Многие из вас знакомы с Оверсаном по статьям в нашем блоге на Хабре, где мы много рассказывали об архитектуре систем ДЦ Оверсан-Меркурий. Об архитектуре облака Скалакси мы тоже рассказывали, но в основном на профильных конференциях, многие наши доклады и презентации уже устарели и стали неактуальны.
Мы думаем, что многие из подсистем и архитектурных решений в Скалакси будут вам интересны и решили о них рассказать. Начать именно с темы распределения ресурсов CPU решили потому, что вопрос о гарантированном объеме вычислительных ресурсов всегда на слуху: мы регулярно слышим его от клиентов, просто интересующихся, критиков и блоггеров.
Чтобы разобраться с распределением ресурсов, придется рассмотреть архитектуру нашей системы виртуализации хотя бы в общих чертах и детально изучить частности. В этой статье я постараюсь объяснить, как работает распределение вычислительной мощности CPU между виртуальными машинами клиентов: сколько времени CPU достается каждой VM и за счет чего это достигается.
Мы в команде Скалакси привыкли к некоторым терминам и определениям, которыми будет пестрить этот текст, поэтому я приведу их список тут:
Многие другие определения и термины раскрываются ниже, по ходу подачи материала.
Рассказ о планировщике CPU в Xen проще всего начать с небольшого вводного описания основных принципов работы Xen гипервизора. Xen — система паравиртуализации, позволяющая на одной физической машине (хосте) запускать несколько гостевых виртуальных машин, которые с помощью Xen получают доступ к ресурсам физической. При этом возможно два варианта запуска гостевой VM — режим паравиртуализации (PV), когда виртуальная машина запускается с модифицированным ядром и знает, что она запущена в Xen, либо машина запускается с любой немодифицированной ОС, при этом для нее запускается специальный процесс, эмулирующий поведение реального железа (qemu-dm), такой режим называется HVM.
В Xen гостевые виртуальные машины также называются доменами. Существует один привилегированный домен (Dom0), через который происходит управление гипервизором, работа других гостевых машин с I/O, управление другими виртуальными машинами. Гостевые виртуальные машины (DomU) могут быть запущены только после загрузки Dom0.

В целом, архитектура гипервизора Xen уже много обсуждалась на хабре, распыляться и раскрывать ее в одной статье еще раз — нет смысла.
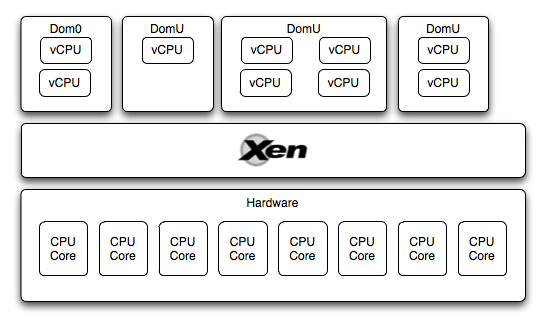
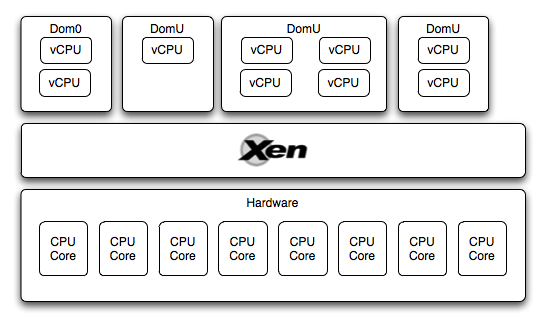
Итак, получается, что у нас есть аппаратный уровень, на котором выполняется гипервизор, поверх которого запущено несколько гостевых виртуальных машин (Dom0 & DomU). У каждой из этих виртуальных машин есть доступ к CPU. Как он организован?
Каждая виртуальная машина работает с так называемыми виртуальными CPU (vCPU), это виртуализованное представление одного ядра. Количество vCPU назначается каждой виртуальной машине индивидуально либо в ее конфигурации, либо с помощью команды xm vcpu-set. При этом, количество vCPU на каждой виртуальной машине может быть не менее одного и не более количества ядер хоста.
Задача гипервизора — правильно распределить время физических CPU между vCPU, решением этой задачи занимается компонент, называемый cpu scheduler. В ходе написания этой статьи я нашел информацию о трех существующих планировщиках и описание некоего планировщика, который должен прийти на смену тому, что по-умолчанию используется в Xen сейчас. Но цель этой статьи — рассказать, каким образом это работает у нас в облаке, поэтому я остановлюсь подробно только на одном: credit scheduler.
