Comments 33
Да, Parallels Cloud Storage — это рулез в быстром и надежном хранении данных :) Спасибо!
А есть ли в планах коммерческая лицензия без првиязки к PCS? Чтобы, например, к OpenVZ можно было прицепить или просто к машине смонтировать.
Было бы круто, если бы Вы еще про ploop написали, без него картина не получается полной — ведь это дам компонента одной системы :)
Вам не кажется, что тестовый файл в 16 Gb на одну ноду слишком мал? Учитывая количество оперативной памяти даже в современных десктопах (8Gb ОЗУ уже норма, 16 тоже не редкость), не говоря уже про сервера. C такими маленькими тестовыми файлами на ноду в итоге вы тестируете производительность ОЗУ в каждой ноде кластера.
Так же не понятен выбор времени теста в одну минуту. Я думаю гораздо интереснее как решение себя ведет под продолжительной интенсивной нагрузкой. Когда кэши насыщаются или просто уже не могут справляться с потоком данных и на сцену выходит она самая :) — производительность шпиндельных дисков.
По поводу энтерпрайз СХД — там давно многие производители пришли к использованию именно софтовых Raid и дисковых пулов. Циклы разработки короче, чем для железячных контроллеров. Разработчиков найти/вырастить проще, баги править удобнее и опять же быстрее. Нет узкого места в виде железных контроллеров. Платформа x86 на данный момент победила, соответственно меняем железо на новое поколение и все. Софт можно использовать старый, а производительность уже выросла. Искусственные ограничения типа: «новая прошивка» не устанавливается на «старое» железо и т.п. сейчас не рассматриваем.
Мне всегда интересно в подобных кластерных решениях в какой момент приложение или VM получает ack о том что запрошенная запись данных произведена. Когда нода получила блок данных в свой кэш? Тогда что будет если в этот момент нода «умрет»? Если ack идет приложению или VM когда блок данных скопирован на другие ноды, то мне кажется проблемой могут стать каналы в 1Gbit/s между нодами и время задержки в самой сети Ethernet между ними. Особенно если кластер физически подключается в общую сеть с потребителями (пользователями или VM).
Единственное с чем полностью и безоговорочно согласен :), так это с тем что файл для теста забитый «мусорными» данными нужно генерировать заранее.
Так же не понятен выбор времени теста в одну минуту. Я думаю гораздо интереснее как решение себя ведет под продолжительной интенсивной нагрузкой. Когда кэши насыщаются или просто уже не могут справляться с потоком данных и на сцену выходит она самая :) — производительность шпиндельных дисков.
По поводу энтерпрайз СХД — там давно многие производители пришли к использованию именно софтовых Raid и дисковых пулов. Циклы разработки короче, чем для железячных контроллеров. Разработчиков найти/вырастить проще, баги править удобнее и опять же быстрее. Нет узкого места в виде железных контроллеров. Платформа x86 на данный момент победила, соответственно меняем железо на новое поколение и все. Софт можно использовать старый, а производительность уже выросла. Искусственные ограничения типа: «новая прошивка» не устанавливается на «старое» железо и т.п. сейчас не рассматриваем.
Мне всегда интересно в подобных кластерных решениях в какой момент приложение или VM получает ack о том что запрошенная запись данных произведена. Когда нода получила блок данных в свой кэш? Тогда что будет если в этот момент нода «умрет»? Если ack идет приложению или VM когда блок данных скопирован на другие ноды, то мне кажется проблемой могут стать каналы в 1Gbit/s между нодами и время задержки в самой сети Ethernet между ними. Особенно если кластер физически подключается в общую сеть с потребителями (пользователями или VM).
Единственное с чем полностью и безоговорочно согласен :), так это с тем что файл для теста забитый «мусорными» данными нужно генерировать заранее.
Консистентность будет подробнее описана в следующем посте, так как это отдельная глубокая тема: как её достичь и сохранить производительность. Забегая вперед, скажу, что PStorage возвращает ack, когда записал все три копии на разные машины.
Кстати, у нас даже специальный процесс тестирования для этого построен, когда пишем данные и зовём sync, затем вырубаем всю или часть системы, и проверяем, что данные действительно записались.
16ГБ — это примерный объем данных, с которыми работают виртуальные машины на ноде.
Я понимаю ваши опасения насчет OС-кешей, но эти кеши легко отключаемы почти в любой I/O тестилке. И по-моему, все уже меряют aio или directio. Кстати, в приведенных результатах OS writeback в принципе не мог работать ни на каком уровне, еще и потому, что в операциях записи после каждого write() зовелся fdatasync(). А sync в PStorage гарантирует, что данные реально записаны на дисках на разных машинах.
