 Привет, Хаброжители! Пол и Харви Дейтелы предлагают по-новому взглянуть на Python и использовать уникальный подход, чтобы быстро решить проблемы, стоящие перед современными айтишниками.
Привет, Хаброжители! Пол и Харви Дейтелы предлагают по-новому взглянуть на Python и использовать уникальный подход, чтобы быстро решить проблемы, стоящие перед современными айтишниками. В вашем распоряжении более пятисот реальных задач — от фрагментов до 40 больших сценариев и примеров с полноценной реализацией. IPython с Jupyter Notebooks позволят быстро освоить современные идиомы программирования Python. Главы 1–5 и фрагменты глав 6–7 сделают понятными примеры решения задач искусственного интеллекта из глав 11–16. Вы познакомитесь с обработкой естественного языка, анализом эмоций в Twitter, когнитивными вычислениями IBM Watson, машинным обучением с учителем в задачах классификации и регрессии, машинным обучением без учителя в задачах кластеризации, распознавания образов с глубоким обучением и сверточными нейронными сетями, рекуррентными нейронными сетями, большими данными с Hadoop, Spark и NoSQL, IoT и многим другим. Вы поработаете (напрямую или косвенно) с облачными сервисами, включая Twitter, Google Translate, IBM Watson, Microsoft Azure, OpenMapQuest, PubNub и др.
9.12.2. Чтение CSV-файлов в коллекции DataFrame библиотеки pandas
В разделах «Введение в data science» предыдущих двух глав были представлены основы работы с pandas. Теперь продемонстрируем средства pandas для загрузки файлов в формате CSV, а затем выполним базовые операции анализа данных.
Наборы данных
В практических примерах data science будут использованы различные бесплатные и открытые наборы данных для демонстрации концепций машинного обучения и обработки естественного языка. В интернете доступно огромное количество разнообразных бесплатных наборов данных. Популярный репозиторий Rdatasets содержит ссылки на более чем 1100 бесплатных наборов данных в формате CSV. Эти наборы изначально поставлялись с языком программирования R, чтобы упростить изучение и разработку статистических программ, тем не менее, они не связаны с языком R. Сейчас эти наборы данных доступны на GitHub по адресу:
https://vincentarelbundock.github.io/Rdatasets/datasets.html
Этот репозиторий настолько популярен, что существует модуль pydataset, предназначенный специально для обращения к Rdatasets. За инструкциями по установке pydataset и обращению к наборам данных обращайтесь по адресу:
https://github.com/iamaziz/PyDataset
Другой большой источник наборов данных:
https://github.com/awesomedata/awesome-public-datasets
Одним из часто используемых наборов данных машинного обучения для начинающих является набор данных катастрофы «Титаника», в котором перечислены все пассажиры и указано, выжили ли они, когда «Титаник» столкнулся с айсбергом и затонул 14–15 апреля 1912 года. Мы воспользуемся этим набором, чтобы показать, как загрузить набор данных, просмотреть его данные и вывести характеристики описательной статистики. Другие популярные наборы данных будут исследованы в главах с примерами data science позднее в этой книге.
Работа с локальными CSV-файлами
Для загрузки набора данных CSV в DataFrame можно воспользоваться функцией read_csv библиотеки pandas. Следующий фрагмент загружает и выводит CSV-файл accounts.csv, который был создан ранее в этой главе:
In [1]: import pandas as pd
In [2]: df = pd.read_csv('accounts.csv',
...: names=['account', 'name', 'balance'])
...:
In [3]: df
Out[3]:
account name balance
0 100 Jones 24.98
1 200 Doe 345.67
2 300 White 0.00
3 400 Stone -42.16
4 500 Rich 224.62Аргумент names задает имена столбцов DataFrame. Без этого аргумента read_csv считает, что первая строка CSV-файла содержит разделенный запятыми список имен столбцов.
Чтобы сохранить данные DataFrame в файле формата CSV, вызовите метод to_csv коллекции DataFrame:
In [4]: df.to_csv('accounts_from_dataframe.csv', index=False)Ключевой аргумент index=False означает, что имена строк (0–4 в левой части вывода DataFrame в фрагменте [3]) не должны записываться в файл. Первая строка полученного файла содержит имена столбцов:
account,name,balance
100,Jones,24.98
200,Doe,345.67
300,White,0.0
400,Stone,-42.16
500,Rich,224.629.12.3. Чтение набора данных катастрофы «Титаника»
Набор данных катастрофы «Титаника» принадлежит к числу самых популярных наборов данных машинного обучения и доступен во многих форматах, включая CSV.
