Watch, да просто навести мышкой на переменную, и смотри/редактируй, сколько влезет.
Окна регистров FPU тоже не вижу.
Оно ещё живо? Ооо.
Не говорю уже о том, что для VS++ POSIX — это оbsolete.
И что такого плохого, что компилятор стал работать согласно стандарту ISO C++, что об этом не стоит говорить? При этом не стандартные имена он так же поддерживает, но честно предупреждает, что если вы хотите, чтобы ваш код соответствовал стандарту и был кросс-платформенным, надо использовать не некие платформо-специфические функции, а их стандартные аналоги.
У коллег в VS++ только debug-сборка работает. В релизе у них просто не собирается…
Ну что, поздравьте ваших коллег.
Ну в общем VS++ — для тех, кто не видел возможности удобных отладчиков.
Вот вы явно со студией не работали нормально (это видно хотя бы по тому, что не знаете как переменные смотреть). Да, что-то прочитали в инете и как-то интерпретировали, что-то в курилки услышали от горе-коллег-партнёров… Поэтому от вас такой вывод странно слышать. Я как активный пользователь VS под винду и QtCreater под линукс (второе только для отладки) могу ответственно заявить, что отлаживаться в студии гораздо удобнее.
Может вам стоит совершить сумасбродство, и перейти на C++ Builder 6.0? :)Зачем? Назовите хоть один важный для меня плюс...
Это я пошутил так.
А чем больше разных компиляторов — тем проще с портируемостью.
Я бы с этим согласился, если бы не то обстоятельство, что один из этих компиляторов даже не знает о существовании C++03, C++11, C++14. Вот сейчас всё просто. Мы когда под gcc портировали с VS2013, там уже такие мелочи оставались… В основном, замена WinAPI'шных функций на std аналоги…
А про Си я вообще не понял.
В MSDN написано, что аппаратные брейкпоинты только для С++, а не для чистого Си. Ну и по сравнению с тем, что я использую сейчас, они недоделанные.
Если вы не видите окна для просмотра структуры, то с вами пока неочём разговаривать. Смотреть и редоктировать данные можно во многих местах
Так покажите мне инспектор структур. Или ссылкой на MSDN или скриншотом. Судя по тому, что вы не понимаете, что это такое — такого окна в VC++ нет.
Почитайте про отладчик Delphi.

Кардинальное отличие инспектора, что он показывает имена полей структуры, а для класса-ещё и имена методов и свойств. Для ответа на вопрос, «в порядке ли данный объект», мне достаточно сделать один клик мышкой с зажатым контролом. А вовсе не добавлять каждое поле объекта в окно Watch.
И что такого плохого, что компилятор стал работать согласно стандарту ISO C++, что об этом не стоит говорить?
Что плохого, что компилятор отказался от международных стандартов ANSI C и POSIX?! Да пусть отказывается, только мы такой компилятор использовать не хотим. Так, по мелочи, плагины написать. На большее он не годится.
если вы хотите, чтобы ваш код соответствовал стандарту и был кросс-платформенным, надо использовать не некие платформо-специфические функции, а их стандартные аналоги.
Вот ровно для этого и придуман POSIX. Это универсальный язык общения с OS. И большая беда Windows, что POSIX подсистема в ней была не развита. В итоге в Win10 пришлось добавлять ядро линукс в режиме виртуальной машины.
Ну что, поздравьте ваших коллег.
Уже написали, что это design-баг. Ну или багофича.
Вот вы явно со студией не работали нормально (это видно хотя бы по тому, что не знаете как переменные смотреть
Как переменные смотреть, я знаю… А вот как смотреть поля структуры или элементы связанного списка — нет. Рассказывайте. А что я мало работал со студией — это факт. я стараюсь работать с удобными продуктами. Поработай с Delphi — поймете, что такое удобный отладчик.
Я бы с этим согласился, если бы не то обстоятельство, что один из этих компиляторов даже не знает о существовании C++03, C++11, C++14.
А зачем нам они? Где в них киллер-фичи, которые заставят нас отказатьсяот потенциальных военных заказов? А военный заказ — это МСВС 3.0 с gcc 2.95.4. И полный запрет на установку и запуск любых программ, кроме собранных на МСВС из собственных исходных кодов.
Ну ладно, откажемся мы от военных заказов. От embeded нам тоже отказаться? Какие из ваших киллер-фичей влезут в 64 килобайта ПЗУ? А в такое же количество ОЗУ?
Мы пишем на Си с отдельными элементами С++. Сейчас я отлаживаюсь на довольно мощной машинке, у которой 192 килобайта ОЗУ и 512 ПЗУ. При этом у меня 8 килобайт кучи. Какие киллер-фичи новых версий С++ не вызовут фрагментации при 10 килобайтах кучи, из которых после начального захвата свободно 2 килобайта?
Если вы такие киллер-фичи знаете, то рассказывайте. В исходном С++ такой фичей были классы, ссылки и комментарии через //. А что полезного для нас добавили в новых версиях?
В MSDN написано, что аппаратные брейкпоинты только для С++, а не для чистого Си. Ну и по сравнению с тем, что я использую сейчас, они недоделанные.
Аппаратный брекпоинт ставится на адрес. Обычный нативный адрес. Там хоть на ассемблере программу пиши. Бряка поставится и сработает. Рекомендую, прежде чем судить о студии, всё таки попробовать сперва её поближе, не на уровне скриншотов.
Так покажите мне инспектор структур. Или ссылкой на MSDN или скриншотом. Судя по тому, что вы не понимаете, что это такое — такого окна в VC++ нет.
Я так и не особо понял, что вы хотите, может что-то такое?
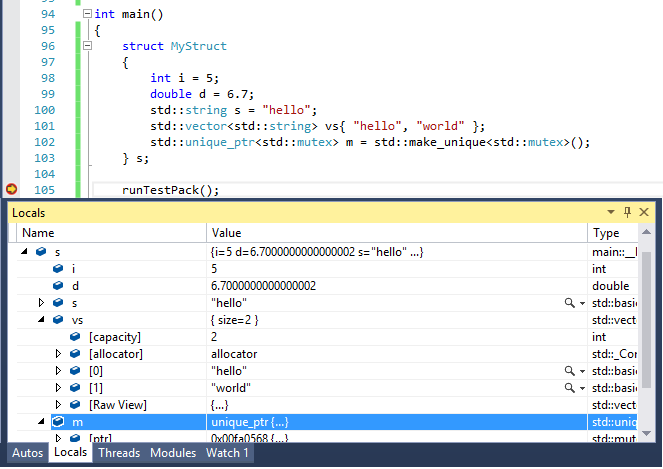
Для ответа на вопрос, «в порядке ли данный объект», мне достаточно просто навести мышкой на переменную. А вовсе не зажимать контрол. И вовсе не добавлять каждое поле объекта в окно Watch (дикость какая).
Что плохого, что компилятор отказался от международных стандартов ANSI C и POSIX?! Да пусть отказывается, только мы такой компилятор использовать не хотим. Так, по мелочи, плагины написать. На большее он не годится.
Вы так и не сказали, что плохого в том, что компилятор C++ отказался от стандартов других языков и от стандартов для операционных систем в пользу стандарта своего языка? Я ещё раз приведу в пример strcmpi/stricmp. О нём в стандарте С99, например, тоже нет не слова. Потому что нет требований ни к одному из компиляторов эту функцию реализовывать. А вот операционная система должна реализовать такую системную функцию, иначе она не будет POSIX-системой. Т.е. здесь наоборот, переход от платформозависиой реализации к стандарту. Т.е. когда вы напишите stricmp, то это скомпилиться, заработает только на POSIX системах (на самом деле в POSIX её уже вроде как выкинули лет 15 назад, в пользу strcasecmp). Тоже самое с strdup, например. Ну нет в стандартах C и C++ этой функции. И даже более. В стандарте C написано, что функции которые начинаются с «str» зарезервированы, и их нельзя использовать. Но так как Майкрософт решила, что пусть функции можно не реализовывать, но они могут пригодиться клиентам, то она их оставила, но с именами, которые не конфликтуют со стандартом (префикс _ — это индикация, что это майкрософт-специфик). Открою ещё один секрет, gcc, например, тоже не реализовывает stricmp.
Вот ровно для этого и придуман POSIX. Это универсальный язык общения с OS. И большая беда Windows, что POSIX подсистема в ней была не развита. В итоге в Win10 пришлось добавлять ядро линукс в режиме виртуальной машины.
Вот я вообще не понял, для чего вы это написали. Есть стандарт для операционной системы, есть стандарты для языков, со своими стандартными библиотеками. Это разная вещь. Или вы предлагаете весь glibc запихать в ядро? А так да, каждая операционка предоставляет свой API, и вопрос какое api лучше: WinAPI или POSIX или ещё какое, к вопросу о компилятору языка отношения не имеет вообще.
Ну что, поздравьте ваших коллег.
Уже написали, что это design-баг. Ну или багофича.
Не понял про design-баг ну или багофичу. А нас это называется другими словами: кривые руки, распиздяйство, несостоятельность, и т.д. Помните, я рассказывал о соседнем департаменте с похожей проблемой? Ну так одного из них, кто нам слишком рьяно доказывал, что им это совершенно невозможно разобраться и поправить, один из нашего департамента однажды назвал жертвой аборта, но это уже слишком грубо на мой взгляд.
Как переменные смотреть, я знаю… А вот как смотреть поля структуры или элементы связанного списка — нет. Рассказывайте.
Рассказываю: просто наведите на переменную мышкой. Всплывёт окно (похожее на locals на скриншоте выше). Если std::vector<> заменить на std::list, то в визуализаторе ничего не поменяется, также все элементы будут видны. Новый скрин не прикладываю, так как там кроде замены vector на list ничего не поменялось. Но! Дальше я рекомендую меньше читать в инете, а больше пробовать самому. Вот попробуйте сами посмотреть как list будет показываться в отладчике.
Поработай с Delphi — поймете, что такое удобный отладчик.
Спасибо, но нет. Я уж лучше на плюсах, по старинке. Или уж на шарпах. Возвращаться к дельфи/билдеру желания нет.
А зачем нам они? Где в них киллер-фичи, которые заставят нас отказатьсяот потенциальных военных заказов? А военный заказ — это МСВС 3.0 с gcc 2.95.4. И полный запрет на установку и запуск любых программ, кроме собранных на МСВС из собственных исходных кодов.
Если верить вики по вашей ссылке, то там везде gcc 4.1 поддерживается. Не густо, конечно, но и не ужас с 2.95. Нам с Astra-linux больше повезло, gcc 4.9, код в бинарном виде сертифицируется, и потом будет ставится. А по поводу киллер-фич, то если вы незнакомы с C++11/C++14, и с тем, насколько сейчас проще и быстрее писать более безопасный код (например, сейчас даже new/delete уже не надо писать в коде), то нам не о чём дальше разговаривать.
Какие из ваших киллер-фичей влезут в 64 килобайта ПЗУ? А в такое же количество ОЗУ?
Большая часть «киллер-фич» — языковые, они не увеличивают кол-во получаемого кода. Например, написание «auto it = » вместо «std::map<std::string, std::vector<std::string>>::const_iterator it = » ну никак не повлияет на размер кода. Тоже и с лямбдами, например, или с rvalue-ссылками.
Мы пишем на Си с отдельными элементами С++. Сейчас я отлаживаюсь на довольно мощной машинке, у которой 192 килобайта ОЗУ и 512 ПЗУ. При этом у меня 8 килобайт кучи. Какие киллер-фичи новых версий С++ не вызовут фрагментации при 10 килобайтах кучи, из которых после начального захвата свободно 2 килобайта?
Вообще ничего не понял про фрагментацию кучи. Это тут при чём?
Аппаратный брекпоинт ставится на адрес. Обычный нативный адрес. Там хоть на ассемблере программу пиши.
Тем страннее ограничение MSDN.
Рекомендую, прежде чем судить о студии, всё таки попробовать сперва её поближе,
Нет, спасибо. Хватило адаптации кода для неё. Боль примерно та же, что и с адаптацией сайта под IE. При этом со всеми остальными компиляторами и операционками — проблем было мало. Даже с WIN32 на linux перешли с меньшей болью, чем при адаптации к VC++
Я так и не особо понял, что вы хотите, может что-то такое?
Уже похоже. А VC++ может иметь 5-7 окон инспектора на экране одновременно (а не рассованные по разным вкладкам)? Иногда есть необходимость сразу несколько структур раскрывать.
Для ответа на вопрос, «в порядке ли данный объект», мне достаточно просто навести мышкой на переменную
я не настолько крут и разобраться в хите длиннее 1024 символов не могу. :-) Особенно, если первые 4К не несут важной информации. :-) Всплывающие подсказки хороши для простых типов, а не для объектов.
А так да, каждая операционка предоставляет свой API
Да нет… Все современные операционки предоставляют POSIX. И только windows — WinAPI. Чтобы выйти за пределы POSIX нужно уж совсем в дебри залезать. Более того, часть POSIX Уже перешла в стандарт языка Си.
Не понял про design-баг ну или багофичу. А нас это называется другими словами: кривые руки, распиздяйство, несостоятельность, и т.д.
Ну вы уже в соседней ветке разобрались. Но с вашей оценкой качества дизайна продукции микрософта я согласен.
Вы так и не сказали, что плохого в том, что компилятор C++ отказался от стандартов других языков и от стандартов для операционных систем в пользу стандарта своего языка?
Все отлично, просто для нас это
Потому что нет требований ни к одному из компиляторов эту функцию реализовывать.
Жалко, что вы не изучали язык FORTRAN. В фортране было разделение между стандартными внутренними функциями, которые могли реализовываться компилятором, и стандартными внешними функциями, которые реализовывались библиотекой.
Так вот, всякие asin никогда компилятором не реализуются. Компилятор может реализовать sqrt или fabs, потому что в сопроцессоре могут быть соответствующие машинные команды.
Открою ещё один секрет, gcc, например, тоже не реализовывает stricmp.
Согласитесь, что кровать — это не холодильник, а библиотека — не компилятор.? Так что открою вам другой секрет — gcc не реализует и strcpy — это делает библиотека. А POSIX-совместимых библиотек весьма много (мы используем glibc, uClibc, Newlib). И все они кроссплатформенные и реализуются на любой нормальной ОС (и даже на части ненормальных. например есть на винде, просто не от микрософта).
и вопрос какое api лучше: WinAPI или POSIX или ещё какое, к вопросу о компилятору языка отношения не имеет вообще.
к нормальному компилятору — да, не имеет. Но вы видели, чтобы VC++ работал не с микрософтовским clibc? Если вы знаете альтернативу — дайте ссылку. Вы же не на пустом месте спутали компилятор с библиотекой. У VC++ библиотека — часть компилятора. Увы, не заменяемая.
Если верить вики по вашей ссылке, то там везде gcc 4.1 поддерживается.
А если почитать внимательно — там gcc 2.95.4. Сертификация идет на конкретную версию МСВС и стоит миллионы. Сертифицировано МСВС 3.0 — или платите миллионы за сертификацию МСВС 5.0 или живите на gcc 2.95.4
то если вы незнакомы с C++11/C++14, и с тем, насколько сейчас проще и быстрее писать более безопасный код (
Увы, знаком. Ничего сильно полезного для нас не вижу. ну попробуйте, найдите хоть одну киллер-фичу.
Например, написание «auto it = » вместо «std::map<std::string, std::vector<std::string>>::const_iterator it = » ну никак не повлияет на размер кода.
я же писал, что на SOC обычно не используют кучу. Так что std::vector нам вообще не нужен. И даже там, где куча есть,, лучше использовать специальные библиотеки для многомерных матриц, чем возиться с std::vector<std::vector<std::vector<std::vector><std::vector>>>> Неужели вы не понимаете, что std::vector придумали для совсем других целей, а не для многомерных массивов. Посмотрите, насколько уродлив код с std::vector<std::vector>> и насколько он красив с eigen. Впрочем eigen — это чуть иной проект
я согласен, если микроскопом забивать гвозди, он потребует многих улучшений. А если молотком… ну так молоток 18ого века — вполне нормальный инструмент.
Лямбды… ну опыт АЛГОЛ-60 показал, что лучше их не использовать, чем использовать. Опять-таки, не актуально в связи с отсутствием у нас контейнеровв STL.
rvalue-ссылки… ну нету у нас лишних копирований. Просто нету. И потребности в этой семантике нету. Фишка полезная. но не для нас.
Вообще ничего не понял про фрагментацию кучи. Это тут при чём?
При том, что из-за опасности фрагментации (отказ программ в малопредсказуемый момент) мы не используем кучу совсем. Для того, чтобы в проекте можно было бы использовать кучу нужна или виртуальная память + swap или памяти должно быть процентов на 60 больше необходимого.
А вот возможность ценой не очень больших усилий отказаться от С++ и в части модулей перейти на Си — это киллер-фича.
Тем страннее ограничение MSDN.
Повторю совет: меньше читать в инете, больше пробовать самому
Нет, спасибо. Хватило адаптации кода для неё. Боль примерно та же, что и с адаптацией сайта под IE. При этом со всеми остальными компиляторами и операционками — проблем было мало. Даже с WIN32 на linux перешли с меньшей болью, чем при адаптации к VC++
Вот прямо возникает вопрос: а вы под какую студию код адаптировали? Не под 5.0? Просто сейчас вот у нас проблема, что gcc 4.9 хуже стандарт поддерживает, чем студия. Я вот уже заколебался код «доунгрейдить», чтобы он у нас под линукс тоже собирался. Про интеловский компилятор я тоже говорил уже, не взлетел тоже в силу ущербности той версии, что была в 2013м компосере (сейчас в 2017м конечно лучше должно встать, но уже на gcc переехали под линукс).
Уже похоже. А VC++ может иметь 5-7 окон инспектора на экране одновременно (а не рассованные по разным вкладкам)? Иногда есть необходимость сразу несколько структур раскрывать.
Окно просмотра переменной можно пинить, и хоть 5, хоть 7, хоть 57 их иметь. Лучше попробуйте, множество вопросов отпадёт.
я не настолько крут и разобраться в хите длиннее 1024 символов не могу. :-) Особенно, если первые 4К не несут важной информации. :-) Всплывающие подсказки хороши для простых типов, а не для объектов
Вот видно, что так и не попробовали. Там не хит на 4к символом всплывает, а полноценное окно просмотра/редактирования переменной. Да, такое же как на моём скриншоте окна locals.
Ну вы уже в соседней ветке разобрались. Но с вашей оценкой качества дизайна продукции микрософта я согласен.
Не передёргивайте. Моё высказывание не относилось к качеству дизайна майкрософт (хотя иногда даже у МС встречается такие, что хочется эти же эпитеты к ним применить).
Потому что нет требований ни к одному из компиляторов эту функцию реализовывать.Жалко, что вы не изучали язык FORTRAN. В фортране было разделение между стандартными внутренними функциями, которые могли реализовываться компилятором, и стандартными внешними функциями, которые реализовывались библиотекой.
Так вот, всякие asin никогда компилятором не реализуются. Компилятор может реализовать sqrt или fabs, потому что в сопроцессоре могут быть соответствующие машинные команды.
Вот не надо меня жалеть, что я Фортран не изучал. Это как пожалеть, что в армии 2 года не служил. И собственно ваш аргумент ни о чём. Ну пусть в Фортране есть внутренние и внешние функции. Это не значит, что он с бодуна должен вдруг начать реализовывать функции не из своего стандарта, например, из стандарта POSIX'а.
А POSIX-совместимых библиотек весьма много (мы используем glibc, uClibc, Newlib). И все они кроссплатформенные и реализуются на любой нормальной ОС (и даже на части ненормальных. например есть на винде, просто не от микрософта).
Отлично, что их много. Как много 100500 других библиотек, некоторые из котолрых реализуют так же свои стандарты. Но это не повод называть компилятор (хоть от майкрософт, хоть от интел, хоть ещё какой), плохим словом, если их рантайм не поддерживает эти левые стандарты.
и вопрос какое api лучше: WinAPI или POSIX или ещё какое, к вопросу о компилятору языка отношения не имеет вообще.к нормальному компилятору — да, не имеет. Но вы видели, чтобы VC++ работал не с микрософтовским clibc? Если вы знаете альтернативу — дайте ссылку. Вы же не на пустом месте спутали компилятор с библиотекой. У VC++ библиотека — часть компилятора. Увы, не заменяемая.
Ну как бы никаких предпосылок, что он может с ним не заработать нету. А так вы вот до 2012-й студии stlport, например, использовали, крутая штука, кстати была 12 лет назад. И опять таки, к сравнению POSIX-api и WinAPI это отношения не имеет. Вообще. Берите любой компилятор (хоть gcc, хоть clang, хоть интеловский, хоть Builder, хоть VC), вам будет доступна стандартная библиотека и API операционной системы. Т.е. под gcc все WinAPI'шные функции также доступны под виндой.
А если почитать внимательно — там gcc 2.95.4. Сертификация идет на конкретную версию МСВС и стоит миллионы. Сертифицировано МСВС 3.0 — или платите миллионы за сертификацию МСВС 5.0 или живите на gcc 2.95.4
Я, наверное, плохо выделил слово везде. На вики написано, что и под MCBC 3.0 доступен 4-й gcc. Не надо для этого на MCBC 5.0 переходить.
Увы, знаком. Ничего сильно полезного для нас не вижу. ну попробуйте, найдите хоть одну киллер-фичу.
Так все думают (да, да, мы думали абсолютно так же), пока не переходят на новый компилятор, и внезапно С++11/С++14 код не начинает пролазить во все места в которые может и не может. И дело может быть даже в одной киллер-фиче, а в общем упрощении и убыстрении написания кода (при этом более безопасного и эффективного).
И даже там, где куча есть,, лучше использовать специальные библиотеки для многомерных матриц, чем возиться с std::vector<std::vector<std::vector<std::vector><std::vector>>>> Неужели вы не понимаете, что std::vector придумали для совсем других целей, а не для многомерных массивов.
Вы так пишете, как будто я пытаюсь вас убедить в том, что vector<vector<vector<...>>> это круто и надо использовать только их, особенно для многомерных массивов :-). Не надо мне лишних грехов приписывать, у меня и так своих немало.
я согласен, если микроскопом забивать гвозди, он потребует многих улучшений. А если молотком… ну так молоток 18ого века — вполне нормальный инструмент.
Хорошая аналогия, я бы до такой не догадался :-). Да, молоток 18-го века, вполне нормальный инструмент, сам таким пользуюсь. А вот профессионалы (по крайней мере, те, что мне ремонт делали), используют гвоздезабиватели (проще, быстрее, и безопаснее, в плане, что хрен ошибёшься).
Лямбды… ну опыт АЛГОЛ-60 показал, что лучше их не использовать, чем использовать. Опять-таки, не актуально в связи с отсутствием у нас контейнеровв STL.
rvalue-ссылки… ну нету у нас лишних копирований. Просто нету. И потребности в этой семантике нету. Фишка полезная. но не для нас.
Блин, у меня аж голова сломалась :-( Причём тут ваш печальный опыт на АЛГОЛ-60 и лямбды в C++? (Секс… ну опыт ТетяМашка-60 показал, что лучше им не заниматься, чем заниматься.). Какую связь лямбры имеют с stl-контейнерами? (это прямо мозг вынесло). Ну и как бы я сильно рад за вас, что у нас нету лишних копирований (а у кого они есть?).
При том, что из-за опасности фрагментации (отказ программ в малопредсказуемый момент) мы не используем кучу совсем.
Мой вопрос был, как это связано, используете вы кучу или нет, с фичами C++11/C++14?
Повторю совет: меньше читать в инете, больше пробовать самому
Напробовался. Цензурных слов нет, очень тянет блевать. я понимаю, у вас логика наркомана: да как ты можешь судить о героине, если ты 5 лет не кололся?!
а вы под какую студию код адаптировали? Не под 5.0?
2012ая вроде.
«Там не хит на 4к символом всплывает, а полноценное окно просмотра/редактирования переменной.»
То есть случайно мышку оставил над переменной, а потом окно закрывать? Ну очередной минус VC++.
Ну пусть в Фортране есть внутренние и внешние функции.
Они есть во всех языках, только стандарт фортрана их выделил явно. Внутренние — это те, про которые компилятор знает. А внешние — про которые не знает.
Но это не повод называть компилятор (хоть от майкрософт, хоть от интел, хоть ещё какой), плохим словом, если их рантайм не поддерживает эти левые стандарты.
Угу, типичное мнение любителя микрософт. я выбираю инструменты под свои задачи. И говорю, что данный инструмент плох для наших задач. А мне начинают втюхивать, что задачи у нас неправильные, код не тот, операционные системы не те, железки не такие… Ну в общем нужно все бросить, фирму закрыть и идти путем one microsoft way. Вам самому не грустно?
Ну как бы никаких предпосылок, что он может с ним не заработать нету.
Ну-ну, попробуйте для начала. Даже gcc не позволяет, чтобы проект, скомпилированный для glibc, запустился с uClibc. Компилятор вызывает много служебных процедур, которые в разных библиотеках разные.
Я, наверное, плохо выделил слово везде. На вики написано, что и под MCBC 3.0 доступен 4-й gcc.
Что за бред? Вы хоть раз с МСВС работали? Ещё раз: сертификация идет на конкретную версию и редакцию МСВС по конкретному процессору. Никакой софт, кроме самописного ставить туда нельзя. Новая редакция с новым gcc — повезло. Старая редакция — платите миллионы за новую сертификацию или пользуйтесь тем, что есть. Мой вам совет — поработайте с МСВС, а потом судите. Не вот, увы, пришлось. Повезло. Кто-то подсуетился вовремя и оплатил сертификацию более нового варианта на тот же
и внезапно С++11/С++14 код не начинает пролазить во все места в которые может и не может.
Упаси нас боже от этого ужаса. Лучше уж вернуться на голый Си.
А вот профессионалы (по крайней мере, те, что мне ремонт делали), используют гвоздезабиватели
Там, где нужна надежность — никогда не используется ничего нового. Все детали — только реально проработавшие 10-20 лет. С известной опытным путем (а не теоретически) наработкой на отказ. Все технологии — старые, с известными проблемами и способами их решениях. Любая операционка — после третьего сервис-пака (одна из причин, почему в банкоматах до сих пор Windows XP). Нужна была бы вашим «профессионалам» надежность — использовали бы молотки. Просто потому, что ремонт гвоздезабивателя в поле — то ещё приключение.
Причём тут ваш печальный опыт на АЛГОЛ-60 и лямбды в C++?
я вам ссылку дал — почитайте внимательно. АЛГОЛ-60 использовал лямбды в виде передачи параметров по наименованию. Выражение, переданное, как параметр запроцедуривалось, и исполнялось в точке обращения. Это приводило к возможности вызывать самые разные побочные эффекты и к красивым трюкам. Через 10-20 лет общее мнение пришло к тому, что это был design-баг и лучше передачу по наименованию не использовать.
Какую связь лямбры имеют с stl-контейнерами?
А где они ещё нужны? Типовой пример из вики
std::vector<int> someList;
int total = 0;
std::for_each(someList.begin(), someList.end(), [&total](int x) {
total += x;
});
std::cout << total;
Да, это действительно наглядней и удобней. Но без STL — просто не нужно.
Ну и как бы я сильно рад за вас, что у нас нету лишних копирований (а у кого они есть?).
У тех, кто выдает объект как результат функции. Например часто результатом функции бывает std::string. Вот тут экономия огромная.
Мой вопрос был, как это связано, используете вы кучу или нет, с фичами C++11/C++14?
Летели два крокодила, один зеленый, а другой в Африку.
Вопрос: Сколько лет бритому ежику.
Ответ: зачем мне холодильник, если я не курю.
Мы не используем кучу. Следовательно, мы не используем STL. Мы вообще пишем на Си с некоторыми элементами С++. Вот и подумайте, какие элементы С++14 будут полезны в Си? что-нибудь равно по силе использованию ссылок вместо указателей. Есть такое? Ах нету? Ну вот то-то, что нету. :-)
Возможность сформировать анонимную функцию вот прям здеся в точке вызова — она, ну, удобная и полезная не только в STL.
Но абсолютно бесполезная для нас. Нету у на временных функций, нужных только в точке вызова.
автоматический вывод типов
То есть убрать возможность проверки? Это само по себе является источником ляпов. А вкупе с системой приведения типов — невообразимым источником разных глюков.
std::string str= "ворона";
auto s = str;
auto k = 'k';
s = k;
И вы долго будете искать вашу корону…
вариадики
не нужны за отсутствием темплейтов. Только не надо мне доказывать, что обязан купить телевизор или использовать темплейты. Темплейт это костыль для написания библиотек. Желающие посмотреть, как это делается без костылей могут изучить язык FORTH.
constexpr
Ещё одна костыльная недофича. Хорошая недофича, конечно. Но пока вы не сможете в compile-time создавать новые операторы — это все будет недофичей. Ну вот не нравится вам, что #elif есть, а elif нету — ну взяли и написали сами, как это делается в FORTH. Думаю, ч то лет за 50 С++ продвинется в этом направлении. constexpr — это шаг в нужную сторону. Но это все-таки костыль, по сравнению с прямой кодогенерацией в compile-time в FORTH.
да мало ли.
Ноль полезного для нас — это мало. Не вижу ничего, позарез нужного мне в моих проектах. Будут другие проекты — будет польза. А пока — ноль по модулю.
Я на этом C++14
у меня есть
мне после хаскеля
Ну у вас и компы не на 18мегагерц работают. И памяти — не 64килобайта. И отладка без паяльника и осциллографа идет. И ещё много-много чего не так.
Давай не путать — мы ненастоящие программисты. У нас многое не так.
А что ваш пример призван показать? В s будет символ k, длина строки равна единице. Что не так?
Желание программиста. Явно имелось ввиду не то, что написано.
И как вам указание типа сильно поможет? Особенно с учётом приведений, опять же
Была очень веселая история в 1998 ногу. Тестирую, вижу баг, пишу @yole — мол у тебя вещественный тип вместо денежного. Он в ответ — у меня все норм. На четвертый раз дал ему тестовый пример, он убедился. Через четыре часа — Чертова Венгерская нотация.!!!!/ Мало назвать переменную так, как читает верным микрософт, надо ещё и на самом деле дать ей нужный тип.
Так что всякая автоматика — вещь не только крайне удобная, но ещё и багоопасная.
Возможность их легко и дёшево создавать меняет мышление.
Героин — тоже. А из дешевого — можно бензин нюхать. :-) Аналогия прямая — все трое приводят к глюкам.
Темплейты (и вообще статический полиморфизм) — это механизм, позволяющий абстрагировать и переиспользовать код. Причём тут библиотеки?
Да по определению "Библиоте́ка (от англ. library) в программировании — сборник подпрограмм или объектов, используемых для разработки программного обеспечения (ПО)". Впрочем, я соглашусь, что молодое поколение имеет право не знать изначальный смысл этого слова.