Время теста должно быть продолжительным — сколько хотите. Просто в регулярном тестировании сложно ждать бесконечность (что было бы идеальным), чтобы промерять все сценарии.
Кстати, у нас даже специальный процесс тестирования для этого построен, когда пишем данные и зовём sync, затем вырубаем всю или часть системы, и проверяем, что данные действительно записались.
16ГБ — это примерный объем данных, с которыми работают виртуальные машины на ноде.
Я понимаю ваши опасения насчет OС-кешей, но эти кеши легко отключаемы почти в любой I/O тестилке. И по-моему, все уже меряют aio или directio. Кстати, в приведенных результатах OS writeback в принципе не мог работать ни на каком уровне, еще и потому, что в операциях записи после каждого write() зовелся fdatasync(). А sync в PStorage гарантирует, что данные реально записаны на дисках на разных машинах.
Время теста должно быть продолжительным — сколько хотите. Просто в регулярном тестировании сложно ждать бесконечность (что было бы идеальным), чтобы промерять все сценарии.
Про недостижимые идеалы речи не идет. Тест от получаса до пары часов вполне информативен. Тестирование с отключением кэша или с direct io не интерестно, так как совсем уж далеко от жизни получается. Все равно кэши использоваться будут, поэтому и интерестны ситуации когда они используется, но не справляется со всей нагрузкой.
По поводу 16Gb, у вас же соотношение не одна VM на одну ноду обычно? Значит и тестировать корректнее или несколько нагружаемых файлов по 16Gb на ноду, или один большой файл размером 16Gb*X VM.
Ну и уж если совсем «придираться» :-) нагрузка блоками по 4K не совсем типична для VM. Даже транзакционные базы данных оперируют страницами по 8K. Другие приложения обычно более крупными блоками оперируют. Кроме того не плохо бы понимать соотношение операци чтения и операций записи в тестируемом профиле нагрузки.
По поводу 16Gb, у вас же соотношение не одна VM на одну ноду обычно? Значит и тестировать корректнее или несколько нагружаемых файлов по 16Gb на ноду, или один большой файл размером 16Gb*X VM.
Ну и уж если совсем «придираться» :-) нагрузка блоками по 4K не совсем типична для VM. Даже транзакционные базы данных оперируют страницами по 8K. Другие приложения обычно более крупными блоками оперируют. Кроме того не плохо бы понимать соотношение операци чтения и операций записи в тестируемом профиле нагрузки.
16GB это средний working set на VM с ноды. Он разделен на 16 файлов по 1GB (1GB горячих данных на VM), чтобы каждый поток грузил свой файл. Один нагрузочный поток — VM.
4K — это минимальная дискретизация данных, она показывает IOPS системы. Тесты с большим блоком показывает пропускную способность.
8K тоже мереть можно, если для вашей системы актуально. Вообще стоит мереть именно актуальную нагрузку для конкретной системы. Идеально — вообще снять дамп IO запросов c рабочей системы и прогнать. :)
Обычно у VM гораздо больше записи чем чтения, больше случайного I/O чем последовательного. И обычно случайное I/O это запросы до 32K.
4K — это минимальная дискретизация данных, она показывает IOPS системы. Тесты с большим блоком показывает пропускную способность.
8K тоже мереть можно, если для вашей системы актуально. Вообще стоит мереть именно актуальную нагрузку для конкретной системы. Идеально — вообще снять дамп IO запросов c рабочей системы и прогнать. :)
Обычно у VM гораздо больше записи чем чтения, больше случайного I/O чем последовательного. И обычно случайное I/O это запросы до 32K.
Еще раз. Может я плохо объясняю :-). Я имел в виду что нагрузку на каждую ноду дает обычно не одна VM, а несколько. VM работает не только с одним Gb горячих даных, которые в итоге и попадают в кэш. Имеет смысл все таки тестировать бОльшие объемы даных на одну ноду. По хорошему раза в 3-5 больше чем ОЗУ ноды.
Да, можно будет попробовать и такой сценарий. К сожалению, полного сета измерений для разного объема данных не могу сейчас привести. Мы выбирали 16GB из статистики и компромисса времени работа теста, чтобы успеть измерить все сценарии. Но еще раз подчеркну, что PStorage обеспечивает строгую консистентность данных, а значит в тесте write()+fdatasync() RAM кэш не влияет.
