И снова здравствуйте! В преддверии старта курса «Архитектор ПО» подготовили перевод еще одного интересного материала.

Последние несколько лет наблюдается рост популярности микросервисной архитектуры. Есть много ресурсов, которые учат правильно ее реализовывать, однако достаточно часто люди говорят о ней, как о серебряной пуле. Против использования микросервисов есть множество аргументов, но самый весомый из них заключается в том, что этот тип архитектуры таит в себе неопределенную сложность, уровень которой зависит от того, как вы управляете отношениями между вашими сервисами и командами. Вы можете найти много литературы, которая расскажет почему (возможно) в вашем случае микросервисы окажутся не лучшим выбором.
Мы в letgo мигрировали с монолита к микросервисам, чтобы удовлетворить потребность в масштабируемости, и сразу же убедились в ее благотворном влиянии на работу команд. При правильном применении, микросервисы дали нам несколько преимуществ, а именно:
Не все микросервисные архитектуры событийно-ориентированные. Некоторые люди выступают за синхронную связь между сервисами в архитектуре такого вида с помощью HTTP (gRPC, REST и т.д.). В letgo мы стараемся не следовать этому шаблону и асинхронно связываем наши сервисы с доменными событиями. Вот причины, по которым мы это делаем:
Исходя из этого мы в letgo стараемся придерживаться асинхронной связи между сервисами, а синхронная работает только в таких исключительных случаях как feature MVP. Мы делаем это потому, что хотим, чтобы каждый сервис генерировал свои собственные сущности на основе доменных событий, опубликованных другими сервисами в нашем Message Bus.
По нашему мнению, успех или неудача при реализации микросервисной архитектуры зависит от того, как вы справляетесь с присущей ему комплексностью и тем, как вашим сервисы взаимодействуют друг с другом. Разделение кода без перевода инфраструктуры связи на асинхронную превратит ваше приложение в распределённый монолит.

Событийно-ориентированная архитектура в letgo
Сегодня я хочу поделиться примером того, как мы в letgo используем доменные события и асинхронную связь: наша сущность User существует во многих сервисах, но ее создание и редактирование изначально обрабатывается сервисом Users. В базе данных сервиса Users мы храним много данных, таких как имя, адрес электронной почты, аватарку, страну и т.д. В нашем сервисе Chat у нас тоже есть концепция пользователя, но нам не нужны те данные, которые есть у сущности User из сервиса Users. В списке диалогов показывается имя пользователя, его аватар и ID (ссылка на профиль). Мы говорим, что в чате есть только проекция сущности User, которая содержит частичные данные. На самом деле в Chat мы не говорим о пользователях, мы называем их “talkers”. Эта проекция относится к сервису Chat и построена на событиях, которые Chat получает из сервиса Users.
То же самое мы делаем с листингами. В сервисе Products мы храним n картинок каждого листинга, но в режиме просмотра списка диалогов мы показываем одну основную, поэтому наша проекция из Products в Chat требует только одну картинку вместо n.
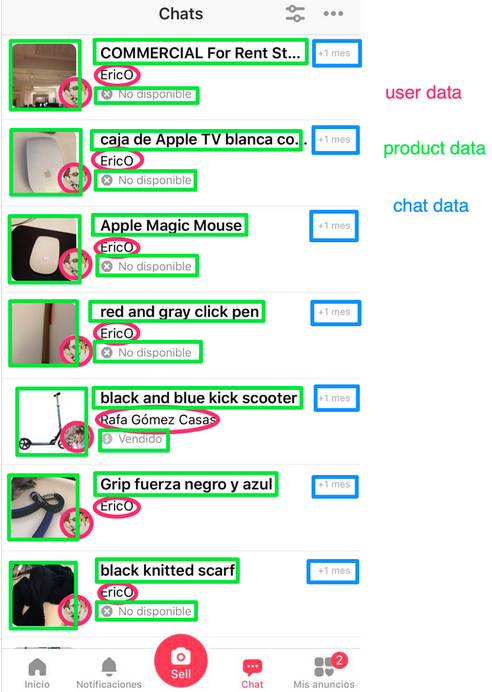
Просмотр списка диалогов в нашем чате. Показано какой конкретно сервис на бэкенде предоставляет информацию.