Но мне все это «переиспользование» напоминает смешную историю 1998ого года. Тогда тот же yole нашел настройку, позволяющую менять количество часов в сутках. Ну вдруг у кого-то 25 часов или 18… :-) За очень редкими исключениями, алгоритмы не инвариантны относительно типов. То есть, сделав алгоритм для double — не надо его расширять на float или int64. Да, есть синтаксический сахар в том, чтобы дать алгоритму сильную типизацию, то есть не просто double, а отдельно TWieight(масса), а отдельно — TVolume(объем).
Но все эти красоты — увы, не перевешивают проблем с отладкой темплейтов.
Так что темплейты нужны на своём месте — там, где код многократно будет использоваться с заведомо разными типами. А таких мест у нас в проекте нету.
А С вам зачем? Что там есть такое, что принципиально невыразимо на ассемблере?
А Си как раз и писался, как универсальный ассеблер (сначала PDP-8, потом PDP-11). *dst++ = *src++; — это одна машинная команды MOV (R3)++, (R2)++.
На C++ под attiny какой-то, где мегагерц ещё меньше, а памяти в окрестности килобайта, я писал.
Прошу прощения за нескромный вопрос, а вы отладились? Проект у заказчика работает или на полке пылиться?
— Я духов вызывать могу из бездны
— И я могу и каждый это может.
— Вопрос лишь, явятся ль они на зов.
Желание программиста. Явно имелось ввиду не то, что написано.
Я так и не понял, кто что желал. Судя по коду, программист явно желал, чтобы строка s == «k», что и исполнено. В чём проблема?
Приведите язык программирования, в котором компилятор гарантирует, что нельзя перепутать целочисленную переменную l с константой 1.
Видимо следствие того, что наши проекты маленькие до 100 тысяч строк и весь код целиком сидит в мозгу. В больших проектах бардака как-то побольше. Ну или дело в том, что мы просто не используем опасных конструкций.
Но я потестируюсь, как время будет. И отчет напишу. Вполне возможно, что я ошибаюсь кардинально.
Сколько ни читал — ну ни разу не было «ой, мы за таким же багом 3 дня гонялись».
Пример использования статического анализатора.
Да, у нас тоже был баг, за которым гонялись долго: математик решил, что математическая эквивалентность означает, что компилятор «оптимизирует все» и сделал установку бита в маске через возведение в степень вместо сдвига.
Оно замечательно работала на x86 потом что сопроцессор работает с 80битными long double, А вот на ARM, увы, только double длиной 64 бита. В итоге вместо на 2**31 выдавало на единичку меньше.
Ещё была смешная история про проверку пустоты строки через strlen. Оно работало, но настолько неэффективно… строки там по 4К были…
Общее впечатление от ваших статей — ну вот как у вас от проверки Clang. Вы же не стали ежедневно проверять свой код Clang, после того как он нашел у вас ошибки?
Но я ещё раз обещаю, что наш код бесплатной версией проверю и статью с результатами напишу.
Вы же не стали ежедневно проверять свой код Clang, после того как он нашел у вас ошибки?
Проверяем каждый день (см. «Тестирование PVS-Studio»).
Если считать их одним и тем же, так мы тогда тоже Clang используем. С практически нулевым результатом.
Машет рукой вправо:
— поворачивайте налево, налево!!!
Водитель поворачивает налево.
— Куда же вы? У нас в Расее куды кажут, там и лево!
string& operator= (char c);
А код — да, кривой, не спорю. В хорошем коде — лучше без auto. Ну разве что в темплейтах — там может так сложиться, что без него не обойтись.
Ну сказали бы, что код без аннотаций типов вы читать не можете
я читаю код даже на тех языках, которых не знаю. И даже какие-то баги нахожу. :-) Но одно дело — найти какие-то ошибки, а другое дело — найти все. Наличие auto понижает шансы на нахождение ошибки. Хотя и делает код более (а не менее) читабельным.
Хотя — тут многое зависит от определений слов, потому я прошу привести, где в вашем толковании проходит граница.
Что касается auto, то почти 60 лет истории языков программирования вполне доказали, что языки, требующие явного указания типа — более надежны, чем языки с неявной типизацией. Мне как-то казалось, что споры о этом утихли примерно к 1975ому году вместе со спорами о GOTO. Но видимо развитие идет по спирали и молодняк просто не в курсе.
pow(2,N) очевидно надёжнее, не надо заморачиваться с правилами битовых сдвигов в C.
Вы математик что ли?! Или только на x86 работали? На АРМ 2**31 дал результат на единицу меньше. И вместо нужного бита в битовой маске установились все биты кроме нужного. Искали это полтора года, нашли вычиткой текста.
И это как раз тот баг, ради поимки которого не жалко денег на статический анализатор.
Скажите, а strlen(str) > 0 тоже для вас лучше *str != 0? А на строках размером 4килобайта? Семантика одинаковая. зато кодогенерация разная…
Во-первых, адекватному выводу типов хорошо если 30 лет
Багоусточивый вывод типов — это миф.
auto x = 1;
auto y = 2;
double xy = x / y;И получаем 0 вместо 0.5. Написали бы double вместо auto — все хорошо бы было.
Во-вторых, где это они доказали? Можно почитать? А то молодняк действительно не в курсе.
Это все было задолго до интернета. Поищите дискуссию про implict none (запрет автоматического определения типа по имени переменной в FORTAN). Ну как бы общее место Поэтому запомните правило: ставить implicit none всегда, а затем корректно обрабатывать вылезающие ошибки. Иначе рано или поздно нарветесь на проблемы. Но сам implict noneпоявился в фортране с большими боями. Слишком уж удобно было, что I. J, K — целые, а X, Y, Z — вещественные.
Вторая история это язык Ада, специально спроектированный для надежных применений. И там тоже в требования попало явное указание типа, как приводящее к большей надежности.
Тут есть другой момент. Кроме того, что в Fotran и BASIC использовалась неявная типизация, там ещё и использовалось неявное описание имен переменных. И критика этих разных сущностей сливалась вместе.
В целом, есть хорошая обзорная статья о плюс и минусах разных систем типизации.
Если сильно надо — могу покопаться в библиотеке, но она у меня на родительской квартире осталась.
А идея простая. Любая избыточность в тексте программы дает компилятору (и статанализатору) больше информации для проверки. Взамен — замедляется написание кода. Поэтому короткие программы удобнее писать на BASIC, а длинные и надежные — на чем-то алголоподобном (Си, Pascal...)
> Скажите, а strlen(str) > 0 тоже для вас лучше *str != 0? А на строках размером 4килобайта?
В читабельности и правилах приведения разницы особо нет. Разве что, второй вариант даже немного лучше — не надо вспоминать, как там себя strlen ведёт на нулевых указателях, из кода сразу всё видно.
Сразу видно что будет ub, если что?
Я встречал не самых необразованных людей, которые думают, что strlen на нулевых указателях — это норма, например.
Это уже implementation defined, может быть ub, а может и не быть. По крайней мере strlen(3) не говорит ничего о поведении при передаче NULL. Естественно, логично предполагать, что в общем случае будет ub, но в частном просто SIGSEGV. На glibc это справедливо.
Кстати, clang выдает предупреждение, если в strlen отдать NULL, но дальше этого не заходит.
Это уже implementation defined, может быть ub, а может и не быть.Это что ещё за разговоры? Implementation defined and Undefined Behaivior — это вообще «из разных опер». Undefined Behavior — это требования, налагаемые не на компилятор, а на программу. Их в программе быть не должно, точка.
По крайней мере strlen(3) не говорит ничего о поведении при передаче NULL.Именно. Что это значит? Правильно: всё описывают «правила использования библиотечных функций» (раздел 7.1.4 в C99/C11). А там — английским по белому написано: If an argument to a function has an invalid value (such as a value outside the domain of the function, or a pointer outside the address space of the program, or a null pointer, or a pointer to non-modifiable storage when the corresponding parameter is not const-qualified) or a type (after promotion) not expected by a function with variable number of arguments, the behavior is undefined.
Кстати, clang выдает предупреждение, если в strlen отдать NULL, но дальше этого не заходит.А вот GCC — заходит:
int foo(char *p) {
int x = strlen(p);
if (!p) return 42;
return x;
}
Даёт:
foo(char*):
sub rsp, 8
call strlen
add rsp, 8
ret
Неплохая такая оптимизация, да? Всё в рамках стандарта, между прочим. Можете сходить на Compiler Explorer сходить, проверить…
Это что ещё за разговоры? Implementation defined and Undefined Behaivior — это вообще «из разных опер». Undefined Behavior — это требования, налагаемые не на компилятор, а на программу. Их в программе быть не должно, точка.
В стандарт сейчас не заглядывал, каюсь. Если сказано в стандарте, что ub — то разговоров нет. И оптимизация абсолютно правомерна.
Моё утверждение базировалось на том, что для strlen это не специфицировано и libc вполне может иметь guard вида if(!str) return 0;.
Моё утверждение базировалось на том, что для strlen это не специфицировано и libc вполне может иметь guard вида if(!str) return 0;Вы путаете C и C++ — это в C++ подобные вещи бывают (скажем в std::operator delete можно nullptr передавать). Но в C — другие законы. По умолчанию — нельзя. Должно быть явно описано, если можно.В частности
std::operator delete так и устроен — проверка на nullptr + вызов free.Естественно, логично предполагать, что в общем случае будет ub, но в частном просто SIGSEGV.Собственно это — большой-большой хинт. Если у вас случается SIGSEGV, то у вас в программе с вероятностью 99% процентов UB…
Значит, вам так повезло в данном конкретном случае, что комбинация размеров типов и поведения оператора сдвига дала нужный вам результат. Сами понимаете, что такой код не очень портируемый и не очень поддерживаемый.
Когда тролите — тролльте потоньше, пожалуйста. Сдвиг столь же переносим, как операция сложения и намного более, чем вещественная арифметика. Впрочем, вы вполне способны и сложение объявить непереносимым. Действительно, может быть переполнение и результат будет неопределенным. :-) Пока (N >=0) && (N < (WORD_BIT-1)) все работает на любой архитектуре. А в реальном использовании все чуть сложнее:
#ifdef USE_GALILEO
typedef uint64_t TSatMask;
#else // USE_GALILEO
typedef uint32_t TSatMask;
#endif // USE_GALILEO
#define ONE_SATT_MASK TSatMask(1)
TSatMask mask = ONE_SATT_MASK << N;
Зато uint32_t mask = pow(2,N); работает непредсказуемо. То есть зависит от архитектуры процессора, софтверной или аппаратной плавающей точки, ключей компилятора, конкретных алгоритмов в софтверной реализации. Если для 2**2 вы получите 4.00000000001 — это не страшно, а вот если будет 3.99999999999999 то при преобразовании в целое у вас получится 3.
Что самое смешное, кодогенерация тоже одинаковая. Можете проверить, gcc и clang, проверенные мной, генерируют одинаковый код для обоих веток:
Проверил на gcc под corrtex-M7, код разный. Жду от вас версию и название библиотеки. Версия компилятора скорее всего не причем, просто std::strlen объявлен inline. ну или вообще через #define или template. Ну и жду от вас теста с нормальным strlen.
1876:../Pobase3/ugol-2a.cpp **** bool test1(const char *str) {return *str != 0;}
1529 0000 0078 ldrb r0, [r0] @ zero_extendqisi2
1531 0002 0030 adds r0, r0, #0
1532 0004 18BF it ne
1533 0006 0120 movne r0, #1
1534 0008 7047 bx lr
1877:../Pobase3/ugol-2a.cpp **** bool test2(const char *str) {return strlen(str) > 0;}
1551 0000 08B5 push {r3, lr}
1556 0002 FFF7FEFF bl strlen
1558 0006 0030 adds r0, r0, #0
1559 0008 18BF it ne
1560 000a 0120 movne r0, #1
1561 000c 08BD pop {r3, pc}
1878:../Pobase3/ugol-2a.cpp **** #include 1879:../Pobase3/ugol-2a.cpp **** bool test3(const char *str) {return std::strlen(str) > 0;}
1578 0000 08B5 push {r3, lr}
1583 0002 FFF7FEFF bl strlen
1585 0006 0030 adds r0, r0, #0
1586 0008 18BF it ne
1587 000a 0120 movne r0, #1
1588 000c 08BD pop {r3, pc}
Написали бы 1.0 вместо 1 — тоже было бы хорошо.
Конечно. Но это значит, что нужно иметь двойной набор констант. Например SECS_PER_DAY — количество часов в сутках (86400), а для поддержки auto потребуется SECS_PER_DAY_FLOAT со значение 86400.0. Увы, неудобно и ненадежно.
Так что пусть auto лет 5-10 отлаживается на подопытных свинках. ну в смысле на всяких настоящих програмистах из хайлоада. А когда наберется опыт, что надежно, а что нет, тогда и в АСУТП можно будет применить.
Длинные и надёжные программы лучше писать на языках с сильной статической выразительной системой типов. C и Pascal к ним не относятся.
Ну в паскале как раз достаточно сильная система типов. Своя операция деления для целых (DIV) и запрет на неявное преобразование вещественных в целые. Так что он как раз подходит. А ещё лучше Delhi, ибо дает много преимуществ.
С остальным более-менее согласен.
Ну, если у вас IEEE754-совместимая система, то всё вполне предсказуемо.
Увы, нет. Оно почти предсказуемо. На х86 сопроцессор выполняет вычисления в long double. А записываем мы временные результаты в double. Убрал компилятор при оптимизации временную переменную — получили капельку иной результат. я уж не говорю о том, что на других архитектурах long double иного размера — не 80, а 96 или 64 бита. Включили -Ofast, он включил -ffast-math и вот вам ещё отличия от IEEE.
Вы хотя бы -O1 добавили?
А какая библиотека — фиг знает, что там на gcc.godbolt.org.
У нас -O2, но дело именно в библиотеке. Можете проверить, при -O0 оно тоже инлайнится. У нас NewLib, а у вас — glibc.
/* Return the length of S. */
# define _HAVE_STRING_ARCH_strlen 1
# define strlen(str) \
(__extension__ (__builtin_constant_p (str) \
? __builtin_strlen (str) \
: __strlen_g (str)))
__STRING_INLINE size_t __strlen_g (const char *__str);
__STRING_INLINE size_t
__strlen_g (const char *__str)
{
register char __dummy;
register const char *__tmp = __str;
__asm__ __volatile__
("1:\n\t"
"movb (%0),%b1\n\t"
"leal 1(%0),%0\n\t"
"testb %b1,%b1\n\t"
"jne 1b"
: "=r" (__tmp), "=&q" (__dummy)
: "0" (__str),
"m" ( *(struct { char __x[0xfffffff]; } *)__str)
: "cc" );
return __tmp - __str - 1;
}
изначально дискуссия началась со споров о нужности auto вообще.
Так вот нам, в нашем коде он более вреден, чем полезен. А у вас — другие задачи и другой код.
Там ещё не зря было «выразительная».
Прошу точнее определить термин, возможно мы его по-разному понимаем. В паскале есть диапазонные типы множества (то есть битовые маски). Так что его система типов — более выразительная, чем в С++. Ещё одно достоинство Delphi (object pascal) — это интерфейсы, как в java.Это некий аналог множественного наследования, но без присущих множественному наследованию проблем.
Ну это как в хаскеле, короче, а ещё лучше — как в Idris каком.
Ещё раз прошу пояснить термин «выразительная система типов».
На самом деле очень сложно привести достаточно краткие примеры для каждой из столь любимых мной функций.
Ещё сложнее вам будет доказать, что эти возможности реально увеличивают надежность.
Реальная задача такова. Есть фиксированное ТЗ с объемом работы. Есть требуемый уровень надежности. Какой язык позволит достигнуть результата за меньшую стоимость и время? Сомневаюсь, что это будет haskel. Высокая оплата разработчиков на haskel вряд ли окупается во столько раз возросшей производительностью и надежность. В лучшем случае, заплатив в 2 раза больше — мы увеличим надежность в корень из двух раз.
С другой стороны, взяв в команду разработчиков на чем-то паскалеподобном высококлассного архитектора, мы можем путем увеличения стоимости проекта процентов на 20 увеличить надежность в несколько раз.
я очень рекомендую сравнить 50 страничек стандарта паскаля (порядка 70 у дельфи) с более тысячей страниц стандарта С++.
А как размер стандарта хаскел со всеми нужными вами расширениями?
Больше возможностей отвергнуть некорректные программы.
я не о возможностях. Возможность стать президентом России у вас есть.А шансов — нету. :-)
typeded int Metr;
typeded int MetrSquare;
Metr l, w, sWrong;
MetrSquare sRight;
sWrong = l * w;
sRight= l * w;
Сумеете ваша система типов ругнуться на sWrong = l * w? Если нет — её возможности несколько не в той области.
Сумеете ваша система типов ругнуться на sWrong = l * w? Если нет — её возможности несколько не в той области.
Если в С++ объявить Metr и MetrSquare как классы и перегрузить операторы умножения, то ругнётся по-моему.
Покажите, пожалуйста, переопределение pow(x.y) на пригодной для физики метода размерностей системе классов.
Это чтобы вторая степень метров возвращала площадь, а третья объём? Подозреваю, что не смогу, это не шахматы, тут думать надо. Если только в рантайме эксепшны кидать. Но это наверное тоже неплохо.
Ну как минимум систему СИ (или СГС) поддержать сможете?
Система Си большая вроде, а я маленький. Но компоненты какие-то думаю, можно.
Сумеете ваша система типов ругнуться на sWrong = l * w?
Сумеет, почему нет? Правда хаскель я знаю не очень хорошо, но пример на расте (язык, кстати, низкоуровневый) показать могу:
struct Metr(u32);
struct MetrSquare(u32);
//let err: Metr = Metr(1) * Metr(2);
let val = Metr(1) * Metr(2);
println!("{:?}", val); // MetrSquare(2)я же прямо написал, сумеет ваша система типов ругнуться. Сама система описаний типов, а не дополнительный код.
я же прямо написал, сумеет ваша система типов ругнуться.
Как по мне, ругаться будет всё-таки система типов, дополнительный код нужен для указания позволенных операций, а не наоборот. Но в остальном да, дополнительный код писать придётся. Стоит ли оно того вопрос сложный, очень может быть, что в каких-то случаях стоит. Ну а вообще, при желании, оно пишется один раз и дальше используется.
Ну и ругань, как вы и хотели, будет происходить на этапе компиляции, а не в рантайме.
Хочется несколько иное — язык, на котором достаточно сказать, что MetSquare — это Metr во второй степени. А весь контроль типов — встроенный.
Стоит ли оно того вопрос сложный, очень может быть, что в каких-то случаях стоит.
Ну если вспомогательные определения занимают 5%, то может и стоит. Но боюсь, то в реальности они будут занимать 80% кода.
Дык, отсутствие неявных преобразований уже повышает надёжность.
Опять же, если этот "вспомогательный код" написан, оттестирован и используется по всему проекту (а может даже не в одном проекте), то сомневаюсь, что дефекты будут частыми.
На язык в котором "достаточно сказать, что MetSquare — это Metr во второй степени" взглянуть было бы интересно, но есть некоторые сомнения, что такие указания были бы достаточно гибкими для всех случаев. Иначе это уже не язык общего назначения.
С 80% явно перебор, мы ведь не о игрушечном примере говорим, а о проекте не самого маленького размера?
Дык, отсутствие неявных преобразований уже повышает надёжность.
Ну это не про С++. В нем неявных преобразований много. В 93ем году экспериментировали с системой преобразований — и выяснили, что лучше её не использовать, а все преобразования писать явно.
С другой стороны, необходимость прописывать явно все преобразования — это перебор. Ибо на системе из 10 классов их будет 90. И даже если половина бессмысленна — то все равно писать много.
Что будет в ином языке — нужно будет проверять.
есть некоторые сомнения, что такие указания были бы достаточно гибкими для всех случаев
Сомнения и у меня есть. Но в реальном мире мы же используем размерности? Значит такую систему типизации создать можно. Проблем пока вижу две:
- градусы, радианы, полуциклы для углов. ну или футы, дюймы, метры для длин.
- сложение уток с курицами дает птицы, а куриц с коровами — живность. То есть без наследования не обойтись.
С 80% явно перебор, мы ведь не о игрушечном примере говорим, а о проекте не самого маленького размера?
Открываю стандарт RTCM 3.2 — 457 типов полей. При обычном программировании — нужен просто множитель для приведения к метрам или герцам. А при строгой типизации? А на все возможные операции? Боюсь, что на переводе из RTCM 3.2 в RINEX можно и 95% вспомогательного кода получить. И да, проект точно будет не самого маленького размера.
Но вполне возможно, что в каких-то областях такой подход будет реально удобней.
Сумеет такое хаскель? Нет? Ну если нет — значит не сильно он поднимет надежность на наших задачах.
Но уже понятно, что ваш уровень таков, что вам кажется, что вики хватает. :-(
Тут могла бы быть колкость об уровне программистов, которые английского не знают, но я просто сошлюсь на здравый смысл: откуда взяться подробным материалам на русском о сравнительно новых и не мейнстримовых языках? А на википедии есть ссылка, в том числе, на официальный сайт с мануалами.
— six cloch.
— such match?
— match such!
— What which?
— a for whom how.
— MGIMO fisnihed?
— ack!
Так что одно дело читать datasheetы, а другое дело — полный разговорный язык.
А вот то, что на разработанный в 1973ем году язык ML нету хорошего русского описания — скорее всего показывает, что этот язык никому не нужен. Не все, что не вылезло в мейнстрим — не заслуживает потраченного на него времени. Но тем менее — это хороший критерий, на что тратить время, а на что нет. Не так уж долго жить на этом свете осталось, чтобы тратить время на ерунду.
Ну вот очень интересная технология. Это переворот не меньший, чем внедрение навигаторов. Автопосадка самолетов, автовождение машин… Через 20 лет высокоточная навигация будет у каждого в кармане.
А ваш ML известен в 1969ого года. И за 45 лет — так ни во что путное не развился. Да, в отдельных нишах что-то используется. Как используется и COBOL, и PROLOG и LISP и FORTH… Но вот глобального переворота — даже в программировании не вижу. В быту — тем более.
А вот то, что вы не умеете отличать одно от другого — это грустно.
С другим значком — не интересно, это почти на любом языке можно. Интереснее всего — это чтобы pow(x, 2.0) давало квадратные метры, а pow(x, 3.0) — кубические. И чтобы система на этапе компиляции понимала, что pow(x1,2.5) / pow(x2, 1.5) — это просто метры.
Вы говорите про метод размерностей и несёте лютую пургу тут же. Это ошибка, за которую любой школьник или студент 1 курса тут же получает линейкой по рукам. Возведение в действительную степень (а равно, скажем, лонарифм или экспонента) определено только для безразмерных величин.
Операция возведения в рациональную степень для размерности определена (хоть и не всегда имеет смысл). Но возведение размерного числа в действительную степень — операция неопределенная и не имеющая никакого смысла. И, уж тем более, не сохраняющая размерность, как линейная функция с безразмерным коэффициентом.
Конечно IEEE754'шные числа являются действительными с некоторой натяжкой, но чтобы трактовать их как рациональные необходимо использовать gmp ,)
Возведение в действительную степень (а равно, скажем, лонарифм или экспонента) определено только для безразмерных величин.
s = a *t**2 / 2;
t = sqrt(2*s)/sqrt(a) = pow(2*s, 0.5) / pow (a, 0.5)
Неужели вы такого в школе не проходили? А номер школы, где равноускоренное движение не проходят, можно? :-)
Если вам так интересен номер моей школы, то ФМШ №18. И, к вашему сожалению, я отличаю натуральные, целые, рациональные и действительные числа.
Если вы не способны понять, что возведение в рациональную степень (а целые и натуральные числа являются рациональными, JFYI) описано на параграф ниже в том же комментарии, то не стоит предполагать, что вокруг такие же люди с органическими патологиями мозга.
Также вам стоило бы понять ещё в школе, что операция возведения в натуральную степень, в целую степень, в рациональную степень и в действительную степень над полем действительных чисел — разные операции, иногда дающие один результат, т. к. для более широкого множества чисел операция строится таким образом, чтобы она обычно давала одинаковый результат для, скажем, натурального числа 2 и целого числа 2.
Но бывают случаи когда это не так: например, операция возведения в целую степень определена для -2 (\in Z), но операция возведения отрицательного числа в рациональную степень не определено над полем действительных чисел, но определена над полем комплексных.
Логарифм определен только для безразмерных? Ха-ха-ха, неужели в школе не говорили про децибелы? логарифмируем 1 киловатт — получаем 3 BW (3 бела") или 30 dBW или 60 dBm. Да, это очень не строго. Но в технике — так. А главное — так в ГОСТах откуда берутся формулы. Ну вот вам ГОСТ 24204-80 и формула абсолютного уровня мощности оттуда:
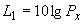
Логарифмируем милливатты и получаем dBm.
Ещё смешнее — с arcsin, Берем arcsin(0.5) и получаем… радианы, градусы, полуциклы, реже -грады и обороты (циклы) — все, что угодно, но не безразмерную величину. Может её стоит называть псевдоразмерной, но уж безразмерной она не является.
pow(x1,2.5) / pow(x2, 1.5) на который вы ополчились — это как раз рациональные, а не действительные числа. Но…
Беда в том, что на компе вообще-то нету действительных чисел. То, что дает IEEE 754 это представление действительных чисел с помощью двоичных дробей. То есть фактически, в обычной плавающей арифметике — все числа рациональные. Причем их не так много. Тип float — это чуть меньше 4 миллиардов значений. То есть ещё у нас далеко не любое число представимо.
Далее, ещё смешнее. pow(x,2.5) мы можем представить как х*х*sqrt(x). И если x — это квадратные метры, то размерность будем m**5; Но… бывают ошибки округления. И 2.4999999999999999 мы должны рассматривать как 2.5.
Бывает ещё смешнее. Синус больше единицы в математике быть не может. Но… синус, подсчитанный через векторное произведение — получился больше 1. Не сильно больше — на 10**-12, но больше. Пришлось вставлять условия — если больше 1, то брать строго 1. А уж потом — arcsin.
Так что жалко, что вас не научили отличию физики от математики, а техники от физики. А что там в математике — извините, не интересно. у меня — техника.
Логарифм определен только для безразмерных? Ха-ха-ха, неужели в школе не говорили про децибелы? логарифмируем 1 киловатт — получаем 3 BW (3 бела") или 30 dBW или 60 dBm. Да, это очень не строго. Но в технике — так. А главное — так в ГОСТах откуда берутся формулы. Ну вот вам ГОСТ 24204-80 и формула абсолютного уровня мощности оттуда:

Логарифмируем милливатты и получаем dBm.
Если вы сами не заметили, то под логарифмом искусственно убирается размерность (выполняется переход к безразмерным величинам) посредством нормализации на 1 Вт/1 мВт. И логарифмируете вы не 1 кВт, а 1 кВт/1 Вт. Если вы этого не понимаете, то лучше бы и не заикались про размерности. Точно такая же ситуация, например, в диффурах, во всяких вещах типа магнитуд (где под логарифмом может быть приведённая к безразмерной энергия, максимальное отклонение в мкм и т. п.)
Ещё смешнее — с arcsin, Берем arcsin(0.5) и получаем… радианы, градусы, полуциклы, реже -грады и обороты (циклы) — все, что угодно, но не безразмерную величину. Может её стоит называть псевдоразмерной, но уж безразмерной она не является.
И получаете радианы, как естественную единицу угла, которая, напомню, отношение длины дуги к радиусу, т. к. безразмерная величина. То, что вы потом её перемасштабируете — к делу не относится.
pow(x1,2.5) / pow(x2, 1.5) на который вы ополчились — это как раз рациональные, а не действительные числа. Но…
Беда в том, что на компе вообще-то нету действительных чисел. То, что дает IEEE 754 это представление действительных чисел с помощью двоичных дробей. То есть фактически, в обычной плавающей арифметике — все числа рациональные. Причем их не так много. Тип float — это чуть меньше 4 миллиардов значений. То есть ещё у нас далеко не любое число представимо.
Как я уже сказал выше, для восприятия чисел типа IEEE754 как рациональных нужно брать gmp или аналогичную библиотеку для работы с generic multiprecision numbers. Вы, естественно, не удосужились прочитать соответствующий абзац. Как известно из ненавистной вам математики любое периодическое действительное число представимо в виде рационального. Но большого смысла в размерности m^{123896721987/999999999999} нет.
Бывает ещё смешнее. Синус больше единицы в математике быть не может. Но… синус, подсчитанный через векторное произведение — получился больше 1. Не сильно больше — на 10**-12, но больше. Пришлось вставлять условия — если больше 1, то брать строго 1. А уж потом — arcsin.
Запросто, sin(1+1i) = 1.298 + 0.635i, и действительная часть, и модуль > 1. Ну или sin(1.571+1.317i) = 2.000, если хочется действительного результата.
Так что жалко, что вас не научили отличию физики от математики, а техники от физики. А что там в математике — извините, не интересно. у меня — техника.
Тут тоже не угадали, я физик. Ну и чтобы не вставать лишний раз — и с технической стороной образования проблем у меня нет, и в АСУТП поработать успел. И повидать программ написанных "инженерами" в которых ни они сами баги нормально выловить не могли, ни просто разобраться. Зато минимально написание повторно используемого кода, почти полное отсутствие форматирования, до 8 стейтментов на одной строке в коде на Си… Вы, кстати тоже код какого-нибудь ПИД-регулятора или фильтра копируете в несколько мест, чтобы потом независимо баги вносить?
И софт от всяких товарищей типа Carel, TAC/SE и Necos/Danfoss не сильно далеко от этого ушел.
Если вы сами не заметили, то под логарифмом искусственно убирается размерность
Это называется абстракция. Странно, что математик не видит их. В технике законодательно (на уровне ГОСТ) принята абстракция, что логарифм от мощности выдает белы. А что под капотом — не важно. Под капотом у умножения — вообще-то сдвиги и сложения. А у взятия квадратного корня — подсчет ряда. И что происходит с размерностью при подсчете ряда — вопрос для меня темный. Да и как сдвиги и сложения меняют размерность — тоже не понятно. Но абстракция такова, что некий ряд делает из квадратных метров метры, а некая последовательность сложений и сдвигов метров с метрами — дает квадратные метры.
Понятно, что строго математически вы правы, но мы говорили про язык для техники. И он должен поддерживать все нужные технике абстракции. Включая, кстати, возможность назначить ряду изменение размерности.
И получаете радианы, как естественную единицу угла, которая, напомню, отношение длины дуги к радиусу, т. к. безразмерная величина.
Естественная где? На плоскости? Вы хоть на одной карте видели радианы? Земля вообще-то круглая. :-) Поэтому естественная единица в геодезии — градус. Видели хоть на одной карте радианы? :-) А самая естественная единица угла — это оборот и доли оборота. Все остальное (градусы, грады, полуциклы) — пляшет от оборота. Так что для техники абстракция плоскости не всегда применима. И в языке для техники нужны и градусы и полуциклы.