В следующий раз по-тестируем с большим объемом данных, почему бы и нет. :)
Кстати, о кэшах. Да, тест с полностью отключенными кэшами имеет смысл. Но, ведь в реальной жизни вы ими пользуетесь! Вопрос в том работают ли они для вашей именно задачи.
В следующий раз по-тестируем с большим объемом данных, почему бы и нет. :)
Кстати, о кэшах. Да, тест с полностью отключенными кэшами имеет смысл. Но, ведь в реальной жизни вы ими пользуетесь! Вопрос в том работают ли они для вашей именно задачи.
Я как раз подводил вас к мысли, что даже синтетические тесты по возможности лучше подводить ближе к реалиям жизни. В том числе и для того что бы не создавать неоправданных завышенных ожиданий у ваших клиентов :-). В этом ракурсе как раз отключение кэша на время тестирования смысла не имеет. В моей практике были ситуации когда включенный кэш (алгоритмы кэширования) приводили к снижению производительности устройства или решения :-).
Ну и никто не отменял утверждения, что тестирование синтетическими тестами -это тестирование «сферического коня в вакууме». Все зависит от конкретных сценариев нагрузки, настроек софта и оборудования. У того же линукса есть минимум 4 интегрированных io шедулера и дефолтный не всегда бывает оптимальным выбором :-). Ну и в любом случае тесты дают пищу к размышлениям, а иногда и в прямую влияют на выбор конкретным заказчиком конкретного решения/оборудования.
Ну и никто не отменял утверждения, что тестирование синтетическими тестами -это тестирование «сферического коня в вакууме». Все зависит от конкретных сценариев нагрузки, настроек софта и оборудования. У того же линукса есть минимум 4 интегрированных io шедулера и дефолтный не всегда бывает оптимальным выбором :-). Ну и в любом случае тесты дают пищу к размышлениям, а иногда и в прямую влияют на выбор конкретным заказчиком конкретного решения/оборудования.
Я правильно понимаю, Parallels Cloud Storage это аналог Distributed File System (вроде MooseFS, Ceph, Lustre, GlusterFS и т.д)?
Да.
Только Parallels Cloud Storage архитектурно ориентирован на хранение больших файлов (>256MB), таких как образы виртуальных машин, базы данных, video, backup, log и прочее. Благодаря такой архитектуре он показывает отличную производительность. Максимальный объем одного кластера — до 8000 ТБ.
Хочу отметить, что PStorage сейчас может хранить файлы вообще любого объема (как большие так и маленькие). Но если записать миллионы-миллирды мелких(!) файлов, то производительность будет уже совсем не такой. Мелкие файлы эффективнее хранить как объекты (Object Storage), а не как файлы. Это уже будущая фича PStorage. NAS сценарий для мелких файлов мы обязательно покроем в следующих релизах. Пока только NAS для больших файлов…
Также PStorage гарантирует строгую консистентность данных, которая очень нужна для виртуализации и БД.
Только Parallels Cloud Storage архитектурно ориентирован на хранение больших файлов (>256MB), таких как образы виртуальных машин, базы данных, video, backup, log и прочее. Благодаря такой архитектуре он показывает отличную производительность. Максимальный объем одного кластера — до 8000 ТБ.
Хочу отметить, что PStorage сейчас может хранить файлы вообще любого объема (как большие так и маленькие). Но если записать миллионы-миллирды мелких(!) файлов, то производительность будет уже совсем не такой. Мелкие файлы эффективнее хранить как объекты (Object Storage), а не как файлы. Это уже будущая фича PStorage. NAS сценарий для мелких файлов мы обязательно покроем в следующих релизах. Пока только NAS для больших файлов…
Также PStorage гарантирует строгую консистентность данных, которая очень нужна для виртуализации и БД.
Есть уже какие-нибудь тесты и сравнения? Цифры все же интереснее описаний :-)
Могу еще одно сравнение пошарить. Это такие же тесты, на PStorage и CEPH на одинаковых нодах. Но только кластер маленький — всего 5 нод.
