В данной статье я расскажу и покажу на примере, о том, как человек с минимальным Data Science опытом, смог собрать данные из форума и сделать тематическое моделирование постов с использованием LDA модели, и выявил наболевшие темы людей с глютеновой непереносимостью.
В прошлом году мне нужно было срочно подтянуть свои знания в области машинного обучения. Я менеджер продуктов для Data Science, Machine Learning и AI, или по-другому Technical Product Manager AI/ML. Одних бизнес навыков и умения разрабатывать продукты, как это обычно бывает в проектах, направленных на пользователей не в технической сфере, не достаточно. Необходимо понимать основные технические концепции индустрии ML, и если нужно, суметь самому написать пример для демонстрации продукта.
Я около 5 лет разрабатывала Front-end проекты, разрабатывала сложные веб приложения на JS и React, но машинным обучением, ноутбуками и алгоритмами никогда не занималась. Поэтому, когда я увидела новость от Отус, что у них открывается пятимесячный экспериментальный курс по Машинному обучению, я, не долго думая, решила пройти пробное тестирование и попала на курс.
В течении пяти месяцев, каждую неделю проходили двухчасовые лекции и домашние задания к ним. Там я узнала об основах ML: различные алгоритмы регрессии, классификации, ансамбли моделей, градиентный бустинг и даже немного затронули облачные технологии. В принципе, если внимательно слушать каждую лекцию, то примеров и объяснений хватает вполне для выполнения домашних заданий. Но все же иногда, как и в любом другом кодинг проекте, приходилось обращаться к документации. Учитывая мою полную рабочую занятость, учиться было достаточно удобно, так как я всегда могла пересмотреть запись онлайн лекции.
В конце обучения данного курса, всем нужно было сдавать итоговый проект. Идея проекта возникла довольно спонтанно, в это время я начала обучение предпринимательству в Stanford, где я попала в команду, которая работала над проектом для людей с глютеновой непереносимостью. В ходе маркет исследования, мне было интересно узнать, что беспокоит, о чем говорят, на что жалуются люди с данной особенностью.
По ходу исследования, я нашла форум на celiac.com с огромным количеством материала по целиакии. Было очевидно, что пролистывать в ручную и читать больше 100 тысячи постов нецелесообразно. Так мне пришла идея, применить знания, которые я получила на данном курсе: собрать все вопросы и комментарии с форума из определенного топика и сделать тематическое моделирование с наиболее часто встречающимися словами в каждом из них.
Шаг 1. Сбор данных с форума
Форум из себя представляет множество топиков различного размера. Всего суммарно на данном форуме около 115 000 топиков и около миллиона постов, с комментариями к ним. Меня интересовала конкретная подтема “Coping with Celiac Disease”, что в переводе буквально означает “Справляться с Целиакией”, если по-русски, то тут подразумевается больше “продолжать жить с диагнозом целиакия и как-то справляться с трудностями”. В этой под-теме около 175 000 постов с комментариями.
Скачивание данных происходило в два этапа. Для начала мне пришлось пройтись по всем страницам под топика и собрать все ссылки ко всем постам, для того, чтобы на следующем этапе, я уже могла собрать комментарий.
url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'Так как форум оказался довольно старый, мне очень повезло и особо каких-либо секьюрных заморочек у сайта не было, поэтому чтобы собрать данные, достаточно было использовать комбинацию User-Agent из библиотеки fake_useragent, Beautiful Soup для работы с html разметкой и знать количество страниц:
# Get total number of pages
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)И далее скачать HTML DOM каждой страницы, чтобы легко и просто вытаскивать данные из них с помощью питоновской библиотеки BeautifulSoup.
# collect pages
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
Для скачивания данных, мне нужно было определить необходимые поля для анализа: найти значения этих полей в DOM и сохранить в dictionary. Я сама пришла из Front-end бекграунда, поэтому работа с домом и объектами для меня была тривиальной.
def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
# collecting titles and urls
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
# collecting author & last action
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
# collecting stats
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
Итого у меня собралось около 15450 постов в данной тематике.
coping_posts_info = collect_post_info(coping_pages)Теперь их можно было перенести в DataFrame, чтобы они красивенько там лежали, и заодно сохранила их в csv файле, чтобы не пришлось еще раз ждать когда данные соберутся с сайта, если случайно сломается notebook или я где случайно переопределю переменную.
df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
# format data
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')После сбора коллекции постов, я перешла к сбору самих комментарий.
def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
# collecting comments
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
ШАГ 2 Анализ данных и тематическое моделирование
В предыдущем шаге мы собрали данные с форума и получили итоговые данные в виде 153777 строк вопросов и комментариев.