Если поискать, то на Хабре можно найти статьи по этой тематике. Поэтому тут мы кратко резюмируем основные принципы планировщика и еще раз разберемся в алгоритме его работы:
Теперь подробнее об алгоритме:
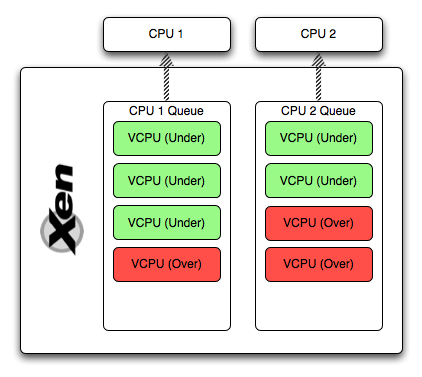
Отработав один time slice (vCPU заблокировался, ушел в idle, наоборот проснулся), CPU перейдет к следующему vCPU в очереди. При этом, потребляя тайм-слайсы CPU, со счета vCPU списываются очки, если количество очков стало отрицательным, то vCPU получит статус over и займет свое место в очереди. Если в очереди закончились vCPU со статусом under, CPU поищет такие vCPU в очередях других ядер. Если же и там его нет — он будет искать следующий vCPU у себя и других со статусом over, но cap, позволяющим выдать vCPU еще немного времени. Этот подход гарантирует, что даже vCPU с достаточно низким weight получит процессорное время, если CPU системы и других виртуальных машин простаивает, а так же гарантирует, что VM получит свое процессорное время.
В Cкалакси, мы используем Xen-гипервизор, виртуальные машины пользователей запускаются на VRT-хостах. Наша собственная разработка, CloudEngine, выбирает, на каком VRT-хосте запустить машину. Алгоритм выбора подходящего хоста называется аллокатором, но если объяснять по-простому — он на основании кол-ва слотов VM выбирает подходящее для нее по размеру место так, чтобы облако было “правильно” укомплектовано: чтобы потом было где запустить другие виртуальные машины и чтобы виртуальным машинам доставалось побольше ресурсов (абзацем выше мы говорили о том, что если физический хост заполнен не на 100%, то CPU будет выделяться больше гарантированного минимума).
В dom0 запускается SLES, у которой cap = 0 и weight = 16384. Далее в domU запускаются клиентские VM, засланные CloudEngine, и их вес назначается из расчета одной единицы веса на один мегабайт RAM. Таким образом получается, что суммарный вес domU-машин при полной загрузке VRT-хоста — 32768. То есть даже если хост загружен под завязку, dom0 получит достаточно вычислительных ресурсов, если они вдруг понадобилось, и хост не “захлебнется” под тяжестью domU-машин.
На самом деле, dom0 почти всегда в idle, поэтому мы можем считать, что CPU распределяется между виртуальными машинами клиентов с некими незначительными потерями на dom0. Франк Кохлер в своей презентации утверждает, что dom0 уже после загрузки в штатном режиме “съедает” до 0,5% CPU.
Также очень важный момент: CloudEngine раскладывает машины в облако таким образом, чтобы на одном хосте было занято до 50% процентов его ресурсов. Это достигается достаточно просто: мы регламентировано гарантируем, что облако зарезервировано, то есть падение до 50% хостов должно привести к миграции VM на другие хосты и продолжению работы, а это значит, что занята может быть максимум половина облака. А это, в свою очередь, означает, что в идеале — на каждом хосте не более 50% занятых ресурсов: это облегчает масштабирование VM (меньше миграций при масштабировании) и увеличивает долю CPU, достающуюся каждой машине.
В этой статье я рассказал, как распределяется CPU между VM в облаке. В следующей я хочу показать, как это работает на практике. Ждите тестов производительности на следующей неделе :) Если вам хочется провести независимый тест — пишите, мы предоставим для этого ресурсы бесплатно.
Если вам интересно почитать материалы по распределению ресурсов CPU в Xen — ниже те источники, информацию из которых я использовал. Если найдете другие интересные статьи — напишите об этом, пожалуйста, в комментариях.
