Comments 77
Сколько у Вас всего IBRN? Секрет? :-)
Скалакси больше не ведет свой блог? Или эта СХД к Скалакси не имеет отношения?
www.oracle.com/us/products/servers-storage/sun-zfs-storage-family-ds-173238.pdf
А это не рассматривали?
Младшие модели стоит 10/20 тысяч долларов (с дисками).
Старшие не могу сказать сколько, но в ней есть все!
Компрессия, дедубликация, репликация, кластеризация, Infiniband из коробки и т.п.
А это не рассматривали?
Младшие модели стоит 10/20 тысяч долларов (с дисками).
Старшие не могу сказать сколько, но в ней есть все!
Компрессия, дедубликация, репликация, кластеризация, Infiniband из коробки и т.п.
Что бы эта штука стала действительно производительной нужно купить кэшей + желательно SSD кэшей и тогда оно становится дорогой.
Да, но в других системах вот это все есть? Компрессия? Dedup? Snapshotting (для хот бекапа незаменимо)?
Снапшоттинг есть в lvm. Остальное гасит производительность. Бесспорно NetApp, EMC и другие системы хранения хороши, но их розничная стоимость столь высока, что мы как продавцы облачного хостинга вылетим с рынка. Объемы же российских заказов сегодня такие, что рассчитывать на закупку крупным оптом для получения нормальных скидок не приходится.
А ваш мегасвич, если не секрет, сколько стоит?
Самое большое ib-оборудование, которое мне доводилось использовать, было циской на 128 DDR портов.
(Зато с ним шел цисковский ультрапроприетарный и инфернальнонадежный сабнет-менеджер, под который циска заставляла ставить два отдельных сервера, без всяких «но»)
Самое большое ib-оборудование, которое мне доводилось использовать, было циской на 128 DDR портов.
(Зато с ним шел цисковский ультрапроприетарный и инфернальнонадежный сабнет-менеджер, под который циска заставляла ставить два отдельных сервера, без всяких «но»)
Как человек «близкий к телу» могу вам сказать, что, допустим, NetApp сейчас очень интересны задачи, подобные решаемой вашей компанией, то есть облачный хостинг, так как в мире они довольно неплохо в нем представлены (тот же rackspace или yahoo, например), а в России — пока нет.
А раз так, то возможны очень, очень значительные скидки на такие как ваши применения.
Не спорю, вы проделали интереснейшую и нужную работу, особенно интересно будет, если вы сможете опубликовать подробности. И, надеюсь, поставленным задачам ваша система соответствует, а «делать новое» всегда интереснее чем «вливать мешок бабла» и покупать готовое.
Но если когда-нибудь вам в будущем будет интересен NetApp, то не стесняйтесь спрашивать. Цены на ваши задачи будут совсем-совсем не «по прайслисту». :)
Может быть и попадем в ваш бюджет. Тем более, повторюсь, нетаппу это направление очень интересно и важно и самому.
А раз так, то возможны очень, очень значительные скидки на такие как ваши применения.
Не спорю, вы проделали интереснейшую и нужную работу, особенно интересно будет, если вы сможете опубликовать подробности. И, надеюсь, поставленным задачам ваша система соответствует, а «делать новое» всегда интереснее чем «вливать мешок бабла» и покупать готовое.
Но если когда-нибудь вам в будущем будет интересен NetApp, то не стесняйтесь спрашивать. Цены на ваши задачи будут совсем-совсем не «по прайслисту». :)
Может быть и попадем в ваш бюджет. Тем более, повторюсь, нетаппу это направление очень интересно и важно и самому.
В NetApp все это есть. Все это и многое другое, что еще пока не скопировано в ZFS ;)
К тому же ZFS сама по себе намного шустрее работает и с кешем обращается лучше, чем многие иные FS.
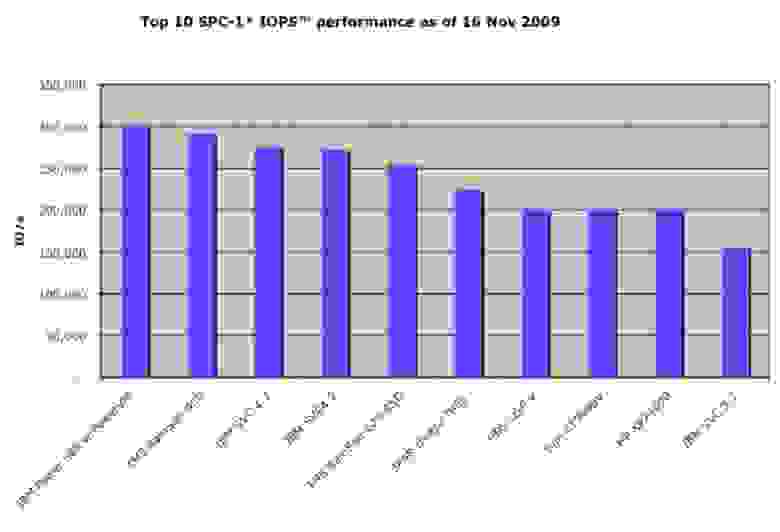
> нам удалось получить более 120 тысяч IOPS на запись с пары IBRN
Вы не сказали главное, на каком паттерне доступа и при каком размере блока.
