
Правда жизни: даже идеальный софт не убережет его разработчика от обращений клиента в службу технической поддержки. А уж если на твоем софте (речь про Parallels Plesk Panel) крутится примерно 50% всех серверов для веб-хостинга в мире, сообщения в саппорт несутся со страшной силой. Помимо сообщений об ошибках и поломках Parallels Plesk Panel (увы, бывает) в саппорт приходят вопросы по реализации кастомных конфигураций, применению нестандартных настроек и реквесты нужных клиентам фичей для их реализации в будущем. Клиенты не всегда следят за развитием продукта и часто просто не в курсе, что предмет их запроса реализован в каком-то из предыдущих апдейтов, а нестандартные настройки уже описаны в статье базы знаний (Knowledge Base) для Parallels Plesk Panel. Нужно было просто придумать, как перехватывать такие запросы «на лету» и автоматически предоставлять пользователям ответы, тем самым разгрузив саппорт под действительно сложные случаи, о которых нет упоминания в базе знаний.
В этом материале изложен опыт Parallels Plesk Service Team (есть твиттер и группа в фейсбуке) – структурного подразделения крупной компании. Но я уверен, статья под катом будет полезна стартапам, у которых уже есть готовый продукт или сервис, но нет службы технической поддержки. И в которых на вопросы пользователей отвечают продакт-менеджер либо фаундер, делая это по пути до офиса или перед сном из дома. Наша система помогла снизить число входящих тикетов на 3-5%. В масштабах Parallels Plesk Panel это тысячи человеко-часов.
Почему мы решили это сделать?
За время существования Parallels Plesk Panel команда технической поддержки и Parallels Plesk Service Team накопили базу знаний по различным проблемам и ошибкам, по выполнению каких-то нестандартных настроек, а также по тому, где и в каких апдейтах был исправлен какой-то баг или добавлена новая функциональность. Знания систематизируются и публикуются в виде статей Knowledge Base. Обновление базы знаний идет в режиме нон-стоп. Практика показывает: даже лучший поиск и самые исчерпывающие данные в базе знаний не гарантируют того, что профессиональные клиенты (в нашем случае – хостинговые компании) самостоятельно и быстро найдут способ решения возникшей у них проблемы с помощью релевантных статей из поисковой выдачи.
Как быть? Мы решили приблизить базу знаний к пользователям так, как это только возможно — интегрировать ее на разные этапы обнаружения и репортинга проблемы клиентом. В двух словах: мы должны были придумать систему (в дальнейшем для краткости будем ее называть так), которая автоматически предлагала бы клиенту варианты решения его проблемы, взятые из базы знаний на основании описания этой проблемы, которое он желает сообщить в нашу службу поддержки.
Реализация этой системы позволила бы снизить количество входящих тикетов в службу технической поддержки за счет того, что клиент самостоятельно решал бы возникающие проблемы в кратчайшие сроки на основании предложенных системой решений из базы знаний. Для хостеров, бизнес которых во много завязан на аптайме клиентских серверов, скорость «починки» проблем является критическим параметром.
С чего мы начали и почему?
Для начала мы создали базу сигнатур. Каждой конкретной статье базы знаний была присвоена одна или несколько сигнатур, максимально точно и уникально описывающая и представляющая ту или иную проблему. Например:
| Signature |
KB article |
|---|---|
1. Can't locate object method "get_msgid" via package "Mail::SpamAssassin::Bayes"2. Spamassassin training3. Train spamassassin4. Spamassassin train |
kb.parallels.com/112919 |
1. Can't connect to local MySQL server through socket2. Trying to establish test connection... ERROR 2002 (HY000) |
kb.parallels.com/114289 |
1. Error code: (2) Could not find a valid SPF record |
kb.parallels.com/6051 |
Точность и уникальность сигнатуры являются главным критерием успешности работы системы.
Например
2012-09-11 05:41:13: (mod_fastcgi.c.2746) FastCGI-stderr: PHP Warning: date(): It is not safe to rely on the system's timezone settings.очень плохая сигнатура, потому что в репорте от клиента может быть другое время
2012-09-11 05:41:13или совсем другое число
mod_fastcgi.c.2746Статья с решением этой проблемы не будет найдена. Поэтому мы старались находить компромисс между уникальностью сигнатуры и ее универсальностью.