Как известно из ненавистной вам математики любое периодическое действительное число представимо в виде рационального
Мне известно про то, что иррациональных чисел — не меньше рациональных. :-)
Как я уже сказал выше, для восприятия чисел типа IEEE754 как рациональных нужно брать gmp или аналогичную библиотеку для работы с generic multiprecision numbers.
Мда… На физфаке СПбГУ тоже так думали. И потеряли все значащие цифры при подсчете сходящегося ряда. :-) Не все абстракции математики выполняются в программировании. Ассоциативный закон сложения — увы, выполняется не всегда.
Тут тоже не угадали, я физик.
Ну тогда все понятно. Видел я, как программируют физики. Картинка с натуры (Программист — П, Физик — Ф, место действия физфак СПбГУ, 1983 год):
Ф — программа что-то не работает
П — у вас деление на ноль
Ф — физически эта переменная не может быть нолем. А можно обойти ошибку?
П — могу не делить, если ноль. Сделал.
Ф — ура! Ошибка исправлена!
Физик, кстати, была доктором наук. Но для физика действительно тяжелая задача — отличить физический смысл от программной реальности.
Вы, кстати тоже код какого-нибудь ПИД-регулятора или фильтра копируете в несколько мест, чтобы потом независимо баги вносить?
Ну вот вам пример ПИД-регулятора, а вот — экспоненциальный фильтр:
result = result * (1. - k) + value * k;
я понимаю, что настоящие программисты обернут этот фильтр в класс, класс в темплейты, получат где-то 200-300 строк кода и за недельку отладят.
Но… у нас система оплаты чуть иная. Нам платят не за количество строк, а за работоспособность. Поэтому прежде чем выносить код в библиотеку — думаем, а насколько нам нужна модицифруемость, а насколько повторная используемость. А прежде, чем использовать чужой библиотечный код — сравниваем время на изучение и время на написание и отладку собственного кода. Ну и все остальные характеристики тоже смотрим.
Потому мы и не настоящие программисты, что мы думаем, а не слепо следуем
Ну в общем любой технологией нужно пользоваться обдуманно, а
почти полное отсутствие форматирования,
Это действительно плохо, но математики так пишут. Почему-то математикам форматирование не нужно для понимания смысла кода.
до 8 стейтментов на одной строке в коде на Си…
В отдельных случаях — это правильно. Много операторов на одной строке писали, чтобы уменьшить количество перфокарт в колоде. А один оператор на строке — дань вычисления производительности программиста исходя из числа строк. Вы как цикл for запишите?
for (int i=0;
i < N;
i++)
или нормально, как for (int i=0; i < N; i++)? Вот аналогичные конструкции (прежде всего инициализацию) и принято писать в одной строке. Вам не кажется, что в этом примере однострочная иницализация явно читаемей была бы?
/* MACHINE CONSTANTS FOR THE BURROUGHS 1700 SYSTEM. */
/*
imach[1] = 2;
imach[2] = 33;
imach[3] = 8589934591;
imach[4] = 2;
imach[5] = 24;
imach[6] = -256;
imach[7] = 255;
imach[8] = 60;
imach[9] = -256;
imach[10] = 255;
*/
Но увы, это переписано с фортрана «1 в 1». :-) Недостатки общепринятого библиотечного кода, между прочим.
Для меня всегда был важен вопрос, чтобы меня помнили после моей смерти. Кого вы знаете из ныне живущих математиков? я Гришу Перельмана, Матиясевича, Башмакова… И то, лишь потому что лично знаком.
Зато по всей России стоит тысяча зданий, просчитанных на прочность программой «Ладога», документацию к которой я правил в 17 лет. И это намного важнее любой математики.
s[0] = 'K' читабельнее, вызывает меньше WTF и вообще.
Я бы на ревью такой код без комментария, что это сделано специально для какой-то адовой оптимизации тоже не пропустил бы. Да и с коментарием тоже подумал бы ещё. Обычно, если не нужна больше ворона, и хочешь корону, пиши полностью, s = «корона»;
Увольте его, пожалуйста, язык тут ни при чём.
Виновата венгерская нотация, усиленно насаждаемая микрософтом. Пока имя переменной в ладу с тмипом — она помогает. Но если сменили тип и забыли поменять имя — наступает локальный песец. Примерно та же фишка и с auto. Так что применять его надо крайне ограничено. А ещё лучше — не применять.
Почитайте про вывод типов в ML-подобных языках, пожалуйста.
Будет ссылочка — почитаю.
Старое поколение, очевидно, имеет право пропустить слово «сборник».
Судя по вашей страсти к повторному использованию, у вас вся программа — это именно сборник повторно используемых частей. :-)
Но смысл-то на самом деле в том, что разработчики библиотек не обязаны разрабатывать и клиентский код
А тестироваться на чем? Так что обязаны, увы.
Почему на флоат не надо?
Большинство FPU использует double или long double. Да и по стандарту Си любой float при операциях сразу преобразуется в double. Так что преобразования — несколько замедлят ваш код. А там, где используется FPU — обычно памяти хватает. А у нас просто по точности ничего не влезет во float. Расстояние до спутников — 20 тысяч км от центра земли, точность измерений — СКО 5 миллиметров. Так что 11 значащих цифр — это минимум.
Какие там особые проблемы по сравнению с обычным кодом?
Конечно! Примерно та же гадость, что и с инлайнами. «суслика видишь? Нет? А он есть».
Так тем более, почему не ассемблер?
Потому что каждый инструмент выгоден в своей области. Там, где надо — там ассемблер. Где важнее универсальность — там Си.
Правда, причём это к тому, влезают плюсы в мелкие микроконтроллеры или нет?
Ну в некотором смысле мы тоже на плюсах пишем. :-)
Суть венгерской нотации в том, чтобы указывать семантику переменной.
Это лишь побочное использование. Сошлюсь на Линуса «Вписывание типа переменной в её имя (так называемая венгерская нотация) ущербно — компилятор и так знает типы и может проверить их, и это запутывает программиста. Не удивительно, что MicroSoft делает забагованные программы. (Encoding the type of a function into the name (so-called Hungarian notation) is brain damaged — the compiler knows the types anyway and can check those, and it only confuses the programmer. No wonder MicroSoft makes buggy programs.)»
Например. А правильной ссылкой была бы ссылка на Бенджамина Пирса, Types and programming languages.Меня интересовала ссылка на описание языка ML.
В каком-то смысле, да. Я стараюсь программы писать так, чтобы в них были видны реюзабельные компоненты. Оно почему-то помогает писать заодно более поддерживаемый и дешёвый для модификаций код.
Это самообман. Посчитайте время, потраченное на реюзабельность и какое количество кода на самом деле повторно используется.
А самая главная проблема это, когда объясняешь любителю повторно используемого кода, что алгоритм долджен работать несколько иначе, а он говорит, что не может этого сделать, ибо код используется ещё в паре мест, где нужно именно существующее поведение. В результате повторно используемый код оборачивается cut & paste, что мне нравится ещё меньше.
Инженер должен уметь предвидеть, какой код стоит сделать повторно используемым, а какой не стоит.
Но если я упираюсь в шину памяти, а не в FPU, то нет.
Согласен. У нас не бывает больших вещественных массивов, область не та.
Очень по существу, спасибо.
я имел ввиду, что для отладки полезно видеть исходный код. А макроопределения, инлайны и темплейты это не позволяют. То есть мы видим мета-код, а как он инплементировался — не видно. Вот и получается, как с тем сусликом. А вкупе с «одаренными» программистами, наворачивающими пять уровней темплейтов друг на друге получается фигня. То есть красиво, но — не отлаживается.
А если серьёзно, венгерская нотация, опять же — она не обязательно про типы, это лишь один из возможных вариантов, пусть и самый распространённый
Вы за деревьями не видите леса. если бы добавляете префикс w для ширины, то тем самым выделяете некий (под)тип width. Это удобно для языков, не позволяющих объявлять свои типы. Ну как пример. В Си нету множеств, потому когда мы используем целую переменную как битовую маску — её разумно выделить префиксом. Это же касается и интервальных типов вроде wifth.
Зачем, если алгоритм вывода типов не зависит от языка?
Вам интересен вывод типов, а мне — устройство языков программирования. Есть возражения?
разрабатывая кусочки программы, как если бы вы их повторно использовали, зачастую получаются более поддерживаемые, заменяемые и слабосвязанные компоненты, которые легче отлаживать и поддерживать.
А теперь — добро пожаловать в реальный мир. О его прелестях — можно почитать в блоге daata.ru. Ну и вот эпическое — Заблуждения программистов об именах. Это вот очень похоже на наши будни…
Так что на первый план в прикладном коде выходят совсем иные характеристики. Те самые, которые вы не называли. Прежде всего — модифируемость. Даже если вы используете overengineering всегда возникают новые условия, которые не вписываются в контракты вашего кода.
Ну как пример. У вас в базе есть ключ идентифицирующий человека. Ну скажем ФИО + дата рождения + место рождения. А потом возникает повесть о несчастной Королеве, которая в половине документов Королёва. Вы бы и рады внести изменения в повторно используемый код, но беда в том. что в одной области в одном раойне у вас есть и Новосёлово и Новоселово.
Ещё пример. Вроде все части ключа должны быть обязательно не пустыми. И тут вдруг суд признает человека без фамилии.
Так что повторное использование — лишь там, где контракт точно не будет сильно меняться. А там, где очевидно, что изменения будут — вредна слабоосвзяанность и повторное использование. Там лучше монолитный, зато легко модифируемый код.
Потому что у любителей повторного использования любой ценой — частая проблема, «ой, я не могу это изменить, этот код используется ещё в 10 местах».
Попробуйте считать, что никаких контрактов на входные данные нет, что любые инварианты в исходных данных могут быть отменены. Если вам в таких условиях покажется быстрее писать повторно используемый код — ну вперед.
Да, для понимания. Мы не знаем, с какими приемниками GPS мы будем работать через 5 лет. И какие из инвариантов в них разрушатся. Проблема не в анализе исходной задачи, а в перемене условий.
А мелкие универсальные кусочки — они и у нас повторно используемые. И сидят в отдельном библиотечном репозитарии.
Только не воспринимайте это как защиту cut'n'paste — его у нас тоже нет.
То же самое можно сказать и про функции, и вообще про любые методы абстракции.
Вы не правы, Код функции я вижу и вполне могу по нему ходить, ставить точки останова и так далее. Более того, я вижу дерево вызовов.
Нормализация имён — ответственность слоя выше.
Отлично! Вы уже признаете, что в разных слоях — разные требования. А нижние слои — и у нас библиотечны и повторно используемые.
Грамотная декомпозиция помогала с этим справляться минимальной кровью.
Ну а я видел немало примеров, как любители повторно используемого кода становились заложниками своей декомпозиции.
Есть повторное использование ради более грамотного дизайна системы,
Зависит от. Если вы тратите на 20% больше времени и получаете хороший дизайн — это отлично. А если вы пишете на 400% больше кода, а потом выясняется, что ваша абстракция не годится для реальных данных — это песец (полярная лисица такая). я за первый вариант, но обычно любители повторного использования выдают второй. Классы — чудо, все операции есть, а проект не работает. Все рабочее время ушло на грамотный дизайн да повторное использование.
А код темплейтов не видите, что ли?
А код внешних функций и библиотек видите?
Макросов и инйланов — не вижу. Темплейт виден, если не заинлайнился. Внешних библиотеки — могу увидеть, если соберу с сорцами.
Во-первых, речь идёт не о разных требованиях
Да нет, именно о разных требованиях. Одно дело — самый нижний слой библиотечных процедур. Ради скорости их можно на ассемблере написать, как тот же #define strlen в glibc.А другое дело — слой прикладной логики, есть модифицируемость намного важнее скорости исполнения.
Это не значит, что любая декомпозиция плоха, и теперь не надо декомпозировать.
Конечно. Плохая декомпозиция — обычно следствие отсутствия учета требований к коду. Универсальность, повторное использование — хороши там, где они нужны.
А то некоторые из-за универсальности пишут в 6 раз больше кода, причем 2/3 этого кода просто не вызывается, 1/6 полезна при отладке и только 1/6 рабочий код. При этом уровень вылизанности — везде одинаков. :-)
Этот код можно повторно использовать, но негде. Это слова совсем. Уникальная железка, уникальный протокол общения…
И если бы разработчик не погнался бы за универсальностью. и повторным использованием — он бы уложился в бюджет из сделал бы работающую систему. А так… Когда проект перешел ко мне, пришлось выкидывать 2/3 неиспользуемого и отлаживать остальное. В итоге отладил, конечно. но матерился сильно.
Это в вашей субъективной практике, или есть какие другие данные?
Это в практике. Из литературы — почитайте у Брукса про эффект второй системы. И вообще вам совет — читайте Брукса. Сразу по иному на процесс разработки начнете смотреть.
А, вы объектный код/асм имеете в виду?
Соответствие бинарного кода исходному. Возможность поставить точку останова, например.
Некоторые. Это ключевое слово. Любую технику можно испоганить при особом желании или таланте.
Беда в том, что люди с желаниями писать универсальный код там, где он не нужен, обычно выбирают С++. Ну или учителя С++ обучают именно такому стилю.
Любители повторно используемого кода неразрывно связаны с написанием второй версии системы?
Не важно по какой причине выбирается более универсальное решение, чем нужно. Важно — что это ведет к лишним трудозатратам, разбуханию кода и меньшей надежности действительно используемого кода. Отлаживается=то все, а не только нужные 20% кода.
У меня почему-то таких проблем даже с шаблонными функциями в дебаг-сборках особо не было. В релизных — там компилятор вообще код хорошенько так переколбашивает, там весело.
Специальная дебажная сборка — это для нас экзотика. Код или работает (98%) или уж такой тонкий баг, что в дебажной сборке его не поймать.
Деление на отладочную и релизную сборку — характерно только для Visual Studio. У нас скорее отладочные и релизные исполнения приложения.
Черты отладочной сборки:
- Включена 10уровневая система логирования. Уровень логирования переключается динамически, стартовый уровень задается в параметра запуска.
- Выдается полный map (а на FreeRTOS ещё и листинги)
- Там, где есть — полный комплект символов для отладчика
- Есть отладочная консоль
- Если есть специальные отладочные функции — они скомпилированы и их вызов может быть включен из командной строки или отладочной консоли.
- Есть выдача довольно полной информации по командам с отладочной консоли или из приложения оператора
- Есть система записи бинарных данных (там, где есть файловая система)
Черты релизной сборки
- Включение оптимизации (-O2 или -Os)
- Сборка под конкретный SoC
Архитектуры: I386, ARM, SPARC, 8086(16бит)
OS: Linux, FreeRTOS, Windows, QNX, FreeBSD, MS-DOS
Компиляторы: gcc, С++ Builder, clang, lcc, Borland C++, MSVC
Варианты отладки (в порядке частоты использований):
- I386, Windows, С Builder, работа по записанным файлам данных
- Включение высоких уровней логгирования + динамическое наблюдение
- Анализ рапортов (отчетов о состоянии) и логов от заказчика
- Вставка дополнительной отладочной печати
- ARM, Linux, gcc, работа по записанным файлам данных
- Отладка отладчиком на целевой системе
Код делится на общую, ОС-зависимую и платформо-зависимую части. Аналогично, ошибки бывают общие, ОС=зависимые, платформо-зависимыеи компиляторо-зависимые.
Специфика работы состоит в том, что если мы работаем по реальным данным и встали на точку останова, то до следующего входа в режим (фиксации RTK быстрой статикой) может пройти и 5 минут. Иными слова — у нас мягкое реальное время.
Основная отладка — по записанным данным в среде разработки. А вот то, что нужно копать отладчиком… там или вылет (и есть адреса в коде) или порча памяти или нехватка стека или гонка или неиниализированные переменные…
Шансы, что при сьборке с ниыми параметрами ошибка перестанет проявляться или будет проявляться иными симптомамии — процентов 80.
Так что не обязательно колоться, чтобы понять, что лично мне не не нужен героин. Не обязательно 10 раз нарваться на то, что «в debug работает в reliase сбоит», чтобы понять, что эта система для нас не подходит.
Ну а любители debug-release с моей точки зрения должны отключать тормоза на своих автомобилях после получения. прав. :-)
Если отладочная сборка для вас экзотика, то у вас нет и не может быть статистики о том, насколько такая сборка упрощает нахождение ошибок.
Ну настолько, что интернет полон воплями «в debug работает, а reliase падает».
P.S. Запрет пользоваться чужим опытом — это логика наркомана
Деление на отладочную и релизную сборку — характерно только для Visual Studio.
В так любимых вами C++Builder и Delphi точно так же есть отдельные профили для отладочной и релизной версий программы и на тулбаре для запуска этих версий даже предусмотрены отдельные кнопки.
Промотайте до главы "Running and debugging" и убедитесь сами: https://community.embarcadero.com/blogs/entry/learn-to-program-with-c-builder-2-building-and-debugging
Таким образом, ваше утверждение о том, что деление на отладочную и релизную сборки присуще только Visual Studio — ложно.
А вот то, что нужно копать отладчиком… там… или неиниализированные переменные
У вас, профессионала, умеющего выделять ключевые слова в комментариях полужирным шрифтом, случаются неинициализированные переменные в релизном коде?
Это все современные компиляторы отлавливать умеют, даже без помощи PVS-Studio. И позволяют трактовать неинициализированные переменные как ошибки компиляции, что и следует делать.
Шансы, что при сьборке с ниыми параметрами ошибка перестанет проявляться или будет проявляться иными симптомамии — процентов 80.
Столь высокий процент плавающих ошибок — не повод ли поразмыслить о качестве кода?
P.S. Запрет пользоваться чужим опытом — это логика наркомана
Я уже заметил, что эта тема — частый гость в ваших комментариях.
Промотайте до главы «Running and debugging» и убедитесь сами:
Рекомендую использовать Google Translate, Как минимум не потеряете смысл.
These are Run Without Debugging and Run [implied, this means Run With Debugging]. это не кнопки запуска отдельных версий. Это запуск одного и того же исполняемого кода под отладчиком или напрямую.
случаются неинициализированные переменные в релизном коде?
Это все современные компиляторы отлавливать умеют, даже без помощи PVS-Studio.
Ох уж эти сказочники… Последняя история. Пишу в battery RAM (чайники зовут его CMOS), читаю — нули. В итоге выясняет — забыл на него тактирование подать. Ну вот вам даже не неинициаизированная переменная, а целая неиницаилизированная память. :-)
Ну и что тут компилятор отловит? Откуда он знает, какой у меня SoC, и как там что инициализируется?
И вообще, инициализация в одном модуле, переменная — в другом, пишем из третьего, читаем из четвертого. Вы думаете в PVS-Studio (не говоря уж о компиляторах) есть межмодульный анализ?
Наивный чукотский юноша, вы хоть в курсе, переменные не только локальные бывают.
Столь высокий процент плавающих ошибок — не повод ли поразмыслить о качестве кода?
Ну конечно, хочется, что 99% багов, за которыми полез в отладчик, были бы сложными и плавающими. Но никто не идеален, процентов 20 — можно было найти и без отладчика, просто аккуратным чтением кода и спецификаций. А так — 99.5% ошибок находятся без залезания в отладчик на целевой системе. То есть воспроизводятся по записанным файлам и не на приборе, а в среде разработки, под windows.
случаются неинициализированные переменные в релизном коде?
я не знаю, что вы имеете ввиду под релизным кодом. Деления на дебаг и релиз у нас нет. Если вы имеете ввиду код, поставленный в прибор, отправленный заказчику, то там пример 1 баг на 2-3 года. Если вы имеете ввиду экспериментальный код, залитый в прибор на стенде — ну зависит от степени экспериментов. Сейчас вот переходил на FreeRTOS (то есть практически работаем на голом железе), ну так вплоть до 5 багов в час находилось. Ну так под линуксом у нас мегабайта 3-4 памяти потреблялось, а тут ужались до 300 килобайт. Само собой, что баги полезли.
Я уже заметил, что эта тема — частый гость в ваших комментариях.
Ну не хочется уж совсем
Напоминает фигак-фигак-продакшен-дривен девелопмент.
Увы, это часто бывает у любителей С++. У них отличный код, только данные из реального мира для него не годятся.
Бинарного или исходного?
Исходного. А если наворочено на темплейтах — то иногда и бинарного.
Только, во-первых, отлаживать проще.
За счет чего?
Во-вторых, при необходимости изменений при грамотных абстракциях и прочих повторных использованиях изменять и, следовательно, повторно отлаживать нужно меньше кода.
Грамотность абстракций для любителей повторного кода обычно имеет противоположный смысл. Для нас чем более абстракция подходит под задачу — тем она грамотней. А для любителей повторного кода важнее гипотетическое повторное применение. В итоге пишутся сферические лошади в вакууме.
Ну как лично ваше достижение. Вот есть объект задвижка. Сложный, отлаженный, используемый сотни раз и в десятке проектов. И вот вы предлагали выдрать из него операцию подачи сигнала на открытие конкретной задвижки.
С точки зрения любого АСУТП-шика — это идиотизм. С точки зрения любителя С++ — нормальный ход. позволяющий втиснуть в схему RAll то, что ресурсом не является.
Ещё один пример. Стоит у вас на кухне однорычажный шаровой смеситель. ну не дошли вы до абстракции пара задвижек. Но до абстракции кран можно было дойти? Увы, это для вас фиг знает как называется, штука такая с одной торчащей палкой.
Беда не только в вас, в том, что вы никогда не сможете стать инженером, она в том, что для инженерии нужны совсем иные качества, чем для любви к С++. Может и есть исключения, но я их пока не видел.
Грамотные абстракции в мире АСУТП — это те, что отражают поведение железа. Чем больше вы делаете свой код повторно используемым — тем хуже вы отражаете конкретное поведение в конкретной ситуации.
Инженерный подход — он в том, чтобы сначала понять, что будет повторно использоваться, а что не будет. Потом — понять, что будет общим при разных повторно использовании, а что нужно параметризовать. А уж потом — писать нужное…
А любители С++… Выдрали первую пришедшую в голову абстракцию, написали кучу ненужного кода, а потом жалуются, что данные кривые. Вот и получается у них фигак-фигак-продакшен. Для сферической лошади в вакууме — работает, для реального ишака в упряжи — сбоит.
Разумеется, там, где речь не идет о реальном мире все проще. И когда вы код для цифровой реальности, то и шансы на повторное использование у вас выше и абстракции ваши будут более походи на реальность. А в нашей области у вас вечно будет фиг знает как называется, штука такая с одной торчащей палкой. И у других любителей С++ — тоже.
При этом не вы ли сидели с дебаггером чуть ранее по треду?
У нас довольно много разных проектов (и в разных местах я говорил про разные проекты, каюсь). Но специальных дебажных сборок нигде нет. Есть нечто среднее.
Если это обеспечивает большую изоляцию, то это оправдано.
Иногда. Если эта изоляция действительно нужна для дела. а не для галочки.
А то так можно, знаете, и функциями на 5 тысяч строк наслаждаться.
Можно. И очень редко — это будет оправдано. Первое, что пришло в голову — так проще при кодогенерации. То есть кормите программу алгоритмом, она выдает код на том же Си, его реализующий. И тут проще сделать все одним куском, чем учить кодогенератор разбивать на процедуры. Если не путаю — так сделан синтаксический анализатор в алголе-68. Кодогенератор кормят формализованной грамматикой, а он генерит огромную процедуру парсера на том же алголе-68.
Ещё раз. Для инженера главное — адекватность решения задаче. А не какие-то формальные критерии хорошо-плохо.
Фиг знает, какой смысл вы вкладываете в слово «инженер»
Ну если вы не видите абстракции «два крана» и называете "штука такая с одной торчащей палкой," — вы не инженер и никогда им не станете.
Инженер — это тот, кто понимает, какие требования к коду. И делает код под требования. А вы — математик. Поэтому сферическая лошадь в вакууме вам милее каурой. И брыкается, и срет и ржет…
В своей области — вы можете быть адекватны своим задачам. В нашей — фи… полное непонимание основ. И нежелание их понимать.
Разделение ответственностей и прочие умные слова редко когда нужны для галочки.
Увы :-( Программа должна работать. Выполнять требуемую функцию. А все остальное (повторное использование, читаемость, модифицируемость, изолированность...) лишь вспомогательные характеристики работающей программы.
То есть на первом месте — работоспособность, на втором — затребованные характеристики (модифицируемость, устойчивость, надежность...), а лишь на третьем — всякая изолированность, повторное использование и так далее.
А когда любители С++ ставят несущественные характеристики на первое место — получается плохо. Код — конфетка, классы, темплейты, все повторно использованное. Но — не работает. И работать не может. Изменить поведение классов «нельзя» — они повторно используемые. Сделать наследника тоже «нельзя» — изоляция не позволяет. «Нельзя» — в смысле автор против. :-) Ну и как водится кода больше в 10 раз, чем нужно.
И это, увы, типично. Ну как пример — ради изоляции в Windows NT 3.1 видеоподсистема (GDI) была вне ядра. Изоляция — отличная, но… производительности не хватило. В итоге — в 4.0 её >с помпой внесли в ядро. :-)
Так что изолированность — это третьестепенная характеристика, которой обычно можно пожертвовать ради более важных вещей. Думаю, что даже вы делаете нити, а не процессы. Хотя изолированность процессов — намного больше. А вот там, где изоляция важнее производительности — там делаются отдельные процессы. Самый известный пример — Chrome.
Я описываю внешний интерфейс. А как оно там на самом деле называется, меня не очень волнует, всё равно ремонтировать это будет специально обученный человек.
Да такое впечатление, что вы и пользуется «специально обученный человек». Там простая абстракция — две задвижки. Оси управления задвижками перпендикулярны и направлены под 45 градусов (вправо-вверх и влево-вверх). Если мы переходим к прямым осям, то вверх ось суммы, а вбок — ось разности.
Так если бы кодогенерация, никаких вопросов бы ни было. Так нет же, это всё руками писалось.
Ещё раз. Очень редко — это будет оправдано. Ничего не могу сказать, не зная задачи и требований к коду. Вообще, деление на подпрограммы — не елинственный способ выделения. Например, в OMRON Ladder подпрограммы есть. Но… обычно не используются. Программа делиться на блоки, блоки — на нетворки, нетворки — на цепи. Но в принципе — это единый огромный кусок кода с общими глобальными переменными.
Если программу с Lаdder переписывать на другой язык, то скорее вредно оформлять нетворки как подпрограммы. Порядок исполнения нетворков важен, а при подпрограммном оформлении он более подвержен искажениям.
И как-то я особо не видел и не слышал жалоб и недовольства по поводу понимания требований.
Тогда непонятно, почему в нашем разговоре вы их не понимаете. Вроде не сильно сложные вещи объясняю.
Давай не путать — мы ненастоящие программисты. У нас многое не так.
На этом надо, наверное, заканчивать дисскусию.
Напробовался. Цензурных слов нет, очень тянет блевать. я понимаю, у вас логика наркомана: да как ты можешь судить о героине, если ты 5 лет не кололся?!
Чушь. Вы так говорите, как будто за все эти годы студия не менялась. Видимо это из-за у вас такое мнение, что за 17 лет Builder C++ 5.0 не поменялся ни на грамм.
То есть случайно мышку оставил над переменной, а потом окно закрывать? Ну очередной минус VC++.
Такими выссказываниями мы показываете свой никакой уровень владения студией, не более того. Не надо делать никаких выводов из выссказываний других людей, скорее всего ошибётесь. Вот и здесь, вы неправильно интерпретировали, что я сказал (на самом деле додумали то, что я не говорил), и сделали какие-то выводы.
Они есть во всех языках, только стандарт фортрана их выделил явно.
Куда вас всё несёт? Причём тут фортран. Мы про C++ говорим.
Угу, типичное мнение любителя микрософт. я выбираю инструменты под свои задачи. И говорю, что данный инструмент плох для наших задач. А мне начинают втюхивать, что задачи у нас неправильные, код не тот, операционные системы не те, железки не такие… Ну в общем нужно все бросить, фирму закрыть и идти путем one microsoft way. Вам самому не грустно?
Я вам про одно, вы про другое. Повторю (надеюсь, всё таки смогу свою мысль донести), при решении задачи надо выбирать правильный инструмент, которым эту задачи надо решать. Но, если вы для своей задачи забивания шурупов выбрали навороченный микроскоп с функцией затягивания болтов, то это не повод называть молотки отстоем. Да у молотков есть своя область применения, и если она вам не подходит (надо не гвозди забивать, а шурупы, в данном примере), используйте другой инструмент. Но это не значит, что все другие инструменты, без так необходимой вам нестандартной функции забивания шурупов — отстой.
Упаси нас боже от этого ужаса. Лучше уж вернуться на голый Си.
Этим вы только подтвердили, что я говорил. Безосновательные страхи, основанные на незнании. Ну чтож, человеку свойственно бояться неизвестного.
Там, где нужна надежность — никогда не используется ничего нового.
Никогда слишком громное слово. Скорее всего вы хотели сказать, что лично вы никогда не используете ничего нового, когда нужна надёжность. И что для вас новое — это что-то моложе 10-20 лет. Просто у других людей всё может быть по другому, например, попробовал раз в одной проекте, не требующем 100% надёжности, в следующий раз можно уже и в таком проекте использовать, без необходимости дожидаться 10летней безотказной отработки этого первого продукта.
Какую связь лямбры имеют с stl-контейнерами?
А где они ещё нужны?
…
Опять таки, вы просто показали, что лямбды ничего не знаете, что нам было уже и так понятно.
Вот вам переписанный пример из вики (хотя пример притянутый за уши) не для контейнеров, а для С-массива:
int someList[100] = ...;
int total = 0;
std::for_each(begin(someList), begin(someList), [&total](int x) {
total += x;
});
В общем люмбды, можно использовать как без контейнеров, так и без stl вообще.
У тех, кто выдает объект как результат функции. Например часто результатом функции бывает std::string. Вот тут экономия огромная.
«Больной, не делайте так».
Мы не используем кучу. Следовательно, мы не используем STL. Мы вообще пишем на Си с некоторыми элементами С++.
Я очень раз за вас лично. Можете и дальше так делать. Только просьба никому не доказывать, что это круто, и что все должны делать как вы.
Вы так говорите, как будто за все эти годы студия не менялась.
Ну как минимум она не сильно менялась за последние полтора года, когда была самой свежей та версия, что мы ставили.
при решении задачи надо выбирать правильный инструмент, которым эту задачи надо решать.
я ровно об этом и говорю. VC++ не подходит для решения наших задач. Ещё раз и громко — НАШИХ задач. Если вам она годится — это ваши проблемы.
Только просьба никому не доказывать, что это круто, и что все должны делать как вы.
Ещё раз и громче. Студия не подходит для решения НАШИХ ЗАДАЧ.. НАШИХ ЗАДАЧ.. НАШИХ ЗАДАЧ.. НАШИХ ЗАДАЧ..
А то, что вы на пустом месте фантазируете про иные задачи — это уже ваши проблемы с пониманием смысла текста.