Если вы снова взглянете на список диалогов, то увидите, что почти все данные, которые мы показываем, не создаются сервисом Chat, но ему принадлежат, поскольку проекции User и Chat являются собственностью Chat. Между доступностью и согласованностью проекций есть компромисс, о котором мы не будем говорить в этой статье, но скажу лишь, что явно легче масштабировать множество маленьких баз данных, чем одну большую.

Упрощенный вид архитектуры letgo
Некоторые интуитивные решения часто становились ошибками. Вот список наиболее важных антипаттернов, с которыми мы столкнулись в нашей архитектуре, связанной с доменными событиями.
1. Толстые события
Мы стараемся делать так, чтобы наши доменные события были как можно меньше и при этом не теряли доменного значения. Нам следовало быть осторожнее при рефакторинге устаревших кодовых баз с большими сущностями и переходе на событийную архитектуру. Такие сущности могут привести нас к толстым событиям, но поскольку наши доменные события трансформировались в публичный контракт, нам нужно было делать их как можно проще. В таком случае рефакторинг лучше рассматривать со стороны. Для начала, мы проектируем наши события с использованием техники event storm, а затем рефакторим код сервиса, чтобы адаптировать его к нашим событиям.
Также нам следует вести себя осторожнее с проблемой «продукта и пользователя»: многие системы используют сущности продукта и пользователя, и эти сущности, как правило, тянут за собой всю логику, и это означает, что все доменные события связаны с ними.
2. События как intentions
Доменное событие, по определению, — это уже произошедшее событие. Если вы публикуете что-то в message bus, чтобы сделать запрос о том, что произошло в каком-то другом сервисе, вы, скорее всего, выполняете асинхронную команду, а не создаете доменное событие. Как правило, мы именуем доменные события в прошедшем времени: ser_registered, product_published и т. д. Чем меньше один сервис знает о других, тем лучше. Использование событий в качестве команд связывает сервисы и увеличивает вероятность того, что изменение в одном сервисе повлияет на другие сервисы.
3. Отсутствие независимой сериализации или сжатия
Системы сериализации и сжатия событий нашей предметной области не должны зависеть от языка программирования. Вам даже не обязательно знать, на каком языке написаны сервисы-потребители. Именно поэтому мы можем использовать сериализаторы Java или PHP, например. Пусть ваша команда потратит время на обсуждение и выбор сериализатора, потому что поменять его в будущем будет сложно и трудоемко. Мы в letgo используем JSON, однако есть множество других форматов сериализации с хорошей производительностью.
4. Отсутствие стандартной структуры
Когда мы начали переносить бэкенд letgo на событийно-ориентированную архитектуру, мы договорились об общей структуре доменных событий. Выглядит она примерно так:
Наличие общей структуры для наших доменных событий позволяет нам быстрее интегрировать сервисы и реализовывать некоторые библиотеки с абстракциями.
5. Отсутствие валидации схемы
Во время сериализации мы в letgo испытывали проблемы с языками программирования без строгой типизации.
Устоявшаяся культура тестирования, которая гарантирует проверку сериализации наших событий, и понимание того, как работает библиотека сериализации, помогает с этим справиться. Мы в letgo переходим на Avro и Confluent Schema Registry, что обеспечивает нам единую точку определения структуры событий нашего домена и позволит избежать ошибок такого типа, а также устаревания документации.
6. Анемичные доменные события
Как я сказал раньше, и как следует из названия, у доменных событий должно быть значение на уровне домена. Ровно также, как мы пытаемся избежать несогласованности состояний в наших сущностях, мы должны избегать этого и в доменных событиях. Давайте проиллюстрируем это на следующем примере: продукт в нашей системе имеет геолокацию с широтой и долготой, которые хранятся в двух разных полях таблицы products сервиса Products. Все продукты могут быть «перемещены», поэтому у нас появятся доменные события для представления этого обновления. Раньше для этого у нас было два события: product_latitude_updated и product_longitude_updated, что не имело большого смысла, если вы не ладья на шахматной доске. В данном случае больше смысла будет в событиях product_location_updated или product_moved.