Пример хорошей сигнатуры:
FastCGI-stderr: PHP Warning: date(): It is not safe to rely on the system's timezone settingsСовсем уж простые и односложные сигнатуры типа FastCGI-stderr или SPF record приводят к тому, что соответствующая статья базы данных будет часто предлагаться совершенно необоснованно во всех тех случаях, где эти сочетания будут упоминаться в репортах от клиентов. Точность поиска падает, кастомер мечется между несколькими статьями в KB, время решения проблемы растет, клиенты кастомера нервничают.
Итак, база сигнатур создана. Мы загрузили ее на сервера Knowledge Base, и она готова к работе. Необходим был инструмент для использования этой базы. Мы его сделали в виде отдельного сервера для API запросов под условным названием Troubleshooter.
Резонный вопрос: почему была выбрана система поиска по статичным сигнатурам, а не более продвинутая? Ответ простой – этот вариант является наиболее быстрым, а скорость работы – наиболее критичный параметр для нашей системы. Когда клиент приходит и заполняет форму тикета своим текстом, он не должен ждать более нескольких секунд, пока этот текст будет проверен системой и не загрузится страница с результатами сканирования. После «обкатки» системы мы видим, как можно улучшить качество поиска по базе сигнатур — например, с помощью использования регулярных выражений или привлечения известных семантических анализаторов для формирования более релевантных сигнатур.
Где и как система используется?
Прежде чем рассказать о механизме работы системы, необходимо описать три основных варианта ее использования:
- Самый главный и самый основной способ использования системы — это интеграция системы в форму отправки тикета на соответствующей странице сайта Parallels.
- Нами были созданы и выпущены утилиты для выполнения их в командной строке Linux или Windows. Эти утилиты по сути являются оффлайн-версией системы и представляют собой надстройки над базой сигнатур, которая выполняет поиск известных сигнатур в определенных лог-файлах Parallels Plesk Panel и на основании найденных сигнатур предлагает список соответствующих статей Knowledge Base. Более подробно эта утилита, имеющая название Spider Tool, описана в статье KB и обсуждается в соответствующем разделе форума Parallels.
- Третий вариант использования системы предназначен для службы технической поддержки при работе с тикетами.
Подробнее о том, как работает каждый из вариантов использования, я расскажу чуть ниже.
В дальнейшем мы предложим кастомерам еще три возможных варианта использования системы. Первый – мы открываем API для тех клиентов, которые желают интегрировать ее в свою инфраструктуру. Второй – онлайн-форма Troubleshooter'а, через которую любой желающий может вписать любую проблему и проанализировать ее на предмет существования соответствующей статьи в Knowledge Base, или загрузить целиком лог-файл и проанализировать его. И третий — интеграция системы непосредственно в интерфейс Parallels Plesk Panel.
Как это работает?
Рассмотрим подробнее, как работает каждый из трех существующих вариантов использования.
Вариант 1.
На специальную страницу сайта Parallels, где принимаются обращения в слубжу поддержки, приходит клиент и, пройдя все шаги, пишет текст с описанием свой проблемы. Затем он нажимает кнопку «Отправить тикет в службу поддержки». Но на самом деле тикет в саппорт не улетает немедленно. На этом этапе тема тикета (то, что вписано в поле Subject) и текст тикета анализируются системой на наличие известных сигнатур. Перед финальной отправкой тикета в службу технической поддержки клиенту предоставляются найденные на основе поиска сигнатур статьи Knowledge Base. Клиент просматривает эти статьи и решает свою проблему самостоятельно при помощи предложенных статей, не отправляя тикет в службу технической поддержки. Если никакая из предложенных ему статей не помогла или ни одной статьи не было найдено, клиент может скачать предложенный для его платформы Spider Tool и воспользоваться вариантом 2. Вариант 2 предполагает установку утилиты Spider Tool для поиска проблем по логам Plesk'а с получением списка соответствующих статей в KB для их решения. В случае, когда клиенту никакой из предложенных вариантов не помог, он окончательно отправляет тикет в службу технической поддержки с помощью кнопки Submit ticket anyway. На скриншоте можно увидеть, как это выглядит в реальности.