А если вы 20 лет поваритесь в АСТУП и embebded — вы оцените, что для наших областей наш подход верный. А для highload — верен ваш подход, не спорю. Там в чести самые свежие версии с самыми свежими багами.
Вот вам переписанный пример из вики (хотя пример притянутый за уши) не для контейнеров, а для С-массива:
Господи, какая кривь!!! И насколько лучше это смотрится без лямбд. Мне что-то кажется, что вы и сами видите, что в вашем примере лямбды лишь ухудшают читаемость кода.
В общем люмбды, можно использовать как без контейнеров, так и без stl вообще.
я вам страшную тайну открою, std::for_each — это STL
«Больной, не делайте так».
Увы, это стандарт С++ такой. string operator+ (const string& lhs, const string& rhs);, et cetera, et cetera… Костыль на костыле и костылем погоняет.
Скорее всего вы хотели сказать, что лично вы никогда не используете ничего нового, когда нужна надёжность.
я хочу сказать, что использование нового запрещено на уровне стандартов отрасли. Нужна наработка на отказ 10 лет — предоставьте результаты испытаний в течение не менее 10 лет. А не опыт с искусственным старением.
я в своей отрасли сам удивляюсь. Знаете, какой GPS приемник летает на современных самолетах? Характеристики уровня 1990ого года, элементная база — примерно 1975ого года. Пару лет назад сменили, теперь характеристики года 1995ого. Если интересно — могу ссылки покидать на разную технику, будете сильно удивлены. ну вот вам процессоры для затравки — это примерно Pentium II. По нашим меркам — весьма современные. Через 2 года самые слабые из них снимут с производства. А те, что помощнее — ещё лет 10 будут производиться.
Господи, какая кривь!!!
Не пытайтесь уйти от темы. Вам доказали что вы были неправы, надо просто написать, «да был дураком, не знал о чём писал, буду умнее. прочитаю RTFM.». А вот уводить разговор в сторону не надо. И так всем (может кроме вас, конечно) очевидно, что пример притянут за уши, и в реальности такой код никто не напишет. Это была просто иллюстрация, что лямбы не связаны с stl-контейнерами, как вы утверждали.
я вам страшную тайну открою, std::for_each — это STL
Мы уже поняли, что вы застряли в 2000-м году на C98. Неужели вы реально могли подумать, что вы кому-то открыли тайну?
Увы, это стандарт С++ такой.
Ни в одном стандарте С++ не написано. что вы обязаны делать 5 вызовов этой функции на 100 строчек кода.
я хочу сказать, что использование нового запрещено на уровне стандартов отрасли.
Раскройте тайну, как у вас появляется эта наработка на отказ, если ничего нового использовать нельзя? И даже более интересный вопрос: почему ваше железо покупают, пока оно где 10 лет безотказно не проработает. Т.е. по вашей логике, написали вы новый код. Он должен где 10 лет покрутится, иначе стандарты отрасли (слово то какой пафосное) запрещают его ставить в эксплуатацию.
В отличие от вас, я прекрасно понимаю, что любое языковое средство делается для решения своих задач. Есть области где оно годится, есть — где не годится, есть — где выглядит уродливым костылем. И только любители микрософта считают, что все должны идти строем по one microsoft way..
Раскройте тайну, как у вас появляется эта наработка на отказ, если ничего нового использовать нельзя?
В бытовых применениях испытывается. (с) Ваш К.О.
Предлагаю вернуться в правильное русло.
Вообще под студией вы и остальные понимают 3 вещи:
— иде
— компилятор С++
— стандартная библиотека
1) Если говорить про иде, (а изначально разговор вроде про неё шёл?), то вполне себе нормальная иде, которая позволяет легко писать код, (притом любой код, хоть java; с лёгкой навигацией, с нормальным редактором, с поддержкой рефакторинга, с фичами типа IntelliSense, поддержкой VCS, моделированием, плагинной системой (можно читать как интеграций во всё, что только можно) и множества других), легко отлаживаться (по крайней мере удобно. не весь функционал windbg доступен, ну чтож, зато не перегружен и интуитивно понятен основной интерфейс. + фичи типа IntelliTrace и т.д.), позволяет подключить любой компилятор (интел сам тулсетом встаёт, clang' сами майкрософтцы допили под винду, можно этот тулсет использовать из коробки, для mingw тулсет вроде как народные умельцы сделали, использовать можно). В общем есть всё, что можно ожидать от нормально IDE и даже множко сверху. Уверен, что, иде, скажу мягко, не хуже, чем любая другая иде 17-ти летней давности.
2) компилятор: его можно тоже по нескольким параметрам рассматривать. например, поддержку стандарта, надежность (чтобы сам компилятор не падал), качество генерируемого кода в плане скорости, качество генерируемого кода и отладночной информации, чтобы потом можно было дампы с клиентов разбирать и т.д.
Так вот по этим показателям, это вполне себе современный компилятор. Я уже писал, что стандарт поддерживает даже лучше интеловского, по надёжности лучше чем gcc (возьмём для определённости) 4.9, в котором я уже начал уставать от internal complier errors. Качество генерируемого кода сейчас тоже не плохо, помню ещё vs2012 практически догнал интеловский, сейчас уже не уверен, что разница найдётся. ну и как плюс есть много нового, что ещё только на стадии включения в стандарт. Те же модули или await'ы, например.
3) здесь похожие критерии: соответствие стандарту, эффективность реализации, отладочные фишки, и т.д.
Так вот, здесь всё тоже неплохо. МС довольно сильно помешано на стандарте, правят все найденные несоответствия со стандартом довольно быстро. (на самом деле она смотрят всегда на последний драфт, ну это не важно). Все стандартные функции реализованы очень эффективно (пример, внутри memset/memcpy/и_т_д есть реализация на AVX, помимо реализации на SSE2 и помимо реализации на MMX).
Я в общем к тому веду, что обсирать студию точно не стоит, вполне, да же так, ВПОЛНЕ, себе достойный коммерческий продукт для разработки. Ну а как иде обсирать её не стоит особенно.
В итоге получается, что я на привычном мне билдере выигрываю от 2 до 7 раз и на написании кода и на его отладке и на изучении чужого кода. Выигрываю у тех, кто давно работает в VC++.
Личные впечатления от переноса кода под VC++ — отвратительные. Впечатления от отладки в нем — ужасные. Да, чуть-чуть не допили, ну совсем чуть-чуть, но это чуть-чуть дает скорость и удобство от отладки.
Ну представьте, что после мерседеса вы пересели на запорожец? Вроде и руль есть и тормоза и передачи переключать можно… Но явно машина не того класса…
Так что я не вижу смысла бесплодно терять время на изучение VC++. Надо именно в нем — значит скомпилюсь и отлажусь именно в нем.
И да, я верю, что вы можете работать в 2-7 раза быстрее тех кто «давно работает в VC++», притом давно — это лет 17, и всё также на MSVS 6.0 с тех давних времён.
То, что вы просто похоже не знаете, как происходит разработка в студии, и при этом так о ней судите не даёт вам плюс
Пока вы за день пишите и отлаживаете новую форму в билдере, кто-то их по 5 штук за это время на Qt в студии лабает. И в ус не дует.
Забыл добавить: При этом, пока вы за день делаете непереносимую фигню на VCL, разработчик в студии делает кроссплатформенную фигню на Qt.
Кроссплатформенность в GUI нам пока не нужна. А будет нужна — в том же дельфи можно компилировать для «Windows, Android, iOS, OS X». Так что вы просто не разбираетесь.
Но вообще я бы предпочел на мобильники и планшеты делать своё приложение, а не портировать виндовое. И задачи несколько разные и приемы работы иные и размер экрана несколько не тот… Потому на мобильники — простые экраны с 1-2 функциями, а на виндоус — сложный экран с кучей данных. Смотреть-то на мобильник будут с расстояния порядка метра (если не 2-3), как на навигатор.
Вот когда поработаете с ней немного,
Немного, это сколько? 20 лет работы и миллион строк кода? у нас два проекта на VС++, по 10-20 тысяч строк кода каждый. И ещё тысяч 30-40 строк кода адаптировано под студию. И да, это в последний раз это было VC++ 2015 (или 2013) — лень сейчас брать ключ и смотреть. Впечатление от студии — омерзительные и нецензурные.
Немного, это когда перестанете явный бред нести про неё. Я даже верю, что у вас есть пару проектов на VC, но подозреваю, что там не лично вы ими занимаются…
Ну да, если 20 лет есть дерьмо полной ложкой, то желание критиковать утихнет. Увы, пришлось самому с VC++ работать. Пока не работал — относился нейтрально, как поработал — так
В Develop Studio да, была поддержка разных языков в одном IDE.
А про дерьмо, вы тут уже за 3 дня довели до ситуации, когда тянет блевать.
Нам с Astra-linux больше повезло, gcc 4.9
4.7.2 должен быть, судя по http://www.astralinux.com/osnovnye-komponenty.html
Я что хочу заметить, PVS больше всего ошибок находит как раз в C-style коде. Так как мы уже полностью ушли от malloc/free/strcpy/strcat/printf/memcpy/ и даже от delete/new, то 2/3 диагностик к нам уже не применимо, так опечатки где-то отлавливает, или муть в условиях.
А вот вам, учитывая «Мы пишем на Си с отдельными элементами С++.» этот инструмент может оказаться гораздо более эффективным. Рекомендую, пока сотрудникам поставить триалки, пусть даже пока скрыть все ворнинги, которые уже есть на данный момент, и поработать пару месяцев на инкременталке. Если за пару месяцев триальные клики закончатся, то этот инструмент вам явно нужен.
А по логу, соглашусь с авторами, это уже не так интересно, так как даже если проверять периодически, то что-то уже будет попадать в основную ветку, тратиться время тестирования и т.д. Лично я лог рассматриваю как проверку, что никто не отключил статанализ, или не забил на него.
1) Есть системы, где декларируемое время простоя может быть сильно ограничего. Например, для АТС помню, в северной америке в полиции downtime был всего 7 минут в год. Т.е. 7 минут, на все падения, переключения на failover, и т.д. И даже на установку нужных апдейтов отдельного времени не давалось. Даже если типичное время переключения на другую ноду всего 30 секунд, то это максимум 14 сбоев в год (в реальности 2-3). В больницах помню, что-то около 30 минут в год было, уже неплохо.
2) есть функциональность, которая может просто работать неправильно. Например, неправильно собираем RTP поток с удалённого устройства, или какая бага у тебя в реализации RTSP/SIP/другой протокол. И воспроизводится она только с железками такого-то бренда, если у него такие-то настройки на такой-то версии фирмваре. И тут, хоть обзапускай сервис, хоть обпереключайся между серверами, а, скажем, RTP поток ни один из сервисов, ни на одном из серверов, собрать правильно не сможет.
Я к тому, что качество кода, всё-таки это играет определённую роль.
И даже на установку нужных апдейтов отдельного времени не давалось.
А зачем оно? Ставим апдейт на ноду теплого резерва, потом выводим её в горячий резерв, а из ноду горячего — в теплый.
Даже если типичное время переключения на другую ноду всего 30 секунд
Типичное время переключения в горячем резерве — микросекунды. Ну как предельный пример — четырехпроцессорный Simatic для АЭС. Два процессора через два модуля ввода-вывода получают одни и те же сигналы. При рассогласовании процессоров (аппаратная проверка каждый так) идет переключение на вторую пару. В софте подобные подходы спасают не всегда, но довольно часто.
А 30 секунд — это теплый резерв. Впрочем, в highload с резервированием и балансировкой справляются ещё лучше, чем в АСУТП.
Ну функциональность, которая не работает с одним из брендов, обходится просто — данный бренд не включается в список оборудования, сертифицированного для работы с программой. :-)
Так то бывает, что проблема не находится на стадии тестирования, а всплывает только у клиента.
Типичное время переключения в горячем резерве — микросекунды.
Это да, только в часто ноды, которые в горячем резерве и падают одновременно :-). Ну а дальше начинается, что дублировать каждый сервер клиент не в состоянии финансово, поэтому есть некий кластер, с N рабочими серверами и с M резервными (N >> M). И переключение на резервный сервер уже не микросекунды занимает, и даже не миллисекунды. Да, 2N серверов, часто встречается, только в идеальном мире, да в мечтах разработчиков.
Так то бывает, что проблема не находится на стадии тестирования, а всплывает только у клиента.
В АСУТП?! Проект делается под клиента и его оборудование. Коробочные продукты — это только полуфабрикаты. После комплексной отладки у клиента ещё идет стадия опытной эксплуатации, потом опытно-промышленной. НеЮ бывает, что сразу в опытно-промышленную эксплуатацию проект ставится. Но это некий высший пилотаж.
Да, 2N серверов, часто встречается, только в идеальном мире, да в мечтах разработчиков.
ну и в АСУТП. Там даже люди часто дублируются. Ибо что делать, если у дежурного острый аппендицит прямо на смене? Значит нужна горячая замена.
Это да, только в часто ноды, которые в горячем резерве и падают одновременно :-)
А вот это уже
Надежное написание требует примерно 30% от стоимости проекта. Дело не в гавнокоде, а в том, что когда период обнаружени я ошбок больше месяца — это не означает, что ошибок в системе нет. Есть! И довольно много: 1-2 на тысячу строк кода. Просто выискивать их все займет десятки лет.
А это у вас опять вредное влияние VC++. Нету в VC++ конструкция try...finaly — значит обеспечивать надежность можно делать только на уровне компов.
Кто только что возмущался (предъявлял это студии) на тему использования не стандартных, не переносимых конструкций? Ну нету finaly в стандарте. И не найдёте вы её, не в gcc, ни в clang'e, ни в icl.
А если серьёзно, то в студии есть поддержка виндовых SEH'ов, в том числе и __try/__catch/__finally.
А если ещё более серьёзно, то уже давно (видно 19 лет назад об этом не знали, но вот 18 назад уже точно было :-) ) люди додумались до RAII. Так что проблема с отсутствием finaly в стандарте C++ сильно преувеличена (именно поэтому и отклонили внесение finaly в стандарт).
Не может микрофсот уже 25 лет сделать, чтобы Word не вылетал с потерей набранного текста
Чёрт, у меня Word на работе последние 5 лет не вылетал ни разу (при том обычно открыто 5-10 документов), в отличие от OpenOffice дома. ЧЯДНТ?
Надежное написание требует примерно 30% от стоимости проекта. Дело не в гавнокоде, а в том, что когда период обнаружени я ошбок больше месяца — это не означает, что ошибок в системе нет. Есть! И довольно много: 1-2 на тысячу строк кода. Просто выискивать их все займет десятки лет.
Вот это адекватная фраза, с ней сложно не согласится.
Ну нету finaly в стандарте.
Есть-есть… Просто это не С++, а Objective C.. ну или java или delphi.
люди додумались до RAII.
я уже описал, почему RAll нам не годится. Ну не для реального мира он. Ибо завязан на LIFO.
Чёрт, у меня Word на работе последние 5 лет не вылетал ни разу
я видел человека, не перезагружавшего Win95 месяцами при дюжине постоянно запущенных программ. Будете на основе этого превозносить Win95 как безглючную систему?
Есть-есть… Просто это не С++, а Objective C… ну или java или delphi.
Ну вот опять куда-то уходите. То VC такой плохой, что это не поддерживает (хотя это вы от незнания ошиблись ), в отличие от мега-крутого Builder'а. Теперь C++ целиком виноват. Пора вам выкидывать Builder на свалку истории в таком случае.
я уже описал, почему RAll нам не годится. Ну не для реального мира он. Ибо завязан на LIFO.
Вообще не понял, причём тут LIFO. У всех годиться, а тут видите ли нет.
я видел человека, не перезагружавшего Win95 месяцами при дюжине постоянно запущенных программ.
Ну вот видите, а вы всё майкрософт ругаете. Видно же, что вы неправы :-)
Вообще не понял, причём тут LIFO. У всех годиться, а тут видите ли нет.
RAll придумали для захвата ресурсов. Чтобы избежать deadlock используется LIFO. Это все абсолютно разумно для многопоточных приложений. И неразумно в жизни, где LIFO не соблюдается.
Если на школьном уровне — «Захватили ложку, захватили вилку, отдали вилку, отдали ложку» ложиться на RAll. А вот наоборот («Захватили вилку, захватили ложку, отдали вилку, отдали ложку) — это уже не RAll, Потому что для RAll области действия объектов должны быть вложенными. А тут они пересекаются, но ни одна из них не вложена в другую. На этом уровне понятно?
Ну вот видите, а вы всё майкрософт ругаете.
Люди настолько хорошо дрессируемы, что приспосабливаются не только к микрософту.
62 килобайта оперативной памяти, машина М-6000 в режиме разделения времени. 5 терминалов, за которыми отлаживаются программисты. диспетчера памяти нет, защита памяти — только 2килобайт загрузчика, и то — прибиваемая. Каждый новый сотрудник приводил к нестабильности системы (3-4 перезагрузки в день) на срок 2 недели. А через 2 недели — опять как утром загрузились так до вечера работаем.
Кстати, если вы читали Ли Вон Яна, то оно, похоже, как раз там писалось. Конечно не мной, а моим шефом.
Если на школьном уровне — «Захватили ложку, захватили вилку, отдали вилку, отдали ложку» ложиться на RAll. А вот наоборот («Захватили вилку, захватили ложку, отдали вилку, отдали ложку) — это уже не RAll, Потому что для RAll области действия объектов должны быть вложенными. А тут они пересекаются, но ни одна из них не вложена в другую. На этом уровне понятно?На этом уровне понятно — непонятно с чего вы решили, что try… finally вас спасёт. Он точно также предназначен для вложенных действий над объектами. Причём в отличие то RAII (где отход то простого LIFO у вас всегда очевиден и нагляден, так как одному объекту приходится управлять несколькими сущностями с хитро вложенными временами жизни) в случае с try… finally конструкции с вложенными временами жизни и конструкция с обычным LIFO и хитрыми вариантами с впуском-выпуском выглядят одинаково (люди ленивы, а 10-вложенные try… finally «некрасиво выглядят») и вопросы типа «а что делать если во время подготовительных операций к закрытию выпуска произошло исключение — впуск-то закрывать или нет?» внимания не привлекают.
В любом случае, RAll предназначен для захвата ресурсов. А для всех остальных целей — это костыль. Предназначение try — работа с исключениями.
Если мы ради RAll разнесли единую технологическую операцию по трем разным кускам кода о какой читаемости можно говорить?!
Ну в общем костыль на костыле и костылем погоняет. Как многое и многое в современном С++.
Хороший пример цепочки костылей
- Костыль «объекты живут не только в куче»
- Раз не только в куче — пришлось делаььб костыль выдачи объектов как результата функции
- Выдача происходит плохо — ввели костыль семантики копирования
- Опять хреново — сделали семантику перемещения.
А если бы объекты жили только в куче — все было бы проще. И функции могли бы выдавать только ссылки на объекты.
Но увы, мне это тоже было не очевидно в 1990ом году.
Это одна из причин, почему мы пишем на Си с элементами С++. А не на С++.
Но вы это напишете один раз в одном классе, оттестируете по самое не балуйся, и потом везде будете использовать читабельный и поддерживаемый код.
Чушь собачья! Полное непонимание нашей предметной области! Код в деструкторе — одноразовый, применим только для данной технологической операции… В этом отличие реального мира от абстрактных сущностей (ресурсов). Сильных отличий два:
- часть освобождения (finally, деструктора) уникальна для каждой операции
- часть захвата (конструктора, try) не атомарна и тоже уникальна
В итоге RAll — это багоопасный костыль. Код из одной процедуры расплывается по 2-3 местам. Ну поймите вы, что реальный мир и математические абстракции вроде ресурсов — разные вещи. Мы не захватываем дверь — мы её открываем или закрываем.
Да, внутри будет флаг, проверяемый в деструкторе
И это ещё один костыль.
Только куча медленная, стек быстрый, а escape analysis — штука ненадёжная, и не с плюсовой системой типов.
Поэтому структура с методами и объект — должны быть несколько разными вещами.
Опыт показывает, что у говорящих так людей основная причина неписания на плюсах — отношение к плюсам как к С с классами
я не утверждаю., что С++ плохой язык. Но он очень не походит к нашей области. Не верите — попробуйте сами. У нас есть задачи, которые мы готовы дать на аутсоринг. Но готовьтесь к тому, что большая часть плюсовой библиотеки просто не влезет в ПЗУ.
Интересная предметная область, если писать повторно используемый код там не приветствуется.
Ну давайте взглянем на реальную жизнь… Что это какое у вас на шее? Почему не повторно используемое? Не годится. Вот у вас есть ягодицы, по форме подходят и тоже частично волосатые. Так что берем и ставим на шею третью ягодицу, Думать нечем, кушать и дышать тоже, зато повторное использование в полный рост. Нравиться?
Ну такая реальная жизнь, что в ней довлеет экономика. Если путем отказа от повторного использования что-то будет быстрее и удобнее — значит повторно не используем. Потому голова у вас не похожа на ягодицу, а ноги — на руки. И даже пальцы — все разные. Уж мелочь, казалось бы — а повторного использования нет.
Есть объект задвижка. Он более-менее типовой, их под сотню на не самом крупном проекте. Но задвижка — это не ресурс. Она не рождается в момент открытия и не исчезает в момент закрытия.
Есть труба. В ней две задвижки; выпуск и впуск. И одна технологическая операция, описанная на пяток комментов выше. Самое больше, что можно представить — это реверс.
А все остальные задвижки — в совсем других местах. У вас всего один анус с клапаном. И процедура управления анусом — совсем не то, что управление уретрой. Хотя вроде и там и там — задвижка. Ну то есть сфинктер. А в пищеводе — оно совсем иначе. И вообщем-то там даже и не сфинктеры.
Вот так и на заводе. Зачем заводу два ануса? У него один. А все прочие трубы — имеют другое назначение. Все технологические операции до и после закрытия задвижки уникальны: транспарант зажечь, проверить наличие рабочих в опасной зоне, давление стравить, масло проверить. Было бы все однотипно — вы могли есть через анус и испражняться через рот. Ну вот и подумайте, почему вы этого не можете. И завод тоже не может.
Нету повторно используемого кода в технологических операциях. Нету.. А там, где есть похоже оборудование — повторно используются технологические операции целиком. Ну вот как руки у вас более-менее одинаковые, а суставы — разные.
Так, на аналогиях, понятней стало? Если нет — то просто запомните, что голова — это не ягодица, хотя и очень похожа по форме.
Тесно связанные, при этом.
Угу. :-( Это дополнительно ухудшает и написание и модернизацию. Технологические операции нужно один куском писать. Причем так, чтобы логика была понятна технологу. А хотите багов — распихивайте тесно-связанные куски по разным местам кода. Рано или поздно рванет, гарантирую.
Зачем? У нас же всё, вообще всё на куче живёт согласно вашему предложению, разве нет?
Затем, что это совсем разные сущности. Есть записи — это строки СУБД или записи на перфокартах или магнитной ленте… Добавление к ним методов не меняет их сути. А есть объекты. Это такая умная штука со скрытыми потрохами. У объекта есть несколько интерфейсов (пропертей, методов), но все самое важное — под капотом.
А вообще почитайте описания. Я вам собственно основы delphi излагаю.
Плюсовой библиотеки чего?
Например текстового ввода-вывода. Никогда не думали, сколько стоит std::cout << «Hello, world!\n»?
Есть. try/finally, в конце концов, тоже разворачивается в некоторый код компилятором, который вы, внезапно, повторно используете.
Уровень вашего понимания понятен. try finally -это не технологическая операция. Если вы не можете отличать операции реального мира от операций с программными объектами — мне вас очень жаль.
Почему по разным? Они пространственно тесно связанные.
Потому что по разным. Сотня-две строк технологической операции, и вне её — деструктор с вызовом закрытия задвижки. Да, они связаны, Но читабельность и надежность кода — сильно падают.
Думал. И сколько стоит std::cin/ifstream, тоже думал. Оказывается, кстати, что чуть меньше, чем fscanf
Ого, как много! мы даже printf в мелком embeded используем свой, на сотню строчек. А не системного монстра.
Когда мне нужна производительность и оптимизация работы с памятью, я беру mmap и boost::string_view
А когда она нужна мне, я придумываю свой велосипед, который ускоряет от 10 до 1000 раз. И не заморачиваюсь на копеечных оптимизациях.
А если серьёзно, почему try/finally не технологическая операция
По определению.
Технологическая операция — это часть технологического процесса, выполняемая непрерывно на одном рабочем месте, над одним или несколькими одновременно обрабатываемыми или собираемыми изделиями, одним или несколькими рабочими.
Конечно, я выразил свою мысль не очень грамотно, поэтому повторю.
Сами технологические операции (завинтить винт, закрыть задвижку, зажечь транспарант) — вполне стандартны и обычно исполняются готовыми функциональными блоками (объектами или процедурами).
А вот техпроцесс записывается без повторно используемого кода. Если оборудование одинаковое — использует техпроцесс целиком, просто с привязкой к другим входам и выходам.
Но записываем мы техпроцесс только так, как его нам дал технолог. Потому что любая отсебятина с повторным использованием — чревата проблемами. Включая, в том числе и аварии с человеческими жертвами. Технолог — может сгруппировать технологические операции в комплексную технологическую операцию. А программист на это права не имеет.
А мне бы пару гигабайт с диска считать и распарсить побыстрее.
Это совсем иная область.
Куда уж быстрее memory mapped files
Сколько процентов времени занимает загрузка страниц из файла? Если 50% — можно ускорить почти в два, ведя загрузку одной нитью (prefetch). а обработку другой.
Ещё один финт ушами — динамическая кодогенерация под конкретную задачу. В 1993ем на году мы на этой технике достигли скорости полнотекстового поиска в 10 тысяч записей в секунду, что было лишь в полтора раз медленней скорости диска. Это под MS-DOS на I386. Второй финт был в том, что поиск велся по запакованным полям без их распаковки. Это в пару раз ускоряло чтение и сам поиск. Автором сего чуда был Антон Москаль, более известный по Паскаль-Москаль и TMT-паскаль, а я там так — прикладной код писал и баги ядра отлавливал.
А самый главный вопрос, впрочем, устраивает ли вас такое изоморфное преобразование try/finally в что-то RAII-подобное, или нет.
В исходном коде — нет. Преобразованиями должен заниматься компилятор. А человек — писать так, как ему понятней. Понятней написание технологического процесса сверху вниз. Вы пример попробуйте записать. Вместо чтения 1-2-3-4 у вас получится что-то 3-1-4-2.
Нет, на синхронизацию больше времени убьёте, если обработка достаточно дешёвая.
Синхронизация там простейшая — первый тред атомарно пишет текущий адрес, второй его читает. Видимо под синхронизацией вы имели ввиду переключение контекстов между тредами. Чтобы не терять на нёе время — запустите prefetch на другом ядре.
Да и readahead в ядре при последовательном чтении очень неплохо справляется.
Ну если у вас linux и никуда переносить не надо — то вы правы. А если нужен перенос? Кроме того, сомневаюсь, что linux закачает вам кэши L2 и L3, не говоря уже об L1. На некоторых алгоритмах, линейно идущих по файлу, можете выиграть очень прилично, вплоть до половины отношения времени загрузки из памяти к времени загрузки из кэша.
Главное — придти к согласию, что такое преобразование по крайней мере корректно.
Преобразование вообще-то в обе стороны работает. А чтобы понять, что важнее — глянем в код. Вызовы деструкторов компилятор генерирует? Значит есть часть finally.
А дальше мы имеем смешную ситуацию. Для лямбды вы видите удобство в написании кода в точке вызова. А для try..finally — вы почему-то за обратное, за вынесение кода вверх, выше try. Будьте уж логичны, не нравится написание кода в точке выполнения — объявите тогда лямбды злом. :-)
Ситуация одинаковая — и лямбды и try-finally удобнее для одноразового кода. А для повторного использования — RAll и обычные классы с operator().
Вот самое забавное в свете всей дискуссии — сейчас вы предлагаете обобщённое решение в том месте и в том контексте, который обобщить, скажем так, весьма трудно.
Это называется инженерный подход. Когда главными факторами является читаемость и быстрота модификации кода — это одно. Когда особых требования нет — универсальное решение лучше. То есть вначале изучаем требования, а лишь потом предлагаем решение.
Что за текущий адрес? Откуда второй тред узнает, что первый оттуда прочитал, и можно писать дальше?
Что??? Первый тред занимается обработкой. И работает независимо от других тредов (в том числе и в их отсутствие). Текущий обрабатываемый адрес записывается в глобальную переменную atomic_t. Второй тред читает данные на некотором смещении от этого адреса и тем самым заносит их в кэши L2 и L3. Возможен и третий тред, делающий загрузку отмапленных страниц в память. Где тут потери на синхронизацию?!
Префетчер в процессоре сам всё закачает,
Можно ссылочку на технологию префетчинга данных? Ну и на каких процессорах она есть.
Если будет нужен — буду смотреть на конкретную целевую систему и думать, как там сделать быстрее.
Разумно. Это как раз инженерное решение. Жалко, что в иных местах вы его отвергаете.
Нет никакой конкретной точки вызова, любой стейтмент внутри блока теоретически может быть точкой вызова
Теоретически и крокодилы летают. Только низенько-низенько. Практически у нас будет goto к точке finally и вызов деструкторов только в ней. Можете сами убедиться. Размотка стека — по вкусу, или до goto или в finally.
А тут ещё один момент. я люблю писать код, который слабо нуждается в оптимизации. То есть у меня -O1 от -O2 отличается на проценты, а -O3 часто хуже -O2. А у вас в коде без оптимизации скорость падает в разы. Опять-таки, это старая школа — раньше советовалось не рассчитывать на оптимизатор, а писать эффективно.
Так, подождите. Вот у вас есть два треда, один файл читает, другой, для простоты, идёт по замапленному и делает всем найденным строкам-похожим-на-числа atoi и складывает их в массив. Что тут кто куда атомарно писать будет?
Тред, идущий по замапленному давайте назовем основным. Он кладет обрабатываемый адрес в переменную. Треды мапинга и выборки в кэш этот адрес читают и работают с адресами несколько больше указанного.
Это всё на этом моём тяжёлом и горячем, но горячо любимом x86.
А у нас прибор в рубке стоит. И при шторме — на него может пара кубометров воды вылиться. Или полкуба льда из снежно-ледового заряда. Так что герметичен — до упора. В итоге используются только холодные процессоры, то бишь прежде всего ARM. В outdoor-исполнении иногда всякие наследники 80186 используют. Из более современного — только Intel Atom или Geode. Так что горячие процессоры — это не к нам.
Вы определитесь, вы про написание кода в точке вызова или про то, что там компилятор сгенерирует?
Про кодогенерацию, конечно.
Я предпочитаю писать человекопонятно, а потом прогнать профайлером
Как правило, читаемый код весьма эффективен. Лишнее наворачивание уровней абстракции как раз ухудшает читаемость.
Но зачем?