Подписывайтесь на наш twitter, мы стараемся искать для вас интересные материалы о виртуализации и облачных вычислениях. И заходите нас потестировать / подать нам идею о нужном вам функционале :)
Мы думаем, что многие из подсистем и архитектурных решений в Скалакси будут вам интересны и решили о них рассказать. Начать именно с темы распределения ресурсов CPU решили потому, что вопрос о гарантированном объеме вычислительных ресурсов всегда на слуху: мы регулярно слышим его от клиентов, просто интересующихся, критиков и блоггеров.
Чтобы разобраться с распределением ресурсов, придется рассмотреть архитектуру нашей системы виртуализации хотя бы в общих чертах и детально изучить частности. В этой статье я постараюсь объяснить, как работает распределение вычислительной мощности CPU между виртуальными машинами клиентов: сколько времени CPU достается каждой VM и за счет чего это достигается.
Определения
Мы в команде Скалакси привыкли к некоторым терминам и определениям, которыми будет пестрить этот текст, поэтому я приведу их список тут:
- VRT-хост или просто VRT — один хост виртуализации, физический сервер, на котором размещаются виртуальные машины пользователей;
- VM — виртуальная машина пользователя, она же — виртуальный сервер. В мире классического хостинга очень простая версия этой штуки называется VPS.
Многие другие определения и термины раскрываются ниже, по ходу подачи материала.
Общая архитектура Xen
Рассказ о планировщике CPU в Xen проще всего начать с небольшого вводного описания основных принципов работы Xen гипервизора. Xen — система паравиртуализации, позволяющая на одной физической машине (хосте) запускать несколько гостевых виртуальных машин, которые с помощью Xen получают доступ к ресурсам физической. При этом возможно два варианта запуска гостевой VM — режим паравиртуализации (PV), когда виртуальная машина запускается с модифицированным ядром и знает, что она запущена в Xen, либо машина запускается с любой немодифицированной ОС, при этом для нее запускается специальный процесс, эмулирующий поведение реального железа (qemu-dm), такой режим называется HVM.
В Xen гостевые виртуальные машины также называются доменами. Существует один привилегированный домен (Dom0), через который происходит управление гипервизором, работа других гостевых машин с I/O, управление другими виртуальными машинами. Гостевые виртуальные машины (DomU) могут быть запущены только после загрузки Dom0.

В целом, архитектура гипервизора Xen уже много обсуждалась на хабре, распыляться и раскрывать ее в одной статье еще раз — нет смысла.
Планирование & распределение мощности CPU
Итак, получается, что у нас есть аппаратный уровень, на котором выполняется гипервизор, поверх которого запущено несколько гостевых виртуальных машин (Dom0 & DomU). У каждой из этих виртуальных машин есть доступ к CPU. Как он организован?
Каждая виртуальная машина работает с так называемыми виртуальными CPU (vCPU), это виртуализованное представление одного ядра. Количество vCPU назначается каждой виртуальной машине индивидуально либо в ее конфигурации, либо с помощью команды xm vcpu-set. При этом, количество vCPU на каждой виртуальной машине может быть не менее одного и не более количества ядер хоста.
Задача гипервизора — правильно распределить время физических CPU между vCPU, решением этой задачи занимается компонент, называемый cpu scheduler. В ходе написания этой статьи я нашел информацию о трех существующих планировщиках и описание некоего планировщика, который должен прийти на смену тому, что по-умолчанию используется в Xen сейчас. Но цель этой статьи — рассказать, каким образом это работает у нас в облаке, поэтому я остановлюсь подробно только на одном: credit scheduler.
Если поискать, то на Хабре можно найти статьи по этой тематике. Поэтому тут мы кратко резюмируем основные принципы планировщика и еще раз разберемся в алгоритме его работы:
- Планировщик работает с vCPU в качестве объекта в очереди. Xen не занимается планировкой задач внутри VM, он лишь управляет временем выполнения vCPU, а гостевая ОС заботится о работе процессов внутри VM;
- Виртуальной машине можно ограничить количество vCPU — от одного, до общего числа ядер;
- Виртуальной машине назначается вес (weight), управляющий приоритетом выделения времени CPU для ее vCPU;
- Cap — искусственное ограничение максимально выделенного количества времени CPU в процентах от одного физического ядра. 20 — 20% одного ядра, 400 — 4 ядра полностью, 0 — нет ограничения;
- Dom0 тоже использует эти параметры (и vCPU) и получает процессорное время согласно своим параметрам weight и cap.