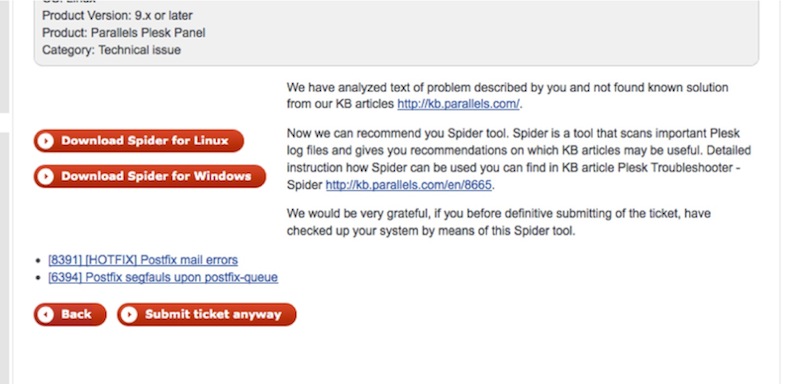
Вариант 2.
Установка и запуск утилиты Spider Tool, работающей из командной строки. Вот ее актуальная версия для Linux, а вот версия для Windows (обе версии скачиваются по клику). В дистрибутивах для обеих платформ содержатся самая свежая база сигнатур и специальный юзерспейс, который предназначен для сканирования наиболее важных лог-файлов Parallels Plesk Panel для поиска соответствий с базой сигнатур. В результате пользователь получает список найденных на его Plesk-сервере проблем со ссылками на соответствующие статьи Knowledge Base для самостоятельного решения этих проблем.
Утилита имеет множество различных опций, расширяющих возможности ее применения. Более подробно о ней можно прочесть здесь.
Вариант 3.
Как сказано в описании первого варианта, система сканирует «тело» и тему «Subject» письма клиента в службу технической поддержки только на этапе его создания. Вся последующая переписка клиента с саппортом проходит в рамках созданного тикета и может быть в любой момент просканирована инженером техподдержки вручную при помощи специальной кнопки в Request Tracker. Система проанализирует всю переписку с учетом новых появившихся деталей проблемы и предложит инженеру те статьи Knowledge Base, которые могут быть полезны ему при работе над тикетом.
Сделанная на коленке схема выглядит весьма топорно, но верно отображает механизм работы системы во всех трех вариантах использования:
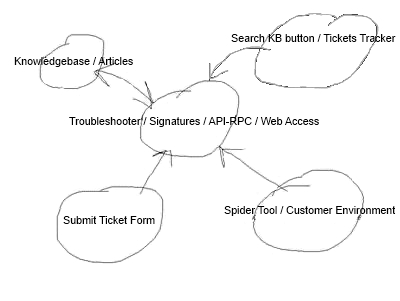
Выводы
Система находится в использовании сравнительно недавно. При ее интеграции были заложены возможности для сбора статистических данных. Эти данные собираются и анализируются каждый месяц. На данный момент мы получаем значения несколько важных метрик – эффективность и качество статей Knowledge Base (KB Quality) и эффективность самой системы (Ticket Avoidance, Accessibility).
По самым предварительным данным, система позволила снизить поток входящих тикетов примерно на 3-5%.
Дальнейшее ее совершенствование позволит значительно увеличить этот показатель. Кроме того, планируется снятие и других метрик. Например, рейтинга (топа) статей Knowledge Base, после показа которых клиент не нажимал кнопку окончательной отправки тикета, для более точной и детальной оценки и анализа работы системы и эффективности имеющихся статей для решения проблем клиента.
Конечно, существуют более мощные системы для решения поставленной задачи. Но они, как правило, предназначены для промышленных систем поиска. Обеспечение необходимой скорости обработки текста требует значительных ресурсов. Кроме того, у нас уже имелась существующая Knowledge Base по «Плеску» объемом около 6 тыс. статей, для модификации которой также потребовались бы существенные ресурсы. Поэтому мы отказались от использования уже существующих дорогостоящих решений как неоправданных для нашего применения, а создали собственную, быструю, дешевую и легковесную систему, которая даже в превоначальном варианте показывает весьма неплохой результат.
UPDATE: Сегодня мы запустили для реального использования онлайн верисю Troubleshooter-а. Пользуйтесь и задавайте вопросы!