Затем, что я руками могу написать алгоритм, который эффективней в разы, иногда в 1000 раз. А надежда на оптимизатор дает лишь проценты. Да и не на всех платформах есть хорошая оптимизация. Как думаете, кто-нибудь сделал оптимизацию на NeuroMatrix? :-)
Как основной тред узнает, что дальше лежит мусор, потому что тред маппинга не успел?
А зачем? Не успел — значит будет загрузка страницы при первом обращении к ней. Это быстрее, чем ожидать треда маппинга, который делает то же самое.
Э, ну я вроде как в ваши рубки-штормы свои методы чтения гигабайтов с диска запихивать и не предлагаю.
Не, вы только свои методы разработки нам навязываете. Увы, вы не понимаете, что цифровой мир и мир реального железа — это разные миры. В том же мире бизнес-логики — повторно используемый код намного более полезен, чем в мире embded и АСУТП. И шансы на повторное использование там сильно выше. И цена универсальности ниже.
В моей практике это правило по какой-то причине не выполняется. Видимо, действительно сильно разными вещами занимаемся.
Возьмите человека из своей области, зарабатывающего больше вас в несколько раз. И сравните читаемость кода. Чем более код читаем — тем выше уровень программиста и выше оплата.
Оптимальное представление этого алгоритма в виде исходного кода — совсем другое.
Зависит от критериев оптимальности. Если для важно повторное использование — это один код, если учет всех мыслимых и немыслимых особенностей реального мира — другой код, если вам нужно написать и забыть — третий код, если понимаете, что код будет многократно модифицироваться — четвертый код.
Это только школьники думают, что есть плохой код и хороший. А инженеру понятно, что у каждой задачи — свои критерии. И есть код адекватный критериям, а есть — неадекватный.
Типичное требование: работать при отказе любого датчика, выявлять неисправность при отказе двух любых датчиков, постараться выявить неисправность при отказе трех любых датчиков. И сразу шансы на повторное использование становятся равны шансам, что встретиться именно эта комбинация датчиков. :-)
Во-первых, как это вы из режима пользователя будете управлять такими атрибутами страницы?
В чем проблема? Как загрузить страницу в память? В linux — mlock, в Windows — VirtualLock, Когда не нужна — разрешить выгрузку из памяти.
Во-вторых, ещё немного, и вы переизобретёте readahead, который уже есть в линуксе.
Ну вообще-то не везде есть linux, :-) На машинку с 300 к памяти его не запихнешь. :-) Да и не только linux есть на свете, бывает ещё freeBSD, QNX, даже MS-DOS…
А лучше работает универсальный readahead из ядра, чем решение ровно под вашу задачу — это вопрос открытый. Скорее всего кастомное решение будет лучше процентов на 15. Обычно цена за универсальность — примерно такого порядка.
Но бывает и наоборот, см. известную историю с OS/360 и VM/370. VM/370 управляла подкачкой настолько хорошо, что OS/360 лучше работала под ней, чем на голом железе.
Вы не поверите, но там те же абстракции, темплейты и прочее счастье.
Угу, а ещё и ровно те же буквы и цифры. :-) Те же, но не такие же. Код намного читабельней. Сравните код eigen c кодом из STL — увидите разницу в классе. Код eigen — адекватен задаче. Код STL — нет. Или задача у его авторов совсем иная была или писать хорошо они не могут.
Мы обсуждали эффективность реализации с точки зрения производительности, разве нет?
Нет. У нас RealTime. Производительность бывает трех видов: недостаточная, достаточная и избыточная. В идеале — избыточная. От ускорения на 20 (или даже 50) процентов ситуация не меняется.
Ну какая разница процессор занят 6 или 4 процента времени? Все равно на пике хватит. А если процессор занят 90% времени, то нам не поможет ускорение на 50%, все равно процессор будет занят 60% времени и на пике этого не хватит.
Так что интересует только алгоритмическое ускорение, то есть в разы и десятки раз. Не можем ускорить — алгоритмически размазываем затраты, чтобы в пике обеспечить свободную мощность.
А от кодирования нам важнее не скорость, а совсем иные характеристики. Например — поведение при отказах, читаемость, адаптируемость.
Как обеспечить контролируемый page fault, пока читающий тред не подгрузит её в память.
Ровно так же, как и раньше — это дело ОС.
Ну я уже говорил, что вы readahead изобретаете.
Скорее всего, это никогда не нужно портировать на QNX.
я рад, что у вас наконец-то проснулось инженерное мышление. :-) Да, свой собственный readahead хорош тем, что мы можем портировать его куда угодно. И у нас есть шансы портироваться на всякие странные архитектуры. И заточка на конкретный linux для нас хуже, чем универсальное решение. А ваш код — действительно никуда переноситься не будет и универсальность вам не нужна.
Если, условно, вам нужно просмотреть почти каждый байт, файл имеет размер 4 гигабайта, а скорость до диска — 100 мегабайт в секунду
Мама!!! Вы уверены, что скорость "до диска" это и есть скорость диска? Мда… инженерная культура у вас....:-(
А насчёт «падающего ворда» — покажите альтернативу со сравнивыми возможностями и не падающую — будет о чём говорить. То что вложения в надёжность не окупаются в случае в Word'ом не значит, что Microsoft не умеет надёжный код писать. В конце-концов сама Windows уже давно не падает если железо не глючит, а она, как бы, не сильно проще Word'а.
Открыть выпуск.
разные операции
Открыть впуск.
перекачка и все прочеее
подготовительные операции к закрытию выпуска
Закрыть выпуск.
ещё всякие операции
подготовительные операции к закрытию впуска
Закрыть впуск.
я не про то, что единая технологическая операция расползается по трем местам кода. Это неудобно, провоцирует ошибки, но это плата за RAll.
И не о том, что придется создавать объекты, у которых смысл только в конструкторе и деструкторе, а никакой физической сущности нету. Это тоже плата за RAll,
И не о том, что на один и тот же выпуск придется пяток разных объектов, Это тоже плата за RAll
Но вы на область действия посмотрите! Видно же, что в реальном мире «неправильные пчелы и они делают неправильный мед». (с) я понимаю, вы захотите сменить технолога, потом завод, потому страну, потом будете искать другой глобус, но не откажитесь от RAll,. Мне проще — я просто выбираю язык под задачу.
Давайте уж оставим RAll для того, для чего его придумали — для управления ресурсами в дисциплине LIFO. А в реальной мире — не ресурсы и скорее FFO.
Кстати, с моей зрения автоматический вызов деструкторов локальных переменных — это костыль. Или уж не вызвать ничего автоматически (это надежнее) или уж автоматически вызывать деструкторы и для объектов в куче (как в COM). Потому что такое половинчатое решение вызвала другие костыли, например "владеющие указатели"… И так один костыль наворачивается на другой и всё это вместе называется современным С++.
Только давайте не будем спорить о языках программирования. Мне не интересны такие холивары…
Обещаю завтра ещё раз прочитать, вдруг смысл написаного дойдёт.
Try
Try
Try
Try
Открыть выпуск.
разные операции
Открыть впуск.
перекачка и все прочеее
Except
Eabort : Raise;
Else Выдача собщений; Raise EAbort
End
Finally
подготовительные операции к закрытию выпуска
Закрыть выпуск.
End
ещё всякие операции
Except
Eabort : Raise;
Else Выдача собщений; Raise EAbort
End
Finally
подготовительные операции к закрытию впуска
Закрыть впуск.
End
Ну так что, напишите с использованием RAll или будете критиковать предметную область?
Для начала, приведите пример как вы собрались это все делать через try/finally.
я бы сказал, что не окупается использование MFC вместо VCL. Ну и сама парадигма «по одной ошибке считаем, что сломали вообще все» тоже не окупается. А вот парадигма «Баг в функциональности — это только баг в функциональности» вполне окупается.
Любое приложение, написанное на основе VCL падать не будет из-за дизайна VCL.
Так можно про 100500 вещей сказать. «Любое приложение, написаное на основе XXX падать не будет из-за дизайна XXX», я с ходу 5 страшных и не очень слов уже придумал, что можно вместо XXX подставить.
шибка в реакции на любое действие пользователя изолируется. То есть у вас может быть access violation при использовании любого пункта меню или нажатию на кнопочку. Но к закрытию всего приложения и потере данных он не приведет.
И это плюс? Молча ловить и глотать системные SEH'и? И ваш любимый MFC и Qt правда тоже самое делают, правда и там и там это легко правится.
я бы сказал, что не окупается использование MFC вместо VCL.
Так, откуда тут MFC появисля? Был Qt. Что за фигня, верните Qt.
А если серьёзно, то на MFC тоже много коммерческого софта написано. И если бы не 2 его недостатка (коннектить сигналы можно только при компиляции, а не динамически, как в Qt) и на поддержка из коробки лейаутов и растяжения форм, то вообще нормальная библиотека была бы.
я с ходу 5 страшных и не очень слов уже придумал, что можно вместо XXX подставить.
Мало придумать. Вы докажите, что вы правы.
И это плюс? Молча ловить и глотать системные SEH'и?
Плюс. Потому что молча — это на вас опыт VC++ влияет. А на самом деле выдается сообщение, если надо — идет логгирование… Статистика примерно такая:
- 0.5% — ошибка фатальная, лавинный отказ, программа закрывается с потерей данных
- 2% — дятел (постоянная выдача собщений об ошибке). При быстрой работе мышкой обычно удается закрыть с сохранением данных.
- 97.5% — отказ одной функциональности
Что за фигня, верните Qt.
А не работал я с Qt. Потому и судить о нём не буду. По слухам — отладчик лучше VC++. Надо бы попробовать, но времени нету.
Плюс. Потому что молча — это на вас опыт VC++ влияет. А на самом деле выдается сообщение, если надо — идет логгирование…
Логирование тоже в VCL встроено? Не верю. А если писать логирование вручную — то какая разница какое там поведение при ошибках по умолчанию? Все равно же по-своему переделывать.
typedef void __fastcall (__closure *TExceptionEvent)(System::TObject* Sender, Sysutils::Exception* E);
ну или (для новых)
(Sender: TObject; E: Exception) ( TExceptionEvent)()
Более того, есть специальный объект для трансляции таких событий в объект формы.
То есть в разных окнах можно сделать разное логгирование.
__closure это киллер-фича, возможность переддать указатель не просто на функцию, а на метод конкретного объекта. Иными словами __closure это два указателя — и на объект и на его метод. Крайне удобно для событийной организации программ потому что позволяет делегировать обработку другому объекту.
Ну как пример foreach. Куча языков имеют его как языковую конструкцию. И С++ тянется к тому. Но вместо того, чтобы программно реализовать новое ключевое слово, используютяс костыли ввиде темплейтов и лямбд.
А на том же форте — ноль проблем. Нужен foreach — взяли и написали. Через несколько часов у вас в языке новый оператор foreach.
С++ давно идет к этому. Собственно начиная с возможности переопределения семантики оператора присваивания — это всё шаги именно в направлении написания собственных операторов. Даже больше. Движение в этом правлении началось ещё с дефайнов Си. Но пока что шаги костыльные.
Дефайны, темплейты, лямбды… это все слабая замена возможности написать свой собственный оператор. Причины понятны, из современных компиляторов только LLVM позволит пользовательскую кодогенерацию.
А прежде чем судить костыль или нет — напишите парочку своих операторов на любом языке, который это позволяет. И уж потом — судите.
Вообще-то уже шесть лет как дотянулся.
Тогда зачем вы дает пример лямбд с std::for_each? Мест, где они реально нужны, не нашлось?
Если немножко подумать, то станет очевидно, что на самом-то деле оператор не отличается от функции вообще ничем.
А если подумать множко, то отличий порядочно. И кодогенерация иная, и пространство имен иное, и проблемы с использованием переменных у оператора нет…
Знаете, почему лямбды — это не полноценные функции? В Алголе 60 попытались ввести вложенные функции. Но обнаружилось, что хорошего способа обращаться из вложенных функций к переменным внешней функции нет.
void external(void)
{
int ext1, exxt2;
voi intA(void) {,...ext2=ext1;...};
voi intB(void) {,...ext2=ext1;...intA();...};
intA();
intB();
}
Пока мы из вызываем IntB из external — все ещё хорошо. Но когда из IntB мы мы вызвали IntA — у неё огромная проблема, как найти в стеке адрес переменных ext2 и ext1. Поэтому лямды не могут вызвать друг друга или рекурсивно самих себя. Да и вообще, обращаются к переменным процедуры очень ограничено.
А вот в операторе этих проблем нету. Оператор не функция — из иного места не вызовется.
Впрочем, наверное, это все слишком сложно для вас. :-(
Надеюсь, предыдущего ответа достаточно, чтобы дать понять, есть у меня опыт для суждений или нет.
Да и так понятно, что опыта нет. Компилятор не писали, кодогенерацию не чувствуете… Напишите свой первый компилятор — совсем по-другому на язык взгляните.
а на FORTH взгляните. Там вообще вся кодогенерация в руках программиста. И даже компиляция — написана на том же форте. Занимает форт-система 14 килобайт (вместе с редактором и системой хранения на диске) и живет без ОС. Наверняка в детстве с форт-системами играли.

Пример показывает, как этим делом пользоваться, и как лямбды упрощают код по сравнению с в остальном таким же примером.
Так о том и речь, что мы не используем «в остальном такие же примеры». :-)
Замечания такие:
- Упрощение только синтаксическое, на уровне эффективности кода упрощения не вижу.
- Лямбды — это костыль по сравнению с нормальными вложенными функциями.
- Лямбды столь же неэфективны, как и обычные вложенные функции
Вот насчет последнего пункта — могу ошибаться. Если ошибаюсь — рассказывайте подробно о кодогенерации.
Можно я просто не буду читать дальше? Причём тут, #!@%^, алгол-60?
Алгол-60 — один из языков, для которого долго искали эффективную кодогенерацию для вложенных функций. Ну и пришли к выводу, что вложенные функции не могут эффективно обращаться к переменным объемлющей функции. То есть они заведомо неэффективны.
В C++ есть:
Милый человек, синтаксически оно и в алголе-60 есть. Причем нормально, без костылей типа [ext1, &exx2]. А что с кодогенерацией? Какой способ обращения будет эффективен, если мы можем вызвать вложенную функцию IntA не только напрямую из внешней, но и через IntB? А если мы вызываем через рекурсивную функцию?
Какая разница, что и где есть синтаксически? Вы мне про кодогенерацию расскажите.
В плюсах могут относительно спокойно (правда, придётся пожертвовать auto в силу особенностей семантики языка, но это не принципиальная проблема):
А с кодогенерацией-то что???? Размотка стека вызовов при каждом входе в лямбду? А если рекурсия там тысячу вызовов накрутила?
А вы что оператором называете?
Да я предпочитаю не спорить о терминах. Давайте возьмем определение из вики:.
Инстру́кция или опера́тор (англ. statement) — наименьшая автономная часть языка программирования; команда. Программа обычно представляет собой последовательность инструкций.
Что там с пространством имён? Что за проблемы с переменными? Что с кодогенерацией, в конце концов?
Честно говоря не очень понимаю на каком уровне вести ликбез. Если уровень слишком сложен — то скажите, объясню на школьном уровне. есть такая вещь — stack frame.
В этом самом фрейме хранятся локальные переменные процедуры. И все операторы спокойно обращаются за ними путем относительной адресации через регистр, указывающий на начало текущего фрейма. Это понятно или уже немного сложно?
Иными словами, с операторами все хорошо. К глобальным переменным по абсолютному адресу, к локальным — по относительному через регистр. Оба этих способа адресации современные машины умеют делать очень быстро.
А вот у функции — все иначе. Чтобы обратить к переменным вызывающей процедуры, ей нужно как-то получить адрес нужного фрейма. И тут есть выбор между плохими и очень плохими решениями. А вот хороших за 50 лет как-то не нашлось. Плохое решение — это механизм параметров. Он медленный и относительно неэффективный. Очень плохое решение -это размотка стека с поиском нужного фрейма. Если ней да бог процедура вызвала себя рекурсивно тысячу раз, то размотка стека начинает отнимать существенное время.
Понятно, что для инлайновых функций таких проблем нету, но инлайновые функции — это собственно такой макрос. Чисто синтаксическое украшательство. Удобное, не спорю. Но каждый вызов — это генерация нового кода. На практике чисто синтаксическое повторное использование порождает гигабайтных монстров.
Проблема с пространством имен — это уровень школы. Если мы в операторе образаемяс к переменной ABC, то мы имеем ввиду переменную ABC той функции, в которой находится этот оператор. Если там нету такой переменной — то глобальную переменную с тем же именем. Вложенностей всего две и это не страшно.
стами немножко более вдумчиво, чем в Dragon Book
А вот что делать, если у нас в функции есть переменная АBC, но мы хотим обратиться к переменной ABC объемлющей функции? Вот тут и возникает проблема пространства имен. Особенно багоопасно она проявляется при использовании макросов. Способ решения известен — полный запрет на обращение к переменным объемлющей процедуры. Потому что формальные параметры сидят в пространстве имен текущей процедуры. Но да, через них мы имеем медленный способ обращения к переменным объемлющей процедуры.
Я не слишком сложно объясняю?
Вот в том и забава, что писал.
Кодогенерацию? И при этом не имеете понятия о лямбдах в алголе-60??? Это же в базовый курс компиляторов всегда входило. Похоже, что вы только синтаксисом занимались. Ну или оптимизацией. А кодогенерацию просто не изучали.
Местами немножко более вдумчиво, чем в Dragon Book
Забавно. Ахо и Ульмана читали, а Пратта? Насколько я помню (все-таки 30 лет прошло), Ахо и Ульман кодогенерацию практически не описывают. Зато многое есть у Пратта.

Ну вот тут вроде можно почитать. Ещё по кологенерации есть очень редкая книга "Как Паскаль и Оберон попадают на «Самсон»", но её в сети я не нашел. Но если очень надо могу отсканить. Или у создателей этого самого самсона текст выпросить.
Все дело в том, что синтаксические красоты, это удобно, но кодогенерация важнее.
И то, и другое компилятор в подавляющем большинстве случаев заинлайнить и сгенерит одинаковый, почти максимально эффективный код.
Так вас интересует повторное использование бинарного кода или повторное использование исходного текста?
Вложенных функций в C++ нет, поэтому сравнивать особо не с чем.
Они есть в других языках. Глупо ограничивать свой мир только С++. Вы ведь тоже не только его знаете? Просто у нас с вами разное множество изученных языков.
Можете думать о лямбде в C++ как об экземпляре анонимной структуры,
Угу, почитал. Это даже не костыль вложенной процедуры, это костыль класса особого типа. Но с некими дополнительными преимуществами, типа выдачи его результатом функции. Чтобы было понятней, слово костыль замените на подвид. У лямбды нету полной мощности класса или вложенной процедуры. Но вообще вполне адекватная замена для stl-like стиля. Вся беда в том, что мы не идем путем one microsoft way и не пишем в этом стиле. Потому нам лямбды и не интересны.
Вас вообще не смущает, что семантика call-by-name ломает вообще всё?
ДА? Ну покажите, что она ломает. Если ей неаккуратно пользоваться — можно много дров наломать. Но сама по себе она ничего не ломает. Просто универсальный, а не костыльный вариант лямбд. Точнее — и лямбд и передачи по ссылке.
Сохранил указатель, если переменная захватилась по ссылке, или скопировал значение, если, как ни странно, по значению, и всё.
Когда сохранил? Установили значения, потом сохранили лямбду (с передачей по значению) в переменную, потом изменили значение. Потом вызвали метод, изменяющий значения и после этого вызывающий лямбду. Какое из трех значений будет использовано? У нормальной вложенной функции — последнее. А у лямбды? Первое? Видите неполную мощность?
Зачем вам какие-то раскрутки фреймов и прочая наркомания, возможно, имевшая смысл 50 лет назад, но не имеющая смысла сейчас, совсем, никакого?
Очевидно же, для позднего связывания. Ну как минимум в лямбдах не хватает чего-то вроде const & — позднего связывания по значению.
Это определение можно трактовать как в вашу, так и в мою пользу.
Вы хотите сказать, что отличия оператора от инлайн-процедуры только синтаксические? В этом вы правы. Но:
- у оператора может быть иной, уникальный синтаксис.
- оператор базируется на ключевых словах
- компилятор по ключевым словам может проверить синтаксис
- если ваша процедура не занилайнится — семантика несколько поменятся
- оператор может иметь возможности, неостидивмое имеными средствами языка, например poke в BASIC
Попробуйте добавить в C++ elif увидите, что нынешние методы С++ просто костыльны. Для удобного определения операторов недостаточно contstexpr, нужна ещё и возможность добавлять свои коды прямо в P-Code.
Правы вы только в том. что есть языки с унифицированным синтаксисом, где все является процедурой. Но С++ к таким не относится.
Ваш напыщенный тон начинает немножко надоедать, упырьте мел, пожалуйста.
Меньше тролльте и все будет проще.
Вообще-то это называется скоупом, по-русски областью видимости, а не пространством имён.
Не путайте. Область видимости- это свойство идентификатора. А пространство имен — это совокупность всех видимых идентификаторов. Но действительно, смысл этого термина за последние 40 лет поменялся. Так что частично вы правы.
Так вот, с учётом вышенаписанного, проблем со скоупингом нет.
Да, согласен, они заменены на проблемы с ранним связыванием пр и передаче по значению.
Инлайновые функции (только если вы не используете опять какие-то левые термины, конечно), имеют абсолютно ту же семантику в плане областей видимости,
Они должны иметь одинаковую семантику с точки зрения программиста на ЯВУ. А точки зрения кодогенерации — семантика разная.
У меня был очень унылый базовый курс компиляторов.
Дело не в этом. У нас с вами — очень разная область интересов. Вот только в вашей области — я не рискую что-то утверждать. А вы лезете в АСУТП со своими школьными представлениями. Может достаточно просто понять, что «в Греции все иначе»?
Но если вы говорите о том, что эта фича менее эффективна, чем другая фича, то подразумевается, что вы сравниваете их хотя бы в рамках одного языка,
Почему? я сравниваю прежде всего, чтобы понимать какой язык адекватен какой задаче.
У слова «костыль» есть вполне определённые негативные коннотации. Непонятно, почему вы их вкладываете.
Потому что знаю более адекватные задаче средства из других языков.
У вас в сишечке самое что ни на есть call by name в макросах. Чем макрос min опасен, если выражение, переданное одним из аргументов, имеет сайд-эффекты?
А в С++ и так много способов выстрелить себе в ногу. Вы этот аргумент уже приводили. Что будет, если у вас побочный эффект в лямбде?
Если по ссылке — последнее.
а если по значению, то первое.
#include <iostream>
int main ()
{
int a = 17;
auto print = [=] { std::cout << a << std::endl; };
a = 20;
print ();
}
Более того, constexpr вообще не нужно для операторов. constexpr и операторы — разные вещи.
Ну жалко, что вы не понимаете идеи. If, for, do, while и даже {} на форте — это функции времени компиляции (то есть constexpr), написанные на самом форте. Ядро форта умеет только условный и безусловный goto, а все управляющие структуры — написаны на самом форте. Для этого нужно всего ничего — умение кодогенерировать goto (и метки) и занимать память в стеке и статике.
Не нужна семантика передачи по значению — не используйте передачу по значению. Я не понимаю вашей проблемы.
Аналогично — не нужен мне RAll, мне нужен try… finally. но меня вы почему-то заставляете использовать ненужный мне RAll.
Семантика разная с точки зрения того
мы уже обсуждали два смысла слова семантика. Меня интересует прежде всего кодогенерация. А вас -некий абстрактный смысл.
озвученные вами причины отказа от определённых фич языка не имеют смысла.
Имеют-имеют. Но вы простейших аналогий не видите. Ещё раз. Достоинство лямды — это написание кода в той точке, где он будет выполняться, а не где-то наверху. Но для try..finally вы этого достоинства не видите в упор. Лямбда — это отказ от повторного использования, но для неё вы считаете это нормальным, а для try..finally — наоборот.
Что для меня бы являлось килл-фичами?
- try..finally
- Поддержка структурных исключений
- Битовые маски как тип языка
- Break из любого блока
Ну в общем хочется delphi с переносимостью Си.
P.S. Может быть потихоньку сведем дискуссию к нулю?
Лямбда — это отказ от повторного использования
Не хочется влазить в дискуссию и вырывать из контекста, но всё-таки почему?
auto lambda = []() { ... };
lambda();
lambda();
lambda();Зато с лямбдами — наоборот. Вы видите их полезность в написании «по месту», а отсутствие повторного использования вас не беспокоит.
Какую бы аналогию вам привести? В зеркало посмотрите. Иногда бывают одинаковые лица — это близнецы. Повторяются отдельные части, например зрачки, рот… А вот комбинация зрачки + брови — не повторяется. Не относится она к повторно используемым.

Только вы что, будете пить из бублика и закусывать чашкой?
Более того, ваша программа на с++ эквивалентна бинарному коду. Так может прямо в бинарном коде писать, раз оно эквивалентно?
Вы уже написали замечательный тезис
Если вам что-то надо помнить про детали реализации абстракций, то вы неправильно выбрали абстракции. Абстракции для того и нужны, чтобы спрятать несущественное на этом уровне оперирования логикой.
И именно с этой точки зрения для нас повторно используемый Rall намного хуже try..fnally, а повторно используемые классы лучше лямбд,
Просто вы привыкли к своей области, где все наоборот. И не желаете признавать, что ваша область — не единственная и даже не самая важная. От сбоя в ваших бизнес-процессах — не погибнут тысячи людей. Максимум — застрелиться менеджер.
Откуда у вас это желание заставить всех идти заведомо непригодными путями? Ну не понимаете вы отличия между ресурсами и технологически операциями. Это ваша проблема, что вы не понимаете чужой области. Даже не моя — я отличия объяснял много раз.
В пятый раз попробовать объяснить? Когда у вас (и у нас) есть чисто программные ресурсы, не имеющие основы в реальном мире, то у вас будет много захватов и освобождений таких ресурсов. Да, действительно, такое короче писать через RAll.
А когда у вас есть вещи из реального мира (задвижки, клапана, концевики, моторы) то у вас в коде будет один «захват» и одно «освобождение». По двум причинам:
- с каждой задвижкой (мотором, концевиком) обычно делается одна технологическая операция. Очень редко — две, прямая и реверс.
- технологический код специально пишется так, чтобы все, относящееся к формированию одного выхода было бы в одной процедуре.
Второй момент — действительно странен для настоящих программистов. Но в мире АСУТП — удобней именно так. Тогда при проблемах с конкретным выходом мы анализируем всего один кусок кода. Это ближе к функциональному программированию, конечно.

То, что записано как выходы (Set, Reset. StartDevice) более нигде в коде использовать не будет. Так что при проблемах с ними — читаем лишь один кусок.
Но я уже понял, что вам легче пить из бублика и закусывать чашкой, чем понять, что в иных областях совсем иные критерии.
Мне, в принципе, не очень сложно ещё поотвечать.
я отвечу, но пока что есть много более важных вещей. Увы, дискуссия стала съедать слишком много времени. Да и частично мы идем по кругу.
Потому что у другого языка могут быть отличия в семантике других влияющих вещей
Это не так важно. Именно сравнение языков между собой дает понимание, какие фичи адекватны задаче, а какие — нет.
Опять вложенные функции? Я так и не увидел ответа на вопрос, почему они более адекватные.
Адекватность берется не в вакууме, а в рамках конкретной задачи. У лямбд копирование значений параметров в точке написания лямбды, а не в точке использования. Кода эти две точки совпадают — это не важно. Когда отличаются — это контринтуитивно, то есть костыльно. Ещё одна костыльность в том, что лямбду нельзя использовать как функцию обратного вызова в асинхронном API. Ну просто потому, что она метод, а не функция.
я вполне поверю, что в ваших задачах все наоборот, но у нас так.
Неа. Я говорю, что они изоморфны.
Чашка изоморфна бублику. Будете пить из бублика и закусывать чашкой?
И мы сравнивали производительность, разве нет?
В АСУТП производительность процессора бывает достаточная (процессор не греется), нормальная (процессор греется) и недостаточная (не успевает). Связано это с тем, что цена компа мала по сравнению с оплатой труда программиста.
А вот производительность программиста — почти всегда недостаточная. :-)
Так что в исполняющемся много раз коротком цикле малопроизводительные конструкции применять не стоит, но сама по себе разница по скорости в 2-3 раза не так важна. Не так уж и важно, загружен проц на 1% или на 2% — все равно проц в комфортном режиме работает и с повышенной наработкой на отказ.
Щито? В любом асинхронном API нельзя? Ну вы совесть-то бы имели всё-таки, что ли.
А что, разве лямбду можно вызвать как функцию???
typedef int func_t(void);
int api_func(int param, func_t *func);
У вас получится передать лямбду как func_t?
А API у нас в 99.99% Сишные. Разумеется, ничто не мешает написать свою С++ обертку над API. Но, как правило, API не ограничивают язык написания и потому Сишные.
Ну так и лямбду туда можно передать, если её capture list пустой.
Пример, плиз. Компилируемый и исполняемый. Лямбда по сути метод, а не функция. То есть имеет свой this и требует его передачи при вызове.
И да, вложенные функции в C++ в этом случае, по-вашему, можно использовать, несмотря на то, что их там нет?
В тех языках, где вложенные функции есть — это один из основных сценариев их применения. То есть функции обратного вызова нужен доступ ко
Пример, плиз. Компилируемый и исполняемый. Лямбда по сути метод, а не функция. То есть имеет свой this и требует его передачи при вызове.
То есть, вам даже лень проверить?
typedef int func_t(void);
int api_func(int param, func_t *func) {}
int main() {
auto lambda = [](){ return 42; };
api_func(0, lambda);
}О том, чтобы всё-таки почитать о лямбдах и узнать, что с пустым списком захвата они приводятся к функциям уже и не говорю. Собственно, это вполне логично: если нет необходимости где-то хранить захваченное, то что мешает компилятору сгенерировать функцию, а не метод?
Собственно, это вполне логично: если нет необходимости где-то хранить захваченное, то что мешает компилятору сгенерировать функцию, а не метод
И как оно тогда передастся в какой-нибудь for_each? Надеюсь вам понятна проблема?
То есть, вам даже лень проверить?
Времени у меня мало на проверку любого бреда… Тем более, что с пустым списком захвата
Проверил. Но как оно перелается в for_each — в упор не понимаю. Разве что стоит рассматривать for_each как макрос.
% grep -R "\[\]" * | grep -v tests | wc -l
605
Ага. 605 раз не повторно используемый код. Это для вас нормально. А когда у нас 15-20 раз в finally код повторно не используется — вы требуете переломать всю структуру программу ради этого вашего повторного использования.
Вам это кажется логичным? Ну тогда у вас проблемы с логикой. :-(
Изначально дискуссия началась с эффективности. Ну, интересные истории про раскрутки фреймов, call-by-name в Алголе-60 и всякое такое. Припоминаете? Не так давно ж вроде было.
Ага, то есть кодогенерацию вы не понимаете. Вложенные процедуры в алголе-60 — это потери в разы, а не проценты. В
Вы, надеюсь, сталепрокатными вещами ограничиваетесь, и если что-то этакое случится, то попадёте только на деньги, а не на людские жизни?