А так — ну 120 тысяч IOPS. Видали и побольше, и не на Infiniband.
Вы не сказали главное, на каком паттерне доступа и при каком размере блока.
А так — ну 120 тысяч IOPS. Видали и побольше, и не на Infiniband.

Мы все подробно расскажем в следующем посте, когда опубликем тесты производительности дисковых систем разных облачных хостеров. 120Kiops — 4kb блоки, random write.
Каков был объем тестировочного блока данных по отношению к общей емкости хранилища?
Поясню вопрос. От размера тестируемого объема сильно зависит результат в IOPS. На маленьком объеме можно достичь весьма высоки результатов даже без «революций».
Вот пример на системе 8-летней давности, на одном 4Gb FC, на 10 дисках и 2GB cache, при 8GB тестируемой области на паттерне OLTP Database (4KB block, 70/30 read/write, 100% random)
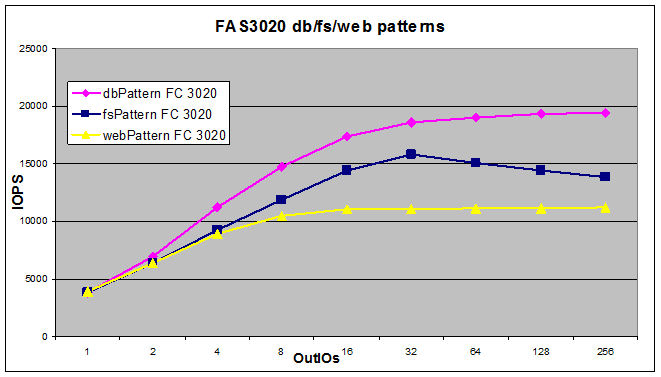
Почти 20 тысяч IOPS, без революций.
При росте объема тестируемой области на весь доступный объем результат, конечно, упадет.
А так — 50K IOPS это «скорость провода» одного уже повсеместного, и все более дешевого 8Gb FC.
То есть 120K IOPS это всего лишь полностью загруженные 3 канала FC.
Стоило ли городить огород с инфинибендом? Пока, из вашего рассказа — неясно в чем цимес. Замах на рубль — удар на копейку, говорилось в моем детстве голозадом. :)
Вот пример на системе 8-летней давности, на одном 4Gb FC, на 10 дисках и 2GB cache, при 8GB тестируемой области на паттерне OLTP Database (4KB block, 70/30 read/write, 100% random)
Почти 20 тысяч IOPS, без революций.
При росте объема тестируемой области на весь доступный объем результат, конечно, упадет.
А так — 50K IOPS это «скорость провода» одного уже повсеместного, и все более дешевого 8Gb FC.
То есть 120K IOPS это всего лишь полностью загруженные 3 канала FC.
Стоило ли городить огород с инфинибендом? Пока, из вашего рассказа — неясно в чем цимес. Замах на рубль — удар на копейку, говорилось в моем детстве голозадом. :)
Целью это разсказа было показать, как именно устроена наша новая система хранения. Тесты на производительность, как я уже сказал, мы опубликуем в следующих постах, вместе с методикой.
3 загруженных канала FC, 3 порта в FC свитче, три оптических кабеля = $$. Infiniband делает все это в одном линке, также успешно справляясь с IP-траффиком и миграциями vm между вычислительными узлами, а стоимость порта у него не выше стоимости 1 порта FC.
3 загруженных канала FC, 3 порта в FC свитче, три оптических кабеля = $$. Infiniband делает все это в одном линке, также успешно справляясь с IP-траффиком и миграциями vm между вычислительными узлами, а стоимость порта у него не выше стоимости 1 порта FC.