Ладья – шахматная фигура. Раньше называлась тура. Ладья может двигаться только по вертикали или по горизонтали через любое количество незанятых полей.
7. Отсутствие инструментов для отладки
Мы в letgo производим тысячи доменных событий в минуту. Все эти события становятся чрезвычайно полезным ресурсом для понимания того, что происходит в нашей системе, регистрации активности пользователей или даже реконструкции состояния системы в определенный момент времени с помощью поиска по событиям. Нам нужно умело пользоваться этим ресурсом, а для этого нужны инструменты для проверки и отладки наших событий. Запросы вида «покажите мне все события, произведенные пользователем John Doe за последние 3 часа» также могут оказаться полезными для обнаружения мошенничества. Для этих целей мы разработали некоторые инструменты на ElasticSearch, Kibana и S3.
8. Отсутствие мониторинга событий
Мы можем использовать доменные события для проверки работоспособности системы. Когда мы что-то разворачиваем (что происходит несколько раз в день в зависимости от сервиса), нам нужны инструменты для быстрой проверки корректности работы. Например, если мы развернем на продакшене новую версию сервиса Products и увидим снижение количества событий product_published на 20%, можно с уверенностью сказать, что мы что-то сломали. На данный момент мы используем InfluxDB, Grafana и Prometheus для достижения этой цели с помощью производных функций. Если вы вспомните курс математики, то поймете, что производная функции f(x) в точке x равна тангенсу угла наклона касательной, проведённой к графику функции в этой точке. Если у вас есть функция скорости публикации определённого события предметной области и вы возьмете от нее производную, то увидите пики этой функции и сможете на основе них устанавливать уведомления. С помощью таких уведомлений вы сможете избежать фраз типа «предупредите меня, если мы будем публиковать меньше 200 событий в секунду в течение 5 минут», и сосредоточиться на значительном изменении скорости публикации.

Здесь случилось что-то странное… А может быть это просто маркетинговая кампания
9. Надежда на то, что все будет хорошо
Мы стараемся создавать устойчивые системы и снижать затраты на их восстановление. В дополнение к инфраструктурным проблемам и человеческому фактору, одна из самых распространенных вещей, которая может повлиять на событийную архитектуру, — это потеря событий. Нам нужен план, с помощью которого мы можем восстановить корректное состояние системы, обработав заново все события, которые были потеряны. Здесь наша стратегия основывается на двух моментах:
10. Отсутствие документации по доменным событиям
Наши доменные события стали нашим публичным интерфейсом для всех систем на бэкенде. Точно так же, как мы документируем наши REST API, нужно документировать и доменные события. Любой сотрудник организации должен иметь возможность просматривать обновленную документацию по каждому событию домена, опубликованному каждым сервисом. Если мы используем схемы для проверки доменных событий, их также можно использовать и в качестве документации.
11. Сопротивление к потреблению собственных событий
Вам разрешается и даже рекомендуется использовать собственные доменные события для создания проекций в вашей системе, которые, например, оптимизированы для чтения. Некоторые команды сопротивлялись этой концепции, поскольку замыкались на концепции потребления чужих событий.
До встречи на курсе!

Последние несколько лет наблюдается рост популярности микросервисной архитектуры. Есть много ресурсов, которые учат правильно ее реализовывать, однако достаточно часто люди говорят о ней, как о серебряной пуле. Против использования микросервисов есть множество аргументов, но самый весомый из них заключается в том, что этот тип архитектуры таит в себе неопределенную сложность, уровень которой зависит от того, как вы управляете отношениями между вашими сервисами и командами. Вы можете найти много литературы, которая расскажет почему (возможно) в вашем случае микросервисы окажутся не лучшим выбором.