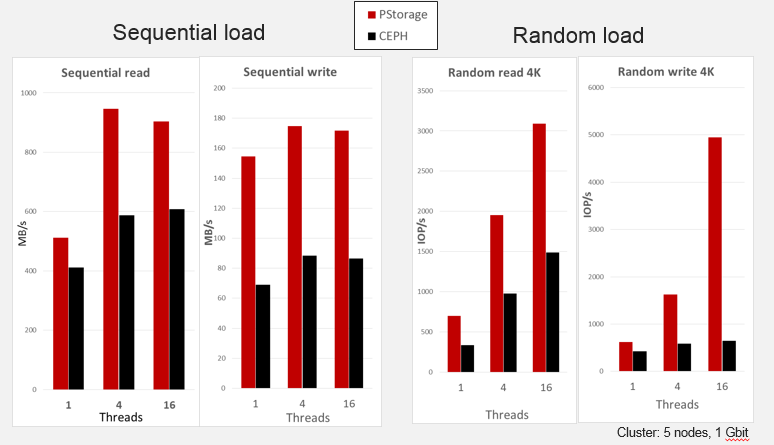

Спасибо, выглядит интересно
Конфигурация: сеть — 10Gbit (увидел ошибку в описании и решил описать подробно), 5 нод, на каждой Core i5, 16G Mem, 3 диска SATA 7200 RPM + один 100G SSD, который использовался для кеширования/журналирования (osd-journals, monitors, write-back) в CEPH и в PStorage.
OC одна — RHEL 7, в обоих случаях ;)
OC одна — RHEL 7, в обоих случаях ;)
Не понимаю, почему и в посте и у ceph на этой картинке IOPS-ы при переходе от случайного чтения к случайной записи падают в разы (107k -> 19k, 204k -> 31k, 1.5k -> 0.6k), но только у PCS на этой картинке они растут (3k -> 5k). Это не ошибка? Тогда за счет чего такой прирост?
Вы сравниваете не «яблоки с яблоками». :) В посте показана масштабируемость IOPS с ростом кластра. Сравнивается 16 поточная нагрузка на кластере из одной, 10 и 21 ноды. В комментах картинка показывает производительность с ростом нагрузки (1, 4 и 16 потоков) на кластере фиксированного размера.
Наверное, я несколько запутал… Посмотрите, пожалуйста, на графики в этом документе. Там они разделены на горизонтальную и вертикальную масштабируемость.
Наверное, вы меня не поняли. Я для простоты рассматиривал только нагрузку в 16 потоков (и все цифры привёл именно для неё). И именно для неё на этой картинке из комментария внезапно наблюдается сильный рост IOPS-ов.
В приведённом документе для 16-ти потоков также видно падение IOPS-ов в вертикальном тесте (9k -> 4k). И я не вижу там нигде роста IOPS-ов при переходе от чтения к записи (при сохранений количества нод кластера и числа потоков). Поэтому и говорю: не ошибка ли в картинке.
В приведённом документе для 16-ти потоков также видно падение IOPS-ов в вертикальном тесте (9k -> 4k). И я не вижу там нигде роста IOPS-ов при переходе от чтения к записи (при сохранений количества нод кластера и числа потоков). Поэтому и говорю: не ошибка ли в картинке.
Проверил логи. Ошибки нет. Это — предмет для исследований. Спасибо, что заметили.
В приведённом документе тесты были на PCS6 (Это Linux kernel 2.6.32) и версии PStorage 6.0.0-789, а в комментах RHEL7 (Это Linux kernel 3.10) и версии PStorage 6.0.7-32. Что-то могло в это время поменяться. Сейчас не могу сказать что именно привело к улучшению — нужно исследовать.
В приведённом документе тесты были на PCS6 (Это Linux kernel 2.6.32) и версии PStorage 6.0.0-789, а в комментах RHEL7 (Это Linux kernel 3.10) и версии PStorage 6.0.7-32. Что-то могло в это время поменяться. Сейчас не могу сказать что именно привело к улучшению — нужно исследовать.
Как это будет работать в Linux?
PStorage монтируется через FUSE. Сейчас работает на PCS и OpenVZ, с января будет на CentOS 7, RHEL 7, Ubuntu 14+.
Сейчас набегут линуксоиды и скажут, что через FUSE все будет медленно работать…
:) Я думаю, что они посмотрят на картинку с графиками в комментах. Посмотрят и оценят у кого медленнее. :)
А если серьезно. Да, в FUSE есть проблемы, мы их справили. Parallels довольно много сделала патчей в mainstream чтобы сделать FUSE быстрым.
А если серьезно. Да, в FUSE есть проблемы, мы их справили. Parallels довольно много сделала патчей в mainstream чтобы сделать FUSE быстрым.
Расскажите, пожалуйста, подробнее, за счёт какого алгоритма реализовано распределение данных по дискам.
Sign up to leave a comment.
Системы хранения данных: как выбирать?!