Обратите внимание, что у Infiniband все совсем не так радужно, как обещают вендоры IB-оборудования.
chelsio.com/assetlibrary/Eight%20myths%20about%20InfiniBand%20WP%2009-10.pdf
Что, впрочем не означает автоматически, что все радужно у 10GB Ethernet, например. Но в случае 10GBE как-то больше перспектив пока видится.
chelsio.com/assetlibrary/Eight%20myths%20about%20InfiniBand%20WP%2009-10.pdf
Что, впрочем не означает автоматически, что все радужно у 10GB Ethernet, например. Но в случае 10GBE как-то больше перспектив пока видится.
Существуют ровно такие же документы с противоположными утверждениями. Я в этой ситуации верю прайсам, которые мы просчитывали с коллегами, и реальной практике использования вот уже на протяжении 2-ух лет. У 10GB никаких исправлений в плане архитектуры не было, это все тот же унылый Ethernet, перспективы исправиться есть только у 40GE и они уже воплощаются в жизнь.
Подскажите infiniband позволяет по одному подключению гонять разные протоколы? У Вас диски отдаются по scsi-rdma, а ip трафик между нодами ходит по IPoIB. Для IPoIB и RDMA используются разные IB карточки или все через один порт подключения?
GPFS поверх SRP выдавала, помнится, скорости в разы выше, чем GPFS самостоятельно использующая RDMA. Правда это решение было дико нестабильным — пришлось отказаться.
Не секрет, что и диски и ib куда быстрее дружат с блоками 0.5-2 мегабайта, а скорости при работе с блоками в 4кб получаются на порядок ниже. Вы не думали в сторону того чтобы использовать внутри виртуальных машин какую-нибудь ФС с большим размером блока?
Не секрет, что и диски и ib куда быстрее дружат с блоками 0.5-2 мегабайта, а скорости при работе с блоками в 4кб получаются на порядок ниже. Вы не думали в сторону того чтобы использовать внутри виртуальных машин какую-нибудь ФС с большим размером блока?
Это не универсально, у нас ведь и Windows.
Ну, виндовс — это вообще отдельная тема =)
А вот если ориентироваться не на массовую аудиторию (нагрузка от которой подозрительно кореллируется с графиком школьных каникул), а скажем на сопровождение крупных проектов, то можно ведь навязать в некоторых технических аспектах свои правила в пользу эффективности? В том числе отняв у клиента право принимать неверные технические решения?
А вот если ориентироваться не на массовую аудиторию (нагрузка от которой подозрительно кореллируется с графиком школьных каникул), а скажем на сопровождение крупных проектов, то можно ведь навязать в некоторых технических аспектах свои правила в пользу эффективности? В том числе отняв у клиента право принимать неверные технические решения?
> 6. Перезагрузка Infiniband свитча.
> Клиентское I/O замораживается на время перезагрузки.
А каким образом ведет себя при этом клиентское ПО, которое динамически создает свои обработчики (apache, как пример)? На сколько я могу понять по-логике, число процессов начнет расти, потребление памяти увеличиться… В итоге имеем — перерасход денег клиента за время простоя/перезапуска оборудования провайдера. Как Вы боретесь с этим? Или пока не сталкивались с такой проблемой?
> Клиентское I/O замораживается на время перезагрузки.
А каким образом ведет себя при этом клиентское ПО, которое динамически создает свои обработчики (apache, как пример)? На сколько я могу понять по-логике, число процессов начнет расти, потребление памяти увеличиться… В итоге имеем — перерасход денег клиента за время простоя/перезапуска оборудования провайдера. Как Вы боретесь с этим? Или пока не сталкивались с такой проблемой?
А каков процент попадания в кеш на СХДшках???
Пока они еще только запущены, то 90-95%, как заполнятся, можно будет получить более адекватную статистику.
Учитывая, что у большинста облачных хостеров состояние близко к «только запущены», тесты производительности дисковых система покажут, в основном, производительность сети и кэша.
Это неверно, хранилища заполняются очень быстро. Мы будем проводить тестирование при полной загрузке пары IBRN.
Очень интересно, как вы снаружи можете определить заполняемость СХД у других хостеров? Утверждение «неверно» чем-то более весомым подкрепить сможете?
Я уверен, что СХД rackspace или amazon заполнены достаточно, о своих же российских коллегах/конкурентах, которых мы будем тестировать, я знаю также достаточно.
Про rackspace и amazon возражений нет — учитывая их возраст и клиентскую базу, их реальная нагрузка более-менее близка к планируемой и является уже устоявшейся величиной.
У российских коллег/конкурентов положение совершенно другое — по причине их молодости и холодности данного рынка вообще, востребованная сейчас мощность на порядки меньше установленной.
У российских коллег/конкурентов положение совершенно другое — по причине их молодости и холодности данного рынка вообще, востребованная сейчас мощность на порядки меньше установленной.