Мы в letgo мигрировали с монолита к микросервисам, чтобы удовлетворить потребность в масштабируемости, и сразу же убедились в ее благотворном влиянии на работу команд. При правильном применении, микросервисы дали нам несколько преимуществ, а именно:
- Масштабируемость приложения: из личного опыта, самый больной момент масштабируемости приложения кроется в его архитектуре. Микросервисы подразумевают модульность кода и всей инфраструктуры (базы данных и т.д.) В правильно реализованной микросервисной архитектуре у каждого сервиса есть своя инфраструктура. Доступ к базе данных пользователей (чтение и запись) может осуществляться только сервисом Users.
- Масштабируемость организации: микросервисы помогают решать организационные проблемы и дают нам возможность управлять кодовой базой, которую изменяют несколько команд. Разделение кодовой базы предотвращает конфликты при внесении изменений. По нашему опыту, работа в больших командах не позволяет эффективно проводить масштабирование, поэтому, как только мы разбили программистов по небольшим командам, наша кодовая база тоже смогла разделиться на небольшие компоненты. К тому же организация работы в небольших командах способствует развитию ответственности.
Событийно-ориентированная архитектура
Не все микросервисные архитектуры событийно-ориентированные. Некоторые люди выступают за синхронную связь между сервисами в архитектуре такого вида с помощью HTTP (gRPC, REST и т.д.). В letgo мы стараемся не следовать этому шаблону и асинхронно связываем наши сервисы с доменными событиями. Вот причины, по которым мы это делаем:
- Улучшение масштабируемости и устойчивости: разделение большой системы на мелкие подсистемы позволяет контролировать влияние сбоев. Например, DDoS или всплеск трафика на одном из сервисов не повлияет на другие. Если ваши сервисы работают синхронно, то при DDoS на один сервис пострадает еще и другой. В таком случае можно говорить о том, что сервисы слишком взаимосвязаны. Для нас ключевой концепцией повышения масштабируемости и устойчивости является обозначение жестких границ сервисов и обеспечение связи между ними.
-

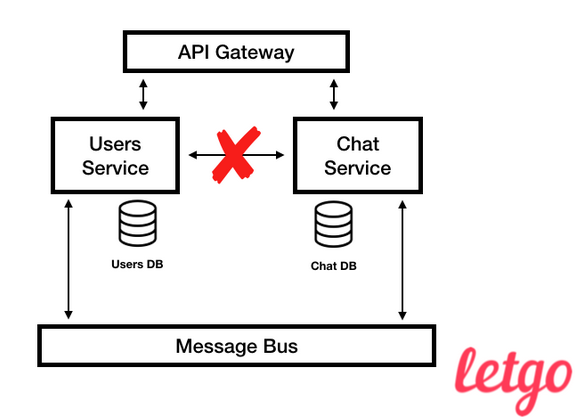
Переборки (bulkheads) – это вертикальные стены в корпусе судна, создающие водонепроницаемые отсеки, которые могут задержать воду в случае пробоины в корпусе корабля или протечки. - Разъединение: Изменение одного сервиса не должно влиять на другие. Мы считаем, что такие практики, как синхронизация развертывания нескольких служб, пахнут плохо, потому что они добавляют операциям сложность. Есть несколько способов эту сложность уменьшить, например, версионировать API, однако из личного опыта компании, скажу, что использование доменных событий в качестве публичного контракта сервиса помогает моделировать его домен так, чтобы работа одного сервиса не влияла на работу других. Сущность пользователя в нашем сервисе Users не должна быть той же самой сущностью, что и в сервисе Chat.
Исходя из этого мы в letgo стараемся придерживаться асинхронной связи между сервисами, а синхронная работает только в таких исключительных случаях как feature MVP. Мы делаем это потому, что хотим, чтобы каждый сервис генерировал свои собственные сущности на основе доменных событий, опубликованных другими сервисами в нашем Message Bus.
По нашему мнению, успех или неудача при реализации микросервисной архитектуры зависит от того, как вы справляетесь с присущей ему комплексностью и тем, как вашим сервисы взаимодействуют друг с другом. Разделение кода без перевода инфраструктуры связи на асинхронную превратит ваше приложение в распределённый монолит.