Теперь подробнее об алгоритме:
- У каждого CPU в Xen есть своя очередь, в которую становятся vCPU. У vCPU в очереди есть уровень кредитов (число) и статус (over / under), который показывает, получило ли виртуальное ядро свою порцию CPU в этом периоде распределения, или еще недополучило;
- Расчетный период — некий период времени, раз в который внешний тред пересчитывает количество кредитов всех vCPU и меняет их статусы соответственно количеству кредитов (очков);
- CPU Time slice — период времени (по-умолчанию 30ms), который CPU предоставляется для одного vCPU.

Отработав один time slice (vCPU заблокировался, ушел в idle, наоборот проснулся), CPU перейдет к следующему vCPU в очереди. При этом, потребляя тайм-слайсы CPU, со счета vCPU списываются очки, если количество очков стало отрицательным, то vCPU получит статус over и займет свое место в очереди. Если в очереди закончились vCPU со статусом under, CPU поищет такие vCPU в очередях других ядер. Если же и там его нет — он будет искать следующий vCPU у себя и других со статусом over, но cap, позволяющим выдать vCPU еще немного времени. Этот подход гарантирует, что даже vCPU с достаточно низким weight получит процессорное время, если CPU системы и других виртуальных машин простаивает, а так же гарантирует, что VM получит свое процессорное время.
Как это организовано в Скалакси
В Cкалакси, мы используем Xen-гипервизор, виртуальные машины пользователей запускаются на VRT-хостах. Наша собственная разработка, CloudEngine, выбирает, на каком VRT-хосте запустить машину. Алгоритм выбора подходящего хоста называется аллокатором, но если объяснять по-простому — он на основании кол-ва слотов VM выбирает подходящее для нее по размеру место так, чтобы облако было “правильно” укомплектовано: чтобы потом было где запустить другие виртуальные машины и чтобы виртуальным машинам доставалось побольше ресурсов (абзацем выше мы говорили о том, что если физический хост заполнен не на 100%, то CPU будет выделяться больше гарантированного минимума).
В dom0 запускается SLES, у которой cap = 0 и weight = 16384. Далее в domU запускаются клиентские VM, засланные CloudEngine, и их вес назначается из расчета одной единицы веса на один мегабайт RAM. Таким образом получается, что суммарный вес domU-машин при полной загрузке VRT-хоста — 32768. То есть даже если хост загружен под завязку, dom0 получит достаточно вычислительных ресурсов, если они вдруг понадобилось, и хост не “захлебнется” под тяжестью domU-машин.
На самом деле, dom0 почти всегда в idle, поэтому мы можем считать, что CPU распределяется между виртуальными машинами клиентов с некими незначительными потерями на dom0. Франк Кохлер в своей презентации утверждает, что dom0 уже после загрузки в штатном режиме “съедает” до 0,5% CPU.
Также очень важный момент: CloudEngine раскладывает машины в облако таким образом, чтобы на одном хосте было занято до 50% процентов его ресурсов. Это достигается достаточно просто: мы регламентировано гарантируем, что облако зарезервировано, то есть падение до 50% хостов должно привести к миграции VM на другие хосты и продолжению работы, а это значит, что занята может быть максимум половина облака. А это, в свою очередь, означает, что в идеале — на каждом хосте не более 50% занятых ресурсов: это облегчает масштабирование VM (меньше миграций при масштабировании) и увеличивает долю CPU, достающуюся каждой машине.
Что дальше
В этой статье я рассказал, как распределяется CPU между VM в облаке. В следующей я хочу показать, как это работает на практике. Ждите тестов производительности на следующей неделе :) Если вам хочется провести независимый тест — пишите, мы предоставим для этого ресурсы бесплатно.
Материалы по теме
Если вам интересно почитать материалы по распределению ресурсов CPU в Xen — ниже те источники, информацию из которых я использовал. Если найдете другие интересные статьи — напишите об этом, пожалуйста, в комментариях.
- Общий обзор архитектуры Xen-гипервизора;
- Информация о системе распределения CPU в Xen;
- Подробно о credit scheduler;
- И еще о распределении ресурсов в Xen;
- Видео презентации Франка Кохлера (Citrix) по XenServer;
Подписывайтесь на наш twitter, мы стараемся искать для вас интересные материалы о виртуализации и облачных вычислениях. И заходите нас потестировать / подать нам идею о нужном вам функционале :)