Но просто собранные данные не интересны, поэтому первым делом, мне захотелось провести очень простую аналитику: я вывела статистику для топ 30 самых просматриваемых топиков и 30 самых комментируемых топиков.
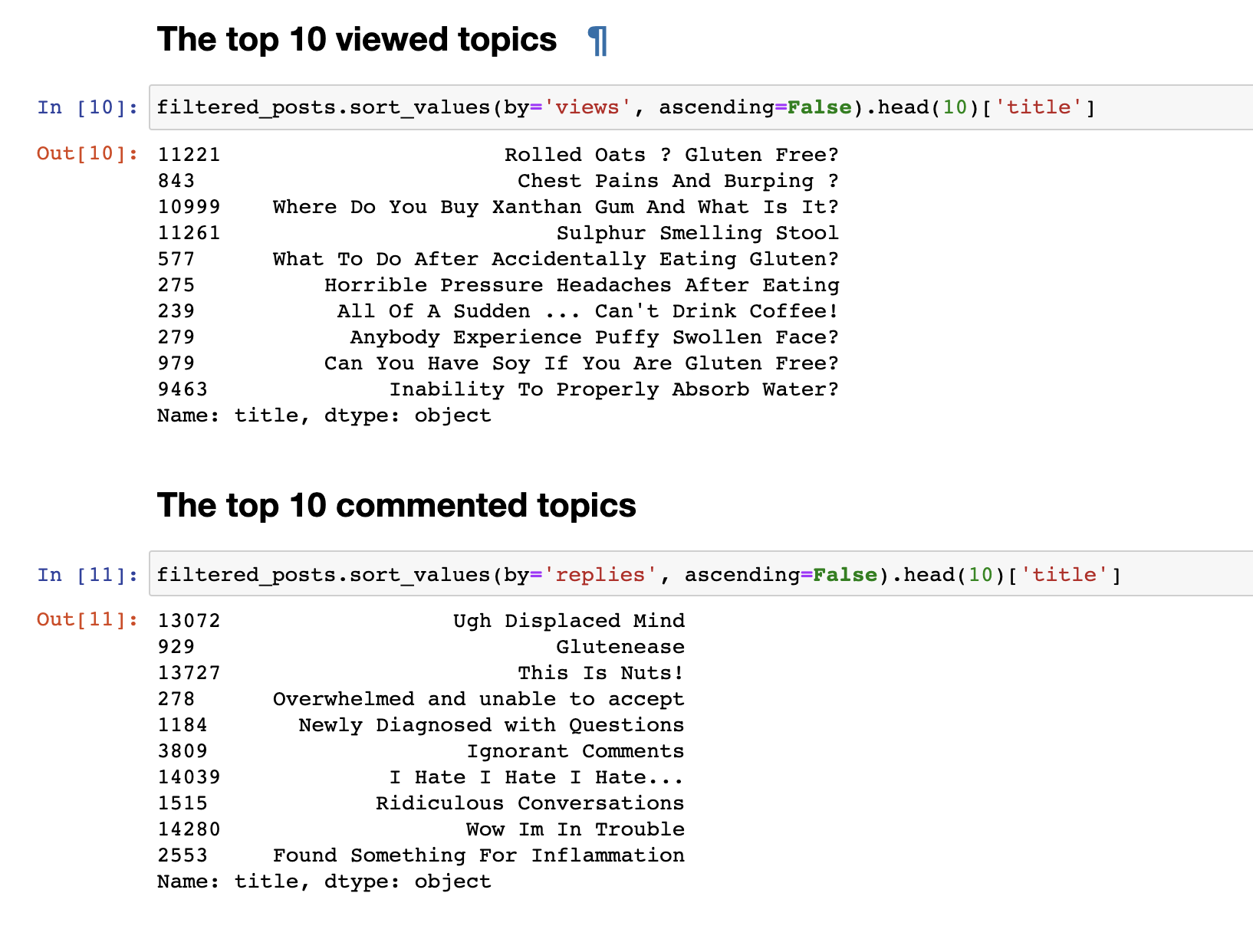
Самые просматриваемые посты не совпали с самими комментируемыми. Заголовки комментируемых постов, даже с первого взгляда, заметны. Их названия имеют более эмоциональный окрас: “Я ненавижу, Я ненавижу, Я ненавижу” или “Высокомерные комментарии” или “Вау, я в беде”. А самые просматриваемые, больше имеют формат вопроса: “Можно ли есть сою?”, “Почему не могу нормально усваивать воду?” и другие.