Событийно-ориентированная архитектура в letgo
Сегодня я хочу поделиться примером того, как мы в letgo используем доменные события и асинхронную связь: наша сущность User существует во многих сервисах, но ее создание и редактирование изначально обрабатывается сервисом Users. В базе данных сервиса Users мы храним много данных, таких как имя, адрес электронной почты, аватарку, страну и т.д. В нашем сервисе Chat у нас тоже есть концепция пользователя, но нам не нужны те данные, которые есть у сущности User из сервиса Users. В списке диалогов показывается имя пользователя, его аватар и ID (ссылка на профиль). Мы говорим, что в чате есть только проекция сущности User, которая содержит частичные данные. На самом деле в Chat мы не говорим о пользователях, мы называем их “talkers”. Эта проекция относится к сервису Chat и построена на событиях, которые Chat получает из сервиса Users.То же самое мы делаем с листингами. В сервисе Products мы храним n картинок каждого листинга, но в режиме просмотра списка диалогов мы показываем одну основную, поэтому наша проекция из Products в Chat требует только одну картинку вместо n.
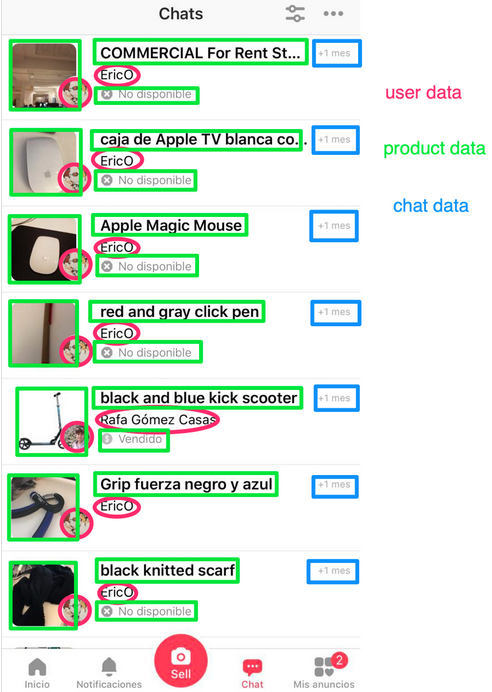
Просмотр списка диалогов в нашем чате. Показано какой конкретно сервис на бэкенде предоставляет информацию.
Если вы снова взглянете на список диалогов, то увидите, что почти все данные, которые мы показываем, не создаются сервисом Chat, но ему принадлежат, поскольку проекции User и Chat являются собственностью Chat. Между доступностью и согласованностью проекций есть компромисс, о котором мы не будем говорить в этой статье, но скажу лишь, что явно легче масштабировать множество маленьких баз данных, чем одну большую.
Упрощенный вид архитектуры letgo
Антипаттерны
Некоторые интуитивные решения часто становились ошибками. Вот список наиболее важных антипаттернов, с которыми мы столкнулись в нашей архитектуре, связанной с доменными событиями.
1. Толстые события
Мы стараемся делать так, чтобы наши доменные события были как можно меньше и при этом не теряли доменного значения. Нам следовало быть осторожнее при рефакторинге устаревших кодовых баз с большими сущностями и переходе на событийную архитектуру. Такие сущности могут привести нас к толстым событиям, но поскольку наши доменные события трансформировались в публичный контракт, нам нужно было делать их как можно проще. В таком случае рефакторинг лучше рассматривать со стороны. Для начала, мы проектируем наши события с использованием техники event storm, а затем рефакторим код сервиса, чтобы адаптировать его к нашим событиям.
Также нам следует вести себя осторожнее с проблемой «продукта и пользователя»: многие системы используют сущности продукта и пользователя, и эти сущности, как правило, тянут за собой всю логику, и это означает, что все доменные события связаны с ними.
2. События как intentions
Доменное событие, по определению, — это уже произошедшее событие. Если вы публикуете что-то в message bus, чтобы сделать запрос о том, что произошло в каком-то другом сервисе, вы, скорее всего, выполняете асинхронную команду, а не создаете доменное событие. Как правило, мы именуем доменные события в прошедшем времени: ser_registered, product_published и т. д. Чем меньше один сервис знает о других, тем лучше. Использование событий в качестве команд связывает сервисы и увеличивает вероятность того, что изменение в одном сервисе повлияет на другие сервисы.