Загрузка набора данных катастрофы «Титаника» по URL-адресу
Если у вас имеется URL-адрес, представляющий набор данных в формате CSV, то вы можете загрузить его в DataFrame функцией read_csv — допустим, с GitHub:
In [1]: import pandas as pd
In [2]: titanic = pd.read_csv('https://vincentarelbundock.github.io/' +
...: 'Rdatasets/csv/carData/TitanicSurvival.csv')
...:Просмотр некоторых строк набора данных катастрофы «Титаника»
Набор данных содержит свыше 1300 строк, каждая строка представляет одного пассажира. По данным «Википедии», на борту было приблизительно 1317 пассажиров, а 815 из них погибли1. Для больших наборов данных при выводе DataFrame показываются только первые 30 строк, потом идет многоточие «…» и последние 30 строк. Для экономии места просмотрим первые и последние пять строк при помощи методов head и tail коллекции DataFrame. Оба метода по умолчанию возвращают пять строк, но число выводимых строк можно передать в аргументе:
In [3]: pd.set_option('precision', 2) # Формат для значений с плавающей точкой
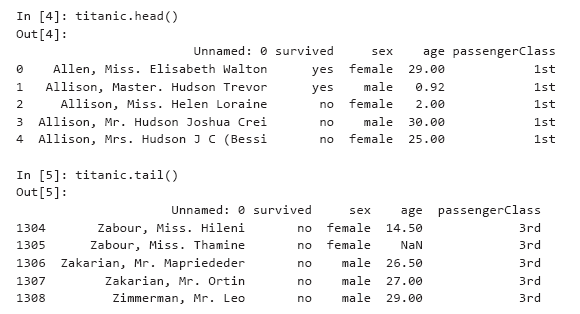
Обратите внимание: pandas регулирует ширину каждого столбца на основании самого широкого значения в столбце или имени столбца (в зависимости от того, какое имеет большую ширину); в столбце age строки 1305 стоит значение NaN — признак отсутствующего значения в наборе данных.
Настройка имен столбцов
Имя первого столбца в наборе данных выглядит довольно странно ('Unnamed: 0'). Эту проблему можно решить настройкой имен столбцов. Заменим 'Unnamed: 0' на 'name' и сократим 'passengerClass' до 'class':


9.12.4. Простой анализ данных на примере набора данных катастрофы «Титаника»
Теперь воспользуемся pandas для проведения простого анализа данных на примере некоторых характеристик описательной статистики. При вызове describe для коллекции DataFrame, содержащей как числовые, так и нечисловые столбцы, describe вычисляет статистические характеристики только для числовых столбцов — в данном случае только для столбца age:
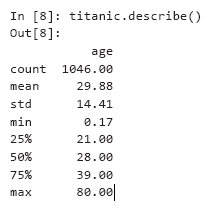
Обратите внимание на расхождения в значении count (1046) и количества строк данных в наборе данных (1309 — при вызове tail индекс последней строки был равен 1308). Только 1046 строк данных (значение count) содержали значение age. Остальные результаты отсутствовали и были помечены NaN, как в строке 1305. При выполнении вычислений библиотека pandas по умолчанию игнорирует отсутствующие данные (NaN). Для 1046 пассажиров с действительным значением age средний возраст (математическое ожидание) составил 29.88 года. Самому молодому пассажиру (min) было всего два месяца (0.17 * 12 дает 2.04), а самому старому (max) — 80 лет. Медианный возраст был равен 28 (обозначается 50-процентным квартилем). 25-процентный квартиль описывает медианный возраст в первой половине пассажиров (ранжированных по возрасту), а 75-процентный квартиль — медиану во второй половине пассажиров.
Допустим, вы хотите вычислить статистику о выживших пассажирах. Мы можем сравнить столбец survived со значением 'yes', чтобы получить новую коллекцию Series со значениями True/False, а затем использовать describe для описания результатов:
In [9]: (titanic.survived == 'yes').describe()
Out[9]:
count 1309
unique 2
top False
freq 809
Name: survived, dtype: objectДля нечисловых данных describe выводит различные характеристики описательной статистики:
- count — общее количество элементов в результате;
- unique — количество уникальных значений (2) в результате — True (пассажир выжил) или False (пассажир погиб);
- top — значение, чаще всего встречающееся в результате;
- freq — количество вхождений значения top.
9.12.5. Гистограмма возраста пассажиров
Визуализация — хороший способ поближе познакомиться с данными. Pandas содержит много встроенных средств визуализации, реализованных на базе Matplotlib. Чтобы использовать их, сначала включите поддержку Matplotlib в IPython:
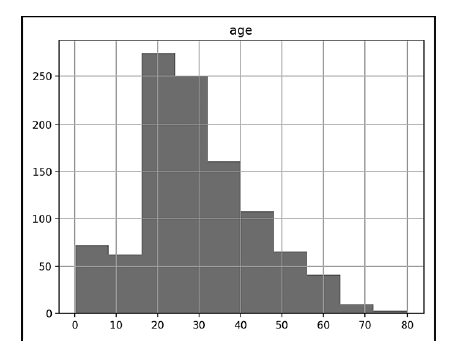
In [10]: %matplotlibГистограмма наглядно показывает распределение числовых данных по диапазону значений. Метод hist коллекции DataFrame автоматически анализирует данные каждого числового столбца и строит соответствующую гистограмму. Чтобы просмотреть гистограммы по каждому числовому столбцу данных, вызовите hist для своей коллекции DataFrame:
In [11]: histogram = titanic.hist()Набор данных катастрофы «Титаника» содержит только один числовой столбец данных, поэтому на диаграмме показана гистограмма для распределения возрастов. Для наборов данных с несколькими числовыми столбцами hist создает отдельную гистограмму для каждого числового столбца.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Python
По факту оплаты бумажной версии книги (дата выхода — 5 июня) на e-mail высылается электронная книга.