Прежде всего попадаем под уголовный кодекс. А в тяжелых случаях — человеческие жизни.
И ровно поэтому нам не нравиться Hype Driven Development за который вы ратуете.
Подумайте сами, почему 605 раз повторно неиспользуемый код в лямбдах — вы считаете правильным, а когда у нас 10-15 раз в finaly код повторно не используется — это вам кажется ужасным. Ответ простой — это дань моде.
А у нас слишком ответственные вещи, чтобы тупо следовать за модой (не тупо — иногда можно).
Вы ведь понимаете, что без обёрток в сишное API вы такие вещи передать точно не сможете? Требование запомнить this, указатель на стекфрейм или что-то подобное никуда не девается.
я как раз понимаю, что могу. Ценой потери эффективности, но могу. Как вариант — маркеры в кадрах стека. И раскрутка до маркера. Ещё вариант — второй стек (как в FORTH), Ещё есть вариант с автогенерацией враппера в стеке (для фон-неймановская архитектуры). Ещё есть вариант с модификацией кода (тоже только фон-неймановская архитектура), но он вам точно не понравиться, ибо нереентерабелен Ну в общем вариантов много, но
Просто вы кодогенерацию не видите, вот вам и кажется, что такого не бывает… А ведь все делали лет 50 назад…
Особенно если API действительно асинхронное, и ваш стекфрейм может уже давно умереть к моменту вызова.
А вот это, как вы уже сами писали, «лишь очередной способ выстрелить себе в ногу». :-) Достаточно перед завершением функции ожидать её окончания.
Не требует, если захватывать нечего.
Ох как мне это не нравиться — полуфункция-полукласс…
Подводя итоги. Честное слово, дискуссия отнимает много времени. Пока ни одной киллер-фичи новых версий С++ вы не показали. Есть полезные вещи вроде constexpr, но ничего такого, из-за чего стоило бы отказать от потенциальной возможности поддержки старых платформ.
nikolaynnov: — Какую связь лямбры имеют с stl-контейнерами?
Jef239: — А где они ещё нужны? Типовой пример из вики
std::vector<int> someList;
int total = 0;
std::for_each(someList.begin(), someList.end(), [&total](int x) {
total += x;
});
std::cout << total;
…
…
Jef239: — Ну как пример foreach. Куча языков имеют его как языковую конструкцию. И С++ тянется к тому. Но вместо того, чтобы программно реализовать новое ключевое слово, используютяс костыли ввиде темплейтов и лямбд.
0xd34df00d: — Вообще-то уже шесть лет как дотянулся. Вы вообще знаете предмет вашей критики или по-прежнему в 98-м году?
Jef239: — Тогда зачем вы дает пример лямбд с std::for_each? Мест, где они реально нужны, не нашлось?
Ну за тем исключением, что «в остальном таких же примеров» у нас нет. Ибо мы пишем на Си. Да, с отдельными, полезными нам элементами С++. Но на Си.
Вам опыт общения с продуктами микрософт мешает. :-) Разумеется, в VCL встроено много событий, позволяющих переопределить поведение без переделки библиотеки. Соответствующее событие зовется OnException и имеет тип (для старых версий С++)
Вы опять бред пишите. Надеюсь, что от незнания, а не из-за умысла наговора. Если говорить именно про Майкрософт, а не про Qt, то гляньте, например CWnd::ProcessWndProcException. Тоже, хочешь логгируй, хочешь дамп пиши, хочешь игнорь. Не надо присваивать ни майкрософт, ни другим людям лишнего.
какая разница какое там поведение при ошибках по умолчанию? Все равно же по-своему переделывать.
А в delphi — событийная модель. Поэтому переписывать методы в наследнике не нужно. Но да, работая только с продуктами микрософт, о ней узнать сложно.
И причём тут ваш бред, по то что пришло или не пришло бы мне в голову? Я доказал, что вы писали бред. Не надо уводить разговор в сторону.
События в windows — это совсем не программирование, основанное на обработчиках событий. Отличие тонкое. В первом случае без обработки событий мы не получаем ничего. Во втором случае обработчик событий не является обязательным, но может модифицировать или расширять поведение основного кода. В windows есть похожие места, например драйверы-фильты.
Мало придумать. Вы докажите, что вы правы.
Не, это вы докажите, что я не прав, раз вы это утверждаете.
Сообщение, логгирование и т.д. — это не молча. Молча, если внутри библиотеки где-то catch(...) стоит. И я так и не понял как VCL определяет к какой категории относится перехваченный SEH, к первой, что надо закрыть программу с потерей данных, или к 97%, когда надо продолжить работать. Я вот понимаю, как я это вручную в MFC/Qt определяю, но как это автоматически может делаться?
Что за фигня, верните Qt.
А не работал я с Qt. Потому и судить о нём не буду. По слухам — отладчик лучше VC++. Надо бы попробовать, но времени нету.
Я раз, что хоть здесь вы про Qt воздерживаетесь. А моя фраза относилось к тому, что вы опять магическим образом с чего-то перебрались на MFC. Хотя до этого в этой теме мы про Qt только разговаривали.
Сообщение, логгирование и т.д. — это не молча.
Ну так и не выдумывайте зря. Ещё раз прочтите что я написал. А то что вы выдумали «молча» — это всего лишь следствие вашего печального опыта с VC++.
И я так и не понял как VCL определяет к какой категории относится перехваченный SEH, к первой, что надо закрыть программу с потерей данных, или к 97%, когда надо продолжить работать.
Есть дерево вызовов. На нем стоит граница изоляции в виде try-блока. Если исключение произошло в пользовательском коде (после границы изоляции) — оно изолируется и работа продолжается. А если исключение уже в системном код (до границы изоляции, то есть ближе к main) выходим.
Да, бывают ситуации, когда разрушили стек. Или потерли системные структуры. И тогда уже исключение идет в системной части VCL и программа выходит.
Хотите посмотреть насколько это надежно? Skype (до покупки микрософтом), Altium Designer, QIP, Total Commander, Light Alloy, The Bat!, Macromedia HomeSite… Видели, чтобы они упали с потерей данных?
Ну а с другой сторонs — падающие Word и OpenOfice.
Хотя до этого в этой теме мы про Qt только разговаривали.
У вас глюки. Если кто-то и говорил по Qt — то только вы сами с собой.
… QIP, ..., The Bat!,… Видели, чтобы они упали с потерей данных?
Да, неоднократно, и что? Софта без багов не бывает.
Да, упали. Обычно аварийное завершение программы с повреждением данных называется именно так. Повреждение почтовой базы при использовании pop3 — крайне неприятное дело, скажу я вам.
Прекратите же уже бред нести :-(
И да, The Bat!, например, падает с потерей данных (а иногда и с потерей всей БД) в бесконечное число раз больше, чем Word.
У меня глюков нет, до того как вы на MFC с чего-то скакнули, в соседней ветке мы уже про Qt говорили.
Пример. Есть координаты с неким шумом, нужно определить начало движения. ну теоретически считаем СКО, выход за 3 СКО — значит движение. Практически — может быть что угодно. Бросок на 5 СКО, например. Или движение с первой секунды и посчитать СКО невозможно.
Ну в общем С++ — это не к нам. К настоящим программистам с их гигабайтами памяти, процессорами со 128ью ядрами и так далее… Да, настоящие программисты не программируют на Паскале. Но мы-то — ненастоящие. На и паскаль (то есть Delphi) сгодится.
Ну в общем очень на вас похоже. И ваш совет любые операции, включающие в себя закрытие задвижек, делать повторно-используемым кодом.
На уровне детского сада задвижка — это обычный кран. Тот самый, который есть у вас в ванной и на кухне в паре экземпляров.
Как у любого крана — у задвижки много состояний, от полностью закрытого до полностью открытого. Если интересно — могу прочитать лекцию про 11 зон, которые есть смысл выделять при программной реализации управления задвижками. Самая простая модель задвижки — это вещественное число, изменяющееся от 0 до 1. При этом скорость изменения не может превышать некоторой константы, то бишь скорости привода с редуктором.
Теперь рассмотрим RAll. Ресурс не может быть захвачен на 11% или на 37%, он атомарен. Вы или захватили его или нет. А вот задвижка запросто может быть открыта и на 11% и на 37% и на 83%. Более того, в силу гистерезиса концевиков мы никогда не можем быть уверены 0% у нас или 1%. Меньше 3% — закрыто, больше 97% — отрыто полностью. Ну да ладно, а то я на пару часов могу про задвижки лекцию зарядить. Но одно надо запомнить — открытие задвижки это медленный (до нескольких минут) многостадийный процесс.
Теперь вернемся к Rall. Что будет при исключении в конструкторе? Деструктор не вызовется, но это и не страшно. Ресурс атомарен, конструктор не дошел до конца — значит ресурс не захвачен.
А что с задвижками? А если вы хоть немного открыли задвижку, то её нудно закрыть по полной схеме. С вывешиванием транспоранта, с проверкой условий, см предварительными действиями…
Резюме такое:
- Модель: ресурс — bool, задвижка — float.
- Время переключения: ресурс — атомарно, задвижка — до минуты.
- Закрытии (деструктор) при исключении по время открытия : ресурс — не нужен, задвижка — необходим.
И неумение видеть управление ресурсом за управлением задвижками — это грустновато.
я рад, что вас научили видеть парадигмы. Беда в том, что вас не научили видеть границы их применимости. А детсадовское знание (наверняка с 3х лет сами краны открывали) вы применять не хотите или не можете.
Умение выделять повторно используемые части алгоритмов — одна из важных составляющих квалификации опытного программиста.
Это важное умение для школьника. И не более того. А для инженера намного важнее умение оценивать более сложные критерии:
- Стоимость. Сколько времени вы потратили на то, чтобы сделать повторно используемые части и какая их часть реально повторно используется.
- Предвидение. Умение оценить, что пригодится в проектах в ближайшие пару лет.
- Эффективность. Вылить воду из чайника, выключить газ и тем самым свести задачу к предыдущей — это повторное использование. Но оно не эффективно.
- Адекватность задаче. Большая опасность повторного использования — это слишком сильно натянутая аналогия. См выше про задвижку.
- Модифицируемость. При модификации повторно используемого алгоритма нужно контролировать, что новая версия будет работоспобна и адекватна задаче во всех проектах, где мы её используем. Довольно часто бывает, что код в двух места пока ещё очень похож. Но уже понятно, что через год одно из мест изменится до неузнаваемости. То есть их похожесть — только совпадение. Голова — она такая же круглая и волосатая, как и ягодица. Но это все-таки разные вещи.
Так вот, коды технологических операций не могут быть повторно использованы по критериям модифицирумости и эффективности. А многие чисто компьютерные вещи, у нас сведены в библиотеку. Ну и они повторно используются в от 2 до 10 проектах.
Ну что же, вы меня ещё более убедили в том, что человек, которому нравится современный С++, не может быть инженером. И да, вы очень похожи на того программиста, с которым мы расстались. Скажите, вы случайно не в Габрово родились?
Значит, и захват ресурса у вас медленный.
Медленный захват ресурса? Это что-то вроде «капельку беременна» и «осетрина седьмой свежести»? Захват ресурса всегда атомарный, иначе никакого смысла в нем нет. Весь смысл схемы RAll — в параллельном исполнении. для исключения deadlock и нужно работать с ресурсами по LIFO (первым захватили — последним отдаем).
И состояние «задвижка открыта» у вас всё равно есть, иначе быть не может, вы же должны в программе в итоге когда-то куда-то продвинуться, не? Будет просто не if (position == 100), а if (position >= 97)
Вы каждый день кран на кузне на
Вообще у задвижки примерно 11
Так что вместо «открыто» можно использовать «Не закрыто». Но тут есть тонкость, называемая гистерезис. Закрыто — 0%, заход на конечник — 2%, сход с конечника — 5%, получение сигнала «перегрузка» с мотора минус 2%. То есть при закрытии, получив сигнал с конечника, мы должны ещё немного дотянуть. К этому добавляются всякие гадости с трением покоя, с застывшей смазкой и так далее.
И опять вспоминаем кухню. Есть такие краны, что если они капают — их бесполезно закрывать. Их надо чуть открыть, а уже потом закрыть. Так что с закрытие
Поэтому теперь любого повторного использования надо бояться как огня, окей.
Скажите, а вы в любви тоже повторно используемым кодом текстом признаетесь? А дома у вас только
Повторное использование хорошо для простых задач. Там бывают десятки и сотни обращений, и такой повторно используемый код складывается в библиотечный слой. А на высшем (технологическом) слое повторное использование — бред.
Иногда повторное использование прямо запрещается заказчиком. Ситуация. Есть сложная технологическая линия. При поломке — оперативно (в течение 2-5 минут) правится код в контроллере и измененная программа работает дальше. До ближайшего ППР (планов-предупредительного ремонта), когда оборудование починят, а программу — вернут в прежний вид. Да, конечно, контролеры обычно пишутся на языках IEC_611313. Но язык ST — не так уж далек от Си и паскаля. Да, конечно, часто удается обойтись установкой блокировки, то есть принудительным переводом входа в 0 или 1 независимо от реального сигнала датчика. И тем не менее, пару раз в неделю приходится править код.
А вот теперь подумайте головой. За 180 минут простоя в месяц снимают премию со всей службы. Не только с вас, любимого, но и с коллег. А премия — равна окладу. И сколько лишних минут у вас уйдет на то, чтобы найти все места повторного использования и понять, не сломает ли там чего ваша правка?
Так что если вы предполагаете, что кусок кода
Есть такая вещь, как контракты. Мне очень лень расписывать это подробно, но, в общем, если у вас вылезает такая проблема, то вы не умеете проектировать системы
Мда… бывает… Господин хороший, вы для начала кухонный кран изучите. Особенно старый и ржавый. Поэкспериментируйте, какие там контракты есть. :-) А потом на опыте убедитесь, что
Контракты — хорошая вещь для работы в искусственном цифровом мире. Там, где нет ничего серьезного, мы просто можем сказать, что контракт нарушен и мы так не играем. А в реальном мире бывает всё, что можно придумать. И кое что из того, что придумать нельзя. И ваш код должен переварить любые некорректные данные. И лучше всего — работать на них. Не может корректно работать — значит диагностировать ошибку и мягко деградировать функционал.
Ну как пример — cuise control. Очень советую, почитайте по ссылке, отлично описывает нашу область. У коллег был контракт: если колеса не вращаются — значит машина не едет. Вроде разумно?
Вот одна из хорошо задокументированных историй. В начале 2004 года американка Энджел Экк (Angel Eck), ранним утром ведя свой Pontiac Sunfire по пустынной автомагистрали в направлении к Денверу и воспользовавшись круиз-контролем, неожиданно обнаружила, что не может сбросить высокую скорость машины ни нажатием на тормоза, ни переводом рычага сцепления в нейтральное положение, ни выключением зажигания. В отличие от перенаселенной Европы, безлюдные регионы США, как и в России, часто не накрыты сетями сотовой связи, но, в конце концов, мобильник Экк заработал, и она смогла дозвониться знакомому механику. Ни один из его советов, правда, не помог укротить автомобиль, несшийся со скоростью 130 км/час, зато находившийся рядом с механиком коллега связался со службой спасения 911. Предупрежденная полиция расчистила автостраду на подъезде к Денверу и разогнала по параллельной полосе одну из своих тяжелых патрульных машин, которая затем пристроилась перед «Понтиаком» и начала понемногу притормаживать. После небольшого удара машины вошли в контакт, и в конце концов автомобиль Экк все-таки удалось остановить.
Отвалился датчик оборотов — и весь контракт полетел к черту.
Вы думаете, что cos(x) от -1 до +1 это хороший контракт? А потом ошибка округления и программа берет arccos от числа больше 1. На 1E-14 больше — но контракт нарушен. И
Значит, вы неправильно провели декомпозицию задачи. Инженерная культура, которую мы потеряли.
Ну я уже писал, что С++никам захочется сменить стан, потом завод, потом страну, потом поискать другой глобус. При неудачно выбранном языке программирования меняют язык.
Успешно послали команду на открытие задвижки (контроллер не сдох, нога не отвалилась, что там ещё может случиться) — всё, этот ресурс захвачен. Как вы и пишете, надо закрывать.
Господи, какой детский сад!!! А если команду не послали, но уже транспарант зажгли и сирену врубили?
В реальном мире — ресурсов нет. Ресурс — это абстракция, придуманная для искусственного цифрового мира. А то, что вы цепляетесь за заведомо непригодные парадигмы — означает вашу профнепригодность к работе с объектами реального мира. Просто запомните, что концепция ресурсов основывается на атомарном захвате. А там, где его нет — там иные концепции.
Чтобы было понятней. Вот вам RAll
Атомарный захват двоичной сущности
Try
...
Finally
Атомарное освобождение двоичной сущности
End
А вот это не RAll, это реальный мир
Try
Работа с аналоговой сущностью
...
Finally
Завершающие действия с аналоговой сущностью
End
При этом завершающие действия — могу и не быть «закрытием». Бывает и наоборот — открытие любой ценой и в любой ситуации. Если при экстренном торможении автомобиля произошло исключение — тормозить все равно надо.
Заявление где-то на уровне тех, с лямбдами на примере Алгола-60.
А зря не почитали про запроцедуривание в алголе. Вашим лямбдам — лет 60 уже. И опыт был накоплен изрядный. Это в С++ они без году неделя.
Искренне рад за него. Серьёзно, без сарказма.
Угу, он тоже очень удивлялся, когда реальный мир вел себя совсем не так, как ему хотелось. И тоже хотел поменять приборы, потом завод, страну и земной шар. Потому и не сумел за год отладить ни один проект.
Вы точно понимаете, чем «атомарный» отличается от «медленный»?
Конечно. А вы понимаете? При медленном захвате есть
Щито? Кто там с кем параллельно исполняется?
Ещё раз советую троллить тоньше. Схема RAll была придумана прежде всего для захвата ресурсов в мультинитевой (multi-threads) среде. Её цель — предотвращение deadlock и гонок. Если бы эта цель не ставилась, то можно было бы сделать намного гибче.
Вообще мой совет — читайте историю ИТ, много более понятным станет.
Я использовал поставленное вами ТЗ про 97%, считающимися открытыми.
Моё ТЗ описано несколько в ином месте. Попробуйте реализовать его на RAll.
А на кухне у меня вообще не кран, а, фиг знает как называется, штука такая с одной торчащей палкой, налево поворачиваешь — горячая вода, направо — холодная. Я её вообще одним движением руки вверх поднимаю до упора. Атомарно.
я же говорю, инженеров вы никогда стать не сможете. Однорычажный шаровой смеситель это. По сути — там две задвижки и общий рычаг регулировки. Атомарно вы его не открываете, если вас подстрелить в момент открытия из access violation, вы его даже по суммарному напору откроете лишь частично.
В конкретно вашем случае вы это повторное использование перепоручили компилятору, вернее, тому, во что он разворачивает try/finally, и теперь упорно отказываетесь это видеть. Окей.
Опять троллите? Не надоело? Повторное использование чего? Загрузки регистров процессора? Ну да, компилятор многократно использует инструкции процессора. И что? Важно, что технологические операции между finally и end записаны в правильном месте кода. То есть техпроцесс читается сверху вниз.
В чём принципиальная разница?
Разницы между RAll и onScopeExit нету — это два сорта одного
Вы реализуйте пример и увидите, что с читабельностью у вас хана. Вместо чтения 1-2-3-4 у вас будет 3-1-4-2 (или что-то похожее). То есть технологи не смогут ваш код проверить. А в итоге — он просто не будет поставлен на завод, пока вы не перепишите его нормально, в читаемом сверху вниз виде.
Вы не программируете техпроцесс. И даже не кодируете. Это все забота технолога. Вы лишь транслируете его из официального описания на язык программирования. И должны делать это с полным соблюдением структуры техпроцессора. Скорее всего это требование даже в ГОСТ включено (я просто не особый знаток гостов).
Давайте что попроще рассмотрим, транзакции в БД, например. Они могут быть медленными, ажно IO на удалённые сервера, но при этом вполне себе атомарными.
я очень надеюсь, что вы троллите, а не просто ламерствуете. В транзакции атомарный момент — это только commit. Простейшая реализация — создаем новую копию, вносим в неё изменения, в момент комита — заменяем основную базу копией.
Одна история офигительнее другой просто. Процитирую википедию: The technique was developed for exception-safe resource management in C++[3] during 1984–89.
Так это только в С++. В тех книжках, что я читал в 81-82ом году все это уже было. Непонимание тут может быть вот в чем. я говорил о модели захват-использование-освобождение, которая была придумала в начале 60ых. А если вы имеете ввиду правила неявного (автоматического) вызова деструктора, то вы правы, но для меня не особенно важно, вызывает ли деструктор компилятор или это нужно явно писать в коде.
А мне в контексте этой задачи неважен суммарный напор, мне важно, что кран открыт, и из него течёт хоть сколько-то воды, и что его лучше бы закрыть.
А кран надо закрывать после любой попытки его открыть. Иначе со временем из него может начать капать. То есть чуть дернули, вроде бы пока ещё закрыто, но со временем — кап-кап-кап…
Неужели вы не видите самого главного отличия? Схема RAll предполагает, что при исключении в конструкторе захват не произошел, поэтому деструктор не вызывается. Таким образом, мы не можем открывать задвижку в конструкторе.Мы можем туда запихать только намерение открыть задвижку. То есть конструктор у нас будет пустым.
Да нормально всё читается.
Для начала — реализуйте пример. Пока вы его не реализовали — вы лишь впустую троллите
В вашем варианте
Не фантазируйте, а посмотрите на код. Только кода вы напишите эквивалентный код с RAll можно будет сравнивать читаемость. Ваша ошибка в том, что вы не понимаете сравнительные размеры частей.
Собственно, я и ошибки предпочитаю так обрабатывать.
Вы точно троллите. У вас исполнение все равно идет сверху вниз. То есть сначала исполняется someOperationSucceeded, а уж потом — нижележащий код.
Вашу схему я использую, но только когда не надо явно писать деиницализацию. Если перед return вам нужно вставить delete — ваша схема становится багоопасной. Тогда придется использовать владеющие указатели или тот же RAll. Но без деинициализации — вполне нормальная схема.
Прям всю базу заменяете?
Почитали бы по ссылке вместо троллинга, а? Там заменяются отдельные страницы.
А у нас какой язык — лейтмотив всего обсуждения?
я с самого начала говорил, что мы не пишем на С++, у нас Си с элементами С++. И знание разных языков дает понимание, что лучше, а что хуже.
При этом вызываются деструкторы всех уже сконструированных объектов.
А их нету. И у меня и вас конструкторы пустые.
Я что-то делаю сильно не так со своей жизнью, если в 00:09 вечером после пятничного релиза занимаюсь таким. И тем не менее,
У меня тоже спор с вами занимает слишком много сил.
Надеюсь, что я правильно уловил суть исходного кода, но смысл понятен, надеюсь.
Ну ужас. Ну хорошо хоть не ужас-ужас-ужас. Ну а теперь смотрим структуру:
- впускХранитель
- выпускGuard
- перекачка и все прочеее
- еще всякие операции
Исполняется 3-2-4-1. Ну вы понимаете, куда вас пошлет технолог с таким кодом? Переделывать. И будете переделывать до тех пор, пока техпроцесс не будет читаться сверху вниз. Ну те же лямбды для 3 и 4 можно ввести. Или ещё как-то извратиться. А можно — не извращаться и использовать try..finally с легко читаемой структурой. не вами читаемой, а технологом.
Не пишите руками delete. Чем вам владеющие указатели вроде того же unique_ptr не угодили?
Ну и опять вы за деревьями не видите леса. Ну а если там не delete, а fclose? Есть простое правило - для надежности программы в процедуре должен быть один return. Разрывая код на множество одноразовых вспомогательных объектов вы лишь ухудшаете его чтение и модификацию.
Вы просто в упор не хотите видеть очевидного: лямбды удобны лишь тем, что позволяют писать код ровно в том месте, где он будет выполняться. Точнее для лямбд вы считаете это достоинством, а для отстальных методов — недостатком. Хотя на самом деле — это достоинство для любых одноразовых частей.
ну а ваш код правильно пишется так
do {
if (!good)
break;
...
} while (false);
Если технолог смотрит в ваш код и посылает переделывать — значит, программист — он. А вы просто кодер.
Машину водите? Программер — тот, кто правила дорожного движения писал. Водитель — кодировщик. А авторы системы автовождения лишь транслируют алгоритмы, полученные от водителей, на понятный компу язык.
Что не исключает кучу творческой работы на более низких уровнях системы.
Вы не программируете техпроцесс. И даже не кодируете. Это все забота технолога. Вы лишь транслируете его из официального описания на язык программирования.
весь набор изменений атомарный. Они либо все вместе происходят, либо нет.
Ну значит вы просто не в курсе, что такое транзакции. Рекомендую ознакомиться с понятием "Уровень изолированности транзакций". Ну как обычно — как любитель С++, так
Значит, либо C, либо C++, нет такого языка «С с элементами C++».
И опять — у вас в голове неверная модель реальности. Вообще говоря, никто не пишет на полном языке, все используют те или иные подмножества. Довольно известный факт — при написании компилятора алгола-68 на алголе-68 использует примерно треть языковых конструкций.
У нас используется очень малая часть возможностей С++ и практически полный набор возможностей Си. Это и называется «С с элементами C++».
Если вы заворачиваете всю вашу работу с кранами в RAII, то нет.
Увы, вы опять неправы. В конструктор нельзя запихнуть технологические операции, потому что при сбое на технологической операции — надо вызывать деструктор. А он — не вызывается при ошибке в конструкторе. Так что конструктор в этой ситуации всегда пустой.
Значит, ваш технолог привык к try/finally.
Технологи привыкли к блок-схемам и SFC, но Try..Finally выразимо в этих понятиях, потому легко объясняется.
А вот объяснить, почему неиспользуемую переменную нельзя выкинуть из программы — весьма сложно. :-) Сами-то сумеете объяснить, почему если у нас не используется переменная double — то компилятор ругнется и переменную выкинет. А если типа Complex — то и не ругнется и не выкинет. Только не надо тавтологий, типа «это же объект». Вы мне объясните, почему неиспользуемый объект не должен выкидываться из программы!
Значит, я возьму RAII-обёртку для fclose, проблем-то.
Проблема простая — усложнение кода. Чтобы понять ваш код с излишними уровнями абстракции, нужно очень много помнить. Вы создаете лишние слои абстракций, они уменьшают читаемость. А чем меньше читаемость — тем хуже с модификацией, с надежностью…
Если вы не используете RAII.
В любом случае. Даже при RAll goto :-) и множество return — это плохо. Есть некоторое количество исключений, основное из которых — творите все, что хотите, если ваш код читаете только лично вы и ваши подчиненные. Для всех остальных — удобнее один выход.
Причина простая — при быстром анализе смотрится на заголовок и конец функции — что же она возвращает. И очень легко просто не заметить return в середине.
Потому что лямбды предназначены именно для этого, чтобы было дёшево (в смысле количества движений руками и нажатий клавиш) создавать функции, которые понадобятся один раз вот здесь.
Вот ровно для этого и предназначен try..finally. Для написания финализации, которой больше нигде применяться не будет.
атомарные изменения вполне могут быть растянуты во времени.
Мда… у вас иная модель в голове. На самом деле, если взгляните на СУБД из реального мира и будете на каждом такте фиксировать состояние памяти и диска, то никаких атомарных изменений вы не увидите. Транзакции — это способ искусственно сделать атомарность для другого треда. Но тред — это такая цифровая сущность, в реальном мире её нет.
В технологических процессах важнее, что видит
Абстракция открывающейся атомарно задвижки — реальному миру неадекватна. Может пропасть электричество, сгореть мотор, задвижку может просто заклинить…
Если уж вам хочется бинарную абстракцию, то это или задвижка закрыта и не управляется программно — или она управляется и по окончании процесса её нужно привести в исходное закрытое состояние. Ещё раз напомню, что у задвижки (и у любого крана) я могу выделить 11 разных зон. Если вы немножко поиграете с краном в ванной — то большинство этих зон увидите.
читает об оспариваемых фичах только через две недели после начала спора — это обычно или нет?
для понимания, что данная фича нам не нужна (или нужна не настолько, чтобы из-за неё отказываться от чего-то важного) мне хватает минимума знаний. Стар я. Детское любопытство давно закончилось. Так что знания мне потребовались лишь для спора с занудами.
Знаете, кто такой зануда? Это человек, с которым проще переспать, чем объяснить, почему вам этого совсем не хочется. Ну вот вы, например. :-)
Я вот, например, наверное, никогда не пользовался функциями с переменным числом аргументов
Ни одного printf не написали? Ой не вериться… А вот с битовыми полями наверняка не сталкивались.
если это единственный агрегированный объект в вашем классе, то смысла в вашем классе действительно нет.
Ну наконец-то поняли! Объект — это задвижка. А объект «задвижка открыта» не имеет смысла.
Потому что, если немножко упрощать, единственная оптимизация, изменяющая видимое поведение программы, которую компилятор имеет право делать — RVO.
я о другом спрашивал. О том, почему в С++ были сделаны именно такие правила, когда судьба неиспользуемой локальной переменной зависит от её типа. Похоже, что это была недоработка в cfront, которую начали эксплуатировать, а уж потом — признали полезной.
Если вам что-то надо помнить про детали реализации абстракций, то вы неправильно выбрали абстракции. Абстракции для того и нужны, чтобы спрятать несущественное на этом уровне оперирования логикой.
Вот именно. Согласен на 300%. Это основная причина, почему единый код технологической операции вредно разрывать на несколько кусков.
По этой же причине RAll пригоден для захвата ресурсов. И не пригоден для всего остального.
При быстром анализе достаточно посмотреть на сигнатуру функции.
В С++ нету диапазонных типов. Если возвращается int — непонятно, как кодируется ошибка — как 0 или как -1 или вообще -MAX_INT. Если возвращается unsigned — непонятно, это указание на то. что результат всегда положительный или на то, что в int может не влезть?
Почему множество return при RAII — это плохо? Только из-за следующего процитированного мной фрагмента, или есть и другие причины?
Да вообще читаемость ниже. То есть оно немного индивидуально, но return в середине кода легко не увидеть. Если редактор сворачивает блоки — return легко может оказаться в свернутом блоке. Я их пишу лишь в начале процедуры, при анализе входных параметров. А дальше — уже один return в конце.
Но вообще… после изучение APL и FORTH стало понятно, что человек может выкрутить мозги на какой угодно стиль и систему понятий. Так что если оно лично вам читабельно — ну что тут поделать…
Что атомарности не существует, поэтому атомарные абстракции не нужны?
Атомарность в процессоре существует. Грубо говоря все, что длиться не больше скана или при закрытых прерываниях или с запретом обращения иных процессоров к памяти — атомарно. На базе этой атомарности можно сделать искусственную атомарность для транзакций и всего прочего. А вот в реальном мире не то что атомарности, там даже процессоров нету.