3. Отсутствие независимой сериализации или сжатия
Системы сериализации и сжатия событий нашей предметной области не должны зависеть от языка программирования. Вам даже не обязательно знать, на каком языке написаны сервисы-потребители. Именно поэтому мы можем использовать сериализаторы Java или PHP, например. Пусть ваша команда потратит время на обсуждение и выбор сериализатора, потому что поменять его в будущем будет сложно и трудоемко. Мы в letgo используем JSON, однако есть множество других форматов сериализации с хорошей производительностью.
4. Отсутствие стандартной структуры
Когда мы начали переносить бэкенд letgo на событийно-ориентированную архитектуру, мы договорились об общей структуре доменных событий. Выглядит она примерно так:
{
“data”: {
“id”: [uuid], // event id.
“type”: “user_registered”,
“attributes”: {
“id”: [uuid], // aggregate/entity id, in this case user_id
“user_name”: “John Doe”,
…
}
},
“meta” : {
“created_at”: timestamp, // when was the event created?
“host”: “users-service” // where was the event created?
…
}
}Наличие общей структуры для наших доменных событий позволяет нам быстрее интегрировать сервисы и реализовывать некоторые библиотеки с абстракциями.
5. Отсутствие валидации схемы
Во время сериализации мы в letgo испытывали проблемы с языками программирования без строгой типизации.
{
“null_value_one”: null, // thank god
“null_value_two”: “null”,
“null_value_three”: “”,
}
Устоявшаяся культура тестирования, которая гарантирует проверку сериализации наших событий, и понимание того, как работает библиотека сериализации, помогает с этим справиться. Мы в letgo переходим на Avro и Confluent Schema Registry, что обеспечивает нам единую точку определения структуры событий нашего домена и позволит избежать ошибок такого типа, а также устаревания документации.
6. Анемичные доменные события
Как я сказал раньше, и как следует из названия, у доменных событий должно быть значение на уровне домена. Ровно также, как мы пытаемся избежать несогласованности состояний в наших сущностях, мы должны избегать этого и в доменных событиях. Давайте проиллюстрируем это на следующем примере: продукт в нашей системе имеет геолокацию с широтой и долготой, которые хранятся в двух разных полях таблицы products сервиса Products. Все продукты могут быть «перемещены», поэтому у нас появятся доменные события для представления этого обновления. Раньше для этого у нас было два события: product_latitude_updated и product_longitude_updated, что не имело большого смысла, если вы не ладья на шахматной доске. В данном случае больше смысла будет в событиях product_location_updated или product_moved.

Ладья – шахматная фигура. Раньше называлась тура. Ладья может двигаться только по вертикали или по горизонтали через любое количество незанятых полей.
7. Отсутствие инструментов для отладки
Мы в letgo производим тысячи доменных событий в минуту. Все эти события становятся чрезвычайно полезным ресурсом для понимания того, что происходит в нашей системе, регистрации активности пользователей или даже реконструкции состояния системы в определенный момент времени с помощью поиска по событиям. Нам нужно умело пользоваться этим ресурсом, а для этого нужны инструменты для проверки и отладки наших событий. Запросы вида «покажите мне все события, произведенные пользователем John Doe за последние 3 часа» также могут оказаться полезными для обнаружения мошенничества. Для этих целей мы разработали некоторые инструменты на ElasticSearch, Kibana и S3.
8. Отсутствие мониторинга событий
Мы можем использовать доменные события для проверки работоспособности системы. Когда мы что-то разворачиваем (что происходит несколько раз в день в зависимости от сервиса), нам нужны инструменты для быстрой проверки корректности работы. Например, если мы развернем на продакшене новую версию сервиса Products и увидим снижение количества событий product_published на 20%, можно с уверенностью сказать, что мы что-то сломали. На данный момент мы используем InfluxDB, Grafana и Prometheus для достижения этой цели с помощью производных функций. Если вы вспомните курс математики, то поймете, что производная функции f(x) в точке x равна тангенсу угла наклона касательной, проведённой к графику функции в этой точке. Если у вас есть функция скорости публикации определённого события предметной области и вы возьмете от нее производную, то увидите пики этой функции и сможете на основе них устанавливать уведомления. С помощью таких уведомлений вы сможете избежать фраз типа «предупредите меня, если мы будем публиковать меньше 200 событий в секунду в течение 5 минут», и сосредоточиться на значительном изменении скорости публикации.