>— При создании нового диска на одном из IBRP выполняется команда lvcreate,
>запоминается таблица device-mapper для созданого тома, через device-mapper
>устройство создается уже на VRT и отдается в Xen.
То-есть на прокси и ксенах живет CLVM — верно?
>запоминается таблица device-mapper для созданого тома, через device-mapper
>устройство создается уже на VRT и отдается в Xen.
То-есть на прокси и ксенах живет CLVM — верно?
А что за сервера используются у вас для IBRN?
Никогда раньше не видел что бы корзины для дисков были и спереди и сзади :)
Даже после такой диковинки как Sun Fire X4500 где диски вертикально внутри корпуса, такое расположение кажется весьма интересным.
Никогда раньше не видел что бы корзины для дисков были и спереди и сзади :)
Даже после такой диковинки как Sun Fire X4500 где диски вертикально внутри корпуса, такое расположение кажется весьма интересным.
Это Супермикра.
Подробнее www.supermicro.com/storage/
Подробнее www.supermicro.com/storage/
А что будет если IB-свитч поломается? Только не говорите, что это в принципе не возможно.
Свитч модульный, хранилище подключено разными линками в разные модули (всего 9 модулей), 6 блоков питания, бэкплейн полностью пассивный. Соответственно может вылететь модуль, что легко будет пережито.
Т.е. вы хотите сказать, что у вас 1 модульный свитч? Выход из строя бекплейна хоть и редкая, но имеющая место штука.
Шасси бывают двух видов, полностью пассивные и с активными компонентами. Активные шасси действительно время от времени могут выходить из строя (выгорел чип, кондер или еще что-нибудь). Данное шасси является полностью пассивным и представляет собой простую кремнивую пластину. Она может сгореть лишь при пожаре.
Ну, вообще-то, я говорил про пассивные компоненты. Был печальный опыт с 2-мя известными производителями оборудования, когда выходил из строя пассивный бекплейн. Хотя вопрос был больше о кол-ве коммутаторов :-)
а если корзина сломается? :)
А правильно ли я понимаю, что вы ушли от использования GPFS??? Т.е. у вас каждая виртуальная машина лежит не на файловой системе образом, а на партиции/разделе?
Зачем тогда drbd есть, если можно два md запустить на разных машинах, экспортировав диски обоих серверов по iscsi? это проще чем drbd. конкуретные mdadm обязаны общаться, чтобы правильно собрать деградировавший массив, а они этого не умеют, потому что для этого не предназначены. или рядом сидит архитектор и разделяет?
Split-brain возможен, если по какой-то причине (глюк в драйверах IB или SCST) на одной из проксей рэйд станет degraded, а на других нет. Сбойная прокси будет писать на одну половинку рейда, остальные на обе. В этот момент сработает мониторинг и инженер вручную выключит со всех проксей ту ноду, которая засбоила и введет ее обратно в строй. Никакие данные при этом не будут потеряны.
Если такая ситуация будет случаться, то мы переключим политику multipath c round-robin на failover, что бы все I/O шло через один md, до тех пор пока он жив.
Если такая ситуация будет случаться, то мы переключим политику multipath c round-robin на failover, что бы все I/O шло через один md, до тех пор пока он жив.
узел с виртуалками получает данные с 2х проксей. одна из проксей считает, что одно из ее хранилищ сломалось, и работает (пишет и читает) только с одним из хранилищ. при этом вторая прокся считает, что оба хранилища рабочие. и работает (пишет и читает) с обоих из хранилищ. т.е. она может пытаться прочитать со второго хранилища то, что там должно быть, но чего нет в результате глюка на первой проксе. так? насколько я понимаю, теоретически оно может упасть за несколько секунд. раньше, чем любой из админов среагирует
мы уже на такие грабли несколько раз наступали. если ты пытаешь софт одной направленности героически натянуть на процессы для которых он не предназначен что-то обязательно перечеркнет всю идею, возможно на последнем из этапов, когда ты уже вложился в это гиблое дело
мы уже на такие грабли несколько раз наступали. если ты пытаешь софт одной направленности героически натянуть на процессы для которых он не предназначен что-то обязательно перечеркнет всю идею, возможно на последнем из этапов, когда ты уже вложился в это гиблое дело
Это очень хорошее замечание, спасибо. Подумаем как лучше это обработать.
В общем исправили уязвимость. На VRT серверах переконфигурировали multipath, что бы использовал failover алгоритм (переключаться, только при падении пути), балансировка путей рандомная, активный путь выбирается при запуске VRT сервера.
Sign up to leave a comment.
Новая система хранения в облаке