Несложный анализ текста мы сделали. Чтобы перейти непосредственно, к более сложному анализу, нужна подготовка самих данных перед подачей ее на вход LDA модели для разбивки по темам. Для этого избавимся от комментариев содержащих меньше 30 слов, для того, чтобы отфильтровать спам и бессмысленные короткие комментарии. Приведем их к нижнему регистру.
# Let's get rid of text < 30 words
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()Удалим ненужные стоп слова, чтобы очистить нашу текстовую подборку
stop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)А также добавим биграммы и сформируем bag of words, чтобы выделить устойчивые словосочетания, например, как gluten_free, support_group, ну и другие словосочетания, которые сгруппировавшись несут определенный смысл.
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
Теперь мы наконец-то готовы к непосредственно самой тренировке LDA модели.
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
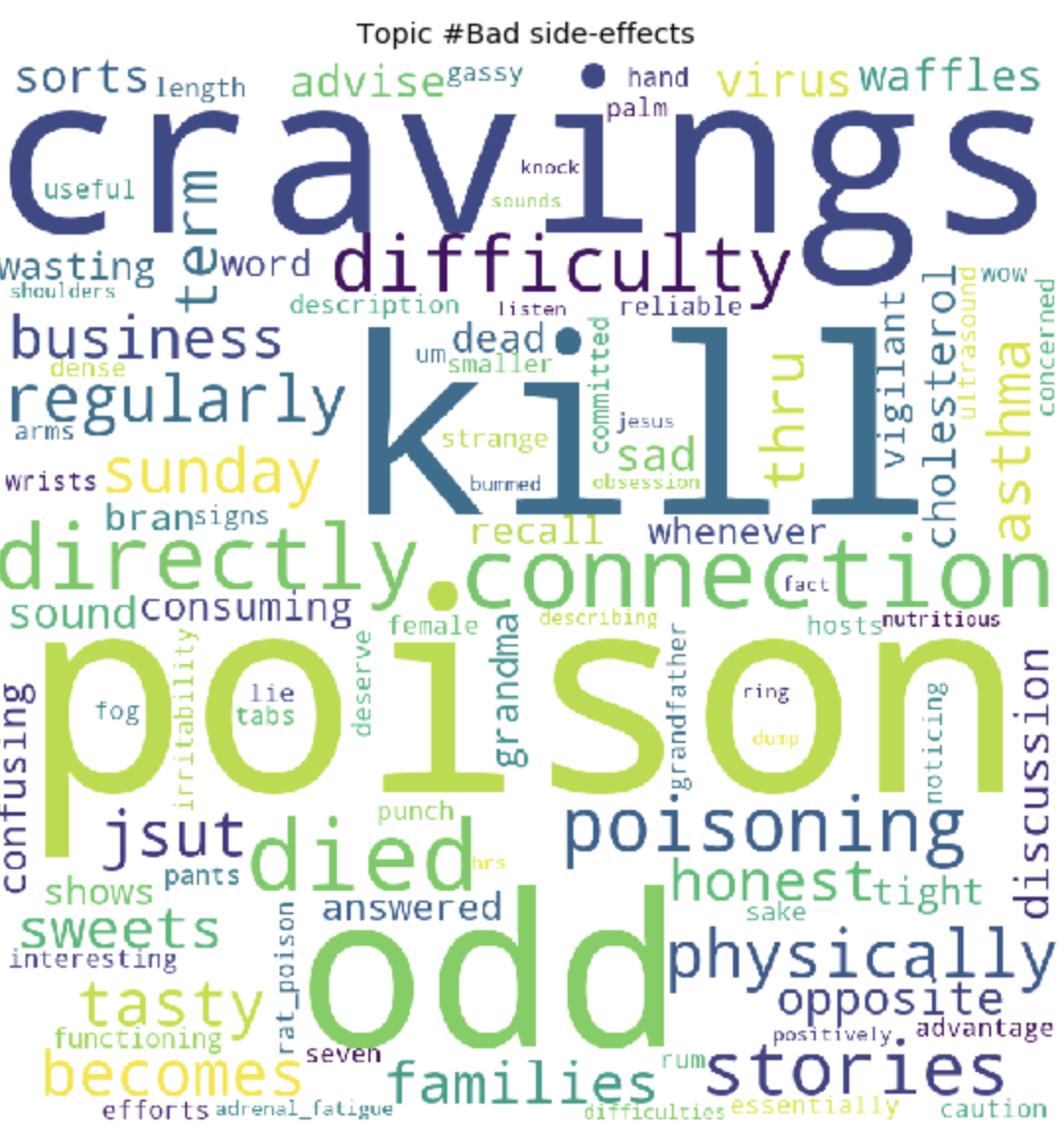