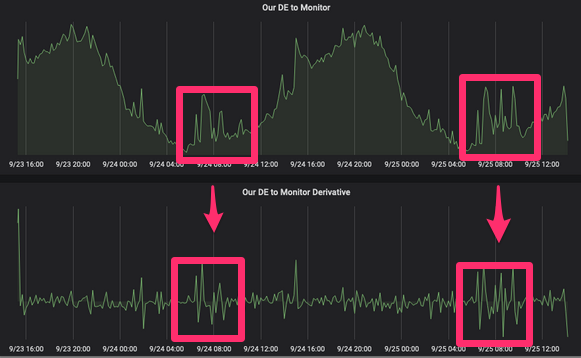
Здесь случилось что-то странное… А может быть это просто маркетинговая кампания
9. Надежда на то, что все будет хорошо
Мы стараемся создавать устойчивые системы и снижать затраты на их восстановление. В дополнение к инфраструктурным проблемам и человеческому фактору, одна из самых распространенных вещей, которая может повлиять на событийную архитектуру, — это потеря событий. Нам нужен план, с помощью которого мы можем восстановить корректное состояние системы, обработав заново все события, которые были потеряны. Здесь наша стратегия основывается на двух моментах:
- Сохранение всех событий: мы должны иметь возможность проводить такие операции, как «повторная обработка всех событий, которые произошли вчера», поэтому нужно какое-то хранилище событий, куда мы будем складывать все происходящие события. В letgo это в больше степени задача команды Data, чем команды Backend.
- Потребительская идемпотентность: наши сервисы-потребители должны иметь возможность обрабатывать событие более одного раза при этом не нарушая внутреннего состояния и не выдавая множества ошибок. Это может понадобиться, если нужно провести восстановление после сбоя и повторно обработать события, или потому, что message bus доставляет сообщение более одного раза. Идемпотенция – это, на наш взгляд, самое дешевое решение этой проблемы. Представьте, что мы в нашем сервисе слушаем событие user_registered из сервиса Users, потому что нам нужна проекция пользователя, а еще у нас есть таблица MySQL, которая использует user_id в качестве первичного ключа. Если при обработке доменных событий user_registered, мы не проверим существование перед вставкой, мы можем столкнуться с большим количеством ошибок дубликации ключей. В таком случае, даже если мы проверим существование пользователя перед вставкой, мы все равно можем получить ошибку из-за задержки между ведущим и ведомым MySQL (в среднем, примерно 30 мс). Поскольку эти проекции могут быть представлены в виде записей ключ-значение, мы перенаправляем их в DynamoDB. Даже если вы пытаетесь действовать идемпотентно, бывают варианты использования, такие как увеличение или уменьшение счетчика, когда очень сложно создать идемпотентного потребителя. В зависимости от того, насколько критичен вариант использования на уровне домена следует определиться, насколько вы терпимы к сбоям и несоответствиям, а также решить, окупается ли стоимость системы дедупликации.
10. Отсутствие документации по доменным событиям
Наши доменные события стали нашим публичным интерфейсом для всех систем на бэкенде. Точно так же, как мы документируем наши REST API, нужно документировать и доменные события. Любой сотрудник организации должен иметь возможность просматривать обновленную документацию по каждому событию домена, опубликованному каждым сервисом. Если мы используем схемы для проверки доменных событий, их также можно использовать и в качестве документации.
11. Сопротивление к потреблению собственных событий
Вам разрешается и даже рекомендуется использовать собственные доменные события для создания проекций в вашей системе, которые, например, оптимизированы для чтения. Некоторые команды сопротивлялись этой концепции, поскольку замыкались на концепции потребления чужих событий.
До встречи на курсе!