Поэтому когда вы
Сравните сами. Кран, капающий часами, видели все. А вот выключатель в искрящем положении — это сотни (или десятки) миллисекунд, не больше. Там пружина, его в любой ситуации притянет к одному из двух устойчивых положений. Триггер — обычно атомарен. Но иногда — даже тригер работает не атомарно.
Так что прежде чем выдумывать атомарные абстракции, надо хорошо предметную область изучить. Но… Это вот общая беда любителей С++ — желание использовать привычные абстракции там, где они не применимы.
Только не называйте это старостью, пожалуйста, а то как-то страшно стареть после такого
А стареть вообще неприятно. В юности я в чем-то был похож на вас. Потом повзрослел, набрался опыта. Зато и научился отличать полезное, от того, что в нашей области бесполезно.
Зачем мне свой принтф писать, стандартный уже есть
Значит использовали. То есть, когда вы писали "Я вот, например, наверное, никогда не пользовался функциями с переменным числом аргументов" вы просто спутали использование функций с переменным числом аргументов с их написанием. Ну господин хороший… Ну или уж пишите корректно или не требуйте 100% корректности от других.
А свой printf пишется для логгирования. И для доступа с нескольких консолей сразу (через радиоканал, через ком-порт, через TCP/IP). Вызов LogPrintf один, а ушло сразу и в лог и на все подключенные консоли.
А вот битовые поля, кстати, использовал. Оказывается полезным, когда хочется побольше данных из памяти побыстрее вытащить, да чтобы в кеш побольше поместилось.
Боюсь что на вытаскивании данных из битовых полей потеряете больше времени, чем сэкономите. Проверьте, там может быть и замедление.
Подождите, как именно судьба неиспользуемой локальной переменной зависит от её типа?
Пишем класс Int со всеми свойствами int. В итоге на неиспользуемый локальный int a имеем предупреждение компилятора и при оптимизации он удаляется. А неиспользуемый локальный Int b живет до окончания области видимости (scope). И никаких предупреждений не вызывает.
я понимаю, что вам это настолько привычно, что вы не видите, что это нелогично. Но по большому счету — лучше было бы иметь язык с запретом на побочные эффекты в конструкторах и одинаковым поведением встроенных и сконструированных типов. Правда такой язык не допускает ваш любимый RAll.
Ага. Поэтому лучше возвращать boost::optional.
Ну это только для ситуации, где всего один вариант «нет результата». Как только у вас появляется код возврата — вас такое не спасет. Но да, в SQL сделано именно так.
Да, поэтому лучше возвращать uint32_t, int64_t и прочие подобные вещи
Неужели вы не видите, что не поможет? Что означает uint32_t? То, что может не влезть в int32_t или то, что это int32_t, только результат не отрицательный? Тут полезны диапазонные типы, которых нет в С++.
Ну будет у вас в конце один return result;. Сильно проще стало?
У меня в конце будет return ok? result: -1;. И да, в таком виде — сильно проще.
Я не очень понял это тезис, можете пояснить? Про процессоры особенно.
Берете природу и законы физики и видите, что все они непрерывны. Да, бывают бифуркации. Но они тоже не атомарны, а несколько растянуты по времени.
Берете вторую природу (технику) и опять — настоящей атомарности в ней нет. У выключателя света — не 2 состояния, а несколько больше. Во время включения и выключения — есть фаза искрения, есть дребезг…
И только когда речь идет о логике и созданных на е ёоснове юриспруденции и математике появляется атомарность.
Да, в программировании это базовое понятие. Но для природы и для техники — это абстракция, во многих случаях выплескивающая с водой ребенка. То есть абстракция неверная и опасная.
Ну как пример, отключили питание от сети, подали от батареи. Если вы решите, что это делается атомарно и мгновенно и забудете сделать задержку — у вас будет в какой-то момент прибор соединен и с сетью и с батареей. И на батарею пойдет ток от сети.
Зачем, если я могу взять boost.log, наваять свой типобезопасный велосипед на вариадиках или что-то подобное сделать?
- Каким количеством ОЗУ и ПЗУ мне придется заплатить? На мелкой машинке у нас даже полный printf не лезет, используем xprintf без поддержки плавающих.
- Как вы будете вызвать логгер из кода на Си? или иметь два логгера — один для системной части, а второй — для прикладной?
- Время выбора чужого решения и его допиливания под специфичные нужды — больше времени написания своего кода (200 строк).
- Один из приоритетов для нас это возможность уйти на чистый Си в ситуации, когда часть кода должна исполняться на какой-то странной архитектуре (DSP, ключ, может даже ПЛИС).
Собственно советую обратить внимание на обзор — из 8 логгеров 5 используют формат printf и 5 формат <<. Из них для нас стоит рассматривать только P7 b и только ради телеметрии (которой у нас пока нету).
Потому что компилятор недостаточно умный, чтобы определить, что конструктор можно убрать. Статический анализ (у которого заодно больше времени на, собственно, анализ, чем у компилятора при компиляции) мог бы помочь.
Ответ неверен. Это языковое решение — разрешить побочные эффекты в конструкторах. Возможно обратное решение — конструктор только выделяет и инициализирует память, а метод init уже занимается установлением связей и побочными эффектами. Такой язык я вполне себе представляю.
пятым местом чую, в общем случае решение проблемы о наличии сайд-эффектов где-то на уровне проблемы останова
Вы не правы. Жесткий контроль на наличие сайд-эффектов возможен. Грубо говоря, каждая функция маркируется как чистая, если она не изменяет своих параметров и глобальных переменных.
Посмотрите внимательно на constexpr там решается ровно та же задача.
Вы на очень скользкую территорию заходите, в общем случае эти задачи трудно решаются и требуют либо принципиально другой типизации, либо отвергают слишком много семантически корректных программ.
Да, это иное построение языка. Но это не значит, что такой язык невозможен. Просто Страустрап не захотел пойти таким путем.
Осталось определить, что такое побочный эффект.
Для данной ситуации: изменение параметров, изменение глобальных переменных и внешнего окружения, за исключением захвата памяти из кучи и стека (и изменения членов класса).
Что как int32_t, только результат не отрицательный
Не всегда, далеко не всегда. Как пример — значение 32битного регистра аппаратуры. Там бывает и старший бит выставлен.
Тогда лучше boost::optional возвращать, опять же.
Если нас не должны вызывать из Си — вполне себе решение.
Она и предоставляется бинарниками (под x86_64, например), для которых заранее известны хэш-суммы. И не обновляется, кроме как новым сертифицированным релизом.
В случае разных security баг публикуется информация о workaround'е или ручном патче, если речь идёт о скриптах, т. к. обновить ПО невозможно.
Еще бы ребята из JetBrains ввели подобную практику. =)
На далеко не топовом i5-2520m с -Xmx750m (на ssd, ессно) и существенно большими файлами не тормозит. Исключение — первичное индексирования sdk/большого проекта (при добавлении sdk или обновлении самого pycharm), но это не сильно долгий процесс.
Вы в багтрекер писали, результаты профилирования отправляли?
В багтрекер не писал тк пользуюсь не часто. Почти убежден что это не баг а фича джава движка и лучше вряд ли кто на нем сделает и что выход тут один — переписать это дело на C++ Qt.
Это может сильно зависеть от используемой версии xorg, используемого видеодрайвера, композитора и версии самой jdk (например, много проблем было на openjdk, которые отсутствовали на oracle jdk). Если у вас win, то может ощутимо влиять резидентный антивирус. Факторов выше крыши.
На C++ никто в здравом уме продукт такого объема переписывать не будет, тем более, что у меня по комментариям на хабре и на форумах складывается впечатление, что продукты jetbrains лагают у очень небольшого процента пользователей (но такие пользователи, естественно более заметны, чем те, у кого всё работает). По наблюдению за некоторыми проектами, которые пытались просто портировать готовое решение на java на c++ — обычно сильно не успевают за темпом разработки при попытке иметь сходный уровень качества, а часто и уровень качества проседает настолько, что оно становится просто не нужно.
1) Жрёт память оно довольно сильно. Сжирает первый гиг быстро. Но! Я импортировал проект ReactOS, и он после индексации сожрал 2.7 Gib RAM. Так что с IDE от JetBrains не так всё плохо. Но конкретно в Clion много чего не хватает, очень много.
Clion сыроват на мой взгляд, правда после 1.0 его не пробовал. Экспериментировал с ним начиная с private EAP.
А проекты на C и C++ и будут более прожорливы, чем, например, на java, где с анализом и индексами существенно попроще. У clion и xmx по умолчанию 2g. Меня не сильно парит прожорливость по памяти, если она обменивается на нормальную навигацию, автодополнение и рефакторинги. И в этом месте clion'у ещё стоит дать времени на развитие.
Мне лично сильно не хватает фич для embedded разработки, но они не слишком популярны в багтрекере.
У них есть академические лицензии (для студентов и преподавателей), лицензии для учебных заведений, лицензии для open source проектов (проект должен быть живым и иметь живое community, это стандартная практика для многих подобных продуктов).
Для индивидуальных разработчиков — да. Что приятно, эти лицензии не ограничивают область применения.
Плюс IDEA CE и PyCharm CE, которые не просто бесплатные, но и свободные, но функционала связанного со всякими web-dev и enterprise фичами там не будет.
Ну, для чего-нибудь well establised живость доказать просто: статистика активности mailing list'а, форума и т. п.
По сути, этим вариантом закрывается кейс, когда разработчик на работе пользуется корпоративной лицензией, а дома ему idea/rm/ws/pc/whatever нужна для работы только над open source проектом.
При обсуждении способов не вспомнили про технологию fuse, через которую можно добавлять соответствующий заголовок ко всем .cpp.
Как это может работать:
1) Разработчики добавляют файл в проект с рекламной информацией и, возможно, своими контактами. Запушивают его в публичный репозиторий.
2) Ваш web crawler находит такие проекты и запускает их анализ на ваших серверах.
3) Результат анализа отправляется разработчикам через возможности самих github / bitbucket / … или по указанным контактам разработчикам.
4) Profit!
Или я что-то неправильно понял?
-Wall -Wextra -W... и посмотрите на результат. Большая часть сообщений — будет из-за того, что проект некоторые «рекомендации лучших собаководов» не соблюдает. Например не обрабатывает все варианты enum в switch. Что вовсе не значит что подобные сообщения отлавливать не нужно — для тех проектов, у кого в style guide подобные вещи прописаны эта диагностика, разумеется — очень полезна.P.S. Кстати -Wall и в clang и в gcc включает в себя далеко не все сообщения обшибках — именно поэтому.
И да, раз вы сделали версию и под Linux — можно ли ждать консольную версию для macOS?
Чисто теоретически это направление нам интересно. Но в планы пока ничего такого не вписано.
Вы не хотели бы рассмотреть вариант подписок которые предлагает например JetBrains для своих продуктов?
Простите, но зачем правило на комментарии? Да еще и в таком стиле?
>Dear PVS-Studio, please check it
Складывается впечатление о каком-то высокомерии.
Насколько урезанной выглядит эта ваша бесплатная версия?
- Мне кажется, в статье дан ответ, на вопрос «зачем правило на комментарии?»
- Они не урезанная. Это полноценная версия. Комментарий — плата за неё.
Мне кажется, вы живете в своем идеальном мире.
Поиграться, народ поиграет в вашу подделку, а после забудет.
Никто не будет в своем разуме засорять код нелепыми комментариями (да еще и в каждом файле!).
Это бред.
«Нельзя так просто взять и выпустить бесплатную версию, нужно обязательно сделать ее неюзабельной» — девиз PVS-Studio
Никто не будет в своем разуме засорять код нелепыми комментариями (да еще и в каждом файле!). Это бред.А тем временем — PVS-Studio и GitHub-сообщество: начало дружбы.
Кажется, где-то вы не договариваете.
Если уж зашла речь о комментариях, зачем из целых 3 вида? Почему нельзя было остановиться на каком-то одном? Есть подоздрение, что вы просто парсите эти комментарии и отключаете множество диагностик для полученного типа (студент, разраб, open-source).
Это, кстати, опровергает тезис из статьи о провале cppcat: «Уровень культуры программирования индивидуальных разработчиков и маленьких команд ниже, чем в крупных компаниях.» Библиотека от очень крупной компании…
Это, кстати, опровергает тезис из статьи о провале cppcat: «Уровень культуры программирования индивидуальных разработчиков и маленьких команд ниже, чем в крупных компаниях.» Библиотека от очень крупной компании…Это embedded. У embedded главное — чтобы было «Дёшево, дёшево, дёшево? Нет — ещё дешевле!»
Этот мир ещё ждёт своих регуляторов. Есть хорошая статья-предупреждение от Брюса. Не знаю — был ли тут перевод, но чувак совершенно прав: в развитии IoT неизбежно (и довольно скоро) наступит момент когда «мир Internet» (где подобный подход приводит к проблемам) и мир embedded (где разработчикам за безопасность и отсуствие ошибок никто не платит) столкнутся. Интересно сколько будет жертв до того, как какие-то нормы будут разработаны…
===============================================================================
Это Вы, простите, так шутите да? В мире embedded 1 единственная ошибка может покалечить, и/или даже убить, в отличии от повисшего сайта, или некорректной вставки фото пользователя в бложик. И тестируют продукты в embedded не меньше, и относятся к этому не менее серьезно. Если это не ардуино-перделка-всепогодная-хрень-показометр конечно :).
А за возможность использовать Ваш продукт (полностью легально для себя любимого) спасибо!
В мире embedded 1 единственная ошибка может покалечить, и/или даже убить, в отличии от повисшего сайта, или некорректной вставки фото пользователя в бложик.Есть такое.
И тестируют продукты в embedded не меньше, и относятся к этому не менее серьезно.Его тестируют примерно как и любую другую железяку. Мы там придумали какие-то тесты, их прогнали, если всё работает — все счастливы. А потом — мы типа релиз выпустили и всё зашибись.
А в мире ПО — этот подход не работает! Для того, чтобы ваше поделие в ступор ввести нужно, чтобы кто-то специально на него как-то воздействие оказал так, чтобы там буфера переполнились, счётчики обнулились и т.д. и т.п. Причём люди активно и постоянно работают над тем, чтобы найти подобные вещи и использовать их. Всё это хвалёное тестирование ничего этого не выявит. Потому я и сказал то, что сказал.
Embedded всё ещё считает что он живёт в мире, где бывает софт без багов. И из этого исходит. А это — уже давно не так. В результате всё это тестирование превращается в фарс: зачем нужны какие-то анализаторы и статистика, если в результате все всё равно знают что в релизе будет полно ошибок и их после этого уже никто и никогда не будет править? А раз никого не волнует реальная безопасность создаваемого продукта и важно только пройти тесты — то зачем вкладываться в культуру программирования? Если за это никто не платит?
Скажите а поддержки F# в планах нет?
А когда вышел анализатор для C# реально скорость добавления диагностик для C++ снизилась в разы. Это даже по changelog'у видно.
Ещё два вопроса перед тем как нырять в чистые воды статического анализа — если (или когда) вы решите, что «халяву» прикрывать надо и уберёте возможность бесплатного использования:
1. могу ли я удалить шапки после этого? Или они должны остаться навсегда после первого использования согласно лиц.соглашению?
2. требуется ли обновлять раз в год бесплатную версию или она не «превращается в тыкву» с течением времени? (да, я помню преимущества постоянного обновления анализатора, но вот представим, что не обновиться никак)
Если Вы используете PVS-Studio for Linux, то сразу переходите ко второму шагу, файл с лицензией вам не понадобится.
Не подскажете, что не так делаю?
$ cat malloc.c
// This is an open source non-commercial project. Dear PVS-Studio, please check it.
// PVS-Studio Static Code Analyzer for C, C++ and C#: http://www.viva64.com
#include <stdlib.h>
int main(int argc, char **argv)
{
(void)argv;
int *i = malloc(argc);
return i[0];
}
$ ./pvs-studio-6.11.20138.1-x86_64/bin/pvs-studio-analyzer trace -- gcc malloc.c -o malloc
$ ./pvs-studio-6.11.20138.1-x86_64/bin/pvs-studio-analyzer analyze
[100%] Analyzing: /home/user/malloc.c
Please request a trial license from our support at support@viva64.com.
Analysis finished in 0:00:00.05
$ ./pvs-studio-6.11.20138.1-x86_64/bin/pvs-studio-analyzer analyze -l malloc.c
[100%] Analyzing: /home/user/malloc.c
License information is incorrect. Please check your registration data or contact Customer Support at support@viva64.com
Analysis finished in 0:00:00.02
./pvs-studio-6.11.20138.1-x86_64/bin/pvs-studio-analyzer analyze -l PVS-Studio.lic
[100%] Analyzing: /home/user/malloc.c
Your license for PVS-Studio has expired. You may renew your license at http://www.viva64.com/en/renewal/.
Analysis finished in 0:00:00.02
Congratulations! PVS-Studio has not found any issues in your source code! 0
Хммм, а я-то думал, что-нибудь да вылезет на крупном проекте. :)
Вы должны вписать в начало каждого файла две строки с комментарием.
Прям-прям каждого?
Даже при полном отсутствии возражений со стороны всех разработчиков, для проектов вроде ReactOS, необходимость перелопатить около 50 000 файлов, чтобы дописать в них эти комментарии выглядит несколько пугающей.
Автоматизация
Если в вашем проекте много файлов, то вы можете воспользоваться вспомогательной утилитой. Вы должны будете
указать ей какой комментарий вставлять и каталог с кодом. Затем утилита рекурсивно обойдет все файлы в
папке и вложенных папках, добавляя в файлы с исходным кодом соответствующие комментарии. Скачать
утилиту (вместе с исходным кодом) можно здесь: how-to-use-pvs-studio-free.
А вы про СКВ (VCS)? Извиняюсь.
А среди наших разработчиков можно встретить тех тех, кто до сих пор сидит на EDGE. И таких не мало.
тех, кто до сих пор сидит на EDGE
Послушайте, а у бомжа, который сидит у вокзала вообще проблема — у него даже компьютера нет.
«Разработчики PVS-Studio — проклятые капиталисты! Заставляют голодающих африканцев 50000 файлов апдейтить.»
Давайте до абсурда не доводить?
Так что, действительно, лучше не доводить до абсурда.
В капитализме я никого не упрекал.
Комментарий
// This is an open source non-commercial project. Dear PVS-Studio, please check it.
// PVS-Studio Static Code Analyzer for C, C++ and C#: http://www.viva64.com
занимает 160 байт. Для 50000 файлов получается около 8Мб несжатых изменений. Даже без учета сжатия для EDGE и тарифов порядка $1/мб трафик вполне подъемный.
svn://svn.reactos.org/reactos/trunk/reactos
файлов там 19 тыс (50 тыс. это видимо посчитались служебные файлы внутри .svn), а *.c* — файлов 7063 — примерно 1.1Мб изменений.
Так что мне кажется это не так страшно.
А на практике, у нас была история, когда глюкнула вспомогательная эксперементальная тулза, что то там чирканула в свн (вроде бы поменялся корневой путь), в результате, хотя файлы синтаксически не поменялись, свн решил, что всем нужно полный чекаут провести. Не смотря на то, что что беду быстро обнаружили и в течение часа свн откатили из бэкапа, в рассылке и ирк-чате шквал вопросов и дискуссий не стихал еще неделю.
Информация собранная людьми становится незначительно менее качественной — строки всё равно плывут и вроде никто не следит за тем чтобы после коммита сохранялись номера строк.
Я не исключаю вероятности что в большом проекте при огромном числе изменений (даже таком синтаксически нейтральном) может быть какая-то непредвиденность, однако я бы тут оценивал не возможные проблемы из-за коммита
трех бесполезных строк в кучу файлов
а возможные проблемы vs выгода от получения инструмента с ценником если не изменяет память — несколько тысяч долларов.
т.е. если инструмент не нужен — то и возможные проблемы от коммита не нужны
если нужен — то соответственно сравнивать степень риска/пользы с выгодой от инструмента, а не с бесполезными изменениями в файлах.
Скажите спасибо, что по милой привычке гугла и прочих «корпораций бобра» бесплатное приложение не будет отправлять «соверешенно обезличенную статистическую телеметрию» на сервера PVS на каждый чих.
Вам дали бесплатную возможность. Каменты — плата за эту возможность. Кто-то может «поставить adblock» см.выше, а кто-то с удовольствием будет пользоваться и с рекламой.
Гораздо лучше чем отсутствие анализа вообще и/или анализ и с рекламой и со сбором данных. Ну а у богатых другие проблемы, нам не интересные.
По-моему, куда как более здравая была бы тема, чем вставлять дурацкие комменты в каждый файл. И опенсорсерам пофиг, и мега-корпорации не позволят у себя такое, и проконтролировать каждого инициативного васю, использующего не ту лицензию в обход начальства, можно будет легко и просто по логам сетевой активности.
в общем, если есть возможность программе в интернет не ходить — это кмк лучше, чем наоборот.
Пользовался лицензионной версией для корпоративного проекта (большая кодобаза, > 15 лет разработки).
Несколько мелких, но вредных ошибок PVS нам поймал.
Теперь обязательно буду применять этот инструмент и в личных проектах.
Многие же ошибки можно проверять не зависимо от особенностей используемого компилятора.
Чтоб было понятно о чём речь и почему меня MS VS не устроил, уточню — я сейчас веду речь о embedded-проектах, конкретно, например, о связке MPLABX + XC8.
Для OpenSource-проектов, которые поддерживают больше чем 2-3 человека, вам нужна совершенно другая модель распространения лицензий. Сделайте web-сервис наподобие openhub.net . Автор опенсорс-проекта отправляет на этот сайт ссылку на свой публичный репозиторий, а вы автоматически выкачиваете код, анализируете, публикуете общедоступный отчет об ошибках о проектах, параллельно рекламируете платную версию для корпоративных пользователей.
Плюс интересная модель монетизации на основе абонентской платы — задержка общедоступной публикации о найденных ошибках на 30 дней, с приоритетным доступом только для авторов проекта. Это будет интересно открытым проектам, которые переживают о своей репутации.
То, что описали вы, стоит хрен знает сколько много человеко-часов разработки, которые мы совершенно точно не будем тратить на такую ерунду.
Мы лучше что-нибудь полезное этими ресурсами сделаем.
pvs-studio --version
В остальном запуск в корне неверный, в Вашем случае надо было так:
pvs-studio-analyzer trace -- gcc -Wall -pedantic void.c
pvs-studio-analyzer analyze -o void.log
plog-converter -a GA:1,2 -t tasklist -o /path/to/project.tasks void.log
Вы можете смело проверять конкретный проект и смотреть результаты. Результаты будут гораздо нагляднее, чем на тестовом файле.
Мне особенно понравился критерий бесплатности: по сути клиент сам решает будет ли он пользоваться платной версией или бесплатной.
Большие организации скорее всего действительно купят, т.к. они явно не индивидуальный проект и тут может сработает бюрократия, может внутренний имидж + нужна поддержка и т.п.
В конце концов большие предприятия и redhat покупают просто из-за поддержки, даже без доп. условий хотя есть бесплатный centos/oracle — точно такие же но без поддержки.
А те, кто будут пользоваться бесплатной версией скорее всё равно всё равно бы никогда анализатора не купили.
Разработчики могли бы быть мягче, но, чай, бесплатно работать никто не хочет.
Нормальный хабр. Предлагают не бесплатный продукт, а продукт за рекламу. Вот люди и пытаются договориться о более удобных (для них) способах.
Ну и четверть комментариев про странную политику ценников-по-запросу. Да, есть компании, которые так делают. Да есть крупные компании так делают. Но почему такая политика обязана нравиться — я не понимаю категорически. Почему нельзя сказать о том, что такая политика тебе не нравится — я тоже не понимаю.
Возьмём для примера JetBrains и их смену схемы лицензирования недавнюю — ведь вой же поднялся! Но! JetBrains прислушались и немного модифицировали эту схему — в результате почти все довольны! Хотя некоторые представители оного в той теме тоже не понимали чего хотят все эти люди...
Так может и до этих корпаратов дойдёт их собственная выгода, которую они смогут достичь, если примут некоторые предложения сообщества… ну если тему постоянно мусолить.
Слушай… Нравишься ты мне… Давай даже за $100K?
Для доказательства — могу в новогодние праздники проверить один из наших проектов linux-версией PVS и оценить найденные баги в рабочих днях.
Разумная цена — недельный ФОП программистов за годовую лицензию.
То есть на самом деле вы выступаете за назначение индивидуальной цены для каждого покупателя?
Так ведь, судя по всему, сейчас так и происходит. Вам поправочные коэффициенты в формуле цены не нравятся?
А не нравится мне отсутствие прайса. Из-за этого перед расчетом эконономического эффекта нужно делать кучу шпионской работы по выяснению цены.
Впрочем, я все равно не покупатель. Нам pvs-studio явно не выгоден.
Из-за этого перед расчетом эконономического эффекта нужно делать кучу шпионской работы по выяснению цены.
одно письмо = куча шпионской работы?
У нас много госконтрактов, соответственно может быть налоговая проверка. А покупка софта без прайса — с точки зрения налоговой, это откат. То есть с точки зрения налоговой мы не купили софт, а просто обналичили эти 25 миллионов.
Вы отличайте сегментацию (против которой никто ничего не имеет) с отсутствием прайса.
И ещё раз повторю — нам pvs-studio не выгоден. Даже бесплатный cppcheck очень слабо выгоден. Время, ушедшее на анализ его логов, конечно, скомпенсировалось тем, что он нашел. Но сильной выгоды — не получилось. Не было никакого «ВАУ, я этот баг полгода искал»
Да, код стал почище.
И ещё раз — я готов доказать свою точку зрения проверкой одного из наших проектов бесплатной демо-версией pvs-studio.
Отсутствия цены на сайте, это стандартная практика в B2B. В первую очередь это связано с непростым ценообразованием, когда цена зависит от количества людей, длительности и другими частными моментами. Точно также действует, например, часто упоминаемый в комментариях Coverity. Такая модель никого не смущает, что подтверждается общением в почте с клиентами и потенциальными клиентами.
Отсутствие цены никогда не было и не может быть препятствием. Это подтверждается наличием больших и уважаемых компаний, ставших нашими клиентами. Уверен, что у скажем у 1C или МТС, не меньше госконтрактов, чем в кампании о которой говорит Jef239.
Про 25 млн, что-то мелко, чего уж сразу не 250. Человек или сознательно троллит или что-то путает. Жалеющие могут запросить цену, написав нам на почту.
Если не выгоден бесплатный Cppcheck, то да, верю, что и PVS-Studio будет не выгоден. Этот тот случай, когда качество кода не имеет значения. Использование статического анализа кода это определенный уровень разработки ПО, когда коллектив разработчиков начинает понимать, что это и для чего он нужен. «ВАУ, я этот баг полгода искал» — это неправильный способ использования анализатора, о чем мы пишем почти в каждой статье.
это стандартная отвратительная практика в B2B
исправил.
Про "непростое ценообразование" — не надо. Вы по простому письму сможете угадать уйму факторов, которые закладываете в цену? Что-то мне не верится. Значит просто пошлёте ценник из прайса… Ну так а зачем тогда лишний шаг, если его можно выложить в паблик. Кастомеру нужны доп. услуги? О различных дополнительных услугах (можно даже без ценников) можно также написать в прайсе.
PS то, что это едят, не означает, что это хорошая практика. И да — не всё B2B использует эту практику… Зато я видел отвратительные по качеству продукты в B2B, которые также используют такую практику.
PPS и как хорошо, что в мире Java есть хорошие рабочие тулы статического анализа… жаль findbugs перестал развиваться
Для того, чтобы получить лид.
А зачем получить лид? Чтобы ОБЪЯСНИТЬ ему лицензионную и ценовую политику. Увы, люди сами не всегда могут понять лицензионную и ценовую политику. И наличие контакта позволяет разговаривать с клиентом. Если же просто что-то на сайте вывесить — он увидел и ушел. При этом неправильно поняв.
Но конечно, комментаторам на Хабре лучше знать как мне вести мой бизнес…
Но конечно, комментаторам на Хабре лучше знать как мне вести мой бизнес…
Это не про бизнес, а про доступность базовой информации. Но если вам не нравится — можете не травмировать свою психику публикациями на хабре. Да и в других местах наверняка ведь найдётся какая-нибудь сволочь, которая будет критиковать ваши подходы… Точно, отличный выход — не публикуйтесь нигде.
PS грамотно составленный прайс занимается ровно тем, что вы пытаетесь сделать вручную. Почему уж у вас такой составить не получается — сказать не берусь.
В первую очередь это связано с непростым ценообразованием
я уже многократно писал, что я не против сегментирования. У нас такая же задача — как продать одно и то же по цене от 1 до 100 тысяч долларов. Но мы её решаем разными возможностями и разным железом.
Но отсутствие прайса — это расчет цены от фонаря. Потому что для сложного ценообразования нужно иметь сложный прайс. При сложном прайсе, действительно, проще запросить цену, чем рассчитывать самостоятельно. Но при этом поставщик прилагает расчет цены, ссылаясь на позиции прайса.
Уверен, что у скажем у 1C или МТС, не меньше госконтрактов, чем в кампании о которой говорит Jef239.
Уверен, что 1С или МТС есть деньги на содержание большого юридического отдела. А у стартапа из 10 человек нет ресурсов на суды с налоговой.
Про 25 млн, что-то мелко, чего уж сразу не 250.
Насколько я помню, лет 5-7 назад фигурировала цифра в 400 тысяч уе. 400 тысяч помножаем на курс примерно в 60 рублей за уе — и получаем 25 миллионов. Поискал — пока что нашел цену в 9 тысяч евро. Ну что же, приношу свои извинения, значит в 40 раз перепутал.
Этот тот случай, когда качество кода не имеет значения.
А мы с вами в разных мирах живем. Для вас предупреждения от -Wall -Wextra — норма. Для нас — указание срочно править код. Не знаю, что вы понимаете под «качеством».
Для меня качество — это работа программы 365*24 в течение 10 лет без единого видимого сбоя. Но это обеспечивается не отсутствием ошибок в коде, а активной защитой в виде нескольких контуров перезапуска. Дело в том, что ошибки в программе всегда будут. И состояние «не найдено ни одной новой ошибки за месяц, все известные исправлены» — не означает, что ошибок нет. Поэтому программа должна постоянно контролировать инварианты, а по наличию ошибки — перезапускать сбойную подсистему. 3 раза не прошел перезапуск — перезапускается система более высокого уровня. В пределе — переход управления на резервный сервер и перезагрузка сбойного сервера.
С моей точки зрения, пока у вас нету сервера в теплом или горячем резерве — говорить о надежности бессмысленно. Потому что заказчику не важно — сгорел вентилятор в блоке питания или сбойнул код в программе. программа и железо, на котором она работает — это единый комплекс. Вот о его качестве и надо говорить.
я уже многократно писал, что я не против сегментирования. У нас такая же задача — как продать одно и то же по цене от 1 до 100 тысяч долларов. Но мы её решаем разными возможностями и разным железом.