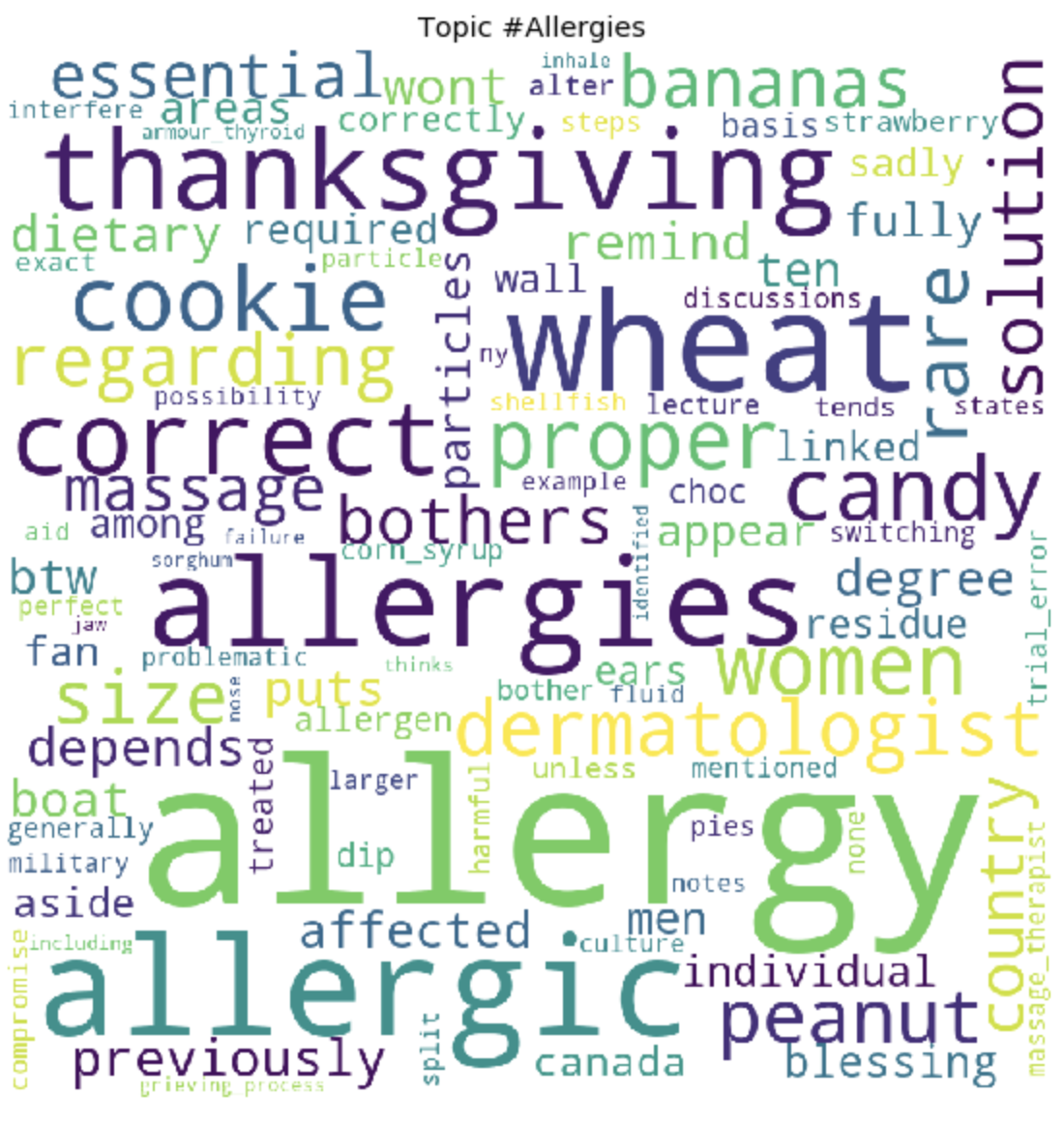
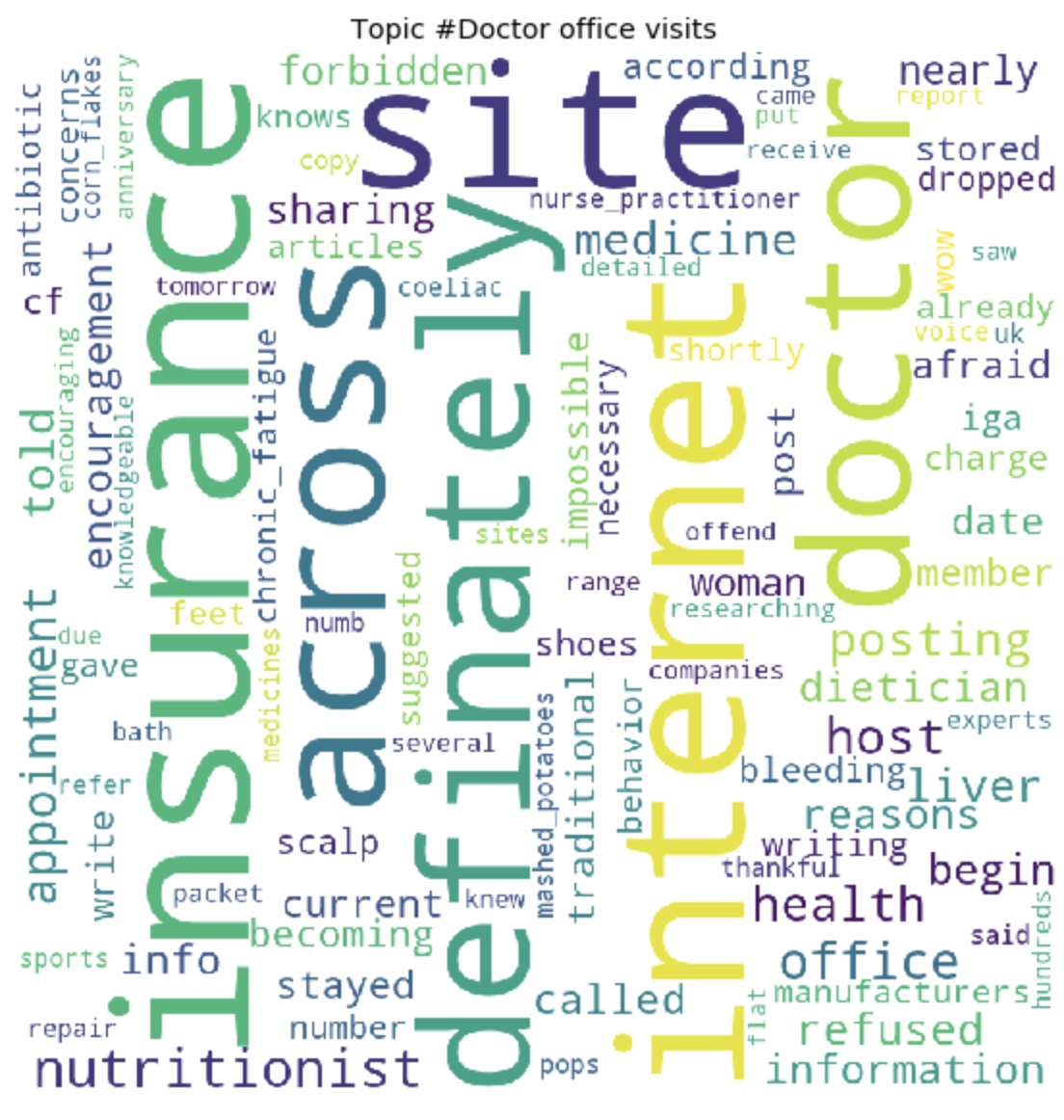
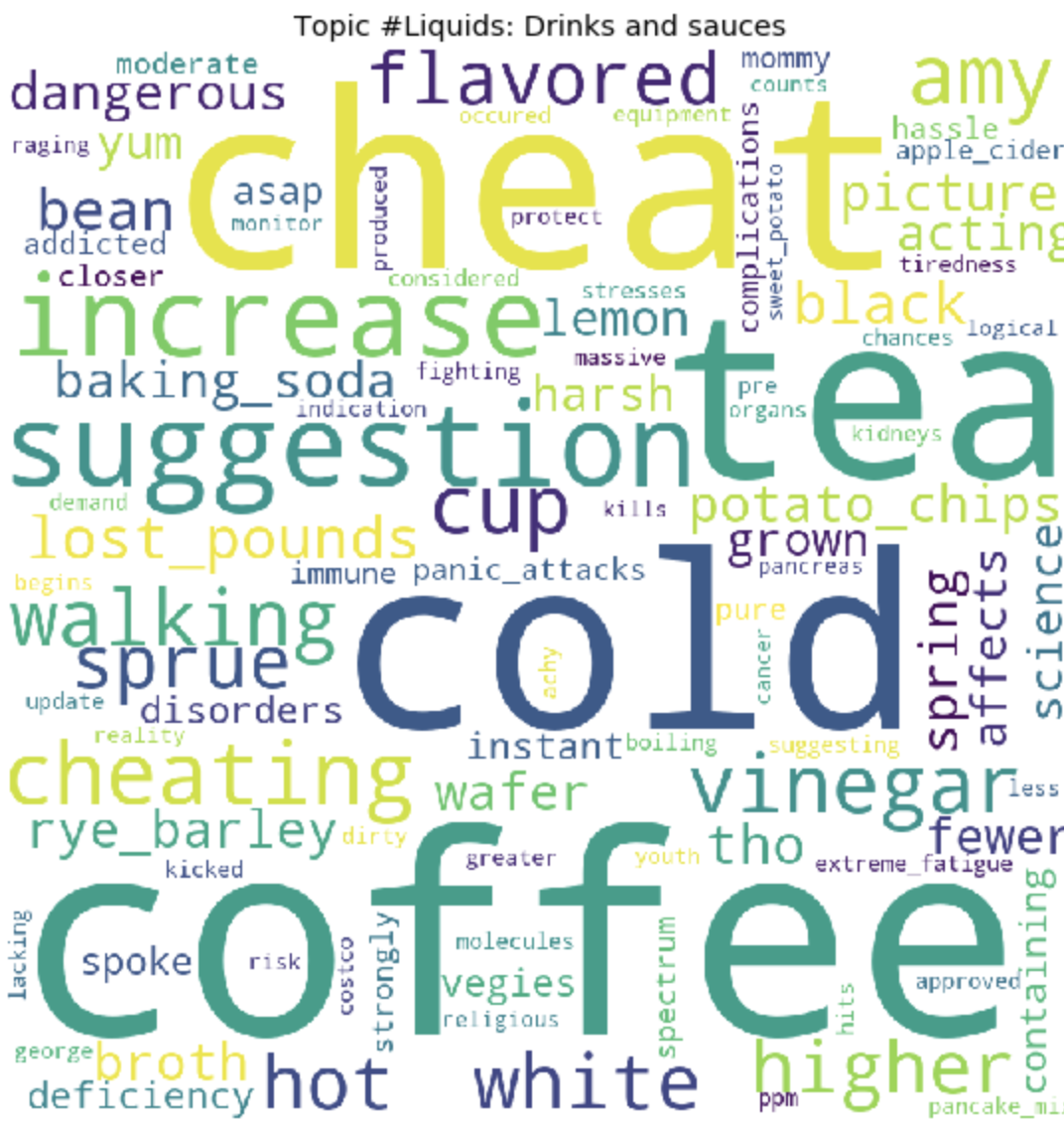
По окончанию тренировки, мы, в конечном итоге, получаем результат сформировавшихся топиков. Которые я прикрепила в конце этого поста.
for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
Как это может быть заметно, топики получились довольно отличимы по содержанию друг от друга. По ним становится ясно, о чем ведутся разговоры у людей с глютеновой непереносимостью. В основном, про продукты питания, походы в рестораны, загрязнения пищи глютеном, ужасными болями, лечением, походами по докторам, семье, непониманием и прочими вещами, с которыми им приходится сталкиваться людям каждый день, в связи со свой проблемой.
Вот и все. Спасибо всем за внимание. Надеюсь этот материал вам оказался интересным и полезным. И все же так как я не DS разработчик, то не судите строго. Если есть, что добавить или улучшить, всегда приветствую конструктивную критику, пишите.
Для просмотра 30 топиков
Осторожно, много изображений