Стандартная ситуация, на самом деле. Так же есть 5 продуктов с перекрашенными логотипами, один из них бесплатный, 3 отличаются только ценой в прайсах и своими возможностями по масштабированию, один — без прайса, но только клиентам проектов уровня областей, государств.
А малый бизнес, конечно, смущается, когда ему впаривают что-то не по прайсу. Тут привыкли каждую копейку считать (иначе бы не выжили в российских реалиях), а отсутствие прайса вызывает неприятные ассоциации, и недоверие :( Вот моё руководство, например, было так сильно расстроено тем, что на сайте не было прайса, что долгое время было табу на тему по покупке лицензий, только в последнее время опять интерес появился к этой теме (видимо забыл уже, что там прайса нету :-) ).
Ну и поскольку железка требует установки на судно, то продавать через дилеров. Для дилеров — прайс, а дальше пусть они сами конкурируют.
А без прайса — это с перламутровыми пуговицами. То есть индивидуальная комплектация по желанию заказчика. Там много чего бывает, например выдача данных по протоколу заказчика.
> В идеале — узнать официально, на фирменном бланке покупателей с реквизитами и печатями.
Вам такую информацию официально не даст никто.
Не официально, за пивом при разговоре старых друзей из разных компаний, может быть и скажут, но лет через пару после покупки…
> У нас много госконтрактов, соответственно может быть налоговая проверка. А покупка софта без прайса — с точки зрения налоговой, это откат. То есть с точки зрения налоговой мы не купили софт, а просто обналичили эти 25 миллионов.
А здесь Вы не просто заблуждаетесь, а нагло врете.
Если хотите опровергнуть, покажите мне актуальные прайсы, ну, хотя бы на ANSYS. Что, цена по запросу? Ой, а как же его бюджетные организации и госкомпании покупают? Или сразу после их налоговая за обналичку того, и в тюрьму?
Ну или давайте хотя бы сервера купим, раз на ANSYS прайсов нет. Что?! И тут цены по запросу?
Да ну его, вон в соседнем магазе счеты купим и пусть эти инженеры на них считают. Работали же как-то 50 лет назад без всего этого…
Официально есть данные по тендерам. Так же официально они есть в отчетности по НДС. А такие вещи периодически утекают в сеть. Ну для начала тут можно полную справку заказать. А вообще, есть специальные фирмы, продающие такую информацию.
А здесь Вы не просто заблуждаетесь, а нагло врете.
К огромному сожалению не вру. Большой тяжелый корабельный прибор. Железо смежников, софт наш. Продают смежники. Прокурорская проверка у покупателей. И в рамках этой проверки прокуратура подозревает, что наши смежники не приборы продают, а занимаются обналичкой и откатами. А мы — запаздываем с отгрузкой. В основном по моей вине — хотелось софт побольше вылизать. В итоге, перед приходом прокуратуры к смежникам два генеральных директора всю ночь собирают приборы.
Это железо, понимаете? Это тяжелый прибор, упадет на ногу — в травму бежать надо. Корпус из пятимиллиметровой стали, ибо на атомные ледоколы ставится. Внутри — куча электронной начинки. При провозе в самолете — каждый раз нужно развиничивать и доказывать, что не бомба. Ну в общем очень не похож на торговлю воздухом.
Ой, а как же его бюджетные организации и госкомпании покупают?
Через тендеры. А если внимательно поискать, то увидим не только максимальную цену в 2.4 миллиона рублей, но и конечную цену тендера. С серверами — аналогично.
Или сразу после их налоговая за обналичку того, и в тюрьму?
Знаете, и серую зарплату многие получают. И неофициально работают. Каждая компания сама для себя определяет уровень риска. У нас нету юристов, нету опыта для тяжбы с налоговой и прокуратурой.
Как пример — у нас вот из-за вот из-за одной публикации в газете «Известия» тряслись. Все банально — пресс-релиз у смежников, журналист уточнил и опубликовал в газете. Вот только спрашивал он ориентировочную цену работы, а опубликовал как итоговую цену ещё не объявленного тендера. А это уже означает проверку ФАС и уголовное дело за сговор.
Так что свят-свят-свят нас от таких контрактов. Тем более на деньги от госзаказа.
Вы сможете доказать прокуратуре, что при наличии бесплатного CppCheck надо платить за PVS-studio? Есть официальное государственные документы, что PVS-studio лучше? Именно официальные, а не просто мнения специалистов.
Или сразу после их налоговая за обналичку того, и в тюрьму?
ну вот вам примеры уголовных дел,
В рамках этой схемы дочерние компании выплачивали многомиллионные вознаграждения сторонним компаниям якобы за изготовление комплектующих для систем управления и ракетоносителей
Уголовное дело о незаконно потраченном полумиллиарде рублей на развитие системы «ГЛОНАСС», продолжается.
Зато известно, что учредители «Транзаса» Михаил Букашко и Александр Кухаренко отметились в числе фигурантов уголовного дела, возбуждённого по статье 198 УК РФ («Уклонение от уплаты налогов»).
это все рядом — заказчики-смежники-конкуренты… Теперь, надеюсь, понятно нежелание покупать по необъявленной цене у фирмы с уставным капиталов 10 тысяч рублей, зарегистрированной в частной квартире?
Ну те за вами реально косяк был, хотя и не совсем такой, который считали налоговики?
> Через тендеры. А если внимательно поискать, то увидим не только максимальную цену в 2.4 миллиона рублей, но и конечную цену тендера. С серверами — аналогично.
Только это индивидуальные цены для конкретного заказчика. Начальная максимальная цена контракта определяется по трем коммерческим предложениям, которые сюрприз сюрприз делаются по запросу заказчика, так как прайса нет.
И, я Вам больше скажу, по этим ценам данный софт/железо больше никто не купит. В следующий раз будут и другие начальные цены и другие конечные.
В связи с этим мой вопрос остается в силе — где общедоступные прайсы?
> А это уже означает проверку ФАС и уголовное дело за сговор.
Так сговор, как я понимаю, все же был?
А ФАС проверяет все тендеры, где нашлись недовольные «поставщики». И к счастью в моей практике пока еще ни один недовольный поставщик, которые не могли ни ТЗ соответствовать, ни ценой выиграть, ничего не получали.
> Вы сможете доказать прокуратуре, что при наличии бесплатного CppCheck надо платить за PVS-studio? Есть официальное государственные документы, что PVS-studio лучше? Именно официальные, а не просто мнения специалистов.
ТЗ кто пишет? Государство или Вы? Так при чем тут государственные документы?
Я не очень уверен, что это вообще придется доказывать.
> ну вот вам примеры уголовных дел,
И все они только купили софт?
> Теперь, надеюсь, понятно нежелание покупать по необъявленной цене у фирмы с уставным капиталов 10 тысяч рублей
А других на рынке нет.
> зарегистрированной в частной квартире?
Разве что это единственное, что можно в упрек поставить компании. Правда юр. адрес в квартире, куда лучше, чем в месте массовой регистрации ООО, где их никогда не было и концов не найти.
Ну те за вами реально косяк был, хотя и не совсем такой, который считали налоговики?
Да это даже не косяк. Пока не пришло время ставить прибор на корабль — он заказчикам не нужен. А когда нужен — то нужен не в офисе, а на судоремонтном заводе. Так что проще приборы напрямую на завод отправлять.
И, я Вам больше скажу, по этим ценам данный софт/железо больше никто не купит.
Спорно. Плюс-минус скачки курса доллара и комплектация. У ANSYS куча вариантов поставки. Ну вот похожая цена в 1.9 милиона, вот в 2.1 миллиона, вот 45 тысяч евро. Уже понятно, что если в договоре будет 10 миллионов — это подозрительно.
В связи с этим мой вопрос остается в силе — где общедоступные прайсы?
А зачем они нам? Мы не покупаем ANSYS. А вы, похоже путаете многое:
1) поставка от дилеров отличается от поставки от производителя. для ANSYS можно запросить пяток дилеров и выбрать наименьшую цену.
2) Отсутствие публикации прайса отличается от отсутствии прайса вообще. В первом случае прайс в долларах (почему и не публикуется) и пересчитается в рубли на день запроса. Более того, вы получите варианты цены в зависимости от опций. Во втором — вам пришлют только сумму, без всяких обоснований.
Так сговор, как я понимаю, все же был?
Не было. Там до последнего дня было непонятно, кто выиграет. На этих тендерах конкуренция такая, что бывает, что минимальная цена на 10 тысяч рублей отличается от следующей. При разбросе цен в пару миллионов — это явный намек на промышленный шпионаж.
ТЗ кто пишет? Государство или Вы?
Государство, конечно. Государство пишет ТЗ и объявляет конкурс. Мы в нем участвуем или прямо или как субподрядчики. Если в ТЗ будет покупка статанализатора — мы его купим. Но пока что таких ТЗ не было.
Я не очень уверен, что это вообще придется доказывать.
А я вообще хочу, чтобы у нас не было ситуация, когда мы должны что-то доказывать прокуратуре. Мы работать хотим, а не с прокуратурой разбираться. У нас и так бывает, что гендиректор несколько ночей подряд работает в офисе. Времени у нас нету на все эти разборки.
А других на рынке нет.
Вы можете это доказать? Статических анализаторов много В том числе есть и бесплатные.
Правда юр. адрес в квартире, куда лучше, чем в месте массовой регистрации ООО, где их никогда не было и концов не найти.
У нас не было проблем с регистрацией в бизнес-центре. Мы там уже полэтажа занимаем. Тут главное — совпадение юр.адреса с фактическим. Проверяется элементарно — пробивкой телефонного номера. В случае квартиры — это заведомо не выполняется. Ну разве что контора из одного человека.
Да это даже не косяк. Пока не пришло время ставить прибор на корабль — он заказчикам не нужен. А когда нужен — то нужен не в офисе, а на судоремонтном заводе. Так что проще приборы напрямую на завод отправлять.
Это косяк в документах тогда на мой взгляд — плохо прописано куда и когда результат необходимо поставить. Если сказано в офис — то в офис, а если сразу на судоремонтный завод, то на него.
Тут писать можно много что, в том числе и прямую поставку от дверей производителя к дверям конечного пользователя, минуя офис непосредственного заказчика (знаю, что такая схема доставки материальных объектов использовалась и о проблемах я не слышал, если она конечно в договорах прописана).
2) Отсутствие публикации прайса отличается от отсутствии прайса вообще. В первом случае прайс в долларах (почему и не публикуется) и пересчитается в рубли на день запроса. Более того, вы получите варианты цены в зависимости от опций. Во втором — вам пришлют только сумму, без всяких обоснований.
Я не списывался на тему цены с PVS, но почему Вы думаете, что у них второй вариант, и нет внутренних прайсов?
Кроме того, есть еще и вендорские скидки для конкретных клиентов о механизмах вычислений которых никто публично не расскажет (а их уровень может быть существенный и начальные цены в торгах могут уже быть частично со скидкой).
Государство, конечно.
Тут Вы меня не поняли. Государство пишет ТЗ на свой заказ, а не на инструменты, с помощью которого заказ будет исполняться. А вот на эти нужные Вам инструменты ТЗ пишете уже Вы.
У нас не было проблем с регистрацией в бизнес-центре
Бизнес-центр и место массовой регистрации это все же разные вещи.
P.S. Из параллельной приватной дискуссии с господином Jef239 я выяснил, что у них действительно есть обоснованные опасения для хорошей перестраховки, но я бы не стал распространять это мнение на весь остальной рынок, в том числе на ту его часть, где есть бюджетные деньги.
Это косяк в документах тогда на мой взгляд — плохо прописано куда и когда результат необходимо поставить.
Ну в общем это рабочая ситуация, не страшная ни для поставщика, ни для заказчика. Если у заказчика горит — можно поставить раньше, если не горит — то можно позже. А вот с точки зрения прокуратуры — это косяк. Хотя прокуратуре не должно быть особого дела до договоров двух частных фирм. Но вот попала одна из фирм под проверку и пошла волна по цепочке.
Я не списывался на тему цены с PVS, но почему Вы думаете, что у них второй вариант, и нет внутренних прайсов?
У них "Для заказа лицензии и получения информации о ценах, пожалуйста, напишите нам." То есть может быть и прайс по запросу и цена по запросу.
Но вы прочтите, что они писали на хабре
Если вы зайдете на страницу покупки PVS-Studio, то увидите, что мы убрали цену и предлагаем связаться с нами, чтобы обсудить её в индивидуальном порядке.
А это уже явно цена по запросу, без всяких прайсов.
А вот на эти нужные Вам инструменты ТЗ пишете уже Вы.
ТЗ самому себе? Юридический смысл его ничтожен. Сам себе я могу написать, что нужны испытания на 2 недели в Сочи в пик туристского сезона. Или в Крыму — тоже в пик. Кстати, и там и там испытывали. Правда далеко не в сезон. И не исходя из нашего ТЗ, а по месту нахождения заказчика.
Бизнес-центр и место массовой регистрации это все же разные вещи.
ну один из сайтов нас причислил к фирмам-однодневкам на основе именно регистрации по бизнес-центру + учредители-физлица.
P.S. Из параллельной приватной дискуссии с господином Jef239 я выяснил, что у них действительно есть обоснованные опасения для хорошей перестраховки, но я бы не стал распространять это мнение на весь остальной рынок, в том числе на ту его часть, где есть бюджетные деньги.
Я даже поясню. Есть такая ниша для малых фирм — спасать горящие проекты. То есть большая контора взяла заказ, деньги проела, но ничего не сделала. И на этом этапе они обращаются к нам с просьбой сделать хоть что-то на те деньги, что остались. Мы делаем, причем ни в каких пресс-релизах нас при этом не указывают. Считается, что наш заказчик сделал все сам. :-) Нам это не мешает, внутри отрасли все равно известно, кто что может, а кто ничего не может.
Но в этих условиях шанс уголовного дела у заказчиков — высокий. Ибо если фирма проела деньги с одного контракта — то это обычно система и таких случаев много.
А на весь остальной рынок — я не распространяю. Если у фирмы есть свой юротдел (или просто свой хороший юрист) — она вполне может не перестраховываться, Но лично мы — лучше 5 раз перестрахуемся, чем под прокурорскую проверку попадем.
Ну в общем это рабочая ситуация, не страшная ни для поставщика, ни для заказчика.
Сейчас контроль за расходованием бюджетных средств растет и нарушение сроков поставки или поставка не туда — это стало серьезным косяком. Да даже требования к формулировкам предмета договора ужесточили иначе казначейство просто ничего не оплатит.
А исправить его как минимум в указании места поставки не сложно. С точки зрения срока, если фактически нужно предоставить результат после даты Х, но только когда заказчик скажет вези, думаю тоже можно что-то придумать, но надо юристов подключать.
А это уже явно цена по запросу, без всяких прайсов.
Или индивидуальные скидки от прайса. Я не знаю, как различить эти две ситуации, но они обе возможны.
Сейчас контроль за расходованием бюджетных средств растет
Это была поставка одной коммерческой фирмы другой. Просто заказчик попал под уголовное дело.
если фактически нужно предоставить результат после даты Х, но только когда заказчик скажет вези, думаю тоже можно что-то придумать,
Это называется передача на ответственное хранение. На первом тендере сделали железо, сдали его. Следующий тендер — по софту. Так что железо у нас. Как софт-то писать, если отлаживаться не на чем?
Или индивидуальные скидки от прайса. Я не знаю, как различить эти две ситуации, но они обе возможны.
Это было бы классно, но я пессимист и в хорошее не верю. В то, что ценник задерут — верю, а в скидки — нет.
Вы сможете доказать прокуратуре, что при наличии бесплатного CppCheck надо платить за PVS-studio? Есть официальное государственные документы, что PVS-studio лучше? Именно официальные, а не просто мнения специалистов.
Никаких официальных документов доказывающих что брендовый сервер лучше самосбора — не существует, но это никому не мешает.
Выбор ПО для внедрения делается на основании ТЗ, и если там будет пункт в котором говориться что ПО должно обладать русскоязычной поддержкой то про CppCheck можно забыть.
Далее, насколько я помню рекомендации по закупкам ПО для госкомпаний выглядят примерно следующим образом Российский вендор > Свободное ПО > Зарубежрый вендор.
Да и вообще, если сомнения продолжают оставаться, всегда можно заказать написание НИР в котором вам напишут что продукт A лучше чем продукты B и C с формулами и таблицами. А в случае чего, вы всегда можете сказать проверяющей организации что НИР просто даёт рекомендации и закупить можно в общем-то любой из продуктов…
Никаких официальных документов доказывающих что брендовый сервер лучше самосбора — не существует,
Ну как минимум есть ГОСТ 27.002-89, ГОСТ 53480-2009 и ГОСТ 27.402-95
На их основе легко доказать, что для конкретных примений самосбор не проходит. Точнее проходит — но после длительных испытаний на надежность по ГОСТ.
Выбор ПО для внедрения делается на основании ТЗ, и если там будет пункт в котором говориться что ПО должно обладать русскоязычной поддержкой
Нету у нас ТЗ, по которым мы обязаны покупать статанализатор. А русскоязычную поддержку к свободному ПО — вполне можно купить.
Да и вообще, если сомнения продолжают оставаться, всегда можно заказать написание НИР
Вы понимаете уровень геморроя для компании из
А получится «если открыть прибор и влезть через диагностические разъемы, то испортив командные файлы можно много чего наворочать». Ну или «если задать вот такую комбинацию дефайнов при компиляции, то компилировать не будет». Ну или «ой, у вас тут бесконечный цикл», Угу, программного выключения железки нету, треды вертятся в бесконечных циклах. Это вот результаты CPPcheck.
Единственное, что могу обещать — честно опубликовать результаты
Вы понимаете уровень геморроя для компании из 7 ой 9 человек????
Ну вот мы и выяснили что устанавливать лифт в двухэтажном частном доме это дорого и не имеет смысла…
Но это же не значит что такая вещь как лифт никому не нужна за такую цену…
Выгодна может быть разовая проверка. Или двухразовая — с выдачей сертификата, что ошибок не обнаружено. Потому что одно дело — надпись на сайте, что исходный код проверяется статическим анализатором, а другое — сертификат, что исходный код прошел проверку без замечаний. Копию сертификат а мы можем приложить к договору. А само наличие инструмента — к договору не прикладывается.
Вы сами себе противоречите.
В одном комментарии вы пишете, что цена лицензии за 1 рабочее место должна зависеть от уровня оплаты программистов, в другом — что цена должна быть фиксированной.
Определитесь уже.
Цена должна быть известной, а не считаться от фонаря по внешнему виду заказчиков.
Не так важно, от каких факторов зависит цена. Важно, что факторы эти должны быть известны. И они не должны противоречить конституции. А тайное формирование цены — это первый признак незаконной обналички и откатов.
А фиксирована цена или нет — это уже личное дело авторов. Фиксировать тоже можно «на разработчика», на «100 тысяч строк кода», на «1 проект»… Не в этом же дело!
Ориентировочно для статанализатора он равен недельной зарплате программиста на год лицензии. Если цена меньше — покупать выгодно. Если больше — не выгодно.
Т.е. вы хотите сказать что цена для команд из 5, 50, 500 разработчиков должна быть фиксированной и одинаковой?
Но это ориентировочный анализ.
Видимо вас сбило то, что я имел ввиду лицензию на работника, а не на компанию.
Под ФОП — понимается не запрлата одного человека, а группы людей. Т.е. ФОП на 50 разработчиков ~ в 10 раз больше, чем ФОП на 5 разработчиков.
Разумная цена — недельный ФОП программистов за годовую лицензию. Больше — уже невыгодно.
Зря заминусовали. ИМХО недельный ФОП — это уже за гранью. Вот недавно пример был. Очередной этап обеления. Выбираем что покупать. Visual Assist или Collaborator. И считали именно так, сколько времени экономит тот или иной инструмент с учётом его стоимости. Т.е. если PVS экономит всего неделю (из 50) времени в году (что хороший показатель на самом деле), то почему мы должны будем купить его по цене скажем 30 т.р за копию, если можно за 8 т.р. купить Visual Assist, который позволит экономить ту же неделю в год, или за 10 т.р. купить Collaborator, который позволит экономить 1.5 недели в год. Это притом, что ни VS ни Collaborator не превратяться в тыкву через год. Хотя цена на продление уже более чем божеская будет потом (30/5=6 т.р. в этом примере).
Особенно в Enterprize, где цена простоя сети магазинов высока. Правда и ошибки, приводящие к неработоспособности всей сети тоже редки. И не факт, что находятся PVS-studio.
Мы в своей программе, требующей высокой надежности, вообще решили, что ошибки в программе всегда будут. И добились надежности (365*24 с 2002 года по сей день) совсем иным путем. При этом в коде осталось ориентировочно от 250 до 500 ошибок (от опечаток до багов размером с упитанную полярную лисицу).
Сколько он может сэкономить на самом деле — непонятно.
Я вот уже несколько лет пользуюсь триалкой. И моё мнение сейчас такое, что это сильно от человека зависит. Например, мне он точно за год использования инкрементального анализа больше дня за прошлый год не съэкономил. Думаю, это у меня привычка, писать «чистый» код есть. Но вот есть чел, он периодически фигню коммитит. Вот ему бы такое неделю съэкономило бы времени. Другой человек, тоже практически говорит, что нет срабатываний на инкременталке, но он тоже сразу хороший код пишет. С другой стороны, одна «паршивая овца», может время много всем попортить, т.е. пропустит какой баг, он у тестирования вылезет, пока бюрократическая машина закрутится, не факт, что именно этот чел править будет, и т.д. Т.е. я думаю, что есть разработчики, которым если дать такой инструмент, то компании это реально полторы-две недели в год времени съэкономит. Маленьким компаниям проще, тут все навиду, обычно уровень разработчиков повыше, чем в больших монстрах, с кучей студентов. Поэтому я и говорю про среднюю неделю на разработчика, и не думаю, что в маленьких компаниях эта цифра будет больше.
Но вот есть чел, он периодически фигню коммитит.
А эта фигня с -Wall -Wextra (ну или иным вариантом полностью включенных варнингов и хинтов) чисто компилируется? Просто те, кто комитит фигню, часто забивают болт на предупреждения.
Бывают ошибки, которые ловятся неделями и даже годами. Иногда это неуловимый Джо, а иногда — и впрямь не поймать. Одна из любимых- pow(2,N) вместо 1U<<N. На intel оно работало, ибо 96 бит в long double. а вот на ARM вместо 2*31 выдавала на 1 меньше.
Но поймает ли PVS-studio что-то серьезное — непонятно. Суд по опубликованному — никаких серьезных багов он не ловит. Да, находятся вещи неприятные, но не ужас-ужас-ужас.
А триалкой российских производителей постоянно пользоваться — не комильфо. Западных — запросто, а вот российских как-то западло мне.
А эта фигня с -Wall -Wextra (ну или иным вариантом полностью включенных варнингов и хинтов) чисто компилируется? Просто те, кто комитит фигню, часто забивают болт на предупреждения.
Конечно не чисто. Но к сожалению у нас даже на -w3 чисто в единичных случаях. Даже ворнинги w1 ещё остались. Вообще есть проекты (рабочие, не заброшенные) с больше 300 ворнингов на w3.
Но поймает ли PVS-studio что-то серьезное — непонятно. Суд по опубликованному — никаких серьезных багов он не ловит. Да, находятся вещи неприятные, но не ужас-ужас-ужас.
В принципе, находит. Т.е. это не бесполезный инструмент. Но ужас-ужас больше шансов найти при первой проверке многолетнего проекта. Так вот, чтобы в моём новом коде ужас-ужас находился на инкременталке, даже и не вспомню. Хотя, свеже-добавленые баги от коллег периодически находит, и даже ужас-ужас встречается.
А триалкой российских производителей постоянно пользоваться — не комильфо. Западных — запросто, а вот российских как-то западло мне.
Постоянно пользоваться на самом деле не хочется, а то вот меня уже Андрей Карпов в почте обвинил в том, что я пользуюсь крякнутой версией, потому что когда я рапортовал им багу про ложное срабатывание, там не было комментариев «Dear PVS...». Да и поддержать хочется российского производителя. Поэтому я и пытаюсь уже сколько времени выбить денег на коммерческую версию у руководства. Хотя чувствую, что с 330 т.р за 9 человек многовато будет, такое никто не одобрит, походу придётся и дальше на триалке сидеть :-(…
Конечно не чисто.
Ну тогда ему и PVS-studio не поможет. Просто внимания обращать не будет.
В принципе, находит.
А примерная годовая экономия времени на поиск багов какая?
Постоянно пользоваться на самом деле не хочется,
Ну вот и мне не хочется… По тем же соображениям.
Ну тогда ему и PVS-studio не поможет. Просто внимания обращать не будет.
Здесь вся надежда, что можно будет таких людей обязать, чтобы в коде не было новых ворнингов анализатора 1-го уровня, хотя бы.
А примерная годовая экономия времени на поиск багов какая?
Я уже написал выше, что ИМХО, это сильно зависит от человека. Тем, кто пишет быстро и грязно, а потом большую часть времени отлавливает баги, это реально может помочь. Мне вот в режиме инкременталки не часто помогает.
Тогда небольшие организации смогут использовать ваш продукт «раз от разу» не переплачивая.
Судя по этому https://habrahabr.ru/company/pvs-studio/blog/316484/#comment_9938592 комментарию, если вы 1 раз добавили строчки в файл и проверили бесплатной версией, эти строчки должны оставаться как GPL. То есть если вы их удалили потом, это будет «лицензия не подходит для данного проекта», но вы использовали её.
Вот только я затрудняюсь оценить это со стороны закона, в отличие от GPL, которая законна (по крайней мере в США точно).
Andrey2008, у меня 2 вопроса:
1. FREE лицензия позволяет использовать PVS-Studio без каких-либо ограничений в ее функциональности, или же разница с коммерческим вариантом есть (предположим, анализатор пропускает какие-то вещи и т.д.)?
2. Когда планируете начать поддерживать VS 2017.
PS: И вопрос из любопытства: Вы сами пишете англоязычные варианты своих статей? Просто интересно.
К тому же, формулировка комментария очень странная. Можно подумать, что люди отправляют свои исходники на какой-то конкурс, по результатам которого лучший проект будет проверен PVS. Лучше бы написали просто, без кривляний: «This project was checked with free version of PVS-Studio».
почему все деньги за все дерут?
// PVS-Studio Static Code Analyzer for C, C++ and C#: http://www.viva64.com
Вот это фрагмент сомнительный. Выглядит так, будто бы исходный код является частью проекта PVS-Studio.
Хотя можно было бы написать что-то вроде этого, (хотя можно на выбор): "// We are using PVS-Studio Static code Analyzer for C, C++ and C#: ..., try it yourself!", "// This project is debugging with PVS-Studio Static code Analyzer for C, C++ and C#: ...", и т.п. Хотя, можно и не обращать внимания на эту надпись, ведь теперь PVS нацелен в основном на большой бизнес, а там дополнительные подписи в коде совсем неприемлемы, да и у них денег всегда достаточно, чтобы купить даже дешевую лицензию (только маленькие компании с ограниченным финансированием не могут себе позволить даже лицензию по цене как на одного человека). Бизнес даже если и пользуются бесплатным и свободным софтом, иногда крайне нуждается в наличии официальной поддержки производителя, чтобы можно было на кого свалить за убытки и чтобы не тратить время и деньги на собственной поддержке дополнительных проектов и либ, чтобы просто позвонить, задать любой тупой вопрос или чтобы тем побыстрее исправили баги.
set
{
if (_value == value)
{
return;
}
OnPropertyChanged("Value");
_value = value;
}
Мне Австрийский друг как раз слил официальную статью на английском (которую я быстро переключил на русский) как раз про это. Скажу, что это очень интересный сюрприз!
Опробовал его некоторое время назад на Linux, чего я долго ждал. Это пока был недельный триал, и как раз попробовал его в деле, и очен хорошо работает из под Qt Creator! Конечно много работы в коде (редактор уровней придётся переписать целиком, чтобы позже можно было добавить полноценную поддержку кооперативного редактирования через сеть). Огромное спасибо за такую возможность!
(Немного подробнее: мои проекты все писаны под MinGW, GCC и CLang и они не совместимы почти с ни одной MSVC (хотя возможно с 2015-й условно совместим, остальное всё либо забаговано, либо имеют отсталую поддержку C++11 и не имеют даже набросков C++14, которые уже были в MinGW, GCC (аж 4.8/4.9-х версий) и CLang на момент VisualStudio 2012/2013), тем более даже на винде предпочитаю Qt Creator, который по мне более дружелюбный и гибкий, через него меньше телодвижений, чтобы прыгать от функции к функции, встроенная возможность рефакторинга, которая в студиях отсутствует (хотя, исправляется плагином VisualAssist, но он в разы медленее чем это через Qt Creator, что чувтсвуется на больших проектах), а MinGW за то, что он быстрее чем MSVC получает поддержку всех современных стандартов C++ и весит в разы легче, и даже за собственный набор библиотек, не требующий доустановки msvcr-ы).
int ToInt(const float val)
{
return static_cast<int>(val > 0 ? val + 0.5 : val - 0.5);
}
double floating = ....;
long integer = static_cast<long>(std::round(floating));
И он как раз выдавал мне предупреждение здесь. Уже позже я скопировал код из Qt-шного qRound и сделал множество функций под разные unsigned/signed short, long, long long, и т.п., потому что штатный только под int, и получил вот такое:
inline long lRound(double d)
{
return d >= 0.0 ? static_cast<long>(d + 0.5) :
static_cast<long>(d - static_cast<double>(static_cast<long>(d - 1))
+ 0.5) + static_cast<long>(d - 1);
}
Анализатором проверить тут увы, не успел, дела, да и триал просрочился.
Постепенно бесплатный вариант лицензирования набирает популярность, и наша команда всё больше времени тратит, оказывая поддержку бесплатным пользователем. При этом многие вопросы повторяются, поэтому мы считаем целесообразным оказывать в дельнейшем поддержку, отвечая на вопросы на сайте StackOverflow.
Общение через сайт StackOverflow сократит объем переписки, и позволит нам часто отвечать на вопросы, просто давая ссылку на уже обсужденный вопрос по данной теме. Более того, многие вопросы просто не будут заданы, так как пользователи смогут найти готовые ответы на StackOverflow самостоятельно, и им не потребуется ожидать нашего ответа в почте.
Итак, всех кто использует бесплатную версию PVS-Studio просим задавать нам вопросы на сайте StackOverflow. Чтобы ваш вопрос не остался незамеченным, используйте тег «pvs-studio».
Наши платные клиенты по-прежнему будут получать поддержку приватно через почту. Впрочем, если кто-то из клиентов будет задавать вопросы через StackOverflow, мы не возражаем.
См. также статью "Поддержка пользователей, использующих бесплатную лицензию PVS-Studio теперь осуществляется на сайте StackOverflow".
Статья: "Бесплатные варианты лицензирования PVS-Studio".
Как использовать PVS-Studio бесплатно